[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp
目录
一、前言
二、项目的相关背景
三、搜索引擎的宏观原理
四、搜索引擎技术栈和项目环境
五、正排索引 VS 倒排索引--原理
正排索引
分词
倒排索引
六、编写数据去除标签和数据清洗模块 Parser
1.数据准备
parser
编码
1.枚举文件 EnumFile
2.去标签ParseHtml()
测试
使用SCP命令在两台Linux服务器之间传输文件
适用场景
命令格式
示例
将scp任务放入后台执行
Boost搜索引擎项目的九个步骤~
- 项目的相关背景
- 搜索引擎的相关宏观原理
- 搜索引擎技术栈和项目环境
- 正排索引 vs 倒排索引 - 搜索引擎具体原理
- 编写数据去标签与数据清洗的模块Parser
- 编写建立索引的模块 Index
- 编写搜索引擎模块 Searcher
- 编写http server模块
- 编写前端模块
准备分几篇文章讲解,持续更新中(●\'◡\'●),会在最后一篇文章中放上项目的gitee~本篇文章先从这几个部分进行实现

一、前言
在日常使用浏览器搜索时,服务器返回的是与搜索关键字相关的网站信息,包括网站标题、内容简述和URL。点击标题后会跳转到对应的网页。常见的搜索引擎如百度、谷歌等覆盖全网信息,而我们的项目是一个小范围的站内搜索引擎,用 boost库 实现的 boost站内搜索
二、项目的相关背景
什么是Boost库?
- Boost库是C++的准标准库,提供许多高级功能。
- 许多Boost组件已被纳入C++11标准。如:哈希、智能指针
- 更多详情可访问Boost官网。
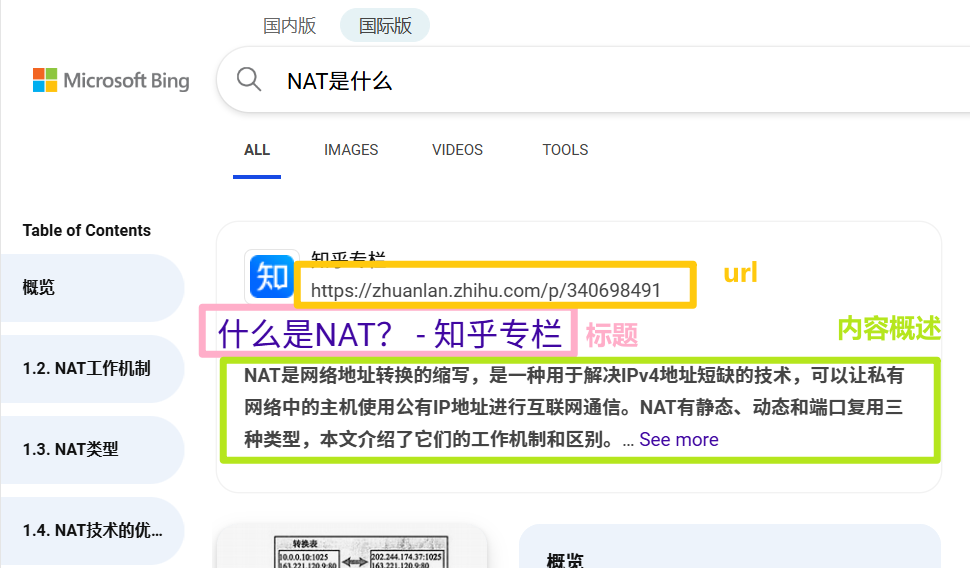
什么是搜索引擎?
- 搜索引擎如百度、360、搜狗展示的信息通常 包括网页标题、摘要和URL。
- 我们设计的搜索引擎将 不包含图片、视频或广告等扩展内容。
- 搜出来的结果展示都是以,标题+内容摘要+url 组成
为什么要做Boost搜索引擎?
