TVP:用于高效二维时序视频定位的文本-视觉提示方法_tvp视觉提示的局限形式什么
温馨提示:
本篇文章已同步至\"AI专题精讲\" TVP:用于高效二维时序视频定位的文本-视觉提示方法
摘要
本文研究的是时序视频定位(Temporal Video Grounding,TVG)问题,其目标是在一段未经剪辑的长视频中,根据一条文本描述预测对应事件片段的起始和结束时间点。近年来,得益于精细的三维视觉特征,TVG 技术取得了显著进展。然而,三维卷积神经网络(3D CNN)计算复杂度高,使得密集的 3D 视觉特征提取过程耗时,且需要大量的内存和计算资源。
为实现高效的 TVG,本文提出了一种新颖的文本-视觉提示(Text-Visual Prompting, TVP)框架,该框架将优化后的扰动模式(我们称之为“提示(prompts)引入 TVG 模型的视觉输入与文本特征中。与 3D CNN 方法形成鲜明对比的是,我们证明 TVP 能够在二维 TVG 模型中有效联合训练视觉编码器与语言编码器,并且仅使用低复杂度的稀疏二维视觉特征,就可以提升跨模态特征融合的性能。
此外,我们提出了一种新的 Temporal-Distance IoU(TDIoU)损失函数,以支持高效的 TVG 学习过程。在两个基准数据集 Charades-STA 和 ActivityNet Captions 上的实验证明,所提出的 TVP 方法显著提升了 2D TVG 的性能(例如在 Charades-STA 上提升 9.79%,在 ActivityNet Captions 上提升 30.77%),同时在推理速度上相较基于 3D 视觉特征的 TVG 模型实现了 5 倍加速。
1. 引言
近年来,时序视频定位(TVG)任务 [30, 74] 取得了显著进展。其中一个关键因素是通过三维卷积神经网络(如 C3D [56] 和 I3D [3])提取的精细密集 3D 视觉特征,因为 TVG 任务需要时空上下文来定位文本查询描述的时刻片段。然而,由于提取这些密集 3D 特征的计算成本极高,目前大多数 TVG 模型通常仅使用由离线 3D CNN 提取的视觉特征作为输入,而不是在 TVG 模型训练过程中联合训练视觉特征提取模块。
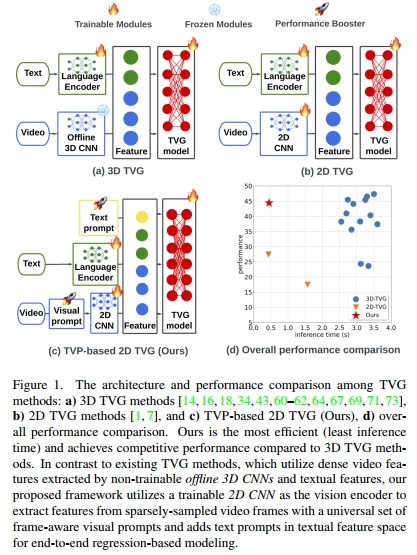
尽管使用 3D 视觉特征的模型(我们称之为“3D 方法或模型”)在性能上优于使用 2D 特征的模型(我们称之为“2D 方法或模型”),但 2D 方法具有一个独特优势,即在 TVG 任务中提取 2D 视觉特征可以显著降低计算成本 [14, 15, 30, 34, 61, 62, 69, 74, 75]。在计算机视觉、自然语言处理和视频-语言任务中,也迫切需要一种高效轻量、性能合理的解决方案 [19, 23, 38, 41, 68, 76–80]。如上所述,采用 3D 视频特征的方法在实际应用中面临较大挑战。因此,开发用于 TVG 任务的紧凑型 2D 解决方案具有重要的实际与经济价值。
在本文中,我们提出了以下问题:
如何提升 2D TVG 方法,使其能够达到与 3D TVG 方法相当的效果?为了解决这一问题,我们提出了一种新颖的 文本-视觉提示(Text-Visual Prompting, TVP) 框架,用于在使用 2D 视觉特征的情况下训练 TVG 模型。如图 1 所示,现有的 2D TVG 和 3D TVG 方法均采用离线预训练的视觉编码器和语言编码器进行特征提取。而与之不同,我们提出的 TVP 框架是端到端可训练的。此外,得益于文本-视觉提示机制以及在大规模图文数据集上的跨模态预训练,我们的框架在推理速度显著加快的同时,能够取得与 3D TVG 方法相当的性能。
传统的 TVG 方法通常包含三个阶段:
① 从视觉和文本输入中提取特征;
② 多模态特征融合;
③ 跨模态建模。
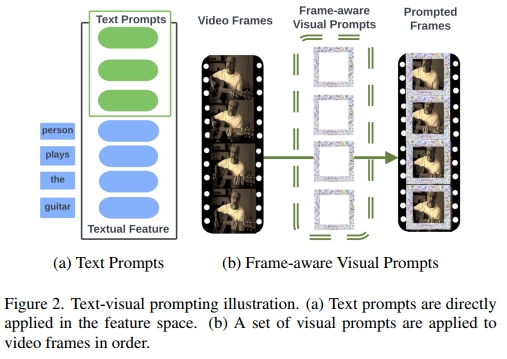
