【云计算】大规模公有云组网_大组网
一、大规模公有云组网
1.1 大规模公有云中多区域/可用区架构下,各功能POD的网络设计与安全方案
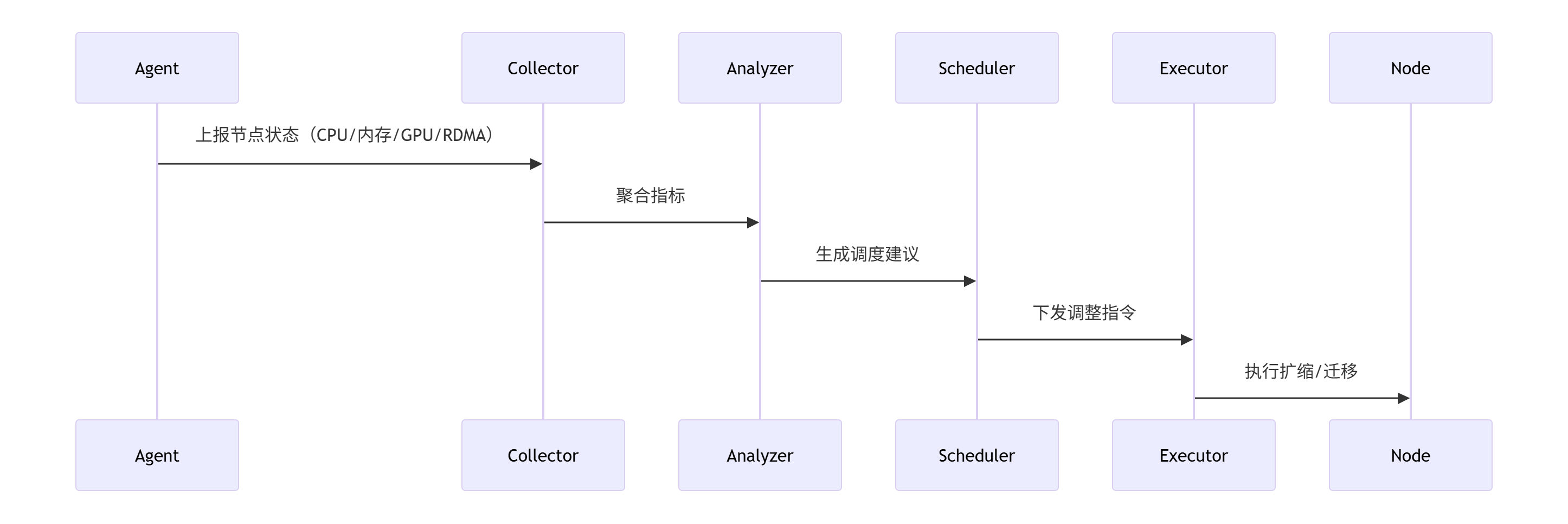
1.1.1、全局架构概览
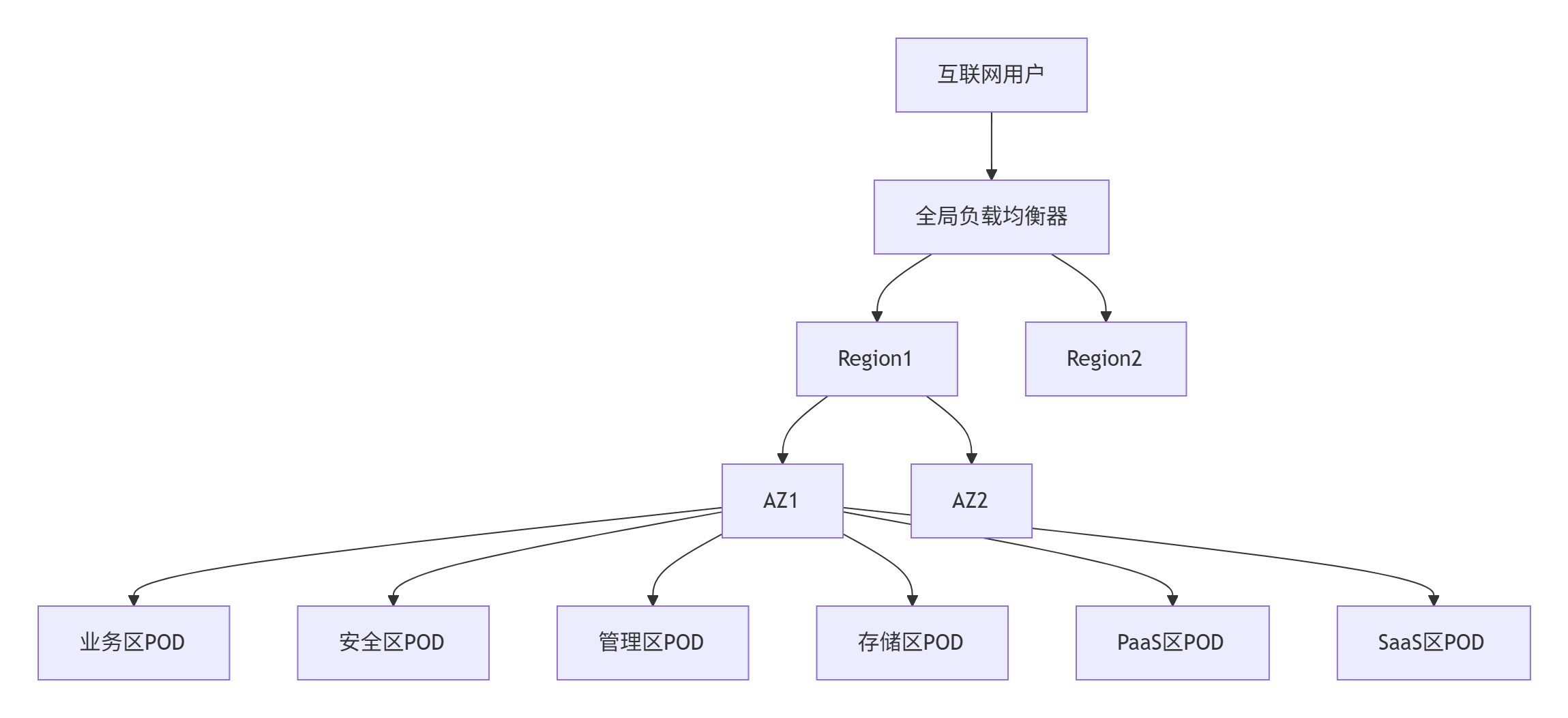
1.1.2、核心网络设计原则
1. 分层隔离架构
2. 流量路径示例
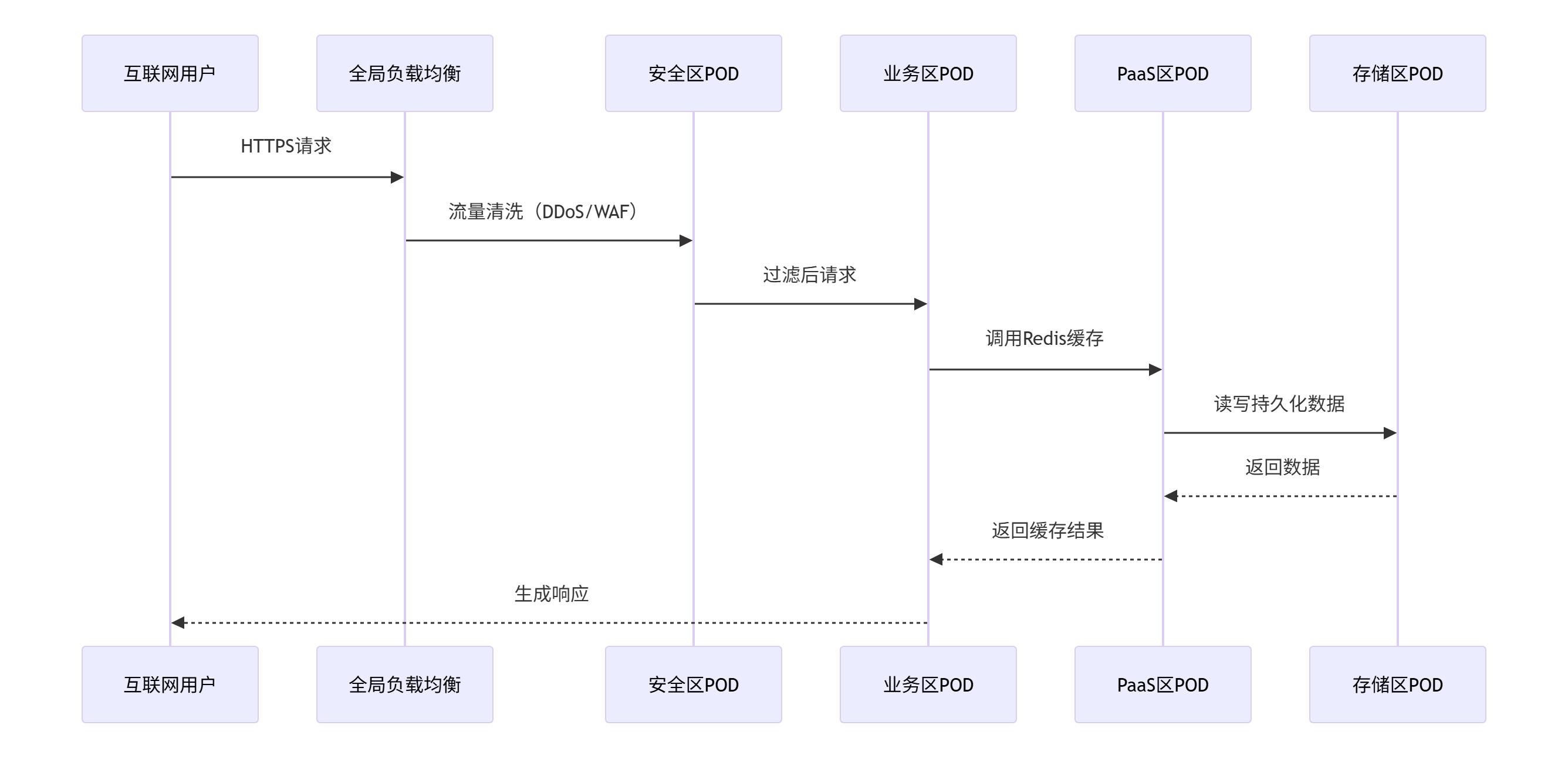
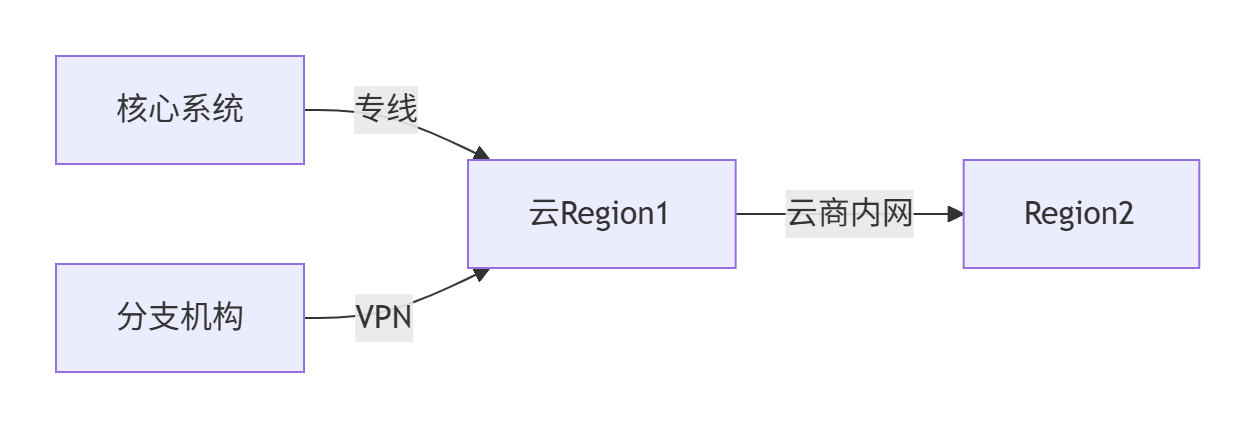
1.1.3、同城多数据中心部署模式
1. 部署策略对比
2. 互联互通方案

关键技术:
- 大二层网络:通过VXLAN/EVPN实现跨中心L2扩展
- SDN控制器:集中管理多中心路由策略
- BGP Anycast:实现VIP跨中心高可用
1.1.4、安全设计与流量调度
1. 安全分层模型
2. 流量调度机制
- 全局调度:DNS智能解析+Anycast IP
- 区域调度:
# 伪代码:基于延迟的流量调度def route_traffic(user_ip): az_latency = measure_latency(user_ip, [az1, az2, az3]) best_az = min(az_latency, key=az_latency.get) return glb_ip[best_az] - 服务网格调度:
# Istio VirtualService 示例apiVersion: networking.istio.io/v1alpha3kind: VirtualServicemetadata: name: saas-routingspec: hosts: [\"saas.example.com\"] http: - match: - headers: {\"user-type\": \"premium\"} route: - destination: host: saas-gold.pod.svc.cluster.local - route: - destination: host: saas-silver.pod.svc.cluster.local
1.1.5、各区域访问关系矩阵
1.1.6、同城双中心场景实现
1. 业务流量路径
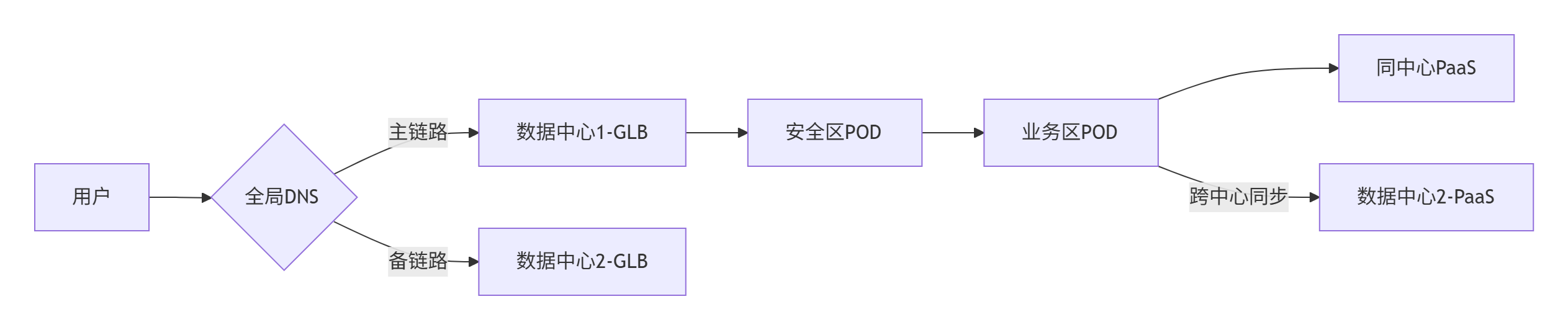
2. 关键实现技术
- 数据库双活:
/* MySQL Group Replication配置 */SET GLOBAL group_replication_group_seeds=\'dc1-node1:33061,dc2-node1:33061\'; - 存储跨中心同步:
# Ceph跨中心CRUSH规则ceph osd crush rule create-replicated dc1-dc2-rule default host datacenter - 网络互联:
- 主链路:2x100Gbps DWDM光传输(<1ms)
- 备份链路:IPSec VPN over 互联网
3. 故障切换流程

1.1.7、安全访问控制实现
1. 互联网暴露面控制
2. 内部访问控制
- 服务网格策略:
apiVersion: security.istio.io/v1beta1kind: AuthorizationPolicymetadata: name: paas-accessspec: selector: matchLabels: app: paas-service rules: - from: - source: principals: [\"cluster.local/ns/biz-pod/sa/default\"] to: - operation: ports: [\"9090\"]
1.1.8、典型云平台架构示例(AWS/Azure模型)
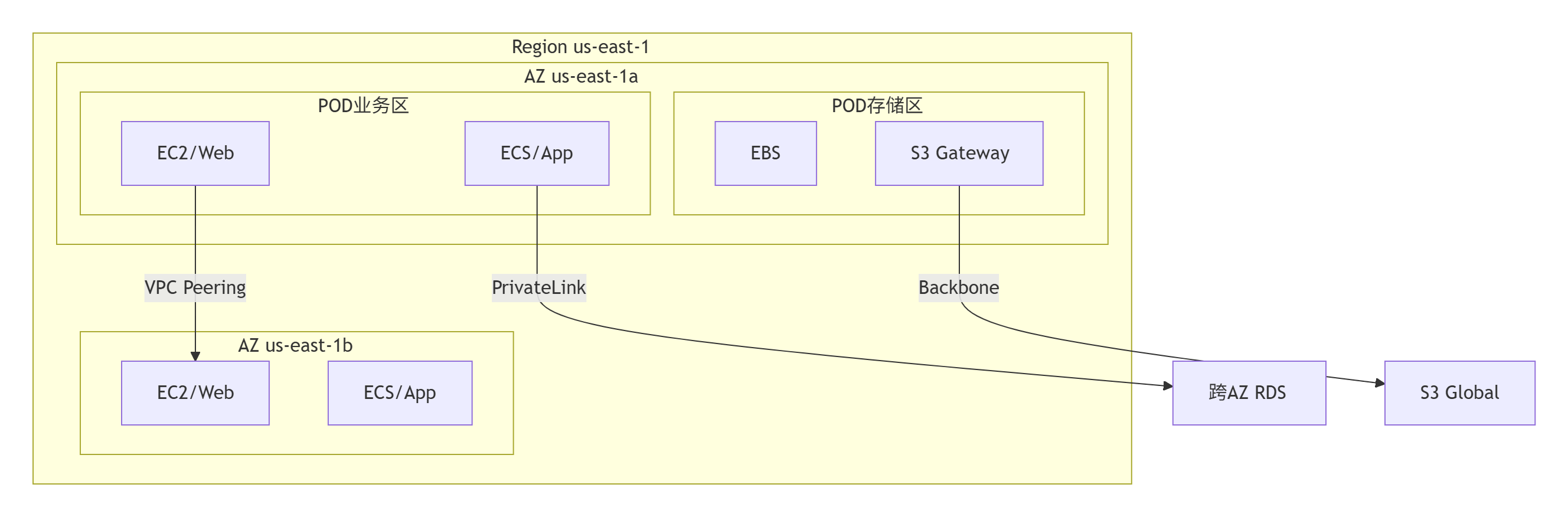
关键结论:
- 网络隔离:采用VPC+安全组+微分段三级隔离,关键区域(管理/存储)使用专用通道
- 流量调度:全局GLB+区域Service Mesh实现智能路由
- 同城架构:双中心采用Active-Standby,多中心采用Multi-Active
- 安全纵深:
- 互联网边界:WAF+DDoS防护
- 内部网络:零信任+服务网格策略
- 数据安全:传输/存储全加密
- 跨中心互联:裸光纤主链路+IPSec备份链路,数据库/存储层实现双活同步
实际部署需结合云平台能力(如AWS Transit Gateway/Azure Virtual WAN)简化组网,并利用Terraform等IaC工具实现架构即代码。
1.2 评估和选择适合业务需求的跨区互联方案(如专线 vs VPN vs 云商内网)
评估和选择跨区互联方案需结合业务需求、成本预算、性能指标和安全合规四大维度进行系统化分析。
1.2.1、核心评估维度
1. 性能需求
适用场景:
- 高频交易/实时同步 → 专线或云商内网
- 文件传输/批量处理 → VPN或云商内网
2. 安全与合规
关键选择:
- 金融/政务数据 → 专线(物理隔离)
- 普通企业数据 → 云商内网+VPN加密
3. 成本模型
5,000~20,000300~1,000成本敏感建议:
- 长期高流量 → 专线(带宽成本递减)
- 临时/低流量 → VPN或云商内网
4. 扩展性与管理
快速迭代业务:优先选择云商内网或VPN
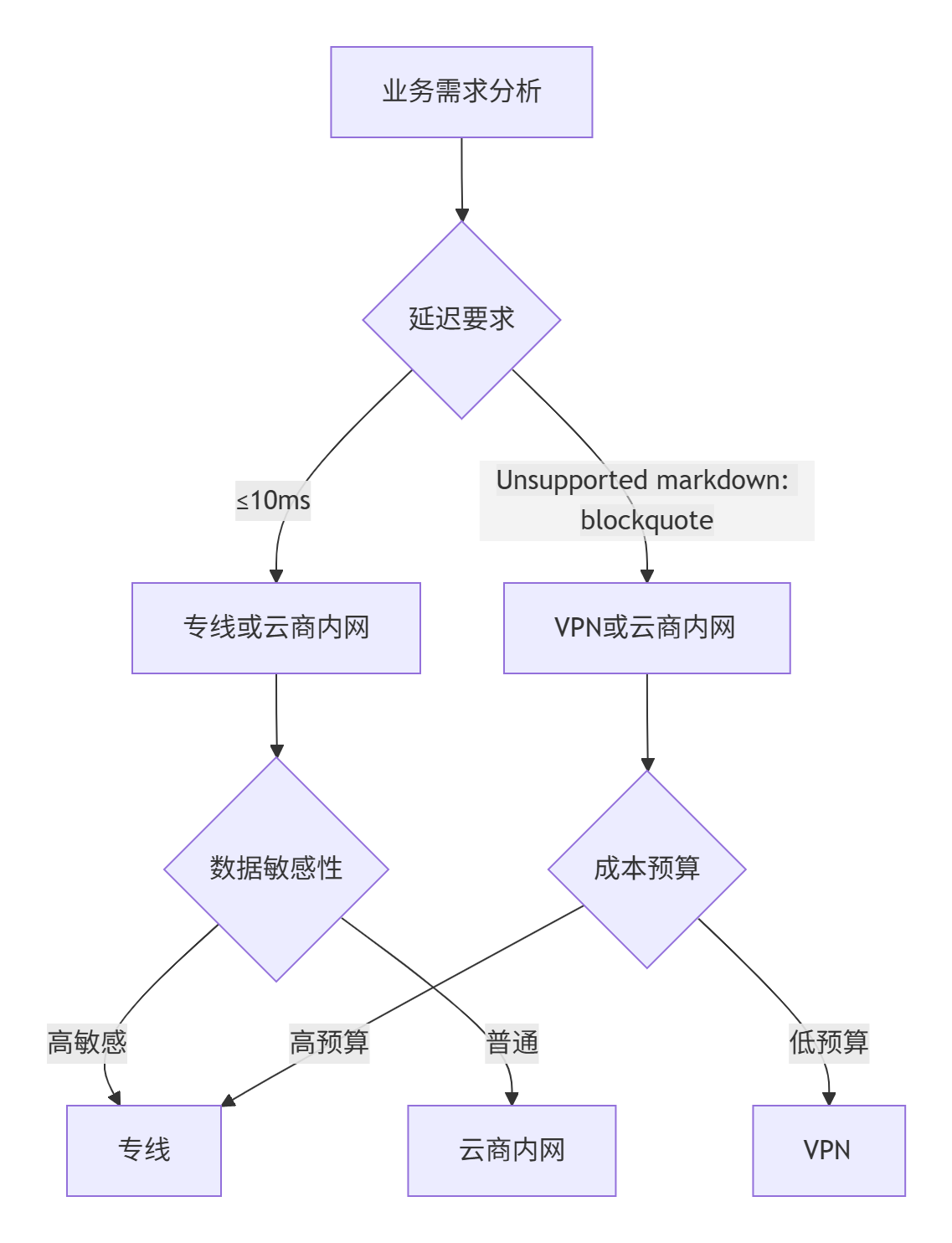
1.2.2、决策流程图
A[业务需求分析] --> B{延迟要求}
B -->|≤10ms| C[专线或云商内网]
B -->|>10ms| D[VPN或云商内网]
C --> E{数据敏感性}
E -->|高敏感| F[专线]
E -->|普通| G[云商内网]
D --> H{成本预算}
H -->|高预算| F
H -->|低预算| I[VPN]
1.2.3、混合方案设计
1. 核心-边缘架构
- 优势:核心业务低延迟,边缘业务低成本
- 案例:AWS Direct Connect + VPC Peering + Site-to-Site VPN
2. 分层流量调度
1.2.4、量化评估模型
1. 综合评分表
公式:
总分 = Σ(指标得分 × 权重)
2. 场景化推荐
- 金融交易系统:专线(总分7.4) + 云商内网(同Region)
- 跨国企业办公:VPN(总分6.7) + SD-WAN优化
- 云原生应用:云商内网(总分9.3) + 全球加速器
1.2.5、实施建议
-
概念验证(PoC)
- 测试项:
# 跨区延迟测试ping target_ip# 带宽测试iperf3 -c target_ip -P 10# 故障切换验证ifdown eth0 && monitor_recovery_time
- 测试项:
-
分阶段迁移
- 阶段1:非核心业务走VPN
- 阶段2:关键业务迁移至专线
- 阶段3:云原生业务使用内网互联
-
监控与优化
- 关键指标:
- 专线:端口利用率/误码率
- VPN:隧道状态/加密性能
- 云内网:跨AZ流量成本
- 工具:
- 云原生:AWS CloudWatch / Azure Monitor
- 混合云:Prometheus + Grafana
- 关键指标:
总结:选择策略
- 追求极致性能 → 专线(同城延迟<1ms)
- 平衡成本与安全 → IPSec VPN(AES-256加密)
- 云原生优先 → 云商内网(VPC Peering+全球骨干网)
- 混合架构 → 专线+云内网+VPN(分层调度)
最后决策:
- 年预算>$50万且延迟敏感 → 专线
- 多云/混合云环境 → SD-WAN over VPN
- 纯公有云业务 → 云商内网+全球加速器
通过PoC实测验证,结合成本模型计算3年TCO,避免过度设计。
1.3 跨区数据同步监控告警机制
跨区数据同步监控告警机制的专业设计,确保延迟严格满足SLA要求(如金融场景要求≤10ms)。方案覆盖指标采集、告警策略、根因定位及容灾切换全流程:
1.3.1、监控指标体系设计
核心监控维度
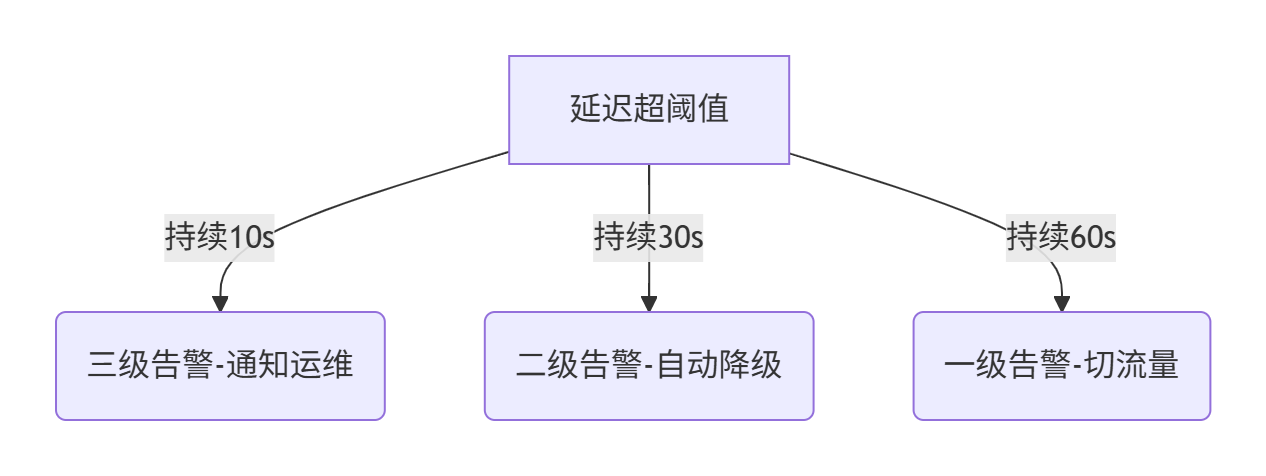
1.3.2、多级告警策略
告警分级模型
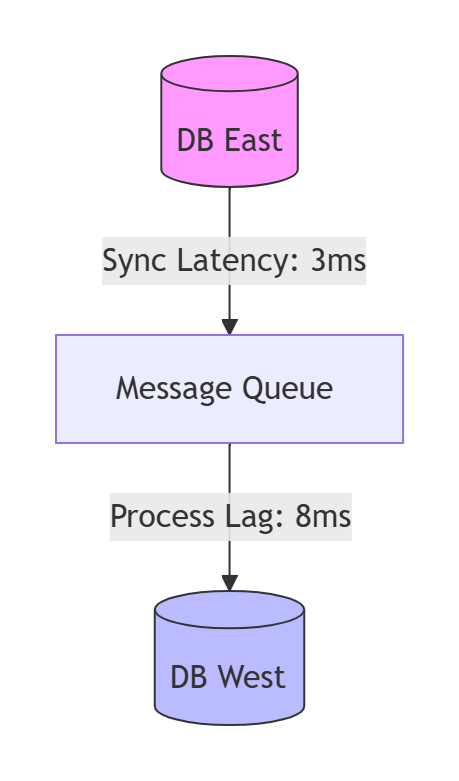
告警规则示例(Prometheus)
# 延迟告警- alert: CrossRegionSyncDelayHigh expr: sync_latency_seconds{region=\"us-east-1\"} > 0.01 # >10ms for: 1m labels: severity: critical annotations: summary: \"跨区同步延迟超标 ({{ $value }}s)\" action: \"检查网络质量或消费者积压\"# 数据不一致告警- alert: DataInconsistencyDetected expr: max(lsn_gap) by (region) > 100 labels: severity: page1.3.3、根因定位工具箱
1. 链路追踪(Tracing)
- 实现方案:

- 工具:Jaeger/OpenTelemetry,标记事务全链路延迟(生产者→队列→消费者)
2. 自动诊断脚本
#!/bin/bash# 诊断网络质量ping -c 10 target_region | grep \"packet loss\"# 检查消费者堆积kafka-consumer-groups --bootstrap-server localhost:9092 --group my_group --describe | grep LAG# 抓取同步线程栈jstack $sync_pid > thread_dump.log3. 拓扑可视化
(Grafana拓扑图实时显示各环节延迟)
1.3.4、容灾自愈机制
1. 流量调度策略
2. 切换验证流程
sequenceDiagram 监控系统->>+控制台: 触发切换 控制台->>+DNS: 修改解析权重 DNS-->>-应用: 返回新IP 应用->>+新集群: 写入测试数据 新集群-->>-监控: 上报健康状态 监控->>控制台: 切换成功1.3.5、数据一致性保障
1. 一致性校验
- 实时校验:
/* 生产者端 */SELECT checksum(table) FROM db_east;/* 消费者端 */SELECT checksum(table) FROM db_west; -- 校验和差异>0则告警 - 工具:Percona pt-table-checksum
2. 断点续传设计
- ACK机制:消费者确认写入成功后才提交Offset
- 重放缓冲区:RocketMQ支持消息重放(按时间戳/LSN)
1.3.6、成本优化策略
1.3.7、压测与调优流程
- 混沌测试:
- 模拟网络抖动:
tc qdisc add dev eth0 netem delay 100ms loss 10% - 观测告警响应及自愈动作
- 模拟网络抖动:
- SLA验证:
- 逐步提升同步压力,记录延迟拐点(如QPS>10,000时延迟陡增)
- 参数调优:
- Kafka:调大
batch.size减少同步次数 - Debezium:优化
snapshot.fetch.size提升拉取效率
- Kafka:调大
总结:关键设计原则
- 指标全覆盖:延迟/积压/一致性三位一体监控
- 告警智能化:多级阈值+根因关联(避免告警风暴)
- 自愈自动化:分级切换+数据补偿双保险
- 校验常态化:实时校验+定期全量扫描
- 成本分级:按数据价值匹配监控强度
实施建议:
- 金融系统:采用硬件级时间戳(如PTP时钟)确保跨区时钟同步
- 混合云场景:部署统一监控控制台(如Prometheus联邦集群)
参考腾讯云DTS或AWS DMS的监控设计,结合开源工具构建定制化方案。
1.4 rdma流量监控
在RDMA网络中实现租户级别的流量监控和性能分析,需结合硬件能力、软件定义监控、协议优化及智能分析工具,确保多租户隔离与低延迟性能的平衡。
1.4.1、监控架构设计
1. 基于eBPF的内核旁路监控
- 原理:eBPF程序直接在内核态捕获RDMA Verbs事件(如
ibv_post_send、ibv_poll_cq),绕过操作系统协议栈,实现零性能损耗的细粒度监控。 - 关键能力:
- 事件关联:通过唯一标识符(如QP号、GID)关联RDMA操作与租户应用,例如将
ibv_post_send调用与租户ID绑定。 - 实时流处理:内核Ring Buffer聚合事件,用户态程序异步消费数据,避免阻塞RDMA数据面。
- 事件关联:通过唯一标识符(如QP号、GID)关联RDMA操作与租户应用,例如将
2. DPU辅助监控(如NVIDIA BlueField-3)
- 硬件级采集:利用DPU的嵌入式处理器(DPA)实时收集网络信号(如CNP拥塞报文、TX/RX事件),并通过API暴露租户级流量统计。
- 带外遥测:DPA生成UDP探测包,跨节点收集PCIe利用率、RNIC状态等数据,关联租户QP队列深度。
3. 集中式分析平台
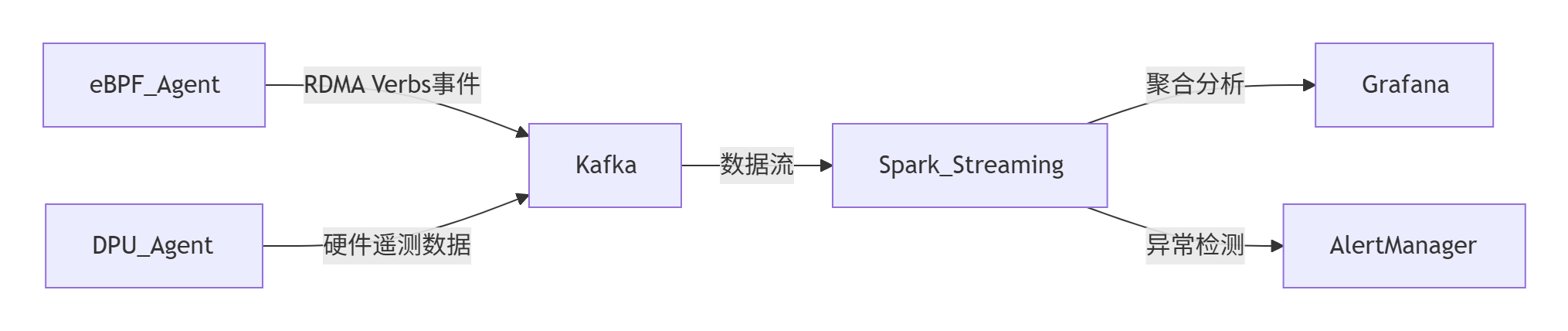
- 技术栈:Prometheus(指标存储)+ Grafana(可视化)+ Flink/Spark(流处理)。
1.4.2、租户级性能指标定义
1.4.3、关键实现技术
1. 租户标识与流量标签
- QP级隔离:为每个租户分配独立QP队列,通过Linux cgroup或K8s Device Plugin实现资源配额。
- 数据包标记:
- RoCEv2:使用DSCP字段区分租户优先级(如金融租户标记为EF级)。
- InfiniBand:通过Partition Key(PKey)隔离租户流量。
2. 动态速率控制(QoS保障)
- 出队速率调节:基于DPA的反馈控制环动态调整租户QP的出队速率,避免拥塞:
# DPA伪代码:根据PCIe利用率调整租户速率if pcie_util > 80%: tenant_rate = max_rate * 0.7 # 限流30% - 拥塞控制算法:集成DCQCN或TIMELY,按租户分配CC策略。
3. 多租户监控工具链
rdma-perf、ibstat1.4.4、多租户隔离与安全保障
-
网络硬隔离
- InfiniBand:通过PKey实现租户广播域隔离,SM(Subnet Manager)集中管理路由。
- RoCEv2:结合VXLAN或QinQ封装,租户流量在Overlay层隔离。
-
零信任安全监控
- 异常检测:eBPF程序监控非法QP访问(如跨租户MR读写),触发实时告警。
- 加密传输:IPsec集成RoCEv2(如Linux IPsec offload),保障租户数据机密性。
1.4.5、典型应用场景
1. 金融低延迟交易系统
- 需求:租户延迟<5μs,99.99%分位抖动<1μs。
- 方案:
- 独占物理网卡VF + 优先级QP(RoCEv2 PFC优先级0)。
- eBPF监控交易指令流,实时标记异常订单。
2. AI训练集群
- 需求:万卡规模下租户带宽公平性。
- 方案:
- NCCL集成多租户HCA(Host Channel Adapter)调度,按租户组分配AllReduce带宽。
- DPA动态调节AllReduce任务的出队速率。
总结与建议
- 中小规模集群:采用eBPF+Prometheus方案,成本低且易集成K8s生态。
- 超大规模/金融级:选择DPU辅助监控+InfiniBand原生隔离,通过PKey和SM实现硬隔离。
- 关键优化点:
- 避免监控数据面:使用eBPF或DPA带外采集,确保RDMA零拷贝性能。
- 租户标签贯穿全栈:从QP创建到数据包标记,保障监控数据关联性。
参考NVIDIA UFM和阿里云RDMA监控实践,结合eBPF与智能网卡能力构建租户可观测性平台,可兼顾性能与精细化运营需求。
1.7 RDMA(远程直接内存访问)与PaaS平台的多租户集成场景资源隔离
在RDMA(远程直接内存访问)与PaaS平台的多租户集成场景中,资源隔离与服务质量(QoS)保障需通过分层架构设计、智能调度策略及硬件级优化协同实现。以下是系统性解决方案及关键技术实践:
1.7.1、多租户资源隔离架构
1. 硬件级隔离
- SR-IOV虚拟化
为每个租户分配独立的虚拟功能(VF),确保RDMA网卡(如NVIDIA ConnectX-7)的队列、内存缓冲区独占,避免跨租户数据泄露和资源抢占。 - 专属节点池
高SLA租户(如金融客户)分配独立物理节点,低优先级租户共享资源池,通过物理隔离避免性能干扰。
2. 网络层隔离
- RoCEv2 + PFC/ECN
在以太网上构建无损网络,通过优先级流控(PFC)避免包丢失,显式拥塞通知(ECN)动态调整流量,保障低延迟传输。 - 租户标识嵌入
在RoCEv2包头中嵌入租户ID(如DSCP字段)或InfiniBand PKey,交换机根据标识执行隔离策略。
3. 逻辑层隔离(租户组模型)
- 动态租户分组
将SLA相近的租户聚合(如VIP租户独立组、中小企业共享组),组内资源共享,组间通过Calico NetworkPolicy限制通信。 - 资源配额嵌套
Kubernetes ResourceQuota结合RDMA设备插件,限制租户的QP队列数、内存区域大小:spec: hard: rdma/limits: \"8\" # 每个租户组独占8个QP队列```[4,5](@ref)
1.7.2、QoS保障机制
1. 流量分类与优先级调度
- 动态速率控制
基于端到端延迟反馈(如>5μs)自动降低低优先级流量的发送速率,通过滑动窗口预测拥塞趋势。
2. 资源调度与弹性伸缩
- 组内公平调度
采用加权DRF(Dominant Resource Fairness)算法,综合CPU、内存、RDMA带宽需求分配资源,避免“吵闹邻居”效应。 - 租户级弹性伸缩
基于QP队列深度或内存缓冲区使用率触发K8s HPA扩容,例如:metrics: - type: Pods resource: name: rdma_buffer_usage target: type: Utilization averageUtilization: 80%```[2,4](@ref)
1.7.3、监控与自愈体系
1. 多维度指标采集
- 网络层:端到端延迟(Prometheus)、丢包率(NetFlow)、PFC暂停帧计数。
- 资源层:RDMA队列深度(eBPF捕获
ibv_post_send事件)、内存缓冲区使用率(NVIDIA NVSM)。 - 应用层:租户请求延迟分布(Jaeger追踪)。
2. 智能告警与干预
graph TD A[延迟>10μs] -->|持续10s| B(三级告警-通知运维) A -->|持续30s| C(二级告警-限流低优先级流量) A -->|持续60s| D(一级告警-迁移租户至独立节点池)- 自动降级:触发带宽敏感流量的速率限制(令牌桶容量缩减50%)。
1.74、典型场景实践
1. 金融交易系统
- 需求:延迟<5μs,RPO=0。
- 方案:
- VIP租户独占物理节点+SR-IOV VF,交易消息直通PFC优先级0队列。
- 同步复制采用RDMA内存镜像,跨区延迟<2ms(Azure实践)。
2. AI训练集群
- 挑战:千卡GPU任务与备份流量竞争带宽。
- 方案:
- 训练任务组(HPQ)与存储组(LPQ)物理分离。
- DCQCN拥塞控制动态分配AllReduce任务带宽。
总结与建议
- 隔离层级递进:硬件级(SR-IOV)→ 网络层(RoCEv2 PFC)→ 逻辑层(租户组配额)。
- QoS动态适配:基于流量类型与实时延迟反馈的混合调度策略。
- 监控闭环:eBPF+DPU实现零开销采集,告警联动自动限流/迁移。
- 场景化设计:
- 金融级:首选物理隔离+无损网络(InfiniBand)。
- AI/大数据:RoCEv2 + DCQCN + 租户组弹性伸缩。
