12 大模型学习——LLaMA-Factory微调_llama factory
一、LLaMA-Factory说明
LLaMA-Factory 是一个低代码的大规模语言模型(LLM)训练框架,它集合了大模型各种好用的开源工具,简化了大模型的微调、评估和部署过程,降低了使用难度。
llama-factory的中文readme地址:LLaMA-Factory/README_zh.md at main · hiyouga/LLaMA-Factory · GitHub
教程:LLaMA Factory
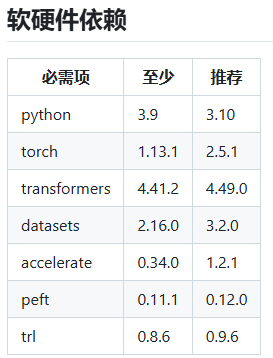
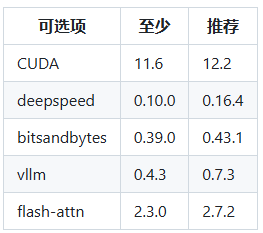
二、LLaMA-Factory 安装与使用
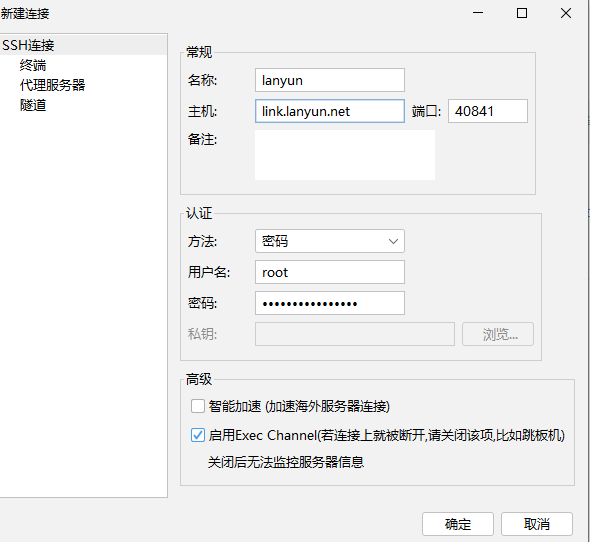
0、FinalShell连接服务器,便于文件管理
1、克隆 LLaMA-Factory 项目,并上传服务器
git clone https://github.com/hiyouga/LLaMA-Factory.git# 如果觉得太慢,可以先官方下载git clone https://gitclone.com/github.com/hiyouga/LLaMA-Factory.git一般可以去官网 https://github.com/hiyouga/LLaMA-Factory.git 上下载好之后解压
(1)文件上传服务器并解压
终端:
切换模型所在目录:cd /root/lanyun-tmp
解压模型: unzip /root/lanyun-tmp/LLaMA-Factory-main.zip
2、安装 LLaMA-Factory 核心包
终端
需要先进入解压后的 LLaMA-Factory 目录
cd /root/lanyun-tmp/LLaMA-Factory-main安装核心包
pip install -e .3、进入 LLaMA-Factory WEBUI 界面
voscode连接服务器,打开解压后的llamafactory
终端输入
# 使用此命令开启 LLaMA-Factory 服务,同样需先进入 LLaMA-Factory 目录cd /root/lanyun-tmp/LLaMA-Factory-mainllamafactory-cli webui成功运行后会出现以下信息,连接浏览器打开便是 LLaMA-Factory 的界面
![]()
使用viscode终端进入,可直接进入界面
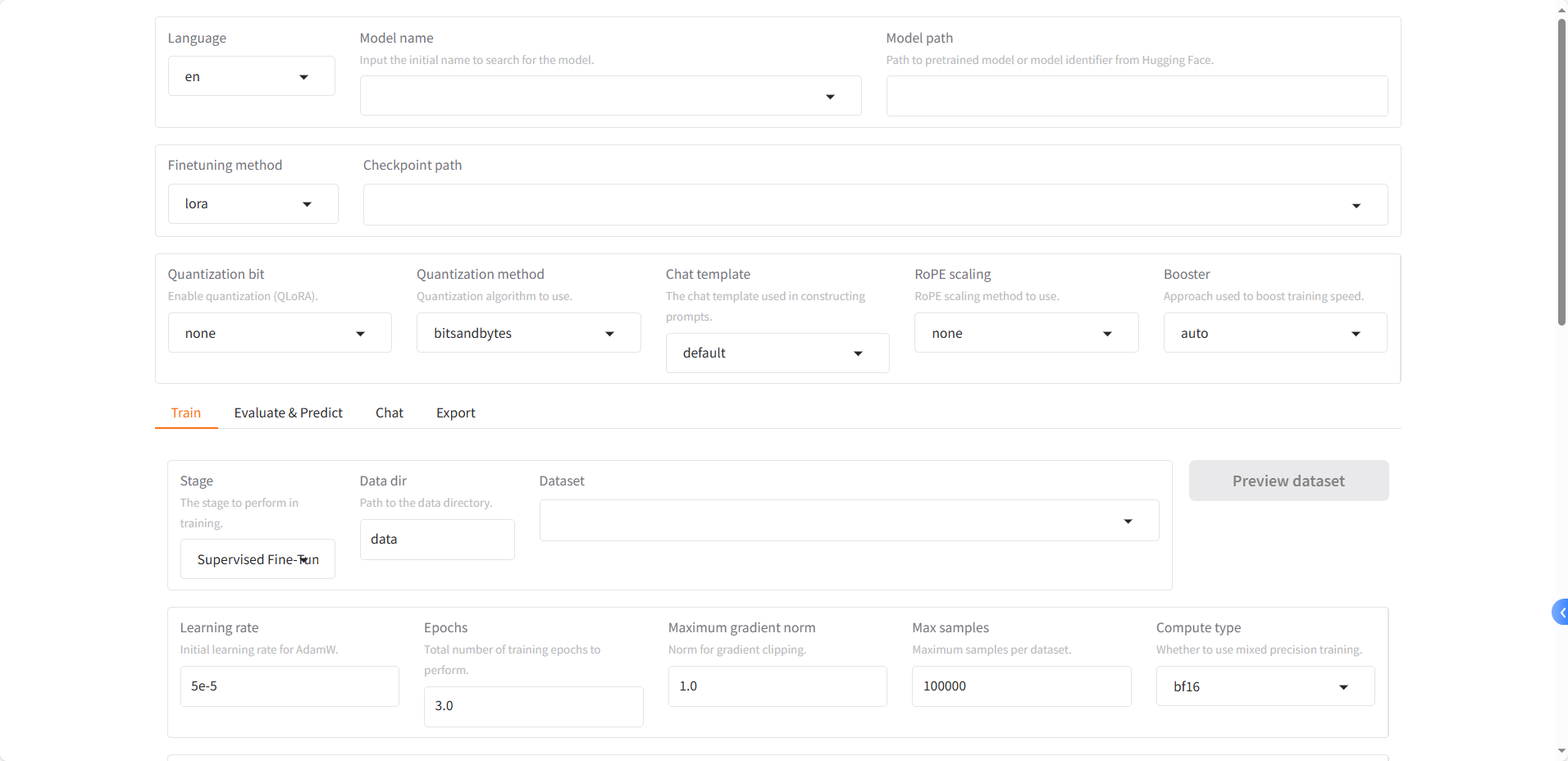
三、常用参数说明
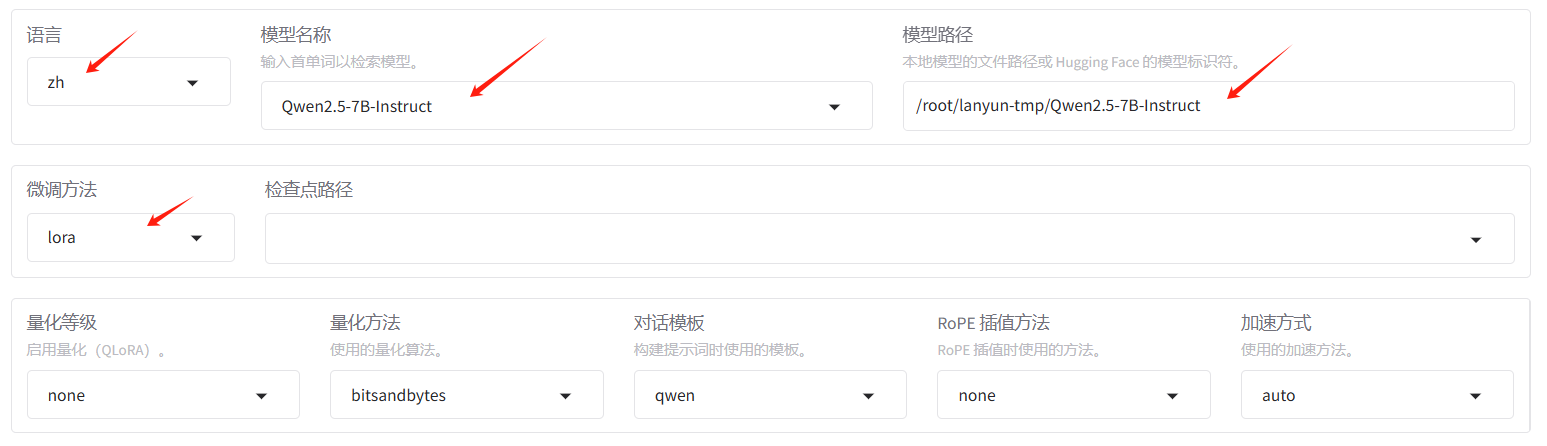
1、语言
英语不好选中文 zh 即可
- en:英语
- ru:俄语
- zh:中文
- ko:韩语
- ja:日文
