我开源了一个更符合人类思维的 AI 搜索引擎,告别 RAG 的“知识碎片”_ai搜索 开源
在探索大语言模型(LLM)的世界时,我们都对 RAG(检索增强生成)技术感到兴奋。它让模型能接触到外部知识,回答我们五花八门的问题。但你是否也曾感到困惑:为什么我用 RAG 搭建的问答机器人,回答总是干巴巴的,缺乏深度和上下文?
答案可能在于,我们喂给模型的“食物”是零散的知识碎片 (Chunks)。传统 RAG 就像是把一本书撕成无数张小纸条,当模型需要答案时,我们只递给它几张可能相关的小纸条。这种方式虽然能找到答案,但模型失去了对全局背景、上下文逻辑的理解能力。
为了解决这个问题,我构思并开发了一个全新的 AI 搜索项目—— TinyAISearch。它的核心理念很简单:像人一样去阅读和理解,而不是像机器一样扫描碎片。
今天,我将它完全开源,希望能为同样在 AI 应用开发道路上探索的你,带来一些新的启发。
前端界面:

聊天界面:
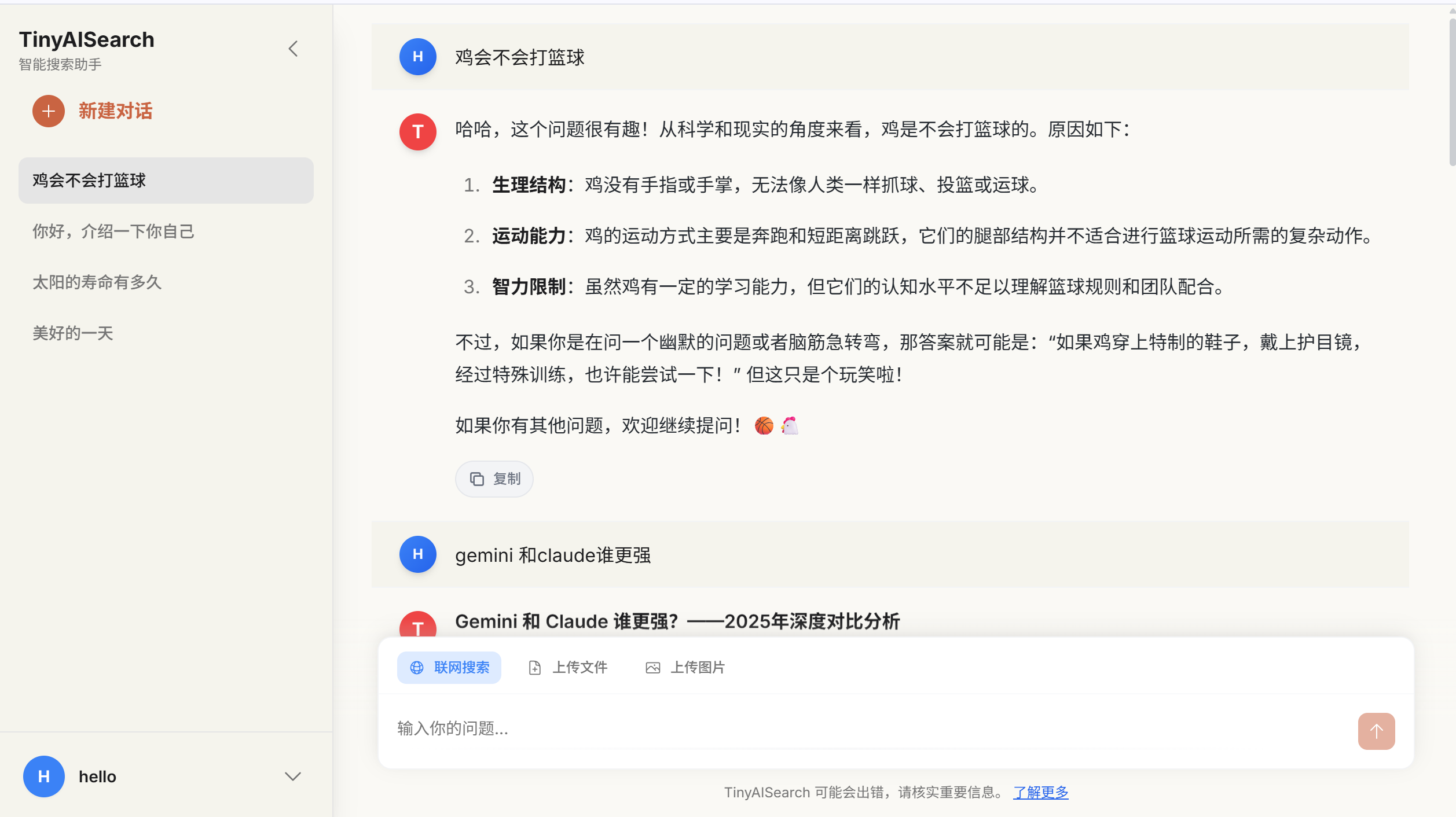
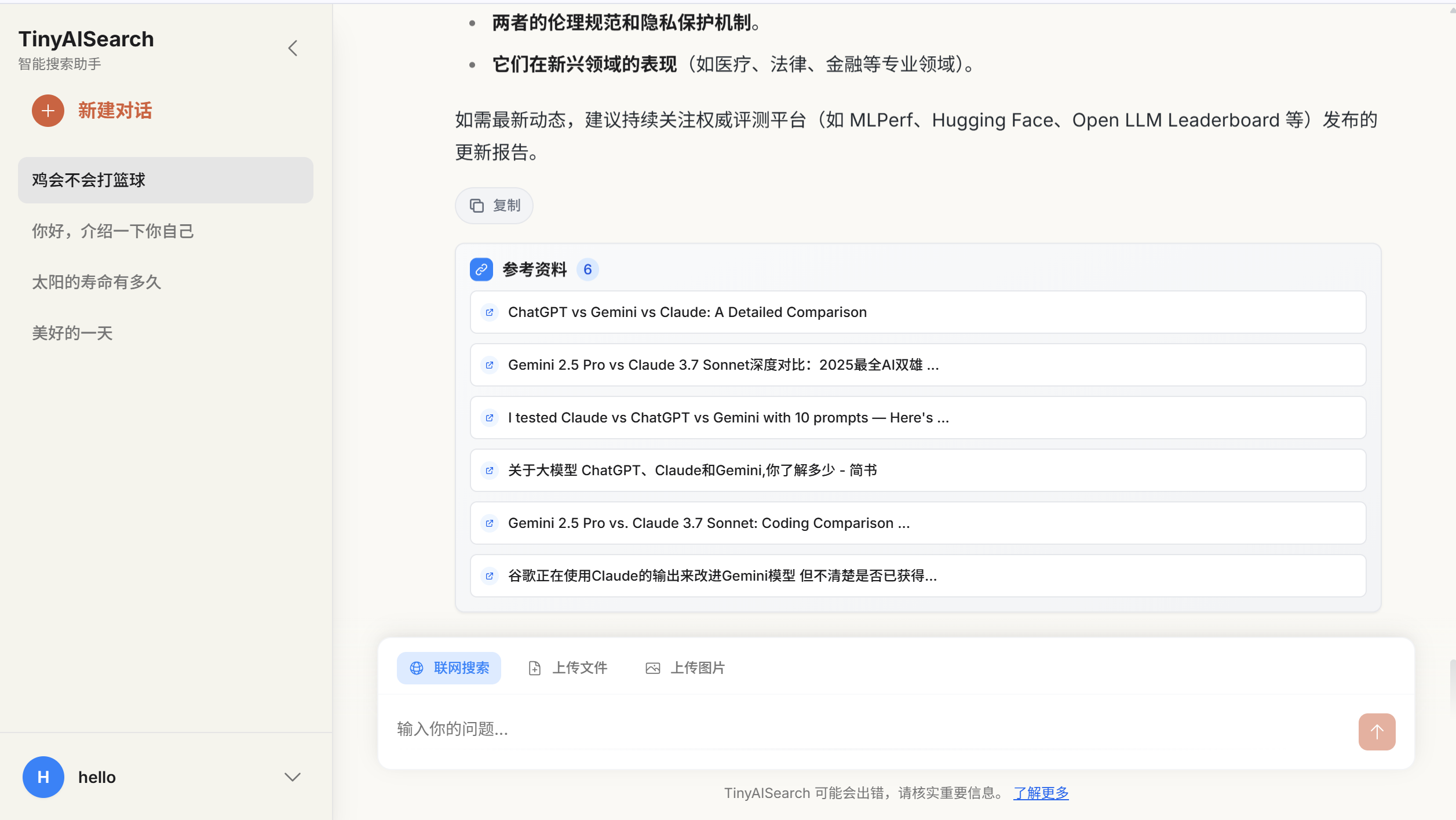
联网搜索信息参考:
🔗 GitHub 仓库地址:TinyAISearch
💡 TinyAISearch 的创新点:V2 网页级召回