- Boost库缺乏站内搜索功能。
- 实现一个类似cplusplus官网的站内搜索功能是有意义的

- 实现目标:搜索一个关键字,就能够跳转到指定的网页,并显示出来
- 站内搜索的数据量相对较小且更垂直化。
三、搜索引擎的宏观原理
通过以下步骤实现:
- 数据准备:获取并存储Boost文档数据。我们可以直接将 boost库 对应版本的数据直接解压到我们对应文件里。
- 去标签 & 数据清洗:提取所需信息(标题、摘要、URL)。我们从boost库拿的数据其实就是对应文档html网页,但是我们需要的只是每个网页的标题+网页内容摘要+跳转的网址,所以才有了去标签和数据清洗(只拿我们想要的)
- 构建索引:对清洗后的数据建立索引(方便客户端快速查找);
- 用户请求处理:解析搜索关键词,检索索引,返回结果。
流程模拟:
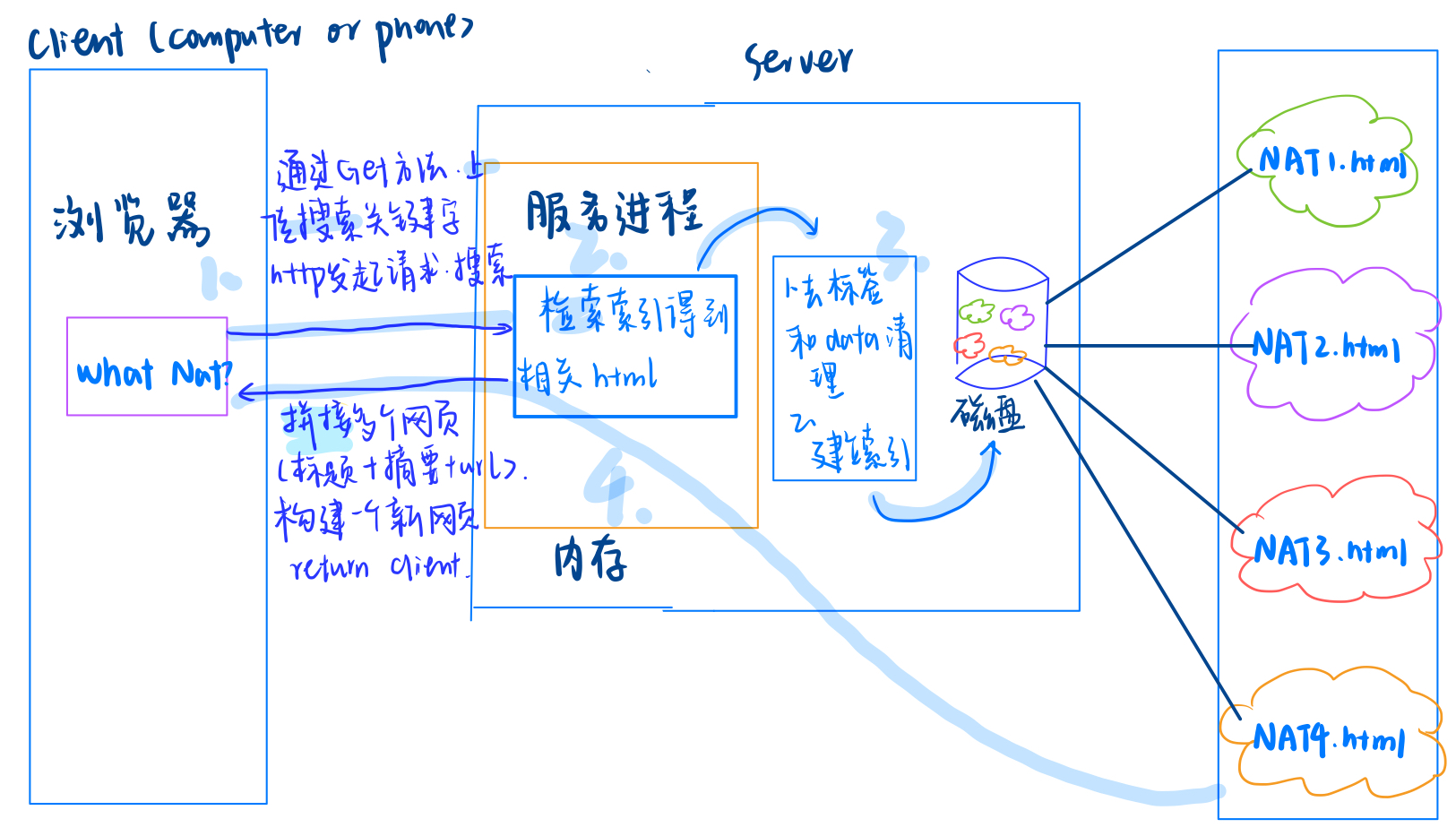
- 当服务器所以的工作都完成之后,客户端就发起http请求,
