人类最后的考试:HLE基准测试如何重新定义AI能力的边界_hle测试
当GPT-4在MMLU(大规模多任务语言理解)基准测试中突破90%准确率时,AI研究界既兴奋又困惑。这个曾经被视为衡量语言模型能力\"圣杯\"的测试,突然失去了区分最先进模型的能力。2025年1月,由AI安全中心(Center for AI Safety)和Scale AI联合发布的HUMANITY’S LAST EXAM(HLE) 基准测试,为这个困境提供了全新的解决方案——一个被设计为\"人类最后一场考试\"的终极评估体系。
为什么我们需要一场\"最后的考试\"?
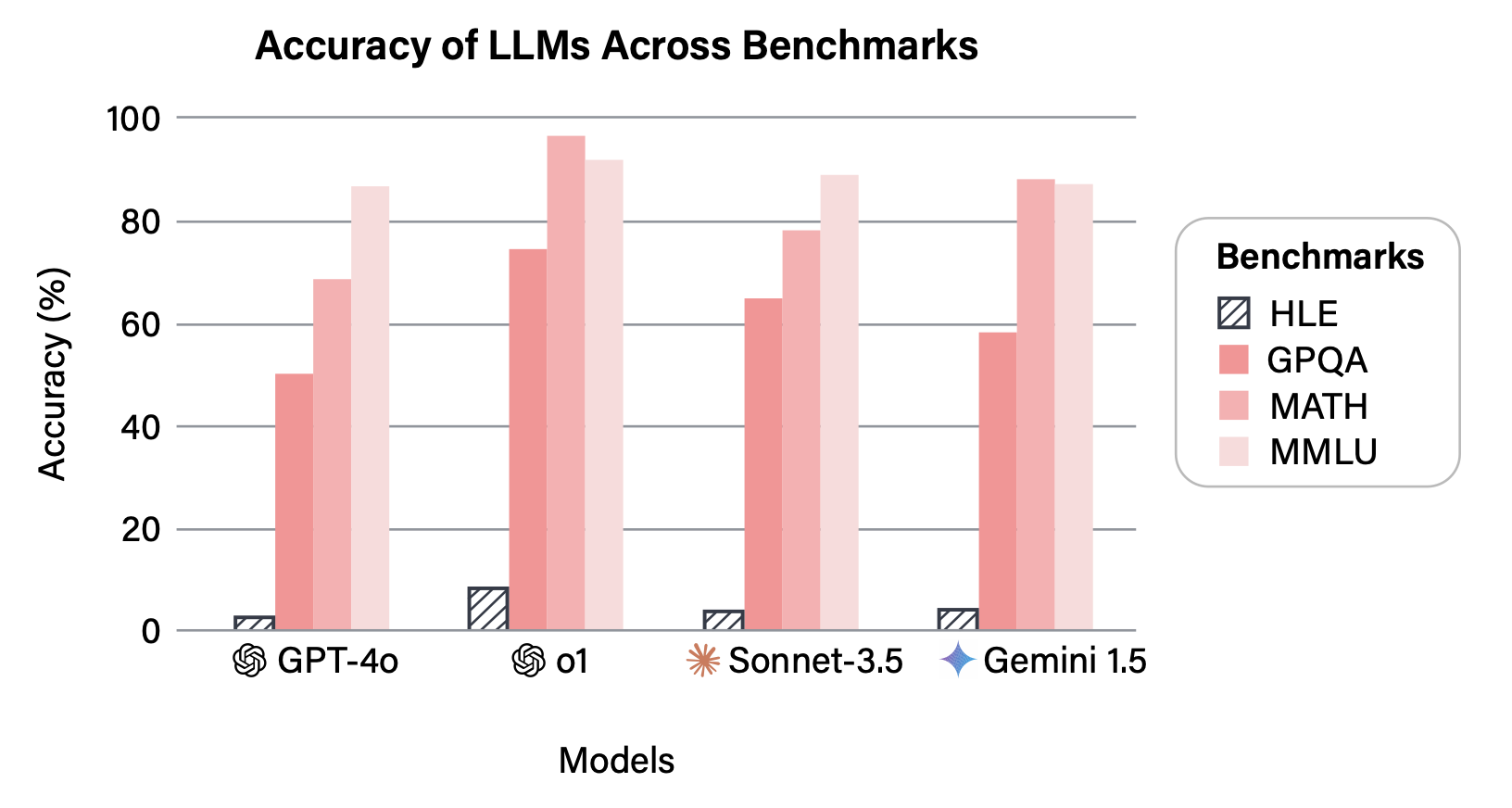
现有AI基准测试正面临严峻的\"饱和危机\"。论文中展示的对比数据显示,当前最先进的LLM在MMLU等经典测试中已达到90%以上的准确率,这意味着这些曾经极具挑战性的基准已无法有效区分模型能力的细微差异。正如研究团队所指出的:“当所有模型都能拿到A+时,成绩单就失去了意义。”
HLE的诞生源于一个核心洞察:评估工具必须与AI发展速度同步进化。传统基准存在三大局限:
- 难度停滞:问题设计跟不上模型能力提升,导致\"天花板效应\"
- 可搜索性:许多问题答案可通过简单网络检索获得,测试的是记忆而非推理
- 覆盖面窄:难以全面评估跨学科的专家级知识
HLE的创新之处在于它直接瞄准\"人类知识前沿\",专注于那些即使对领域专家也具有挑战性的问题。这些问题无法通过简单搜索解决,必须依赖深度推理和专业知识才能回答。
HLE基准测试的构建:全球智慧的结晶
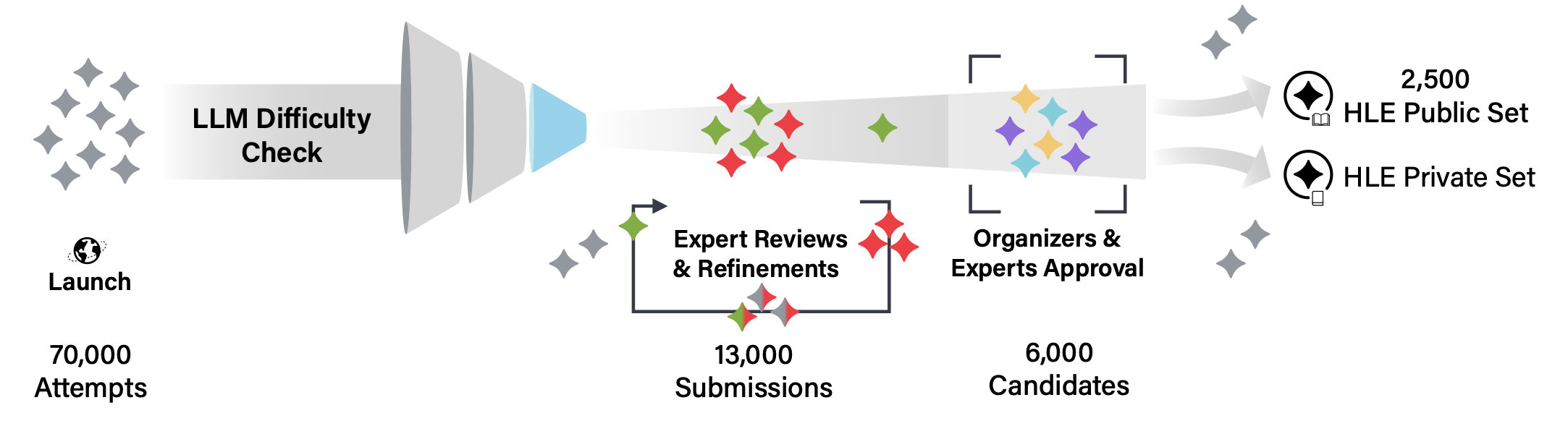
HLE的2500道题是全球协作的产物,来自近1000名学科专家的贡献,他们分别隶属于50个国家的500多所机构,其中绝大多数拥有教授、研究员或研究生学历。这个庞大的创作者网络确保了问题的专业性和多样性。
严格的筛选机制
HLE采用了多阶段过滤流程,确保每道题都能真正检验最先进AI的能力:
-
