本地部署Vanna实战,快速解决NLP2SQL

一、背景
随着DeepSeek的火爆,基于AI的应用也如雨后春笋般迸发出来,如何根据用户的一句话来找到用户所需要的信息,采用传统的方式无法通过模糊匹配等实现复杂的业务场景,故探索一种新的思路来实现信息获取。Text2SQL将自然语言文本转换为SQL(结构化查询语言)语句的技术,该技术可以让用户使用自然语言来查询数据库,而无需掌握复杂的SQL语法。
二、Vanna是什么?
Vanna的核心是一个Python包,它使用检索增强功能来帮助您使用llm为数据库生成准确的SQL查询。Vanna的工作分为两个简单的步骤——在你的数据上训练一个RAG“模型”,然后问一些问题,这些问题将返回SQL查询,这些查询可以设置为自动在你的数据库上运行。
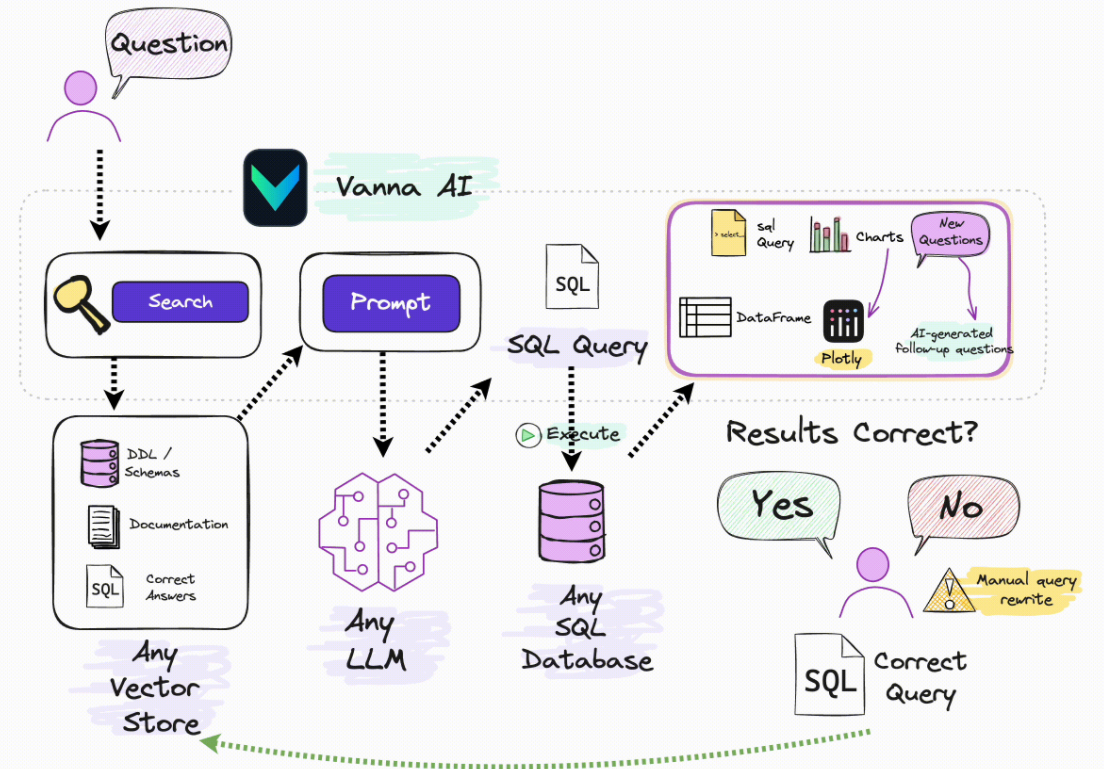
三、为啥要使用Vanna
起初是通过Dify实现Text2SQL查询,DDL语句放在提示词中,如果DDL比较多,容易造成提示词比较长,输入Token比较多,目前这种方案还处于优化中,目前只是实现此功能。另外一种方案也是想通过Vanna来实现Text2SQL查询。
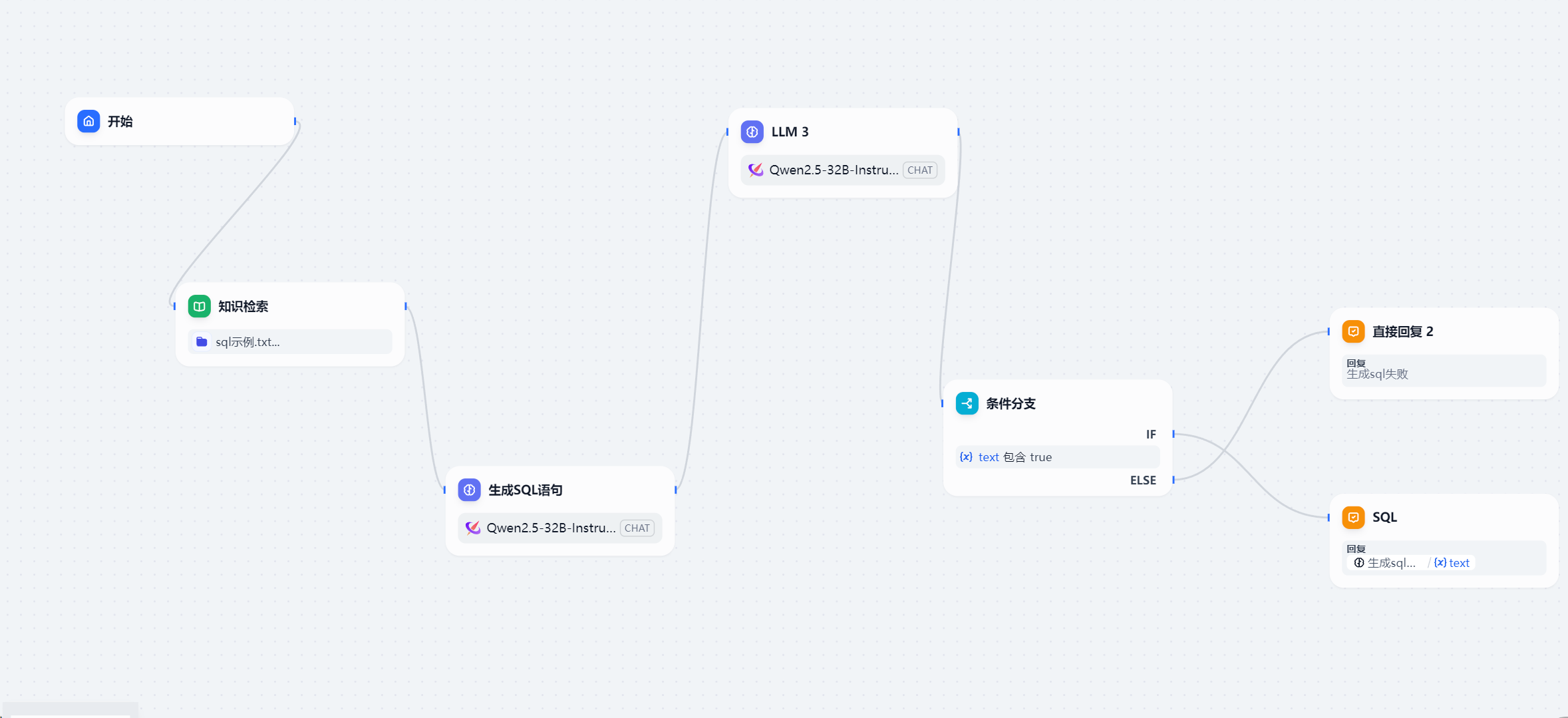
四、Vanna能力
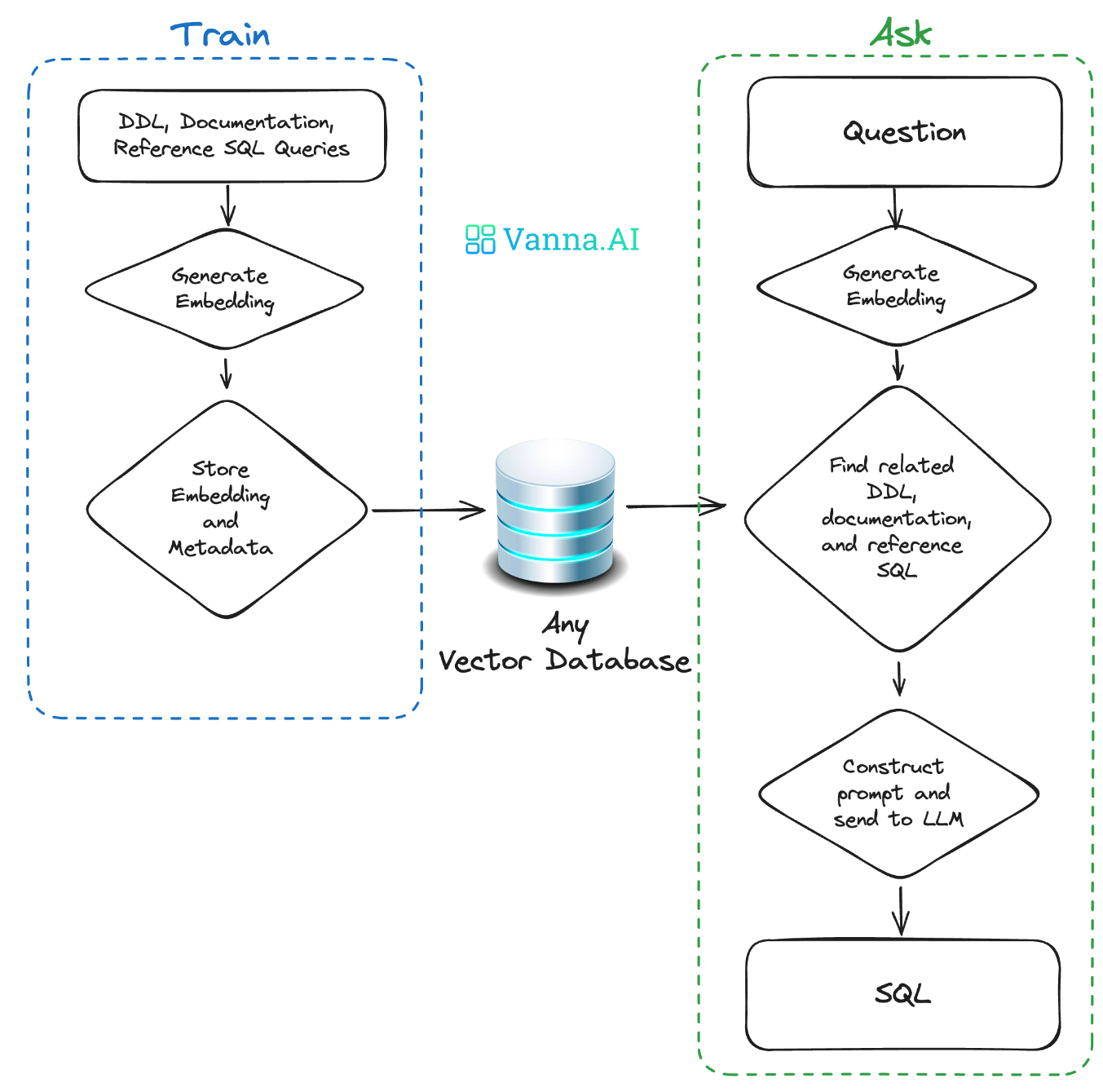
这个是参考官网的流程图,比较清楚的看出包括两部分在你的数据集上训练RAG模型和问答
4.1 训练RAG模型
把DDL/Schemas描述、文档、参考SQL等交给Vanna训练一个用于RAG检索的“模型”。Vanna的RAG模型训练,支持以下几种方式:
1、DDL语句
DDL语句有助于Vanna了解你的数据库表结构信息
vn.train(ddl=\"CREATE TABLE my_table (id INT, name TEXT)\")2、文档内容
可以是你的企业、应用、数据库相关的任何文档内容,只要有助于Vanna正确生成SQL即可,比如对你行业特有名词的解释、特殊指标的计算方式等。
vn.train(documentation=\"Our business defines XYZ as ABC\")3、SQL或者SQL问答对
即SQL的样例,这显然有助于大模型学习针对您数据库的知识,特别是有助于理解提出问题的上下文,可以大大提高sql生成正确性。
