小红书关键词搜索爬虫_小红书关键词爬取
文章目录
- 一、简介
- 二、工具设计
-
- 2.1界面设计
- 2.2流程设计
- 三、代码实现
-
- 3.1.界面代码实现
- 3.2.内容爬取代码实现
- 3.3.总体实现
一、简介
一款小红书爬虫工具,可以根据关键词进行搜索下载笔记内容,可以设置搜索条数、搜索内容!
(1)输出表格:博主ID、关键词、三连数、笔记链接等
(2)以笔记标题为目录存储笔记图片;
二、工具设计
工具设计初衷是为了针对小红书运营专员方便进行相关词条进行笔记检索,方便根据三连数、关键词等参数进行快速过来和内容整理,主要是提高该部分从业人员的工作效率,那么主要需要包含以下一个强需求:
- 要能够有边界的操作界面;
- 要支持多个过滤参数配置;
- 要能够支持进行循环中断检索;
- 要能够有较为清晰的操作提示;
2.1界面设计
离线工具且界面要求简单易操作,这里选择使用Tkinter作为UI开发工具;
采用最简单的网格布局如下:
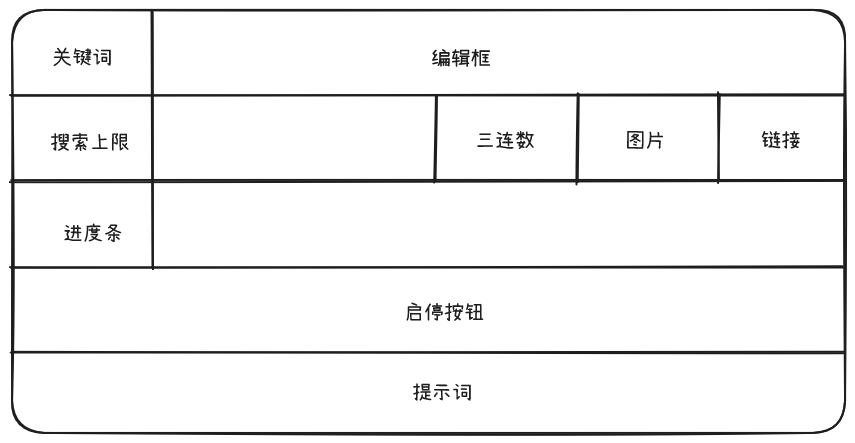
根据要求界面设计如下:

2.2流程设计
2.2.1.明确需求
主要就是能够进行关键词检索后能够拿到各个笔记的URL,通过分析小红书每个笔记的URL其中都用较为固定的ID和token部分,例如:
https://www.xiaohongshu.com/explore/667ad3cf000000001d01530f?xsec_token=ABLSu50SAsII4x9OxuH2KHDa3qraPRWiPww25jEweu7cA=&xsec_source=pc_search&source=web_search_result_notes
其中:667ad3cf000000001d01530f为ID
ABLSu50SAsII4x9OxuH2KHDa3qraPRWiPww25jEweu7cA=为token
2.2.2.抓包分析
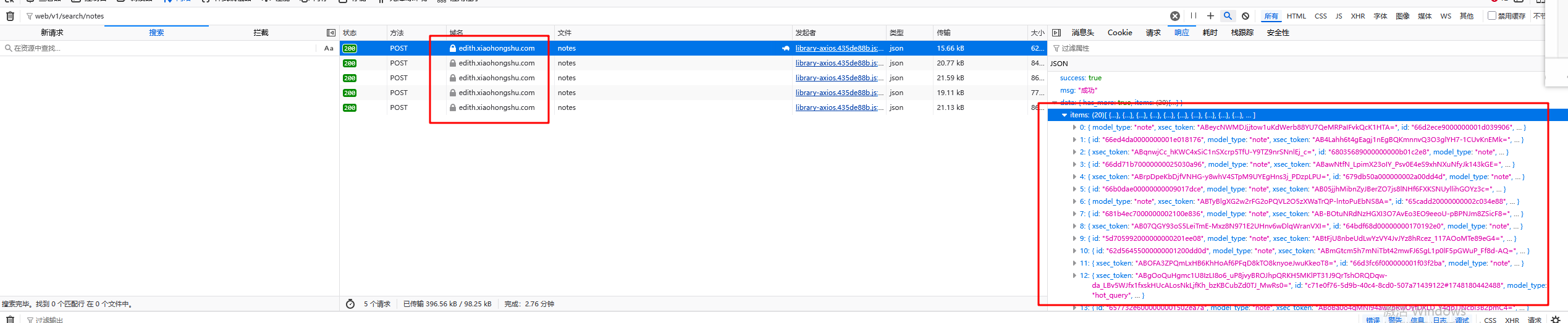
通过抓包分析和过滤发现,例如根据上述token来进行搜索,会发现在这条web/v1/search/notesURL中会有上述两个字段的返回记录,那么我们可以断定该条URL的返回请求肯定包含着大量的被检索出的笔记URL;

于是针对关键词检索时的所有URL进行过滤发现,与预期一致:
2.2.3.发送请求
- 关键词搜索
由于小红书官网限制针对关键词搜索时必须进行登录后才能操作,那么通过抓包分析发现小红书请求标头有两个字段X-s和X-S-Common无法直接模拟获取(需要能够掌握逆向技术),那么这个就大大提高的爬虫门槛;
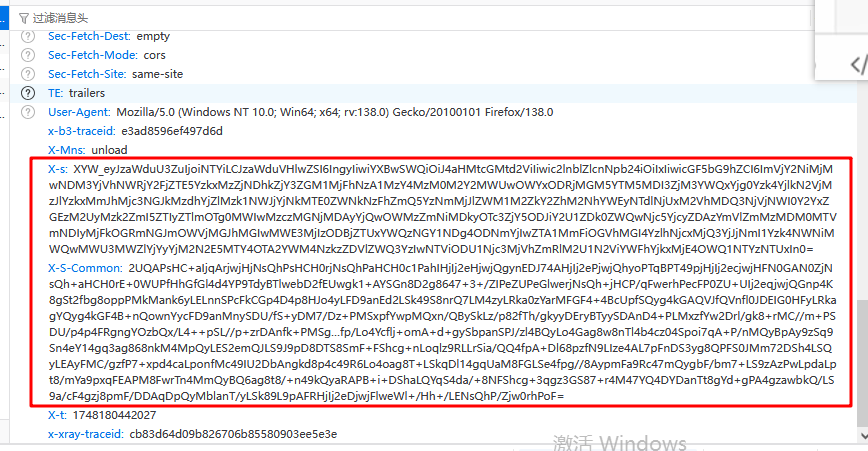
那么针对这种情况,我们想到了DrissionPage通过真实的用户登录操作来实现该步骤!
这里的DrissionPage在使用前一定要先设置下他的启动路径,但是只要设置一次就够了!
from DrissionPage import ChromiumOptionspath = r\'D:\\my_chrome_path\\chrome.exe\'# 这里设置你自己电脑的chrome可执行程序路径ChromiumOptions.set_browser_path(path).save()- 笔记内容请求
由于单独请求和访问某条笔记内容链接无需登录操作,那么我们可以直接使用老办法request来进行模拟请求!
2.2.4.获取解析数据
- 通过元素面板定位数据标签来获取数据内容;
- 监听数据包获取响应数据(推荐);
2.2.5.保存数据
笔记内容等文字数据存储到表格中,图片直接写入固定目录中;这里采用openpyxl来操作表格。
三、代码实现
3.1.界面代码实现
import tkinter as tkfrom tkinter import ttkimport threading# 设置全局字体主题font_style = { \'family\': \'微软雅黑\', \'size\': 12, \'weight\': \'bold\'}# tkinter主体root = tk.Tk()root.title(\"小红书爬虫\")root.eval(\'tk::PlaceWindow . center\') # 居中窗口root.resizable(False, False) # 禁用窗口大小调整# 第一行tk.Label(root, text=\"关键词\", font=font_style).grid(row=0, column=0, padx=5, pady=5)keyword = tk.Entry(root)keyword.insert(0, \"大有泰\")keyword.grid(row=0, column=1, columnspan=4, padx=5, pady=5, sticky=\"ew\")# 第二行 搜索上限 和 配置项tk.Label(root, text=\"搜索上限\", font=font_style).grid(row=1, column=0, padx=5, pady=5)limitcount = tk.Entry(root)limitcount.insert(0, \"50\")limitcount.grid(row=1, column=1, padx=5, pady=5)# 默认:博主、内容、关键词# 