而 TVP 不同于传统方法,它在 TVG 模型的视觉输入和文本特征中引入了优化的输入扰动模式(我们称之为 “prompts”)。我们在文本特征中加入可训练参数作为 文本提示(text prompts),并设计了一套通用的、感知帧位置的模式作为 视觉提示(visual prompts)。具体来说,我们从视频中采样固定数量的帧,在训练过程中对输入查询句子的文本提示和不同时间位置帧的视觉提示进行优化;在测试时,将同一组优化后的视觉提示和文本提示应用于所有测试视频。图 2 中展示了引入的视觉提示与文本提示示意图。据我们所知,这是首次在使用 2D 视觉特征的回归型 TVG 任务中成功引入提示学习以提升性能的工作。
与 3D CNN 相比,2D CNN 在特征提取时会丢失视频的时空信息。受 transformer 在视觉-语言任务中成功应用的启发 [9, 22, 35, 44, 47, 54, 55],以及提示学习近期在视觉与语言领域 transformer 中的应用 [2, 25, 27, 32, 37, 40],我们选择以 transformer 作为基础的 TVG 模型,并提出使用提示机制来弥补 2D 视觉特征中缺失的时空信息。此外,我们还提出了一种用于训练的 时间距离 IoU(Temporal-Distance IoU, TDIoU)损失函数。
我们提出的框架在以下两个方面区别于已有方法:
- 首先,它专为提升使用 2D CNN 作为视觉编码器的回归型 TVG 方法的性能而设计,而非为了迁移学习 [2, 21, 26];
- 其次,它使用 2D CNN 从稀疏采样的视频帧中提取视觉特征,这比使用 3D 方法所需内存更少,更适用于长视频等实际应用场景 [34, 60–62, 69, 75]。
此外,得益于 2D CNN 的紧凑设计,我们提出的框架能够实现语言编码器与视觉编码器的联合训练,以促进更有效的多模态特征融合。总结而言,本工作的贡献包括:
• 我们提出了一个高效有效的框架,用于训练 2D TVG 模型,在该框架中我们引入了 TVP(文本-视觉提示)机制,以提升稀疏 2D 视觉特征的利用效率,而无需依赖代价高昂的 3D 特征。据我们所知,这是首个将提示学习扩展应用于 TVG 问题的工作。我们的方法在所有 2D 方法中取得最优,并在性能上可与 3D TVG 方法媲美。
• 在技术层面,我们将视觉提示与文本提示相结合,共同提升 2D 视觉特征的有效性。在此基础上,我们提出了一种基于TDIoU(时间距离 IoU)的提示-模型协同训练方法,以获得高精度的 2D TVG 模型。
• 在实验层面,我们验证了所提出方法在 Charades-STA 和 ActivityNet Captions 数据集上的实证效果。例如,在 Charades-STA 上提升了 9.79%,在 ActivityNet Captions 上提升了30.77%,并且相比 3D TVG 方法,推理速度提升达 5 倍。
2. 相关工作
Video Temporal Grounding(TVG)。TVG 的目标是根据一段文本描述,在未经裁剪的视频中预测目标片段的起始和结束时间点。早期的 TVG 方案 [7,14,20,39,62,64,70] 主要采用两阶段的 “提议-排序” 流水线:① 提议:使用滑动窗口或提议网络从输入视频中生成候选片段;② 排序:根据文本查询对候选片段进行排序,得分最高的候选即为最终预测结果。相比基于提议的方法,基于回归的方法 [16, 67, 69] 直接预测目标片段的起始/结束时间点,无需对大量候选进行排序,因此推理速度更快,这也是我们工作聚焦于回归式 TVG 的原因之一。此外,基于强化学习(RL)的方法则将 TVG 任务建模为一系列决策过程 [18, 60]。特别地,这类方法训练一个智能体,通过移动或缩放窗口来定位目标片段。在训练过程中,如果调整后的窗口更接近目标时刻,则智能体获得奖励,反之受到惩罚。
