windows 系统部署hadoop和spark(完整全面版本)_windows端搭建hadoop hbase hive spark
前提系统已经安装jdk
选型版本
1:seala:2.13.16
2: hadoop:2.10.2
3: spark:2.4.7
4: winutils
1:下载
seala 地址: Scala 2.13.16 | The Scala Programming Language
hadoop地址:Index of /hadoop/common
spark地址:Apache Archive Distribution Directory
winutils:winutils/hadoop-2.9.2 at master · cdarlint/winutils · GitHub
![]()

2:安装
1:scala安装
一直点下一步完成后验证 : 打开命令行 输入 scala -version
安装成功

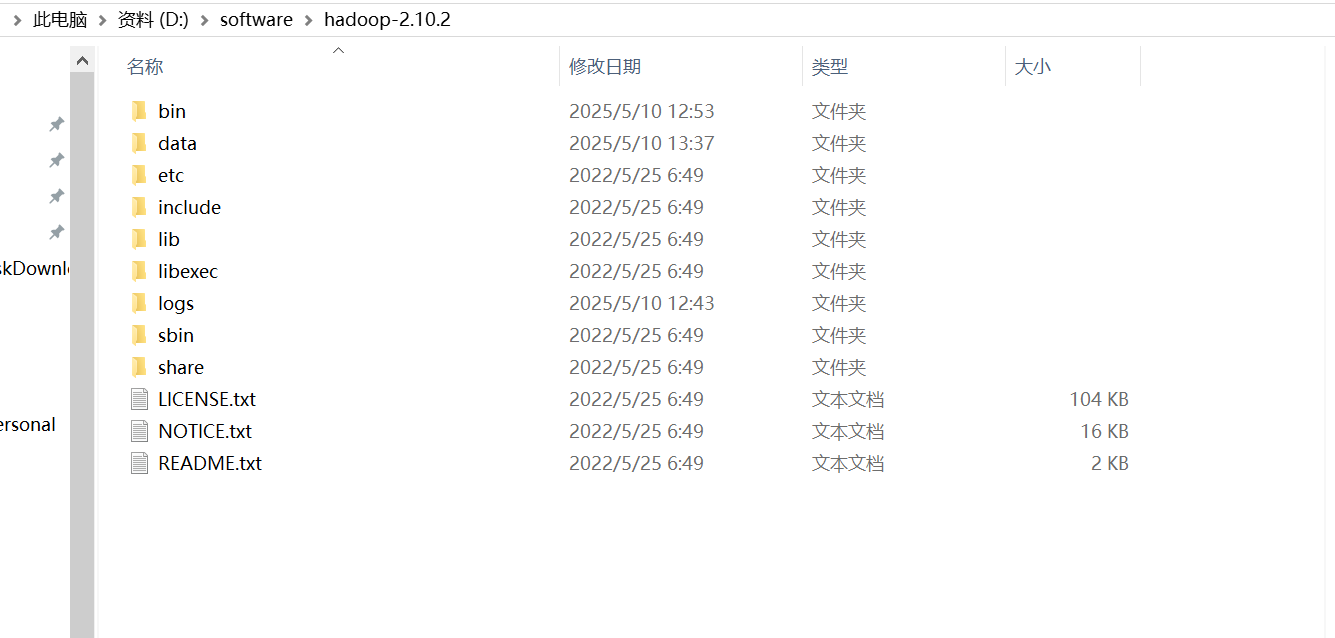
2:hadoop安装