TinyAISearch 最大的创新点,是我称之为 “V2 检索模式” 的网页级召回(Page-Level Retrieval)流程。它模拟了人类在解决复杂问题时的搜索行为:
1. 🤔 智能规划 (Plan):当你输入“今天武汉天气怎么样?”,它不会立刻就去搜索。而是先让 LLM 分析你的意图,生成一个周密的搜索计划,比如:`{\"query\": \"今天武汉天气预报\", \"engine\": \"baidu\"}`,目前支持百度、Duckduckgo进行搜索,google搜索作为辅助,因为前两个直接使用python库,避免大家配置API等繁琐步骤。
2. 🌐 网页爬取 (Crawl): 它根据计划,像一个真正的用户一样,从搜索引擎获取多个相关网页,并完整爬取这些网页的**正文内容。
3. ⚖️ 网页级召回 (Retrieve): 这是最关键的一步!TinyAISearch 不会将网页切成碎片。相反,它会综合运用向量相似度和 BM25 算法,计算你的问题与 每一篇完整网页的相关性,将这些相关性得分进行softmax归一化处理后相加,然后对这些网页进行排序。
4. ✍️ 生成答案 (Generate): 最后,根据问题难度,它会将排名最高的几篇完整网页作为上下文,一次性提供给 LLM。有了完整、连贯的背景知识,LLM 就能像读完几篇深度报道的专家一样,为你生成高质量、有深度的回答。
