蓝耘元生代:基于ComfyUI的AI工作流构建实践——技术架构与开发者效率的双重革新_comfyui causallm
声明:文章为本人平台测评博客,并没有推广该软件 ,非广告,为用户体验文章
文章目录
- 引言
-
- 一、平台技术底座:支撑高效工作流的四大核心能力
-
- 1.1 蜂巢式异构调度引擎(关键技术解析)
- 1.2 容器化AI运行时(Containerized AI Runtime)
- 二、工作流构建实战:从单卡推理到分布式训练
-
- 2.1 单卡推理优化技术
- 2.2 分布式训练加速方案
- 三、全链路监控体系:让每个Token的花费可见
-
- 3.1 成本控制的三层防护
- 3.2 性能诊断工具链
- 四、开发者生态:开箱即用的AI组件市场
-
- 4.1 预集成工作流模板
- 4.2 自定义组件开发SDK
- 五、从开发到部署:全生命周期管理示例
-
- 5.1 自动化测试流水线
- 5.2 生产环境A/B测试
- 结语:技术驱动的工作流革新
- 立即注册,开启无限可能
引言
在人工智能技术高速迭代的今天,算力资源的高效利用与开发流程的简化已成为行业核心诉求。蓝耘元生代智算云平台(LY Cloud)凭借其异构算力调度引擎、容器化弹性架构与全生命周期AI支持,为开发者与企业提供了从模型训练到推理部署的一站式解决方案。
平台通过三大技术突破重构开发范式:
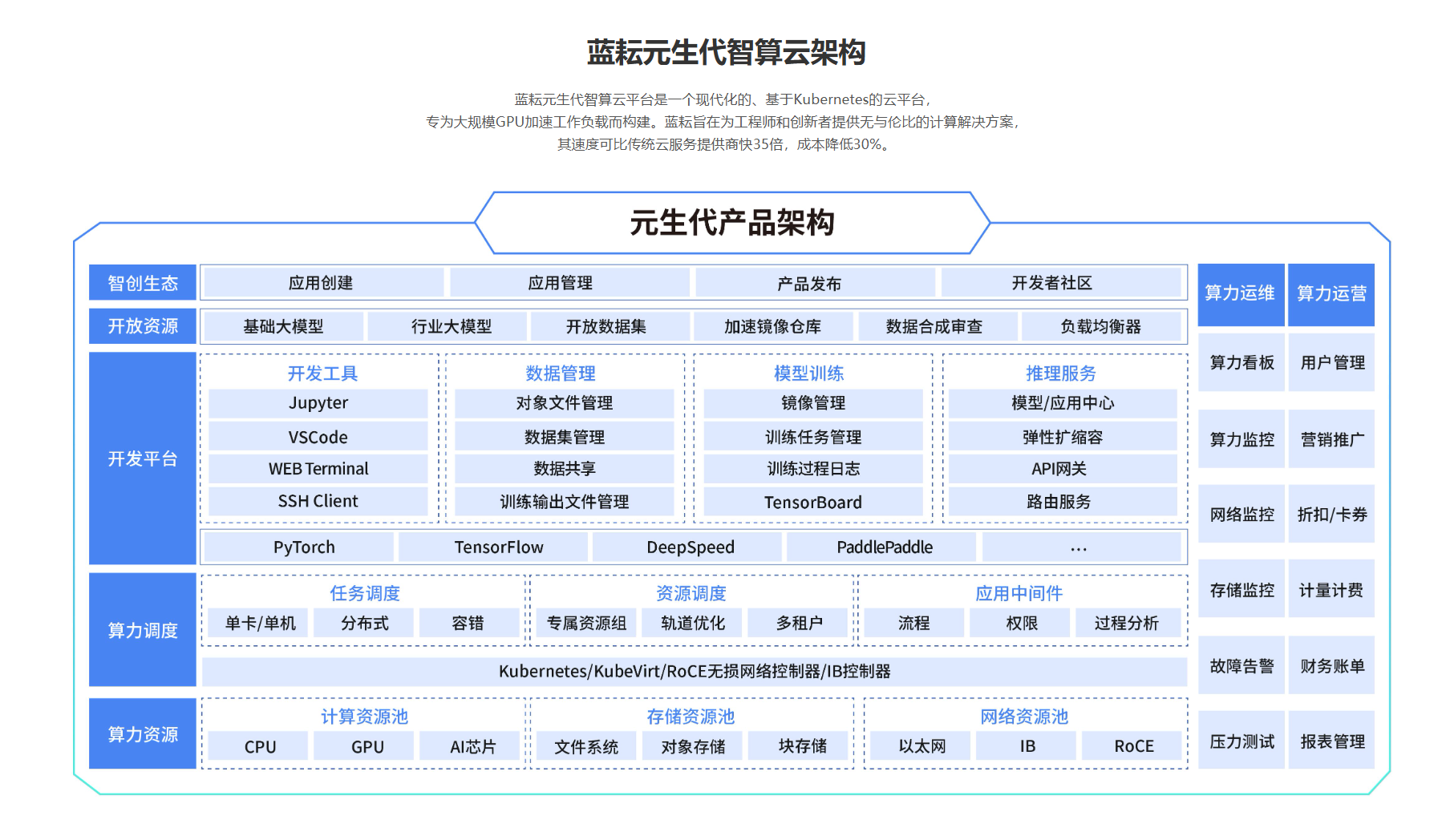
- 算力民主化:基于蜂巢式资源网络,动态匹配GPU/CPU/TPU组合,实现95%以上的硬件利用率,较传统虚拟化方案提升35%性能,成本降低30%;
- 流程工业化:集成Kubernetes原生云架构与裸金属服务器直通技术,支持秒级弹性扩容与资源隔离,千亿参数模型训练吞吐量提升28%;
- 生态开放化:提供OpenAI兼容接口与预集成模型市场(如DS满血版、Stable Diffusion等),开发者无需代码重构即可迁移项目,新用户更享500万免费Token额度。
本文将以技术实现深度解析与开发者第一视角体验为主线,探讨蓝耘平台如何通过ComfyUI工作流构建、混合精度训练加速、成本精细化管控等核心能力,解决传统开发中的资源浪费、部署复杂、调试低效等痛点。从异构调度算法原理到API调用实战,从分布式训练优化到多模态应用案例,全面展现平台在AIGC、自动驾驶、医疗诊断等场景中的技术落地价值。
一、平台技术底座:支撑高效工作流的四大核心能力
1.1 蜂巢式异构调度引擎(关键技术解析)
蓝耘元生代平台通过动态资源拓扑感知算法,实现GPU/CPU/TPU的智能组合调度。其技术特性包括:
- 硬件感知调度:自动识别NVIDIA/AMD/寒武纪等不同厂商硬件的指令集特性
- 负载预测:基于时间序列分析预判未来5分钟资源需求,提前启动实例预热
- 跨节点通信优化:采用RDMA over Converged Ethernet (RoCE)协议,降低分布式训练延迟
👉 实操示例:查看当前集群硬件拓扑
lanyun cluster topology my-cluster-01 # 输出示例:# GPU Nodes: 3x A100-80GB (NVLink互联)# CPU Nodes: 8x Intel Sapphire Rapids 56C # 网络带宽:200Gbps RoCE1.2 容器化AI运行时(Containerized AI Runtime)
