Kafka 3.x版本 KRaft模式集群搭建教程_kraft 搭建kafka集群
1.前言
Apache Kafka 从 2.8.0 版本(2021年4月发布) 开始正式引入 KRaft(Kafka Raft)模式,作为 替代 ZooKeeper 的元数据管理机制。
为什么引入 KRaft?
-
简化架构:减少对 ZooKeeper 的依赖,降低运维复杂度。
-
提高性能:减少元数据同步的延迟,提升集群扩展性。
-
增强稳定性:Raft 协议比 ZooKeeper 更易于理解和维护。
本文使用以下3台服务器演示使用Kraft模式的kafka集群环境
每台服务器的kafka目录统一使用 /u01/kafka。选择3台服务器搭建集群的原因如下:
Apache Kafka 官方文档 明确说明:
\"A KRaft cluster requires at least three controller nodes for production environments to maintain availability.\"
(KRaft 集群在生产环境至少需要 3 个 controller 节点以保证可用性)
KIP-500 设计文档指出:
\"The metadata quorum must tolerate F failures with 2F+1 nodes.\"
(元数据仲裁集群需要2F+1个节点来容忍F个故障)
KRaft 使用 Raft 共识算法,其核心规则是:
-
法定人数(Quorum) =
(N/2) + 1(其中N是节点总数)-
3 节点集群:需要 2 个节点在线(可容忍 1 个故障)
-
2 节点集群:需要 2 个节点在线(无法容忍任何故障)
-
-
2 节点集群的问题:
-
如果 1 个节点宕机,剩余 1 个节点无法满足
(2/2)+1=2的法定人数要求 -
集群将 无法选举 Leader,导致服务不可用
-
2.准备工作
1 官网下载压缩包
Kafka官网:Apache Kafka ,下载Kafka压缩包,本文以kafka_2.13-3.7.0.gz版本作为样例。请注意,kafka运行需要Java环境支撑,linux配置Java环境的方法此处不做描述,请自行查阅相关文章。
2 解压
# 创建kafka目录,sftp上传压缩包到这个目录下mkdir /u01# 进入目录cd /u01# 解压缩tar -zxvf kafka_2.13-3.7.0.gz# 重命名mv kafka_2.13-3.7.0 kafka3.集群部署
本文中主要介绍的是Kafka KRaft模式,因此需要对kraft模式配置文件进行更改。
vi /u01/kafka/config/kraft/server.properties以下是翻译后的配置文件
# Licensed to the Apache Software Foundation (ASF) under one or more# contributor license agreements. See the NOTICE file distributed with# this work for additional information regarding copyright ownership.# The ASF licenses this file to You under the Apache License, Version 2.0# (the \"License\"); you may not use this file except in compliance with# the License. You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an \"AS IS\" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.## This configuration file is intended for use in KRaft mode, where# Apache ZooKeeper is not present.