AI 视频生成新突破:FramePack 开源项目引领视频扩散技术变革 一键汉化整合包 FramePack-F1 20250628更新 支持magcache加速_framepack整合包
FramePack 是一个开源项目,旨在通过创新的神经网络结构实现高效的视频生成。以下是对其的详细介绍:
项目概述
FramePack 是 “Packing Input Frame Contexts in Next - Frame Prediction Models for Video Generation” 论文的官方实现和桌面软件。它采用逐帧(或逐帧段)预测的方式生成视频,能将输入上下文压缩到固定长度,使生成工作负载与视频长度无关,即使在笔记本 GPU 上,13B 模型也能处理大量帧。
优势特点
-
低资源要求 :对于生成 1 分钟(60 秒)30fps(1800 帧)的视频,最低只需 6GB GPU 显存,适合在 RTX 30XX、40XX、50XX 系列的 Nvidia GPU 上运行,GTX 10XX/20XX 未测试。
-
高效性 :在 RTX 4090 桌面 GPU 上,生成速度为 2.5 秒 / 帧(未优化)或 1.5 秒 / 帧(启用 teacache),即使在 3070ti 或 3060 笔记本 GPU 上,也仅是慢 4 - 8 倍,并且生成过程可实时看到帧反馈。
-
大批次训练 :能像图像扩散训练一样使用较大批次大小进行训练。
安装与使用
-
安装 :目前该项目是一个功能性的桌面软件,Windows 的一键安装包即将推出。Linux 系统下,推荐使用独立的 Python 3.10 环境,通过 pip 安装 torch、torchvision、torchaudio 等依赖,并安装 requirements.txt 中的其他要求。还支持多种注意力机制,如 PyTorch attention、xformers、flash - attn、sage - attention,默认使用 PyTorch attention,也可根据需要安装其他注意力内核。
-
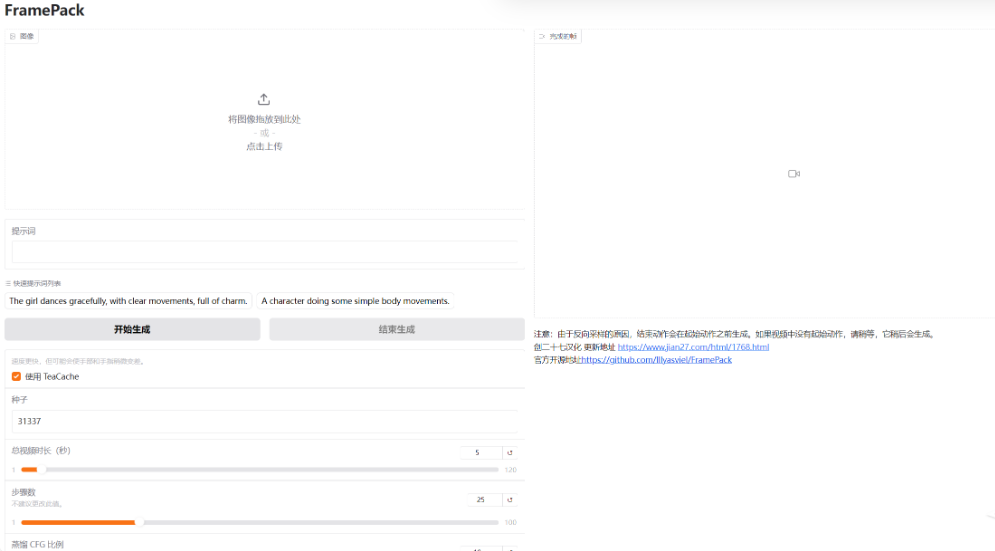
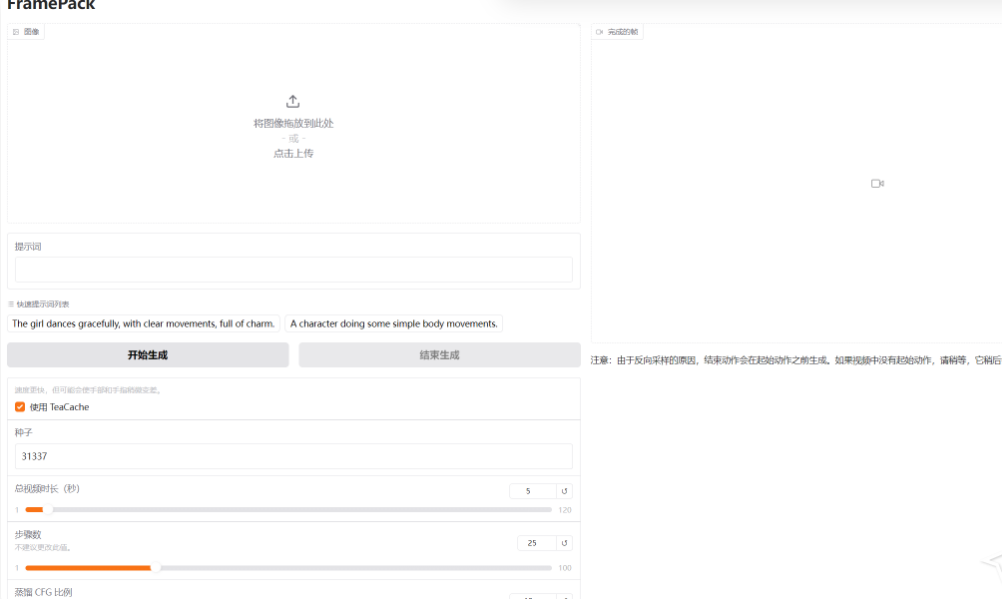
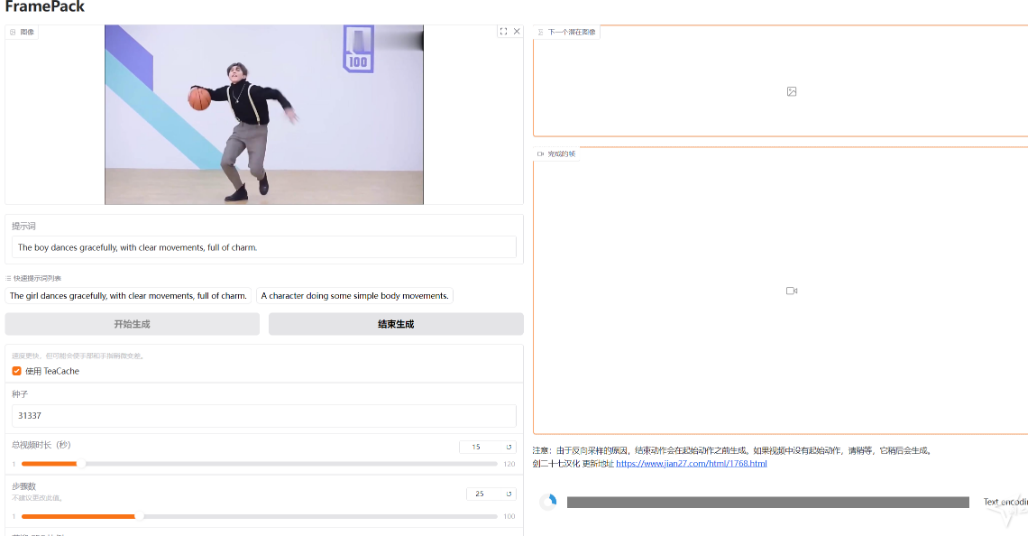