2、模型名称和模型路径
- 模型名称:待训练的模型名称,因为每个大模型能够接受的提示词模板都是固定的,修改此参数【对话模版】参数也会自动匹配。
- 模型路径:支持huggingface在线路径,或者本地的模型路径(注意是绝对路径,.config文件上一层)
一般先下载好模型,用本地模型路径
3、微调方法和检查点路径
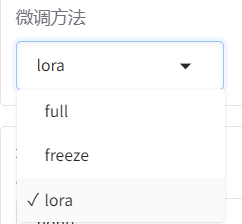
(1)微调方法
LLaMA-Factory 提供了三种微调方法
- full:全量微调,就是所有权重都进行训练。
- freeze:冻结微调,只训练部分层,其它层的权重进行冻结,也就是不进行训练。
- lora:目前众多微调方法中,最常用,也是相对来说效果比较好的微调方法之一。有类似需要的计算资源少,计算效率高,不改变原始模型结构等等的优点。
-
(2)检查点路径
检查点路径在长时间训练大模型的时候会经常用,主要作用是把训练过程中的阶段性结果进行保存,这里是设置指定的保存地址的。这样如果训练过程意外中断,可以从检查点开始继续训练,不用从头再开始训练。若不设置,则默认保存在 LLaMA-Factory 的 /saves文件中
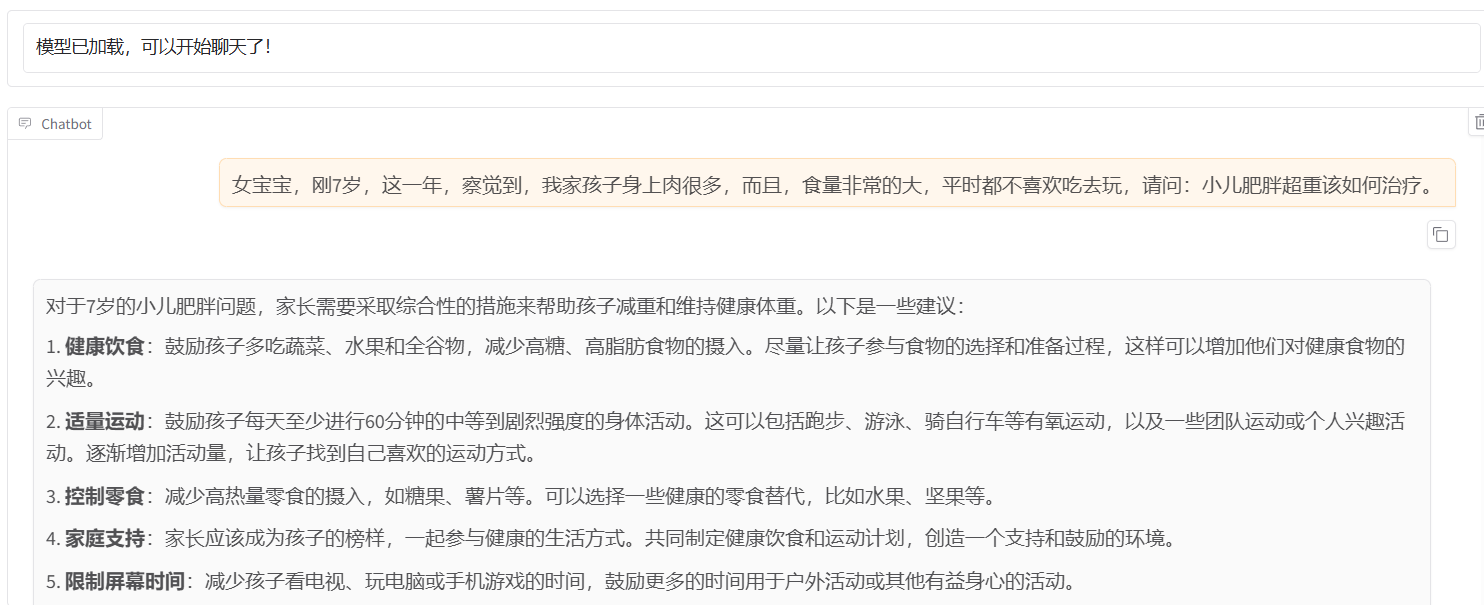
微调前可以加载模型 进入chat模型,看模型能否正常加载。
四、准备数据集
具体可以看 LlamaFactory 的说明文档: 数据处理 - LLaMA Factory