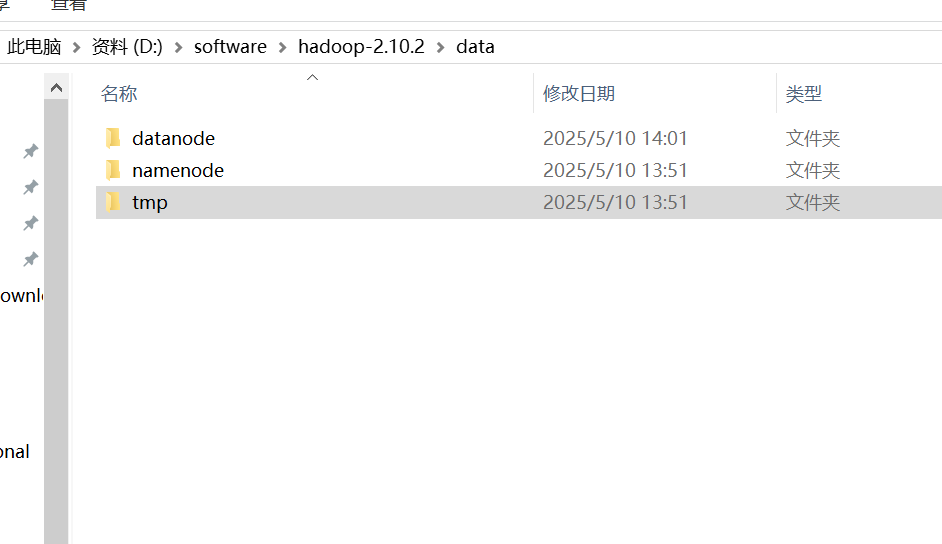
解压hadoop压缩包后创建data文件夹下再创建三个datanode,namenode,tmp
1:配置环境变量
![]()
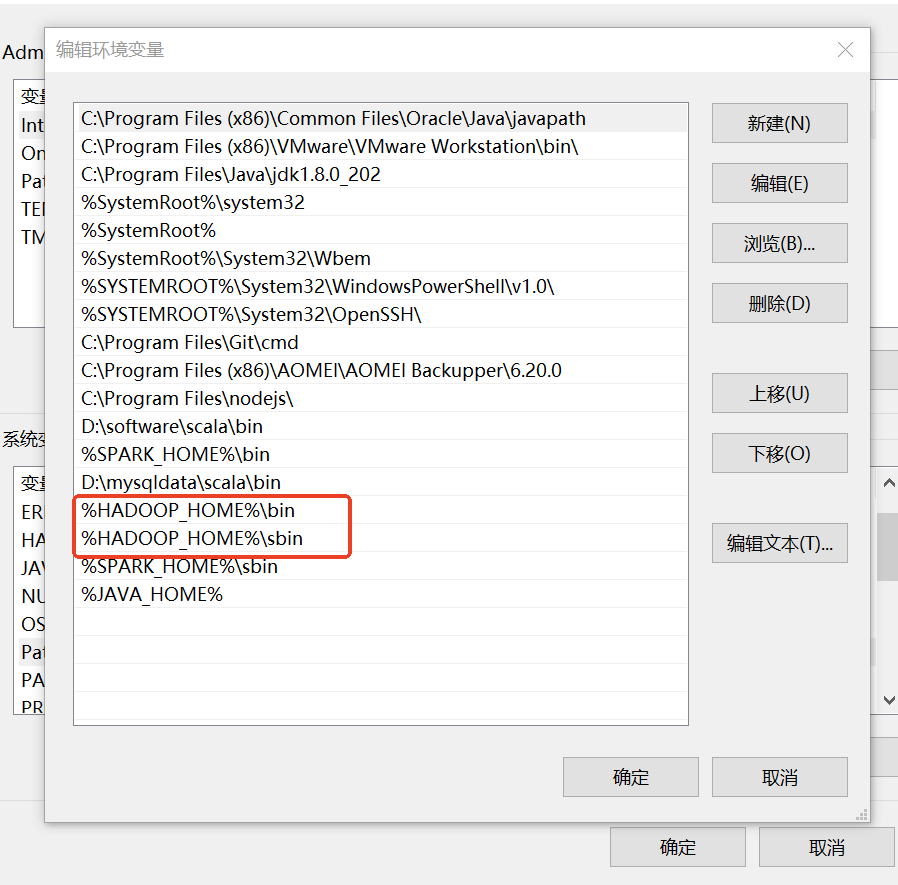
2:配置
修改etc目录
\\etc\\hadoop\\core-site.xml
hadoop.tmp.dir
D:\\software\\hadoop-2.10.2\\data\\tmp