vn.train(question=\"What is the average age of our customers?\",sql=\"SELECT AVG(age) FROM customers\")4、训练计划
这是vanna提供的一种针对大型数据库自动训练的简易方法。借助RDBMS本身的数据库内元数据信息来训练RAG model,从而了解到库内的表结构、列名、关系、备注等有用信息。
df_information_schema=vn.run_sql(\"SELECT * FROM INFORMATION_SCHEMA.COLUMNS\")plan=vn.get_training_plan_generic(df_information_schema)vn.train(plan=plan)4.2 问答
提出问题,获得回答,RAG模型训练完成后,可以用自然语言直接提问。Vanna会利用RAG与LLM生成SQL,并自动运行后返回结果。
4.3 实践
基于以上初步的了解,本地环境进行部署实践,需要先初始化本地的python env,这里使用anaconnda来初始化,ollama模型部署框架,词向量嵌入模型(放在本地向量数据库的缓存目录),以及数据准备。
五、vanna部署
5.1 大模型环境
这里部赘述了,有需要的看公众号 DataSpeed 历史的文章。此处以千问模型为例
ollama run qwen:7b5.2 chromaDB本地向量数据库
vanna 默认使用 chromaDB本地向量库,chromaDB默认使用all-MiniLM-L6-v2模型。
5.3 Anaconda本地环境
需要准备一些必要的依赖
conda create -n vanna -y python=3.9conda activate vannapip install \'vanna[chromadb,ollama,mysql]\'pip install ipykernel- 若包安装时出现的 chroma-hnswlib 问题,下载vs_tools 并安装如下内容,然后重试安装依赖。
5.4 数据准备
准备一些演示数据