可选:三连、图片、链接sanlian_var = tk.BooleanVar(value=True)tk.Checkbutton(root, text=\"三连\", variable=sanlian_var, font=font_style).grid(row=1, column=2, sticky=\"w\")pic_var = tk.BooleanVar(value=True)tk.Checkbutton(root, text=\"图片\", variable=pic_var, font=font_style).grid(row=1, column=3, sticky=\"w\")link_var = tk.BooleanVar(value=True)tk.Checkbutton(root, text=\"链接\", variable=link_var, font=font_style).grid(row=1, column=4, sticky=\"w\")# 第三行 搜索进度tk.Label(root, text=\"搜索进度\", font=font_style).grid(row=2, column=0, padx=5, pady=5)progress_bar = ttk.Progressbar(root, mode=\"determinate\")progress_bar.grid(row=2, column=1, columnspan=3, padx=5, pady=5, sticky=\"ew\")progress_text = tk.StringVar(value=\"0%\")tk.Label(root, textvariable=progress_text, font=font_style).grid(row=2, column=4, padx=5, pady=5)# 全局参数stop_event = threading.Event() # 设置线程事件用于控制线程启停running_thread = None # 保存线程对象# 主线程 -- 具体内容在下一部分实现def long_task():pass# 启停按钮处理函数def btn_func(): global running_thread thread_param = {} if btn_var.get() == \"开始\": if keyword.get() == \"\": messagebox.showerror(\"错误\", \"请输入搜索关键词\") return btn_var.set(\"结束\") keyword.config(state=\"disable\") if not running_thread or not running_thread.is_alive(): stop_event.clear() # 重置停止标志 progress_bar[\'value\'] = 0 # 初始化进度条值 running_thread = threading.Thread(target=long_task, daemon=True) running_thread.start() mesg_text.set(\"开始\") else: btn_var.set(\"开始\") keyword.config(state=\"normal\") if running_thread and running_thread.is_alive(): stop_event.set() # 设置停止标志# 第四行 启停按钮btn_var = tk.StringVar()btn_var.set(\"开始\")tk.Button(root, textvariable=btn_var, command=btn_func, font=font_style).grid(row=3, column=0, columnspan=5, padx=5, pady=5, sticky=\"ew\")# 第五行 动态变化提示信息mesg_text = tk.StringVar(value=\"就绪\")tk.Label(root, textvariable=mesg_text).grid(row=4, column=0, columnspan=5, padx=5, pady=5, sticky=\"w\")root.mainloop()3.2.内容爬取代码实现
# 导入数据请求模块import requests# 导入正则表达式模块import re# 导入文件操作模块import os# 导入自动化模块from DrissionPage import ChromiumPage# 导入url编码模块from urllib.parse import quote# 打开浏览器 (实例化浏览器对象)g_browser_handle = ChromiumPage()# 监听数据包-用于获取根据关键词返回的所有笔记URLg_browser_handle.listen.start(\'web/v1/search/notes\')# 模拟浏览器请求单个笔记URL的标头headers = { # cookies \'Cookie\': \'code your cookie here\', # referer 防盗链, 请求网址从哪里跳转过来 \'referer\': req_url, # user-agent 用户代理, 