Temporal Action Detection(TAD)。TAD 旨在判断视频中是否存在预定义的动作,并预测其发生的时间区间 [12,13,48,53,56,59,63]。与 TVG 不同,TAD 的输入仅为视频,也就是说,TAD 只需要对视频进行语义理解。而 TVG 不仅需要理解视频,还需理解自然语言,同时还要处理视频与语言之间的多模态交互。因此,TVG 任务的挑战性更大。
Text Prompting。提示学习近年来在自然语言处理领域取得了巨大成功 [25, 32, 37, 40, 46, 49–52, 58]。文本提示是一种数据无关的扰动操作,应用于文本输入或其嵌入向量,以提升下游任务的性能。最简单的方式是通过人类设计构造输入模板 [46, 49–51]。虽然人工模板简单且可解释,但通常不是最优的输入提示。为此,研究者提出了在离散输入空间 [25, 52, 58] 或语言模型的嵌入空间中 [32, 37, 40] 搜索最优提示的方法。
Visual Prompting。受 NLP 领域提示学习的启发,Bahng 等人首次提出视觉提示(VP)方法 [2],用于重编程源视觉模型(如 ImageNet 预训练分类器)以完成下游目标任务(如 CIFAR-10 图像分类)。VP 与视觉领域中的模型重编程技术本质上是一致的 [4–6, 11, 57, 65, 72, 81],即向测试图像加入一种通用的输入扰动,以提升目标任务的性能指标,如准确率、鲁棒性或公平性。
Multi-Modal Prompting。尽管视觉提示和文本提示近期受到广泛关注,但在多模态学习任务中仍较少探索,尤其是在时间视频定位任务(TVG)上。现有研究 [2, 27, 66] 主要聚焦于将文本与视觉提示集成进 CLIP(对比语言-图像预训练)模型,以提升基于图像的数据下游任务性能。而在视频理解任务中,多模态提示的相关研究几乎为空白。本文首次开发了文本-视觉提示技术(TVP),以在使用 2D 视觉特征的前提下,提升 TVG 任务的性能。
3. 方法
本节将首先介绍基于回归的 TVG 问题的形式化定义,随后我们将展示 TVP(text-visual prompts,文本-视觉提示)的设计,并给出我们提出的 TVP 框架的总体概览。
3.1 问题定义
设 v∈ R N v i d × C × H × W v \\in \\mathbb{R}^{N_{vid} \\times C \\times H \\times W} v∈RNvid×C×H×W 表示一个未经裁剪的视频序列,由 N v i d N_{vid} Nvid 帧图像组成;设 s∈ R N t e x s \\in \\mathbb{R}^{N_{tex}} s∈RNtex 表示由 N t e x N_{tex} Ntex 个语言 token 组成的文本查询。此处,视频-查询对 (v,s) (v, s) (v,s) 来自于一个视频语言数据集 D D D。给定 v v v 和 s s s,TVG 的目标是预测由查询 s s s 所描述的视频片段的时间区间 T ^ =( t ^s t a , t ^e n d ) \\hat{T} = (\\hat{t}_{sta}, \\hat{t}_{end}) T^=(t^sta,t^end)。该任务中的视觉-语言融合模型可表述为:
T ^ = f ( g t e x( s ) , g v i d( v ) ) ( 1 ) \\hat { \\mathbf { T } } = f \\big ( \\, g _ { \\mathrm { t e x } } ( \\mathbf { s } ) , \\, g _ { \\mathrm { v i d } } ( \\mathbf { v } ) \\, \\big )\\quad(1) T^=f(gtex(s),gvid(v))(1)
其中, f f f 表示 TVG 模型本体, g v i d g_{vid} gvid 和 g t e x g_{tex} gtex 分别表示视觉编码器和语言编码器。
3.2 TDIoU 损失函数
