第二十五篇 Selenium模拟真人点击登录,搞定动态网站与复杂交互!你的终极爬虫!_爬虫点击工具 csdn
模拟人工,终极爬虫
- 序言 静态爬虫搞不定?面对动态网站与登录交互
- 1. 你的“虚拟浏览器”:Selenium库入门
-
- 1.1 爬虫自动化利器,安装Selenium与浏览器驱动
- 1.2 第一个Selenium脚本:Python自动打开网页
- 2.Python模拟真人点击与表单填写
-
- 2.1 模拟点击:像人一样点击网页元素
- 2.2 模拟输入与表单填写:自动化数据提交
- 3.动态网站与高级操作
-
- 3.1 处理弹窗与切换窗口:让Python应对多变场景
- 3.2 执行JavaScript:与网页“深度对话”
- 4.验证码与多因素认证的思路和策略
-
- 4.1验证码处理:从手动到半自动(文字/滑块/点选)
- 4.2多因素认证(MFA)策略:更高安全层级的自动化挑战
- 5.成果:你的“终极爬虫工具”!
- 6.尾声:Selenium自动化,开启无限可能!
序言 静态爬虫搞不定?面对动态网站与登录交互
在上一篇中,我们学习了如何使用Requests和BeautifulSoup来抓取网站信息,构建了你的“智能信息收集器”。然而,你很快就会遇到这样的“拦路虎”:
数据动态加载: 很多网站的内容,在你访问时并不是直接显示在HTML里的,而是通过JavaScript(JS)异步加载出来的(比如评论
数据需要登录: 很多系统不是直接就可以抓取的,需要携带令牌,比如密码,比如token,等等,需要鉴权后才能开放服务。
验证码的阻挠: 还有些系统防止机器登录,需要通过验证码,或者是选择,或者是滑动,对于爬虫自动化而言都是现实的挑战。
如何破局呢?其实最好的方法就是模拟,通过模拟浏览器的行为,甚至可以控制浏览器,类似真人操作一样,这样在大型自动化测试中广泛使用。
1. 你的“虚拟浏览器”:Selenium库入门