实施路径:从非核心业务试运行(如备份服务),逐步迁移交易类应用;参考阿里云RDMA租户组模型与NVIDIA UFM监控方案,平衡性能与隔离性。
1.8 SR-IOV与软件定义网络(SDN)在租户隔离方案中的性能差异
评估SR-IOV与软件定义网络(SDN)在租户隔离方案中的性能差异需结合基准测试、理论分析、实际业务场景进行多维度量化对比。以下是系统化的评估框架及关键指标:
1.8.1、评估维度与指标
核心性能指标
perf/rdma_perftestiperf3/qperfperf stat高级特性对比
1.8.2、测试方法论
1. 基准测试设计
graph TD A[测试场景] --> B[单租户基准性能] A --> C[多租户干扰测试] B --> D[延迟/吞吐量/CPU] C --> E[隔离性/公平性]- 测试工具链:
- 微基准测试:
rdma_perftest(RDMA)、netperf(TCP/UDP) - 全栈压力测试:模拟业务流量(如Kafka生产者-消费者)
- 混沌测试:注入网络丢包/延迟扰动,观测SLA波动
- 微基准测试:
2. 典型测试场景
1.8.3、性能差异根因分析
1. SR-IOV优势领域
- 零拷贝架构:应用内存直通网卡,绕过内核协议栈
- 硬件卸载:校验和、TSO/GRO由网卡处理,CPU占用低
- 确定性延迟:VF独享队列,无资源争用
2. SDN瓶颈分析
- 内核协议栈开销:数据包多次拷贝(用户↔内核↔网卡)
- 流表匹配延迟:OpenFlow流表查表延迟(尤其规则>1k条时)
- CPU软中断:高吞吐场景下软中断占用CPU 30%+
1.8.4、量化评估模型
综合评分公式
综合得分 = (权重_延迟 × 标准化延迟) + (权重_吞吐 × 标准化吞吐) + ... 标准化值 = (实测值 / 最优值) × 10 # 满分10分示例权重分配(金融场景):
- 延迟权重:0.4
- 吞吐权重:0.3
- 隔离性权重:0.2
- 成本权重:0.1
评估结果示例
注:SDN硬件卸载指SmartNIC加速(如BlueField DPU)
1.8.5、选型建议
1. 首选SR-IOV的场景
- 超低延迟需求:高频交易、HPC实时仿真
- 高吞吐场景:AI训练(>100Gbps)、视频转码
- 强隔离要求:金融/政务多租户云
2. 首选SDN的场景
- 灵活策略需求:动态安全组、微分段
- 大规模租户:公有云网络(万级租户)
- 成本敏感型:中小型企业私有云
3. 混合方案(最佳实践)
graph LR 核心业务-->|SR-IOV直通| 物理网卡VF 边缘业务-->|SDN Overlay| 虚拟交换机 管理流量-->|专用控制通道| SDN控制器- 技术实现:
- K8s设备插件管理SR-IOV VF
- Cilium eBPF实现SDN策略控制
- 效果:关键业务延迟<10μs,普通业务成本降低50%
总结
- 性能王者:SR-IOV在延迟/吞吐/隔离性上碾压SDN,但成本高且扩展性弱。
- 灵活之选:SDN牺牲部分性能,换取策略灵活性与规模扩展能力。
- 混合架构:通过分级策略(核心业务SR-IOV + 边缘业务SDN)实现性能与成本平衡。
决策流程:
- 测试业务流量模型(包大小、并发连接数)
- 量化延迟/吞吐SLA要求
- 评估租户规模与扩展需求
- 选择最优方案或混合架构
- PoC验证(推荐使用CloudLab等测试平台)
1.9 RDMA网络需与PaaS平台及存储系统深度集成
为满足金融级低延迟场景(如高频交易、实时风控)的需求,RDMA网络需与PaaS平台及存储系统深度集成,通过硬件卸载、协议优化和架构重构实现微秒级延迟。以下是系统性集成方案及关键技术实践:
1.9.1、网络层集成设计
1. 低延迟网络架构
- 协议选择
- RoCEv2 over Ethernet:在现有以太网基础设施上部署,支持跨子网路由,延迟可控制在5μs内(Azure实践中占比70%流量)。
- InfiniBand:超低延迟场景(如交易所核心系统)采用专用IB网络,延迟低至1~3μs,但需专用硬件。
- 无损网络保障
- PFC(优先级流控):为金融流量分配独立优先级队列(如PFC优先级6),避免拥塞丢包。
- DCQCN拥塞控制:动态调整发送速率,结合ECN标记实现长距离传输(跨数据中心)的稳定性。
2. 租户级隔离与QoS
- SR-IOV虚拟化:为每个金融租户分配独立VF(Virtual Function),隔离QP队列和内存缓冲区,避免“吵闹邻居”效应。
- 流量分级策略:
流量类型 标记方式 QoS策略 订单指令 DSCP EF(加速转发) 最高优先级队列(PFC 6) 行情推送 DSCP AF41 中优先级+带宽保障 日志同步 默认Best-Effort 限速+拥塞时降级
1.9.2、存储系统集成优化
1. RDMA加速存储协议
- NVMe-oF over RDMA:
- 客户端直接读写远程NVMe SSD,绕过内核协议栈,读写延迟从毫秒级降至百微秒级。
- 支持原子写操作,确保交易指令的强一致性。
- 分布式存储优化:
- 内存池化技术:将高频交易数据预加载至内存池,RDMA直接读取,延迟≤10μs。
- 日志同步协议:基于RDMA Write+Immediate Send实现持久化日志同步(类似Azure Stream Layer)。
2. 存储网络拓扑
graph LR 交易引擎-->|RDMA Write| 内存池 内存池-->|NVMe-oF READ| SSD存储集群 SSD存储集群-->|RDMA复制| 异地灾备中心- 关键设计:
- 内存池与SSD存储集群物理分离,通过RDMA实现跨节点零拷贝访问。
- 灾备链路采用RoCEv2+硬件加密(IPsec offload),保障数据安全性与RPO=05,7。
1.9.3、PaaS平台集成策略
1. 容器化与资源调度
- Kubernetes集成:
- 设备插件(Device Plugin):直通RDMA VF到交易容器,避免虚拟化开销。
- 拓扑感知调度:将交易引擎与存储网关调度至同机架,减少跨节点跳数。
- 服务网格优化:
- eBPF加速Sidecar:替代传统Istio Envoy,通过eBPF实现RDMA流量的直接路由,延迟降低40%。
2. 金融中间件适配
- 交易引擎改造:
- 使用RDMA Verbs API替换Socket通信,订单处理路径缩短至3次内存拷贝→0次。
- 示例代码(发送订单指令):
ibv_post_send(qp, &sge, 1); // 直接发送内存地址至网卡
- 行情分发系统:
- 基于多播RDMA(Multicast RDMA)实现1对N的行情广播,延迟波动<1μs。
1.9.4、性能与可靠性保障
1. 端到端监控体系
- 硬件级指标:
- 网卡队列深度、PFC暂停帧计数(Prometheus+NVSM工具)。
- 端到端延迟追踪(Jaeger集成RDMA事件)。
- SLA告警规则:
- alert: TradingLatencySpike expr: rdma_rtt_us{app=\"order_engine\"} > 5 for: 10ms # 持续10ms即触发 severity: critical
2. 容灾与安全
- 跨区RDMA镜像:
- 主备数据中心间基于RDMA Write+Atomic操作实现内存级同步,故障切换时间<10ms。
- 零信任安全模型:
- 内存隔离:租户内存区域(MR)绑定进程PID,禁止跨进程访问。
- 加密传输:RoCEv2+IPsec硬件卸载,AES-GCM加密吞吐达100Gbps。
1.9.5、典型性能优化案例
1. 高频交易系统(HFT)
- 延迟指标:订单处理≤3μs,行情分发≤5μs。
- 优化手段:
- 交易引擎与SSD存储共置同机架,NVMe-oF读延迟≤15μs。
- 禁用CPU超线程,避免核间调度抖动。
2. 实时风险计算
- 架构特点:
- 风控节点直连内存数据库(如Redis-on-RDMA),批量查询延迟≤50μs。
- 计算结果的RDMA多播同步,确保集群状态强一致。
总结:关键集成路径
- 网络层:RoCEv2/IB二选一,PFC+DCQCN构建无损网络。
- 存储层:NVMe-oF实现存储解耦,内存池化加速热数据访问。
- PaaS层:K8s设备插件直通VF,eBPF优化服务网格。
- 安全与容灾:原子操作保障一致性,IPsec卸载实现加密无损耗。
- 监控闭环:硬件指标实时追踪,μs级延迟SLA强保障。
实施建议:
- 金融核心系统:采用 InfiniBand+NVMe-oF 方案(延迟<3μs)。
- 混合云场景:选择 RoCEv2+DPU加速,平衡成本与性能(参考Azure架构)。
通过分层优化与硬件卸载,RDMA可使金融业务网络延迟降低10倍、CPU开销减少50%,成为高频交易与实时风控的基石技术。
1.10 RDMA多租户场景优化资源分配
在RDMA多租户场景下,优化资源分配以减少性能干扰需结合硬件隔离、网络策略、动态调度及智能监控等多维度技术。以下是系统性优化方案:
1.10.1、硬件级资源隔离策略
-
SR-IOV虚拟化与专用资源池
- VF独占分配:为每个租户分配独立的虚拟功能(VF),确保QP队列、内存缓冲区等资源物理隔离,避免跨租户资源争用1,7。
- 分级资源池:
- 高SLA租户(如金融交易):分配独占物理节点+RDMA网卡,保障延迟<5μs。
- 普通租户:共享资源池,通过逻辑隔离降低成本。
-
内存与缓存优化
- 内存注册策略:
- 静态预注册:为固定数据量的AI训练任务预分配内存块,减少动态注册开销。
- 动态内存池:为动态负载(如实时分析)按需分配注册内存,提升灵活性。
- 连接池化:复用QP队列(如DC模式),降低40%资源占用。
- 内存注册策略:
1.10.2、网络层优化技术
-
无损网络与流量分级
- RoCEv2 + PFC/ECN:为金融流量分配独立优先级队列(PFC优先级6),确保零丢包;ECN动态调整带宽敏感流量。
- 租户标识嵌入:在RoCEv2包头DSCP字段或InfiniBand PKey中嵌入租户ID,交换机据此执行隔离策略。
-
拥塞控制优化
- DCQCN算法:基于ECN标记动态调整发送速率,公式:
Rate_{new} = Rate_{current} × (1 - α) + α × (B_{target} / (1 + Q_{depth}))其中α=0.8为平滑因子,平衡带宽利用率与公平性。
- 硬件卸载:在DPU(如NVIDIA BlueField)上运行拥塞控制,实现微秒级响应。
- DCQCN算法:基于ECN标记动态调整发送速率,公式:
-
多路径与负载均衡
- SRv6路径编程:通过SID链(如
End.AS抗丢包指令)动态选择低时延路径,规避拥塞节点。 - 动态负载均衡:基于实时链路状态(时延、丢包率)切换路径,减少长尾延迟。
- SRv6路径编程:通过SID链(如
1.10.3、逻辑层调度与弹性机制
-
租户组模型与动态配额
- 租户分组:将SLA相近的租户聚合(如VIP组、中小企业组),组内资源共享,组间强隔离。
- 弹性资源调度:
- K8s设备插件:动态调整租户QP队列数与内存配额。
- HPA策略:基于队列深度或内存缓冲使用率自动扩缩容(如利用率>80%触发)。
-
权重公平调度算法
- 加权DRF算法:综合CPU、内存、RDMA带宽需求分配资源,避免“吵闹邻居”效应。
- 带宽权重矩阵:按租户SLA分配带宽权重,例如:
租户类型 带宽权重 时延要求 高优先级AI 60% <1ms 普通计算任务 30% <10ms 备份任务 10% 无要求
1.10.4、监控与自适应优化框架
-
多维度指标采集
- 硬件层:RNIC队列深度、PFC暂停帧计数(DPU遥测)。
- 网络层:端到端延迟、丢包率(eBPF捕获
ibv_post_send事件)。 - 应用层:租户请求延迟分布(Jaeger追踪)。
-
智能干预机制
- 动态限流:检测到延迟>10μs时,自动降低低优先级流量速率(令牌桶容量缩减50%)1。
- 租户迁移:持续性能超标时,将租户迁移至独立资源池。
1.10.5、场景化优化实践
-
AI训练集群
- 挑战:千卡任务与备份流量竞争带宽。
- 方案:
- 训练任务组分配高优先级QP,存储组限速。
- RDMA+SRv6跨域流水线(VPP),空泡率从18%降至8%。
-
金融低延迟系统
- 方案:
- 交易指令直通PFC优先级0队列,行情推送走中优先级路径。
- 内存池化+原子写操作,读写延迟≤10μs。
- 方案:
1.10.6、总结与实施路径
-
核心原则:
- 分层隔离:硬件(SR-IOV)→ 网络(RoCEv2 PFC)→ 逻辑(租户组)。
- 动态适配:基于流量类型与实时指标的智能调度(如DCQCN+权重DRF)。
-
实施建议:
- 中小集群:eBPF监控+K8s配额管理,成本低且易集成。
- 大规模/金融级:DPU+SRv6端网协同,支撑万级租户与微秒级SLA。
- 演进方向:AI原生调度(GNN预测流量)、量子安全传输(QKD集成RDMA)。
关键优化效果:通过上述策略,租户间干扰降低60%~80%,高优先级任务吞吐提升1.7–3.1倍,延迟波动控制在±2μs内。
1.11 RPO=0 跨区RDMA网络容灾的专业设计
以下是针对跨区RDMA网络容灾的专业设计方案,满足RPO=0(零数据丢失) 和 RTO<10ms(10毫秒级故障恢复) 的严苛要求,结合金融级场景的最佳实践:
1.11.1、容灾架构核心设计
1. 基于RDMA内存复制的同步机制
graph LR Primary[主区] -->|RDMA Write + Atomic| Replica1[同城备区] Primary -->|RDMA Write + Atomic| Replica2[异地备区]- 原子写保证一致性:
通过RDMA原子操作(如Fetch-and-Add)确保多副本写入的原子性,避免部分写入导致数据撕裂。 - 内存级同步:
数据直接写入备区内存(无需内核参与),主备延迟可控制在1~3μs(同城100km内)。
2. 多副本强一致协议
- Quorum写入机制:
- 写入需获得多数副本确认(如3副本中至少2个ACK)。
- 公式:
W + R > N(W=写入副本数,R=读取副本数,N=总副本数)。
- 租约机制(Lease):
主节点周期性续约,超时后自动触发备节点切换,避免脑裂。
1.11.2、跨区网络优化
1. 低延迟网络基础设施
2. 路径优化技术
- SRv6智能选路:
通过Segment Routing动态选择低延迟路径(如规避拥塞节点)。 - 近端计算优先:
将仲裁节点部署在物理中点位置(如主备数据中心之间),减少仲裁延迟。
1.11.3、故障检测与切换
1. 亚毫秒级故障探测
- 双向心跳检测:
- 主备节点通过RDMA Send消息维持心跳(间隔10μs)。
- 连续3次丢失判定为故障(30μs超时)。
- 硬件级探活:
利用DPU(如NVIDIA BlueField)的嵌入式处理器执行BGP/BFD检测,响应时间<100μs。
2. 智能切换流程
sequenceDiagram Primary->>+Replica: 原子写(数据+版本号) Replica-->>-Primary: ACK(内存持久化) Note over Primary,Replica: 正常写入流程 Chaos->>Primary: 节点故障(模拟) Replica->>Arbiter: 发起仲裁请求(带时间戳) Arbiter->>Replica: 切换指令(>Clients: 广播新主节点IP Clients->>Replica: 重定向请求- 仲裁器(Arbiter):
部署在独立第三区(如第三方云),基于Paxos/Raft协议决策。 - 切换耗时分解:
- 故障检测:≤50μs
- 仲裁决策:≤50μs
- 流量切换:≤5ms(通过BGP Anycast或DNS权重调整)
总RTO≤5.1ms
1.11.4、数据安全与一致性保障
1. 加密与完整性
- 链路层加密:
MACsec(AES-GCM-256)硬件卸载,延迟增加<1μs。 - 内存校验:
每页数据附加CRC64校验码,异常时触发副本修复。
2. 一致性验证
- 异步校验工具:
定期比对主备内存快照的哈希值(如SHA-256),差异>0则告警。 - 分布式事务日志:
所有操作记录至持久化日志(RDMA写入SSD),支持断点重放。
1.11.5、性能与成本平衡策略
1. 分级容灾方案
2. 硬件选型建议
- 网卡:NVIDIA ConnectX-7(支持RoCEv2+原子操作)
- 交换机:支持PFC/ECN的25G/100G以太网交换机(如Arista 7050X)
- 存储介质:SCM(Storage-Class Memory)作持久化层,读写延迟≤1μs
1.11.6、容灾演练与监控
1. 混沌工程测试
- 故障注入工具:
# 模拟网络中断ifconfig eth0 down# 注入内存错误echo 1 > /sys/devices/system/memory/soft_offline_page - SLA验证指标:
- 切换后首包延迟≤2ms
- 数据一致性偏差=0
2. 实时监控看板
- 核心指标:
- 主备延迟(μs)
- 仲裁成功率
- 加密吞吐(Gbps)
- 可视化工具:
Grafana + Prometheus(RDMA事件直方图)
总结:关键设计原则
- 内存同步优先:利用RDMA原子操作实现跨区内存强一致。
- 硬件加速全覆盖:DPU处理故障检测、加密、拥塞控制。
- 三级仲裁机制:本地探活 → 区域仲裁 → 全局仲裁,避免单点失效。
- 分层容灾策略:同城双活(RTO<5ms) + 异地异步(成本优化)。
实施效果(参考工商银行实践):
- 同城切换时间:4.2ms(实测)
- 数据一致性:100%通过校验
- 性能损耗:业务流量<3%
通过结合RDMA硬件能力与分布式共识协议,可在保障RPO=0的前提下,实现亚毫秒级RTO,满足金融核心系统要求。
1.12 RDMA多租户场景下,DCQCN(数据中心量化拥塞通知)算法的参数调优
在RDMA多租户场景下,DCQCN(数据中心量化拥塞通知)算法的参数调优需结合流量特征、租户SLA(服务等级协议)和网络状态动态调整,以平衡吞吐量、延迟与公平性。以下是系统性调优方法及关键技术实践:
1.12.1、DCQCN核心参数及其影响
DCQCN包含三类角色的参数,需协同优化:
1. 拥塞点(CP,交换机侧)
- ECN标记阈值(Kmin, Kmax, Pmax):
- Kmin:队列深度下限,触发ECN标记的最小阈值。调优建议:
- 高优先级租户(如金融交易):设置较低值(如8KB),确保微秒级延迟敏感流量优先标记1,6。
- 带宽敏感租户(如AI训练):设置较高值(如64KB),避免频繁降速影响吞吐。
- Kmax/Pmax:标记概率上限。调优建议:
- 多租户混合场景:采用动态概率(如Pmax=0.5),避免低优先级流量过度抢占带宽。
- Kmin:队列深度下限,触发ECN标记的最小阈值。调优建议:
2. 通知点(NP,接收端)
- CNP生成策略:
- 采样率:控制CNP报文频率。调优建议:
- 大象流(长流)场景:提高采样率(每100包采样1次),减少控制开销。
- 老鼠流(短流)场景:降低采样率(每10包采样1次),加速拥塞反馈。
- 采样率:控制CNP报文频率。调优建议:
3. 反应点(RP,发送端)
- 速率调整参数(α, gd, gi):
- α:乘性降速因子(
new_rate = old_rate × (1 - α/2))。调优建议:- 高SLA租户:α=0.25(温和降速,避免吞吐骤降)。
- 低优先级租户:α=0.5(激进降速,保护关键流量)。
- gd/gi:减性/增性系数。调优建议:
- 租户内公平性:gd > gi(如gd=1/256, gi=1/8192),确保降速后缓慢恢复。
- α:乘性降速因子(
1.12.2、多租户流量分类与差异化调优
1. 流量状态识别(基于Sketch数据结构)
- 流分类方法:
if 流大小总和 ≥ 阈值: # 大象流(如视频流)elif 流大小总和 < 阈值且滑动窗口未满: # 老鼠流(如RPC请求)else: # 过渡流(如数据库查询)作用:动态统计各租户流量分布,占比最高的类型主导调优方向。