- 通过GET方法,上传搜索关键,
- 服务器收到了会进行解析,通过客户端发来的关键字 去检索已经构建好的索引,找到了相关的html后
- 将逐个的将每个网页的标题、摘要和网址拼接起来,构建出一个新的网页,响应给客户端
- 至此,客户就看到了相应的内容,点击网址就可以跳转到boost库相应的文档位置。
网页概述:
- tltle
- 内容摘要
- url
盈利方式:
- 推送广告,竞价排名收费
四、搜索引擎技术栈和项目环境
技术栈:
- C/C++/C++11, STL,
- 相关库
- Web 前端( HTML5, CSS, JavaScript), jQuery, Ajax。
相关库
- Boost库(文件遍历)
- Jsoncpp(json 处理)
- cppjieba(分词)
- cpp-httplib(网络库-http 服务)
项目环境
- Ubuntu 云服务器,
- vim/gcc/g++/Makefile
- VS2022 或 VSCode
五、正排索引 VS 倒排索引--原理
- 正排索引:文档ID-->文档关键词/ 内容。
- 倒排索引:文档的关键词-->文档ID。
分词
目标文档进行分词:目的:方便建立倒排索引和查找
停止词:了,吗,的,the,a,一般情况我们在分词的时候可以不考虑
正排索引
文档 1
我以后要养一只小猫
文档 2
我以后还要养一只小狗
分词
1:我 /以后 /要养/ 一只/ 小猫
2:我 /以后 /还要养 /一只 /小狗
倒排索引
我
文档 1,文档 2
以后
文档 1,文档 2
小猫
文档 1
小狗
文档 2
⭕模拟一次查找的过程:
用户输入:关键词->倒排索引中查找->提取出文档ID(1,2)->通过倒排数据找到正排ID->找到文档的内容->title+conent(desc)+url 文档结果进行摘要->通过 json字符串响应回去-->然后在用户的浏览器显示出一个个网页信息
代码实现逻辑:
下载Boost库 -> 解析HTML -> 数据清洗 -> 构建索引 -> 提供搜索接口 -> 显示结果。
- 数据准备:从Boost官网下载 boost 库,并解压至Linux目录。
- 选择所需文件:写一个解析程序从一个个html文件的源码中提取标题、内容和url,将他们保存到硬盘的一个data.txt文件中。
- 读取:读取data.txt文件,建立正排和倒排索引,提供索引的接口来获取正排和倒排数据
- 数据拷贝:写一个html页面,提供给用户一个搜索功能。然后模拟上述查找过程
六、编写数据去除标签和数据清洗模块 Parser
1.数据准备
- boost 官⽹: https://www.boost.org/
下载:
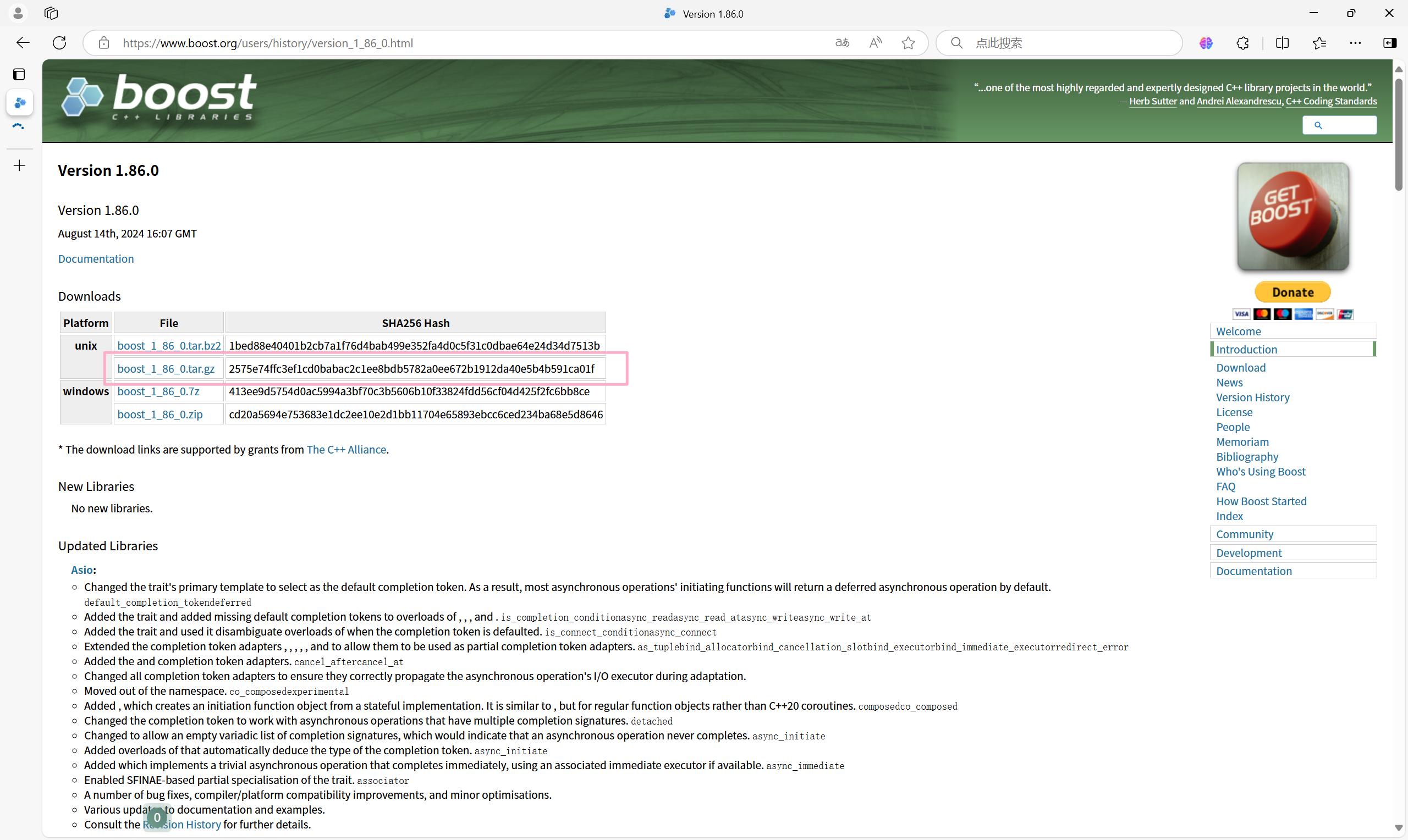
之后 rz -E,再解压
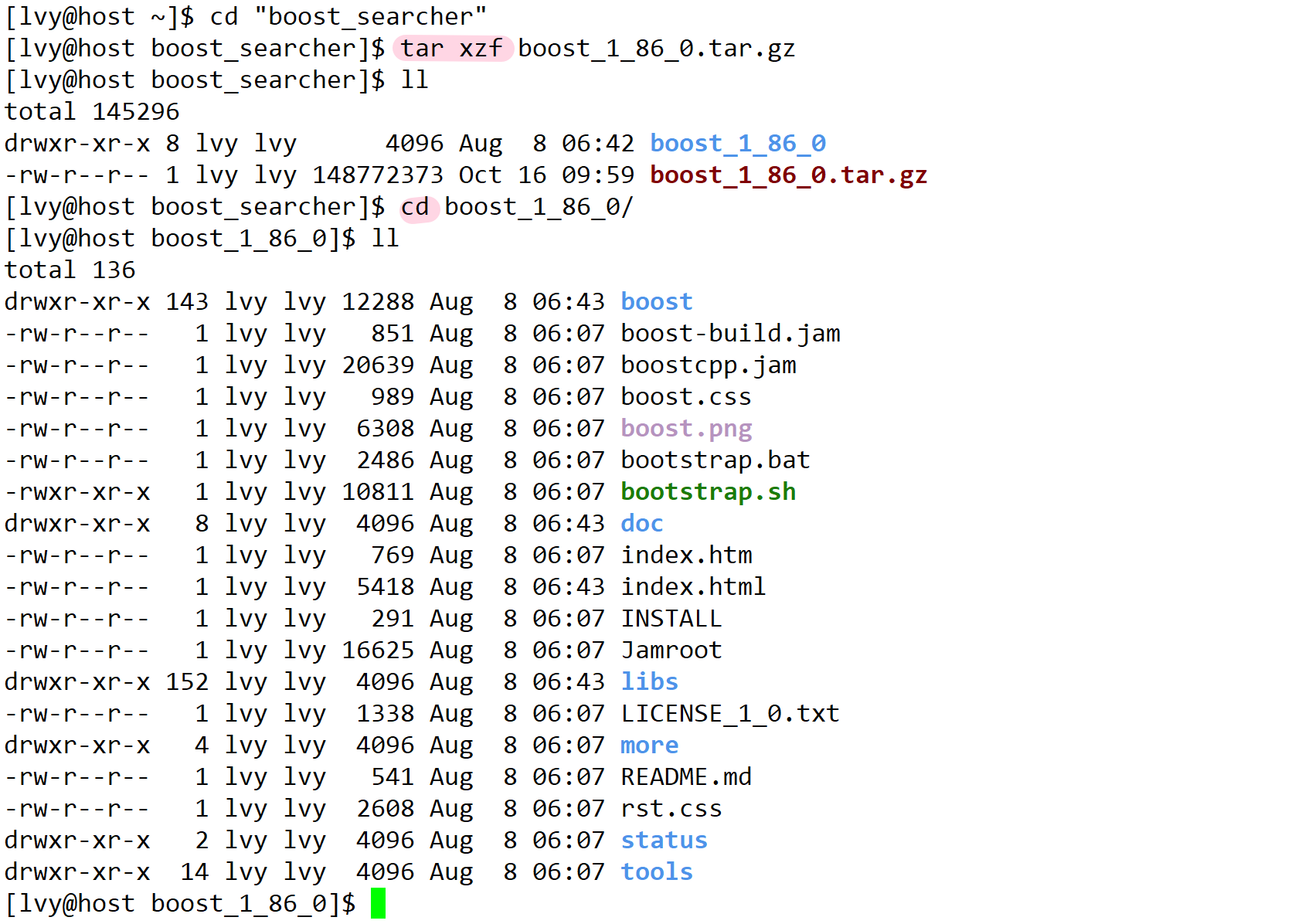