要搞定复杂的动态网站和交互,我们需要一个能模拟真实浏览器行为的工具——Selenium!
它不是一个普通的网络请求库,而是一个自动化测试工具,可以直接控制浏览器(如Chrome, Firefox),像真人一样点击、输入、滚动、等待,从而获取JavaScript动态加载的内容,实现Python自动化抓取。
作用: Selenium通过浏览器驱动(WebDriver),直接发送指令给浏览器,让浏览器执行你的自动化任务。
1.1 爬虫自动化利器,安装Selenium与浏览器驱动
安装它需要两个部分组成
python库: pip install selenium
浏览器驱动 (WebDriver): 这是连接Python脚本和实际浏览器的“桥梁”。你需要下载对应你浏览器版本的驱动。
下载浏览器驱动 (以Chrome为例):
查看Chrome浏览器版本: 打开Chrome浏览器,在地址栏输入 chrome://version 并回车。找到“Google Chrome”后的版本号(例如 120.0.6099.109)。
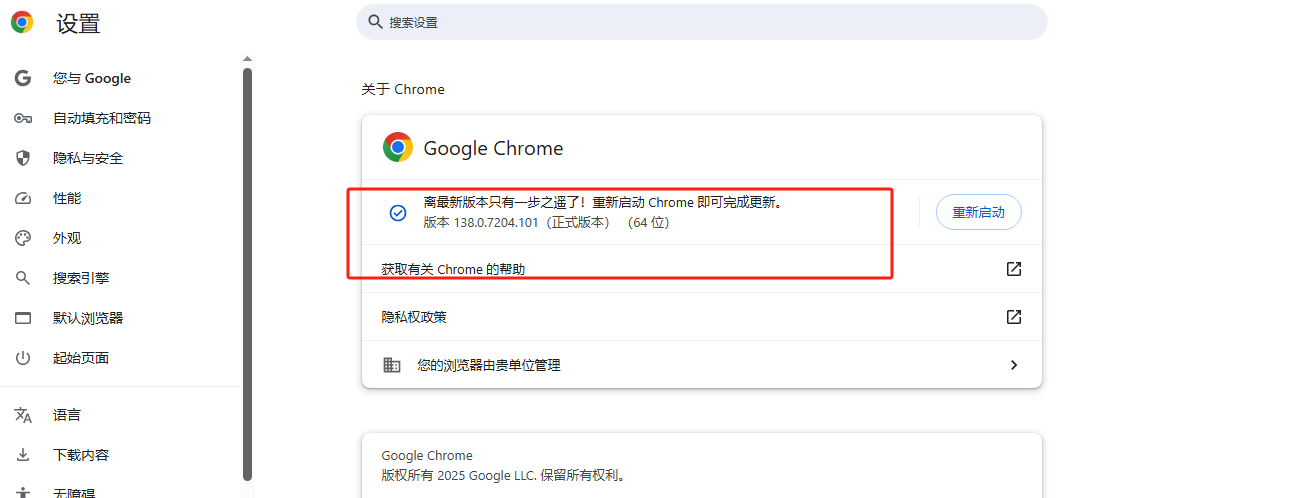
下载对应驱动: 访问ChromeDriver官方下载页面:https://chromedriver.chromium.org/downloads。找到与你Chrome浏览器版本号完全匹配或最接近的ChromeDriver版本。
解压并放置: 将下载的 chromedriver.zip 解压,得到 chromedriver.exe。
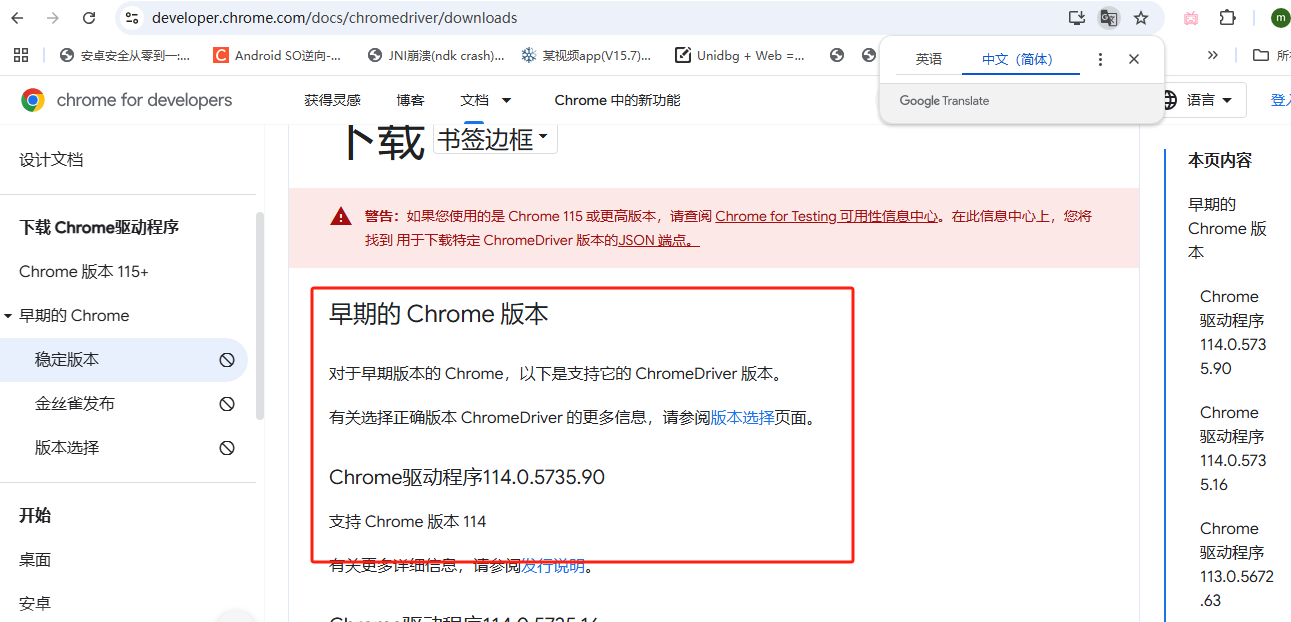
放置路径:
放置到Python脚本同目录: 最简单,直接将 chromedriver.exe 放到你的Python脚本所在的文件夹。
1.2 第一个Selenium脚本:Python自动打开网页
让我们来编写第一个Selenium脚本,让Python自动打开一个网页!
