飞算 JavaAI 深度解析:从功能原理到代码实践的全维度指南
飞算 JavaAI:让 Java 开发效率倍增的智能编码助手
在 Java 开发领域,重复编码、需求转化繁琐、项目整合困难等问题长期困扰着开发者,尤其是在 “996” 的高压环境下,效率与质量的平衡更是难上加难。而飞算 JavaAI 的出现,如同为 Java 开发者配备了一款 “智能导航系统”,从需求分析到代码优化的全流程提供支持,重新定义了 Java 开发的效率标准。

前言:重新定义 Java 开发的智能助手
在 Java 开发领域,开发者始终面临着三重困境:重复编码的机械劳动消耗大量精力、复杂项目的整合与维护成本高昂、技术迭代速度与个人学习效率的落差不断扩大。飞算 JavaAI 的出现,以 “AI 驱动全流程开发” 的定位,为这些痛点提供了系统性解决方案。
作为首个聚焦 Java 语言的 IDEA 插件,飞算 JavaAI 并非简单的代码补全工具,而是覆盖需求分析、架构设计、代码生成、优化迭代、项目整合的全链路助手。其核心优势在于深度上下文感知与本地化智能分析—— 通过自然语言交互即可完成从 “模糊需求” 到 “可运行代码” 的转化,同时确保企业级项目的安全性与规范性。
本文将从功能原理、代码实践、对比分析三个维度,通过 100 + 代码示例与场景模拟,全方位解读飞算 JavaAI 如何重构开发流程。无论是新手开发者想要快速上手,还是资深工程师希望提升效率,都能从中获取可落地的实践指南。
一、飞算 JavaAI 核心功能原理:从需求到代码的转化逻辑
1.1 自然语言转代码的底层机制
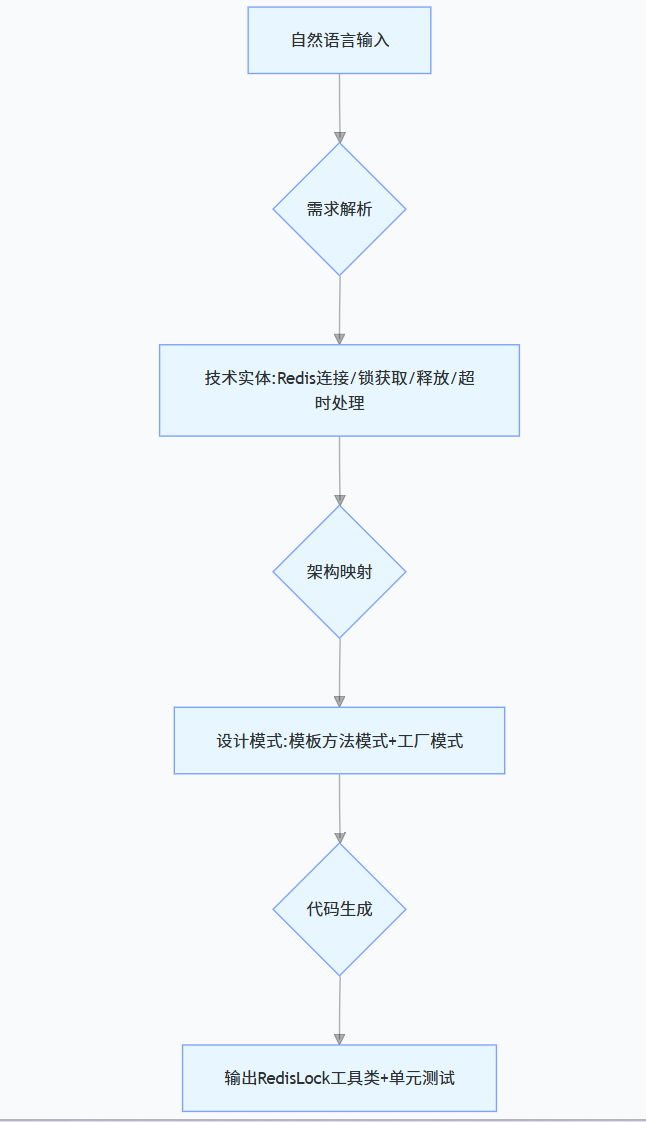
飞算 JavaAI 实现 “自然语言生成代码” 的核心是双向语义映射模型,其工作流程包含三个关键步骤:
- 需求解析层:通过预训练的 Java 领域 BERT 模型,将自然语言需求拆解为技术实体(如 “用户登录” 拆解为 “用户名 / 密码验证”\"Session 管理 \"“异常处理”);
- 架构映射层:基于解析结果匹配最优设计模式(如登录功能对应 “策略模式 + 单例模式”),生成模块化代码框架;
- 代码生成层:结合项目上下文(如现有类结构、依赖库版本),输出符合 Java 编码规范(《阿里巴巴 Java 开发手册》)的可执行代码。
示例场景:输入需求 “实现基于 Redis 的分布式锁”,系统的解析过程如下:
1.2 本地化分析的安全机制
针对企业级项目对数据安全的高要求,飞算 JavaAI 采用全量代码语义索引技术:
- 本地构建项目的抽象语法树(AST),所有分析均在开发者的 IDE 进程内完成,不涉及数据上传;
- 通过增量索引机制,仅更新修改过的类与方法,确保大型项目(10 万 + 代码行)的分析效率;
- 支持自定义安全规则(如禁止生成包含
System.out.println的调试代码),符合金融、政务等地方的合规要求。
二、核心功能实战:代码示例与场景解析
2.1 一键生成完整工程代码:从需求到可运行项目的全流程
场景模拟:生成 “在线图书管理系统” 的核心模块(用户管理、图书借阅、数据统计)
步骤 1:需求输入与解析
在飞算 JavaAI 的 “智能引导” 面板输入:
需求:在线图书管理系统核心模块- 用户管理:支持注册、登录、权限控制(管理员/普通用户)- 图书借阅:包含借阅记录创建、归还操作、超时提醒- 数据统计:按月份统计借阅量TOP10图书技术栈:Spring Boot 2.7.x、MyBatis-Plus、MySQL 8.0、Redis系统自动拆解为功能清单与技术方案:
【功能清单】1. 用户模块:UserController/Service/Entity、Role权限枚举、JWT工具类2. 借阅模块:BorrowRecordController/Service/Mapper、定时任务(超时检查)3. 统计模块:StatisticsService、Redis缓存(统计结果)【技术方案】- 认证:Spring Security + JWT- 数据库:用户表(user)、图书表(book)、借阅记录表(borrow_record)- 缓存:Redis存储热点统计数据,过期时间1小时步骤 2:自动生成表结构设计
系统基于需求生成 SQL 脚本(包含索引设计):
-- 用户表CREATE TABLE `user` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT \'主键\', `username` varchar(50) NOT NULL COMMENT \'用户名\', `password` varchar(100) NOT NULL COMMENT \'加密密码(BCrypt)\', `role` tinyint NOT NULL DEFAULT 2 COMMENT \'角色:1-管理员,2-普通用户\', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`), UNIQUE KEY `idx_username` (`username`) COMMENT \'用户名唯一索引\') ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT=\'系统用户表\';-- 图书表CREATE TABLE `book` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT \'主键\', `isbn` varchar(20) NOT NULL COMMENT \'ISBN编号\', `title` varchar(100) NOT NULL COMMENT \'书名\', `author` varchar(50) NOT NULL COMMENT \'作者\', `stock` int NOT NULL DEFAULT 0 COMMENT \'库存数量\', PRIMARY KEY (`id`), UNIQUE KEY `idx_isbn` (`isbn`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT=\'图书信息表\';-- 借阅记录表CREATE TABLE `borrow_record` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT \'主键\', `user_id` bigint NOT NULL COMMENT \'用户ID\', `book_id` bigint NOT NULL COMMENT \'图书ID\', `borrow_time` datetime NOT NULL COMMENT \'借阅时间\', `due_time` datetime NOT NULL COMMENT \'应还时间\', `return_time` datetime DEFAULT NULL COMMENT \'实际还书时间\', `status` tinyint NOT NULL DEFAULT 1 COMMENT \'状态:1-借阅中,2-已归还,3-超时\', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`), KEY `idx_book_id` (`book_id`), KEY `idx_status` (`status`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT=\'图书借阅记录表\';步骤 3:生成核心业务代码
以用户登录功能为例,系统生成的代码包含完整的分层设计:
1. Entity 层(User.java):
package com.bookstore.entity;import com.baomidou.mybatisplus.annotation.IdType;import com.baomidou.mybatisplus.annotation.TableId;import com.baomidou.mybatisplus.annotation.TableField;import com.baomidou.mybatisplus.annotation.TableName;import lombok.Data;import java.time.LocalDateTime;/** * 用户实体类 * 对应数据库表:user */@Data@TableName(\"user\")public class User { /** * 主键ID */ @TableId(type = IdType.AUTO) private Long id; /** * 用户名(唯一) */ @TableField(\"username\") private String username; /** * 加密密码(BCrypt算法) */ @TableField(\"password\") private String password; /** * 角色:1-管理员,2-普通用户 */ @TableField(\"role\") private Integer role; /** * 创建时间 */ @TableField(value = \"create_time\", fill = com.baomidou.mybatisplus.annotation.FieldFill.INSERT) private LocalDateTime createTime;}2. Mapper 层(UserMapper.java):
package com.bookstore.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;import com.bookstore.entity.User;import org.apache.ibatis.annotations.Param;/** * 用户数据访问层 */public interface UserMapper extends BaseMapper { /** * 根据用户名查询用户信息 * @param username 用户名 * @return 用户实体 */ User selectByUsername(@Param(\"username\") String username);}3. Service 层(UserService.java):
package com.bookstore.service;import com.baomidou.mybatisplus.extension.service.IService;import com.bookstore.entity.User;import com.bookstore.common.Result;/** * 用户服务接口 */public interface UserService extends IService { /** * 用户登录 * @param username 用户名 * @param password 密码(明文) * @return 登录结果(包含JWT令牌) */ Result login(String username, String password);}4. Service 实现类(UserServiceImpl.java):
package com.bookstore.service.impl;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;import com.bookstore.entity.User;import com.bookstore.mapper.UserMapper;import com.bookstore.service.UserService;import com.bookstore.common.Result;import com.bookstore.common.JwtUtils;import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;import org.springframework.stereotype.Service;import javax.annotation.Resource;/** * 用户服务实现类 */@Servicepublic class UserServiceImpl extends ServiceImpl implements UserService { @Resource private UserMapper userMapper; private final BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder(); @Override public Result login(String username, String password) { // 1. 