LLaMA-Factory 目前只支持 Alpaca 和 ShareGPT 两种数据格式,分别适用于指令监督微调和多轮对话任务。
dataset_info.json 包含了所有可用的数据集。如果您希望使用自定义数据集,请务必在 ataset_info.json 文件中添加数据集描述,并通过修改 dataset: 数据集名称 配置来使用数据集。
Alpaca 格式:Alpaca 格式由斯坦福大学的研究人员提出,主要用于单轮指令微调任务。针对不同任务,数据集的格式要求不同。
应用场景:
- 适用于单轮任务,如问答、文本生成、摘要、翻译等。
- 结构简洁,任务导向清晰,适合低成本的指令微调。
属于Alpaca 形式的 指令监督微调数据集,核心有4个键,分别对应着微调的四个指令:
- instruction(必填):明确的任务指令,模型需要根据该指令生成输出。
- input(可选):与任务相关的背景信息或上下文。在 RAG任务中,input参数可以用于提供检索到的外部知识或上下文信息,帮助模型生成更准确的回答
- output(必填):模型需要生成的正确回答。
- system(可选):系统提示词,用于定义任务的上下文。
- history(可选):历史对话记录,用于多轮对话任务。用于控制多轮对话,指上下文信息,若无历史对话,则为[]。注:如果有多轮对话,那么history 这个list是有先后顺序的。list[0]为第一轮,list[1]为第二轮,依次向后排序,而 instruction 是存放最新一轮对话信息示例