CREATE TABLE IF NOT EXISTS vuser ( `id` INT PRIMARY KEY COMMENT \'用户ID\', username VARCHAR(50) COMMENT \'用户名\', email VARCHAR(100) COMMENT \'电子邮件\', age INT COMMENT \'年龄\', gender VARCHAR(10) COMMENT \'性别(男/女)\', city VARCHAR(50) COMMENT \'城市\') COMMENT=\'用户信息表\' CHARACTER SET=utf8mb4 COLLATE=utf8mb4_unicode_ci;INSERT INTO vuser (`id`, username, email, age, gender, city) VALUES(1, \'张三\', \'zhangsan@example.com\', 30, \'男\', \'北京\'),(2, \'李四\', \'lisi@example.com\', 25, \'女\', \'上海\'),(3, \'王五\', \'wangwu@example.com\', 40, \'男\', \'广州\'),(4, \'赵六\', \'zhaoliu@example.com\', 35, \'女\', \'深圳\'),(5, \'小明\', \'xiaoming@example.com\', 28, \'男\', \'成都\'),(6, \'小红\', \'xiaohong@example.com\', 45, \'女\', \'重庆\'),(7, \'小华\', \'xiaohua@example.com\', 32, \'男\', \'天津\'),(8, \'小丽\', \'xiaoli@example.com\', 27, \'女\', \'南京\'),(9, \'小李\', \'xiaoli2@example.com\', 38, \'男\', \'武汉\'),(10, \'小美\', \'xiaomei@example.com\', 33, \'女\', \'西安\');5.4、Vanna启动部署
python代码demo如下:
#!/usr/bin/env python# -*- coding: utf-8 -*-\"\"\"@author: zhyaoeng@Project :vannaTest @Time : 2025/3/18 16:27@File : testv.py@Software: PyCharm# code is far away from bugs with the god animal protecting I