############################## 服务部分 ############################## 这台服务器的角色,设置此项将使用KRaft模式process.roles=broker,controller# 与此实例的角色关联的节点idnode.id=1# 集群controller全列表字符串,格式按照[节点id@ip:port],多个用英文逗号隔开,集群会自动监测节点状态,选举合适的节点# 指定哪些节点参与集群元数据的管理(如主题创建、分区分配、Leader 选举等)# 取代 ZooKeeper的关键配置,多个节点通过该配置互相通信,某个节点故障,重新选举Leader controller.quorum.voters=1@localhost:9093############################# Socket Server Settings ############################## 套接字服务器侦听的地址.# 组合节点(即具有`process.loes=broker,controller`的节点)必须在此处至少列出控制器侦听器。# 如果未定义代理侦听器,则默认侦听器将使用等于java.net.InetAddress.getCanonicalHostName()值的主机名,# PLAINTEXT侦听器名称,端口9092# 格式:# listeners = listener_name://host_name:port# 样例:# listeners = PLAINTEXT://your.host.name:9092listeners=PLAINTEXT://:9092,CONTROLLER://:9093# 用于代理之间通信的侦听器名称。inter.broker.listener.name=PLAINTEXT# 代理将向客户端通告侦听器名称、主机名和端口。# 如果未设置,则使用listeners的值。advertised.listeners=PLAINTEXT://localhost:9092# 控制器使用的侦听器名称的逗号分隔列表。# 如果在`listener.security.property.map`中没有设置显式映射,则默认将使用PLAINTEXT协议# 如果在KRaft模式下运行,这是必需的。controller.listener.names=CONTROLLER# 将侦听器名称映射到安全协议,默认情况下它们是相同的。有关更多详细信息,请参阅配置文档listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# 服务器用于从网络接收请求并向网络发送响应的线程数num.network.threads=3# 服务器用于处理请求的线程数,其中可能包括磁盘I/Onum.io.threads=8# 套接字服务器使用的发送缓冲区(SO_SNDBUF)socket.send.buffer.bytes=102400# 套接字服务器使用的接收缓冲区(SO_RCVBUF)socket.receive.buffer.bytes=102400# 套接字服务器将接受的请求的最大大小(防止OOM)socket.request.max.bytes=104857600############################# 日志部分 ############################## 以逗号分隔的存储日志文件的目录列表log.dirs=/tmp/kraft-combined-logs# 每个主题的默认日志分区数。更多的分区允许更大的并行性用于消费,但这也会导致跨代理的文件更多。num.partitions=1# 启动时用于日志恢复和关闭时用于刷新的每个数据目录的线程数。# 对于RAID阵列中有数据驱动器的安装,建议增加此值。num.recovery.threads.per.data.dir=1############################# 内部主题设置 ############################## 组元数据内部主题“__consumer_offsets”和“__transaction_state”的复制因子# 对于开发测试以外的任何东西,建议使用大于1的值来确保可用性,例如3。offsets.topic.replication.factor=1transaction.state.log.replication.factor=1transaction.state.log.min.isr=1############################# 日志刷新策略 ############################## 消息会立即写入文件系统,但默认情况下,我们只使用fsync()进行同步# OS缓存延迟。