1、LlamaFactory 的数据集配置分为两步:
(1)准备数据
将训练数据存放至.json文件中,然后将训练数据的json文件上传至LLaMA-Factory 的 ./data目录下
- 这里使用的数据集是直接从魔塔上下载的中文医疗对话数据集
- train_0001_of_0001.json放入 LLaMA-Factory 文件夹中的 data 文件夹下
如果数据集划分了训练集和测试集,则将其中的 alpaca_train_dataset.json 和 alpaca_test_dataset.json 都放入 LLaMA-Factory 文件夹中的 data 文件夹下
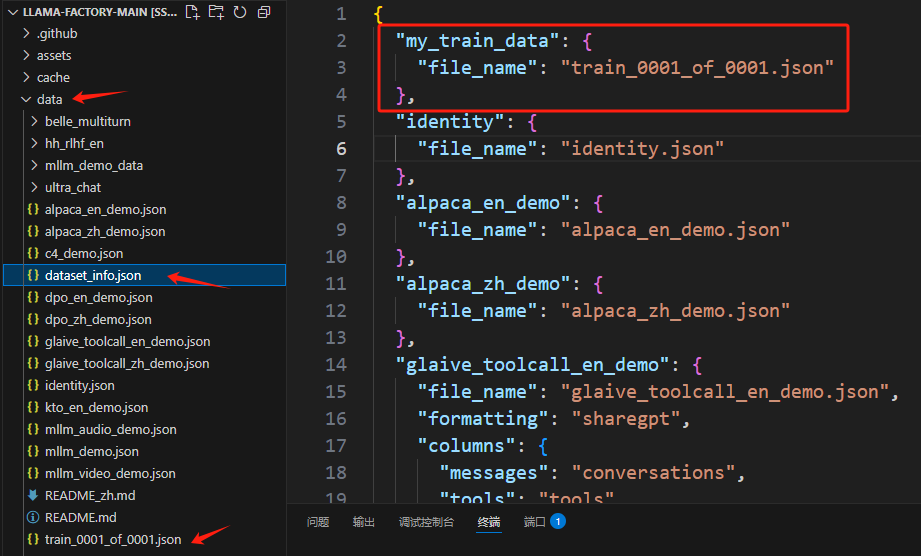
(2)注册数据
配置 ./data 中 的 data_info.json 文件,把训练数据路径(文件名)补充进入即可。名称可以自由命名
- 在 data 文件夹中的 data_info.json 中补充新添的数据集文件
(3)在 webui 页面中的数据集栏选择调用
这里数据集可以选一个或多个

五、训练相关参数
1、训练方式
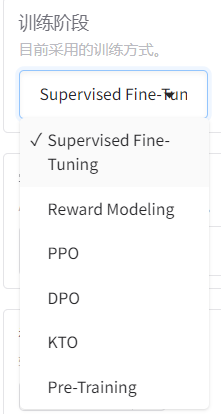
- Supervised Fine-Tuning (监督微调)监督微调是最常见的微调方法,使用标注好的数据对预训练模型进行进一步训练,以适应特定任务(如分类、问答等)。