这种方式的好处是显而易见的:它为模型提供了背景信息,而不仅仅是知识片段。
🛠️ 不只是 V2,你也可以使用传统的RAG
当然,为了方便你对比和学习,项目也内置了传统的 V1 检索模式。你可以在配置中一键切换,亲手体验不同策略的优劣:
- V1-High 模式: 相似度检索 + Rerank 重排序,经典的 RAG 流程。
- V1-Higher 模式: 多路召回(相似度 + BM25)+ RRF 融合,更进一步的性能优化。
通过在不同模式间切换,你可以直观地感受到“网页级召回”带来的巨大提升,深入理解 RAG 技术的每一个环节。
✨ TinyAISearch技术实现
* 前后端: 它是一个开箱即用的完整项目,包含了从后端(FastAPI)到前端(Vue 3)的全套代码。你可以把它当作一个学习项目,快速掌握 AI 应用开发的全貌,而不是在零散的代码片段中迷失。
* 模型支持: 它是一个绝佳的实验平台。你可以轻松替换任意兼容 OpenAI API 的模型(Qwen、DeepSeek、GLM、Ollama 等),修改召回策略,甚至在此基础上构建更复杂的应用。
* 功能完备: 支持多用户、多会话,界面简洁现代,拥有良好的交互体验。
如果你对这个项目感兴趣,或者它激发了你的灵感,请访问我们的 GitHub 仓库:

