爬虫&逆向--Day11--DrissionPage详细教程
一、基本概述
DrissionPage 是一个基于 Python 的网页自动化工具。它既能控制浏览器,也能像requests一样收发数据包,更重要的是还能把两者合二为一。因此,简单来说DrissionPage可兼顾浏览器自动化的便利性和 requests 的高效率。
DrissionPage功能强大,内置无数人性化设计和便捷功能。并且它的语法简洁而优雅,代码量少,对新手友好。
二、环境安装
2.1、运行环境
操作系统:Windows、Linux 或 Mac。
Python 版本:3.6 及以上
支持浏览器:Chromium 内核(如 Chrome 和 Edge)
2.2、一键安装
请使用 pip 安装 DrissionPage:
#最新版本安装pip install DrissionPage # 没安装过,可以执行这个pip install DrissionPage --upgrade # 之前安装过,可以执行这个进行更新
三、快速入门
3.1、页面类
在DrissionPage中有一个非常重要的工具叫做“页面类”,用于控制浏览器和收发数据包。DrissionPage 包含三种主要页面类。根据需要在其中选择使用。
ChromiumPage
如果只要控制浏览器,导入ChromiumPage。
from DrissionPage import ChromiumPage
SessionPage
如果只要收发数据包,导入SessionPage。
from DrissionPage import SessionPage
WebPage
WebPage是功能最全面的页面类,既可控制浏览器,也可收发数据包。
from DrissionPage import WebPage
3.2、控制浏览器
如果要控制浏览器,需设置浏览器路径。程序默认设置控制 Chrome,所以下面用 Chrome 演示。
3.2.1、尝试启动浏览器
默认状态下,程序会自动在系统内查找 Chrome 路径。
执行以下代码,浏览器启动并且访问了相关网站,如果访问执行成功说明可直接使用,跳过后面的步骤即可。
from DrissionPage import ChromiumPage# 创建/打开一个浏览器page = ChromiumPage()page.get(\'https://www.baidu.com\')
3.2.2、设置浏览器驱动路径
如果上面的步骤提示出错,说明程序没在系统里找到 Chrome 浏览器。
可用以下其中一种方法设置,设置会持久化记录到默认配置文件,之后程序会使用该设置启动。
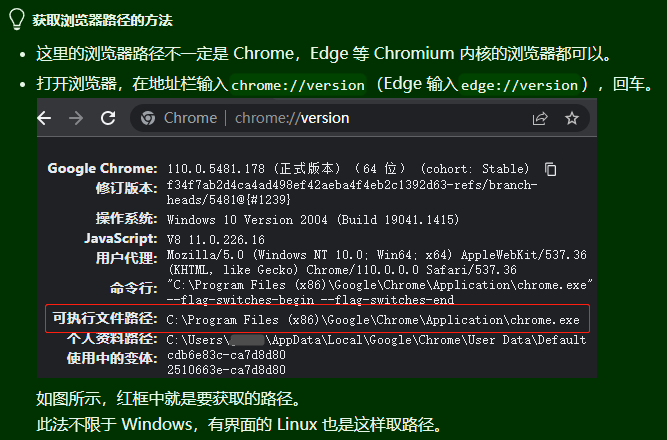
-
方法1:
-
新建一个临时 py 文件,并输入以下代码,填入您电脑里的 Chrome 浏览器可执行文件路径,然后运行。
from DrissionPage import ChromiumOptionspath = r\'D:\\Chrome\\Chrome.exe\' # 请改为你电脑内Chrome可执行文件路径ChromiumOptions().set_browser_path(path).save()
这段代码会把浏览器路径记录到配置文件,今后启动浏览器皆以新路径为准。
另外,如果是想临时切换浏览器路径以尝试运行和操作是否正常,可以去掉
.save(),以如下方式结合第1️⃣步的代码。from DrissionPage import ChromiumPage, ChromiumOptionspath = r\'D:\\Chrome\\Chrome.exe\' # 请改为你电脑内Chrome可执行文件路径co = ChromiumOptions().set_browser_path(path)page = ChromiumPage(co)page.get(\'http://DrissionPage.cn\')
-
-
方法2:
-
在命令行输入以下命令(路径改成自己电脑里的):
dp -p D:\\Chrome\\chrome.exe
-
现在,请重新执行第1️⃣步的代码,如果正确访问了目标网址,说明已经设置完成。
from DrissionPage import ChromiumPagepage = ChromiumPage()page.get(\'https://www.baidu.com\')
3.2.3、控制浏览器
现在,我们通过一些例子,来直观感受一下 DrissionPage 的工作方式。
本示例演示使用ChromiumPage控制浏览器登录 gitee 网站。