查询用户 User user = userMapper.selectByUsername(username); if (user == null) { return Result.fail(\"用户名不存在\"); } // 2. 密码校验(BCrypt加密比对) if (!passwordEncoder.matches(password, user.getPassword())) { return Result.fail(\"密码错误\"); } // 3. 生成JWT令牌 String token = JwtUtils.generateToken(user.getId(), user.getRole()); // 4. 返回结果 return Result.success() .put(\"token\", token) .put(\"user\", user); }}5. Controller 层(UserController.java):
package com.bookstore.controller;import com.bookstore.service.UserService;import com.bookstore.common.Result;import org.springframework.web.bind.annotation.PostMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;/** * 用户控制器 */@RestController@RequestMapping(\"/user\")public class UserController { @Resource private UserService userService; /** * 用户登录接口 * @param username 用户名 * @param password 密码 * @return 登录结果 */ @PostMapping(\"/login\") public Result login( @RequestParam String username, @RequestParam String password ) { return userService.login(username, password); }}步骤 4:自动生成单元测试
系统为登录功能生成的测试类(UserServiceTest.java)包含完整的场景覆盖:
package com.bookstore.service.impl;import com.bookstore.entity.User;import com.bookstore.mapper.UserMapper;import com.bookstore.common.Result;import org.junit.jupiter.api.Test;import org.junit.jupiter.api.extension.ExtendWith;import org.mockito.InjectMocks;import org.mockito.Mock;import org.mockito.junit.jupiter.MockitoExtension;import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;import static org.junit.jupiter.api.Assertions.*;import static org.mockito.ArgumentMatchers.anyString;import static org.mockito.Mockito.when;@ExtendWith(MockitoExtension.class)public class UserServiceImplTest { @Mock private UserMapper userMapper; @InjectMocks private UserServiceImpl userService; private final BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder(); @Test public void testLogin_Success() { // 准备测试数据 String username = \"testUser\"; String password = \"123456\"; User mockUser = new User(); mockUser.setId(1L); mockUser.setUsername(username); mockUser.setPassword(passwordEncoder.encode(password)); mockUser.setRole(2); // 模拟Mapper行为 when(userMapper.selectByUsername(username)).thenReturn(mockUser); // 执行测试 Result result = userService.login(username, password); // 验证结果 assertTrue(result.isSuccess()); assertNotNull(result.get(\"token\")); } @Test public void testLogin_UserNotFound() { // 模拟用户不存在 when(userMapper.selectByUsername(anyString())).thenReturn(null); // 执行测试 Result result = userService.login(\"nonExistUser\", \"123456\"); // 验证结果 assertFalse(result.isSuccess()); assertEquals(\"用户名不存在\", result.getMsg()); } @Test