以下配置控制数据到磁盘的刷新。# 这里有一些重要的权衡:# 1. 持久性:如果不使用复制,未擦除的数据可能会丢失。# 2. 延迟:当确实发生刷新时,非常大的刷新间隔可能会导致延迟峰值,因为将有大量数据需要刷新。# 3. 吞吐量:冲洗通常是最昂贵的操作,较小的冲洗间隔可能会导致过度寻道。# 以下设置允许用户配置刷新策略,以便在一段时间后刷新数据,或# 每N条消息(或两者)。这可以在全局范围内完成,并在每个主题的基础上覆盖。# 在强制将数据刷新到磁盘之前要接受的消息数#log.flush.interval.messages=10000# 在强制刷新之前,消息可以在日志中停留的最长时间#log.flush.interval.ms=1000############################# 日志保留策略 ############################## 以下配置控制日志段的处置。该策略可以设置为在一段时间后或累积给定大小后删除段。# 只要满足这些条件中的任何一个,就会删除一个片段。删除总是从日志末尾开始。# 该配置表示 Kafka 会将 topic 中的消息保存 168 小时(7天),超过这个时间的旧日志段(log segments)会被自动删除,log.retention.hours=168# 基于大小的日志保留策略。除非剩余的段降至log.retention.bytes以下,否则将从日志中修剪段。函数独立于log.retenation.hours。#log.retention.bytes=1073741824# 日志段文件的最大大小。当达到此大小时,将创建一个新的日志段。log.segment.bytes=1073741824# 根据保留策略检查日志段是否可以删除的间隔log.retention.check.interval.ms=3000001.挑选关键配置进行修改
节点1: 192.168.0.14
# 节点 ID
node.id=1# 完整的集群通信端口,节点之前互相通信
controller.quorum.voters=1@192.168.0.41:9093,2@192.168.0.17:9093,3@192.168.0.32:9093
#不同服务器绑定的端口,如果不指定ip,直接写//:9092等同于 //0.0.0.0:9092
listeners=PLAINTEXT://192.168.0.41:9092,CONTROLLER://192.168.0.41:9093# 对外发布的地址,调用kafka的配置使用
advertised.listeners=PLAINTEXT://192.168.0.41:9092# 修改kafka数据存储目录
log.dirs=/u01/kafka/data
节点2: 192.168.0.17
# 节点 ID
node.id=2# 完整的集群通信端口,节点之前互相通信
controller.quorum.voters=1@192.168.0.41:9093,2@192.168.0.17:9093,3@192.168.0.32:9093
#不同服务器绑定的端口,如果不指定ip,直接写//:9092等同于 //0.0.0.0:9092
listeners=PLAINTEXT://192.168.0.17:9092,CONTROLLER://192.168.0.17:9093# 对外发布的地址,调用kafka的配置使用
advertised.listeners=PLAINTEXT://192.168.0.17:9092# 修改kafka数据存储目录
log.dirs=/u01/kafka/data
节点3: 192.168.0.32
# 节点 ID
node.id=3# 完整的集群通信端口,节点之前互相通信
controller.quorum.voters=1@192.168.0.41:9093,2@192.168.0.17:9093,3@192.168.0.32:9093
#不同服务器绑定的端口,如果不指定ip,直接写//:9092等同于 //0.0.0.0:9092
listeners=PLAINTEXT://192.168.0.32:9092,CONTROLLER://192.168.0.32:9093# 对外发布的地址,调用kafka的配置使用