传统上,TVG 模型通过最小化时间 IoU 损失 L t I o U L_{tIoU} LtIoU 来训练,定义如下:
L t I o U= ( 1 − T ^ ( θ ) ⋂ T T ^ ( θ ) ⋃ T ) ( 2 ) \\mathcal { L } _ { \\mathrm { t I o U } } = \\left( 1 - \\frac { \\hat { \\mathbf { T } } ( \\boldsymbol { \\theta } ) \\bigcap \\mathbf { T } } { \\hat { \\mathbf { T } } ( \\boldsymbol { \\theta } ) \\bigcup \\mathbf { T } } \\right)\\quad(2) LtIoU=(1−T^(θ)⋃TT^(θ)⋂T)(2)
其中,为简化表示,令 θ \\theta θ 表示公式 (1) 中所有可训练参数, T=( t s t a , t e n d ) T = (t_{sta}, t_{end}) T=(tsta,tend) 为与输入视频-查询对 (v,s) (v, s) (v,s) 对应的目标片段的真实时间区间。公式 (2) 的核心思想是最大化预测时间区间与其真实值之间的重叠程度。
然而,在预测区间与真实区间没有重叠的情况下,时间 IoU 损失 L t I o U L_{tIoU} LtIoU 会面临梯度消失问题。受 [82] 启发,我们提出了一种新型的 TDIoU(Temporal-Distance IoU)损失函数,用于训练我们提出的 TVG 模型。TDIoU 在原始 IoU 的基础上引入了预测视频片段与目标片段的中心时间点差距和持续时间差异,且这两项都是归一化处理的。我们将在下文进一步详细介绍该损失函数的设计。
距离损失 L dis L_{\\text{dis}} Ldis
为了避免在预测区间与真实区间不重叠的情况下导致的梯度消失问题,我们引入了距离损失 L dis L_{\\text{dis}} Ldis,通过直接最小化归一化后的中心时间点差距来缓解该问题。此外,我们添加了一个阈值 α 1 \\alpha_1 α1,用于防止训练后期出现震荡现象。该距离损失定义如下:
L dis = max ( ∣ t s t a + t e n d 2 − t ^ s t a + t ^ e n d 2 ∣ ∣ T ^ ∪ T ∣ , α 1 ) ( 3 ) L_{\\text{dis}} = \\max \\left( \\frac{ \\left| \\frac{t_{sta} + t_{end}}{2} - \\frac{\\hat{t}_{sta} + \\hat{t}_{end}}{2} \\right| }{ | \\hat{T} \\cup T | }, \\alpha_1 \\right)\\quad(3) Ldis=max ∣T^∪T∣ 2tsta+tend−2t^sta+t^end ,α1 (3)
其中, T=( t s t a , t e n d ) T = (t_{sta}, t_{end}) T=(tsta,tend) 是真实时间区间, T ^ \\hat{T} T^ 是由 TVG 模型(公式 1)预测的时间区间。实验中我们将 α 1 \\alpha_1 α1 设置为 0.2。
持续时间损失 L dur L_{\\text{dur}} Ldur
虽然距离损失 L dis L_{\\text{dis}} Ldis 缓解了梯度消失问题,但它只关注了中心时间点之间的差距,而忽略了时间段本身的长度差异。这种设计在某些情况下可能不够精确——例如,若两个视频片段的中心点重合,但持续时间却完全不同,模型可能依旧产生较大误差。为了解决这一问题,我们进一步提出了持续时间损失 L dur L_{\\text{dur}} Ldur,定义如下:
L dur = max (∣ T − T ^ ( θ ) ∣ ∣ T ∣ , α 2 ) , (4) L_{\\text{dur}} = \\max \\left( \\frac{ \\left| T - \\hat{T}(\\theta) \\right| }{ |T| }, \\alpha_2 \\right), \\tag{4} Ldur=max ∣T∣ T−T^(θ) ,α2 ,(4)
其中, α 2 \\alpha_2 α2 是我们设定的精度容忍阈值,实验中取值为 0.4。
最终的 TDIoU 损失函数
我们提出的 TDIoU(Temporal-Distance IoU)损失函数 综合了三部分:传统的时间 IoU 损失、距离损失和持续时间损失。最终损失函数定义如下:
L = L tIoU + β 1 L dis + β 2 L dur , (5) L = L_{\\text{tIoU}} + \\beta_1 L_{\\text{dis}} + \\beta_2 L_{\\text{dur}}, \\tag{5} L=LtIoU+β1Ldis+β2Ldur,(5)
其中, β 1 >0 \\beta_1 > 0 β1>0、 β 2 >0 \\beta_2 > 0 β2>0 是正则化系数,用于调节三项损失在训练中的权重。
3.3 文本-视觉提示设计
受到在 transformers 中使用提示(prompts)的应用启发 [2, 21, 36, 37],我们提出了联合文本-视觉提示(text-visual prompting)来提升模型性能,其中提示作为优化的扰动模式。在提高数据处理效率方面,我们从未裁剪的视频 v 中均匀采样视频帧,得到 v s a m ∈ R N s a m × C × H × W \\mathbf { v } _ { \\mathrm { s a m } } \\in \\mathbb { R } ^ { N _ { \\mathrm { s a m } } \\times C \\times H \\times W } vsam∈RNsam×C×H×W,其中 Nsam 为采样的帧数。此外,我们在采样的视频帧的像素空间中引入了一组帧感知的视觉提示 δ v p ∈ R N s a m × d v p \\delta _ { \\mathrm { v p } } \\; \\in \\; \\mathbb { R } ^ { N _ { \\mathrm { s a m } } \\times d _ { \\mathrm { v p } } } δvp∈RNsam×dvp,并在文本特征空间中引入了文本提示 δ t p ∈ R N t p × d t p \\delta _ { \\mathrm { t p } } \\, \\in \\, \\mathbb { R } ^ { N _ { \\mathrm { t p } } \\times d _ { \\mathrm { t p } } } δtp∈RNtp×dtp。通过将视频帧采样和文本-视觉提示结合到 TVG 模型(1)中,我们得到:
( t ^ s t a, t ^ e n d) = f ( δ t p, g t e x( s ) , g v i d( v s a m+ δ v p) ) ( 6 ) ( \\hat { t } _ { \\mathrm { s t a } } , \\hat { t } _ { \\mathrm { e n d } } ) = f ( \\, \\delta _ { \\mathrm { t p } } , \\; g _ { \\mathrm { t e x } } ( \\mathbf { s } ) , \\; g _ { \\mathrm { v i d } } ( \\mathbf { v } _ { \\mathrm { s a m } } + \\delta _ { \\mathrm { v p } } ) \\, \\, ) \\quad(6) (t^sta,t^end)=f(δtp,gtex(s),gvid(vsam+δvp))(6)