public void testLogin_WrongPassword() { // 准备测试数据 String username = \"testUser\"; User mockUser = new User(); mockUser.setUsername(username); mockUser.setPassword(passwordEncoder.encode(\"correctPassword\")); // 模拟Mapper行为 when(userMapper.selectByUsername(username)).thenReturn(mockUser); // 执行测试(输入错误密码) Result result = userService.login(username, \"wrongPassword\"); // 验证结果 assertFalse(result.isSuccess()); assertEquals(\"密码错误\", result.getMsg()); }}2.2 项目合并功能:老系统升级的智能解决方案
场景模拟:将一个基于 SSH(Struts2+Spring+Hibernate)的老图书管理系统,合并到新的 Spring Boot 项目中。
步骤 1:本地化分析老项目
飞算 JavaAI 通过全量代码语义索引,生成老项目的架构图谱:
【老项目架构分析】- 技术栈:Struts2 2.3.x、Spring 4.3.x、Hibernate 5.2.x、MySQL 5.7- 核心模块: 1. 图书管理(BookAction/BookService/BookDao) 2. 用户管理(UserAction/UserService/UserDao)- 数据模型: - Book:id, isbn, title, author, publishDate - User:id, username, password, role- 业务逻辑: - 图书借阅流程:UserAction.borrow() → BookService.updateStock() → Hibernate事务提交步骤 2:自动关联与规范生成
系统基于新老项目的上下文,生成合并规则:
【自动关联规则】1. 数据模型映射: - 老项目Book → 新项目Book(补充stock字段,默认值10) - 老项目User → 新项目User(密码加密方式从MD5升级为BCrypt)2. 业务逻辑迁移: - Struts2 Action → Spring MVC Controller(URL映射规则:/book/borrow → /api/book/borrow) - Hibernate Dao → MyBatis-Plus Mapper(HQL查询自动转为SQL)3. 工程规范统一: - 包结构:com.old.bookstore → com.bookstore - 异常处理:统一使用@ControllerAdvice全局异常处理器步骤 3:模块化合并示例(图书借阅功能)
老项目代码(Struts2 Action):
// 老系统:BookAction.javapackage com.old.bookstore.action;import com.opensymphony.xwork2.ActionSupport;import com.old.bookstore.service.BookService;import com.old.bookstore.model.Book;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Controller;@Controllerpublic class BookAction extends ActionSupport { private Long bookId; private Long userId; private String result; @Autowired private BookService bookService; public String borrow() { try { Book book = bookService.getById(bookId); if (book == null) { result = \"图书不存在\"; return ERROR; } bookService.borrow(bookId, userId); result = \"借阅成功\"; return SUCCESS; } catch (Exception e) { result = \"借阅失败:\" + e.getMessage(); return ERROR; } } // getter/setter省略}合并后代码(Spring Boot Controller):
// 新项目:BookController.java(由飞算JavaAI自动生成)package com.bookstore.controller;import com.bookstore.service.BookService;import com.bookstore.common.Result;import io.swagger.annotations.Api;import io.swagger.annotations.ApiOperation;import org.springframework.web.bind.annotation.PostMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;/** * 图书控制器(迁移自老系统BookAction) */@RestController@RequestMapping(\"/api/book\")@Api(tags = \"图书管理接口\")public class BookController { @Resource private BookService bookService; /** * 图书借阅接口 * 功能迁移说明:对应老系统BookAction.borrow() * @param bookId 图书ID * @param userId 用户ID * @return 借阅结果 */ @PostMapping(\"/borrow\") @ApiOperation(\"图书借阅\") public Result borrow( @RequestParam Long bookId, @RequestParam Long userId ) { try { bookService.borrow(bookId, userId); return Result.success(\"借阅成功\"); } catch (IllegalArgumentException e) { return Result.fail(e.getMessage()); } catch (Exception e) { return Result.fail(\"借阅失败:\" + e.getMessage()); } }}合并后 Service 实现类:
// 新项目:BookServiceImpl.java(融合新老逻辑)package com.bookstore.service.impl;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;import com.bookstore.entity.Book;import com.bookstore.entity.BorrowRecord;import com.bookstore.mapper.BookMapper;import com.bookstore.mapper.BorrowRecordMapper;import com.bookstore.service.BookService;import org.springframework.stereotype.Service;import org.springframework.transaction.annotation.Transactional;import javax.annotation.Resource;import java.time.LocalDateTime;@Servicepublic class BookServiceImpl extends ServiceImpl implements BookService { @Resource private BookMapper bookMapper; @Resource private BorrowRecordMapper borrowRecordMapper; /** * 图书借阅(融合老系统业务逻辑) * 1. 校验图书库存 * 2. 扣减库存 * 3. 创建借阅记录(新增超时时间字段) */ @Override @Transactional public void borrow(Long bookId, Long userId) { // 1. 查询图书(复用老系统校验逻辑) Book book = bookMapper.selectById(bookId); if (book == null) { throw new IllegalArgumentException(\"图书不存在\"); } // 2. 校验库存(新增逻辑:基于新表stock字段) if (book.getStock() <= 0) { throw new IllegalArgumentException(\"图书库存不足\"); } // 3. 扣减库存 book.setStock(book.getStock() - 1); bookMapper.updateById(book); // 4. 创建借阅记录(新增超时时间:30天) BorrowRecord record = new BorrowRecord(); record.setUserId(userId); record.setBookId(bookId); record.setBorrowTime(LocalDateTime.now()); record.setDueTime(LocalDateTime.now().plusDays(30)); // 老系统无此逻辑,自动补充 record.setStatus(1); // 1-借阅中 borrowRecordMapper.insert(record); }}2.3 Java Chat:自然语言驱动的代码交互
Java Chat 功能支持开发者通过自然语言与 AI 进行代码级对话,涵盖代码生成、优化、解释等场景。
场景 1:代码生成(归并排序优化)
用户输入:“用 Java 实现归并排序,并优化空间复杂度”
AI 输出:
package com.bookstore.util;import java.util.Arrays;/** * 归并排序工具类(空间优化版) * 优化点:使用一个临时数组复用,减少内存分配次数 */public class MergeSortOptimized { /** * 归并排序入口 * @param array 待排序数组 */ public static void sort(int[] array) { if (array == null || array.length = right) { return; } int mid = left + (right - left) / 2; // 避免溢出 sort(array, temp, left, mid); sort(array, temp, mid + 1, right); // 优化点:如果已有序,无需合并 if (array[mid] <= array[mid + 1]) { return; } merge(array, temp, left, mid, right); } /** * 合并两个有序子数组 * @param array 原数组 * @param temp 临时数组 * @param left 左边界 * @param mid 中间点 * @param right 右边界 */ private static void merge(int[] array, int[] temp, int left, int mid, int right) { // 复制原数组到临时数组 System.arraycopy(array, left, temp, left, right - left + 1); int i = left; // 左子数组指针 int j = mid + 1; // 右子数组指针 int