advertised.listeners=PLAINTEXT://192.168.0.32:9092# 修改kafka数据存储目录
log.dirs=/u01/kafka/data
2.以上节点都配置完成,初始化集群数据目录
生成存储目录的唯一ID,这个ID将在每个节点使用,这个id类似与zookeeper的cluster.id,标识这些节点属于同一个集群环境,确保数据同步
[root@master-014 kafka]# bin/kafka-storage.sh random-uuid6NH_or3kTSKGMIQGYFYjSw在每一台服务器下执行以下操作:
[root@master-014 kafka]# bin/kafka-storage.sh format -t 6NH_or3kTSKGMIQGYFYjSw -c /u01/kafka/config/kraft/server.propertiesmetaPropertiesEnsemble=MetaPropertiesEnsemble(metadataLogDir=Optional.empty, dirs={/tmp/kraft-combined-logs: EMPTY})Formatting /tmp/kraft-combined-logs with metadata.version 3.7-IV4.执行完成后,就可以看到我们配置的log目录下面生成了mete文件
[root@master-014 kafka]# cd data/[root@master-014 data]# ll总用量 8-rw-r--r--. 1 root root 249 7月 10 11:12 bootstrap.checkpoint-rw-r--r--. 1 root root 122 7月 10 11:12 meta.properties其他两个节点进行相同操作,配置并完成初始化操作。如果后续涉及到节点IP的变更、日志文件夹的变更,都要先删除data目录后,重新生成一个cluster.id然后全量重新初始化
3.启动集群
[-daemon] : 后台运行,目前我们进行测试,直接在终端执行,观察日志,不添加此参数
./bin/kafka-server-start.sh [-daemon] ./config/kraft/server.properties
接下来需要确认,每个节点之间的9093端口是否能够互相访问,如果防火墙限制了端口,会导致启动后报错无法访问其他节点,在每台服务器上防火墙增加端口白名单
# 增加9092端口,外部程序链接访问sudo firewall-cmd --permanent --add-port=9092/tcp# 增加9093端口,内部节点通信,9093端口可以限制仅允许集群节点ip访问sudo firewall-cmd --permanent --add-port=9093/tcp# 重新加载sudo firewall-cmd --reload启动完成后,窗口会输出启动成功的相关信息,如下:
3个节点都启动完成后,使用以下指令查看每个节点的状态,可以看到3个节点
[root@localhost kafka]# bin/kafka-broker-api-versions.sh --bootstrap-server 192.168.0.41:9092192.168.0.17:9092 (id: 2 rack: null) -> (...)192.168.0.32:9092 (id: 3 rack: null) -> (...)192.168.0.41:9092 (id: 1 rack: null) -> (...)4.测试集群情况
创建一个名为test-topic的topic,因为是3个节点,因此设置3分区、3副本
[root@localhost kafka]# bin/kafka-topics.sh --create --topic test-topic --bootstrap-server 192.168.0.41:9092 --partitions 3 --replication-factor 3Created topic test-topic. 单独给每一个kafka节点都开一个窗口,消费这个队列消息,再开一个窗口选择任意节点往这个队列推送消息,可以看到生产消息的同时,3个节点都消费到了消息,如下图所示:
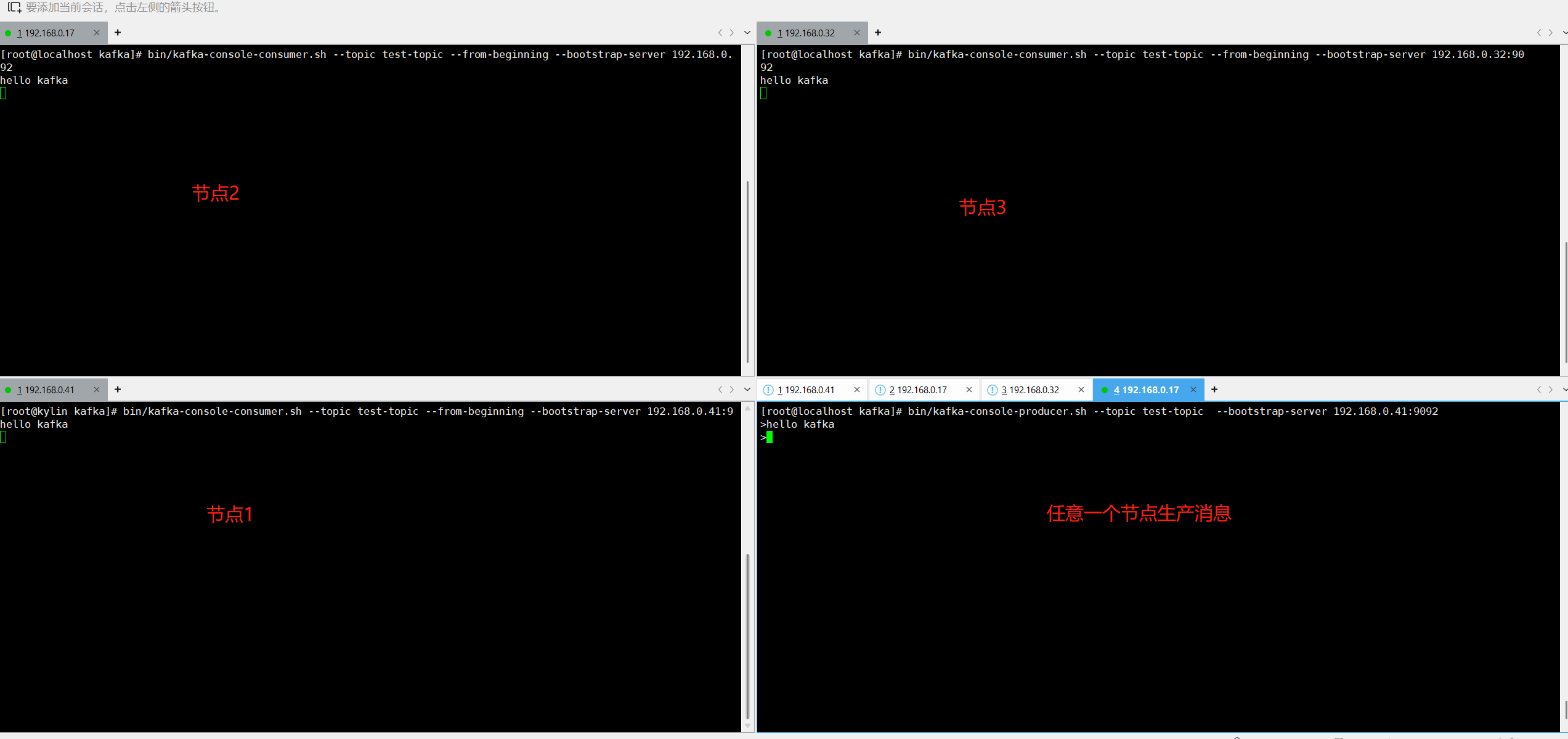
本文内容就完成了,希望对你有帮助~