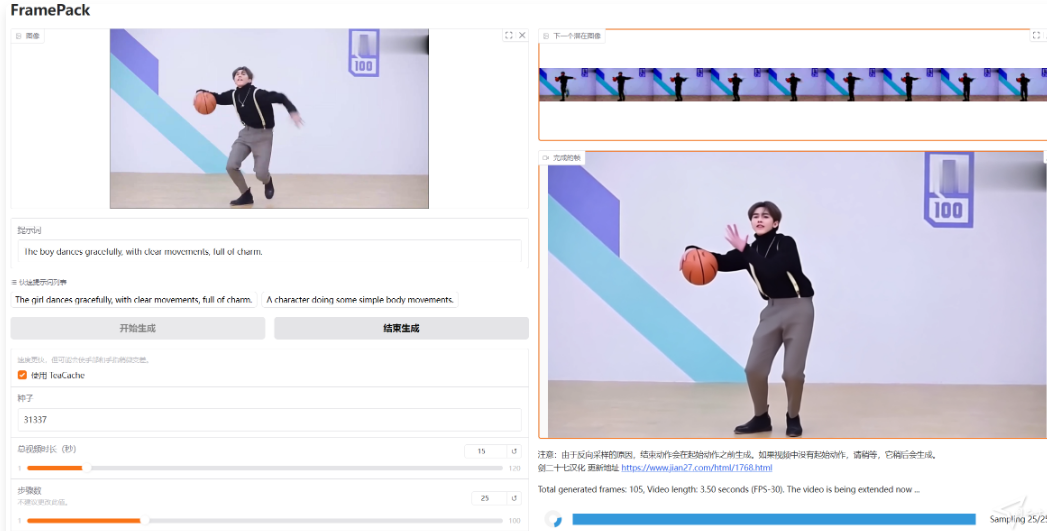
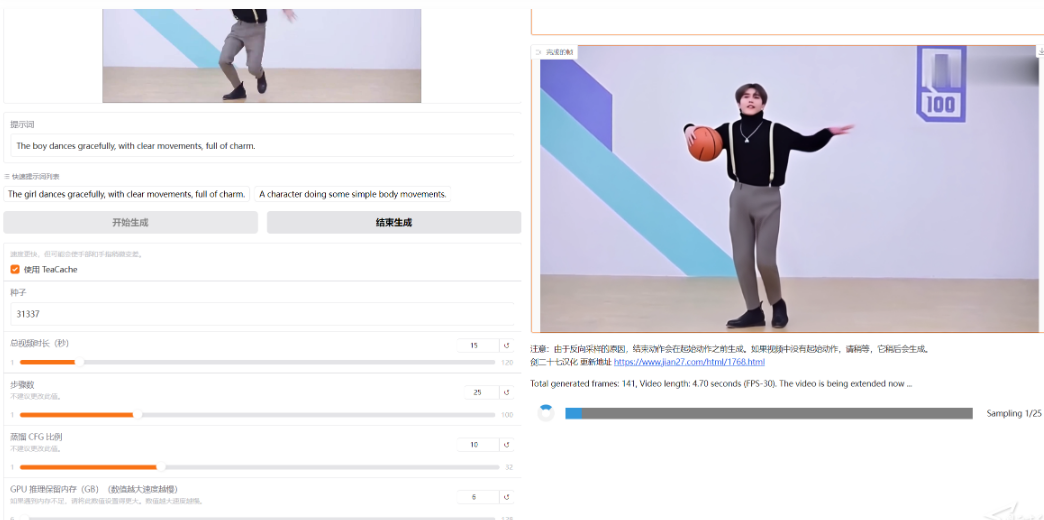
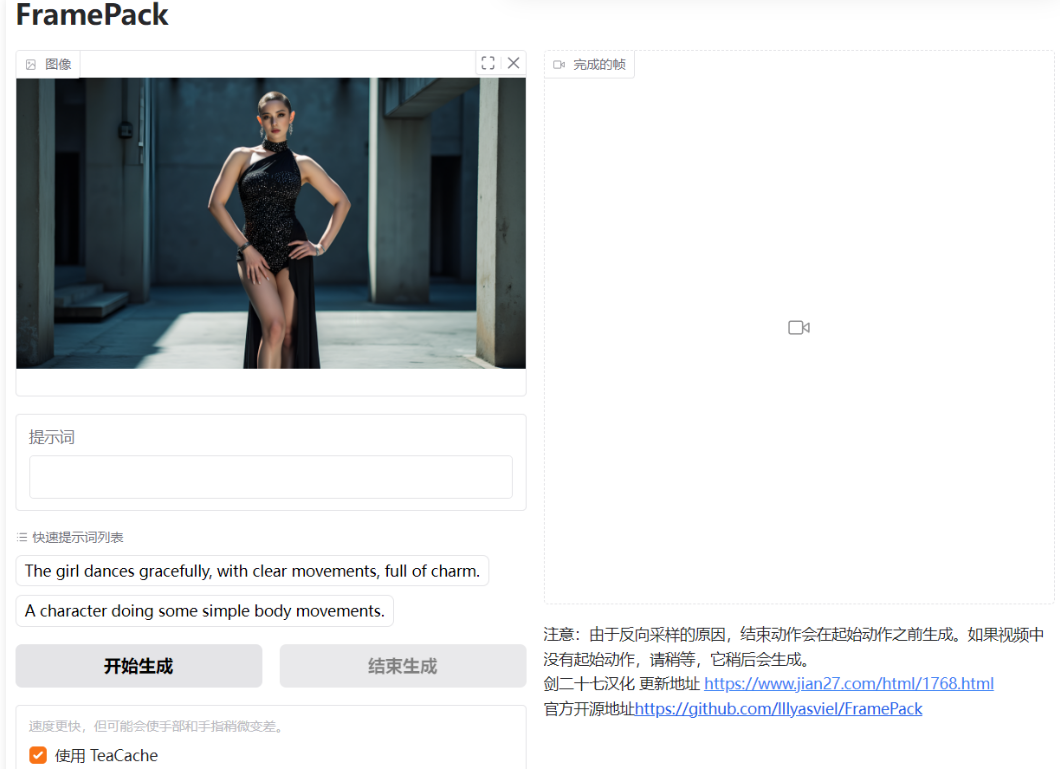
使用 :其 GUI 界面简洁,左侧上传图像并输入提示词,右侧显示生成的视频和潜在预览。由于是逐帧段预测模型,视频会越来越长,可看到每个部分的进度条和下一区域的潜在预览。初始进度可能较慢,因为设备需要预热。
示例与指南
项目提供了多个示例,如 “Image - to - 5 - seconds”“Image - to - 1 - minute” 等,用户可下载示例图像,复制提示词,按照指定参数设置进行操作,观察生成结果。还给出了使用 ChatGPT 生成提示词的模板,帮助用户编写更有效的提示词。
注意事项
-
TeaCache 和量化等技术虽能提高速度,但可能会影响结果质量,建议先用这些技术尝试想法,再用完整扩散过程获得高质量结果。
-
不同设备可能会得到略有不同的结果,但总体应相似,在某些情况下可能完全相同。
总之,FramePack 为视频生成领域提供了一种高效、实用的解决方案,具有广阔的应用前景。
整合包说明
1 汉化界面
2 功能未做任何修改
3 自行安装好cuda12.4
4 再次感谢大神lllyasviel无私分享
5 官方的整合包和我制作的整合包 区别有3个 a cuda版本不同,b 官方整合包还需要下载模型文件 c 官方是英文的
20250505 更新
1 未做任何修改,保持原汁原味
2 自行安装好cuad12.4
3 更新到FramePack-F1
20250511 更新
1 支持批量生成视频
2 自行安装好cuad12.4
3 详细介绍说明 https://github.com/chuckkay/QueueItUp_FramePack/blob/QueueItUp/
视频演示地址:
https://www.bilibili.com/video/BV1Y95rztEHd?t=0.2
20250628 更新记录
1 支持magcache 加速,据作者说可以提速加速2.25-2.45倍的样子,我实测确实有效。
2 AI环境安装了xFormers 按理说也会提升处理速度
3 cuda还是12.4,下次看看升级到12.8
下载地址
夸克网盘