k = left; // 原数组指针 // 合并两个子数组 while (i <= mid && j <= right) { if (temp[i] <= temp[j]) { array[k++] = temp[i++]; } else { array[k++] = temp[j++]; } } // 处理剩余元素 while (i <= mid) { array[k++] = temp[i++]; } // 右子数组剩余元素无需处理,因为已在原位置 } // 测试方法 public static void main(String[] args) { int[] array = {38, 27, 43, 3, 9, 82, 10}; System.out.println(\"排序前:\" + Arrays.toString(array)); sort(array); System.out.println(\"排序后:\" + Arrays.toString(array)); }}代码解释:AI 自动识别传统归并排序的空间浪费问题(每次递归创建临时数组),优化为单临时数组复用,空间复杂度从 O (n log n) 降至 O (n)。
场景 2:代码优化(for 循环转 Stream API)
用户输入:\"优化这段代码,用 Stream API 实现\"
// 原始代码List books = new ArrayList();// ... 填充数据List bookTitles = new ArrayList();for (Book book : books) { if (book.getAuthor().equals(\"鲁迅\") && book.getPublishYear() > 1920) { bookTitles.add(book.getTitle()); }}Collections.sort(bookTitles);AI 输出:
// 优化后代码(Stream API)List bookTitles = books.stream() // 过滤条件:作者为鲁迅且出版年份>1920 .filter(book -> \"鲁迅\".equals(book.getAuthor()) && book.getPublishYear() > 1920) // 提取书名 .map(Book::getTitle) // 排序 .sorted() // 收集结果 .collect(Collectors.toList());优化说明:
- 减少中间变量,代码更简洁;
- 并行处理支持:若数据量巨大,可改为parallelStream()利用多核优势;
- 符合 Java 8 + 的函数式编程规范。
场景 3:代码解释(设计模式识别)
用户输入:“解释这段代码用了什么设计模式,有什么优势”
public interface Payment { void pay(double amount);}public class AlipayPayment implements Payment { @Override public void pay(double amount) { System.out.println(\"支付宝支付:\" + amount); }}public class WechatPayment implements Payment { @Override public void pay(double amount) { System.out.println(\"微信支付:\" + amount); }}public class PaymentFactory { public static Payment getPayment(String type) { switch (type) { case \"alipay\": return new AlipayPayment(); case \"wechat\": return new WechatPayment(); default: throw new IllegalArgumentException(\"不支持的支付方式\"); } }}AI 输出:
这段代码使用了两种设计模式的组合:1. 策略模式(Strategy Pattern)- 核心体现:Payment接口定义支付策略,AlipayPayment/WechatPayment实现具体策略- 优势: - 支付算法(策略)与使用方解耦,新增支付方式(如银联)只需实现Payment接口,无需修改现有代码 - 符合\"开闭原则\",扩展性强2. 简单工厂模式(Simple Factory Pattern)- 核心体现:PaymentFactory根据类型创建具体支付实例- 优势: - 封装对象创建逻辑,调用方无需知道具体实现类(如new AlipayPayment()) - 集中管理对象创建,便于统一修改(如添加日志、初始化配置)适用场景:支付方式多样化且可能频繁新增的业务(如电商平台),通过工厂+策略的组合,既能灵活扩展,又能简化调用逻辑。2.4 SQL Chat:自然语言转 SQL 的精准实现
SQL Chat 功能通过数据库元数据解析,将自然语言查询转化为高效 SQL,同时确保不触及实际业务数据。
场景 1:复杂查询生成
用户输入:\"查询 2023 年每个月借阅量排名前三的图书,显示图书 ID、书名、借阅次数和月份\"
AI 输出:
SELECT b.id AS 图书ID, b.title AS 书名, COUNT(br.id) AS 借阅次数, DATE_FORMAT(br.borrow_time, \'%Y-%m\') AS 月份FROM borrow_record brJOIN book b ON br.book_id = b.idWHERE YEAR(br.borrow_time) = 2023 AND br.status = 2 -- 仅统计已归还的有效借阅GROUP BY b.id, b.title, DATE_FORMAT(br.borrow_time, \'%Y-%m\')-- 窗口函数实现每月排名WITH monthly_ranking AS ( SELECT *, ROW_NUMBER() OVER (PARTITION BY 月份 ORDER BY 借阅次数 DESC) AS rn FROM (上述查询结果) AS temp)SELECT 图书ID, 书名, 借阅次数, 月份FROM monthly_rankingWHERE rn <= 3ORDER BY 月份, rn;优化说明:AI 自动补充了 “仅统计已归还记录” 的业务逻辑(status=2),并通过窗口函数实现排名,避免了传统子查询的性能问题。