LLM难度预检测:所有题目首先会接受当前最先进LLM的\"挑战\"。只有那些所有模型都无法正确回答(单选题允许一个模型答对,以排除运气因素)的题目才会进入下一阶段。这个过程累计记录了70,000多次尝试,最终约13,000道\"难住\"AI的题目进入专家评审。
-
两轮专家评审:
- 第一轮:由拥有研究生学历的领域专家根据标准化评分表进行评估,重点关注问题的原创性、难度和清晰度
- 第二轮:由组织者和资深评审员从通过第一轮的题目中精选出最终入选的问题
-
社区反馈与审计:发布后还会通过社区反馈机制和专门的审计团队进一步优化,确保问题的准确性和公平性
这种严苛的筛选流程使得HLE的每一道题都经过了AI和人类专家的双重验证,确保其能有效衡量\"人类级专家知识\"。
丰富的题型与学科覆盖
HLE包含两种主要题型:精确匹配题(要求模型输出特定字符串)和多选题(通常有5个或更多选项)。作为一个多模态基准,约14%的问题需要结合文本和图像理解才能回答,其余为纯文本问题(24%为多选题,76%为精确匹配题)。
学科覆盖极为广泛,超过100个学科,主要类别包括:
- 数学(41%)
- 生物学/医学(11%)
- 计算机科学/人工智能(10%)
- 物理(9%)
- 工程学(9%)
- 化学(7%)
- 人文社科(4%)
- 其他(9%)
这种分布反映了HLE对深度推理能力的重视,特别是数学推理,因为研究团队认为数学能力是跨学科通用推理能力的重要指标。
题目示例:窥见HLE的难度与广度
HLE的题目设计既专业又富有挑战性,让我们通过几个示例来感受其特点:
数学题
两个函子F₁, G: C → D之间的自然变换集合可以表示为端(end):
Nat(F, G) ≅ ∫ᵃ Hom_D(F(A), G(A))
定义从F到G的自然余变换集合为余端(coend):
CoNat(F, G) ≅ ∫^A Hom_D(F(A), G(A))
设:
F = B·(∑₄),即4元对称群∑₄的delooping的神经的under ∞-范畴,在B∑₄的唯一0-单形下
G = B·(∑₇),即7元对称群∑₇的delooping的神经的under ∞-范畴,在B∑₇的唯一0-单形下
问:F和G之间有多少个自然余变换?