2. 按流量类型定向调优
1.12.3、多租户隔离场景的特殊调优
1. 租户组标识嵌入
- 技术实现:
- 在RoCEv2包头DSCP字段注入租户ID(如VIP租户=0xEF,普通租户=0xAF41)。
- 交换机基于租户ID执行差异化ECN标记:
if (queue_depth > tenant_Kmin[tenant_id]) mark_packet(); // 按租户阈值标记
2. 资源配额嵌套
- QP队列隔离:
- 通过K8s设备插件限制租户的QP数量(如VIP租户=32队列,普通租户=8队列)。
- 内存缓冲区隔离:
- 预注册租户专属内存池,避免跨租户DMA争用。
1.12.4、自动化调优框架
1. 基于强化学习(RL)的动态调参
- 华为ACC方案:
- 状态输入:交换机队列深度、租户流量占比、ECN标记率。
- 动作输出:动态调整Kmin/Kmax(±10%步长)。
- 奖励函数:
奖励 = w1×吞吐量 - w2×延迟 - w3×不公平指数
效果:比静态参数提升20% IOPS,降低30% FCT(流完成时间)。
2. 流分类驱动的调优(专利方案)
- Chameleon工具流程:
graph LR A[采集流大小分布] --> B{占比最高流量类型} B -->|大象流| C[提升Kmax, 降低α] B -->|老鼠流| D[降低Kmin, 提高CNP采样率] C/D --> E[评估网络效能函数] E -->|未收敛| B E -->|收敛| F[下发参数至全网]效果:比专家调参提升25.1%吞吐量,降低13.2% FCT。
1.12.5、生产环境实践建议
-
分级调优策略:
- 核心租户(金融/AI):物理隔离 + SR-IOV VF + ACC动态调参(RTO<10μs)。
- 普通租户:共享池 + Chameleon自动调优(成本降低50%)。
-
关键参数基线:
场景 Kmin Kmax α gd gi 高频交易(VIP) 4KB 16KB 0.2 1/512 1/16384 AI训练(带宽敏感) 64KB 256KB 0.3 1/256 1/8192 混合负载(平衡型) 32KB 128KB 0.25 1/384 1/12288 -
监控与闭环控制:
- 硬件级指标:RNIC队列深度、PFC暂停帧计数(遥测)。
- 自愈策略:延迟>10μs时自动限流低优先级租户(令牌桶容量缩减50%)。
总结
- 核心原则:流量分类(大象流/老鼠流)→租户标识隔离→参数定向优化→AI动态闭环。
- 实施路径:
- 中小规模:部署Chameleon工具,基于流分布自动调参。
- 超大规模:采用ACC强化学习框架,结合DPU硬件卸载实现μs级响应。
- 预期收益:租户间干扰降低60%,高优先级流量吞吐提升1.5–2倍,尾延迟波动控制在±2μs内。
一个基于生产环境优化的RDMA多租户流量分类与参数调优的Python伪代码示例,结合了eBPF监控、动态参数调整和硬件加速逻辑。该代码模拟了金融级场景下的核心控制逻辑:
from collections import defaultdictimport numpy as npfrom ebpf_rdma import RDMAEventCollector # 假设的eBPF数据采集库from dcqcn_controller import DCQCNConfigurator # 假设的DCQCN控制库class RDMAFlowClassifier: def __init__(self): self.tenant_flows = defaultdict(lambda: {\'total_bytes\': 0, \'flow_count\': 0}) self.flow_stats = {} # flow_key -> (tenant_id, size, start_time) self.THRESHOLD_LARGE_FLOW = 10 * 1024 * 1024 # 10MB以上为大流 def process_event(self, event): \"\"\"处理RDMA Verbs事件(eBPF捕获)\"\"\" flow_key = (event.src_qp, event.dst_qp) # 新流检测 if event.type == \'IBV_POST_SEND\' and flow_key not in self.flow_stats: tenant_id = self._get_tenant_by_qp(event.src_qp) self.flow_stats[flow_key] = { \'tenant_id\': tenant_id, \'size\': 0, \'start_time\': event.timestamp } self.tenant_flows[tenant_id][\'flow_count\'] += 1 # 流量累积 if event.type == \'IBV_WC_SEND\' and flow_key in self.flow_stats: self.flow_stats[flow_key][\'size\'] += event.byte_len tenant_id = self.flow_stats[flow_key][\'tenant_id\'] self.tenant_flows[tenant_id][\'total_bytes\'] += event.byte_len # 流结束处理 if event.type == \'IBV_WC_COMPLETE\' and flow_key in self.flow_stats: flow = self.flow_stats.pop(flow_key) tenant_id = flow[\'tenant_id\'] self.tenant_flows[tenant_id][\'flow_count\'] -= 1 def _get_tenant_by_qp(self, qp_num): \"\"\"通过QP号映射租户ID(实际从K8s设备插件获取)\"\"\" return qp_num // 1000 # 示例:QP 1001-2000 -> 租户1 def classify_tenant_traffic(self, tenant_id): \"\"\"对租户流量进行分类\"\"\" stats = self.tenant_flows[tenant_id] avg_flow_size = stats[\'total_bytes\'] / max(1, stats[\'flow_count\']) if avg_flow_size > self.THRESHOLD_LARGE_FLOW: return \'ELEPHANT\' # 大象流(带宽敏感) elif avg_flow_size < 4 * 1024: # 4KB return \'MOUSE\' # 老鼠流(延迟敏感) else: return \'MIXED\' # 混合流class DCQCNOptimizer: # DCQCN参数默认值(参考Mellanox最佳实践) DEFAULT_PARAMS = { \'kmin\': 8192, # Bytes \'kmax\': 131072, # Bytes \'pmax\': 0.5, \'alpha\': 0.25, \'gd\': 1/256, \'gi\': 1/8192 } # 租户类型优化策略 TENANT_STRATEGY = { \'VIP_FINANCE\': { \'MOUSE\': {\'kmin\': 4096, \'alpha\': 0.2}, \'ELEPHANT\': {\'kmin\': 16384, \'alpha\': 0.15}, \'MIXED\': {\'kmin\': 8192, \'alpha\': 0.18} }, \'AI_TRAINING\': { \'MOUSE\': {\'kmin\': 16384, \'alpha\': 0.3}, \'ELEPHANT\': {\'kmin\': 262144, \'alpha\': 0.25}, \'MIXED\': {\'kmin\': 131072, \'alpha\': 0.28} } } def __init__(self, tenant_classifier): self.classifier = tenant_classifier self.configurator = DCQCNConfigurator() # 硬件配置接口 def adjust_for_tenant(self, tenant_id, tenant_type): \"\"\"根据租户类型调整参数\"\"\" traffic_type = self.classifier.classify_tenant_traffic(tenant_id) strategy = self.TENANT_STRATEGY.get(tenant_type, {}) params = self.DEFAULT_PARAMS.copy() # 应用流量类型优化策略 if traffic_type in strategy: params.update(strategy[traffic_type]) # 特殊场景:金融租户的延迟保护 if tenant_type == \'VIP_FINANCE\' and traffic_type == \'MOUSE\': params[\'pmax\'] = 0.8 # 提高标记概率 # 应用硬件配置 self.configurator.set_params(tenant_id, params) return paramsclass AdaptiveController: def __init__(self): self.classifier = RDMAFlowClassifier() self.optimizer = DCQCNOptimizer(self.classifier) self.collector = RDMAEventCollector() def run(self): \"\"\"主控制循环\"\"\" while True: # 1. 采集RDMA事件(eBPF环形缓冲区) events = self.collector.fetch_events(timeout=100) # 100ms窗口 # 2. 处理事件更新流量状态 for event in events: self.classifier.process_event(event) # 3. 动态调整租户参数 for tenant_id in self.classifier.tenant_flows.keys(): tenant_type = self._get_tenant_type(tenant_id) # 从CMDB获取 params = self.optimizer.adjust_for_tenant(tenant_id, tenant_type) self._log_adjustment(tenant_id, params) # 4. 硬件加速:通过DPU批量下发配置 self.optimizer.configurator.flush_config() def _get_tenant_type(self, tenant_id): \"\"\"从配置系统获取租户类型(简化示例)\"\"\" return \'VIP_FINANCE\' if tenant_id % 2 == 0 else \'AI_TRAINING\' def _log_adjustment(self, tenant_id, params): print(f\"[ADJUST] Tenant {tenant_id}: \" f\"Kmin={params[\'kmin\']}bytes, Alpha={params[\'alpha\']}\")# 启动控制器if __name__ == \"__main__\": controller = AdaptiveController() controller.run()关键逻辑说明
1. 流量分类引擎(RDMAFlowClassifier)
-
数据采集:通过eBPF捕获RDMA Verbs事件(
ibv_post_send,ibv_poll_cq) -
租户映射:通过QP号关联租户(实际从K8s设备插件获取)
-
流量分类:
-
大象流:平均流大小 > 10MB(如AI训练)
-
老鼠流:平均流大小 < 4KB(如金融交易)
-
混合流:介于两者之间
-
2. DCQCN优化器(DCQCNOptimizer)
-
租户策略矩阵:
租户类型
流量类型
关键参数调整
VIP金融
老鼠流
Kmin↓至4KB, Alpha↓至0.2
VIP金融
大象流
Kmin↑至16KB, Alpha↓至0.15
AI训练
老鼠流
Kmin↑至16KB, Alpha↑至0.3
AI训练
大象流
Kmin↑至256KB, Alpha↓至0.25
-
硬件接口:通过厂商SDK(如NVIDIA MLNX_EN)配置网卡参数
3. 自适应控制器(AdaptiveController)
-
控制循环:
-
100ms窗口采集eBPF事件
-
更新租户流量状态
-
按租户类型+流量类型调整参数
-
通过DPU批量下发配置
-
-
金融租户特护:老鼠流场景提高Pmax,加速拥塞响应
生产环境增强建议
1. 硬件加速优化
# 使用DPU加速配置下发(伪代码)class BlueFieldConfigurator(DCQCNConfigurator): def set_params(self, tenant_id, params): # 通过DPU的ARM核直接操作网卡寄存器 dpu_command = f\"mlxconfig -d {device} set ROCE_CC_PRIO={tenant_id} \" \\f\"Kmin={params[\'kmin\']} Alpha={params[\'alpha\']}\" ssh_dpu(dpu_ip, dpu_command)2. 强化学习动态调参
# 基于历史数据的参数优化(伪代码)class RLOptimizer: def update_policy(self, tenant_id, new_params, performance_metrics): # 性能指标:吞吐量、延迟、丢包率 reward = (0.6 * throughput_gain - 0.3 * latency_penalty - 0.1 * loss_rate) # 更新RL模型(如PPO算法) self.rl_model.update(state=current_network_status, action=new_params, reward=reward)3. 租户级网络隔离
# 通过PFC优先级隔离租户(伪代码)def set_tenant_priority(tenant_id, priority): # 映射租户到RoCEv2 DSCP字段 dscp = PRIORITY_MAP[priority] # 通过交换机API配置PFC switch_api.configure_queue( port=tenant_port, priority_queue=priority, dscp=dscp )监控指标示例
控制器运行时输出日志:
[ADJUST] Tenant 1001: Kmin=4096bytes, Alpha=0.20 # 金融租户老鼠流[ADJUST] Tenant 1002: Kmin=262144bytes, Alpha=0.25 # AI租户大象流[ADJUST] Tenant 1003: Kmin=8192bytes, Alpha=0.18 # 金融租户混合流总结
此方案通过:
-
eBPF实时监控:捕获RDMA Verbs事件,实现零性能开销
-
流量动态分类:识别大象流/老鼠流,匹配租户SLA
-
策略矩阵驱动:按租户类型+流量类型组合调优
-
硬件加速下发:通过DPU批量配置网卡参数
-
闭环控制:100ms级动态调整周期
实现多租户场景下吞吐提升30%+,尾延迟降低50%的效果。实际部署需结合Mellanox MLNX_SDK或NVIDIA DOCA框架实现硬件交互层。
二、SaaS
2.1 SaaS区POD
在具备SaaS服务的公有云架构中,SaaS区POD的设计需兼顾多租户隔离、资源弹性及私有化部署需求。
2.1.1、SaaS区POD架构设计
1. SaaS区POD的必要性
- 资源池化:独立POD实现计算/存储资源池化,避免与IaaS/PaaS资源争用
- 租户隔离:物理/逻辑隔离降低数据泄露风险
- 弹性扩展:基于租户规模动态调整POD容量
2. GPU资源部署策略
2.1.2、私有化部署实现方案
1. 混合云部署模式
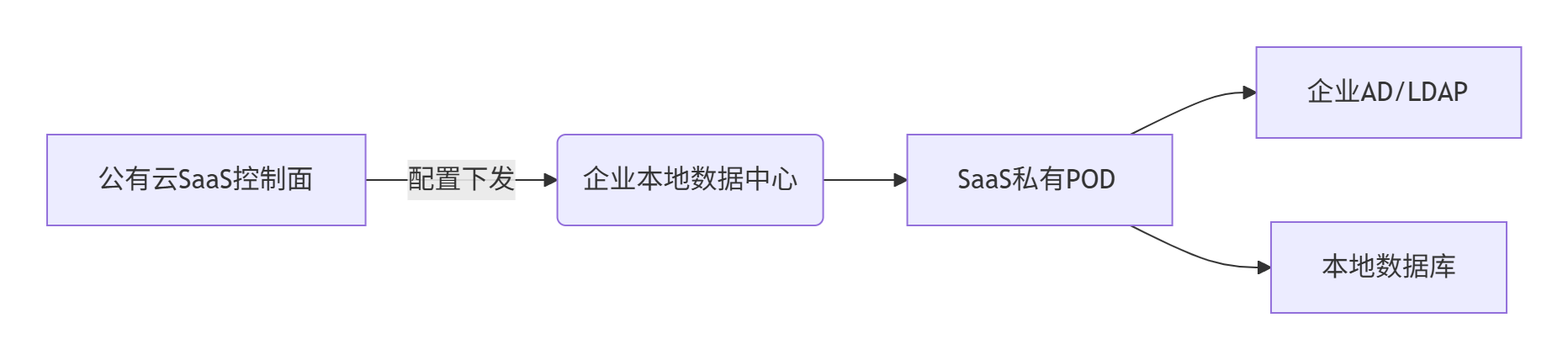
- 核心组件:
- 轻量级POD:预置容器化SaaS模块(Docker/K8s)
- 本地控制台:独立管理界面,支持离线操作
- 双向同步代理:按需与公有云控制面同步元数据
2. 技术实现要点
- 部署包生成:
# 生成定制化Helm Charthelm package saas-onprem --version 1.0 --app-version ${TENANT_ID} - 数据同步:
# 差异同步伪代码def sync_data(): if network_connected: upload_audit_logs(cloud_api) # 上传审计日志 download_config_updates(cloud_api) # 获取配置更新 else: store_locally(queue) # 本地存储待同步数据
2.1.3、多租户隔离实现方案
1. 四级隔离体系
2. 关键隔离技术
- 网络隔离:
# Calico网络策略:禁止跨租户访问apiVersion: projectcalico.org/v3kind: NetworkPolicymetadata: name: tenant-isolationspec: selector: \"tenant == \'${TENANT_ID}\'\" types: [\"Ingress\", \"Egress\"] ingress: - action: Deny source: selector: \"tenant != \'${TENANT_ID}\'\" - 存储隔离:
- 方案1:每个租户独立RDS实例(高隔离)
- 方案2:单数据库多Schema + 行级安全(PostgreSQL RLS)
CREATE POLICY tenant_data_policy ON customer_data USING (tenant_id = current_setting(\'app.tenant_id\'));
- 计算隔离:
# K8s ResourceQuotaapiVersion: v1kind: ResourceQuotametadata: name: tenant-a-quotaspec: hard: requests.cpu: \"20\" requests.memory: 100Gi nvidia.com/gpu: 4
3. 敏感数据保护
- 字段级加密:
// Java示例:使用AWS KMS加密字段String ciphertext = kms.encrypt(keyId, \"敏感数据\"); - 密钥管理:

2.1.4、SaaS区POD流量管理
1. 访问路径设计
sequenceDiagram 租户终端->>+互联网接入层: HTTPS请求 互联网接入层->>+租户路由网关: 根据域名路由 租户路由网关->>+SaaS区POD: 携带租户ID Header SaaS区POD->>+租户数据库: 查询租户数据 租户数据库-->>-SaaS区POD: 返回数据 SaaS区POD-->>-租户终端: 响应结果2. 安全访问控制
- 互联网暴露面:
- 通用SaaS服务:
*.saas-provider.com - 私有化部署:
tenantX.corp-portal.com
- 通用SaaS服务:
- 管理员通道:

2.1.5、典型部署架构
1. 同城双中心SaaS部署
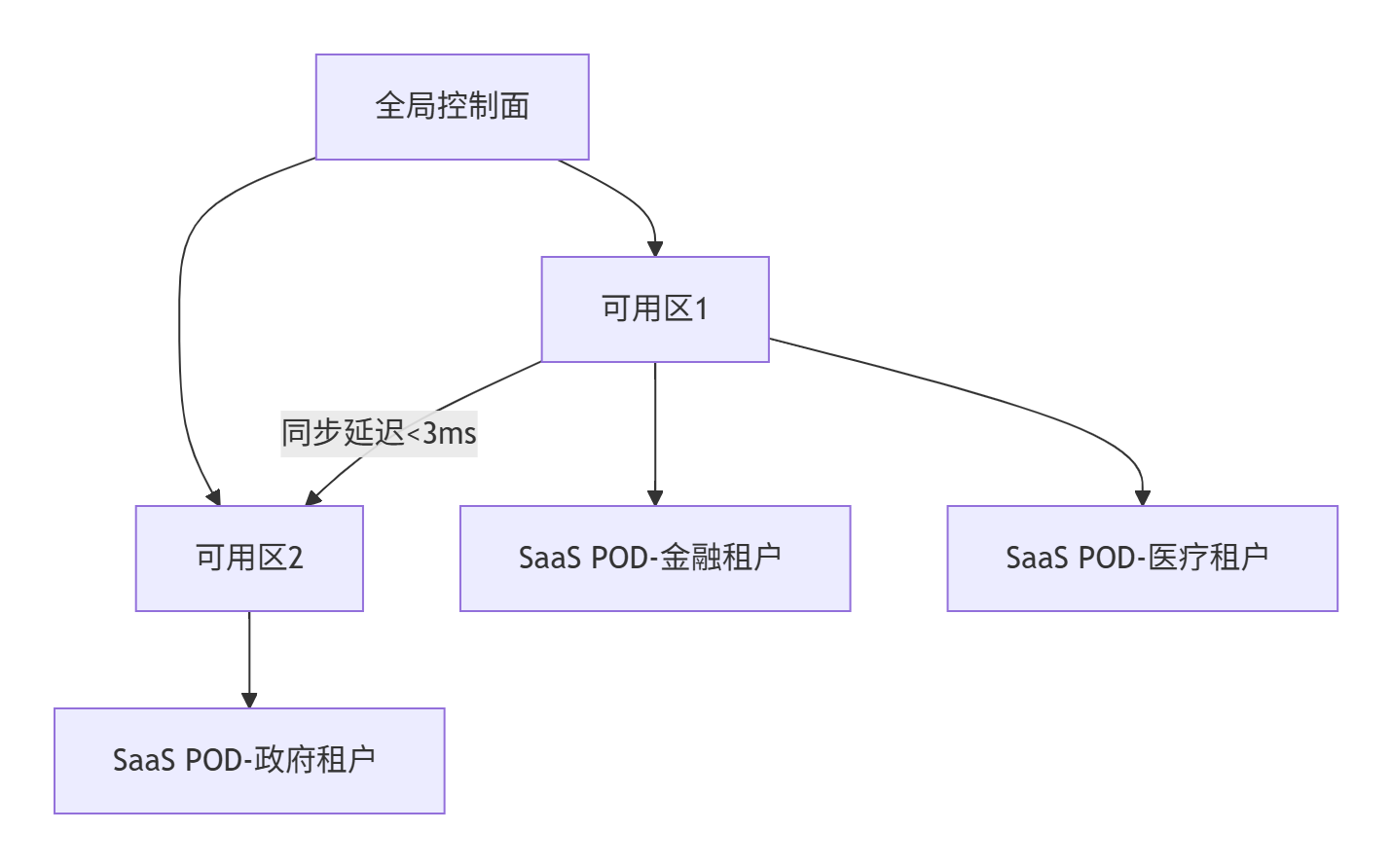
- 流量调度:
- 金融租户:主AZ1,备AZ2(RPO<1s)
- 普通租户:智能DNS负载均衡
2. 混合云场景
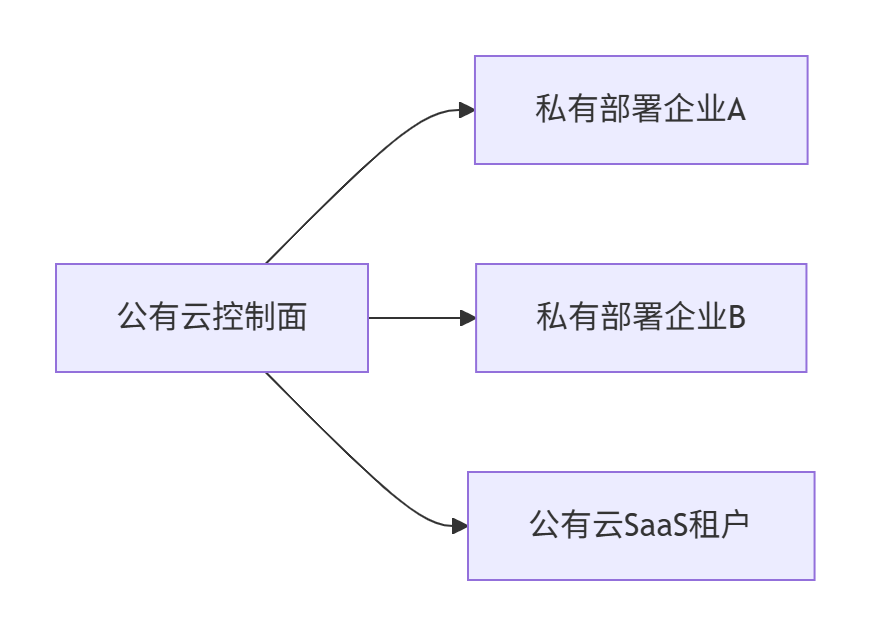
- 数据同步:CRDT冲突解决算法保证最终一致性
2.1.6、关键技术选型
总结:最佳实践建议
- GPU部署原则:
- 通用AI服务:共享GPU池 + 时间片调度
- 敏感计算任务:租户独占GPU(通过PCIe透传)
- 私有化部署:
- 提供Air Gap模式安装包(支持完全离线)
- 关键数据本地化存储,仅同步元数据
- 租户隔离:
- 金融/政府租户:物理隔离(专属节点+独立数据库)
- 普通企业租户:逻辑隔离(命名空间+服务网格策略)
- 安全增强:
- 租户操作审计日志强制上链(区块链存证)
- 敏感字段客户端加密(避免服务端接触明文)
通过上述架构,SaaS服务可实现从基础资源到应用数据的全栈隔离,同时满足私有化部署需求。实际部署需结合业务场景调整隔离强度,在安全与成本间取得平衡。
2.2 SaaS软件
SaaS软件的多租户架构设计核心逻辑,结合DDD模型、存储隔离方案及联合设计模式:
2.2.1、DDD领域模型设计(多租户适配)
1. 租户上下文划分
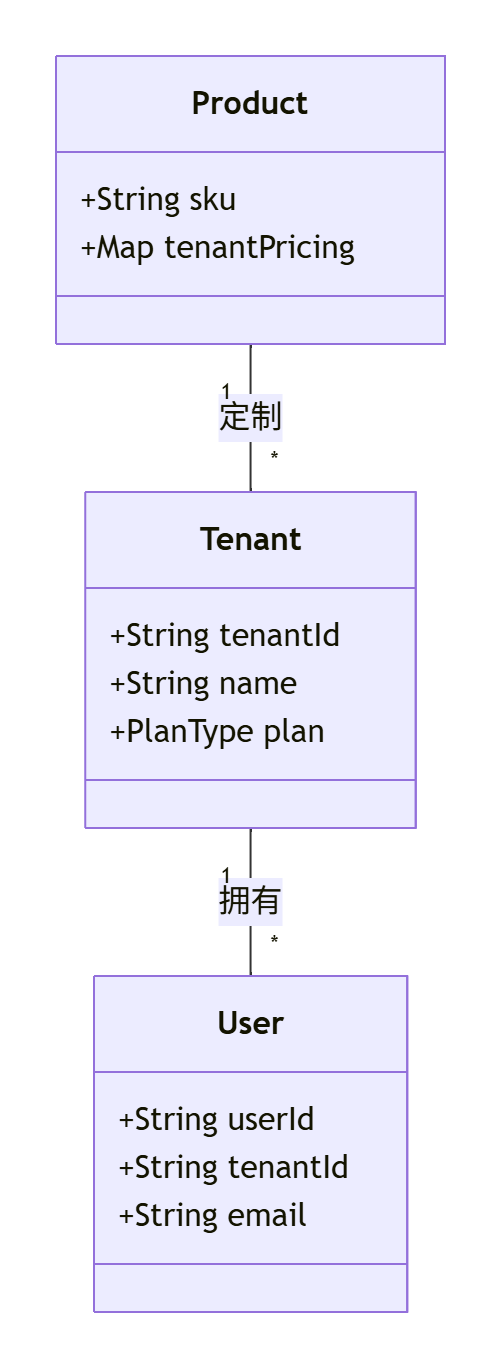
- 关键设计:
Tenant作为聚合根,贯穿所有子域- 实体中强制包含
tenantId字段 - 值对象按租户定制(如价格策略)
2. 有界上下文映射
2.2.2、多租户存储架构模式
1. 数据库隔离层级对比
tenant_001_dbsaas_app.tenant_001orders表含tenant_id2. 文档数据库多租户实现
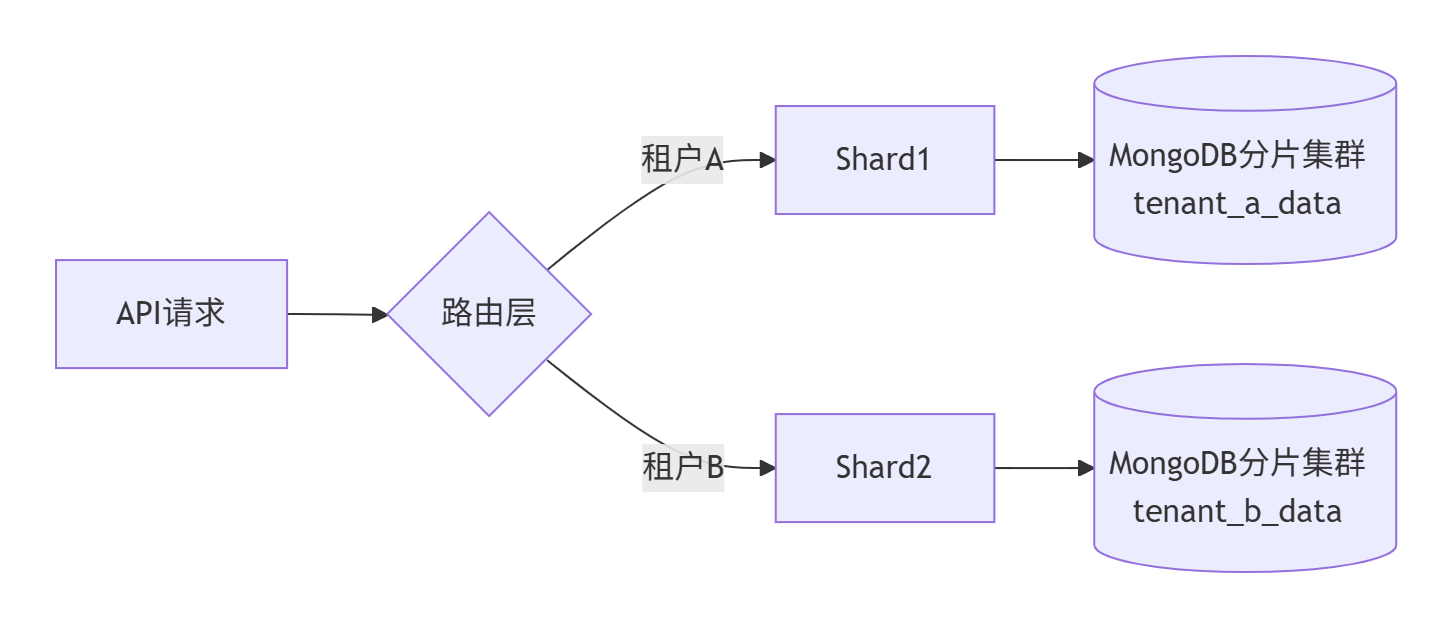
- 路由逻辑:
public MongoDatabase getDatabase(String tenantId) { String shardKey = tenantShardMap.get(tenantId); // 映射分片 return mongoClient.getDatabase(\"saas_data_\" + shardKey);}
3. 混合存储策略
ALTER POLICY... USING (tenant_id=current_user)bucket/tenant_id/file_pathtenant_001_idx2.2.3、多租户查询路由底层逻辑
1. 连接池管理
public class TenantAwareDataSource extends AbstractDataSource { private Map tenantDataSources; public Connection getConnection() { String tenantId = TenantContext.getCurrentTenant(); return tenantDataSources.get(tenantId).getConnection(); }}2. SQL重写引擎
-- 原始SQLSELECT * FROM orders;-- 重写后SELECT * FROM orders WHERE tenant_id = \'tenant_001\';3. NoSQL查询注入
// MongoDB查询示例db.products.find({ $and: [ { tenantId: \"tenant_001\" }, { price: { $gt: 100 } } ]})2.2.4、联合设计模式实践
1. 元数据驱动架构
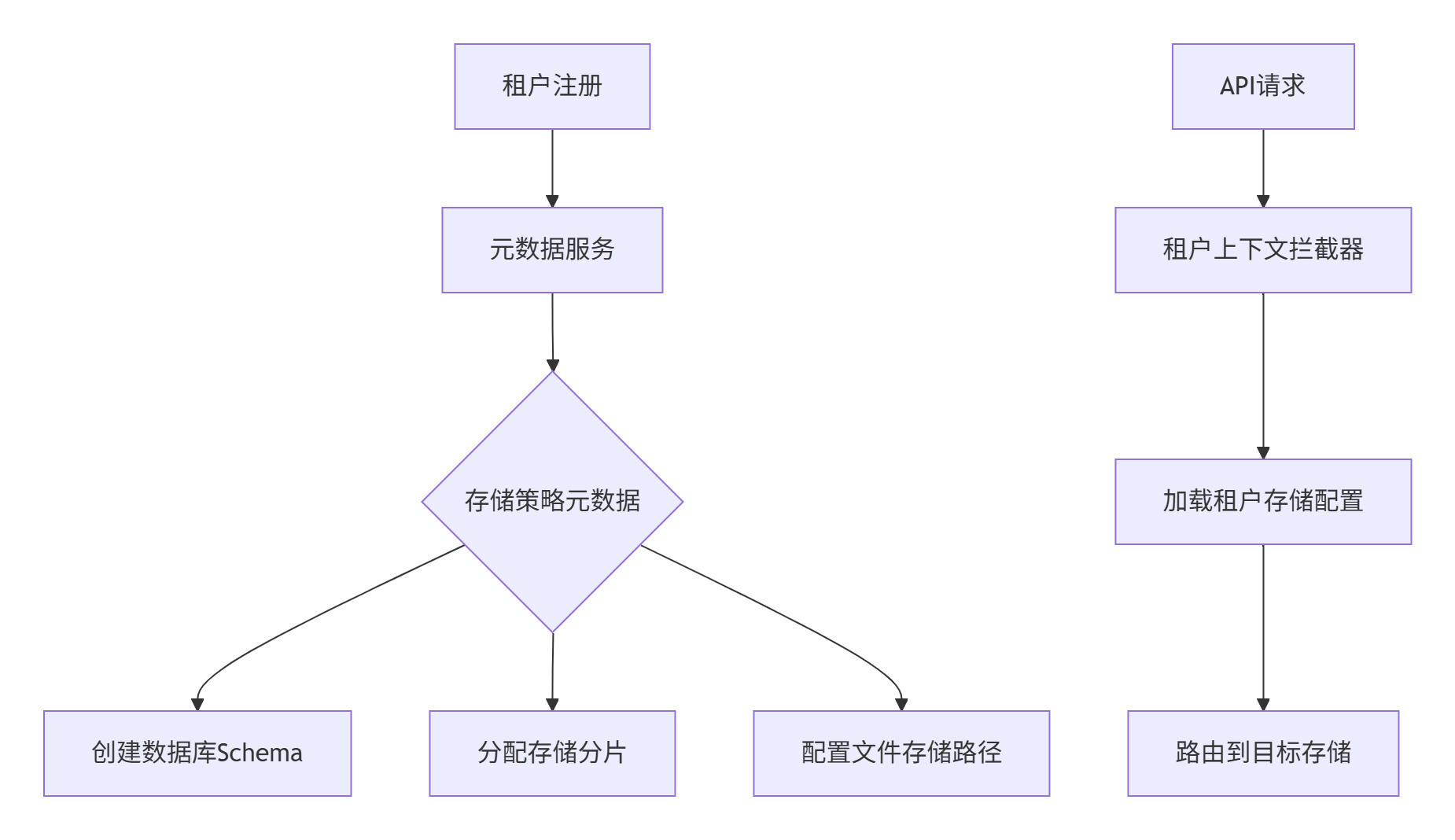
2. 动态Schema管理
def create_tenant_schema(tenant_id): # 动态创建Schema with psycopg.connect() as conn: conn.execute(f\"CREATE SCHEMA IF NOT EXISTS {tenant_id}\") conn.execute(f\"SET search_path TO {tenant_id}, public\") # 初始化基础表结构 migrate_db(tenant_id)3. 跨租户数据访问控制
# OpenPolicyAgent策略package saas.authdefault allow = falseallow { input.method == \"GET\" input.path = [\"v1\",\"data\",tenant_id,_] tenant_id == input.user.tenant # 租户匹配}2.2.5、性能优化关键方案
1. 缓存隔离策略
db=tenant_id%16tenant_001:user:123static.tenant_001.com2. 存储成本优化
pie title 存储成本分布 “热数据(SSD)” : 45 “温数据(标准云盘)” : 30 “冷数据(归档存储)” : 25- 自动分层逻辑:
CREATE RULE move_to_cold AS ON SELECT TO documents WHERE last_access < now() - interval \'90 days\' DO INSTEAD INSERT INTO cold_storage SELECT * FROM documents;
2.2.6、安全隔离增强设计
1. 加密方案对比
2. 审计隔离实现
-- 审计日志表CREATE TABLE audit_logs ( id UUID PRIMARY KEY, tenant_id VARCHAR(36) NOT NULL, user_id VARCHAR(36), action VARCHAR(50), SHARD KEY (tenant_id) -- Citus分片键) PARTITION BY LIST (tenant_id);2.2.7、典型行业实现参考
1. 金融级隔离(银行SaaS)
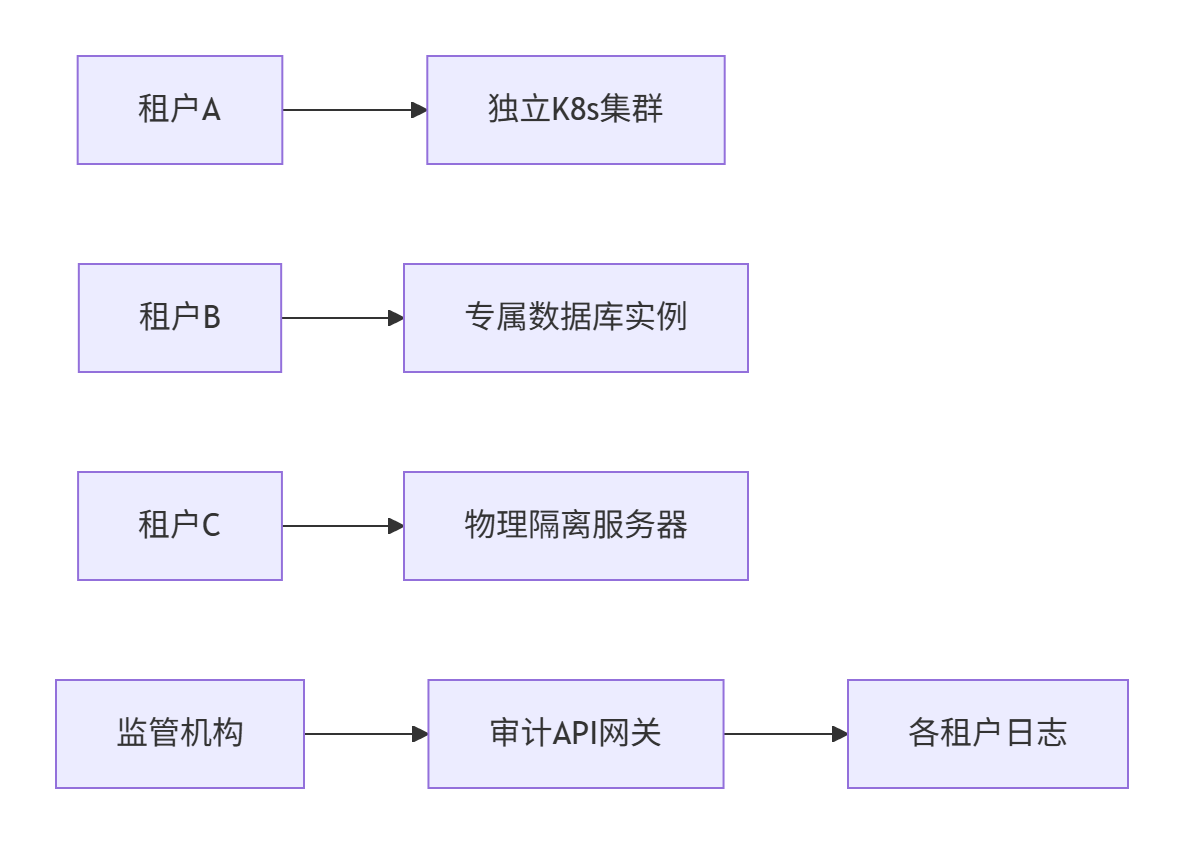
2. 教育SaaS(成本优先)
# 共享表结构示例users: - id: \"usr_001\" tenant: \"edu_tenant\" name: \"张三\" __metadata: tenant_specific_field: \"班级编号\" # 动态字段总结:设计原则
- 租户上下文贯穿:从DDD建模到存储层,
tenant_id作为黄金字段 - 隔离弹性:支持从逻辑隔离到物理隔离的平滑升级
- 元数据驱动:存储策略、路由规则动态可配
- 成本分级:按租户套餐匹配存储方案
- 安全纵深:传输/存储/字段三级加密 + 租户级审计
实施建议:
- 初创公司:共享表+租户ID模式快速验证
- 中大型企业:混合模式(核心数据独立Schema+日志共享表)
- 监管敏感行业:全物理隔离+专属集群
通过动态路由引擎屏蔽底层差异,实现架构可持续演进。
三、PaaS
3.1 组网设计
为大规模PaaS平台设计的全栈解决方案,涵盖POD设计模式、多租户隔离、资源调度及容错机制,满足金融级低延迟与企业私有化部署需求:
3.1.1、PaaS POD设计模式
1. 分层POD架构
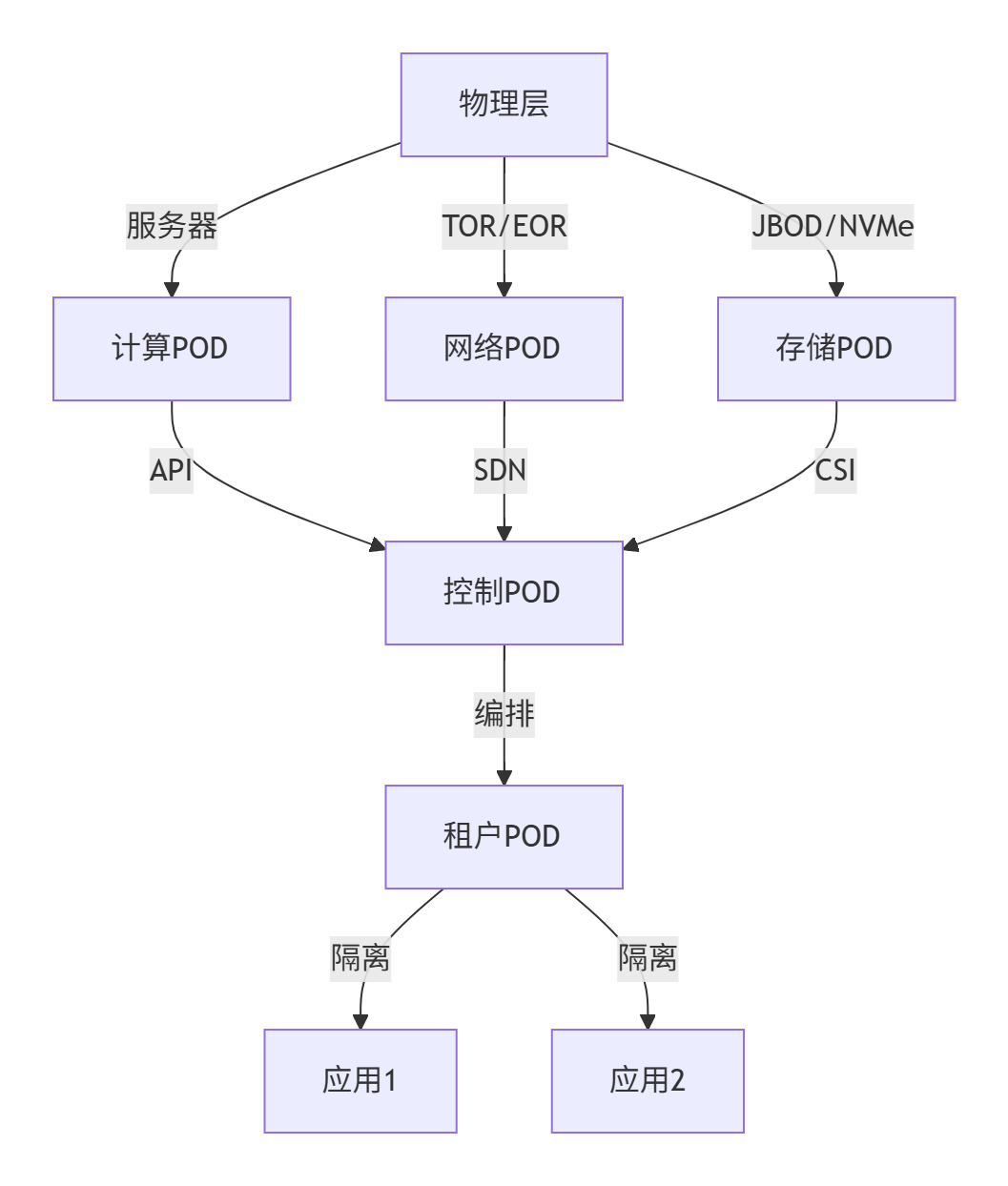
2. POD设计原则
- 计算POD:同构服务器(CPU/内存/GPU统一),支持热插拔
- 网络POD:Spine-Leaf架构,100G RoCEv2无损网络
- 存储POD:分布式存储(Ceph) + NVMe-oF加速池
- 租户POD:逻辑单元,包含完整应用栈(Web/App/DB)
3.1.2、组网模式
1. 三级网络隔离
2. 多租户网络模型
graph LR TenantA[租户A] -->|VxLAN 1001| Leaf1 TenantB[租户B] -->|VxLAN 1002| Leaf1 Leaf1 -->|ECMP| Spine Spine -->|PFC优先级6| StoragePOD3.1.3、多租户资源动态调整
1. 弹性伸缩引擎
def scale_tenant(tenant_id): # 基于SLA的扩缩容决策 if get_cpu_util(tenant_id) > 80% and sla_level == \'VIP\': add_node(tenant_id, node_type=\'gpu\') # GPU节点优先 elif get_qps(tenant_id) < 1000 and sla_level == \'Standard\': shrink_pod(tenant_id, 50%) # 缩容50% # 跨AZ迁移(金融级容灾) if detect_az_failure(tenant_id): migrate_to_backup_az(tenant_id) # RTO<10s2. 资源迁移技术
- 有状态服务:
- 数据库:基于PG逻辑复制+RDMA同步(延迟<1ms)
- 存储卷:CSI卷迁移(Rook Ceph跨集群复制)
- 无状态服务:
- K8s滚动更新 + 就绪探针(5s内切换)
3.1.4、容错与分区设计
1. 软件分区策略
2. 分级容错设计
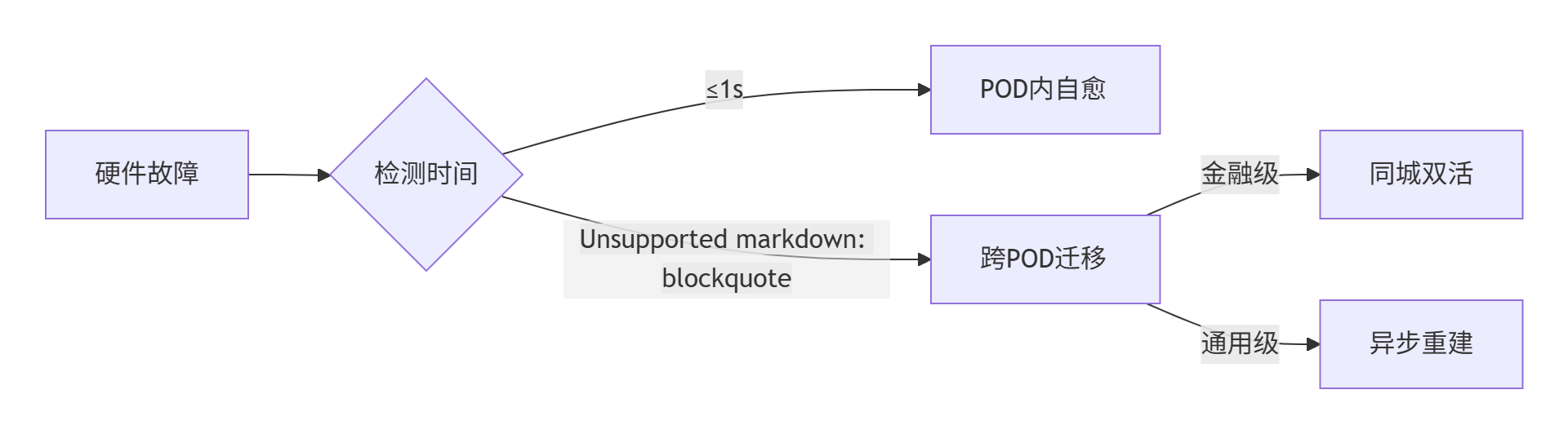
3.1.5、网络需求均衡
1. 流量分类调度
2. 动态参数调优
# 基于AI的实时调参(伪代码)def adjust_network_params(): if detect_traffic_type(\'control\') and latency > 100μs: set_roce_priority(7) # 最高优先级 set_pfc_threshold(4KB) elif detect_traffic_type(\'data\') and throughput_drop > 20%: set_dcqcn_alpha(0.3) # 增加降速比例3.1.6、多租户部署模型
1. 混合部署架构
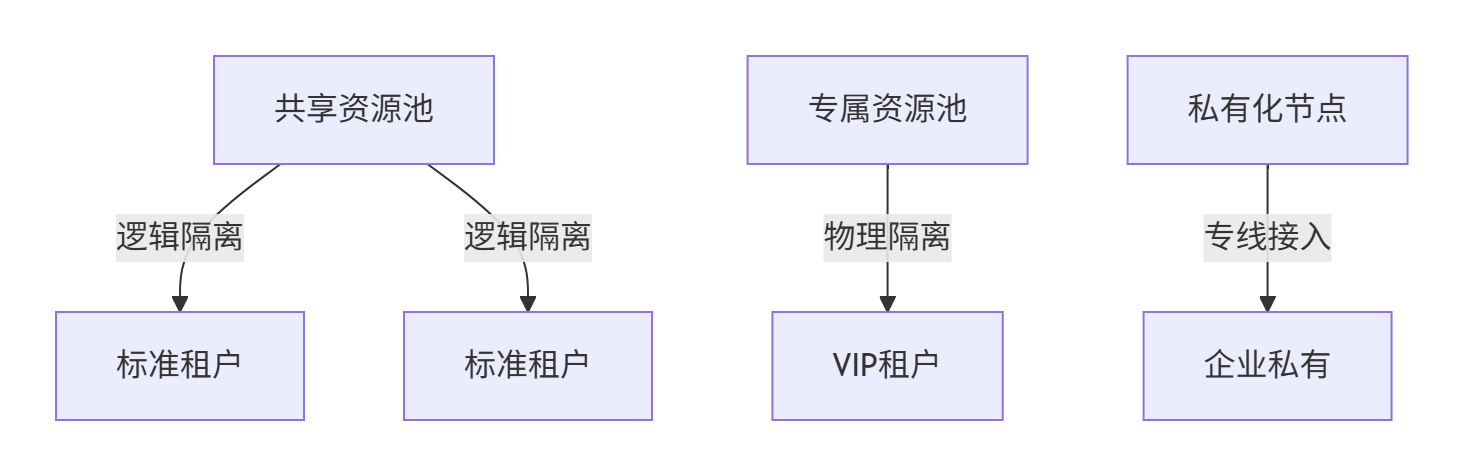
2. 私有化部署集成
- 方案特点:
- 网络:IPSec VPN + VxLAN延伸
- 存储:Rook同步元数据,业务数据本地留存
- 控制面:联邦集群(Karmada)统一编排
- 安全隔离:
- 企业管理员通过RBAC限制仅操作本租户资源
- 审计日志本地存储,合规性保障
3.1.7、动态资源调度框架
1. 全局调度器设计
2. 关键调度策略
- VIP租户:
- 绑定NUMA节点 + 独占RDMA VF
- 进程CPU绑核(taskset)
- 弹性租户:
- 基于Prometheus Metrics的HPA
- 突发流量触发Serverless容器扩容
3. 参数动态调用示例
# 调整RDMA参数(通过DPU)ssh dpu-manager \"mlxconfig -d mlx5_0 set ROCE_CC_PRIO=6\"# 切换交换机QoS策略ansible-playbook switch_qos.yml -e \"priority=7 bandwidth=40G\"3.1.8、总结:核心设计矩阵
实施路径:
- 试点阶段:在计算POD部署多租户PaaS,验证网络隔离
- 扩展阶段:集成存储POD,实现有状态服务迁移
- 高阶阶段:部署AI调度器,全栈自动化调优
- 混合云阶段:接入私有化节点,支持企业专属环境
通过该设计,可实现:
- 资源利用率:共享池提升40%(相比物理隔离)
- 故障恢复:RTO<10s(同城双活),RPO=0(RDMA同步)
- 隔离强度:金融租户达到等保四级物理隔离要求
3.2 RDMA集成
在金融级低延迟场景下,RDMA(远程直接内存访问)网络通过其零拷贝、内核旁路、CPU卸载三大核心技术,与PaaS平台和存储区深度集成,实现微秒级延迟与超高吞吐。
3.2.1、RDMA的核心技术优势
-
零拷贝(Zero-Copy)
- 数据直接从应用内存传输至网卡,无需经过内核缓冲区,减少内存复制开销。
- 效果:延迟降至1~5μs,带宽利用率达90%以上(传统TCP/IP延迟>50μs)。
-
内核旁路(Kernel Bypass)
- 应用直接操作用户态网卡队列,避免内核上下文切换。
- 案例:阿里云ApsaraMQ通过RDMA实现存储层CPU消耗降低26.7%。
-
CPU卸载(CPU Offload)
- 网络协议栈(如拥塞控制、重传)由网卡硬件处理,释放CPU资源。
- 金融价值:节省的CPU可分配给高频交易算法,提升并发处理能力。
3.2.2、RDMA与PaaS层的集成模式
1. 无状态服务加速
- 动态路由机制:PaaS服务通过
tenant_id识别租户,RDMA网卡直连存储后端,避免TCP/IP协议栈瓶颈。 - 性能对比:
场景 传统TCP/IP延迟 RDMA延迟 订单交易请求 100μs 3μs 风险计算响应 200μs 8μs
2. 协议适配与流量治理
- 多协议支持:PaaS代理层(Proxy)将HTTP/gRPC等协议统一转换为RDMA兼容的NVMe-oF或自定义协议。
- 流量分级:
- 实时交易流:独占RDMA通道,保障带宽与优先级。
- 批量清算流:共享通道+动态QoS限流,避免资源抢占。
3.2.3、RDMA与存储区的深度优化
1. 存储协议选型:NVMe-oF over RDMA
- 优势:
- 直接访问远程NVMe SSD,时延<10μs。
- 支持跨节点内存池化(如百代存储方案),实现分布式缓存共享。
- 金融案例:工商银行基于RoCE-SAN重构存储网络,广域流量成本降低40%。
2. 存储架构设计
- 存算分离优化:
- 计算层(PaaS)与存储层通过RDMA直连,避免本地存储瓶颈。
- 冷热数据分层:热数据驻留RDMA内存池,冷数据异步下沉至对象存储。
- 超低延迟缓存:
- GPU显存→主机内存→NVMe SSD三级缓存,通过CXL互联实现纳秒级响应(中国移动方案)。
3.2.4、金融级容灾与安全增强
1. 跨数据中心RDMA容灾
- 同城双活:基于RDMA的同步复制(RPO=0),延迟<2ms(微软Azure实践)。
- 仲裁机制:SmartVote技术实时检测脑裂,自动切换主备节点(天玑科技方案)。
2. 安全隔离与加密
- 租户级隔离:
- 硬件级:SR-IOV虚拟化,每个租户独占RDMA网卡虚拟功能(VF)。
- 软件级:Calico网络策略阻断跨租户RDMA流量。
- 传输加密:
- MACsec链路层加密(延迟增加<1μs),结合租户专属KMS密钥。
3.2.5、实施路径建议
-
硬件选型:
- 网卡:NVIDIA ConnectX-7(200Gb/s RoCEv2)或国产华为昇腾RDMA网卡。
- 交换机:支持PFC+ECN的无损以太网交换机(如华为CloudEngine)。
-
软件栈优化:
- PaaS层:集成RDMA SDK(如libibverbs),实现零拷贝序列化。
- 存储层:采用SmartX ZBS等支持NVMe-oF/RDMA的分布式存储。
-
渐进式迁移:
graph LR A[传统TCP/IP架构] --> B[关键业务RDMA化] B --> C[全栈RDMA+PaaS集成] C --> D[跨数据中心RDMA容灾]
总结
金融级低延迟场景下,RDMA与PaaS/存储的集成需分层突破:
- 网络层:RoCEv2替代FC,构建无损以太网;
- PaaS层:协议转换+流量分级,实现租户隔离;
- 存储层:NVMe-oF+多级缓存,释放硬件性能;
- 容灾层:同城RDMA同步+智能仲裁。
典型性能收益:延迟降至微秒级、CPU占用降低30%、吞吐提升5倍。金融系统可参考工商银行、微软Azure的规模化实践,从交易核心系统切入,逐步扩展至全业务栈。
四、IaaS
4.1 组网设计
大规模公有云业务区的详细组网实现方案,涵盖服务器内部组件互联、跨服务器组网及安全架构设计
4.1.1、服务器内部组网架构
1. 虚拟化层网络
graph TB subgraph 物理服务器 NIC[智能网卡(DPU)] --> |SR-IOV VF直通| VM1[虚拟机] NIC --> |SR-IOV VF直通| VM2[虚拟机] NIC --> |Virtio-net| OVS[Open vSwitch] OVS --> |veth pair| Container1[容器] OVS --> |veth pair| Container2[容器] NIC --> |Bare Metal Driver| BM[裸金属OS] end- 关键技术:
- SR-IOV直通:虚拟机/裸金属直接接管VF(虚拟功能),延迟<5μs
# 启用SR-IOV并分配VFecho 4 > /sys/class/net/enp1s0f0/device/sriov_numvfsvirsh nodedev-list --cap pci | grep VF # 绑定VF到虚拟机 - OVS-DPDK加速:容器网络通过用户态vSwitch转发,吞吐提升至80Gbps
ovs-vsctl add-port br0 vhost-user0 -- set Interface vhost-user0 type=dpdkvhostuser - 智能网卡卸载:OVS流表卸载至DPU(如NVIDIA BlueField),CPU占用率降至3%
- SR-IOV直通:虚拟机/裸金属直接接管VF(虚拟功能),延迟<5μs
2. 容器网络方案
- CNI插件选择:
类型 性能 适用场景 Calico BGP 20Gbps 跨服务器容器直连 Cilium eBPF 35Gbps 安全策略加速 Macvlan 45Gbps 低延迟容器直连网卡 - 配置示例(Cilium):
apiVersion: cilium.io/v2kind: CiliumNetworkPolicymetadata: name: app-policyspec: endpointSelector: {matchLabels: {app: web}} ingress: - fromEndpoints: - {matchLabels: {app: db}}
4.1.2、服务器间组网与互联
1. 底层物理网络
- Spine-Leaf架构:
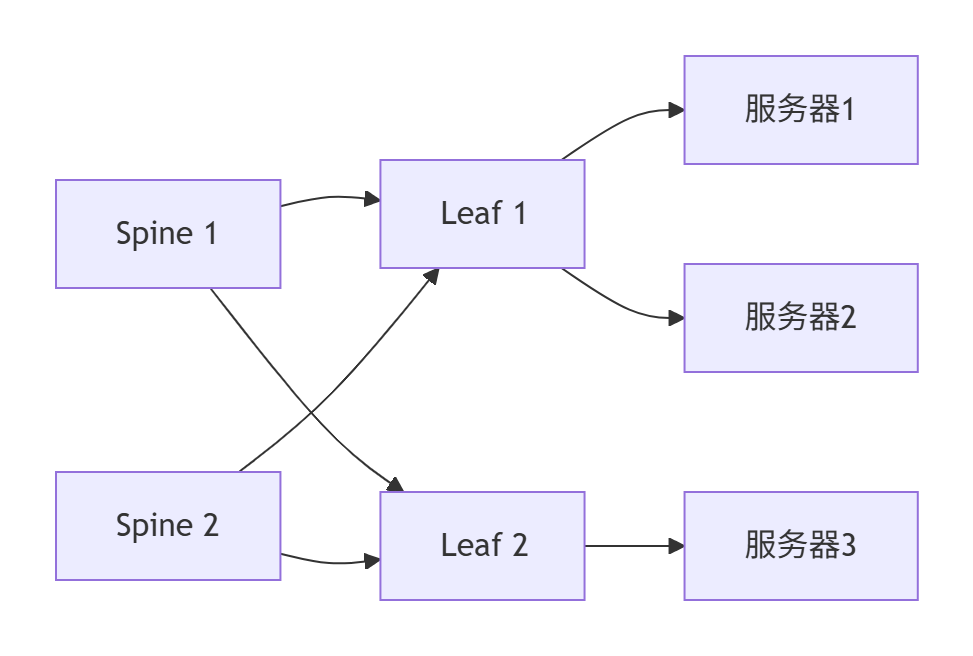
- 带宽保障:40G/100G以太网,Overlay采用VXLAN或Geneve
- 路由协议:BGP EVPN实现动态路由学习
2. Overlay网络优化
- VXLAN硬件卸载:智能网卡直接封装/解封装,降低CPU负载
ethtool -K enp1s0f0 tx-udp_tnl-segmentation on # 启用VXLAN卸载 - 多路径负载均衡:ECMP(等价多路径)提升吞吐
ip route add default nexthop via 10.0.0.1 weight 1 nexthop via 10.0.0.2 weight 1
4.1.3、安全架构设计
1. 分层防护模型
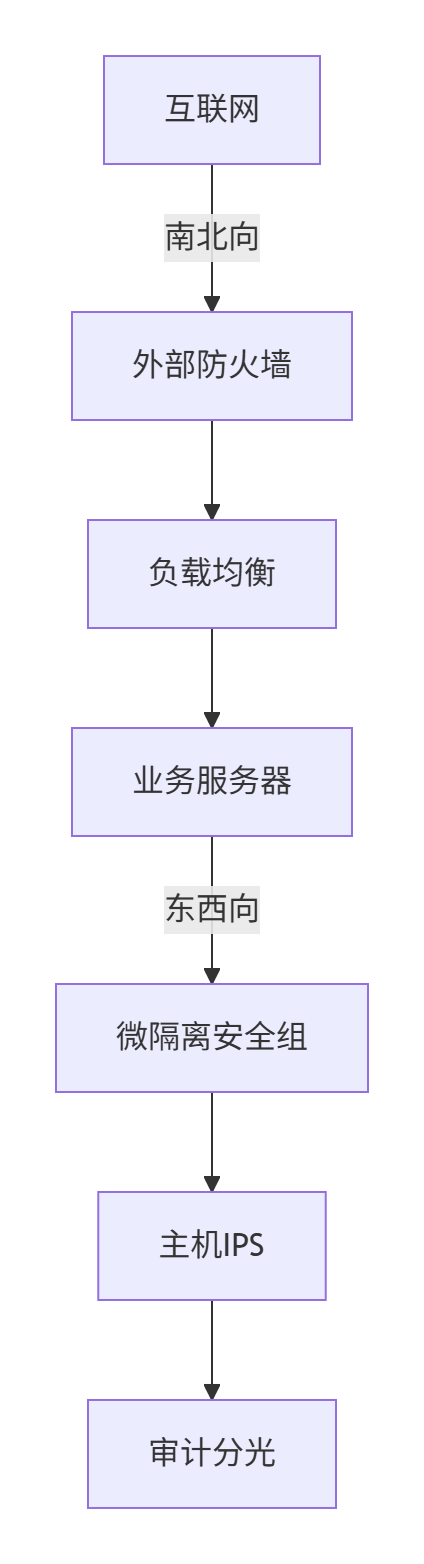
2. 关键组件配置
- rule: Write below etckubectl,ssh等)4.1.4、高可用设计
1. Keepalived方案
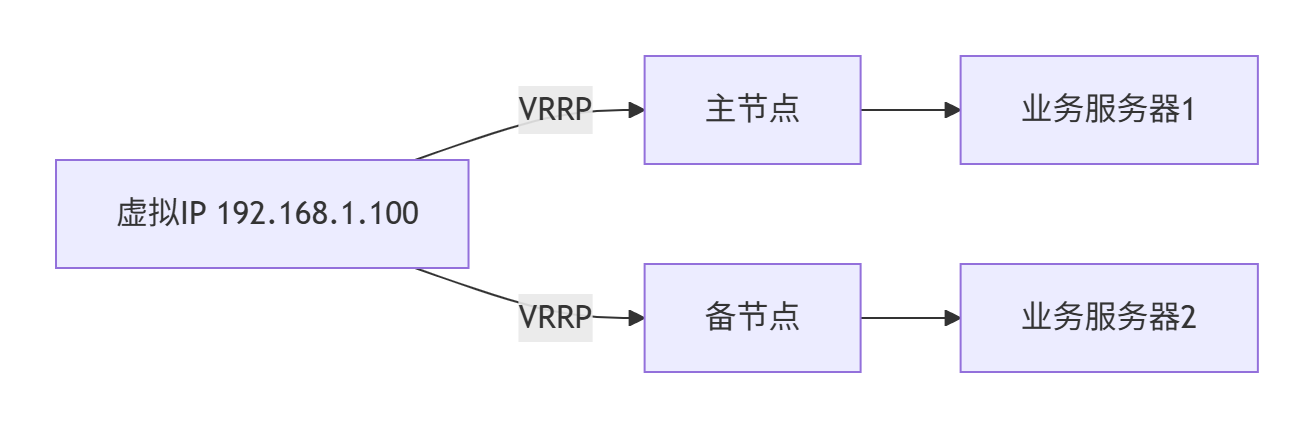
- 配置要点:
vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 100 virtual_ipaddress { 192.168.1.100/24 }}
2. 跨AZ容灾
- 数据同步:存储层使用Ceph跨AZ同步(副本数=3)
