将sherpa-onnx嵌入unity中进行语音识别(ASR)_sherpa-onnx unity
起因
因为有语音识别需求,且需要低延迟,在查找了很多ASR项目后,偶然间发现sherpa-onnx比较契合我的需求,因为可以本地部署还免费,查找了不少资料后发现很少有sherpa-onnx+unity的资料,因此尝试自己研究下。
sherpa-onnx项目基础介绍
sherpa-onnx 是一个开源项目,旨在提供离线的语音识别、文本转语音、说话人识别和语音活动检测(VAD)功能。该项目支持很多语言,其中包括C#,在原项目文件中有C#示例,因此可以移植到unity中,本文参考了sherpa-onnx的TTS实现和原项目C#示例代码。
首先该项目进行语音识别需要语音识别大模型,我这边以 sherpa-onnx-streaming-zipformer-bilingual-zh-en-2023-02-20 模型作为测试,要下载该模型请自行去该项目的官方网址去下载。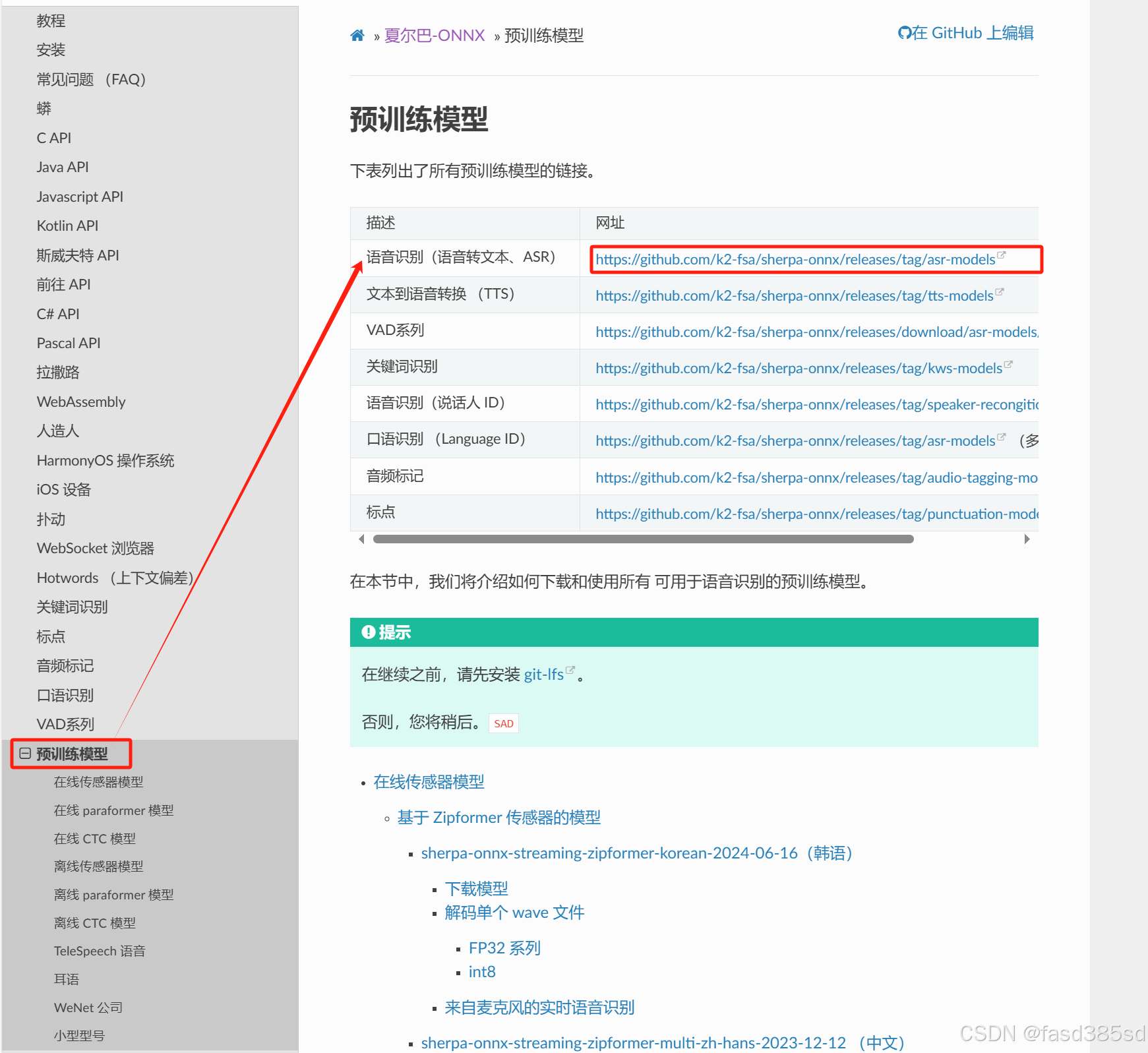
然后需要导入相关dll库和lib库,我在原项目文件中找了很久都没找到,最后在他的示例项目中找到。
现在万事俱备,接下来可以开始了。
首先在官方的C#示例代码中有流式和非流式的示例代码,此处先以流式作为例子,至于非流式道理差不多。直接上代码:
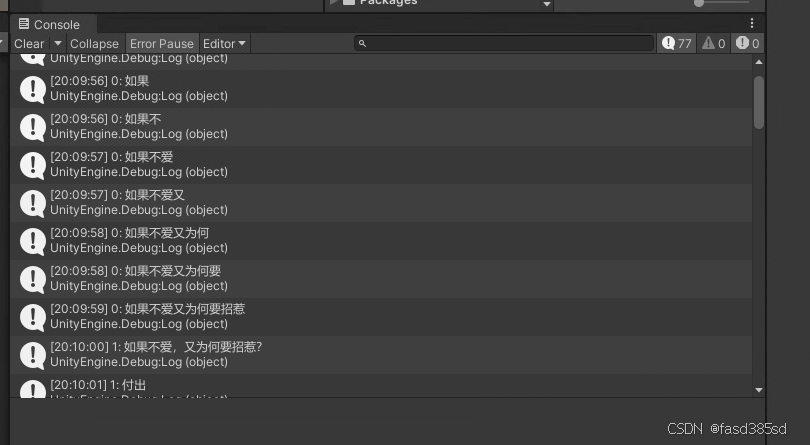
using SherpaOnnx;using System;using System.Collections;using System.Collections.Generic;using System.IO;using System.Threading;using UnityEngine;public class MyAsr_Test : MonoBehaviour{ private static int minFreq, maxFreq;//最小和最大频率 WaitForSeconds seconds = new WaitForSeconds(0.2f); /// /// 上一次采样位置 /// int lastSampling; float[] f = new float[16000]; AudioClip microphoneClip; bool recoeding = true; bool Init() { if (Microphone.devices.Length > 0) { Debug.Log($\"设备名称为:{Microphone.devices[0]}\"); Microphone.GetDeviceCaps(null, out minFreq, out maxFreq); if (minFreq == 0 && maxFreq == 0) { maxFreq = 44100; } return true; } return false; } /// /// 设置录音状态 /// void SetRecoeding(bool recoeding) { this.recoeding = recoeding; if (recoeding) lastSampling = 0; } private IEnumerator Start() { Init(); yield return seconds; var model_dir = Path.Combine(Application.streamingAssetsPath, \"SoundToTextModel\"); var modelDir = Path.Combine(model_dir, \"sherpa-onnx-streaming-zipformer-bilingual-zh-en-2023-02-20\"); OnlineRecognizerConfig config = new(); config.FeatConfig.SampleRate = 16000; config.FeatConfig.FeatureDim = 80; config.ModelConfig.Transducer.Encoder = Path.Combine(modelDir, \"encoder-epoch-99-avg-1.onnx\"); config.ModelConfig.Transducer.Decoder = Path.Combine(modelDir, \"decoder-epoch-99-avg-1.onnx\"); config.ModelConfig.Transducer.Joiner = Path.Combine(modelDir, \"joiner-epoch-99-avg-1.onnx\"); config.ModelConfig.Paraformer.Encoder = \"\"; config.ModelConfig.Paraformer.Decoder = \"\"; config.ModelConfig.Tokens = Path.Combine(modelDir, \"tokens.txt\"); config.ModelConfig.Provider = \"cpu\"; config.ModelConfig.NumThreads = 1; config.ModelConfig.Debug = 0; config.DecodingMethod = \"greedy_search\"; config.MaxActivePaths = 4; config.EnableEndpoint = 1; config.Rule1MinTrailingSilence = 2.4f; config.Rule2MinTrailingSilence = 0.8f; config.Rule3MinUtteranceLength = 20; #region 添加识别标点符号的模型 OfflinePunctuationConfig opc = new OfflinePunctuationConfig(); OfflinePunctuationModelConfig opmc = new OfflinePunctuationModelConfig(); string model_path = Path.Combine(model_dir, \"sherpa-onnx-punct-ct-transformer-zh-en-vocab272727-2024-04-12\", \"model.onnx\"); if (!File.Exists(model_path)) { yield break; } opmc.CtTransformer = model_path; opmc.NumThreads = 2; opmc.Provider = \"cpu\"; opmc.Debug = 1; opc.Model = opmc; var offlinePunctuation = new OfflinePunctuation(opc); #endregion OnlineRecognizer recognizer = new(config); OnlineStream s = recognizer.CreateStream(); string lastText = string.Empty; int segmentIndex = 0; // 等待应用获取麦克风权限 yield return