代码:
```gofrom selenium import webdriverfrom selenium.webdriver.chrome.service import Service # 推荐使用Service来管理驱动from selenium.webdriver.common.by import By # 导入By模块用于元素定位import osimport time # 用于添加延时def open_webpage_example(url, driver_path): \"\"\" 使用Selenium自动打开指定网页。 这是浏览器自动化的基础,也是Python自动化抓取的第一步。 :param url: 要打开的网页URL :param driver_path: ChromeDriver的路径 (如果不在PATH中) \"\"\" # 1. 配置浏览器驱动服务 # Service对象会管理ChromeDriver的启动和关闭 service = Service(executable_path=driver_path) # 2. 初始化Chrome浏览器 # options可以设置浏览器的一些行为,如无头模式(不显示浏览器界面) options = webdriver.ChromeOptions() # options.add_argument(\"--headless\") # 启用无头模式 (浏览器不显示界面在后台运行) # options.add_argument(\"--disable-gpu\") # 禁用GPU,在无头模式下有时需要 driver = None # 初始化driver为None,确保在finally中关闭 try: driver = webdriver.Chrome(service=service, options=options) # 3. 打开网页 print(f\"🚀 正在打开网页:{url}\") driver.get(url) print(f\"✅ 网页已打开,当前标题:{driver.title}\") time.sleep(3) # 暂停3秒,以便观察效果 except Exception as e: print(f\"❌ 打开网页失败:{e}\") finally: if driver: print(\"✨ 关闭浏览器。\") driver.quit() # 关闭浏览器进程和WebDriver服务if __name__ == \"__main__\": test_url = \"https://www.baidu.com\" # 百度首页 # 请替换为你的ChromeDriver.exe的实际路径 # 如果已将chromedriver.exe放到系统PATH中,可以直接写 \"chromedriver.exe\" chrome_driver_path = os.path.expanduser(\"~/Desktop/chromedriver.exe\") # 确保ChromeDriver.exe在指定路径 if not os.path.exists(chrome_driver_path): print(f\"请将chromedriver.exe放置到 \'{os.path.dirname(chrome_driver_path)}\' 目录。\") else: open_webpage_example(test_url, chrome_driver_path)操作:
准备ChromeDriver: 将chromedriver.exe放到你的Python脚本同目录或系统PATH中。
修改代码路径和URL: 复制上方代码到VS Code,保存为selenium_open_webpage.py。修改 chrome_driver_path 和 test_url。
运行: 在VS Code终端运行 python
selenium_open_webpage.py。
2.Python模拟真人点击与表单填写
仅仅打开网页还不够,真正的Python自动化抓取需要与网页进行交互。Selenium能够精确模拟真人点击网页元素,并自动化表单填写,提交数据。
作用: Selenium通过元素定位(如ID、XPath、CSS选择器)找到网页上的特定元素,然后调用其方法(如click(),send_keys())进行操作。
2.1 模拟点击:像人一样点击网页元素
场景: 网站有“下一页”按钮,或者需要点击某个链接才能显示更多内容。传统爬虫无法触发JS事件。
方案: Selenium能够通过元素定位,精准点击按钮、链接或任何可点击的网页元素。
代码:
from selenium import webdriverfrom selenium.webdriver.chrome.service import Servicefrom selenium.webdriver.common.by import Byimport osimport timedef simulate_click_example(url, driver_path): \"\"\" 使用Selenium自动打开网页并模拟点击元素。 这是Python自动化抓取和模拟真人点击的基础。 :param url: 要打开的网页URL :param driver_path: ChromeDriver的路径 \"\"\" service = Service(executable_path=driver_path) options = webdriver.ChromeOptions() driver = None try: driver = webdriver.Chrome(service=service, options=options) driver.get(url) print(f\"🚀 网页已打开:{driver.title}\") time.sleep(2) # 等待页面加载完成 # **核心操作:定位元素并点击** # 以百度首页为例,点击“新闻”链接 # 1. 找到新闻链接的定位方式 (通常通过F12开发者工具查看) # 假设新闻链接的text是“新闻”,或者其class/id news_link = driver.find_element(By.LINK_TEXT, \"新闻\") # 通过链接文本定位 # 或者 By.ID, By.CLASS_NAME, By.XPATH, By.CSS_SELECTOR 等 print(f\"✅ 找到新闻链接,正在点击...