Python爬虫基础之Selenium详解
文章目录
-
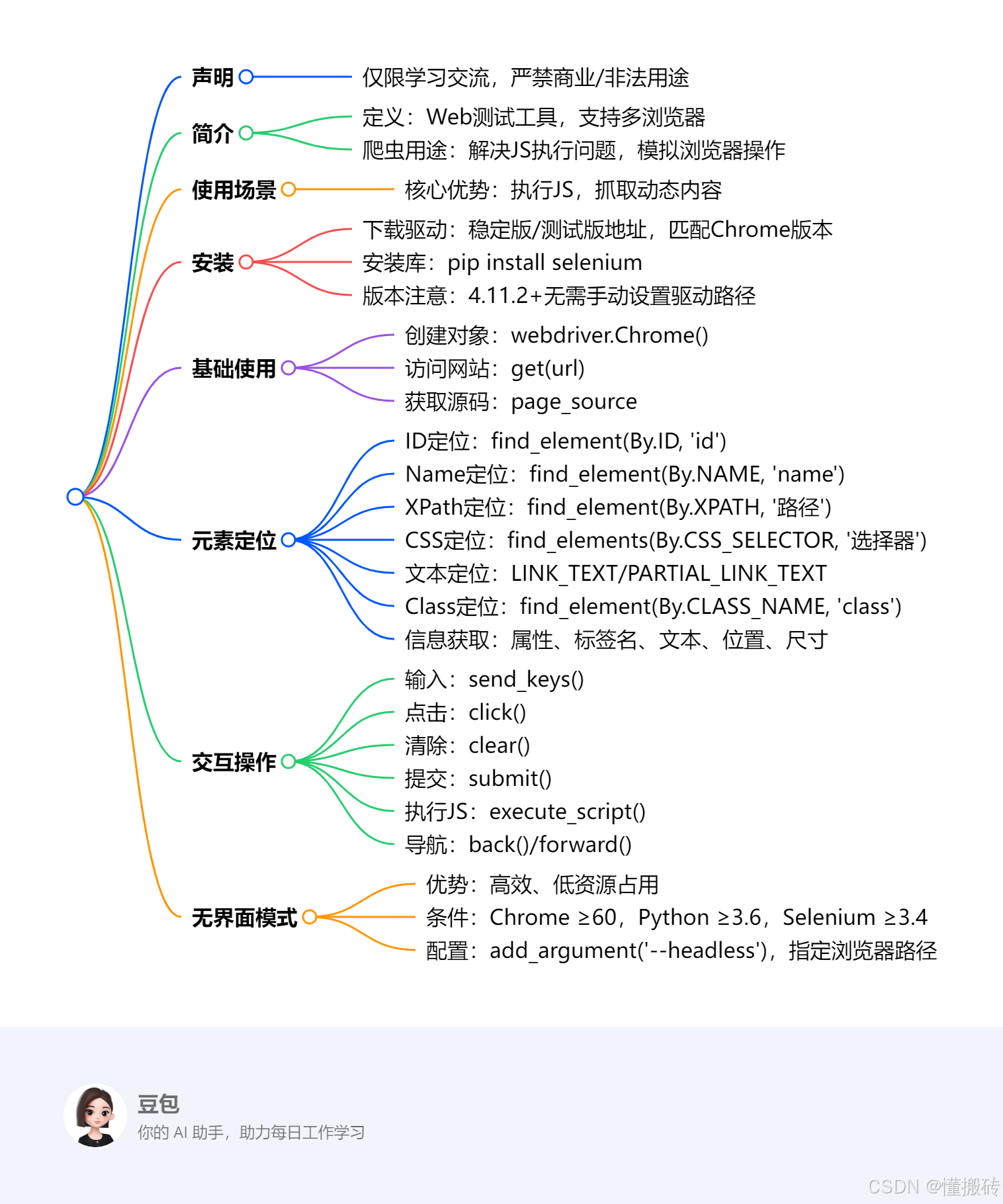
- 一、声明
- 二、Selenium 简介
- 三、使用场景
- 四、安装步骤
- 五、基础使用示例
- 六、元素定位方法
- 七、页面交互操作
- 八、无界面模式(Chrome Headless)
- 思维导图
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
一、声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关。
二、Selenium 简介
- 定义
- 用于Web应用测试的工具,支持多浏览器(Chrome、Firefox、Edge等)。
- 爬虫场景:解决
requests无法执行JavaScript的问题,模拟浏览器操作获取动态渲染内容。
- 核心原理
- 驱动浏览器模拟用户行为(点击、输入、滑动等),通过Python接口实现自动化操作。
三、使用场景
- 核心优势:自动执行JavaScript,抓取动态加载数据(如Ajax渲染内容)。
四、安装步骤
- 下载浏览器驱动
- Chrome驱动:
- 稳定版:稳定版
- 测试版(向下兼容):测试版
- 操作:匹配本地Chrome版本(如Chrome 116选测试版118),解压驱动到项目根目录。
- Chrome驱动:
- 安装Selenium库
- 命令:
pip install selenium
- 命令:
- 版本注意:
- Selenium 4.11.2+ 无需手动指定驱动路径,直接调用
webdriver.Chrome()。
- Selenium 4.11.2+ 无需手动指定驱动路径,直接调用
五、基础使用示例
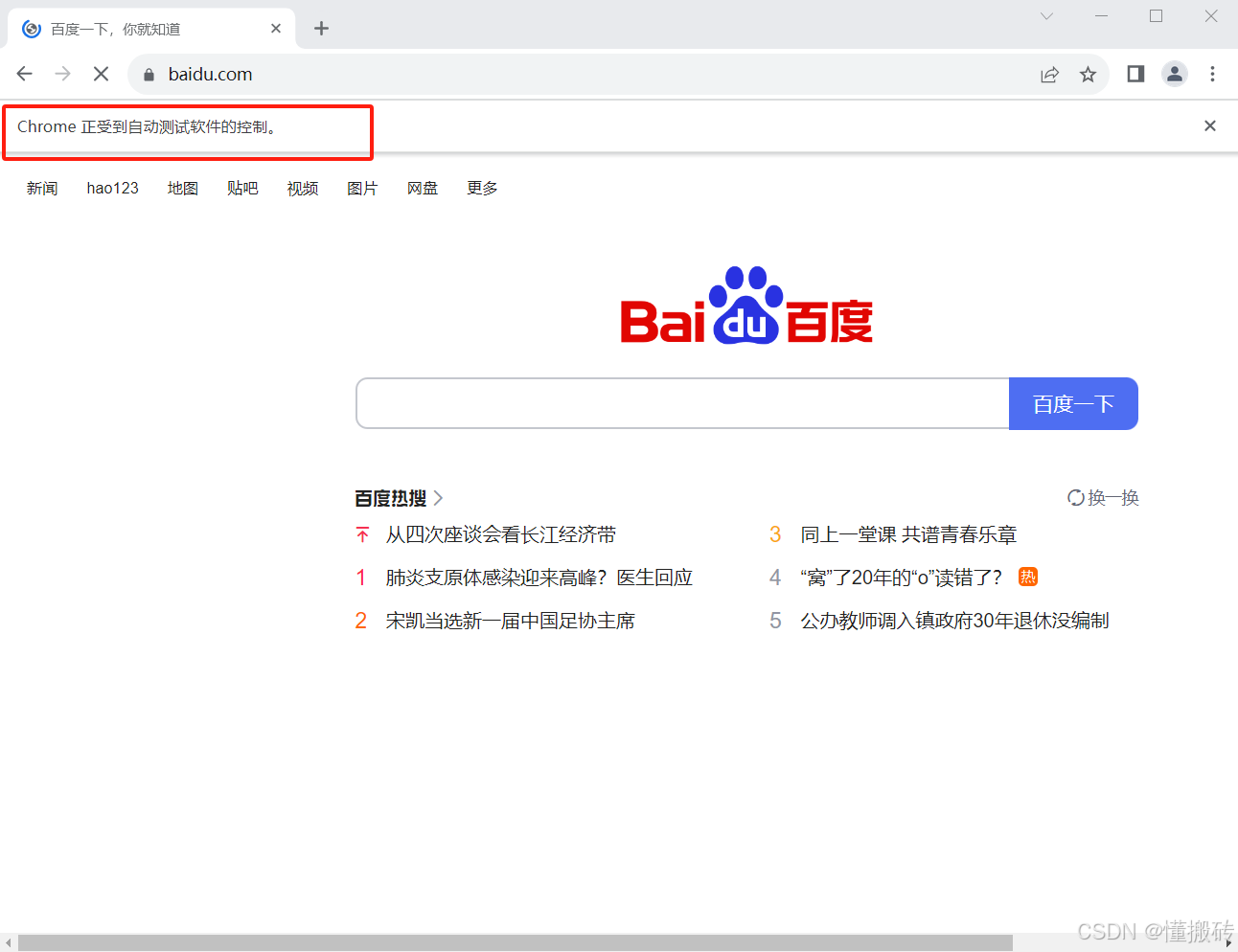
from selenium import webdriver# 创建浏览器对象(旧版本需指定驱动路径,新版本无需)browser = webdriver.Chrome() # 或 webdriver.Chrome(\'chromedriver.exe\')# 访问网站url = \"https://www.baidu.com\"browser.get(url)# 获取页面源码content = browser.page_sourceprint(content)# 关闭浏览器browser.quit()需要注意的是,如果你的 selenium 是4.11.2以上的版本,不需要设置driver.exe的路径,selenium 可以自己处理浏览器的驱动程序,因此代码直接改为brower = webdriver.Chrome()即可。