- Reward Modeling(奖励建模)奖励建模是一种用于优化模型输出质量的方法,通常用于强化学习(RL)的上下文中。
- PPO(Proximal Policy Optimization) PPO 是一种基于强化学习的微调方法,用于优化模型的输出策略。
- DPO (Direct Preference Optimization)DPO 是一种基于人类偏好的直接优化方法,用于训练模型以生成更符合人类偏好的输出。
- Pre-Training(预训练)预训练是指从头开始训练一个大模型,通常使用大量的无监督数据(如文本语料库)。预训练的目标是让模型学习通用的语言知识和模式。
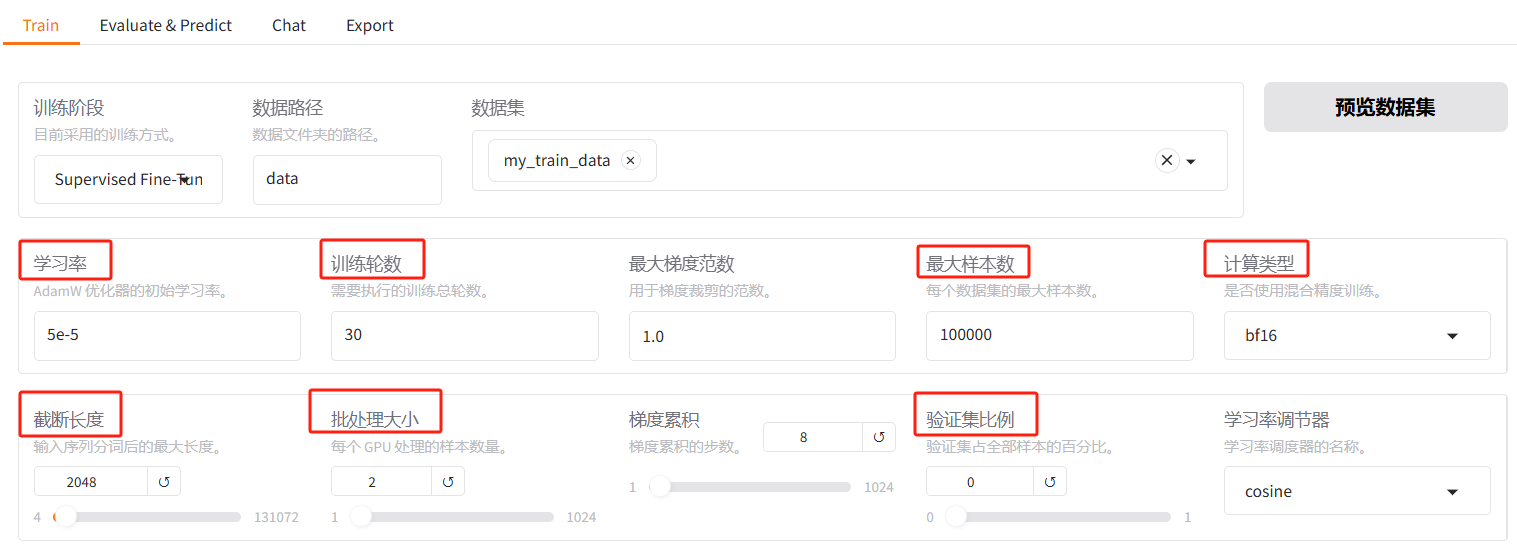
2、训练参数
以上的参数就与平常 LLM 训练时候类似
- 学习率:可以不用修改
- 训练轮次:根据数据集大小调整,可以调的高一些,比如1000,因为可以随时停止
- 梯度:根据显存情况调整
- 最大样本数:根据数据集大小和训练需求设置。主要是防止数据量过大导致的内存溢出问题
- 计算类型:这里支持混合精度训练选择(fp16或 bf16)bf16的效果更佳一些。 bf16对某些架构是不支持的,和硬件有关(GPU的架构)。
- 截断长度:根据任务需求/数据集配置,通常默认值为 1024
- 验证集比例