表示浏览器/设备基本身份信息 \'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 \' \'Safari/537.36 \'}# 关键词输入key_word = \"python爬虫\"key_word_url = quote(key_word)req_url = f\"https://www.xiaohongshu.com/search_result?keyword={key_word_url}&source=web_explore_feed&type=51\"# 访问网站g_browser_handle.get(req_url)# 等待数据包加载r = g_browser_handle.listen.wait()# 获取响应数据 -> 字典数据json_data = r.response.body# 键值对取值, 提取ID和token所在列表items = json_data[\'data\'][\'items\']print(f\"搜索条数:{len(items)}\")# 判断文件夹是否存在--用于存储图片if not os.path.exists(\'img\'): os.mkdir(\'img\')# for循环遍历, 提取列表里面的元素for item in items: try: # 提取ID id_ = item[\'id\'] # 提取博主昵称 uper = item[\'note_card\'][\'user\'][\'nick_name\'] print(f\"uper:{uper}\") # 提取token token = item[\'xsec_token\'] # 单个笔记的请求网址 url = f\'https://www.xiaohongshu.com/explore/{id_}?xsec_token={token}&xsec_source=pc_search\' print(url) # 发送请求 response = requests.get(url=url, headers=headers) \"\"\"获取数据\"\"\" # 获取响应的文本数据 html = response.text \"\"\"解析数据\"\"\" # 提取帖子标题 old_title = re.findall(\'\', html)[0] # 替换特殊字符 title = re.sub(r\'[\\\\/:*?\"|\\n]\', \' \', old_title) #print(old_title) # 提取帖子内容 note_content = re.findall(\'\', html)[0] # 提取帖子关键词 note_keywords = re.findall(\'\', html)[0] # 提取帖子点赞数 note_like = re.findall(\'\', html)[0] # 提取帖子收藏数 note_collect = re.findall(\'\', html)[0] # 提取帖子评论数 note_comment = re.findall(\'\', html)[0] print(f\"Like:{note_like} Collect:{note_collect} Comment:{note_comment}\") print(f\"-----------------------------------------------------------------------\") # 提取帖子图片链接 img_list = re.findall(\'\', html) # 定义序号 num = 1 # for循环遍历, 提取列表里面的元素内容 for img in img_list: # 对于图片链接发送请求, 获取二进制数据 img_content = requests.get(url=img).content # 数据保存 with open(\'img\\\\\' + title + str(num) + \'.jpg\', \'wb\') as f: # 写入数据 f.write(img_content) num += 1 except Exception as e: print(e)该部分逻辑只实现了首次打开关键词搜索页面时的数据获取,但是大部分网址都会随着页面侧面滑条下滑动态请求新的数据,那么小红书也是同样的原理,所以为了获取更多的数据,我们还需要实现滑条下滑的动作!
from DrissionPage.common import Actionsfrom DrissionPage import ChromiumPage# 打开浏览器 (实例化浏览器对象)g_browser_handle = ChromiumPage()ac = Actions(dp)# 监听数据包g_browser_handle.listen.start(\'web/v1/search/notes\')# 获取前5页数据for page in range(5):g_browser_handle.listen.wait()print(\"processing...\")# 滑条向下滑动1500像素ac.scroll(delta_y=1500)3.3.总体实现
以上3.2的爬虫部分放在3.1部分中long_task就可以实现根据按钮进行启停关键词搜索;完整项目代码请移步木易师傅!!


