初识卷积神经网络CNN
卷积神经网络CNN
全连接神经网络存在的问题:
- 输入的形式应该是列向量,但是卷积神经网络中的输入是图像(2D矩阵),那么就需要对图片进行展平处理,原本图像中蕴含的空间等信息就被打乱了
- 输入的特征多了,那么神经元的参数就会很多,层的结构就很复杂,容易过拟合
通道数
通道数 是指图像或特征图在深度方向上的维度数量(可以类比全连接神经网络中的特征矩阵的x_i的特征数)
例如:
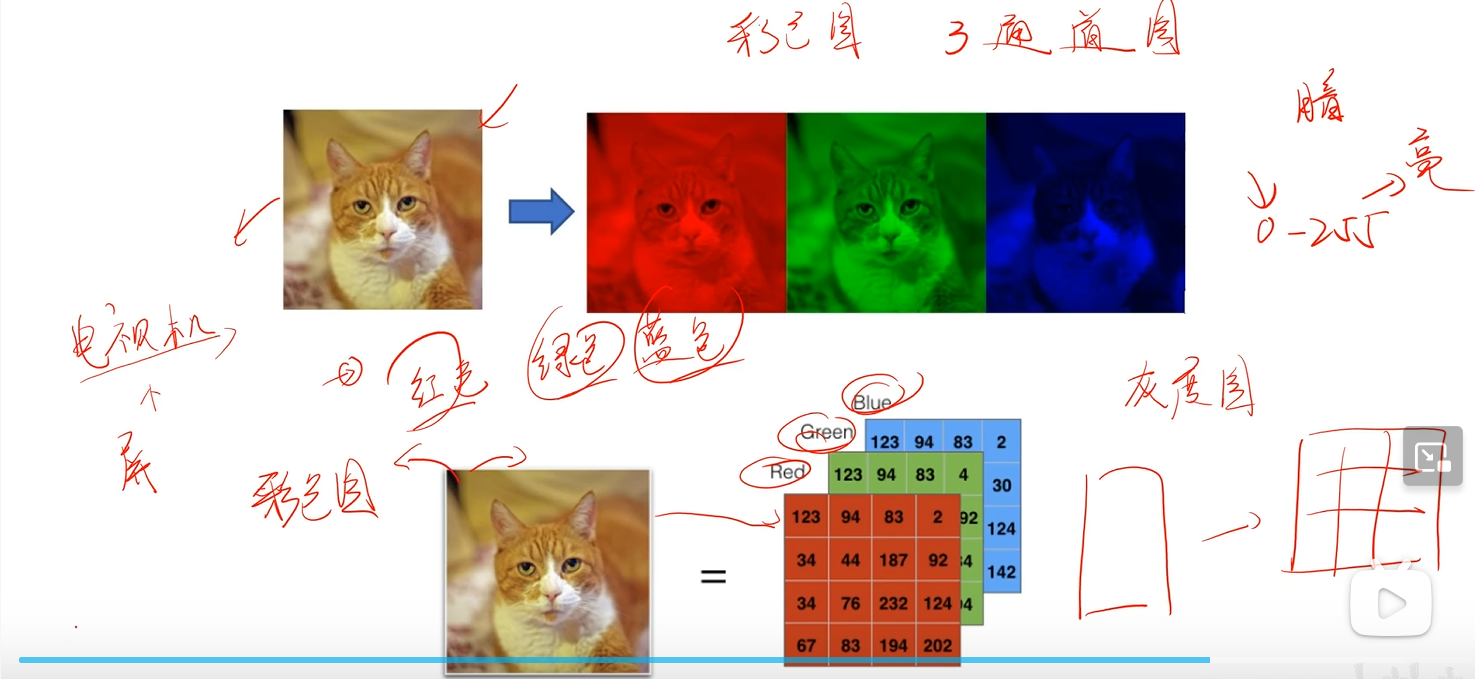
- 灰度图只有一个通道(特征):亮度
- RGB图像:3个通道(红,绿,蓝)
- RGBA图像:4个通道(红,绿,蓝,透明度)
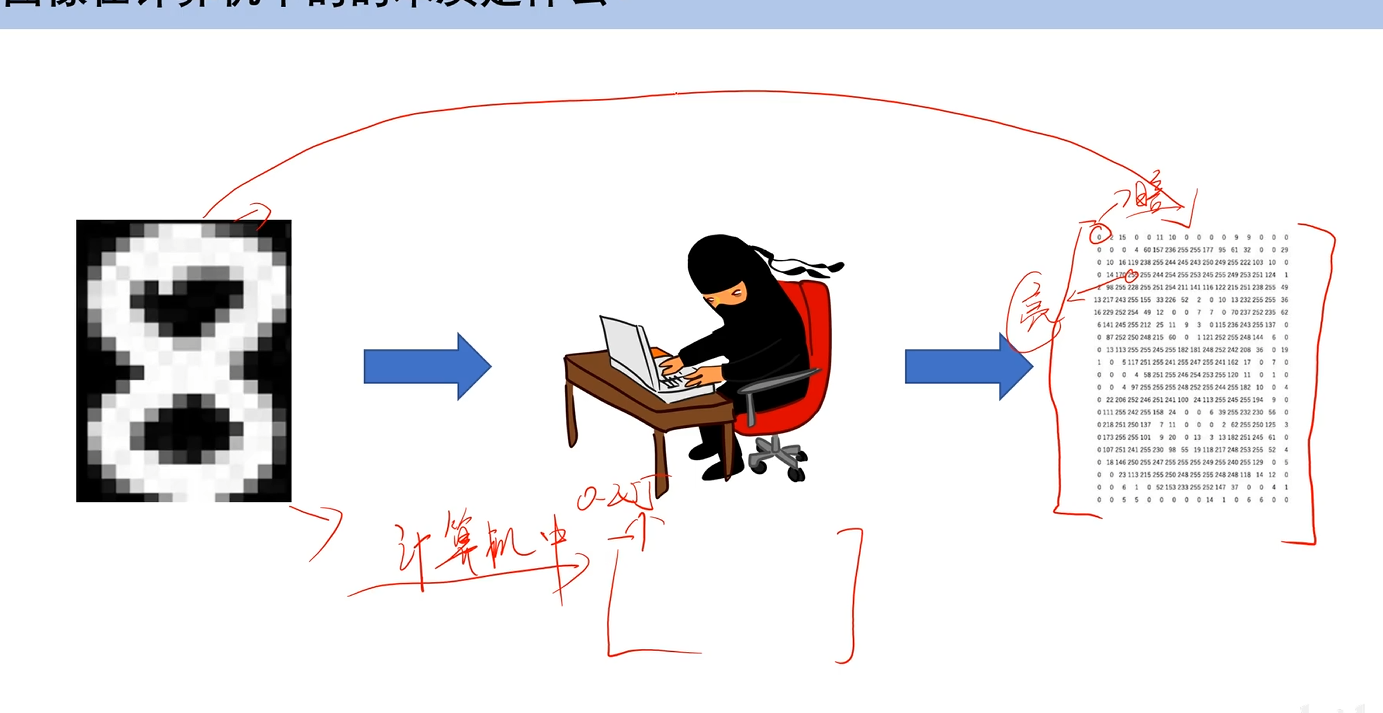
图像在计算机中的本质
一个大的数值矩阵,每个元素代表像素的亮度或颜色
对于灰度图(只有黑白两色):255表示亮白,0表示黑,只有一个通道
对于彩色图像
三通道图
整体结构
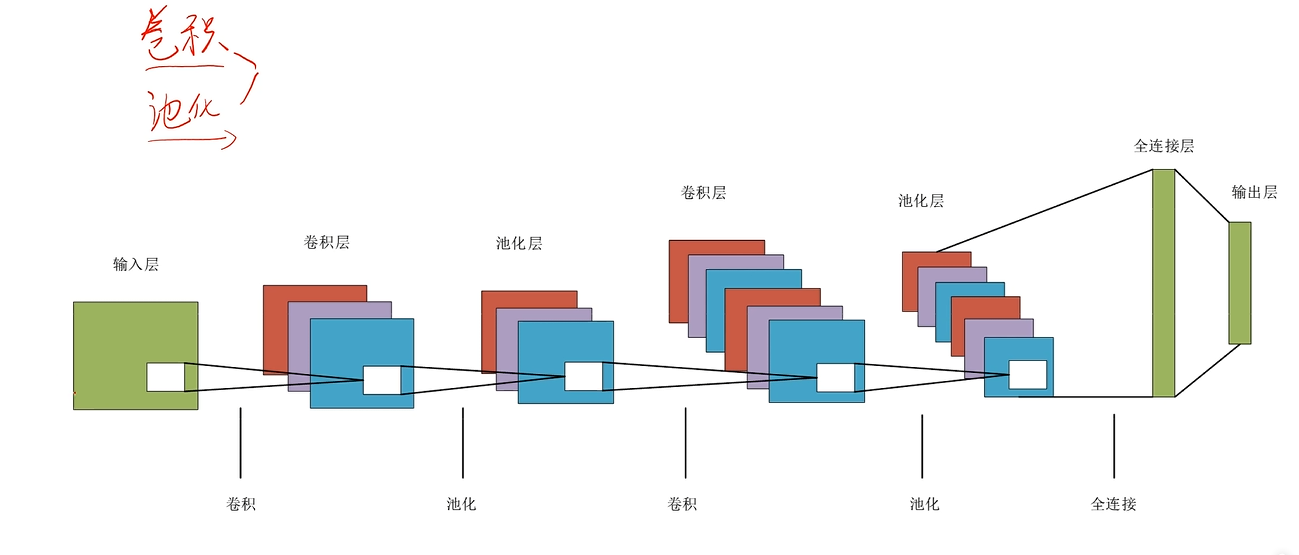
卷积层
还是与手写数字为例;在密集层中,每个神经元都可以获取到整个的像素矩阵;而在卷积层中,我们让神经元只能获取到一部分像素而不是全部,这个特性被称为局部感知
局部感知的优点
- 计算更快(输入的矩阵更小,那么对于神经元来说,参数的数量大大减小)