from DrissionPage import ChromiumPage# 创建页面对象,并启动浏览器page = ChromiumPage()# 跳转到登录页面page.get(\'https://gitee.com/login\')# 定位到账号文本框,通过id获取文本框元素ele = page.ele(\'#user_login\')# 输入对文本框输入账号ele.input(\'您自己的账号\')# 定位到密码文本框并输入密码page.ele(\'#user_password\').input(\'您自己的密码\')# 点击登录按钮:@attrName=value,这是根据属性和属性值进行标签定位的方式page.ele(\'@value=登 录\').click()
注意:ele()方法用于查找元素,它返回一个ChromiumElement对象,用于操作元素。值得一提的是,ele()内置了等待,如果元素未加载,它会执行等待,直到元素出现或到达时限。默认超时时间 10 秒。
3.3、收发数据包
本示例演示用SessionPage已收发数据包的方式采集 中大网校 网站课程标题数据。网址:中大网校课程中心|选课中心|网络课程-中大网校
from DrissionPage import SessionPage# 创建页面/请求对象page = SessionPage()# 访问某一页的网页page.get(f\'https://ke.wangxiao.cn/\')# 获取所有开源库元素列表(所有库的链接的a标签的class属性值都是一样的)# class . id # value @links = page.eles(\'.setmeal-title\')# 遍历所有元素for link in links: # 打印链接信息: print(link.text)\"\"\" 备注: SessionPage和Requests区别:请求发送成功之后,不会返回响应对象, 不用去接收get请求的返回值,因为所有的内容都会包含在了请求对象当中\"\"\"
.text获取元素的文本
3.4、模式切换
这个示例演示WebPage如何切换控制浏览器和收发数据包两种模式。
通常,切换模式是用来应付登录检查很严格的网站,可以用控制浏览器的形式处理登录,再转换模式用收发数据包的形式来采集数据。
需求:基于浏览器控制模式进行gitee的登陆,登录成功后切换模式基于收发数据包的性质访问该账户的个人主页,获取该账户主页左下角所有的组织名称。
备注:下面的代码是在个人主页进行的代码定位
from DrissionPage import WebPage# 创建页面对象page = WebPage()# 访问网址,进行登录page.get(\'https://gitee.com/login?redirect_to_url=%2F\')# 定位到账号文本框,获取文本框元素ele = page.ele(\'#user_login\')# 输入对文本框输入账号ele.input(\'您的账号\')# 定位到密码文本框并输入密码page.ele(\'#user_password\').input(\'您的密码\')# 点击登录按钮:@attrName=value,这是根据属性和属性值进行标签定位的方式page.ele(\'@value=登 录\').click()# 切换到收发数据包模式page.change_mode() # 切换的时候程序会在新模式重新访问当前 url。# 切换模式后,重新访问基于登录状态后新的url(个人主页)page.get(\'https://gitee.com/您的昵称\')# 根据class属性值获取div标签,然后将该div下面class为item的元素标签批量获取items = page.ele(\'.ui middle aligned list\').eles(\'.item\') # 局部解析# 遍历获取到的元素for item in items: # 打印元素文本 print(item(\'.content\').text)
4、ChromiumPage详解
顾名思义,ChromiumPage是 Chromium 内核浏览器的页面,使用它,我们可与网页进行交互,如调整窗口大小、滚动页面、操作弹出框等等。还可以跟页面中的元素进行交互,如输入文字、点击按钮、选择下拉菜单、在页面或元素上运行 JavaScript 代码等等。
可以说,操控浏览器的绝大部分操作,都可以由ChromiumPage及其衍生的对象完成,而它们的功能,还在不断增加。除了与页面和元素的交互,ChromiumPage还扮演着浏览器控制器的角色,可以说,一个ChromiumPage对象,就是一个浏览器。
4.1、启动和接管浏览器
用ChromiumPage()创建页面对象。根据不同的配置,可以接管已打开的浏览器,也可以启动新的浏览器。程序结束时,被打开的浏览器不会主动关闭,以便下次运行程序时使用(由 VSCode 启动的会被关闭)。
4.1.1、启动浏览器
这种方式代码最简洁,程序会使用默认配置,自动生成页面对象。创建ChromiumPage对象时会在指定端口启动浏览器。默认情况下,程序使用 9222 端口。
from DrissionPage import ChromiumPagepage = ChromiumPage()