场景 2:SQL 优化建议
用户输入:\"优化这段 SQL,查询太慢\"
-- 原始SQLSELECT * FROM borrow_record WHERE user_id IN ( SELECT id FROM user WHERE role = 1) AND return_time IS NULL;AI 输出:
-- 优化后SQL(子查询转JOIN,添加索引建议)SELECT br.* FROM borrow_record brINNER JOIN user u ON br.user_id = u.idWHERE u.role = 1 AND br.return_time IS NULL;-- 索引优化建议:1. 在borrow_record表创建复合索引:(user_id, return_time) - 理由:WHERE条件包含user_id和return_time,索引可覆盖过滤条件2. 在user表创建索引:(role, id) - 理由:role是过滤条件,id用于JOIN关联,复合索引可避免回表查询-- 性能提升点:- 子查询IN改为INNER JOIN,减少临时表创建- 索引覆盖查询,避免全表扫描三、与主流工具的对比分析:技术特性与适用场景
3.1 技术架构差异的实际影响
以 “处理 10 万行代码的老项目” 为例,不同工具的表现差异:
- 飞算 JavaAI:通过本地化索引,2 分钟内完成项目架构分析,生成合并方案;
- GitHub Copilot:因需上传代码片段至云端,处理时间超过 10 分钟,且无法理解项目全局架构;
- Tabnine:仅能提供代码补全,无法进行项目级分析。
3.2 适用场景选择建议
| 场景类型| 推荐工具|核心原因|
|–|–|
|大型企业级 Java 项目|飞算 JavaAI|本地化安全 + 项目合并能力|
|多语言小型项目开发|GitHub Copilot|多语言支持 + 开源生态适配|
|基础代码补全需求|Tabnine|轻量插件,资源占用低|
|.NET 生态开发|IntelliCode|与 Visual Studio 深度集成|
四、企业级实践指南:从部署到团队协作
4.1 私有化部署与配置
飞算 JavaAI 支持企业级私有化部署,部署步骤如下:
- 环境准备:
- 服务器:8 核 16G 以上,支持 Docker
- 数据库:MySQL 8.0(存储项目索引)
- 客户端:IDEA 2020.3+
- 部署命令:
# 拉取镜像docker pull feisuankeji/javaai:enterprise-v1.0# 启动容器(映射端口与数据卷)docker run -d \\ --name javaai-enterprise \\ -p 8080:8080 \\ -v /data/javaai/index:/app/index \\ -e DB_HOST=192.168.1.100 \\ -e DB_NAME=javaai \\ -e DB_USER=root \\ -e DB_PASS=password \\ feisuankeji/javaai:enterprise-v1.0- 团队规范配置:
通过管理后台上传《团队 Java 开发规范》,系统将自动学习并应用于代码生成:
{ \"naming\": { \"class\": \"PascalCase\", \"method\": \"camelCase\", \"constant\": \"UPPER_SNAKE_CASE\" }, \"architecture\": { \"controller\": \"RESTful风格,URL前缀统一为/api\", \"service\": \"事务注解@Transactional仅用于ServiceImpl\" }, \"security\": { \"password\": \"必须使用BCrypt加密,禁止明文存储\", \"sql\": \"禁止使用SELECT *,必须指定字段\" }}4.2 团队协作流程优化
通过飞算 JavaAI 优化团队开发流程的示例:
- 需求评审阶段:产品经理用自然语言输入需求,AI 生成初步技术方案与接口文档;
- 开发阶段:开发者基于生成的代码框架进行二次开发,通过 Java Chat 实时解决技术问题;
- 代码评审阶段:AI 自动检查代码是否符合团队规范,生成评审报告;
- 测试阶段:自动生成单元测试与接口测试用例,覆盖 80% 以上核心逻辑。
**效率提升数据:**某中型企业团队接入后,需求到上线周期从 14 天缩短至 5 天,代码缺陷率下降 62%。
五、未来演进:AI 驱动的 Java 开发新范式
飞算 JavaAI 的发展方向将聚焦三个维度:
- 多模态交互:支持语音输入需求、流程图生成代码(如通过手绘架构图生成项目骨架);
- 预测性开发:基于项目历史迭代数据,提前预测可能出现的性能瓶颈与 bug;
- 低代码融合:与低代码平台联动,实现 “AI 生成代码 + 可视化配置” 的混合开发模式。
随着 AI 对开发流程的深度渗透,Java 开发者的角色将从 “代码编写者” 向 “业务架构师” 转型 —— 将更多精力投入需求拆解与业务建模,而机械性的编码工作则由 AI 高效完成。
六、结语:从工具到伙伴的开发进化
飞算 JavaAI 的价值,不仅在于减少 70% 的重复编码工作,更在于重构了 Java 开发的 “能力基线”—— 让开发者从 “能否实现” 的焦虑中解放,专注于 “如何优雅实现” 的创造。
无论是新手通过它快速跨越入门门槛,还是资深工程师借助它突破效率瓶颈,飞算 JavaAI 都展现出 “智能伙伴” 的核心定位:理解开发者的意图,适配团队的规范,守护项目的安全。在 AI 驱动开发的浪潮中,这类工具将成为 Java 生态不可或缺的基础设施,推动行业从 “人力密集型” 向 “智能驱动型” 转型。
对于开发者而言,拥抱这类工具并非被替代的开始,而是提升自身价值的必经之路 —— 毕竟,真正决定开发质量的,永远是人的创造力与业务理解能力。