- 需要更少的训练数据,更不容易过拟合(参数减少,模型复杂度降低,就不容易过拟合)
卷积层会改变通道的数目,在前一层的输入提取出不同的特征,同时会改变图片的长和宽
卷积核/滤波器
定义:一个在图像上滑动的小窗口,它与图像的局部区域进行点积运算,从而提取出该区域的特征。其实可以类比全连接神经网络的参数w,只不过它是共享的
卷积核是一个4D张量,形状为(C_out,C_in,K,K)
- C_out:输出通道数/卷积核数量
- C_in:输入通道数
- K:卷积核大小(K×K)
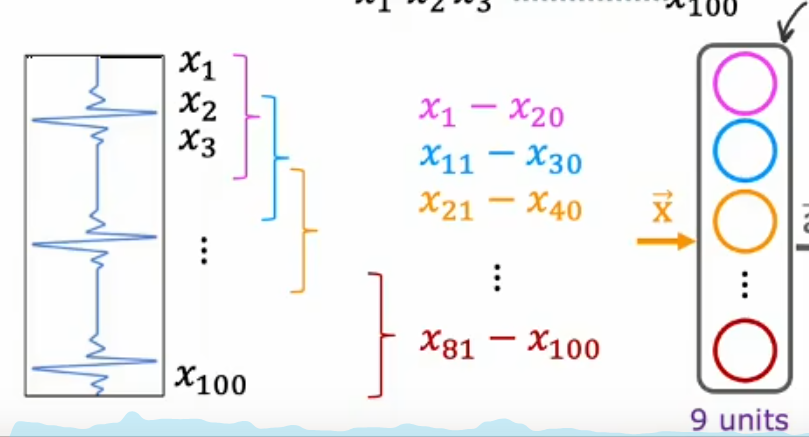
案例:心电图信号分类
池化层
池化层可以改变图像的大小,但不改变通道数
卷积运算
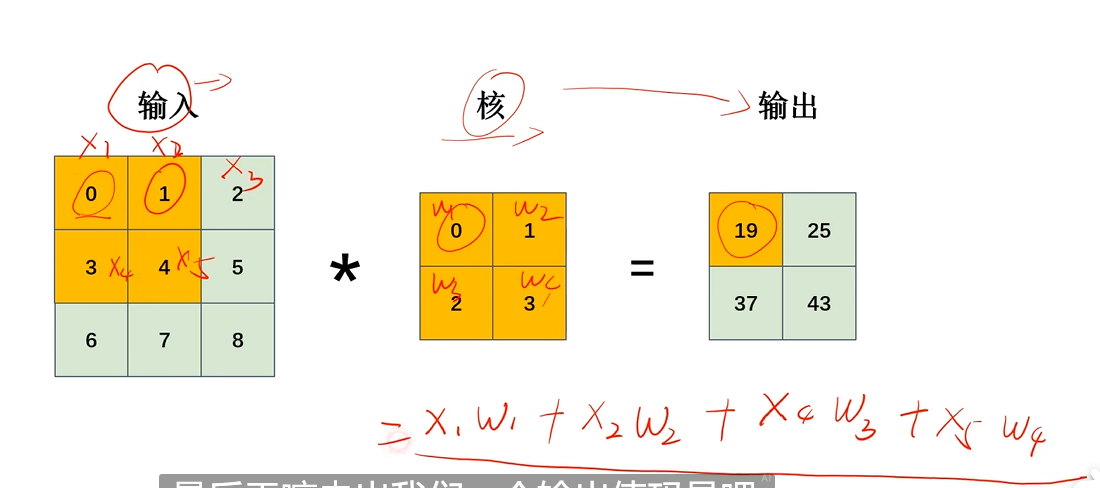
对应位置相乘再相加
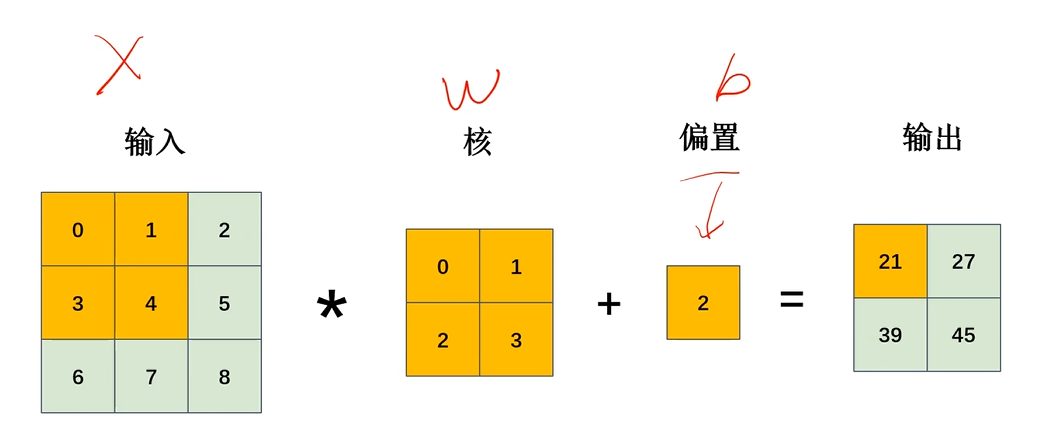
带偏置的计算过程
权重共享
对于全连接神经网络,输入中的每个特征都对应着一个神经元中的一个参数
而对于卷积神经网络并非这样
卷积神经网络中,是同一个卷积核在整个输入图像上滑动,对所有局部区域使用相同权重参数
- 卷积核的参数在整个图像上是共享的
- 不同位置的局部区域都使用这个相同的卷积核做卷积操作
- 每个位置的输出是该卷积核与对应局部区域的点积结果
填充
为了控制卷积后输出的特征图尺寸;在输入特征图周围填充0