3、其他参数

- 日志间隔:多久输出日志信息
- 保存问题:多久保存权重,这里不是按轮次保存
4、LoRA参数
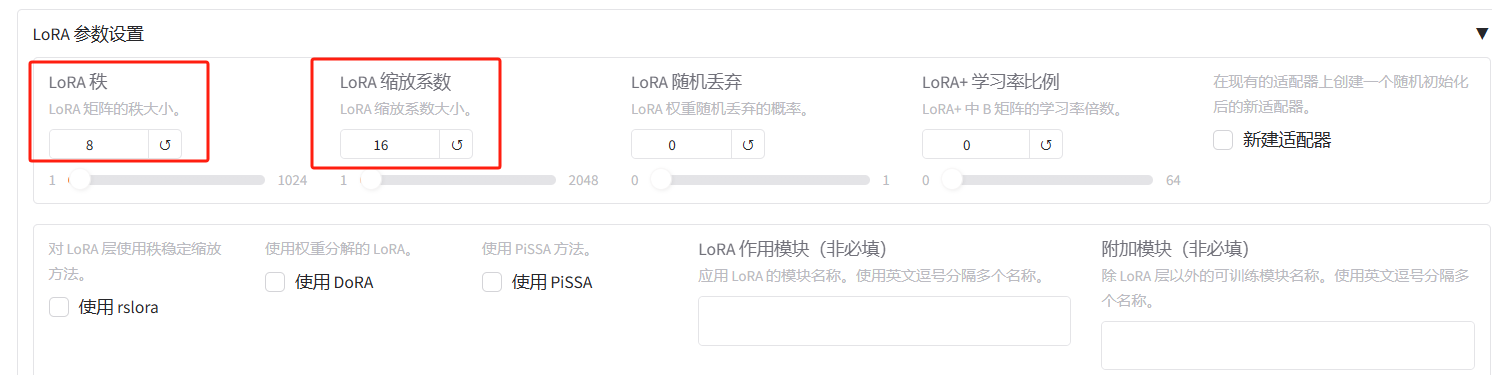
主要是Lora秩的大小、Lora缩放系数
LoRA秩:LoRA秩越大模型越大,默认秩是8
(一)训练train
在参数和数据集配置完成后就可以开始训练了,显存不够的话调一下参数,模型训练好后,会保存至 LLaMA-Factory 的 /saves文件中
方式一:
参数配置完成后,选择预览命令,将命令复制,然后粘贴到一个新建的yaml文件,再在终端输入指令运行
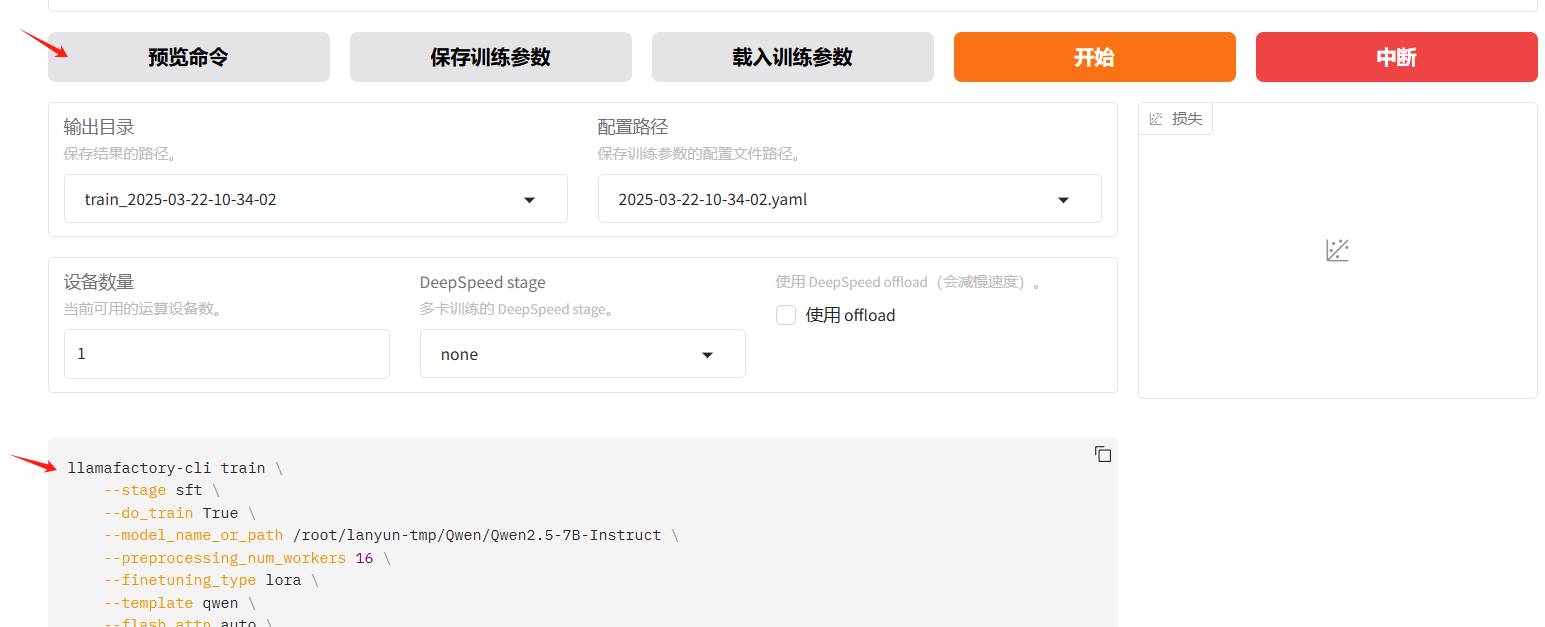
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml # 示例方式二:
参数配置完成后,直接点击开始
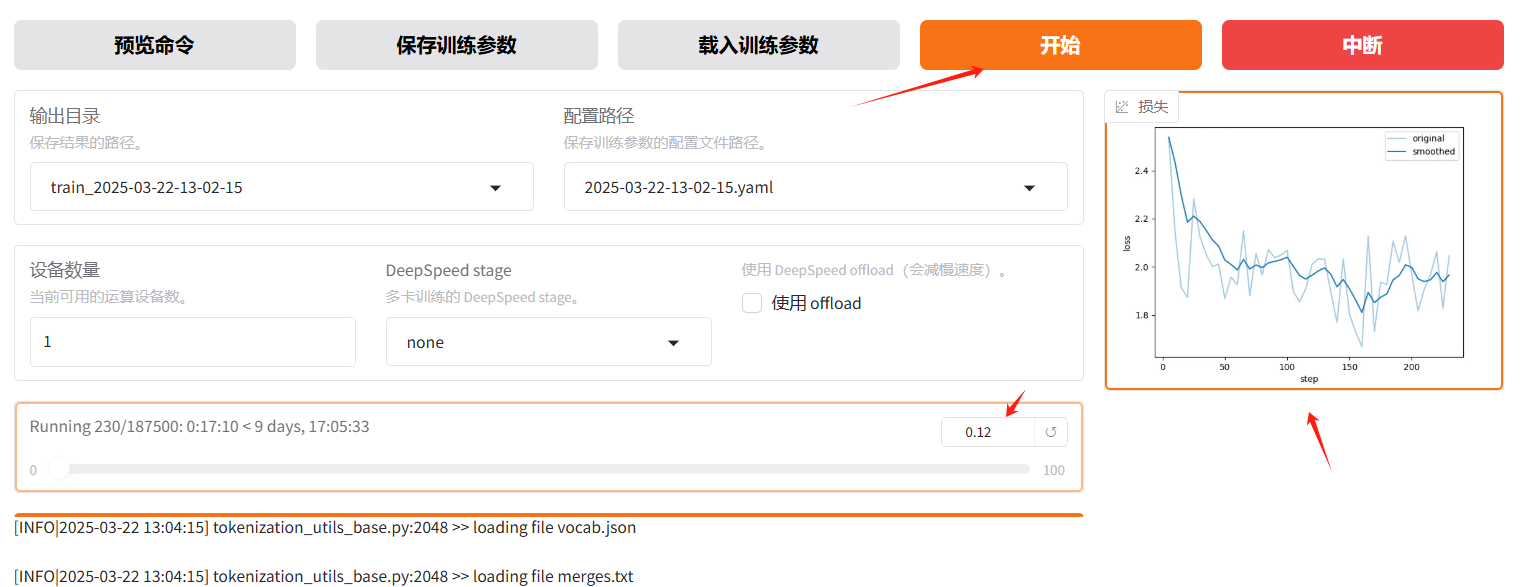
训练完后就可以在设置的output_dir下看到如下内容,主要包含3部分
- adapter开头的就是 LoRA保存的结果了,后续用于模型推理融合
- training_loss 和trainer_log等记录了训练的过程指标
- 其他是训练当时各种参数的备份
loss在 正常情况下会随着训练的时间慢慢变小,最后需要下降到1以下的位置才会有一个比较好的效果,可以作为训练效果的一个中间指标。