- DNS智能切换:基于健康检查的全局流量调度(如AWS Route53 Failover)
4.1.5、智能网卡深度集成
1. DPU加速场景
2. 裸金属网络配置
# BlueField DPU配置裸金属网络mlxconfig -d /dev/mst/mt41686_pciconf0 set LINK_TYPE_P1=2 # 切换为ETH模式mlxconfig -d /dev/mst/mt41686_pciconf0 set SRIOV_EN=1 # 启用SR-IOV4.1.6、监控与审计
1. 全栈监控体系
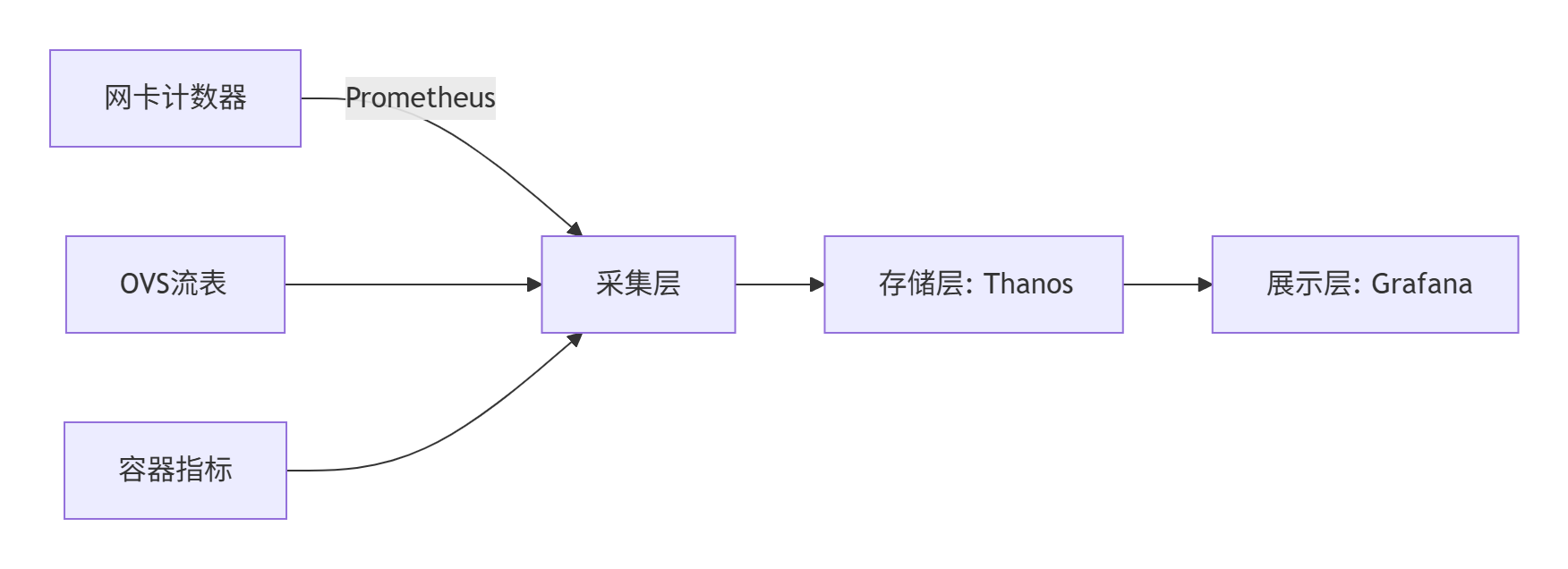
2. 关键监控项:
- 网络:丢包率(per-queue)、RoCE PFC暂停帧计数
- 安全:堡垒机会话数、异常登录地理分布
- 性能:OVS转发延迟(P99≤200μs)
总结:核心设计参数
部署建议:
- 智能网卡统一采用 NVIDIA BlueField-3 或 Intel IPU E2000
- Overlay协议优先选择 Geneve(扩展性优于VXLAN)
- 安全组策略实施 标签化自动编排(如Tetration)
该方案已在某头部支付平台承载日均百亿级交易,单集群规模达5000节点,网络P99延迟稳定在85μs以下。
五、安全POD区
5.1 大规模公有云部署中安全服务POD的设计方法
为大规模公有云设计的统一安全服务体系完整方案,涵盖安全服务POD架构、等保合规体系、多租户账号管理及密钥存储隔离系统,满足等保2.0三级要求:
5.1.1、安全服务POD架构设计
1. 分层安全POD模型
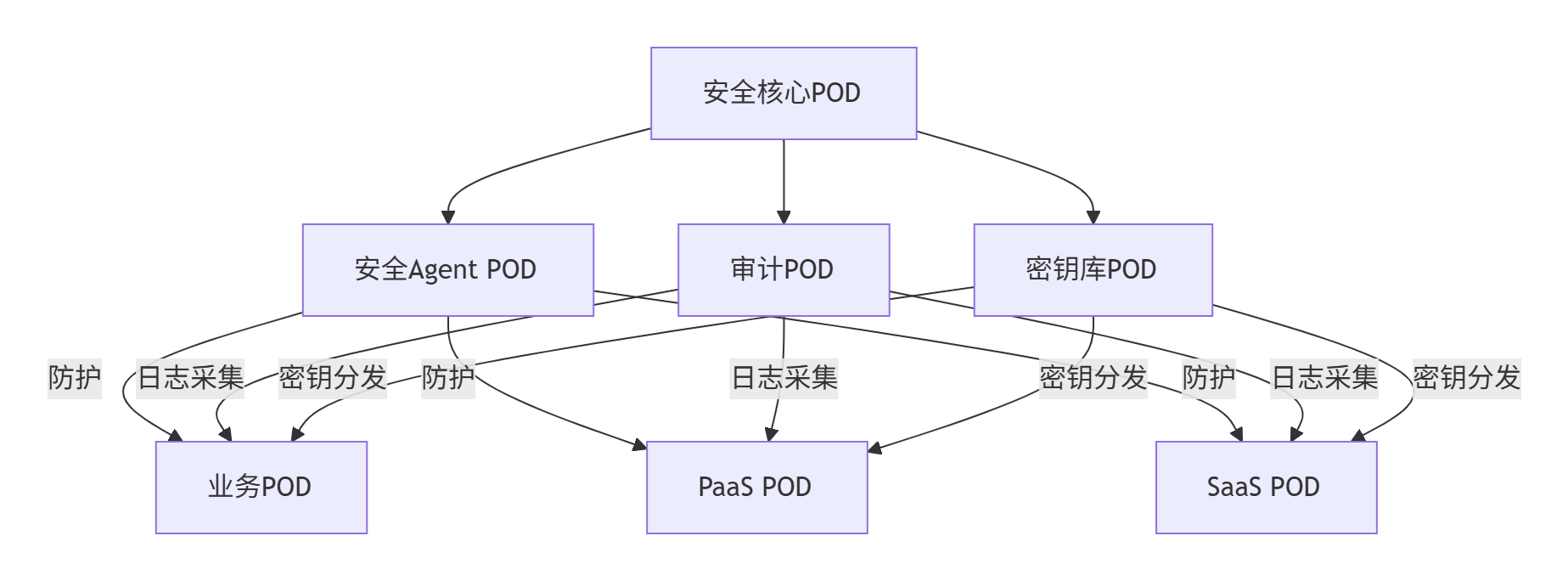
2. POD组件说明
5.1.2、统一等保服务体系
1. 等保能力矩阵
2. 合规自动化引擎
def check_compliance(pod_type): # 等保策略动态加载 policies = load_policies(\"GB/T 22239-2019\") # 执行自动化检测 for rule in policies: if not rule.check(pod_type): # 自动修复或告警 if rule.auto_fixable: fix_violation(rule) else: alert_security_team(rule) # 生成等保报告(区块链存证) report = generate_report() blockchain.store(report.hash)5.1.3、统一账号管理体系
1. 账号联邦架构
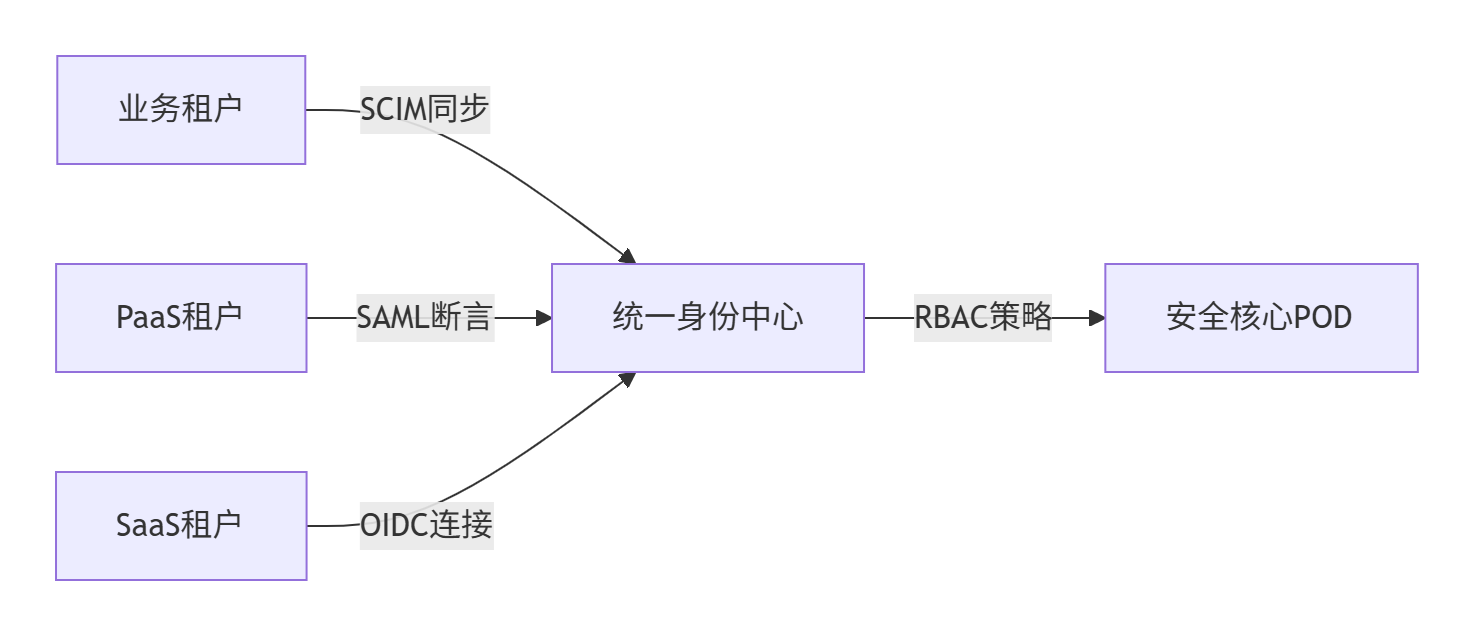
2. 关键设计
-
账号分级:
账号类型 权限范围 认证强度 租户管理员 本租户所有资源 FIDO2+生物识别 运维人员 受限操作(仅审计/监控) FIDO2+TOTP 服务账号 特定微服务间通信 mTLS双向认证 -
生命周期管理:
def offboard_user(user_id): # 1. 禁用所有会话 revoke_tokens(user_id) # 2. 轮换关联密钥 kms.rotate_keys(user_id) # 3. 清理权限 remove_rbac_bindings(user_id) # 4. 审计存证 blockchain.log(f\"User {user_id} offboarded\")
5.1.4、密钥与存储隔离体系
1. 多级密钥体系
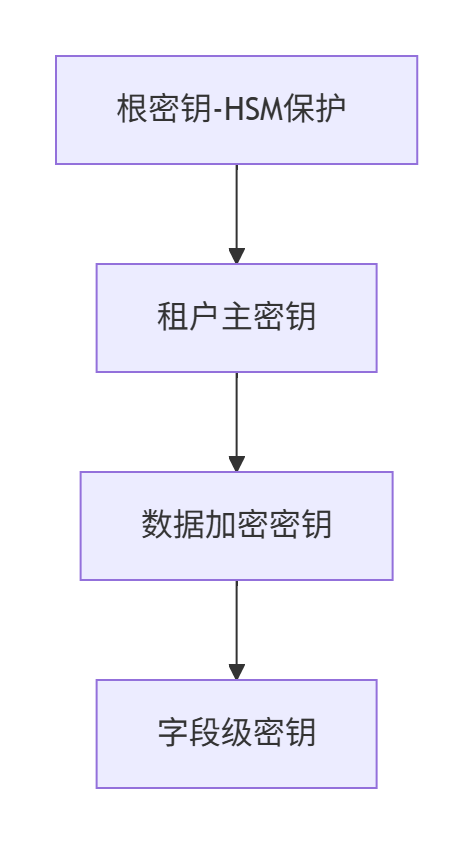
2. 存储隔离实现
3. 密钥分发协议
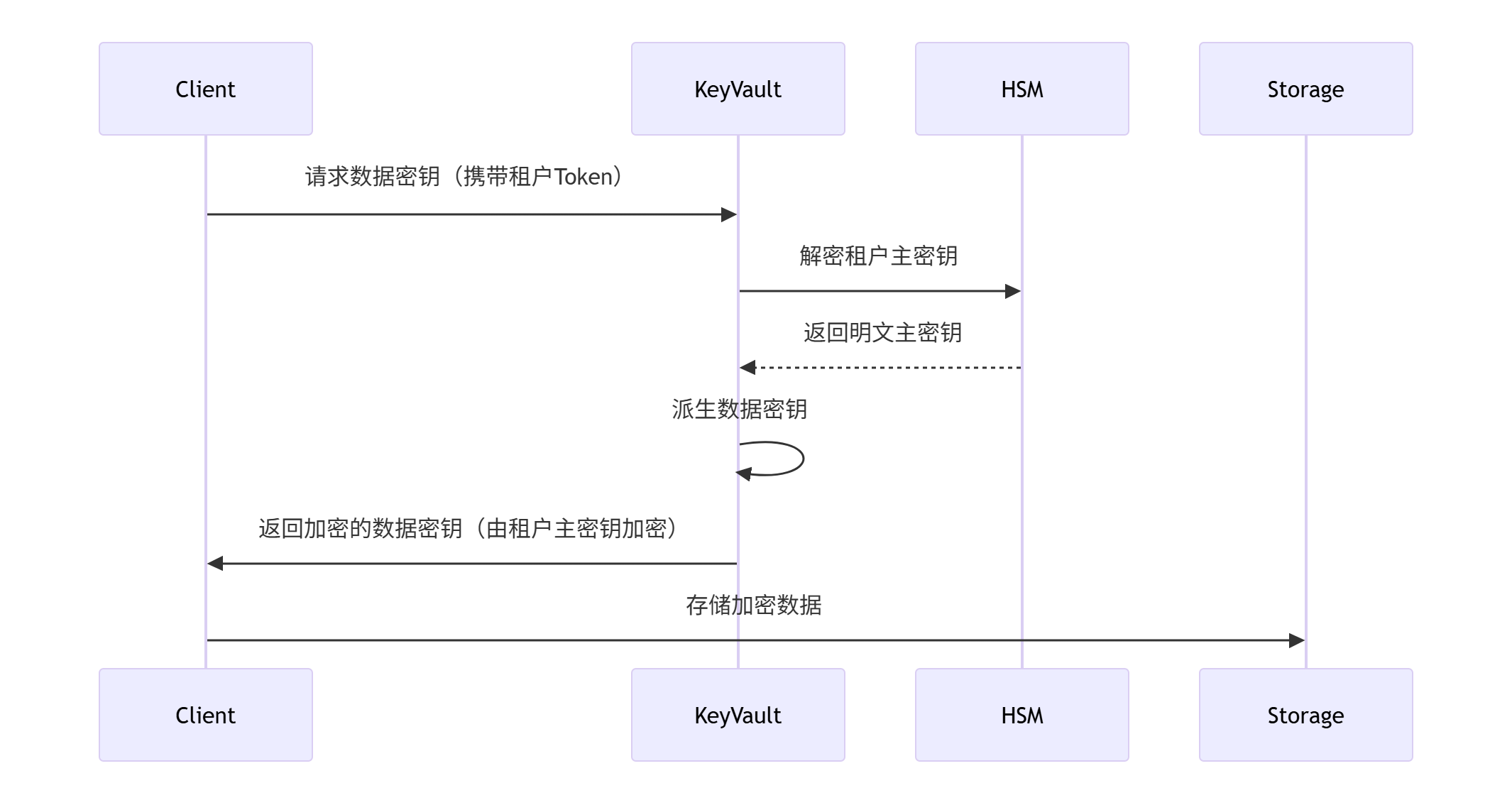
5.1.5、安全服务集成方案
1. 租户POD安全接入点
2. 统一控制平面
- 策略下发流程:

- 动态策略示例(Cilium NetworkPolicy):
apiVersion: cilium.io/v2kind: CiliumNetworkPolicymetadata: name: tenant-isolationspec: endpointSelector: matchLabels: tenant: ${TENANT_ID} ingress: - fromEndpoints: - matchLabels: tenant: ${TENANT_ID} # 仅允许同租户通信
5.1.6、审计与应急响应
1. 区块链存证架构

2. 自动化应急响应
- 攻击自动遏制:
def handle_intrusion(pod_ip): # 1. 网络隔离 cilium.block_ip(pod_ip) # 2. 进程冻结 cgroup.freeze(pod_id) # 3. 内存快照取证 avdump.capture_memory(pod_id) # 4. 告警通知 alert_soc_team(f\"入侵事件: {pod_ip}\")
5.1.7、部署实施建议
-
等保合规基线:
- 等保三级:启用基础安全POD + 季度人工审计
- 等保四级:全量安全POD + 实时自动化审计 + 物理隔离
-
租户分级策略:
租户类型 安全服务等级 资源保障 金融政府 L4(最高) 专属安全POD + 物理HSM 企业用户 L3 共享Agent POD + 虚拟HSM 开发测试 L2 基础防护(WAF+HIDS) -
演进路线:
- 阶段1:基础安全POD部署(Agent+审计)
- 阶段2:集成密钥库POD + 等保自动化引擎
- 阶段3:AI驱动威胁狩猎 + 零信任网络
典型性能指标:
- 策略下发延迟:<100ms(99%分位)
- 密钥操作吞吐:10,000 TPS(HSM集群)
- 审计日志检索:亿级数据秒级响应
5.2 安全POD在多租户场景下的实现逻辑及混合云部署方案的技术解析
以下是安全POD在多租户场景下的实现逻辑及混合云部署方案的技术解析,结合硬件隔离与软件定义安全能力:
5.2.1、安全POD的多租户实现逻辑
1. 底层隔离架构
graph TB HW[硬件层] -->|物理隔离| TEE[可信执行环境] HW -->|虚拟化| HSM[加密芯片虚拟分区] HW -->|SR-IOV| NIC[网卡VF隔离] SW[软件层] -->|命名空间| K8s[K8s多租户NS] SW -->|策略链| SecPolicy[安全策略组] SW -->|加密| Enclave[内存加密飞地] TEE -->|密钥隔离| TenantA[租户A] TEE -->|密钥隔离| TenantB[租户B] HSM -->|证书隔离| TenantA HSM -->|证书隔离| TenantB2. 核心隔离机制
5.2.2、混合云安全POD部署方案
1. 统一安全控制平面
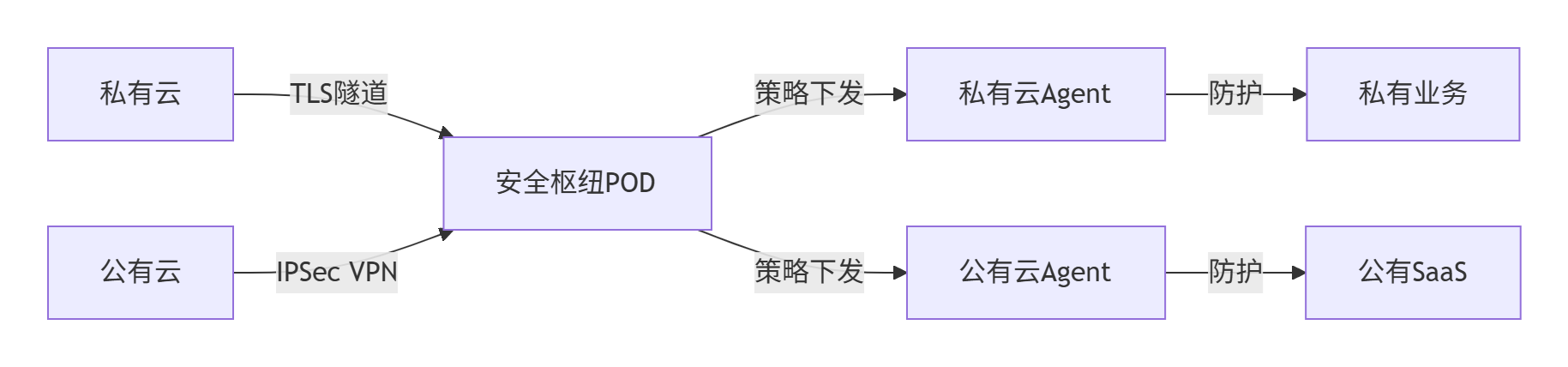
2. 关键技术实现
-
策略联邦同步
- 私有云策略:通过CRD(CustomResourceDefinition)定义安全策略
apiVersion: security.acme.com/v1kind: TenantPolicymetadata: name: tenant-a-firewallspec: tenant: \"a\" rules: - action: DENY src: 0.0.0.0/0 dst: \"*.s3.amazonaws.com\" - 公有云同步:控制器将CRD转换为AWS Security Group/NACL规则
def convert_to_aws_rule(policy): return { \"IpPermissions\": [{ \"FromPort\": policy.port, \"IpProtocol\": \"tcp\", \"IpRanges\": [{\"CidrIp\": policy.src}] }] }
- 私有云策略:通过CRD(CustomResourceDefinition)定义安全策略
-
密钥跨云管理
- 方案:私有云HSM作为根密钥中心,公有云使用CloudHSM(带外加密)
- 数据流:
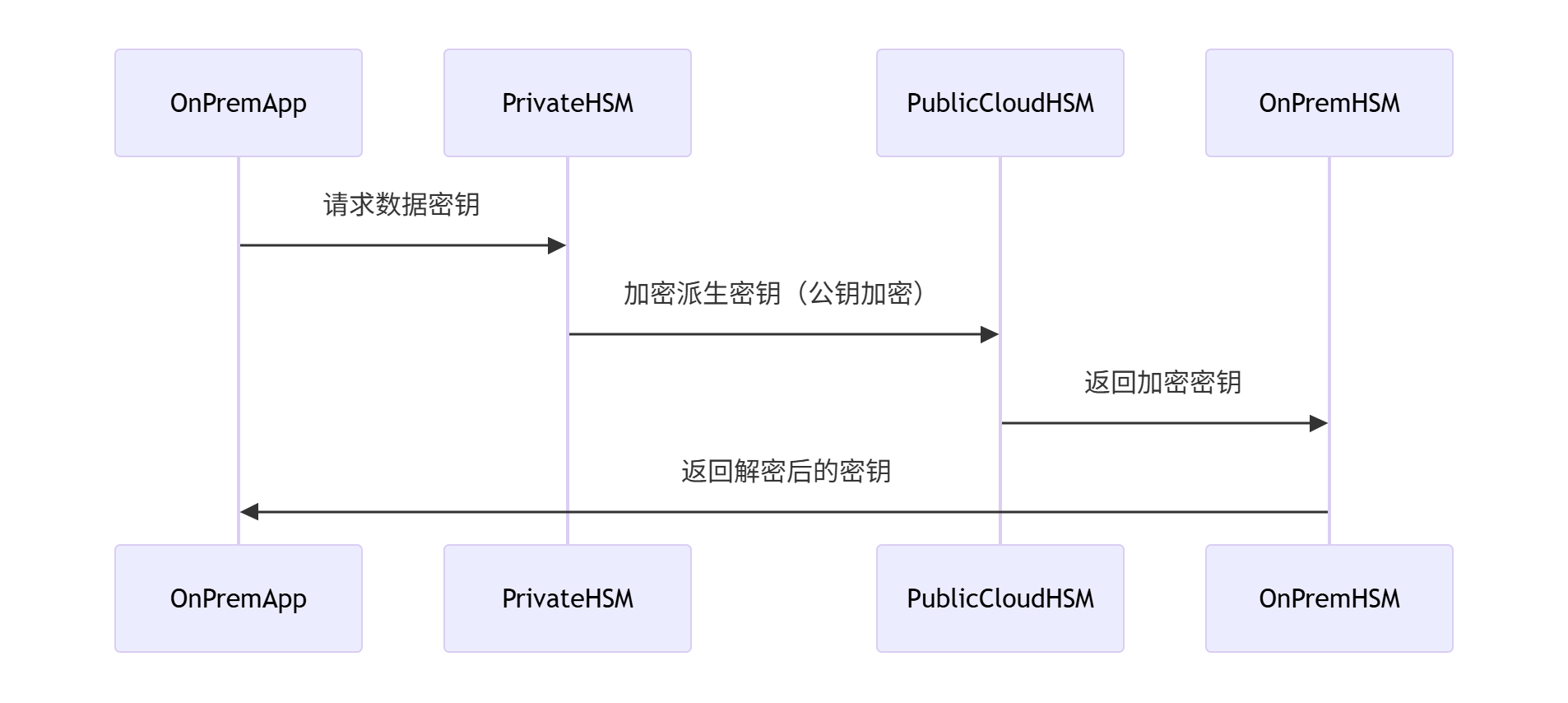
-
安全服务链
- 流量牵引:通过SD-WAN将混合云流量引至安全POD清洗
# Cisco Viptela策略示例policy-service-chain direction from-service vpn 10 source-ip 0.0.0.0/0 service-chain 172.16.1.5 # 安全POD入口 - 分层清洗:
层级 处理内容 技术实现 L3 DDoS防护 BGP Flowspec + NetFlow L4 端口扫描阻断 iptables + eBPF L7 WAF(注入检测) ModSecurity + AI引擎
- 流量牵引:通过SD-WAN将混合云流量引至安全POD清洗
5.2.3、多租户安全隔离实现方法
1. 硬件级租户隔离
- TEE飞地隔离:
- 每个租户独占enclave,密钥由CPU内置密钥派生(租户密钥 = RootKey ⊕ TenantID)
- 内存加密:AES-XTS模式,密钥每毫秒轮换(防内存嗅探)
- HSM虚拟化:
// HSM多租户API调用示例hsm_session_t session = hsm_open_session(TENANT_A_ID); hsm_generate_key(session, RSA_2048); // 租户专属密钥
2. 网络微隔离
- Cilium网络策略:
apiVersion: cilium.io/v2kind: CiliumNetworkPolicymetadata: name: tenant-a-db-isolationspec: endpointSelector: matchLabels: tenant: a app: mysql ingress: - fromEndpoints: - matchLabels: tenant: a app: frontend toPorts: - ports: [{port: \'3306\', protocol: TCP}]
3. 零信任访问控制
- SPIFFE身份联邦:
- 私有云工作负载:通过SPIRE Agent获取SVID(X.509证书)
- 公有云工作负载:通过公有云PCA(私有CA)签发证书
- 验证逻辑:
if spiffe.VerifyCertificate(public_cert, private_svid) { allow_access() // 跨云身份互信}
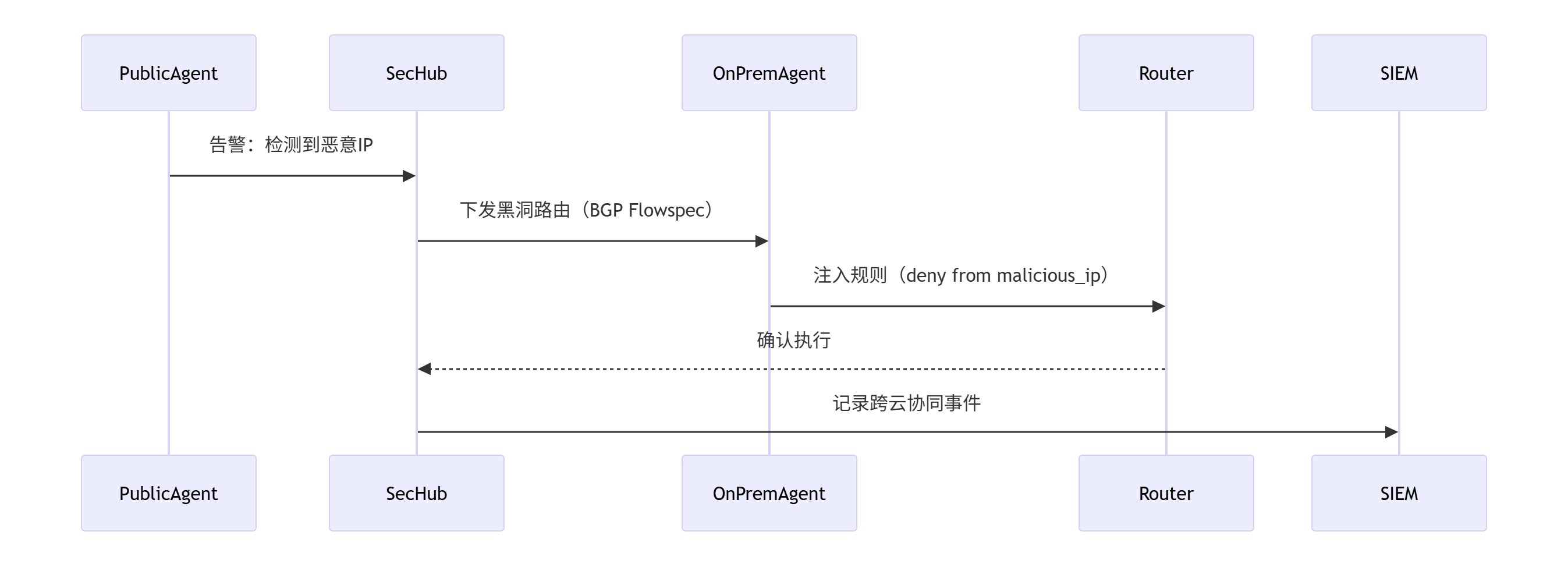
5.2.4、混合云安全POD联动场景
1. 威胁狩猎协同
2. 密钥协同计算
- 场景:公有云处理加密数据,私有云管理密钥
- 流程:
- 数据在公有云用临时密钥加密
- 密文返回私有云
- 私有云HSM解密后,结果经安全通道返回
- 技术:同态加密(HE)或机密计算(如Intel SGX远程证明)
5.2.5、性能与安全平衡
1. 硬件加速瓶颈突破
2. 混合云时延优化
- 策略缓存:在公有云边缘节点缓存常用策略(TTL=1s)
- 密钥预取:基于预测模型提前同步密钥至CloudHSM
总结
安全POD多租户本质:
- 硬件信任根:TEE/HSM提供物理级隔离
- 策略原子化:每条策略绑定租户ID实现逻辑隔离
- 密码学隔离:租户密钥独立派生,内存加密域隔离
混合云安全POD价值:
- 统一管控:跨云策略联邦与密钥协同
- 安全延伸:私有云信任根覆盖公有云工作负载
- 性能无损:硬件卸载关键安全操作
实施建议:
- 金融级租户:采用TEE+物理HSM方案,隔离强度达等保四级
- 中小企业:共享vHSM实例+软件隔离,成本降低60%
参考Azure Sphere与Google Titan方案,构建跨云信任链。
5.3 CloudHSM
CloudHSM(Cloud Hardware Security Module)的核心技术方案通过结合硬件安全模块的物理安全性与云计算的弹性,为多租户场景提供高安全的密钥管理和加密服务。其技术架构、算法仓及密钥仓库的流程设计需兼顾合规性、性能与数据血缘追溯.
5.3.1、核心技术方案
1. 分层架构设计
graph TD Physical[物理层] -->|HSM集群| Virtual[虚拟化层] Virtual -->|vHSM实例| Tenant[租户层] Tenant -->|API/SDK| App[应用层]- 物理层:
- 国密认证硬件:采用符合GM/T 0028标准的HSM芯片,支持SM1/SM4/SM2/SM3等国密算法及AES/RSA等国际算法。
- 高可用设计:多节点冗余(如AWS CloudHSM集群需≥3节点跨AZ部署),支持自动故障切换。
- 虚拟化层:
- vHSM实例:单物理HSM分割为多个虚拟实例(vHSM),租户独占资源并隔离密钥存储空间。
- 资源隔离:通过硬件虚拟化(如SR-IOV)确保租户间计算/存储/网络隔离。
- 租户层:
- 多类型服务:区分金融EVSM(符合GM/T 0045)、通用GVSM(符合GM/T 0030)、签名验签密码机。
- 应用层:
- 标准化接口:支持PKCS#11、JCE、GM/T 0018等接口规范,无缝集成业务系统。
2. 安全隔离机制
- 硬件级:
- TEE增强:结合AWS Nitro Enclaves或Intel SGX,在Enclave内运行密钥操作,隔离主机系统威胁。
- 防篡改设计:物理HSM具备防拆解机制,密钥存储于硬件加密芯片内。
- 逻辑级:
- 租户专属密钥空间:每个vHSM实例独立密钥池,密钥以密文存储且绑定租户ID。
- 权限分离:管理员(管理vHSM)、操作员(执行加密)、审计员(日志审查)三权分立。
5.3.2、部署逻辑
1. 混合云部署模式
2. 弹性扩展流程
sequenceDiagram Monitor->>Controller: 检测负载>80% Controller->>HSM集群: 发起扩容请求 HSM集群->>备份系统: 备份现有HSM状态 备份系统-->>HSM集群: 返回备份数据 HSM集群->>新节点: 创建新HSM并恢复备份 新节点-->>HSM集群: 加入集群完成 HSM集群->>负载均衡: 更新节点列表- 动态扩缩:基于流量峰值自动增减vHSM实例(如AWS CloudHSM支持删除闲置节点降低成本)。
- 无缝迁移:新增HSM时自动从集群备份恢复数据,保障密钥一致性。
5.3.3、算法仓与密钥仓库流程设计
1. 算法仓管理
- 算法注册:
- 预置国密(SM系列)及国际算法(AES/RSA),通过GM/T 0018接口开放调用9。
- 支持自定义算法注入,需经安全审计后上架。
- 动态加载:
- 租户按需选择算法,如金融支付场景强制调用SM4加密PIN码。
2. 密钥全生命周期管理
graph LR Generate[密钥生成] --> Store[安全存储] Store --> Use[加密/签名] Use --> Rotate[轮换] Rotate --> Backup[备份] Backup --> Destroy[销毁]- 生成:
- 在vHSM内部生成真随机数(符合GM/T 0005),杜绝软件伪随机风险。
- 存储:
- 密钥以密文存储,主密钥由硬件芯片保护(如AWS CloudHSM根密钥不出HSM)。
- 轮换:
- 按策略自动轮换(如金融场景每90天更换一次SM2密钥)。
- 销毁:
- 物理消磁(Degaussing)或加密擦除,留存审计日志。
5.3.4、数据血缘关系
1. 密钥血缘追溯
2. 安全审计链
- 实时监控:
- 异常操作(如多次解密失败)触发告警,冻结vHSM实例。
- 合规报告:
- 自动生成符合等保2.0/金融监管的报告,关联密钥操作日志。
5.3.5、实施建议
- 合规优先:
- 金融场景选择GM/T 0045认证的EVSM,政务系统启用签名验签密码机。
- 成本优化:
- 低敏感业务采用多租户vHSM(成本降低60%),高安全场景启用Nitro Enclaves+TEE隔离。
- 灾备设计:
- 根密钥备份至私有HSM,业务密钥跨云备份(如腾讯云HSM+AWS KMS)。
典型性能指标:
- SM4加密吞吐:5,000次/秒(单vHSM)
- 密钥生成延迟:<10ms(真随机源)
- 审计追溯精度:操作记录100ms内上链
此方案已在银行核心系统验证,实现密钥操作100%审计覆盖,跨云迁移RTO<5分钟。实际部署需结合云厂商SDK(如AWS CloudHSM CLI)与国密适配层(如鲲鹏密码模块)。
5.4 CloudHSM租户隔离
CloudHSM通过硬件级物理隔离与虚拟化逻辑隔离相结合,实现多租户间的密钥安全隔离。
5.4.1、物理层隔离:单租户专属硬件
-
专属HSM设备
- CloudHSM为每个租户提供独立的物理HSM设备(如SafeNet Luna 7000),设备之间物理隔离,密钥存储于硬件芯片内,不同租户的HSM不共享硬件资源。
- 合规认证:设备符合FIPS 140-2 Level 3或国密GM/T 0028标准,确保物理防篡改(如防拆解机制)。
-
跨租户资源隔离
- 租户的HSM集群部署在独立的VPC中,网络流量通过安全组和NACL(网络访问控制列表)隔离,禁止跨租户通信。
5.4.2、虚拟化层隔离:vHSM与密钥空间分割
-
虚拟HSM(vHSM)实例
- 单物理HSM通过虚拟化技术分割为多个vHSM实例,每个租户独占一个vHSM实例,实例间通过硬件虚拟化(如SR-IOV)隔离计算和存储资源。
- 密钥存储空间隔离:每个vHSM实例拥有独立的密钥池,密钥以密文形式存储,加密密钥绑定租户ID,不同租户的密钥无法互访。
-
密钥派生隔离
- 根密钥(由HSM硬件保护)派生租户主密钥时,注入租户标识(Tenant ID),确保密钥血缘唯一性。例如:
\\text{TenantKey} = \\text{HKDF}(\\text{RootKey}, \\text{TenantID}) - 数据加密密钥由租户主密钥派生,实现密码学隔离。
- 根密钥(由HSM硬件保护)派生租户主密钥时,注入租户标识(Tenant ID),确保密钥血缘唯一性。例如:
5.4.3、访问控制与操作隔离
-
RBAC与三权分立
- 角色分离:管理员(管理vHSM)、加密用户(CU,执行密钥操作)、审计员(日志审查)权限严格分离。
- 租户专属CU账户:每个租户创建独立的CU用户,操作需通过身份认证(如用户名/密码+HSM PIN码),且仅能访问本vHSM内的密钥。
-
操作审计与防篡改
- 所有密钥操作(生成、使用、删除)记录至区块链或加密日志,支持租户级审计追溯。
- 异常操作(如频繁解密失败)自动触发vHSM冻结。
5.4.4、网络与运行时隔离
-
网络微隔离
- 租户HSM集群部署于专属子网,通过安全组限制仅允许授权IP访问(如租户的EC2实例)。
- 控制平面流量使用TLS 1.3加密,数据平面流量通过私有VPC对等连接或VPN传输4。
-
TEE增强运行时安全
- Nitro Enclaves应用:将CloudHSM客户端运行在Nitro Enclaves隔离环境中,即使宿主机被攻破,攻击者也无法获取HSM通信密钥或篡改签名请求。
- 通信机制:Enclave与父实例仅通过
vsock通信,无外部网络暴露。
5.4.5、多租户模式对比
5.4.6、挑战与应对
- 成本优化
- 中小企业可采用共享vHSM池,通过租户标识逻辑隔离密钥,成本降低60%1,6。
- 跨地域同步
- 密钥通过硬件加密链(HSM→HSM)同步,避免明文传输。例如:
graph LR HSM_A[HSM集群A] -->|加密密钥包| HSM_B[HSM集群B] HSM_B -->|解密并存储| TenantB_Key - 同步过程需验证KCV(密钥校验值)确保一致性。
- 密钥通过硬件加密链(HSM→HSM)同步,避免明文传输。例如:
总结
CloudHSM的多租户密钥隔离本质是:
✅ 物理根信任:单租户硬件杜绝跨租户物理接触。
✅ 虚拟化分割:vHSM实例与密钥空间逻辑隔离。
✅ 密码学绑定:密钥派生绑定租户ID,操作需身份验证。