相比传统虚拟化方案,蓝耘的轻量级容器方案具备:
- 快速启动:预集成PyTorch 2.2 + CUDA 12.1的镜像仅需8秒加载
- 版本隔离:通过命名空间隔离不同项目的Python依赖环境
- 持久化存储:分布式文件系统实现容器重启后模型权重保留
👉 实操示例:创建带持久化存储的ComfyUI容器
# comfyui-persistent.yaml storage: - name: model-store path: /stable-diffusion/models size: 1TiB backup_policy: daily # 自动每日快照二、工作流构建实战:从单卡推理到分布式训练
2.1 单卡推理优化技术
蓝耘平台通过TensorRT-LLM编译器对HuggingFace模型进行内核优化:
- 算子融合:将多个GPU操作合并为单一内核,减少内存拷贝
- 显存优化:通过PagedAttention技术降低KV Cache内存占用
👉 实操示例:部署优化后的DeepSeek-R1模型
from lanyun.optim import compile_model # 原始HuggingFace模型 model = AutoModelForCausalLM.from_pretrained(\"deepseek-r1\") # 蓝耘优化编译 optimized_model = compile_model( model, precision=\"fp16\", kernel_fusion=True, # 启用算子融合 paged_attention=True # 启用分页注意力 ) # 部署为HTTP服务 lanyun deploy create \\ --model optimized_model \\ --gpu-type a100 \\ --endpoint /deepseek-r12.2 分布式训练加速方案
平台内置的3D并行训练框架支持:
- 张量并行(Tensor Parallelism)
- 流水线并行(Pipeline Parallelism)
- 数据并行(Data Parallelism)
👉 实操示例:启动千亿参数模型训练
lanyun train start \\ --script train_llm.py \\ --parallel-mode \"tp=2, pp=4, dp=8\" \\ --hyperparameters \"batch_size=1024, lr=3e-5\" \\ --resource-profile \"gpu=a100x64\" 三、全链路监控体系:让每个Token的花费可见
3.1 成本控制的三层防护
lanyun budget set --daily 50lanyun autoscale --max-cost 30lanyun cost analyze --by-project3.2 性能诊断工具链
- GPU火焰图:定位显存泄漏点
lanyun diagnose gpu-flamegraph --pid 1423 - 通信矩阵分析:检测分布式训练瓶颈
lanyun diagnose nccl-matrix job-2024
四、开发者生态:开箱即用的AI组件市场
4.1 预集成工作流模板
lanyun template create text-to-videolanyun template create chatbot --params \"max_tokens=128000\"4.2 自定义组件开发SDK