这道题不仅要求掌握范畴论的基本概念,还需要对对称群和∞-范畴有深入理解,显然超出了普通研究生的知识范围,属于专业研究级别的问题。
生态学题
雨燕目(Apodiformes)中的蜂鸟独特地拥有一对双侧卵圆形骨,这是一种籽骨,嵌入在尾部降肌(m. depressor caudae)扩张的十字形止点腱膜的尾外侧部分。这个籽骨支撑着多少对肌腱?请用数字回答。
这类问题测试的是极其专业的解剖学知识,需要特定领域的深入研究背景,无法通过常识或基础教科书知识回答。
计算机科学题
设G为一个图。G的边指示器是一个函数a: {0,1} → V(G),使得{a(0), a(1)} ∈ E(G)。
考虑如下马尔可夫链M = M(G):
M的状态空间是G的所有边指示器的集合,转移定义如下:
假设Mₜ = a。
- 均匀随机选择b ∈ {0,1}
- 均匀随机选择v ∈ N(a(1-b))(其中N(v)表示v的开邻域)
- 设a’(b) = v且a’(1-b) = a(1-b)
- 设Mₜ₊₁ = a’
我们称图类G是\"行为良好的\",如果对于每个G ∈ G,马尔可夫链M(G)收敛到唯一的平稳分布,且这个唯一的平稳分布是均匀分布。
以下哪个图类是行为良好的?
这类问题将图论与概率理论结合,要求对马尔可夫链的收敛性有深刻理解,同时需要具备证明和推理能力。
这些示例表明,HLE的问题不仅需要专业知识,还强调深度推理、跨概念连接和创造性思维,正是当前AI系统的薄弱环节。
AI在HLE上的表现:差距依然巨大
对当前最先进LLM的测试结果揭示了一个明确的事实:在人类知识前沿领域,AI还有很长的路要走。测试数据显示,所有模型在HLE上的准确率都极低:
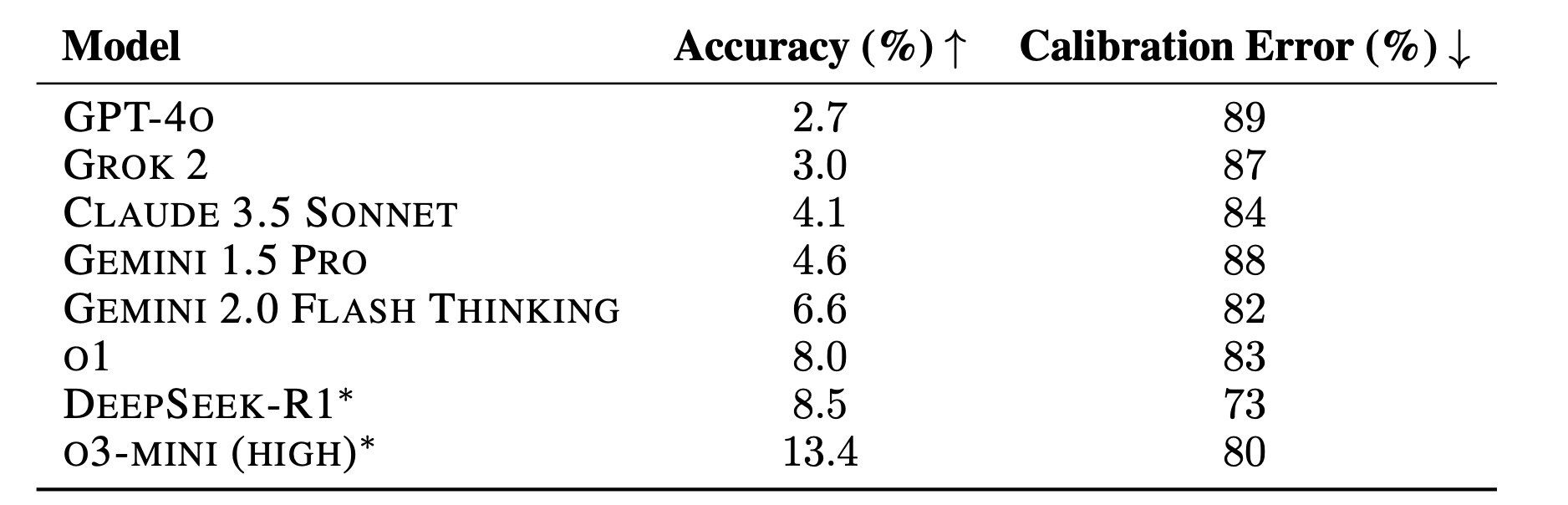
更令人担忧的是模型的校准误差(RMS calibration error)普遍很高(均超过70%)。这意味着模型在给出错误答案时往往自信心爆棚,而不是承认自己的无知。这种\"过度自信\"是AI安全领域的一个重要关注点,因为它可能导致在高风险场景中做出错误决策。
分学科来看,模型在各领域的表现也存在差异:
- O3-MINI在数学(18.6%)和工程学(6.5%)上表现相对较好
- DEEPSEEK-R1在计算机科学/AI(7.5%)和人文社科(10.4%)上表现突出
- O1在物理学(6.9%)和化学(10.0%)上相对领先