给定一个预训练的 2D TVG 模型 f,文本-视觉提示(TVP)的目标是学习一组通用的视觉提示 δ v p \\delta _ { \\mathrm { v p } } δvp 和文本提示 δ t p \\delta _ { \\mathrm { t p } } δtp ,分别集成到采样的视频帧和文本特征中。具体来说,一组不同的视觉提示会按顺序应用到一个未裁剪视频的均匀采样帧中。在训练过程中,只有视觉提示和文本提示集通过反向传播进行更新。在微调过程中,提示被冻结,TVG 模型和编码器的参数会进行更新。在测试阶段,优化后的视觉提示集和文本提示集会应用到所有测试时的视频-查询对。
3.4. 框架
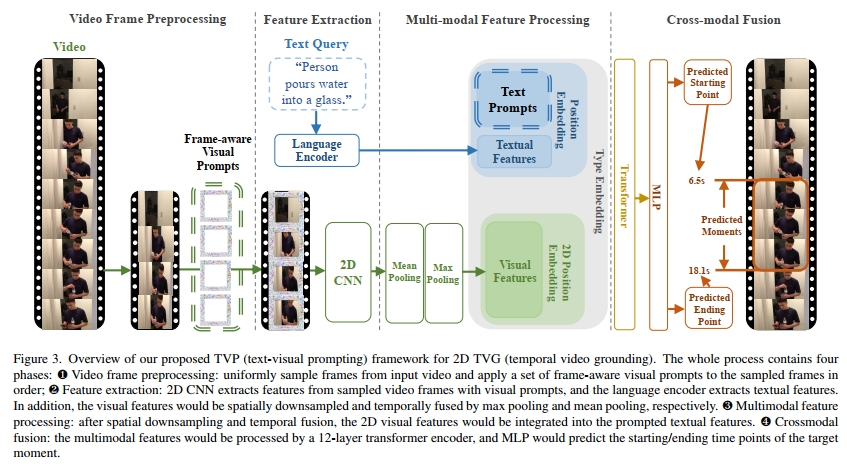
受到 transformers 在视觉-语言任务中成功应用的启发,我们选择了 ClipBERT [31] 作为 2D TVG 的基础模型。从 ClipBERT 扩展出来,我们的基于回归的 TVG 模型的输入为可描述的句子和均匀采样的未裁剪视频帧,如图 3 所示。然后,目标视频片段的预测起始和结束时间点将作为模型输出。如算法 1 所述,我们提出的 TVP 框架包含四个阶段:
❶ 视频帧预处理:我们从一个输入的未裁剪视频 v 中获得稀疏采样的帧 vsam,并在填充位置上应用通用的帧感知视觉提示 δ v p \\delta _ { \\mathrm { v p } } δvp。
❷ 特征提取:2D 视觉编码器(ResNet-50 的前 5 个 ConvBlock)gvid 和语言编码器(一个可训练的词嵌入层)gtex 分别从提示后的帧 vsam′ 和文本输入 s 中提取特征。
❸ 多模态特征处理:按照 Pixel-BERT [22] 的设置,2D 视觉特征 Qvid 通过 2×2 的最大池化层进行空间下采样,并通过均值池化层在时间上进行融合。然后,文本提示 δ t p \\delta _ { \\mathrm { t p } } δtp 被集成到文本特征 Q t e x \\mathbf { Q } _ { \\mathrm { t e x } } Qtex 中。此外,可训练的 2D 视觉位置嵌入 M2D 和文本位置嵌入 Mpos 被应用于处理后的 2D 视觉特征 Q v i d ′ \\mathbf { Q } _ { \\mathrm { v i d } } ^ { \\prime } Qvid′ 和提示后的文本特征 。之后,处理和位置编码后的 2D 视觉特征 Q v i d′ ′ \\mathbf { Q } _ { \\mathrm { v i d } } ^ { \\prime \\prime } Qvid′′被展平并集成到提示和位置编码后的文本特征 Q t e x ′ , \\mathbf { Q } _ { \\mathrm { t e x } } ^ { \\prime } , Qtex′,中。此外,类型嵌入 Mtype 会被添加到集成的多模态特征 Q a l l \\mathbf { Q } _ { \\mathrm { a l l } } Qall 中,以指示特征的源类型。
❹ 跨模态融合:使用一个 12 层的 transformers [10] 对 Qall 进行跨模态融合,然后使用一个多层感知器(MLP),最后通过 sigmoid 函数作为预测头,处理变换器的最后一层跨模态表示 Q C M \\mathbf { Q } _ { \\mathrm { C M } } QCM,从而生成目标时刻的预测起始/结束时间点 ( t ^s t a , t ^s t a ) ( \\hat { t } _ { \\mathrm { s t a } } , \\hat { t } _ { \\mathrm { s t a } } ) (t^sta,t^sta),这些时刻由文本查询输入描述。
温馨提示:
阅读全文请访问\"AI深语解构\" TVP:用于高效二维时序视频定位的文本-视觉提示方法