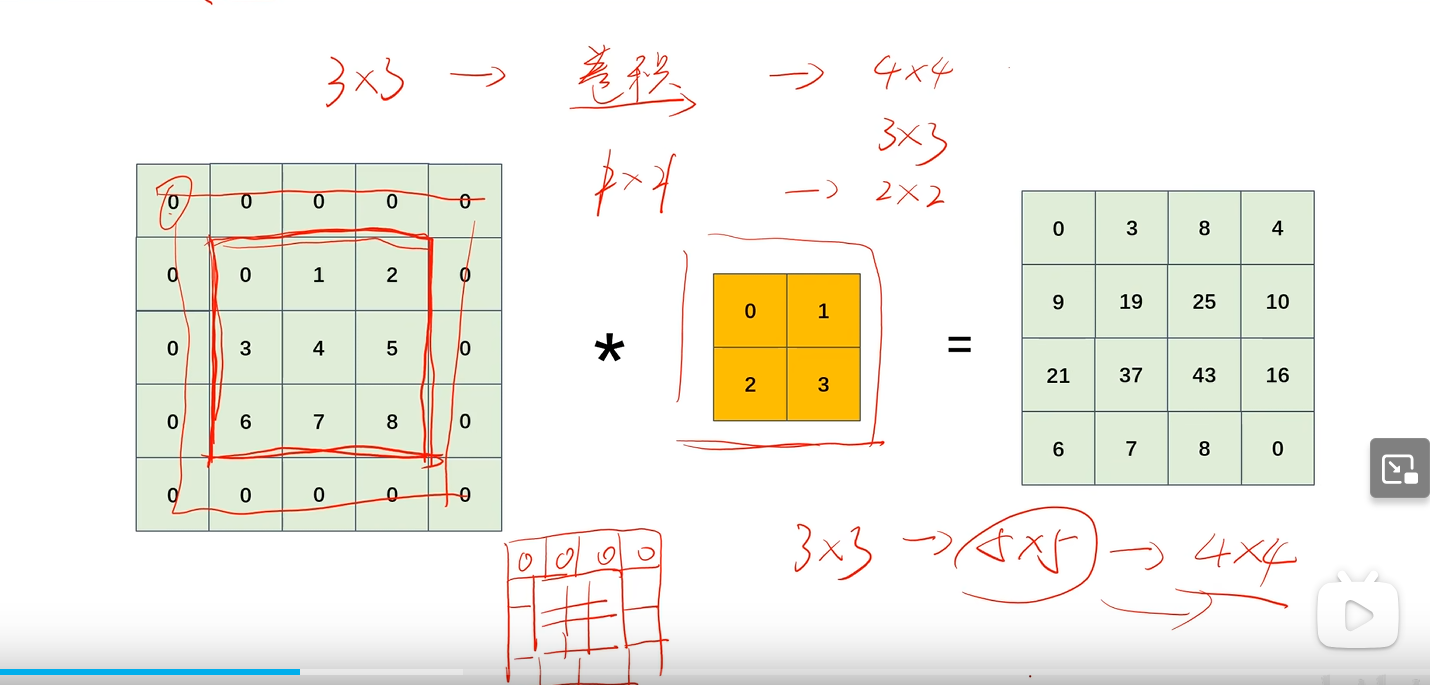
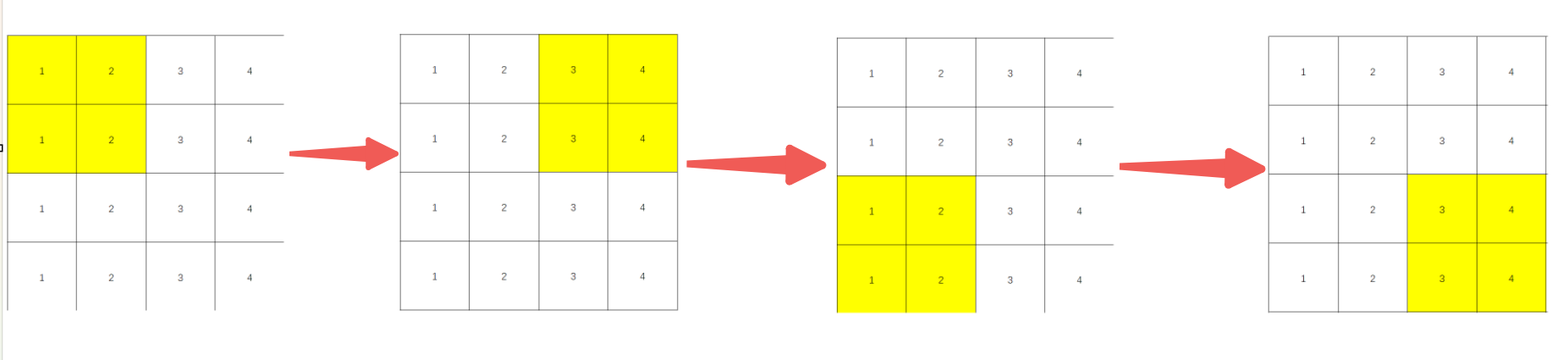
步幅
指卷积核一次移动几格;能够控制输出特征图的大小
eg:步幅为1

步幅为2
卷积运算后特征图大小
输出特征图的高OH=H+2P−FHS+1输出特征图的高OH=\\frac{H+2P-FH}{S}+1输出特征图的高OH=SH+2P−FH+1
- H:输入特征图的高
- P:填充的宽度(多了几圈)
- FH:卷积核的高
- S:步幅
OW=W+2P−FWS+1OW = \\frac{W+2P-FW}{S}+1OW=SW+2P−FW+1
- W:输入特征图的宽
- P:填充的宽度(多了几圈)
- FW:卷积核的宽
- S:步幅
多通道卷积运算
特征图有n通道,卷积核就有n通道
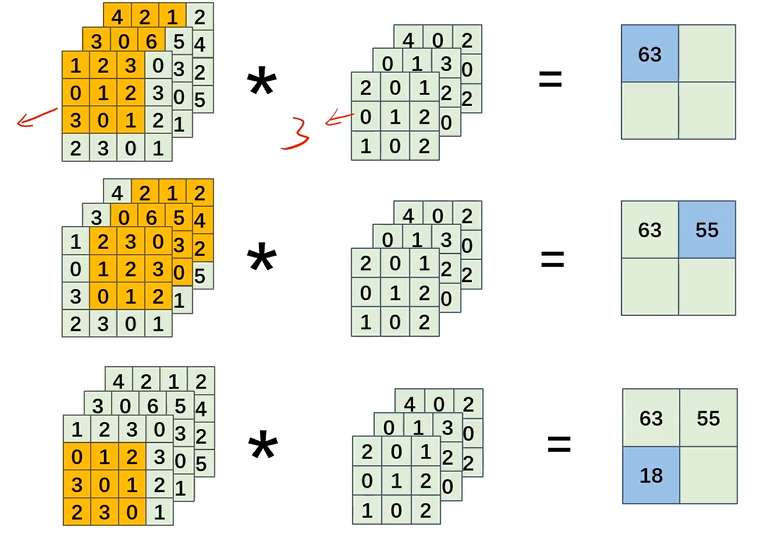
将每个通道的卷积结构相加;有n个卷积核,输出特征图通道数就为n

对于多通道卷积运算,我们可以用立体图表示
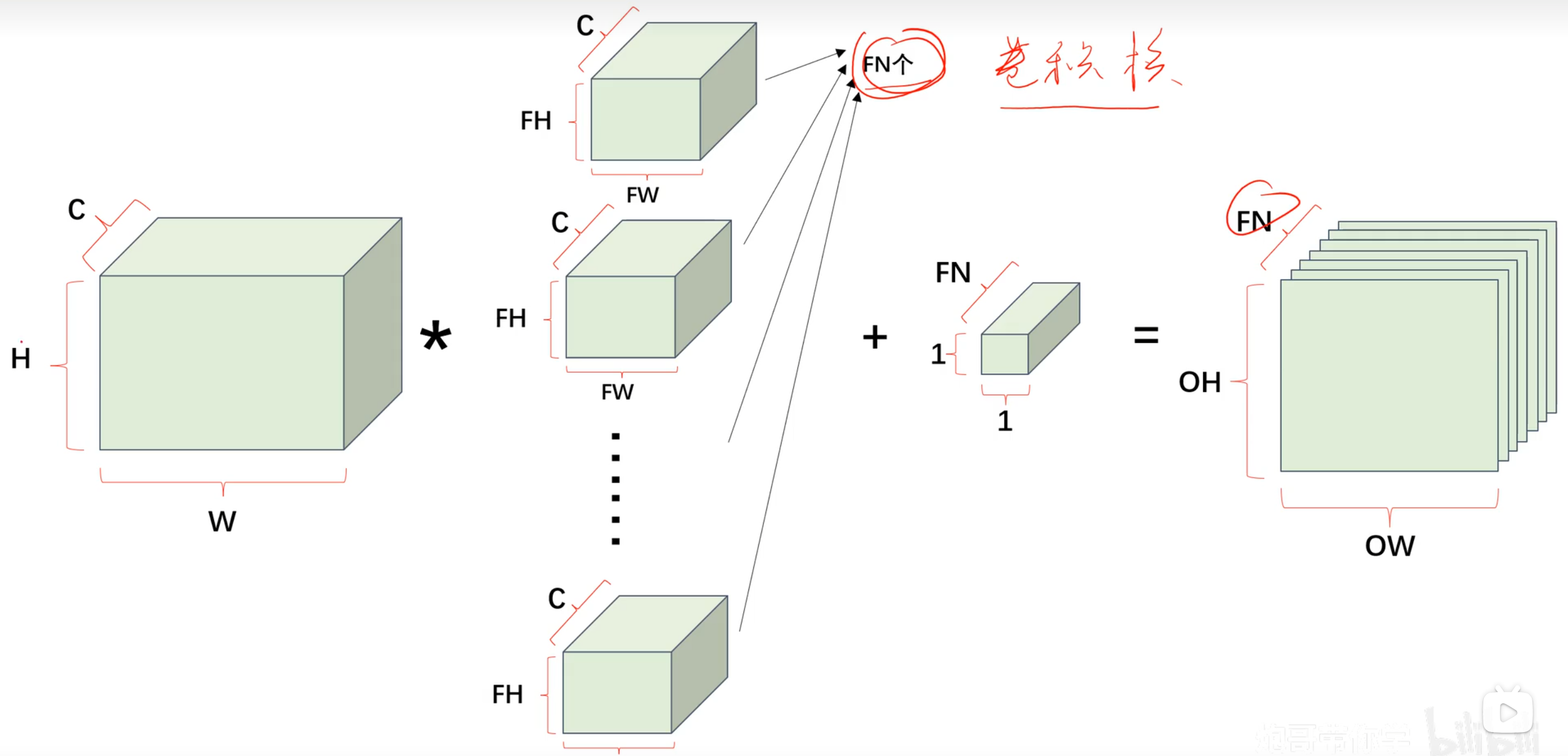
- C:输入通道数
- W:输入特征图的宽度
- H:输入特征图的高度
- FW:卷积核宽度
- FH:卷积核高度
- FN:输出通道数/输出的特征图数/卷积核数量
池化运算