但总体而言,所有模型在所有领域的表现都远低于人类专家水平,这表明HLE成功捕捉到了当前AI的能力边界。
HLE的意义与未来影响
HLE不仅仅是一个测试,它代表了评估AI能力的新思路,具有多方面的重要意义:
为研究提供基准
HLE为AI研究提供了一个清晰的目标和衡量标准。随着模型在HLE上的表现提升,我们可以更精确地追踪AI在专家级知识和推理能力上的进步。研究团队预测,到2025年底,模型可能在HLE上达到50%的准确率,这将标志着AI在封闭性学术问题上接近人类专家水平。
助力政策制定
通过提供AI能力的清晰测量,HLE有助于政策制定者更好地理解AI发展的实际进度,从而制定更合理的治理措施和安全标准。当AI在HLE上达到特定里程碑时,可能需要相应的监管框架调整。
促进安全研究
HLE的低准确率和高校准误差结果凸显了当前AI系统的局限性,特别是在处理复杂、专业问题时的不可靠性。这为AI安全研究提供了方向,如如何提高模型的自我认知能力,使其在面对超出能力范围的问题时能够适当表达不确定性。
超越HLE的未来
值得注意的是,研究团队强调HLE可能是\"最后一场学术考试\",但绝非AI的最后一个基准。因为HLE主要测试封闭性问题的解决能力,而真实世界的许多挑战涉及开放性研究、创造性问题解决和跨领域协作,这些都需要新的评估方法。
HLE的发布还伴随着一个重要举措:公开2500道题作为基准,同时保留一个私有测试集以检测模型是否存在过拟合。这种做法平衡了透明度和评估的有效性,确保HLE能在未来一段时间内保持其作为AI能力衡量标准的价值。
结语:在人类与AI的边界上
HUMANITY’S LAST EXAM这个名字既大胆又意味深长。它不仅是对当前AI能力的终极考验,也象征着人类对自身知识边界的反思。当AI最终能在HLE上取得优异成绩时,这不仅标志着AI的进步,也意味着人类创造了能够理解并扩展自身知识边界的工具。
HLE提醒我们,AI的真正价值不在于超越人类,而在于与人类协作,共同探索未知的知识领域。在这个意义上,\"人类最后的考试\"或许将成为AI与人类共同智慧的新起点,而非终点。
通过HLE,我们不仅能更好地衡量AI的进步,也能更深刻地理解人类智能的独特之处,从而在AI快速发展的时代找到人类与机器协作的最佳平衡点。随着HLE的不断完善和应用,它必将在AI研究、安全和治理领域发挥越来越重要的作用,帮助我们负责任地推动AI技术的发展,使其真正造福人类。