\") news_link.click() # 点击元素 time.sleep(3) # 观察点击后的效果 print(f\"✨ 点击后页面标题:{driver.title}\") except Exception as e: print(f\"❌ 模拟点击失败:{e}\") finally: if driver: driver.quit()if __name__ == \"__main__\": test_url = \"https://www.baidu.com\" chrome_driver_path = os.path.expanduser(\"~/Desktop/chromedriver.exe\") simulate_click_example(test_url, chrome_driver_path)操作:
准备ChromeDriver: 同1.2节。
修改代码路径和URL: 修改 chrome_driver_path 和 test_url。
运行: 运行 python selenium_simulate_click.py。
效果展示:
2.2 模拟输入与表单填写:自动化数据提交
场景: 每天重复登录同一个系统,记住并输入复杂的账号密码很麻烦。
方案: 使用Selenium定位到用户名和密码输入框,调用send_keys()方法自动输入,然后点击登录按钮,实现自动化输入账号密码。
代码:
from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timedef auto_login(url, username_locator, password_locator, login_button_locator, username, password): \"\"\" 自动化登录网页。 这是Selenium模拟登录和自动化输入账号密码的核心功能。 :param url: 登录页面URL :param username_locator: 用户名输入框的定位器 (By.ID, \"id_value\") :param password_locator: 密码输入框的定位器 (By.NAME, \"name_value\") :param login_button_locator: 登录按钮的定位器 (By.XPATH, \"//button[text()=\'登录\']\") :param username: 账号 :param password: 密码 \"\"\" driver = None try: driver = webdriver.Chrome() driver.get(url) time.sleep(2) # 等待页面加载 # 定位并输入用户名 driver.find_element(username_locator[0], username_locator[1]).send_keys(username) print(f\"✅ 已输入用户名:{username}\") time.sleep(0.5) # 模拟真人输入间隔 # 定位并输入密码 driver.find_element(password_locator[0], password_locator[1]).send_keys(password) print(f\"✅ 已输入密码。\") time.sleep(0.5) # 定位并点击登录按钮 driver.find_element(login_button_locator[0], login_button_locator[1]).click() print(\"✅ 已点击登录按钮。\") time.sleep(5) # 等待登录完成或页面跳转 print(f\"当前页面标题:{driver.title}\") if \"登录成功\" in driver.title or \"dashboard\" in driver.current_url: # 简单判断登录是否成功 print(\"✨ 登录成功!\") else: print(\"⚠️ 登录可能失败,请检查账号密码或页面状态。\") except Exception as e: print(f\"❌ 自动化登录失败:{e}\") finally: if driver: driver.quit()if __name__ == \"__main__\": # 请替换为你要登录的网站URL和对应元素的定位器 # 示例使用一个虚拟的登录页面参数,实际请自行替换 # 假设登录页面有 id=\"username\", name=\"password\", id=\"loginBtn\" auto_login( url=\"https://example.com/login\", # 替换为实际登录URL username_locator=(By.ID, \"username\"), password_locator=(By.NAME, \"password\"), login_button_locator=(By.ID, \"loginBtn\"), username=\"your_username\", # 你的账号 password=\"your_password\" # 你的密码 ) print(\"请根据实际网站元素调整定位器和账号密码进行测试。\")步骤:
准备环境: pip install selenium,并下载ChromeDriver。
选择登录页面: 找一个测试网站的登录页面(切勿在重要账户或敏感网站上进行测试!)。
使用浏览器开发者工具分析用户名、密码框和登录按钮的定位器(id、name、xpath等)。
修改代码: 复制上方代码到VS Code,保存为auto_login.py。修改 url、定位器和账号密码。
运行: 运行 python auto_login.py。
效果展示:
3.动态网站与高级操作
现代网站充满了动态加载内容、弹窗、以及需要特殊处理的交互。Selenium的强大在于它能模拟用户的这些“高级操作”,让你轻松搞定动态网站与复杂交互!