池化运算是按通道独立运算的,即池化层运算不会对输入特征图的通道进行改变
池化核
类比卷积运算,我们也可以引入池化核这一概念
与卷积核相同和区别:
- 相同点:都是在特征图上滑动的窗口,并提取信息
- 不同:池化核仅仅是告诉算法要在特征图什么区域提取一块多大的特征,对这块特征取最大值或者平均,而不是和自身进行点积
最大池化运算
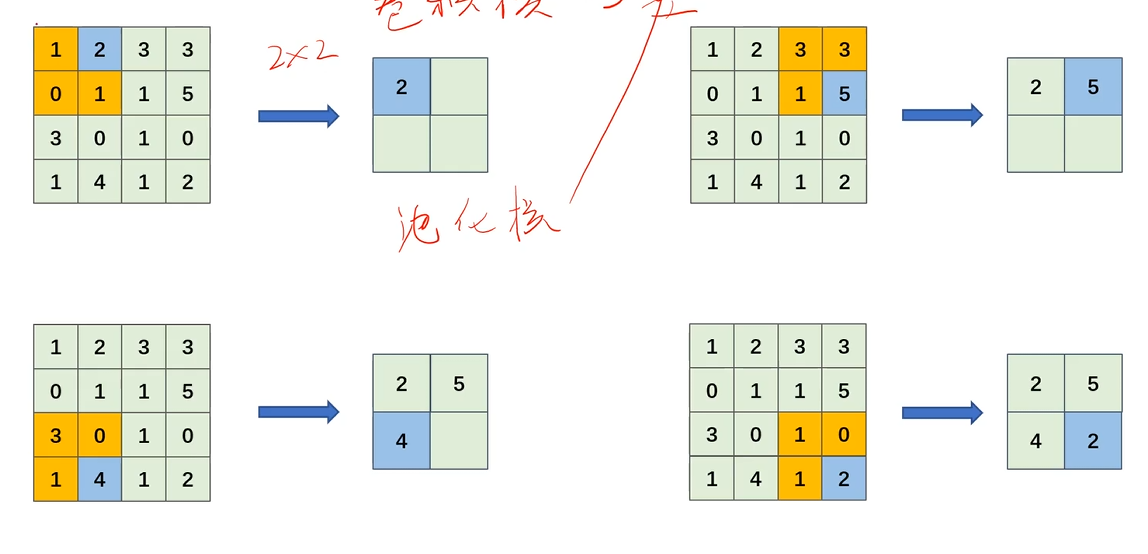
每次在区域中找到最大值
平均池化运算
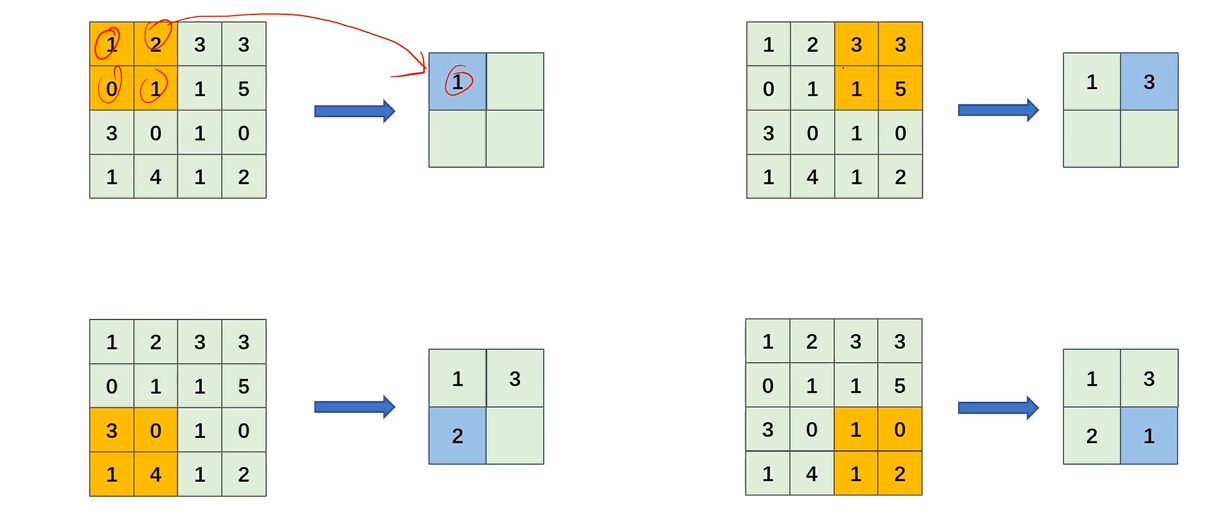
区域内的值相加求平均
优点
-
对微小的位置变化具有鲁棒性,使模型更加健壮

输出尺寸
OH=H+2P−FHS+1OW=W+2P−FWS+1OH=\\frac{H+2P-FH}{S}+1 \\\\OW = \\frac{W+2P-FW}{S}+1OH=SH+2P−FH+1OW=SW+2P−FW+1
- H,W:输入特征图的高、宽
- P:填充的宽度(多了几圈)
- FH,FW:池化核的高、宽
- S:步幅
代码实现
模拟mnist手写数字识别
全部代码
import numpy as npimport tensorflow as tffrom keras.optimizers import Adamfrom tensorflow.keras import models, layers, activations# 