指定端口启动浏览器:
# 启动9333端口的浏览器,如该端口空闲,启动一个浏览器page = ChromiumPage(9333)\"\"\" 备注: ip:定位到唯一的一台计算机设备(启动运行很多软件) port:用来标识一台计算机上运行的每一个软件 \"\"\"
4.1.2、接管浏览器
当页面对象创建时,只要指定的端口port已有浏览器在运行,就会直接接管。无论浏览器是哪种方式启动的。比如:先通过如下代码启动一个端口为8888的浏览器
from DrissionPage import ChromiumPagepage = ChromiumPage(8888)
在启动的端口为8888的浏览器中,手动访问百度页面,然后使用如下程序测试是否可以接管该浏览器:
from DrissionPage import ChromiumPagepage = ChromiumPage(8888)# 打印接管浏览器的page标题和访问的urlprint(page.title, page.url)# 百度一下,你就知道 https://www.baidu.com/
4.1.3、多浏览器共存
如果想要同时操作多个浏览器,或者自己在使用其中一个上网,同时控制另外几个浏览器跑自动化,就需要给这些被程序控制的浏览器设置单独的端口和用户文件夹,否则会造成冲突。
from DrissionPage import ChromiumPage, ChromiumOptions# 创建多个配置对象,每个指定不同的端口号和用户文件夹路径# D:\\data1和D:\\data2文件夹如果不存在会自动创建,用来保存浏览器在操作时,所产生的缓存数据do1 = ChromiumOptions().set_paths(local_port=9111, user_data_path=r\'D:\\data1\')do2 = ChromiumOptions().set_paths(local_port=9222, user_data_path=r\'D:\\data2\')# 创建多个页面对象page1 = ChromiumPage(addr_or_opts=do1)page2 = ChromiumPage(addr_or_opts=do2)# 每个页面对象控制一个浏览器page1.get(\'https://www.baidu.com\')# 进行对百度网页的操作page2.get(\'http://www.163.com\')# 进行对163网页的操作
4.2、页面交互
-
get():该方法用于跳转到一个网址。当连接失败时,程序会进行重试。
page.get(\'https://www.baidu.com\')
-
back():此方法用于在浏览历史中后退若干步。
page.back(2) # 后退两个网页
-
forward():此方法用于在浏览历史中前进若干步。
page.forward(2) # 前进两步
-
refresh():此方法用于刷新当前页面。
page.refresh() # 刷新页面
-
run_js():此方法用于执行 js 脚本。
from DrissionPage import ChromiumPagepage = ChromiumPage()# 用传入参数的方式执行 js 脚本显示弹出框显示 Hello world!# 参数1:执行的js脚本。参数2:*args表示给js脚本传递的参数page.run_js(\'alert(arguments[0]+arguments[1]);\', \'Hello\', \' world!\')
-
run_js_loaded():此方法用于运行 js 脚本,执行前等待页面加载完毕。
page.run_js_loaded(\'alert(arguments[0]+arguments[1]);\', \'Hello\', \' world!\')
-
scroll.to_bottom():此方法用于滚动页面到底部,水平位置不变。
page.scroll.to_bottom()
4.3、查找元素
本节介绍 DrissionPage 自创的查找元素语法。
查找语法能用于指明以哪种方式去查找指定元素,定位语法简洁明了,熟练使用可大幅提高程序可读性。
以下使用这个页面进行讲解test.html(可以在pycharm中使用chrome打开该页面获取页面链接):
第一行
第二行
第三行
第二个div
基本定位语法:注意下面的ele和eles
page.ele:只能定位满足要求第一次出现的标签
page.eles:定位到满足要求所有的标签