作用: 等待元素出现、切换到特定上下文(如iframe、新窗口)、直接执行JavaScript代码。
3.1 处理弹窗与切换窗口:让Python应对多变场景
场景: 网页上突然弹出广告窗口,或者点击某个链接会打开一个新窗口,常规爬虫无法处理。
方案: Selenium的switch_to.alert用于处理浏览器弹窗,driver.window_handles用于管理多窗口。
代码:
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECimport timedef handle_popups_windows(url): \"\"\" 自动化处理网页弹窗和多窗口切换。 这是Python复杂交互和网页自动化进阶。 \"\"\" driver = None try: driver = webdriver.Chrome() driver.get(url) print(f\"✅ 已打开网址:{url}\") # 示例1:处理JS弹窗 (alert, confirm, prompt) # 假设页面上有一个JS按钮会触发alert # driver.find_element(By.ID, \"alert_button\").click() # WebDriverWait(driver, 10).until(EC.alert_is_present()) # 等待alert出现 # alert = driver.switch_to.alert # 切换到alert # print(f\"捕获到弹窗信息: {alert.text}\") # alert.accept() # 接受 (点击确定) 或 alert.dismiss() (点击取消) # print(\"✅ 弹窗已处理。\") # time.sleep(1) # 示例2:处理新窗口/新标签页 # 假设页面上有一个链接会打开新窗口 # original_window = driver.current_window_handle # 获取当前窗口句柄 # driver.find_element(By.ID, \"new_window_link\").click() # WebDriverWait(driver, 10).until(EC.new_window_is_opened(driver.window_handles)) # 等待新窗口打开 # for window_handle in driver.window_handles: # 遍历所有窗口句柄 # if window_handle != original_window: # driver.switch_to.window(window_handle) # 切换到新窗口 # break # print(f\"✅ 已切换到新窗口,新窗口标题:{driver.title}\") # # 在新窗口进行操作 # driver.close() # 关闭新窗口 # driver.switch_to.window(original_window) # 切换回原窗口 # print(\"✅ 已切换回原窗口。\") # time.sleep(1) print(\"✨ 模拟弹窗和新窗口处理完成。\") print(f\"当前页面标题:{driver.title}\") except Exception as e: print(f\"❌ 处理弹窗/窗口失败:{e}\") finally: if driver: driver.quit()if __name__ == \"__main__\": # 请创建一个包含JS弹窗按钮和新窗口链接的HTML文件进行测试 print(\"请创建测试HTML文件并修改URL进行测试。\") # Example: handle_popups_windows(\"file:///path/to/popup_window_test.html\")步骤:
准备HTML文件: 创建一个包含JS弹窗和/或新窗口链接的HTML文件。
修改代码: 修改 url 为你的本地HTML文件路径。
运行: 运行 python handle_popups_windows.py。
3.2 执行JavaScript:与网页“深度对话”
场景: 有些网页操作无法通过Selenium直接点击(如隐藏元素),或者需要执行一些复杂的页面脚本。
方案: Selenium的execute_script()方法允许你直接在浏览器中执行JavaScript代码,实现与网页的**“深度对话”,这在动态网站爬取**中非常有用。
代码:
from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timedef execute_js_on_webpage(url): \"\"\" 在网页上执行JavaScript代码。 这是Python复杂交互和动态网站爬取的强大工具。 :param url: 目标网页URL \"\"\" driver = None try: driver = webdriver.Chrome() driver.get(url) print(f\"✅ 已打开网址:{url}\") time.sleep(2) # 示例1:隐藏元素 # driver.execute_script(\"document.getElementById(\'some_element_id\').style.display=\'none\';\") # print(\"✅ 页面元素已隐藏。\") # time.sleep(1) # 示例2:滚动页面 (最常用场景) # 滚动到页面底部 driver.execute_script(\"window.scrollTo(0, document.body.scrollHeight);\") print(\"✅ 页面已滚动到底部。\") time.sleep(2) # 示例3:获取页面动态生成的内容 (数据采集进阶) # 假设页面上有一个动态生成的div,内容是\"Hello Dynamic World\" # dynamic_content = driver.execute_script(\"return document.getElementById(\'dynamic_div\').innerText;\") # print(f\"✅ 获取到动态内容:{dynamic_content}\") print(\"✨ 模拟JavaScript执行完成。\") except Exception as e: print(f\"❌ 执行JavaScript失败:{e}\") finally: if driver: driver.quit()if __name__ == \"__main__\": # 请创建一个包含动态内容和可滚动内容的HTML文件进行测试 # 例如:一个很长的网页,或者一个点击按钮后才显示内容的页面 print(\"请创建测试HTML文件并修改URL进行测试。\") # Example: execute_js_on_webpage(\"file:///path/to/dynamic_scroll_test.html\")步骤:
准备HTML文件: 创建一个长HTML文件(内容足够长以便滚动)或一个有动态内容的HTML文件。
修改代码: 修改 url。
运行: 运行 python execute_js.py。
4.验证码与多因素认证的思路和策略
验证码和多因素认证是自动化登录和数据采集的“拦路虎”。虽然没有一劳永逸的万能解法,但我们可以探讨一些思路和策略来应对。
作用: 验证码旨在区分人和机器,MFA旨在增加安全层级。绕过它们通常需要技术、服务或用户配合。
4.1验证码处理:从手动到半自动(文字/滑块/点选)
场景: 登录时出现图形验证码(扭曲文字)、滑块验证码、点选验证码,阻止自动化。
方案与策略:
人工识别+手动输入: 最简单,效率低,适合小规模任务。Python暂停,等待用户输入。
OCR(光学字符识别): 对图片验证码进行文字识别。
库推荐: Pytesseract(需安装Tesseract OCR引擎),识别简单文字。
限制: 识别率不高,对复杂、扭曲、带干扰线的验证码效果差。
打码平台: 将验证码图片发送到第三方打码平台 ,由人工或AI识别后返回结果。
优点: 识别率高,可处理复杂验证码。
缺点: 成本、速度、隐私问题。
AI模型识别: 自行训练AI模型识别特定类型验证码。
优点: 长期成本低,高度定制。
缺点: 技术门槛高,需要大量数据和AI开发能力。
滑块/点选验证码:
思路: 模拟拖拽动作(ActionChains),图像识别(OpenCV)定位滑块和缺口。
挑战: 滑块轨迹、反爬机制复杂,非常容易被检测。
无头模式 (Headless Mode): 有些验证码在无头模式下可能不显示。
ocr 识别文字代码:
# 假设你已经安装了 pytesseract 和 tesseract-ocr 引擎# pip install pytesseract# 安装 Tesseract-OCR 引擎:https://tesseract-ocr.github.io/tessdoc/Installation.htmlfrom PIL import Image import pytesseract import osdef ocr_captcha_image(image_path): \"\"\" 使用OCR技术识别图片验证码。 这是Python验证码处理的一种策略。 :param image_path: 验证码图片路径 :return: 识别出的文本 \"\"\" if not os.path.exists(image_path): return print(f\"❌ 验证码图片不存在:{image_path}\") try: img = Image.open(image_path) # 对图片进行预处理 (灰度化、二值化、去噪等) 可以提高识别率 # img = img.convert(\'L\').point(lambda x: 0 if x < 128 else 255, \'1\') # **核心操作: pytesseract 识别** text = pytesseract.image_to_string(img, config=\'--psm 7\') # --psm 7 假设图片中只有一行文本 print(f\"✅ 验证码图片 \'{os.path.basename(image_path)}\' 识别结果:\'{text.strip()}\'\") return text.strip() except Exception as e: print(f\"❌ 验证码识别失败:{e}\") return Noneif __name__ == \"__main__\": # 准备一张简单的文字验证码图片 (如 4位数字或简单字母) 到桌面 captcha_image_path = os.path.expanduser(\"~/Desktop/captcha_sample.png\") # 假设你有一张图片 if not os.path.exists(captcha_image_path): # 简单模拟一个图片 (实际需真实验证码) Image.new(\'RGB\', (100, 40), color = \'white\').save(captcha_image_path) print(f\"请在 \'{os.path.dirname(captcha_image_path)}\' 放置一个名为 \'captcha_sample.png\' 的文字验证码图片进行测试。\") else: ocr_captcha_image(captcha_image_path)操作步骤:
安装Tesseract-OCR引擎: 这是Pytesseract的底层引擎,需要单独安装。
安装pytesseract: pip install pytesseract pillow。
准备验证码图片: 在桌面准备一张简单的文字验证码图片。
修改代码路径: 修改 captcha_image_path。
运行: 运行 python ocr_captcha.py。
4.2多因素认证(MFA)策略:更高安全层级的自动化挑战
痛点场景: 登录后,还需要手机短信验证码、邮箱验证码、APP扫码确认等,自动化流程被中断。
方案与策略:
人工干预: 最常见且可靠。Python暂停,等待用户手动输入验证码。
邮件/短信服务集成: (高级且有风险)如果你的账户可以接收
到API调用的邮件/短信,理论上可以通过Python读取邮件/短信内容来获取验证码。
风险: 涉及邮箱/手机号的API权限,安全性、隐私和平台服务条款问题。
二维码扫码: 模拟点击“扫码登录”后,Python截取二维码,通过图像识别(OpenCV)解析二维码内容,或提示用户手动扫描。
记住设备: 许多MFA系统有“记住此设备”选项。首次手动登录并勾选后,后续自动化登录可能不需要MFA。
API登录: 终极解决方案。 放弃模拟浏览器,直接通过网站提供的API接口进行登录,这通常不需要MFA或有专门的API认证方式。
限制: 需要网站提供开放API,且可能对API调用有频率限制和安全要求。
[表格:验证码与MFA处理策略对比]
5.成果:你的“终极爬虫工具”!
恭喜你!通过本篇文章,你已经掌握了Python自动化爬虫的各项核心魔法,亲手打造了一个能够模拟真人点击登录,搞定动态网站与复杂交互的**“终极爬虫工具”**!

我们深入学习了Selenium库,它堪称Python网页自动化的“瑞士军刀”,实现了:
Selenium模拟登录: 像真实用户一样,自动化输入账号密码,突破网站登录限制。
搞定动态网站: 处理弹窗、多窗口切换,执行JavaScript,让Python能与复杂网页深度交互。
验证码与MFA策略: 掌握了OCR识别、打码平台、API登录等多种应对Python验证码处理和多因素认证自动化的思路。
6.尾声:Selenium自动化,开启无限可能!
通过本篇文章,你已经掌握了Python自动化爬虫的强大能力,为你的办公自动化之旅又增添了一个重量级技能!你学会了如何利用Selenium,高效地进行网页登录和复杂交互。
除了今天学到的功能,你还希望Python的Selenium能帮你实现哪些更复杂的网页自动化任务?比如:自动化表单提交后的数据校验?定时自动打卡?自动化抢购?在评论区分享你的需求和想法,你的建议可能会成为我们未来文章的灵感来源!
敬请期待! 网页自动化系列即将迎来更精彩的篇章!我们将继续探索Selenium的高级应用,以及如何结合其他技术,打造更智能、更稳定的Web自动化解决方案!同时,本系列所有代码都将持续更新并汇总在我的GitHub仓库中,敬请关注!未来,这个**“Python职场效率专家实战包”还将包含更多开箱即用、功能强大**的自动化工具,助你一路开挂!