获取mnist手写数字数据集(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()# 维度改成4维,适配卷积层的输入格式 (60000, 28, 28)->(60000, 28, 28, 1)x_train = x_train[:, :, :, np.newaxis].astype(float)x_test = x_test[:, :, :, np.newaxis].astype(float)model = models.Sequential([ layers.Conv2D( 32, # 卷积核数量 (4, 4), # 卷积核尺寸 activation=activations.relu, # 经过该层后使用的激活函数,为了引入非线性特征 input_shape=(28, 28, 1) # 与mnist特征的shape相同 ), layers.MaxPool2D( (3, 3) # 池化核大小 ), layers.Conv2D( 64, # 卷积核数量 (4, 4), # 卷积核尺寸 activation=activations.relu, # 经过该层后使用的激活函数,为了引入非线性特征 ), layers.MaxPool2D( (3, 3) # 池化核大小 ), # 将2D展平为1D才能传入全连接层 layers.Flatten(), # 全连接层 layers.Dense( units=64, activation=activations.relu ), # 输出层 layers.Dense( units=10, activation=activations.linear )])model.compile( loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True), # 稀疏交叉熵损失函数 optimizer=Adam() # adam优化)model.fit( x_train, y_train, epochs=5, validation_split=0.1 # 每次从训练集中划分10%作为验证集)# 前向传播值logits = model(x_train)y_train_pred = tf.nn.softmax(logits)print(y_train_pred)# 评估模型loss = model.evaluate(x_test, y_test)print(loss)详解:
用到的库
import numpy as npimport tensorflow as tffrom keras.optimizers import Adamfrom tensorflow.keras import models, layers, activations获取数据集并进行初步处理