👉 示例:开发支持动态LoRA加载的文本编码器
from lanyun.sdk import ComfyComponent class DynamicLoRAEncoder(ComfyComponent): VERSION = \"1.2\" @classmethod def INPUT_TYPES(cls): return { \"required\": { \"base_model\": (\"MODEL\",), \"lora_path\": (\"STRING\", {\"default\": \"\"}) } } def encode(self, base_model, lora_path): # 平台自动处理模型缓存与加载 if lora_path: self.load_lora(lora_path) return super().encode(base_model) # 注册到组件市场 lanyun.component.publish(DynamicLoRAEncoder)五、从开发到部署:全生命周期管理示例
5.1 自动化测试流水线
# .lanyun-ci.yml stages: - test: commands: - pytest tests/ --gpu=a10g # 申请测试用GPU - deploy: trigger: branch: main actions: - lanyun model build --prod - lanyun deploy canary --percent 5% 5.2 生产环境A/B测试
# 部署两个模型版本 lanyun deploy create --name model-v1 --traffic 70% lanyun deploy create --name model-v2 --traffic 30% # 实时监控指标 watch lanyun metrics compare \\ model-v1 model-v2 \\ --metrics \"latency_avg,accuracy_top1\"结语:技术驱动的工作流革新
蓝耘元生代平台通过三大技术突破重构AI开发体验:
- 算力民主化:异构资源池让3090到A100硬件无缝协同
- 流程工业化:从Prompt调优到模型压测的全标准化
- 成本透明化:细粒度至单个API调用的成本追溯
立即注册,开启无限可能
蓝耘元生代技术文档不仅是操作手册,更是AI工程化的方法论宝库。通过对其技术体系的深度挖掘,开发者能够将理论认知转化为产业落地的实际能力。立即访问蓝耘官网与产品文档中心,开启您的算力革命之旅!
在使用蓝耘智算平台前,首先需要完成注册。
访问蓝耘智算平台👈在首页中找到 “注册” 按钮,点击进入注册页面。
在注册页面,你需要填写一系列必要信息,包括有效的电子邮箱地址、自定义的用户名和强密码(建议包含字母、数字及特殊字符,以增强账户安全性),以及手机号码并完成短信验证码验证
完成上述步骤后,点击 “注册” 按钮提交信息。注册成功后,系统会自动发送一封验证邮件到你填写的邮箱,登录邮箱并点击验证链接,完成账号激活。激活后,你就可以使用注册的账号登录蓝耘智算平台,开启你的创作之旅
🚀 平台直达链接:蓝耘智算平台
💡 提示:新用户可领取 20 元代金券,体验高性能 GPU 算力!