Application.RequestUserAuthorization(UserAuthorization.Microphone); // 如果未获取到麦克风权限 if (!Application.HasUserAuthorization(UserAuthorization.Microphone)) yield break; do { microphoneClip = Microphone.Start(null, true, 1, 16000); yield return null; } while (!Microphone.IsRecording(null)); Application.quitting += () => Microphone.End(null); Debug.Log(\"开始录音\"); while (true) { yield return seconds; int currentPos = Microphone.GetPosition(null); bool isSucceed = microphoneClip.GetData(f, 0); if (!recoeding) continue; if (isSucceed) { if (lastSampling != currentPos) { int count = 0; float[] p = default; if (currentPos > lastSampling) { count = currentPos - lastSampling; p = new float[count]; Array.Copy(f, lastSampling, p, 0, count); } else { count = 16000 - lastSampling; p = new float[count + currentPos]; Array.Copy(f, lastSampling, p, 0, count); Array.Copy(f, 0, p, count, currentPos); count += currentPos; } lastSampling = currentPos; s.AcceptWaveform(16000, p); } } while (recognizer.IsReady(s)) { recognizer.Decode(s); } var text = recognizer.GetResult(s).Text; bool isEndpoint = recognizer.IsEndpoint(s); if (!string.IsNullOrWhiteSpace(text) && lastText != text) { lastText = text; Debug.Log($\"\\r{segmentIndex}: {lastText}\"); } if (isEndpoint) { if (!string.IsNullOrWhiteSpace(text)) { ++segmentIndex; lastText = offlinePunctuation.AddPunct(text); Debug.Log($\"\\r{segmentIndex}: {lastText}\"); } recognizer.Reset(s); } } }}上述是一个测试脚本,引入了sherpa-onnx自动添加标点的模型(该模型同样去官网自行下载),因为仅使用sherpa-onnx的asr语音识别模型那么它识别的结果不会自动添加标点符号,如果不需要自动添加标点可以将自动添加标点的部分代码删掉。
将该脚本随便挂在一个物体上就可以测试了,个人觉得还行(这里以音乐来测试)。