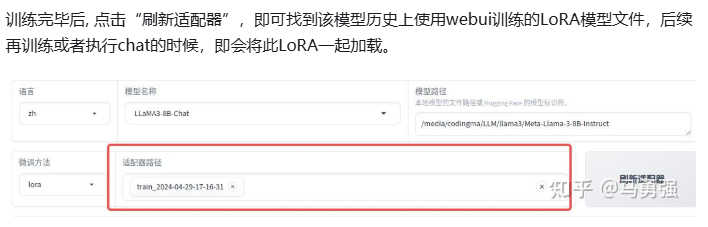
继续训练
加载检查点路径(适配器),继续训练
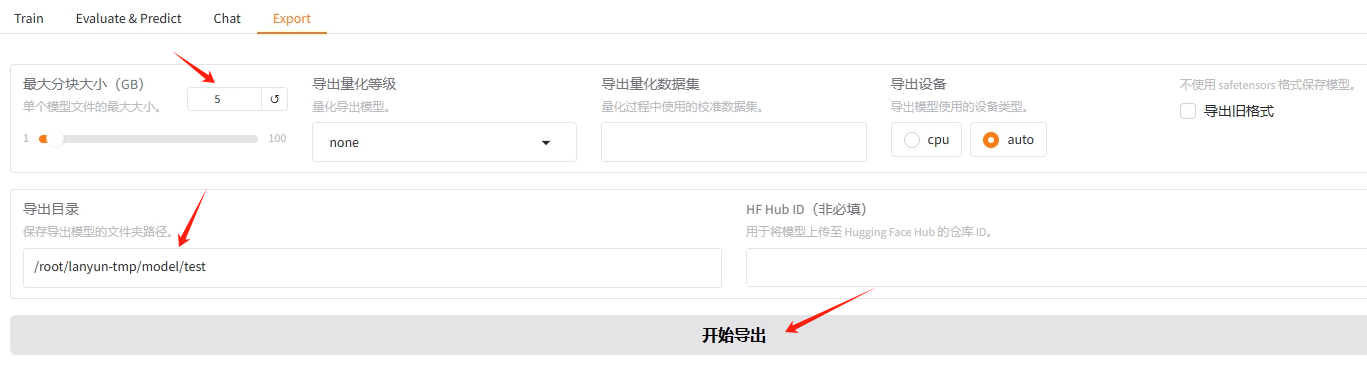
(二)模型导出 Export
方式一:
创建导出.yaml文件,终端输入指令运行
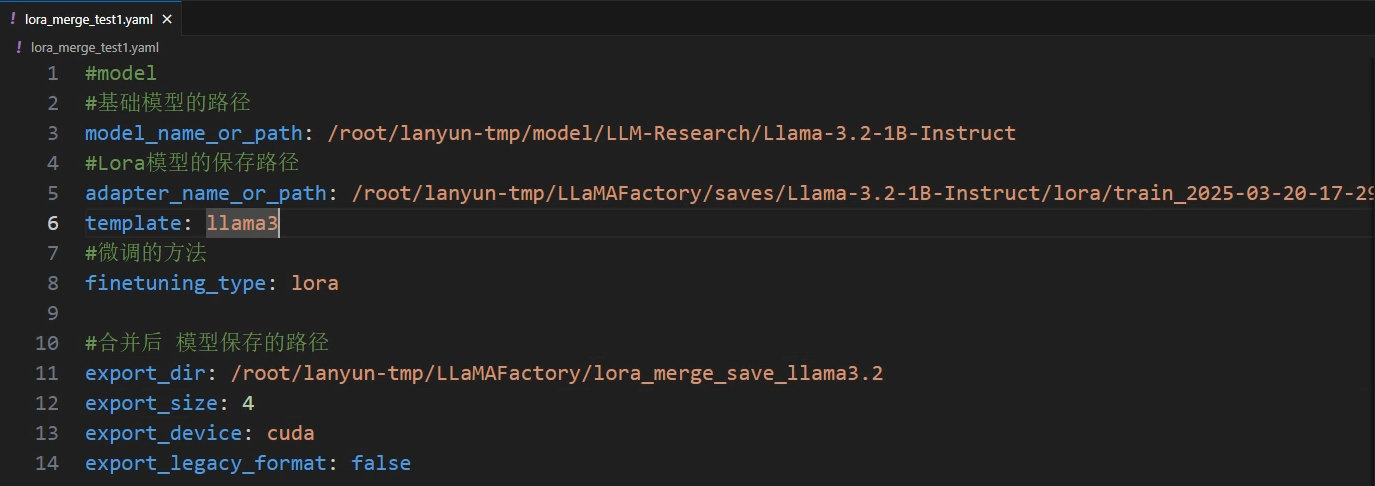
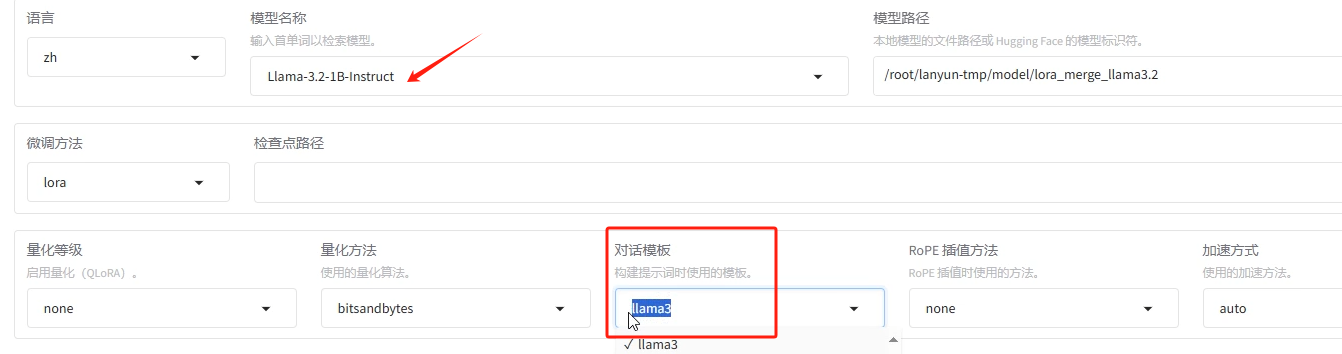
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml # 示例template根据具体模型会用不同的模板,可在webui中查看
方式二:
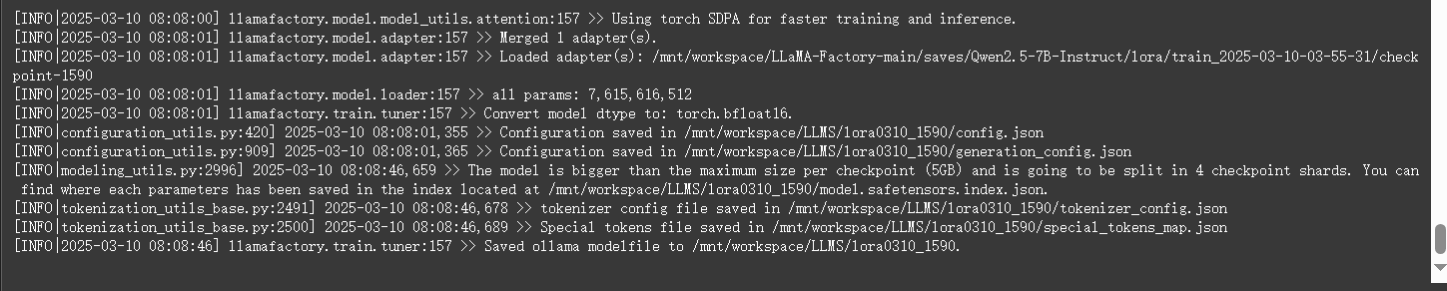
切换至 Export ,补充检查点路径(checkpoint文件路径、检查点路径),即可导出
(三)模型测试 Evaluate&Predict
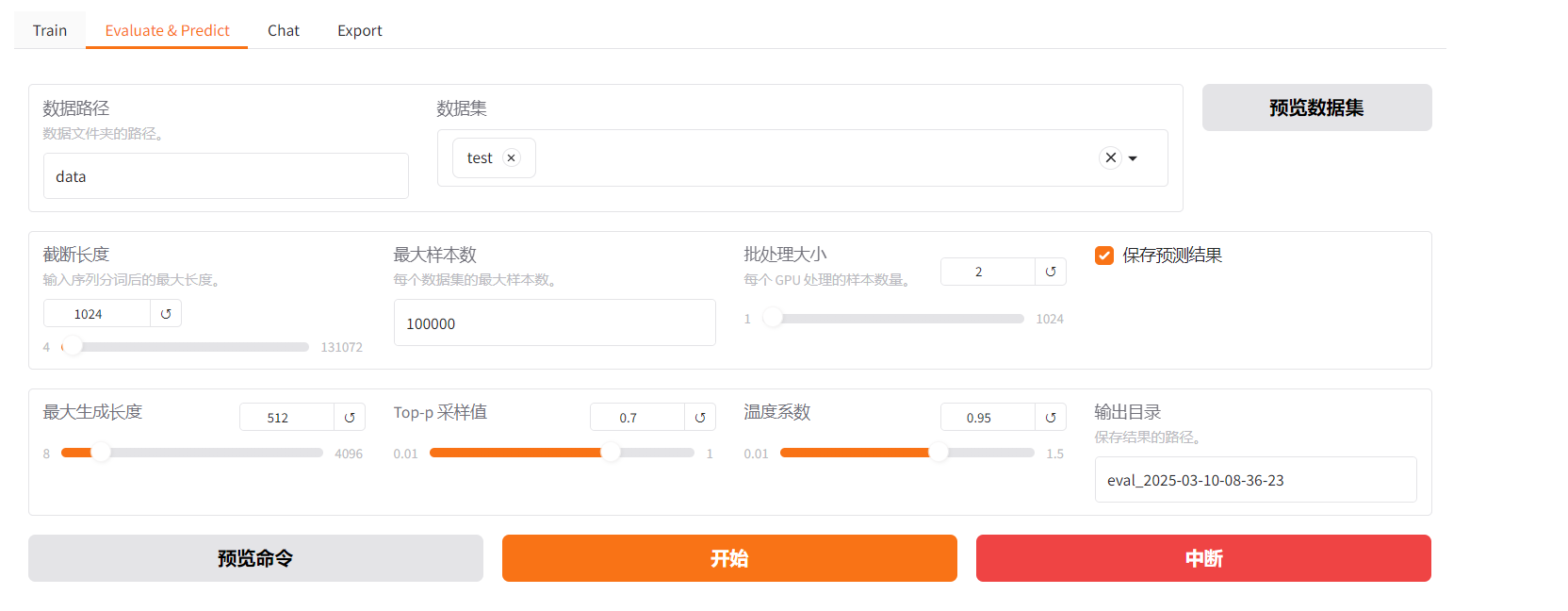
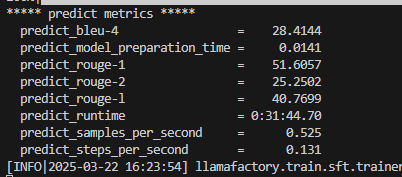
可以用 Evaluate&Predict 这个模块对模型进行测试,这里使用测试集,其他保持不变

(四)模型推理chat
还是先加载已经合并完成的模型,然后选择 Chat 板块进行模型的推理

知识扩展