fs.defaultFS
hdfs://127.0.0.1:9000
\\etc\\hadoop\\hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
D:\\software\\hadoop-2.10.2\\data\\namenode
dfs.datanode.data.dir
D:\\software\\hadoop-2.10.2\\data\\datanode
\\etc\\hadoop\\mapred-site.xml
mapreduce.framework.name
yarn
mapred.job.tracker
hdfs://localhost:9001
\\etc\\hadoop\\yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hahoop.mapred.ShuffleHandler
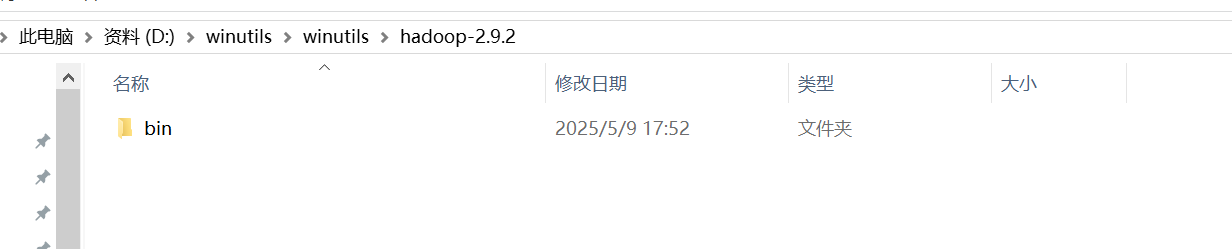
3:替换bin