love animals. They taste delicious. ┏┓ ┏┓ ┏┛┻━━━┛┻┓ ┃ ☃ ┃ ┃ ┳┛ ┗┳ ┃ ┃ ┻ ┃ ┗━┓ ┏━┛ ┃ ┗━━━┓ ┃ 神兽保佑 ┣┓ ┃ 永无BUG! ┏┛ ┗┓┓┏━┳┓┏┛ ┃┫┫ ┃┫┫ ┗┻┛ ┗┻┛\"\"\"from vanna.ollama import Ollamafrom vanna.chromadb import ChromaDB_VectorStorefrom vanna.flask import VannaFlaskAppclass MyVanna(ChromaDB_VectorStore, Ollama): def __init__(self, config=None): ChromaDB_VectorStore.__init__(self, config=config) Ollama.__init__(self, config=config)vn = MyVanna(config={\'model\': \'qwen:7b\',\'ollama_host\': \'http://127.0.0.1:11434\'})vn.connect_to_mysql(host=\'192.168.15.xxx\', dbname=\'las\', user=\'rot\', password=\'1234\', port=3306)# The information schema query may need some tweaking depending on your database. This is a good starting point.df_information_schema = vn.run_sql(\"SELECT * FROM INFORMATION_SCHEMA.COLUMNS\")# This will break up the information schema into bite-sized chunks that can be referenced by the LLMplan = vn.get_training_plan_generic(df_information_schema)vn.train(ddl=\"\"\"CREATE TABLE IF NOT EXISTS vuser ( `id` INT PRIMARY KEY COMMENT \'用户ID\', username VARCHAR(50) COMMENT \'用户名\', email VARCHAR(100) COMMENT \'电子邮件\', age INT COMMENT \'年龄\', gender VARCHAR(10) COMMENT \'性别(男/女)\', city VARCHAR(50) COMMENT \'城市\') COMMENT=\'用户信息表\' CHARACTER SET=utf8mb4 COLLATE=utf8mb4_unicode_ci;\"\"\")if __name__ == \'__main__\': app = VannaFlaskApp(vn) app.run()5.5 查询结果
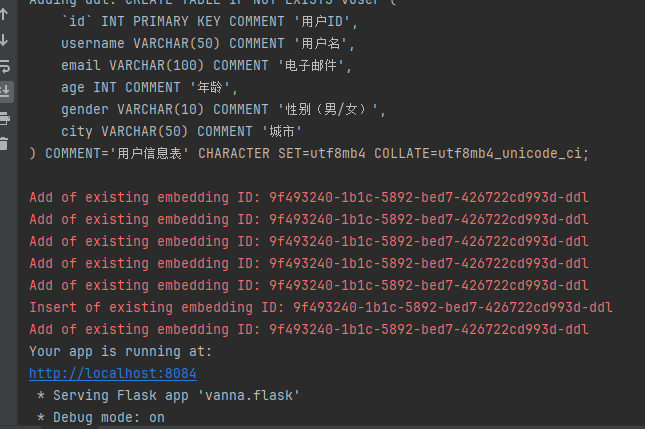
执行以上py文件后运行结果如图所示,点击http://localhost:8084进入页面
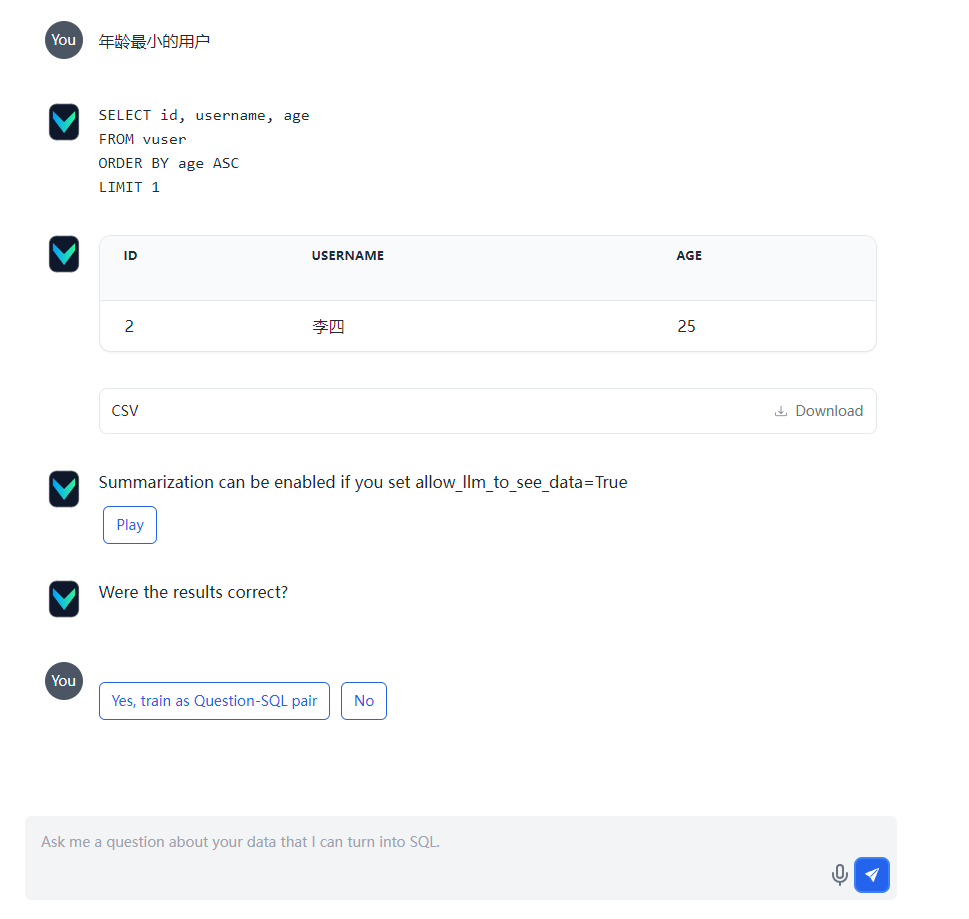
这里举个例子:
要查询表中年龄最小的用户,就会根据问题转化成对应的SQL,执行查询语句,返回结果,查询的正确结果为李四,如果查询结果正确,可以点击Yes,将此问答结果添加到训练数据中
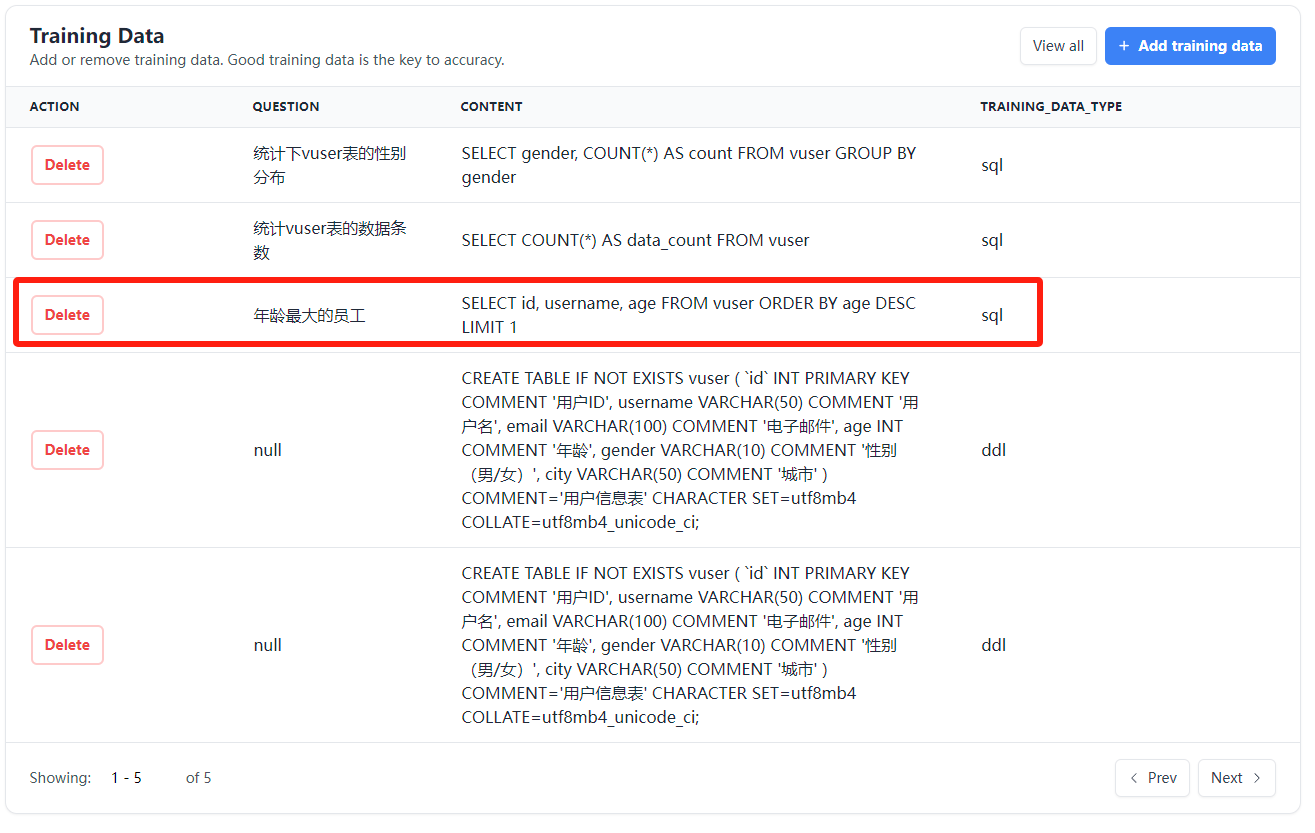
六、vanai本地化
上面代码只能进行demo验证,日常使用时还是使用本地向量库和大模型,并放在服务器上长期使用和训练。笔者搜了很多本地化的教程,大家都写的很简单,为了助力读者快速上收,我写的详细一些。
这里使用已有的qdrant向量库和ollama大模型。
6.1 添加依赖
pip install fastembedpip install PyMySQL6.2 本地化Python案例
from vanna.ollama import Ollamafrom vanna.flask import VannaFlaskAppfrom vanna.qdrant import Qdrant_VectorStorefrom qdrant_client import QdrantClientqdrant_url = \'http://xxx:6333\'ollama_url = \'http://xxx:11434\'class MyVanna(Qdrant_VectorStore, Ollama): def __init__(self, config=None): Qdrant_VectorStore.