运行代码,得到下面的效果:
六、元素定位方法
browser.find_element(By.ID, \'su\')id属性精准定位browser.find_element(By.NAME, \'wd\')name属性定位browser.find_element(By.XPATH, \'//input[@id=\"su\"]\')browser.find_elements(By.TAG_NAME, \'input\')browser.find_elements(By.CSS_SELECTOR, \'#su\')browser.find_elements(By.LINK_TEXT, \'地图\')browser.find_elements(By.PARTIAL_LINK_TEXT, \'地\')browser.find_element(By.CLASS_NAME, \'wrapper_new\')class属性定位元素信息获取:
get_attribute(\'属性名\'):获取元素属性(如class)tag_name:获取标签名text:获取元素文本内容location:获取元素坐标位置size:获取元素尺寸
七、页面交互操作
- 输入文本
input_box = browser.find_element(By.ID, \'kw\')input_box.send_keys(\'selenium\') # 输入文本 - 点击操作
button = browser.find_element(By.ID, \'su\')button.click() # 模拟点击 - 清除文本
input_box.clear() # 清空输入框内容 - 回车提交
input_box.submit() # 模拟回车键 - 执行JavaScript
browser.execute_script(\'document.documentElement.scrollTop=10000\') # 滑动页面 - 前进/后退
browser.back() # 后退browser.forward() # 前进
八、无界面模式(Chrome Headless)
- 优势:
- 无界面渲染,运行效率更高,资源占用少。
- 使用条件:
- Chrome版本:Windows ≥60,Linux/Unix ≥59
- Python ≥3.6,Selenium ≥3.4
- 代码示例