把winutils下的bin替换成hadoop-2.10.2\\bin
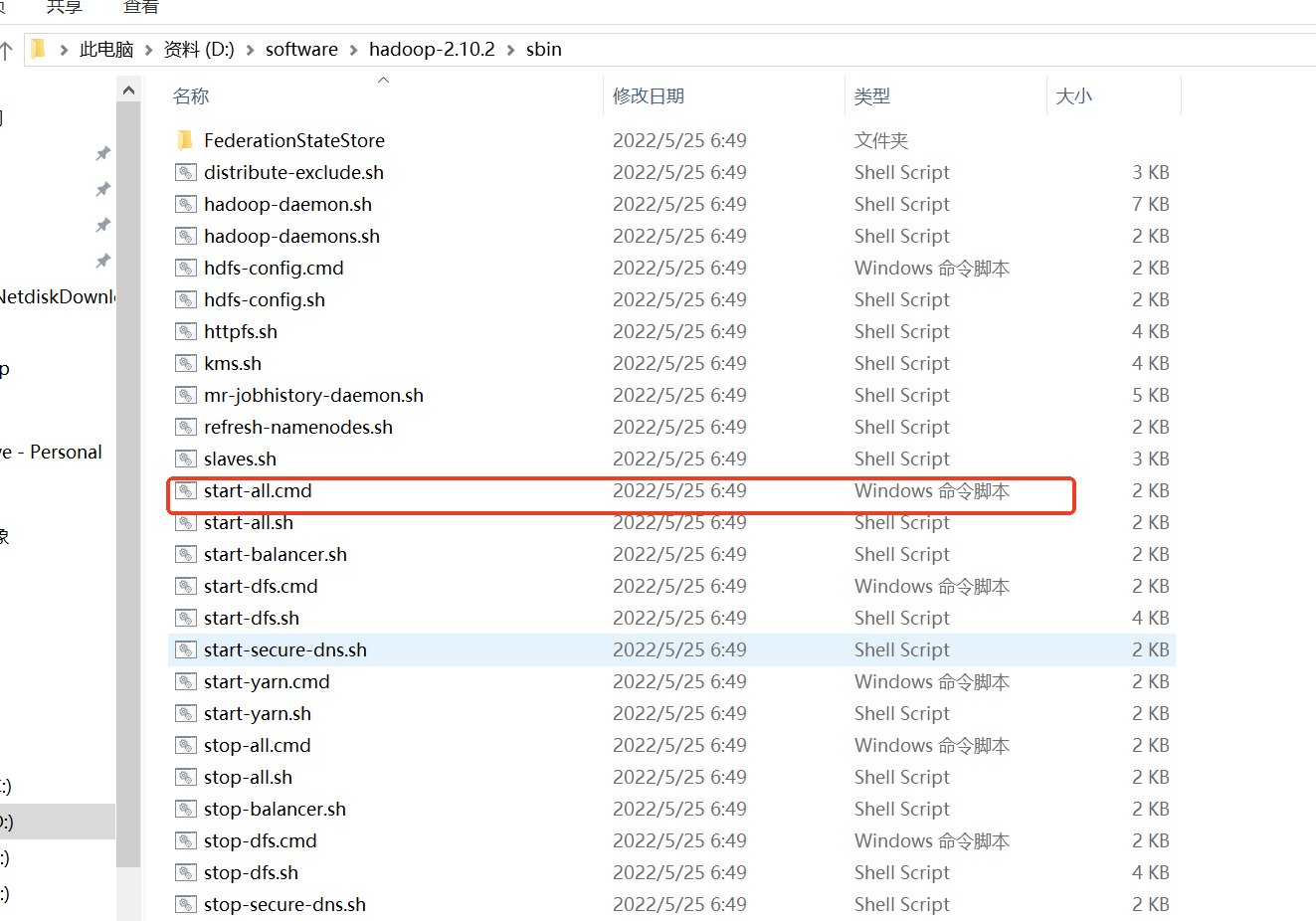
4:启动
执行sbin目录下start-all.cmd
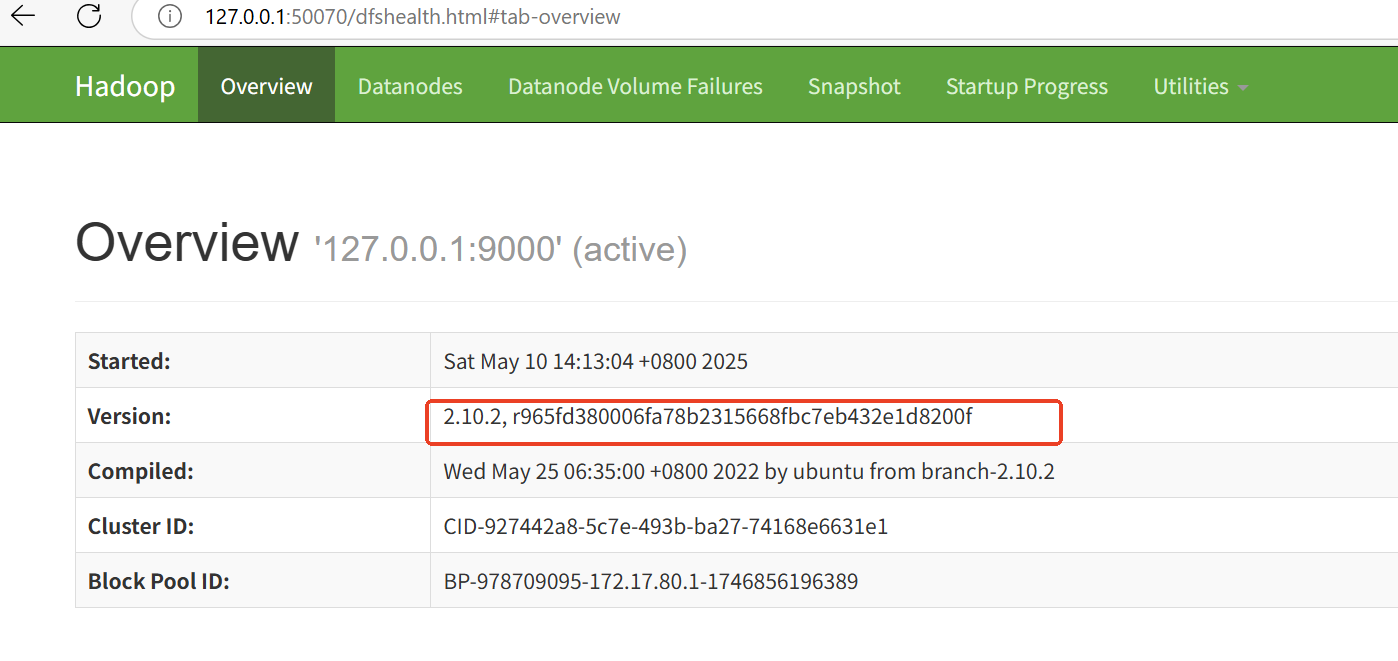
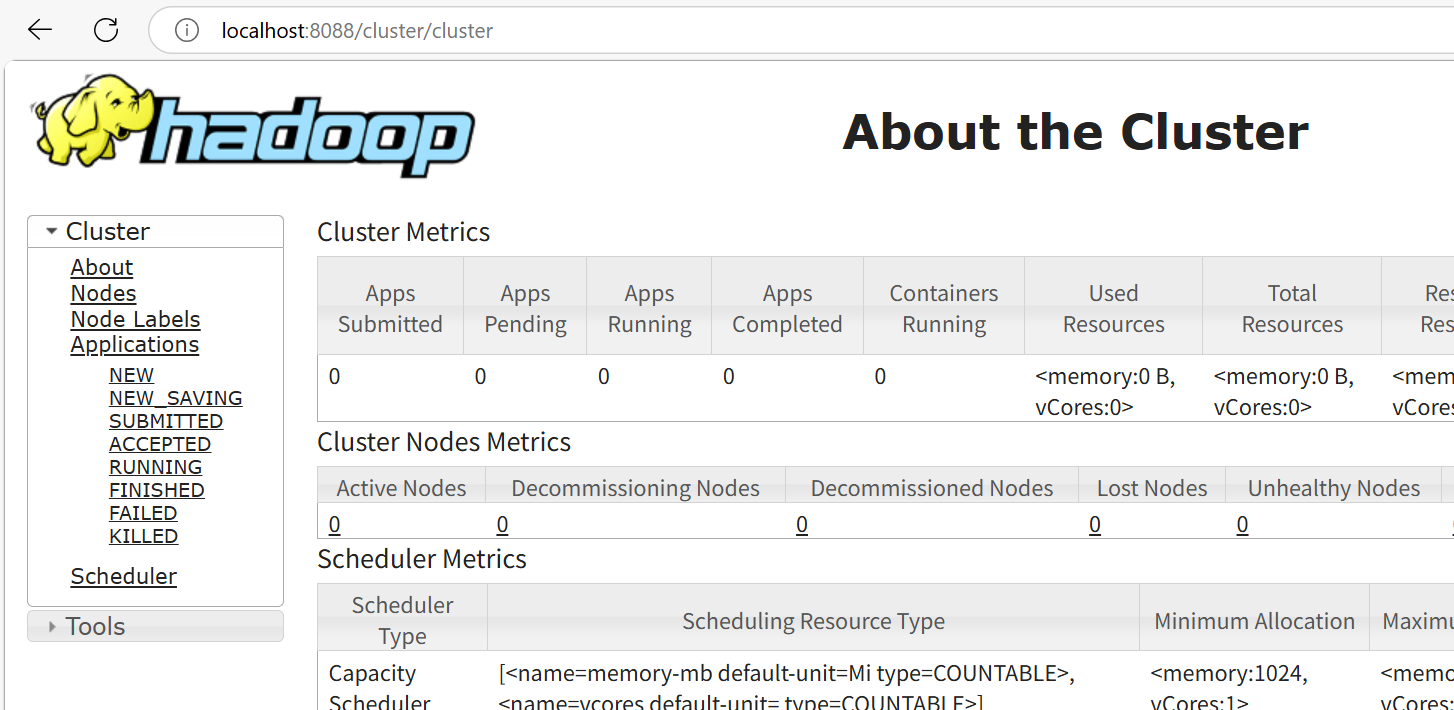
4:验证
http://127.0.0.1:50070/
http://127.0.0.1:8088/
3:安装spark