# 获取mnist手写数字数据集(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()# 维度改成4维,适配卷积层的输入格式 (60000, 28, 28)->(60000, 28, 28, 1)x_train = x_train[:, :, :, np.newaxis].astype(float)x_test = x_test[:, :, :, np.newaxis].astype(float)卷积层,使用tensorflow.keras.layers.Conv2D()
layers.Conv2D( 32, # 卷积核数量 (4, 4), # 卷积核尺寸 activation=activations.relu, # 经过该层后使用的激活函数,为了引入非线性特征 input_shape=(28, 28, 1) # 与mnist特征的shape相同 ),池化层,使用tensorflow.keras.layers.MaxPool2D() (最大池化运算)
layers.MaxPool2D( (3, 3) # 池化核大小 ),整体结构
model = models.Sequential([ layers.Conv2D( 32, # 卷积核数量 (4, 4), # 卷积核尺寸 activation=activations.relu, # 经过该层后使用的激活函数,为了引入非线性特征 input_shape=(28, 28, 1) # 与mnist特征的shape相同 ), layers.MaxPool2D( (3, 3) # 池化核大小 ), layers.Conv2D( 64, # 卷积核数量 (4, 4), # 卷积核尺寸 activation=activations.relu, # 经过该层后使用的激活函数,为了引入非线性特征 ), layers.MaxPool2D( (3, 3) # 池化核大小 ), # 将2D展平为1D才能传入全连接层 layers.Flatten(), # 全连接层 layers.Dense( units=64, activation=activations.relu ), # 输出层 layers.Dense( units=10, activation=activations.linear )])编译模型
model.compile( loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True), # 稀疏交叉熵损失函数 optimizer=Adam() # adam优化)训练模型
model.fit( x_train, y_train, epochs=5, validation_split=0.1 # 每次从训练集中划分10%作为验证集)获取最终损失函数值