from DrissionPage import ChromiumPagepage = ChromiumPage()page.get(\'http://localhost:63342/PythonCodes2/Day11/test.html?_ijt=3khkgg158914gnbmb8ogaat4lo&_ij_reload=RELOAD_ON_SAVE\')# id属性定位tag1 = page.ele(\'@id=one\') # 获取第一个id为one的元素print(tag1)# 文本定位tag2 = page.ele(\'@text()=第一行\') # 获取第一个文本为“第一行”的元素print(tag2)# 当需要多个条件同时确定一个元素时,每个属性用\'@@\'开头。tag3 = page.ele(\'@@class=p_cls@@text()=第三行\') # 查找class为p_cls且文本为“第三行”的元素print(tag3)# 当需要以或关系条件查找元素时,每个属性用\'@|\'开头。tag4 = page.eles(\'@|id=row1@|id=row2\') # 查找所有id为row1或id为row2的元素print(tag4)# 表示模糊匹配,匹配含有指定字符串的文本或属性。tag5 = page.eles(\'@id:ow\') # 获取id属性包含\'ow\'的元素print(tag5)# 表示匹配开头,匹配开头为指定字符串的文本或属性。tag6 = page.eles(\'@id^row\') # 获取id属性以\'row\'开头的元素print(tag6)# 表示匹配结尾,匹配结尾为指定字符串的文本或属性。tag7 = page.ele(\'@id$w1\') # 获取id属性以\'w1\'结尾的元素print(tag7)\"\"\" [, ] [, ] [, ] \"\"\"
选择器定位语法
id选择器定位:
ele1 = page.ele(\'#one\') # 查找id为one的元素ele2 = page.ele(\'#=one\') # 和上面一行一致ele3 = page.ele(\'#:ne\') # 查找id属性包含ne的元素ele4 = page.ele(\'#^on\') # 查找id属性以on开头的元素ele5 = page.ele(\'#$ne\') # 查找id属性以ne结尾的元素
class选择器定位:
e1 = page.ele(\'.p_cls\') # 查找class属性为p_cls的元素e2 = page.ele(\'.=p_cls\') # 与上一行一致e3 = page.ele(\'.:_cls\') # 查找class属性包含_cls的元素e4 = page.ele(\'.^p_\') # 查找class属性以p_开头的元素e5 = page.ele(\'.$_cls\') # 查找class属性以_cls结尾的元素
文本选择器定位:
element1 = page.ele(\'text=第二行\') # 查找文本为“第二行”的元素element2 = page.ele(\'text:第二\') # 查找文本包含“第二”的元素element3 = page.ele(\'第二\') # 与上一行一致
标签选择器定位:
ele1 = page.ele(\'tag:div\') # 查找第一个div元素ele2 = page.ele(\'tag:p@class=p_cls\') # 与单属性查找配合使用ele3 = page.ele(\'tag:p@@class=p_cls@@text()=第二行\') # 与多属性查找配合使用
xpath定位:
eles = page.eles(\'xpath://div/p[@id=\"row1\"]\')
4.4、获取元素信息
htmlinner_htmltagtexttexts()attrsattr(\'attrName\')linkxpath元素列表中批量获取信息
eles()等返回的元素列表,自带get属性,可用于获取指定信息。
from DrissionPage import SessionPagepage = SessionPage()page.get(\'https://www.baidu.com\')eles = page.ele(\'#s-top-left\').eles(\'t:a\')print(eles.get.texts()) # 获取所有元素的文本print(eles.get.links()) # 获取所有元素的链接print(eles.get.attrs(\"class\")) # 获取所有元素的指定属性值
5、SessionPage详解
顾名思义,SessionPage是一个使用Session(requests 库)对象的页面,且它还封装了网络连接和 html 解析功能,使收发数据包也可以像操作页面一样便利。
并且,由于加入了本库独创的查找元素方法,使数据的采集便利性远超 requests + beautifulsoup 等组合。