1:解压文件
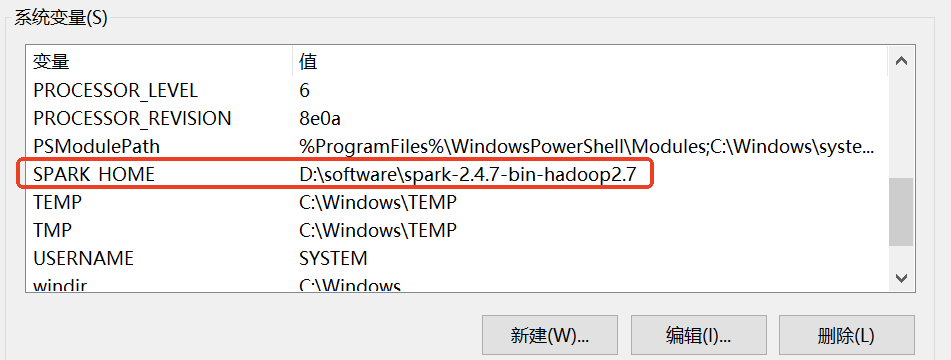
2:配置环境变量
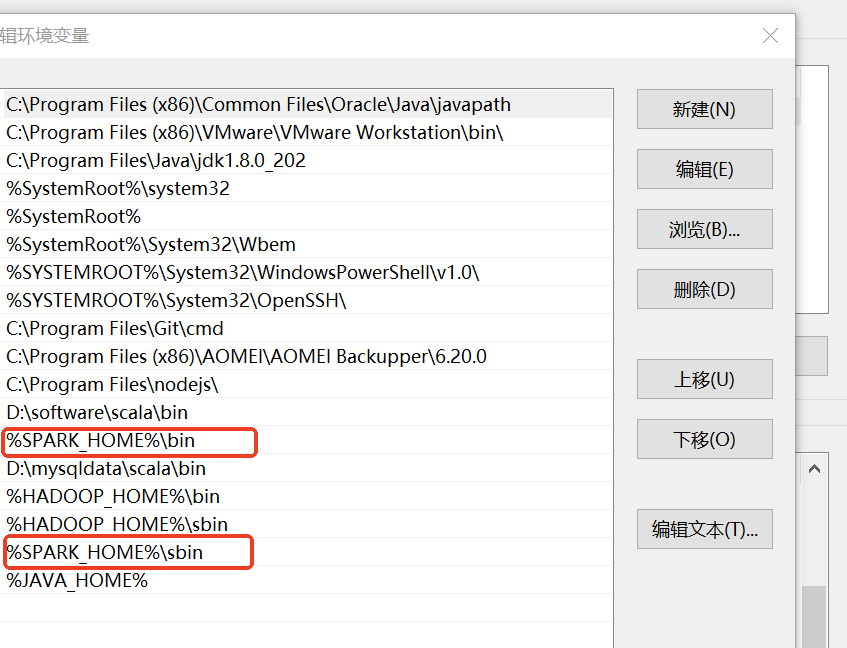 3:启动
3:启动
命令行输入:spark-shell
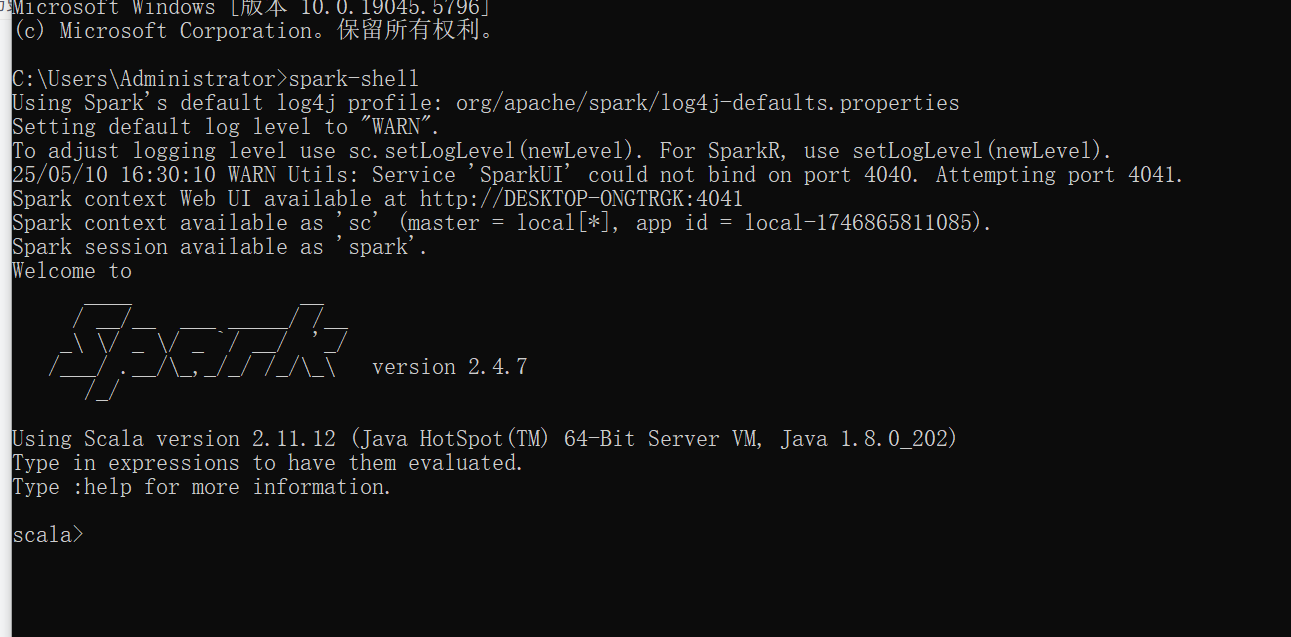
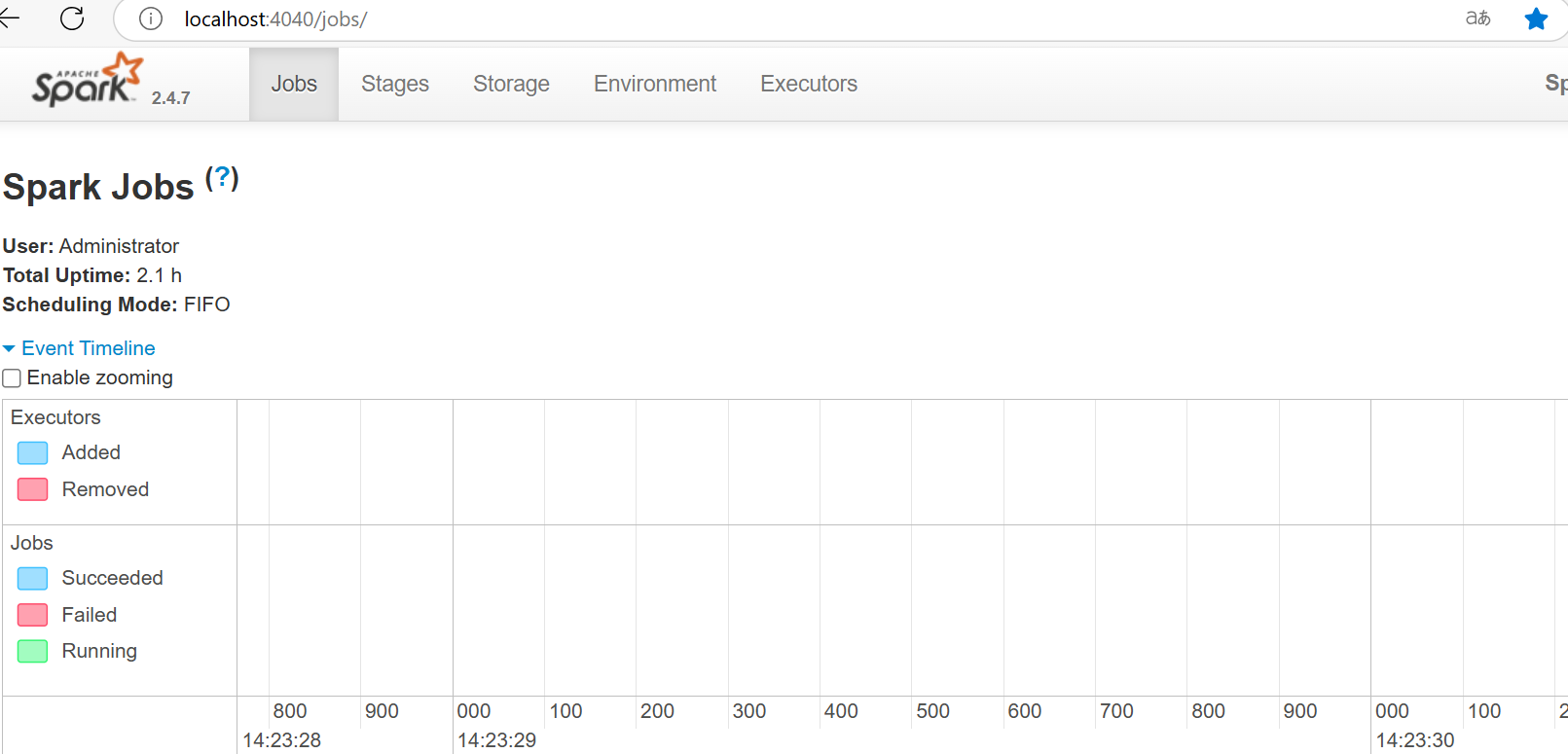
4:验证
http://127.0.0.1:4040/