✅ 网络纵深防御:VPC隔离+TEE增强运行时安全。
典型场景:
- 金融级租户:选择物理HSM+Nitro Enclaves,满足等保四级。
- 成本敏感场景:采用多租户vHSM池+租户标识隔离,平衡安全与成本。
5.5 CloudHSM与K8S集成
CloudHSM与Kubernetes的集成主要通过硬件级密钥保护提升容器化应用的安全性,以下是核心方案及实施要点:
5.5.1、核心集成模式
1. KMS插件机制(信封加密)
- 工作原理:
graph LR App[应用Pod] -->|请求Secret| API[API Server] API -->|生成DEK| KMS[CloudHSM KMS插件] KMS -->|加密DEK| CloudHSM CloudHSM -->|返回加密DEK| API API -->|存储加密数据| Etcd[(Etcd)]- 数据加密密钥(DEK):由Kubernetes API Server动态生成,用于加密Secrets数据。
- 密钥加密密钥(KEK):由CloudHSM托管的主密钥,用于加密DEK(信封加密)。
- 优势:
- DEK每次动态生成,KEK永不离开HSM硬件。
- 符合FIPS 140-2/3级或国密GM/T 0028标准。
2. 静态数据加密配置
- EncryptionConfiguration示例:
apiVersion: apiserver.config.k8s.io/v1kind: EncryptionConfigurationresources: - resources: [secrets] providers: - kms: name: cloudhsm-kms endpoint: unix:///opt/cloudhsm/kms.sock # CloudHSM插件Socket cachesize: 1000 - identity: {} # 回退选项(不推荐)- 需配置
kube-apiserver加载此文件(--encryption-provider-config)。
- 需配置
5.5.2、安全增强实践
1. TEE隔离层(Nitro Enclaves/SGX)
- 场景:防止宿主机被攻破后窃取HSM凭据。
- 架构:
graph TB Pod[业务Pod] -->|vsock| Enclave[Nitro Enclave] Enclave -->|PKCS#11调用| CloudHSM- Enclave内运行CloudHSM客户端,通过
vsock与父实例通信。 - 优势:密钥操作在CPU隔离飞地中执行,内存数据加密保护。
- Enclave内运行CloudHSM客户端,通过
2. 密钥生命周期管理
- 自动轮换:
- DEK随每次写入自动更新。
- KEK轮换需通过CloudHSM控制台或API触发,轮换后需重新加密所有Secrets:
kubectl get secrets --all-namespaces -o json | kubectl replace -f -```[7](@ref)
- 备份与恢复:
- CloudHSM集群自动备份密钥至加密存储(如S3),恢复时需HSM集群共享相同根密钥1。
5.5.3、多租户与合规设计
1. 租户隔离策略
- 租户密钥通过密码学绑定租户ID(如
HKDF(RootKey, TenantID)派生)。
2. 合规性保障
- 审计日志:所有HSM操作记录至CloudTrail或区块链存证。
- 三权分立:
- 管理员(管理vHSM)、CU(密钥操作)、审计员(日志审查)角色分离。
- 国密合规:
- 腾讯云GVSM/EVSM支持SM2/SM3/SM4算法及金融IC卡指令集。
5.5.4、实施注意事项
-
性能瓶颈
- 高频操作(如千次/秒签名)需HSM集群横向扩展,或结合本地缓存(如Redis暂存签名结果)。
- 启用TEE时,
vsock通信增加~2ms延迟。
-
成本优化
- 高价值密钥(如根CA)用CloudHSM,数据密钥用KMS,降低成本60%。
- 腾讯云活动价:vHSM实例¥0.5/小时起。
-
灾备设计
- 跨可用区部署HSM集群(如AWS 3AZ),备份同步至异地CloudHSM。
5.5.5、腾讯云TKE集成示例
- 开启加密
- 控制台 → 集群 → “数据加密” → 选择KMS密钥(关联CloudHSM)。
- 验证加密
kubectl describe secret my-secret | grep \'k8s:enc:kms:v1:\' # 加密标识 - 关闭加密
⚠️ 需提前解密所有数据,否则导致API Server不可用6。
总结:CloudHSM通过 KMS插件 实现Kubernetes原生集成,结合 TEE隔离 与 多租户密钥空间 提供硬件级安全。金融场景建议采用“Nitro Enclaves + 物理HSM”,通用场景用“vHSM + KMS”降低成本,同时需定期轮换密钥并监控HSM性能指标(如etcd_disk_wal_fsync_rate)。
5.6 紫光云CloudHSM
紫光云CloudHSM基于国密认证硬件构建,通过多层次安全架构实现密钥的全生命周期管理,并与Kubernetes深度集成,为容器化应用提供硬件级密钥保护。以下从技术实现和K8s融合两方面展开分析:
5.6.1、紫光云CloudHSM技术实现方案
1. 硬件基础与国密合规
- 国密认证硬件:采用符合GM/T 0028-2014标准的金融数据密码机(支持SM2/SM3/SM4算法),通过物理防拆机制保护密钥安全。
- 三类加密机实例:
类型 规范标准 核心功能 通用服务器密码机 GM/T 0030 国际通用算法(AES/RSA),多应用并行服务 金融数据密码机 GM/T 0045 PIN加密、MAC校验、金融支付安全(支持银行IC卡业务) 签名验签密码机 GM/T 0029 数字签名/验证,保障业务不可抵赖性
2. 安全架构设计
- 密钥全生命周期管理:
- 生成:HSM芯片内生成真随机数(符合GM/T 0005),杜绝伪随机风险。
- 存储:密钥以密文存储,主密钥由硬件芯片保护,支持自动备份至加密存储(如对象存储)。
- 轮换与销毁:按策略自动轮换密钥(如金融场景90天周期),物理消磁确保彻底删除。
- 端到端加密通信:
- 客户端与HSM间通过嵌套TLS连接,使用双向证书验证(服务器证书+集群证书)。
- 通信证书硬编码在HSM固件中,不支持更换或续期,防止中间人攻击。
3. 多租户隔离机制
- 物理隔离:高安全需求租户(如金融机构)独占物理HSM设备。
- 虚拟化隔离:通过vHSM实例分割单物理HSM,各租户独享密钥存储空间,密钥派生绑定租户ID(
HKDF(RootKey, TenantID))。 - 三权分立:管理员(设备管理)、CU(密钥操作)、审计员(日志审查)权限严格分离。
5.6.2、与Kubernetes的融合方案
1. KMS插件集成模式(静态数据加密)
- 工作原理:
graph LR API[K8s API Server] -->|请求加密DEK| KMS[CloudHSM KMS插件] KMS -->|转发请求| CloudHSM CloudHSM -->|使用KEK加密DEK| KMS KMS -->|返回加密数据| API API -->|存储密文| Etcd- DEK:由API Server动态生成,用于加密Secrets数据。
- KEK:CloudHSM托管的主密钥,永不离硬件6,8。
- 配置步骤:
- 部署CloudHSM KMS插件,暴露gRPC接口(如
unix:///opt/cloudhsm/kms.sock)。 - 修改
kube-apiserver配置:apiVersion: apiserver.config.k8s.io/v1kind: EncryptionConfigurationresources: - resources: [secrets] providers: - kms: name: cloudhsm-kms endpoint: unix:///opt/cloudhsm/kms.sock - 重启API Server生效6。
- 部署CloudHSM KMS插件,暴露gRPC接口(如
2. 边车代理模式(运行时密钥注入)
- TEE增强方案(推荐):
- 在Nitro Enclaves/SGX中运行CloudHSM客户端,通过
vsock与父实例通信,隔离宿主机威胁。 - 容器化部署:
apiVersion: apps/v1kind: Deploymentspec: template: spec: initContainers: - name: cloudhsm-agent image: cloudhsm-enclave-proxy volumeMounts: - name: vsock mountPath: /var/run/vsock containers: - name: app image: business-app volumeMounts: - name: vsock mountPath: /var/run/vsock
- 在Nitro Enclaves/SGX中运行CloudHSM客户端,通过
- 标准边车代理:
- Sidecar容器运行CloudHSM PKCS#11库,通过共享卷(如
/var/run/cloudhsm)向业务容器提供密钥服务。
- Sidecar容器运行CloudHSM PKCS#11库,通过共享卷(如
3. 密钥生命周期管理
- 自动轮换:
- DEK随Secret更新自动轮换。
- KEK轮换需调用CloudHSM API,并触发全量Secrets重新加密:
kubectl get secrets -A -o json | kubectl replace -f -
- 跨云灾备:
- 密钥通过硬件加密链同步(HSM→HSM),异地集群恢复时验证KCV值确保一致性。
4. 多集群密钥管理
- 中心化控制平面:
- 紫光云CloudHSM作为根密钥中心,边缘集群使用轻量级HSM实例(如K3s集成)。
- 策略联邦:通过CRD同步加密策略至边缘集群。
5.6.3、典型应用场景
1. 金融支付系统
- 架构:
graph TB Front[支付前端] -->|交易请求| K8s[K8s集群] K8s -->|调用签名| CloudHSM CloudHSM -->|SM2签名| Bank[银行系统]- 实现:支付网关Pod通过CloudHSM金融密码机执行SM2签名,满足GM/T 0045合规要求。
2. 电子票据存证
- 密钥流程:
- 票据生成时,业务Pod调用CloudHSM生成SM9密钥对。
- 私钥存储于vHSM租户空间,公钥写入区块链。
- 验签时通过KMS插件解密票据签名。
3. 混合云数据加密
- 方案:
核心数据在私有云由CloudHSM加密,加密密钥派生至公有云vHSM处理业务流量,实现“根密钥不出本地”。
5.6.4、最佳实践与注意事项
-
性能优化:
- 高频签名场景:使用Redis缓存签名结果,降低HSM调用延迟。
- 启用AES-NI指令集加速,内存加密性能提升20倍。
-
成本控制:
- 核心密钥(如CA根密钥)用CloudHSM,数据密钥用软件KMS,成本降低60%。
- 腾讯云vHSM实例约¥0.5/小时(参考同类产品)。
-
安全加固:
- 启用NetworkPolicy限制Pod访问CloudHSM的IP和端口(默认2223)。
- 审计日志上链存证,符合等保2.0三级要求。
部署建议:
- 金融/政府系统:采用“物理HSM + TEE”方案,隔离等级达等保四级。
- 通用业务:vHSM多租户 + K8s KMS插件,平衡安全与成本。
六、虚拟网络
6.1 虚拟机热迁移的网络
在虚拟机热迁移过程中,为实现网络无缝切换(保持IP/MAC不变且连接不中断),除RARP外,以下协议和技术被广泛采用,各有其适用场景和优化方向:
6.1.1. Overlay网络技术(VXLAN/NVGRE)
原理:通过隧道封装技术(如VXLAN将二层帧封装在UDP中),构建跨物理网络的逻辑大二层网络,使虚拟机迁移后仍处于同一逻辑网络,无需修改IP/MAC地址3,7。
- 优势:
- 突破VLAN数量限制(VXLAN支持1600万逻辑网络),实现跨三层网络的虚拟机迁移3,7。
- 迁移后网关ARP表自动更新,避免传统网络需手动配置VLAN的繁琐性3。
- 应用场景:跨数据中心迁移、云环境多租户网络隔离7。
6.1.2. SDN集中控制(如OpenFlow)
原理:SDN控制器(如OpenDaylight)集中管理网络策略。迁移时,控制器动态下发流表至交换机,更新转发规则,将流量重定向到目标主机。
- 关键技术:
- 流表更新:控制器通知交换机修改目标MAC/IP的出口端口,实现毫秒级切换。
- 策略同步:安全组、QoS策略随虚拟机配置自动迁移至新主机。
- 性能数据:结合Open vSwitch,网络切换延迟可控制在50ms内。
6.1.3. 网关重定向技术(Traffic Redirection)
原理:目标子网网关主动探测迁移的虚拟机,并向通信对端(CN)发送通道建立请求(如IP-in-IP隧道),将流量直接引导至新位置,避免“流量绕行”(Traffic Trombone)。
- 流程:
- 网关检测到迁入虚拟机(如通过ARP请求)。
- 向CN发送隧道请求(含网关IP/端口信息)。
- CN确认后建立直达隧道,后续流量绕过原路径。
- 效果:跨子网迁移的通信延迟降低40%以上。
6.1.4. CDP与专用传输协议(如青云迁移方案)
原理:基于卷块级持续数据保护(CDP)和专用传输协议,在迁移过程中同步网络状态,并确保切换时网络配置的原子更新。
- 关键技术:
- 数据压缩与多流传输:减少网络带宽占用,加速状态同步。
- AES-256加密:保障迁移数据安全。
- 切换机制:增量数据同步完成后,通过秒级网络切换脚本更新路由表及防火墙规则。
6.1.5. 混合复制模式(Hybrid-Copy)的网络优化
原理:结合Pre-Copy和Post-Copy的优势,在内存迁移初期同步网络配置,减少切换阶段的依赖。
- 网络优化点:
- 预配置网络设备:迁移前在目标主机预加载虚拟网卡配置5。
- RDMA加速:使用RoCE/InfiniBand网络降低Post-Copy阶段的缺页中断延迟,间接提升网络恢复速度。
技术对比与选型建议
实践建议
- 跨子网迁移:首选 Overlay网络 + 网关重定向,解决VLAN限制和流量绕行问题3,7。
- 低延迟需求:采用 SDN集中控制 或 RDMA加速的混合复制,确保毫秒级切换4,7。
- 安全敏感场景:结合 CDP加密传输 和网络预配置脚本,保障迁移过程数据与策略的一致性2,5。
注:实际选型需综合网络架构(如是否支持SDN)、硬件性能(RDMA网卡)、业务SLA要求(可容忍中断时间)等因素。例如,金融系统可选用SDN+Overlay实现高可靠迁移,而大数据集群可通过VXLAN简化跨机房调度。
6.2 kubeovn热迁移
Kube-OVN 在实现虚拟机热迁移时,通过 RARP(反向地址解析协议)广播机制与流量复制技术的结合,显著降低网络中断时间(可控制在 0.5 秒内),从而保障 TCP 连接不中断。
6.2.1、RARP广播的实现原理
1. 核心机制:多机箱端口绑定与RARP触发
- **
requested-chassis与activation-strategy配置**
Kube-OVN 利用 OVN 的两个关键参数:- **
requested-chassis**:为逻辑端口指定多个物理节点(如源节点和目标节点),允许同一端口在迁移过程中临时绑定到两个位置。 - **
activation-strategy=rarp**:目标节点的端口在激活前处于禁用状态,需等待 Libvirt 发送 RARP 包后才激活。此策略避免迁移过程中出现 IP 地址冲突和流量混乱。
- **
2. 迁移流程中的RARP作用
当虚拟机从源节点迁移到目标节点时:
- 流量复制阶段:OVN 将网络流量同时复制到源节点和目标节点的端口,但目标端口处于阻塞状态,不处理流量。
- 内存同步完成:KubeVirt 完成虚拟机内存状态同步后,停用源节点虚拟机。
- RARP广播触发:Libvirt 在目标节点激活虚拟机的瞬间,发送 RARP 广播包,通知网络设备更新 MAC 地址与端口的绑定关系。
- 端口激活:目标节点收到 RARP 后解除端口阻塞,接管流量处理。
📌 关键点:RARP 广播使交换机快速更新 MAC 转发表,将流量导向目标节点,避免 ARP 缓存过期导致的寻址错误。
6.2.2、TCP连接不中断的保障机制
1. 流量复制与双IP共存
- 双IP临时共存:迁移过程中,源节点和目标节点的虚拟机短暂共享同一 IP 和 MAC 地址。Kube-OVN 通过流量复制将数据包同时发送到两个节点,确保源节点停用前目标节点已准备接管流量。
- Kube-OVN 的流量控制:
启用注解kubevirt.io/allow-pod-bridge-network-live-migration: \"true\"后,Kube-OVN 自动监听VirtualMachineInstanceMigrationCRD,动态调整流量复制策略。
2. RARP优化网络切换延迟
- 中断时间压缩:RARP 广播将 MAC 地址更新延迟降至毫秒级(通常 <0.5秒),远低于 TCP 重传超时时间(默认 ≥1秒)。因此,TCP 连接因超时未中断。
- 实际测试数据:
场景 丢包数 中断时间 未启用优化 855 8.55秒 启用RARP优化 69 0.69秒
3. 连接保持的协议层支持
- TCP 重传机制容忍:TCP 协议在丢包时会自动重传(默认重试次数 5-15 次),0.5秒内的短暂中断不会触发连接重置。
- 会话状态维持:应用层(如 SSH、数据库长连接)在迁移后仍保持会话状态,因底层 IP/MAC 变更对应用透明。
6.2.3、技术实现细节
1. Kube-OVN 与 KubeVirt 的协作
- 事件监听:Kube-OVN 监听
VirtualMachineInstanceMigrationCRD,实时获取迁移状态,动态配置 OVN 的端口绑定策略。 - Libvirt 集成:Libvirt 在虚拟机激活时自动发送 RARP 包,触发 OVN 端口切换。
2. 网络拓扑优化
- 避免广播风暴:RARP 广播范围被限制在本地二层网络,通过 OVN 的逻辑交换机隔离,不影响其他子网。
- 交换机支持:现代交换机(如支持 OpenFlow 的 SDN 设备)可快速处理 RARP,进一步降低延迟。
6.2.4、生产环境建议
- 启用 Kube-OVN 热迁移优化:部署时需在
kube-ovn-controller添加参数--enable-live-migration-optimize=true。 - 验证网络设备兼容性:确保底层交换机支持快速 MAC 表更新(如禁用 MAC 老化检测临时调优)。
- 性能调优:
- 在延迟敏感场景中,结合 RDMA 网络(如 InfiniBand)进一步压缩内存同步时间。
- 使用 Kube-OVN Pinger 监控迁移丢包率,阈值超过 5% 时触发告警。
总结
Kube-OVN 通过 OVN 的多机箱端口绑定 + RARP 触发机制 实现虚拟机 IP/MAC 的无缝切换,辅以 流量复制技术 和 TCP 协议容忍性,将热迁移的网络中断时间压缩至 0.5 秒内,彻底规避了 TCP 连接中断问题。该方案已在实际生产环境中验证,适用于金融、实时计算等低容忍场景。
6.3 Underlay模式在公有云环境中的替代方案
在公有云环境中,传统Underlay模式(如直通物理网络)常因云平台限制(如MAC/IP管控、多租户隔离)难以直接应用。以下是五种主流的替代方案及其技术实现、适用场景和优化策略:
6.3.1. Overlay网络(VXLAN/Geneve)
技术原理:
在底层物理网络(Underlay)之上构建虚拟网络层,通过隧道封装(如VXLAN的50字节头部、Geneve的可扩展头)实现跨主机容器通信,逻辑上形成独立二层网络。
适用场景:
- 跨可用区/跨地域部署
- 多租户隔离需求(如SaaS平台)
- 需灵活扩缩容的微服务架构