from DrissionPage import SessionPage# 创建页面/请求对象page = SessionPage()# 访问某一页的网页page.get(f\'https://ke.wangxiao.cn/\')# 获取所有开源库元素列表(所有库的链接的a标签的class属性值都是一样的)links = page.eles(\'.setmeal-title\')# 遍历所有元素for link in links: # 打印链接信息: print(link.text)
5.1、get请求
get()方法语法与 requests 的get()方法一致,在此基础上增加了连接失败重试功能。与 requests 不一样的是,它不返回Response对象,而是返回一个bool值,表示请求是否成功。
示例:请求51游戏指定关键字对应的搜索结果页面
from DrissionPage import SessionPagepage = SessionPage()url = \'https://game.51.com/search/action/game/\'headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36\'}cookies = {\'name\': \'value\'}# proxies = {\'http\': \'127.0.0.1:1080\', \'https\': \'127.0.0.1:1080\'}param = {\"q\": \'传奇\'}page.get(url, headers=headers, cookies=cookies, params=param, proxies=None)print(page.html, page.title)
其他参数:

5.2、post请求
请求:中国人事考试网---站内搜索:中国人事考试网
from DrissionPage import SessionPagepage = SessionPage()url = \'http://www.cpta.com.cn/category/search\'headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36\'}cookies = {\'name\': \'value\'}# proxies = {\'http\': \'127.0.0.1:1080\', \'https\': \'127.0.0.1:1080\'}data = {\"keywords\": \'财务\', \'搜索\': \'搜索\'}page.post(url, headers=headers, cookies=cookies, data=data, proxies=None)print(page.html, page.title)
注意:在get和post请求中,headers中的User-Agent可以不写,因为SessionPage和WebPage在创建页面对象时会自动加载一个ini的配置文件,该配置文件中已经存在了User-Agent。
ini 文件初始内容如下:
......[session_options]headers = {\'user-agent\': \'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8\', \'accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\', \'connection\': \'keep-alive\', \'accept-charset\': \'GB2312,utf-8;q=0.7,*;q=0.7\'}[timeouts]base = 10page_load = 30script = 30[proxies]http =https = [others]retry_times = 3retry_interval = 2
5.3、page对象常用属性
url:此属性返回当前访问的 url。title:此属性返回当前页面title文本。raw_data:此属性返回访问到的二进制数据,即Response对象的content属性。html:此属性返回当前页面 html 文本。json:此属性把返回内容解析成 json。比如请求接口时,若返回内容是 json 格式,用html属性获取的话会得到一个字符串,用此属性获取可将其解析成dict。
逆向关联:将招投标网站中的招标信息进行爬取
备注:该网页不能直接右键打开开发者模式,只能通过浏览器右上角的【更多工具】--【开发者工具】
url:全国招标公告公示搜索引擎-中国招标投标公共服务平台
from DrissionPage import ChromiumPage# 创建页面对象,并启动浏览器page = ChromiumPage()url = \'https://ctbpsp.com/#/\'page.get(url)links = page.eles(\'.left_body_name\')# 遍历所有元素for link in links: # 打印链接信息: print(link.text)