__init__(self, config=config) Ollama.__init__(self, config=config)vn = MyVanna(config={\'url\':qdrant_url,\'https\':qdrant_url,\'ollama_host\': ollama_url,\'model\': \'deepseek-r1:14b\'})vn.connect_to_mysql(host=\'192.168.15.xxx\', dbname=\'las\', user=\'rot\', password=\'1234\', port=3306)# The information schema query may need some tweaking depending on your database. This is a good starting point.df_information_schema = vn.run_sql(\"SELECT * FROM INFORMATION_SCHEMA.COLUMNS\")# This will break up the information schema into bite-sized chunks that can be referenced by the LLMplan = vn.get_training_plan_generic(df_information_schema)vn.train(ddl=\"\"\"CREATE TABLE IF NOT EXISTS vuser ( `id` INT PRIMARY KEY COMMENT \'用户ID\', username VARCHAR(50) COMMENT \'用户名\', email VARCHAR(100) COMMENT \'电子邮件\', age INT COMMENT \'年龄\', gender VARCHAR(10) COMMENT \'性别(男/女)\', city VARCHAR(50) COMMENT \'城市\') COMMENT=\'用户信息表\' CHARACTER SET=utf8mb4 COLLATE=utf8mb4_unicode_ci;\"\"\")if __name__ == \'__main__\': app = VannaFlaskApp(vn) app.run()6.3 代码解释
代码关键在于 MyVanna与config的参数如何写,也是很多教程没说清楚的地方。
class MyVanna(Qdrant_VectorStore, Ollama): def __init__(self, config=None): Qdrant_VectorStore.__init__(self, config=config) Ollama.__init__(self, config=config)vn = MyVanna(config={\'url\':qdrant_url,\'https\':qdrant_url,\'ollama_host\': ollama_url,\'model\': \'deepseek-r1:14b\'})授人以鱼不如授人以渔,其实关键要看源码,以Qdrant_VectorStore为例,源码中是对config做出了要求,下面是Qdrant_VectorStore.__init__的config关键代码,因此要在config增加url这个key。 其他的向量或大模型可以参照这个方式来解决。
if client is None: self._client = QdrantClient( location=config.get(\"location\", None), url=config.get(\"url\", None), prefer_grpc=config.get(\"prefer_grpc\", False), https=config.get(\"https\", None), api_key=config.get(\"api_key\", None), timeout=config.get(\"timeout\", None), path=config.get(\"path\", None), prefix=config.get(\"prefix\", None), )七、总结
vanna可以结合自己的数据库以及向量库进行先训练后问答,这一块儿可以参考官网https://vanna.ai/docs/app/,官网还提供了使用 Vanna 构建一个网站应用程序或者一个应用程序接口(API)https://github.com/vanna-ai/vanna-flask,欢迎大家一起探讨学习。