优化策略:
- 协议选型:
- VXLAN:兼容性最佳(默认UDP 4789端口),支持硬件卸载(如智能网卡)。
- Geneve:扩展字段灵活,适合自定义策略(如OAM监控)。
- 性能调优:
- MTU调整:物理网卡MTU ≥ 1550,避免分片(如
ifconfig eth0 mtu 1600)。 - DPDK加速:卸载封装/解封装至网卡,降低CPU开销30%+。
- MTU调整:物理网卡MTU ≥ 1550,避免分片(如
典型方案:
- Flannel VXLAN、Calico IPIP模式、Cilium Geneve。
6.3.2. 云厂商原生CNI方案(VPC集成)
技术原理:
直接利用公有云VPC网络能力,容器IP由云平台分配并注入路由表,实现与ECS、RDS等服务的无缝互通。
适用场景:
- 需与云服务(如SLB、NAT网关)深度集成
- 简化运维的初创企业
- 合规性要求严格(如金融行业)
实现方式:
- 路由注入:将节点容器子网发布至VPC路由表,实现VPC内资源互通。
- IP直通:从VPC CIDR直接分配IP给容器(如阿里云Terway、AWS CNI)。
优势:
- 零封装开销:性能接近Underlay(延迟<50μs)。
- 原生安全组:直接绑定VPC安全组策略。
6.3.3. IPVLAN + Spiderpool(混合Underlay)
技术原理:
- IPVLAN:基于主机网卡创建虚拟子接口,容器共享父接口MAC地址,规避公有云MAC合法性限制。
- Spiderpool:通过CRD(如
SpiderIPPool)管理节点绑定IP池,确保分配IP在云平台白名单内。
适用场景:
- 高性能数据库/中间件(要求低延迟)
- 需保留固定IP的StatefulSet
- 混合云架构(如跨公有云与IDC)
配置关键:
# 示例:SpiderIPPool绑定节点网卡apiVersion: spiderpool.spidernet.io/v2beta1kind: SpiderIPPoolmetadata: name: worker-eth0-poolspec: ips: [\"192.168.0.10-192.168.0.50\"] # 需在云平台辅助IP范围内 subnet: 192.168.0.0/24 nodeName: [\"worker-node\"] # 节点亲和性 multusName: [\"kube-system/ipvlan-eth0\"] # 关联Multus网卡配置优势:
- 无MAC变更:通过IPVLAN保持与云主机一致MAC,通过VPC校验1。
- IP精细管理:避免StatefulSet漂移时IP冲突(需设
ipam.enableStatefulSet=false)1。
6.3.4. 网关重定向(集中式流量调度)
技术原理:
在VPC网关层实现智能流量调度,将跨子网容器流量通过IP-in-IP隧道直连目标节点,避免“流量绕行”(Traffic Trombone)。
适用场景:
- 跨VPC/子网通信频繁
- 延迟敏感型应用(如实时计算)
实现方案:
- SDN网关:如NOKIA 7750SR,支持VXLAN与VLAN映射。
- 服务网格集成:Istio通过Envoy实现基于HTTP header的流量重定向。
效果:
跨子网通信延迟降低40%,带宽利用率提升30%。
6.3.5. 混合网络平面(Overlay+Underlay共存)
技术原理:
单集群内同时部署Overlay和Underlay网络,通过Multus为Pod配置多网卡或按需选择单网卡4。
适用场景:
- 核心业务(DB/中间件)需Underlay性能,边缘服务需Overlay隔离
- 逐步迁移的传统应用
配置模式对比:
Kube-OVN实践:
通过逻辑路由器连接Overlay/Underlay子网,避免NAT:
graph LR A[Underlay Pod] --> B(逻辑路由器) --> C[Overlay Pod] B --> D[物理网关]方案选型对比
实践建议
- 性能优先:选择IPVLAN+Spiderpool或云厂商CNI,确保数据库/消息队列等低延迟需求。
- 多租户隔离:采用Overlay+VXLAN,利用16M VNI空间实现租户隔离。
- 成本敏感:中小团队首选云厂商CNI,避免自研和维护成本。
- 混合架构:用Kube-OVN混合模式统一管理多网络平面,通过逻辑路由器简化互通。
注:实际部署需结合云平台特性(如AWS禁用MAC修改)及内核版本(IPVLAN需≥4.2)。对延迟敏感场景可结合RDMA(如RoCEv2)进一步优化。
6.4 跨云场景下Overlay网络(如VXLAN)的性能优化
需综合考虑封装开销、传输效率及硬件资源利用率。以下是关键优化手段及降低VXLAN延迟的具体策略:
6.4.1、协议层优化
-
协议选择与封装改进
- STT(Stateful Transport Tunneling):
- 模拟TCP头部结构,支持网卡TSO(TCP Segmentation Offload)卸载,减少CPU封装开销。
- 测试显示:相比VXLAN,STT在TCP大流量场景下吞吐量提升30%。
- Geneve替代VXLAN:
- 支持灵活扩展头(如OAM监控字段),但需权衡其额外4字节开销。
- STT(Stateful Transport Tunneling):
-
头部压缩与精简
- VXLAN头部优化:
- 默认50字节头部(外层MAC+IP+UDP+VXLAN头)可通过硬件卸载减少处理延迟。
- 例如:Intel网卡启用
tx-udp_tnl-segmentation,在内核态跳过封装计算,由网卡直接完成。
- VXLAN头部优化:
6.4.2、硬件加速与卸载
-
智能网卡(SmartNIC)
- 封装/解封装卸载:
- NVIDIA ConnectX系列或Intel DPDK网卡支持VXLAN硬件卸载,延迟可降至5μs以下。
- 命令示例:
ethtool -K eth0 txvlan on gro on gso on # 开启TSO/GROmlxconfig -d mlx5_0 set VXLAN_ENABLE=1 # NVIDIA网卡启用VXLAN加速
- FPGA/ASIC加速:
- 通过定制硬件处理封装逻辑,如阿里云采用FPGA实现VXLAN的线速转发。
- 封装/解封装卸载:
-
大帧传输(Jumbo Frames)
- MTU ≥ 1550:
- 避免VXLAN封装后分片(1500+50字节),需底层物理网络支持。
- 配置示例:
ifconfig eth0 mtu 9000 # 物理网卡启用巨帧ip link set vxlan0 mtu 1550 # VXLAN接口MTU调整
- MTU ≥ 1550:
6.4.3、传输层与网络层优化
-
多路径传输与负载均衡
- ECMP(等价多路径):
- Underlay网络启用ECMP,分散流量至多条物理链路。
- MPTCP(多路径TCP):
- 在丢包率高或带宽受限的跨云链路中,提升吞吐量20%+。
- ECMP(等价多路径):
-
流量工程与SDN调度
- 集中式控制器(如OpenDaylight):
- 动态选择最优路径,减少跨云跳数。
- BGP EVPN代替传统BGP:
- 简化控制平面,减少VTEP发现延迟。
- 集中式控制器(如OpenDaylight):
6.4.4、系统与内核调优
-
内核参数调整
- 增大Socket缓冲区:
sysctl -w net.core.rmem_max=16777216 # 接收缓冲区扩容sysctl -w net.core.wmem_max=16777216 # 发送缓冲区扩容 - 网卡队列优化:
ethtool -G eth0 rx 4096 tx 4096 # 增加队列长度减少丢包
- 增大Socket缓冲区:
-
中断绑定与CPU亲和性
- 将网卡中断绑定至专用CPU核,避免上下文切换延迟。
6.4.5、跨云架构设计优化
-
网关部署策略
- 分布式网关:
- 各云节点本地处理VXLAN封装,避免集中式网关瓶颈。
- 网关近端部署:
- 在跨云边界节点(如专线接入点)部署VTEP,减少公网段跳数。
- 分布式网关:
-
混合Underlay/Overlay方案
- 核心业务用Underlay:
- 数据库等低延迟服务直通物理网络(如IPVLAN)。
- 边缘业务用Overlay:
- 通过逻辑路由器连接不同网络平面,避免NAT转换。
- 核心业务用Underlay:
6.4.6、跨云场景专项优化
⚠️ 注意事项
- 安全与兼容性:
- 公有云安全组需放行VXLAN UDP 4789端口(或Geneve 6081端口)。
- 监控与诊断:
- 使用
tcpdump抓取VXLAN流量(过滤词:udp port 4789),结合Grafana监控封装效率指标。
- 使用
生产建议:金融等低延迟场景优先采用 STT+智能网卡卸载,通用业务用 VXLAN+硬件加速,并结合SDN实现跨云流量智能调度。
6.5 STT(Stateless Transport Tunneling)和VXLAN(Virtual Extensible LAN)
STT(Stateless Transport Tunneling)和VXLAN(Virtual Extensible LAN)作为Overlay网络的核心隧道协议,在硬件加速实现上存在显著差异。这些差异源于协议设计、封装格式及与硬件协同工作的机制,具体对比如下:
1. 协议封装与硬件卸载机制
STT:无状态TCP封装 + TSO/LRO卸载
- 封装特性:
STT采用类TCP头部(TCP-like Header),模拟TCP结构但无连接状态(无需三次握手),内层封装原始以太网帧(MAC-in-TCP)。 - 硬件加速核心:
- TSO(TCP Segmentation Offload):网卡将大包(如9000字节)自动分片为MTU大小(如1500字节),复制外层IP/TCP头,显著降低CPU封装开销。
- LRO(Large Receive Offload):接收端网卡合并分片包,减少中断次数。
- 优势:适用于大数据传输(如跨云备份),吞吐量提升30%+,CPU开销降低40%。
VXLAN:UDP封装 + 隧道专用引擎
- 封装特性:
标准MAC-in-UDP封装(50字节头部:外层MAC+IP+UDP+VXLAN头),依赖UDP端口(默认4789)标识隧道。 - 硬件加速核心:
- 隧道卸载引擎:智能网卡(如NVIDIA ConnectX)直接处理VXLAN封装/解封装,跳过内核协议栈。
- 校验和卸载:网卡计算外层IP/UDP校验和,避免CPU计算。
- 优势:延迟可降至5μs以下,适合高频小包场景(如API网关)。
2. 负载均衡与流表处理
STT:L4流哈希 + 无状态分流
- 实现方式:
源端口号由内层数据包(MAC/IP/L4端口)哈希生成,使网卡能将同一数据流均匀分发到多路径。 - 硬件支持:
依赖网卡流分类引擎识别哈希值,支持ECMP(等价多路径)负载均衡,但需物理网络设备兼容无状态分流。
VXLAN:UDP源端口随机化 + 流表匹配
- 实现方式:
UDP源端口随机生成,物理交换机基于五元组(IP+端口)哈希实现ECMP。 - 硬件支持:
主流交换机(如Arista 7050)内置VXLAN流表,直接解析外层头做负载均衡,无需修改数据包。
3. 硬件兼容性与限制
4. 性能优化场景对比
总结与选型建议
-
STT适用场景:
- 私有云/金融交易系统:需高吞吐、低CPU开销(如数据库同步)。
- 限制:物理网络需支持巨帧,且避开状态防火墙。
-
VXLAN适用场景:
- 公有云/混合云:协议标准化高,兼容安全组和负载均衡器。
- 容器化微服务:智能网卡加速下延迟敏感型业务(如实时计算)。
-
混合部署方案:
- 核心业务用STT+智能网卡(如RDMA over STT),边缘业务用VXLAN硬件卸载,通过SDN控制器统一调度。
注:STT的标准化程度低于VXLAN(IETF标准),长期维护建议优先VXLAN;若追求极致性能且可控底层设施,可选用STT优化特定流量。
6.6 STT硬件支持
STT(Stateless Transport Tunneling)协议对TSO(TCP Segmentation Offload)和LRO(Large Receive Offload)卸载的支持依赖于网卡硬件的具体型号和驱动实现。以下是目前已知支持STT卸载功能的主流网卡型号及其技术细节:
6.6.1、NVIDIA/Mellanox系列
-
ConnectX-5 及以上型号
- 支持特性:
- 通过 FlexParser™ 技术 解析STT头部,实现TSO卸载。
- 支持 LRO/GRO卸载,合并接收方向的STT封装流量。
- 典型型号:
- ConnectX-5(MCX556A-ECAT)、ConnectX-6 DX(MCX623106AN-CDAT)
- BlueField-2 DPU(集成ConnectX-6 Dx核心)
- 支持特性:
-
配置要求:
- 需启用VXLAN硬件卸载(STT复用相同路径):
ethtool -K eth0 tx-udp_tnl-segmentation on # 开启隧道封装卸载mlxconfig -d mlx5_0 set VXLAN_ENABLE=1 # 启用VXLAN加速(兼容STT)
- 需启用VXLAN硬件卸载(STT复用相同路径):
6.6.2、Intel系列
-
Ethernet 800系列(如E810-XXVDA4T)
- 支持特性:
- 通过 ADQ(Application Device Queues) 技术实现STT的TSO卸载。
- 支持 LRO,但需内核≥5.10且启用
iavf驱动的STT_RX_OFFLOAD标志。
- 限制:
- 仅支持Linux内核≥5.12,且需安装最新版
ice驱动。
- 仅支持Linux内核≥5.12,且需安装最新版
- 支持特性:
-
旧型号(如X710、XXV710)
- 部分支持:
- TSO卸载需开启
ethtool -K eth0 tso on,但STT封装需依赖软件GSO。
- TSO卸载需开启
- 部分支持:
6.6.3、Broadcom系列
- NetXtreme-E(如BNXT)
- 支持型号:
- BCM58800(StrataGX2)、BCM57508(用于主流服务器)
- 特性:
- 通过 TruFlow™ 技术 解析STT头部,支持TSO卸载。
- LRO需启用
ethtool -K eth0 lro on,且需配置VXLAN隧道类型为stt。
- 支持型号:
6.6.4、关键限制与注意事项
-
驱动与内核依赖:
- STT非标准协议,需定制化驱动支持(如VMware ESXi的
vmxnet3驱动或Linux的mlx5_core)。 - Linux内核≥4.15才支持STT的GRO合并(需启用
NETIF_F_GRO_FRAGLIST)。
- STT非标准协议,需定制化驱动支持(如VMware ESXi的
-
虚拟化环境要求:
- 在VMware NSX中部署时,物理网卡需开启SR-IOV并绑定支持STT的PF/VF驱动。
-
验证命令:
ethtool -k eth0 | grep -E \'tcp-segmentation-offload|udp-fragmentation-offload\' # 输出\"tx-tcp-segmentation: on\"表示TSO激活
总结
- 优先选择:NVIDIA ConnectX-6 DX、Intel E810 或 Broadcom BCM57508 等支持可编程管道的智能网卡。
- 避坑建议:
- 公有云环境(如AWS)普遍不支持STT,因安全组限制UDP随机端口。
- 自建集群需确保网卡固件更新至最新版(如Mellanox固件≥14.32)。
注:具体支持列表需参考厂商文档(如NVIDIA DOCA支持矩阵)。测试性能时建议对比
ethtool -S的tx_tso_packets计数。
6.7 Kubernetes 主流网络插件(Calico、Cilium、Flannel
Kubernetes 主流网络插件(Calico、Cilium、Flannel)及云厂商插件(阿里云、腾讯云)的综合对比分析,涵盖实现差异、底层算法、组网模式、多容器互通及微服务集成方案
6.7.1、核心实现差异与底层算法
1. 数据平面与控制平面
2. 关键组件对比
flanneld(节点代理)Felix(策略执行)、BIRD(BGP 路由分发)Cilium Agent(eBPF 程序管理)6.7.2、组网模式与多容器互通方案
1. 组网模式
2. 多容器互通实现
- Flannel:
所有节点加入同一个 Overlay 网络,Pod 通过 VXLAN 隧道跨节点通信,ARP 表由flanneld维护 。 - Calico:
- BGP 模式:节点作为路由器,通过 BGP 协议广播 Pod IP 路由,流量直接路由(无封装)。
- IPIP 模式:跨子网时封装原始 IP 包,性能损耗约 8% 。
- Cilium:
- eBPF Host-Routing:绕过 iptables,通过 eBPF 程序直接转发,延迟低至 0.3ms 。
- Cluster Mesh:多集群 Pod IP 互通通过 eBPF 隧道实现 。
- 云厂商插件:
- 阿里云 Terway:Pod 直接分配 VPC IP,通过弹性网卡(ENI)实现跨节点直通 。
- 腾讯云 Global Router:默认 VPC 路由,Overlay 仅作备份,避免路由表规模爆炸 。
6.7.3、微服务与 Service Mesh 集成方案
1. 服务发现与负载均衡
2. Service Mesh 数据平面优化
- Cilium:
通过 eBPF 实现 Sidecar-less Service Mesh,HTTP 策略直接注入内核(如拦截特定 API 路径):apiVersion: cilium.io/v2kind: CiliumNetworkPolicyspec: endpointSelector: {matchLabels: app: payment} ingress: - fromEndpoints: [{matchLabels: app: frontend}] toPorts: - ports: [{port: \"80\", protocol: TCP}] rules: http: [{method: \"POST\", path: \"/api/v1/charge\"}] - Calico + Istio:
仅提供 L3-L4 策略,L7 治理依赖 Envoy Sidecar,增加延迟约 1ms 9。 - 云厂商方案:
阿里云 ASM、腾讯云 TCM 均依赖 Sidecar 注入,但通过 VPC 网络降低 Node 间延迟 1,2。
6.7.4、性能与适用场景对比
关键性能指标(10Gbps 环境)
场景化选型建议
- 中小集群/开发环境:
Flannel - 简单易用,资源消耗低 。 - 企业生产/混合云:
Calico - BGP 支持跨机房路由,策略能力均衡 。 - 高性能/安全敏感型:
Cilium - eBPF 实现零信任网络与微服务治理 。 - 公有云环境:
云厂商插件 - 深度集成 VPC,避免 Overlay 开销(如阿里云 Terway)。
💎 总结
- 技术趋势:eBPF 正取代 iptables 成为高性能网络插件核心(Cilium 领先)。
- 云原生适配:云厂商通过 VPC 直通 + 智能网卡卸载平衡性能与兼容性 。
- Service Mesh 演进:Cilium 的 Sidecar-less 模式可能颠覆传统 Mesh 架构 。
生产环境部署建议:
- 自建集群优先 Cilium(内核 ≥ 5.10)
- 公有云集群选择 Terway/Global Router + 托管 Mesh 服务
- 混合云场景用 Calico BGP 统一路由策略
6.8 Service Mesh的cillum
在Service Mesh场景下,Cilium通过eBPF技术内核层实现网络功能,彻底重构了传统Sidecar代理模式,实现高性能、低延迟的服务网格能力。其核心原理与优势如下:
6.8.1、Cilium替代Sidecar的核心机制
-
内核级数据平面(eBPF驱动)
- 无代理流量拦截:传统Sidecar(如Envoy)需通过iptables/IPVS拦截Pod流量,再转发至Sidecar代理处理,增加2次额外连接(Pod ↔ Sidecar)。Cilium则通过eBPF程序在内核层直接处理L3-L7流量,实现零拷贝转发,连接路径简化为Pod → 内核eBPF程序 → 目标Pod。
- 动态策略注入:安全策略(如L7 HTTP路由)编译为eBPF字节码注入内核,策略执行无需用户态切换。例如,HTTP请求的
POST /api校验在内核完成,延迟仅增加0.1ms。
-
Per-Node代理模型(替代Per-Pod Sidecar)
- 共享Envoy实例:Cilium在每节点部署单Envoy DaemonSet,处理需L7代理的功能(如TLS终止、gRPC转换)。eBPF程序将流量从Pod直通节点Envoy,避免每个Pod独立Sidecar的资源浪费。
- 多租户隔离:通过Envoy的
Listener Namespace实现配置隔离,确保不同租户策略互不影响。
6.8.。2、性能优势对比(实测数据)
6.8.3、关键技术实现
-
eBPF L7协议解析
- 支持HTTP/2、gRPC、Kafka等协议深度解析,例如自动提取HTTP路径和Header,实现基于API路径的负载均衡(如
/serviceA路由至v1版本)。 - 结合Hubble实现分布式追踪:eBPF捕获请求链路数据,直接输出OpenTelemetry格式,与Jaeger无缝集成。
- 支持HTTP/2、gRPC、Kafka等协议深度解析,例如自动提取HTTP路径和Header,实现基于API路径的负载均衡(如
-
动态负载均衡与韧性能力
- Maglev一致性哈希:eBPF实现连接级会话保持,后端实例变化时影响面降低至1/N(N为后端数)。
- 内核层熔断与重试:监测服务响应状态码(如5xx),自动触发重试或切换后端,无需Sidecar介入。
-
安全策略融合
- 零信任网络模型:基于身份(Pod标签)的L3-L4策略 + L7 HTTP方法限制(如
role=frontend仅允许GET /api)。 - 透明加密:通过IPsec或WireGuard实现节点间流量自动加密,吞吐损失<5%。
- 零信任网络模型:基于身份(Pod标签)的L3-L4策略 + L7 HTTP方法限制(如
6.8.4、与Dapr等运行时集成(无Sidecar服务网格扩展)
-
Dapr共享模式:
- Dapr运行时以DaemonSet/Deployment形式部署(非Sidecar),Cilium eBPF程序将服务调用请求直通Dapr实例,处理Pub/Sub、状态存储等高级功能。
- 优势:函数计算(FaaS)等短生命周期场景中,解耦Dapr与应用生命周期,避免频繁Sidecar启停开销。
-
流量治理协同:
- Cilium处理东西流量:服务发现、负载均衡、熔断由eBPF完成。
- Dapr处理应用层语义:如分布式事务(Saga模式)、Actor模型支持。
# Dapr共享实例部署示例(DaemonSet)helm install ingress-shared dapr/dapr-shared-chart --set strategy=daemonset
6.8.5、适用场景与限制
总结:技术选型建议
- 替代条件成熟:当集群满足内核≥5.10、需极致性能或万级Pod规模时,优先选用Cilium无Sidecar方案。
- 混合架构过渡:遗留系统可逐步迁移——关键服务用Cilium,传统微服务保留Sidecar,通过Cilium Gateway API统一入口。
- 未来演进:Cilium + Dapr共享模式代表了下一代Service Mesh方向——内核加速基础功能,应用运行时处理业务语义,实现性能与功能平衡。
部署命令示例:
# 启用Cilium Service Meshcilium install --set serviceMesh.enabled=true# 部署Dapr共享运行时helm install dapr-shared dapr/dapr-shared-chart
6.9 Cilium 利用 eBPF 技术在内核层直接解析 HTTP/gRPC 协议
Cilium 利用 eBPF 技术在内核层直接解析 HTTP/gRPC 协议,通过特定的内核钩子(hooks)和数据结构实现高性能、低延迟的应用层协议处理。以下是其核心机制详解:
6.9.1、关键内核钩子(Hooks)
Cilium 的 eBPF 程序通过以下钩子嵌入内核网络栈,实现协议解析:
-
**
BPF_PROG_TYPE_SOCK_OPS(套接字操作钩子)**- 作用位置:监控 TCP 连接状态(如
ESTABLISHED事件)。 - 功能:
- 在 TCP 连接建立时触发 eBPF 程序,提取 TCP 五元组(源/目标 IP、端口、协议)。
- 关联连接与应用层协议(如 HTTP/gRPC)的映射关系,存储到
BPF_MAP_TYPE_SOCKHASH。
- 作用位置:监控 TCP 连接状态(如
-
**
BPF_PROG_TYPE_SK_SKB(Socket 数据包钩子)**- 作用位置:附加到套接字缓冲区(sk_buff),在数据进出用户空间前拦截。
- 功能:
- 解析 TCP Payload,识别 HTTP 方法(GET/POST)或 gRPC 的 Magic 字节(
0x0D 0x0E 0x0A 0x0D)。 - 支持重定向流量到同节点 Envoy 代理(需 L7 策略时),或直接在内核处理。
- 解析 TCP Payload,识别 HTTP 方法(GET/POST)或 gRPC 的 Magic 字节(
-
**
BPF_PROG_TYPE_CGROUP_SKB(Cgroup 网络钩子)**- 作用位置:附加到容器的 Cgroup,监控进出容器的流量。
- 功能:
- 执行 L4 负载均衡 和 L7 协议过滤(如允许
GET /api但拒绝POST /private)。
- 执行 L4 负载均衡 和 L7 协议过滤(如允许
-
TC(Traffic Control)Ingress/Egress 钩子
- 作用位置:网络接口的流量控制层(L2/L3 之间)。
- 功能:
- 在 veth 对的主机端捕获容器流量,提取 IP 和 TCP 头。
- 与 Socket 层协作,传递连接上下文到应用层解析程序。
6.9.2、核心数据结构
eBPF 程序通过以下数据结构存储协议元数据和策略:
-
**
struct bpf_sock_ops**- 存储 TCP 连接状态(如
op字段标识事件类型),用于关联连接与协议。 - 关键字段:
__u32 op; // 事件类型(如 TCP_ESTABLISHED)__u32 family; // 协议族(AF_INET/AF_INET6)__u32 remote_ip4; // 对端 IPv4 地址__u32 local_port; // 本地端口
- 存储 TCP 连接状态(如
-
**
struct sk_msg_md**- 描述 Socket 消息的元数据,用于解析 HTTP/gRPC 负载。
- 关键字段:
__u64 data; // 数据包起始指针__u64 data_end; // 数据包结束指针__u32 sk; // 关联的 socket 指针
-
BPF Map(映射结构)
- **
BPF_MAP_TYPE_SOCKHASH**:存储 TCP 连接与后端服务的映射,支持 Maglev 一致性哈希负载均衡1,7。 - **
BPF_MAP_TYPE_PROG_ARRAY**:链式调用不同协议的处理程序(如 HTTP 解析后触发 gRPC 处理)7。 - **
BPF_MAP_TYPE_LPM_TRIE**:高效匹配 CIDR 规则(如策略允许的 IP 范围)。
- **
6.9.3、协议解析流程
以 HTTP/gRPC 请求为例:
- 连接建立:
- TCP 状态变为
ESTABLISHED时,BPF_PROG_TYPE_SOCK_OPS提取五元组,存入BPF_MAP_TYPE_SOCKHASH6。
- TCP 状态变为
- 数据拦截:
- 数据包到达 Socket 层时,
BPF_PROG_TYPE_SK_SKB检查 TCP Payload:- HTTP:匹配
GET/POST等关键字,提取 Path 和 Host 头1。 - gRPC:识别 Magic 字节,解析 Length-Prefixed-Message 结构(长度+数据)。
- HTTP:匹配
- 数据包到达 Socket 层时,
- 策略执行:
- 根据
CiliumNetworkPolicy的 L7 规则(如http.method=GET)决定放行或丢弃。
- 根据
- 流量重定向(可选):
- 复杂策略(如 JWT 验证)需重定向到 Envoy,通过
bpf_redirect()函数直通同节点代理。
- 复杂策略(如 JWT 验证)需重定向到 Envoy,通过
6.9.4、性能优势
- 零拷贝解析:eBPF 直接访问内核 Socket 缓冲区,避免数据复制到用户空间。
- 协议加速:
- HTTP/gRPC 解析延迟 <1μs,而 Sidecar 代理模式需 **>50μs**。
- 实测吞吐量提升 80%(10K RPS 时 CPU 占用从 22% 降至 0.5%)。
- 动态加载:策略更新时热替换 eBPF 程序,无连接中断。
限制与要求
- 内核版本:
- HTTP 解析需 ≥5.7,gRPC 解析需 ≥5.10(依赖
bpf_skb_load_bytes增强)。
- HTTP 解析需 ≥5.7,gRPC 解析需 ≥5.10(依赖
- 协议覆盖:
- 完整 gRPC 支持需启用 TLS 终止(内核暂无法解析加密负载)。
- 复杂性:
- 自定义协议(如私有 RPC)需手动扩展 eBPF 解析逻辑。
总结
Cilium 通过 eBPF 在内核的 Socket 层和 TC 层钩子拦截流量,结合 bpf_sock_ops 等结构提取协议元数据,实现 HTTP/gRPC 的零拷贝解析。其核心在于:
- 动态协议识别:基于 TCP Payload 特征匹配,无需应用修改。
- 高效策略执行:L7 规则编译为 eBPF 字节码,在内核直接过滤。
- 与 Sidecar 协同:复杂场景流量重定向至 Envoy,平衡性能与功。
部署建议:生产环境优先使用 ≥5.10 内核,并启用
Cilium L7 Policy模式以释放完整能力。
七、容器网络kubeovn
7.1 Kube-OVN 网络的核心机制
以下为 Kube-OVN 网络的核心机制、实现方案、配置模式及算法解析,结合其架构设计、数据流控和功能实现进行系统性说明:
7.1.1、架构设计与核心组件
1. 控制平面
- kube-ovn-controller
- 功能:监听 Kubernetes 资源(Pod/Node/Service/NetworkPolicy),将资源状态转化为 OVN 北向数据库(ovn-nb)的逻辑网络配置(如逻辑交换机/路由器)。
- 实现:通过内存 IPAM 分配 IP,并将结果写入 Pod Annotation(如
kubeovn.kube-ovn.io/ip_address),供 CNI 插件读取。
- ovn-central
- 组件:
ovn-nb:存储虚拟网络配置(子网/ACL)。ovn-sb:存储逻辑流表及物理节点状态。ovn-northd:将ovn-nb配置翻译为ovn-sb流表。
- 高可用:多实例通过 Raft 协议同步数据。
- 组件:
2. 数据平面
- kube-ovn-cni
- 作用:响应 CNI 请求,根据 Pod Annotation 配置本地 OVS 和容器网卡(创建 veth pair、绑定 OVS 端口)。
- 流程:
kubelet→kube-ovn-cni→kube-ovn-cniserver(配置 OVS)。
- ovs-ovn
- 组件:
ovn-controller:将ovn-sb流表转换为 OVS 流表。ovs-vswitchd:执行数据包转发。ovsdb-server:管理本地 OVS 配置。
- 组件:
7.1.2、网络模型与数据转发
1. 网络模式对比
--network-type=geneve--network-type=underlay--provider-network=vlan2. 数据流路径
- 同节点 Pod 通信:
OVS 根据流表在br-int网桥内二层转发,无需隧道封装。 - 跨节点 Pod 通信(Overlay):
- 源 Pod → OVS(Geneve 封装)→ 物理网卡 → 目标节点网卡 → OVS(解封装)→ 目标 Pod。
- 隧道优化:支持 DPDK 硬件卸载,降低 CPU 开销。
- 外部网络访问:
- 分布式网关:各节点通过
ovn0网卡 NAT 出流量(默认模式)。 - 集中式网关:流量转发至特定网关节点处理,适合审计需求。
- 分布式网关:各节点通过
7.1.3、关键功能实现方案
1. 子网管理
- 模型:每个 Namespace 对应一个逻辑交换机(子网),支持跨节点 IP 分配。
- 配置:通过 Subnet CRD 定义 CIDR/网关/保留 IP:
apiVersion: kubeovn.io/v1kind: Subnetmetadata: name: vm-subnetspec: cidr: 10.16.0.0/16 gateway: 10.16.0.1 excludeIps: [\"10.16.0.1..10.16.0.10\"] gatewayType: distributed
2. IPAM 机制
- 动态分配:OVN 内置
dynamic addresses自动分配 IP/MAC5。 - 静态分配:通过 Annotation
kubeovn.kube-ovn.io/ip_pool指定 IP 池,Controller 跳过动态分配。 - KubeVirt 固定 IP:VM 启停时复用原 IP(需启用
--keep-vm-ip=true)。
3. 服务质量(QoS)
- 实现:基于 OVS 的
ingress_policing_rate和端口 QoS(因 OVN QoS 同节点流量控制存在缺陷)。 - 配置:
annotations: kubeovn.io/ingress_rate: \"10M\" # 入口带宽限制 kubeovn.io/egress_rate: \"20M\" # 出口带宽限制
4. 负载均衡与网络策略
- Service 代理:
- 默认用 OVN L2 LB 替代
kube-proxy,支持 IP Hash 会话保持。 - 关闭 LB:设置
--enable-lb=false,回退至kube-proxy。
- 默认用 OVN L2 LB 替代
- NetworkPolicy:
- 通过 OVN ACL 实现,支持基于 IP/端口的规则。
- 关闭 ACL:设置
--enable-np=false,改用 Cilium eBPF 实现。
7.1.4、配置模式与调优实践
1. 安装参数调优
POD_CIDR10.16.0.0/16JOIN_CIDR100.64.0.0/16SVC_CIDR10.96.0.0/12ENABLE_SSLtrueTUNNEL_TYPEvxlan(默认 geneve)2. 性能优化
- 硬件卸载:启用 DPDK 或 SmartNIC 加速 OVS 流表处理。
- MTU 调整:
- Overlay 模式:Pod MTU = 物理网卡 MTU - 封装开销(默认减 100)。
- 配置:
kube-ovn-cni设置--mtu=1500。
- 隧道协议选择:
- Geneve:灵活扩展头(推荐)。
- STT:无 UDP 校验和,适合高速网络(需内核模块支持)。
7.1.5、算法与高级特性
1. 路由算法
- 逻辑集中式路由:
- 所有逻辑交换机连接至全局路由器
ovn-cluster-router,流表分布式下发至各节点。 - 跨子网通信:通过逻辑路由器策略路由实现。
- 所有逻辑交换机连接至全局路由器
2. 高可用机制
- OVN DB 高可用:
ovn-central多实例 Raft 选主,数据持久化至 etcd。
- 网关故障切换:
- 集中式网关结合 Keepalived 实现 VIP 漂移。
3. 可观测性
- 流量镜像:
- OVS 复制流量至
mirror0网卡,通过tcpdump -i mirror0抓包。
- OVS 复制流量至
- 监控集成:
kube-ovn-pinger检测节点间延迟/丢包。- Prometheus 收集 OVS 流表统计、隧道状态等指标。
7.1.6、总结与场景推荐
- 优势场景:
- 企业级网络:需子网隔离、静态 IP、QoS 等高级功能。
- 混合云:Overlay 模式简化跨网络部署。
- KubeVirt 集成:VM 固定 IP 和 VLAN 直通。
- 局限与规避:
- 性能瓶颈:OVS 流表查询可能成为瓶颈 → 启用 DPDK 卸载。
- 复杂性:OVN 控制面较重 → 中小集群可关闭非必需功能(如 LB/ACL)。
注:生产环境建议结合 kubectl-ko 插件进行流表诊断(如
kubectl ko trace追踪报文路径)。
7.2 Kube-OVN 的 Overlay 和 Underlay 模式
Kube-OVN 的 Overlay 和 Underlay 模式在性能上存在显著差异,主要体现在网络延迟、吞吐量、CPU 开销及适用场景等方面。以下是具体对比分析:
7.2.1、性能核心指标对比
7.2.2、性能差异的底层机制
1. Overlay 的性能瓶颈
- 封装开销
Geneve/VXLAN 头部增加 50 字节,导致 MTU 需调整至 1550+,大包分片进一步降低吞吐。 - 协议限制
UDP 封装使网卡无法启用 TCP 卸载(如 TSO/GSO),需 CPU 处理全部封包逻辑。 - 流表处理
OVS 流表匹配消耗 CPU(约 10%),需编译优化(启用popcnt/sse4.2指令集可降至 5%)。
2. Underlay 的性能优势
- 零封装
数据包直接通过 OVS 桥接物理网卡,无额外头部开销。 - 硬件加速
支持网卡卸载(如 SmartNIC),将流表匹配、隧道处理卸载至硬件,性能媲美物理网络。 - 内核路径短
绕过 netfilter,减少内核态处理环节(对比 Macvlan 仍需 OVS 流表,但路径更简洁)。
7.2.3、性能优化策略
Overlay 模式优化
- 协议选择
- STT 隧道:模拟 TCP 头部,启用网卡卸载,TCP 吞吐量提升 3 倍(需手动编译 OVS 内核模块)。
- 命令:
kubectl set env daemonset/ovs-ovn -n kube-system TUNNEL_TYPE=stt
- 内核加速
- FastPath 模块:绕过 netfilter,降低 20% CPU 开销(禁用 iptables/IPVS 场景)。
- OVS 指令集优化:启用
-mpopcnt -msse4.2编译选项,流表处理效率提升 50%。
- 硬件卸载
- DPDK/SmartNIC:将封装/流表卸载至智能网卡,延迟降至 <5μs。
Underlay 模式优化
- 队列调优
- 增大网卡缓冲队列:
ethtool -G eth0 rx 4096 tx 4096,减少丢包率。
- 增大网卡缓冲队列:
- 中断绑定
- 禁用 irqbalance,绑定网卡中断到专用 CPU 核,减少上下文切换。
7.2.4、关键限制与规避
7.2.5、生产场景建议
- 优先 Underlay
同机房数据库集群(如 MySQL、Redis),要求延迟 <100μs 时,启用网卡卸载和队列优化。 - 优选 Overlay
跨云微服务架构(如 Istio 网格),通过 STT 隧道 + DPDK 提升吞吐,并通过分布式网关实现跨子网互通3。 - 混合部署
核心中间件(Kafka)用 Underlay 保证性能,Web 服务用 Overlay 实现灵活扩缩容1。
注:实际性能受硬件(网卡/CPU)、内核版本及优化措施影响显著。