from selenium.webdriver.chrome.options import Optionschrome_options = Options()chrome_options.add_argument(\'--headless\') # 启用无界面模式chrome_options.add_argument(\'--disable-gpu\') # 禁用GPU加速(可选)chrome_options.binary_location = r\'C:\\Chrome安装路径\\chrome.exe\' # 指定浏览器路径browser = webdriver.Chrome(options=chrome_options)browser.get(\'https://www.baidu.com\')browser.save_screenshot(\'baidu.png\') # 保存页面截图
思维导图
## **声明**- 仅限学习交流,严禁商业/非法用途## **简介**- 定义:Web测试工具,支持多浏览器- 爬虫用途:解决JS执行问题,模拟浏览器操作## **使用场景**- 核心优势:执行JS,抓取动态内容## **安装**- 下载驱动:稳定版/测试版地址,匹配Chrome版本- 安装库:pip install selenium- 版本注意:4.11.2+无需手动设置驱动路径## **基础使用**- 创建对象:webdriver.Chrome()- 访问网站:get(url)- 获取源码:page_source## **元素定位**- ID定位:find_element(By.ID, \'id\')- Name定位:find_element(By.NAME, \'name\')- XPath定位:find_element(By.XPATH, \'路径\')- CSS定位:find_elements(By.CSS_SELECTOR, \'选择器\')- 文本定位:LINK_TEXT/PARTIAL_LINK_TEXT- Class定位:find_element(By.CLASS_NAME, \'class\')- 信息获取:属性、标签名、文本、位置、尺寸## **交互操作**- 输入:send_keys()- 点击:click()- 清除:clear()- 提交:submit()- 执行JS:execute_script()- 导航:back()/forward()## **无界面模式**- 优势:高效、低资源占用- 条件:Chrome ≥60,Python ≥3.6,Selenium ≥3.4- 配置:add_argument(\'--headless\'),指定浏览器路径