⽬前只需要boost_1_86_0/doc/html⽬录下的html⽂件,⽤它来进⾏建⽴索引
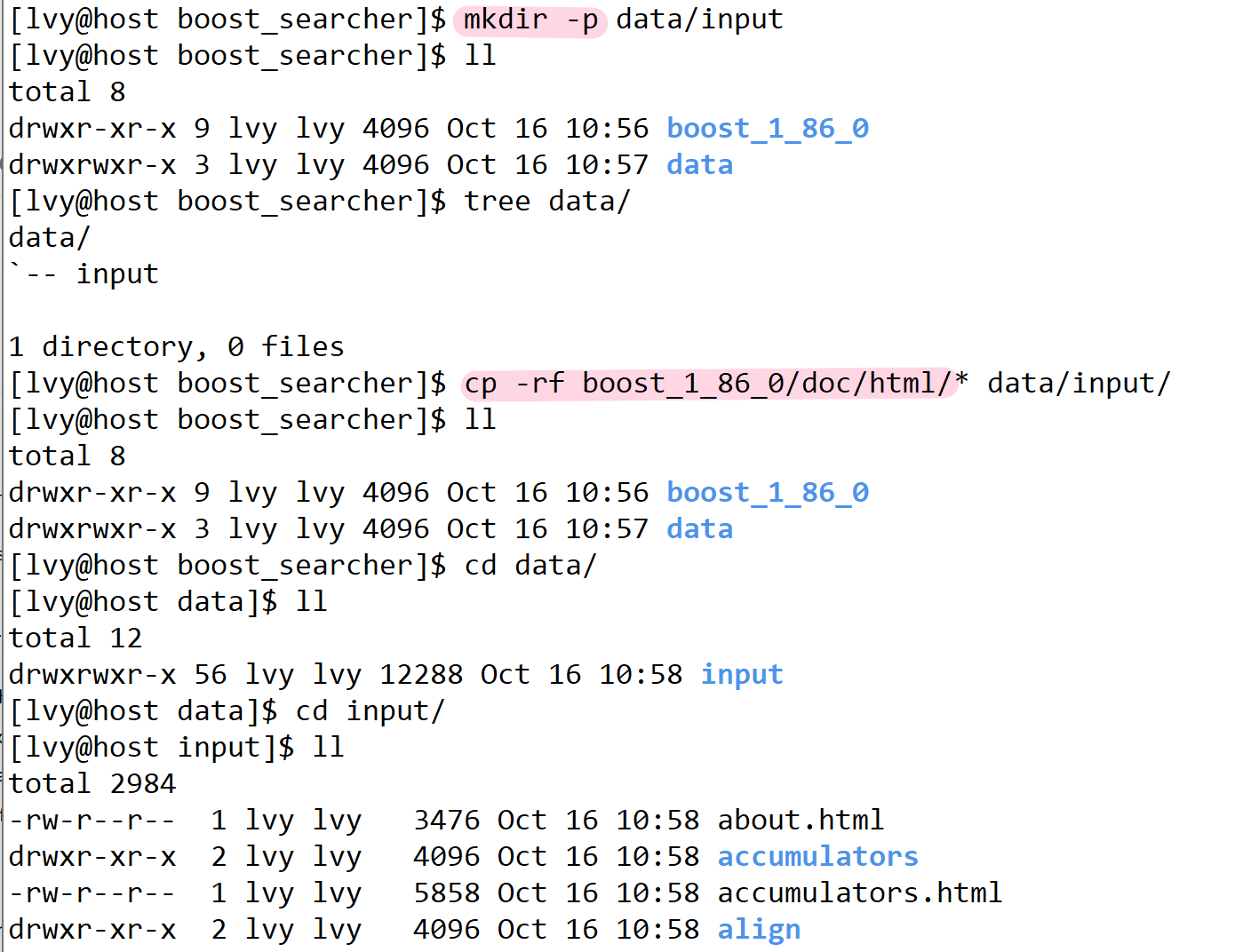
将我们所需要的数据源 拷贝到 data目录下的intput目录下--清洗数据完成
parser
这里我是在 vscode 下进行代码编写的,但是需要连接一下云服务器,与 Linux进行同步。 你也可以选择 vim。
基本框架:
- 将 data/input/ 所有后缀为 html 的文件筛选出来 ---- 清洗数据
- 然后对筛选好的html文件进行解析(去标签),拆分出标题、内容、网址 ---- 去标签
- 最后将去标签后的所有html文件的标题、内容、网址处理后,写入到 data/raw_html/raw.txt 下
什么是去标签呢?
举例 nano process.html 查看一下
对数据清洗之后,拿到的全都是 html 文件,此时还需要对 html 文件进行去标签处理,我们这里随便看一个html文件
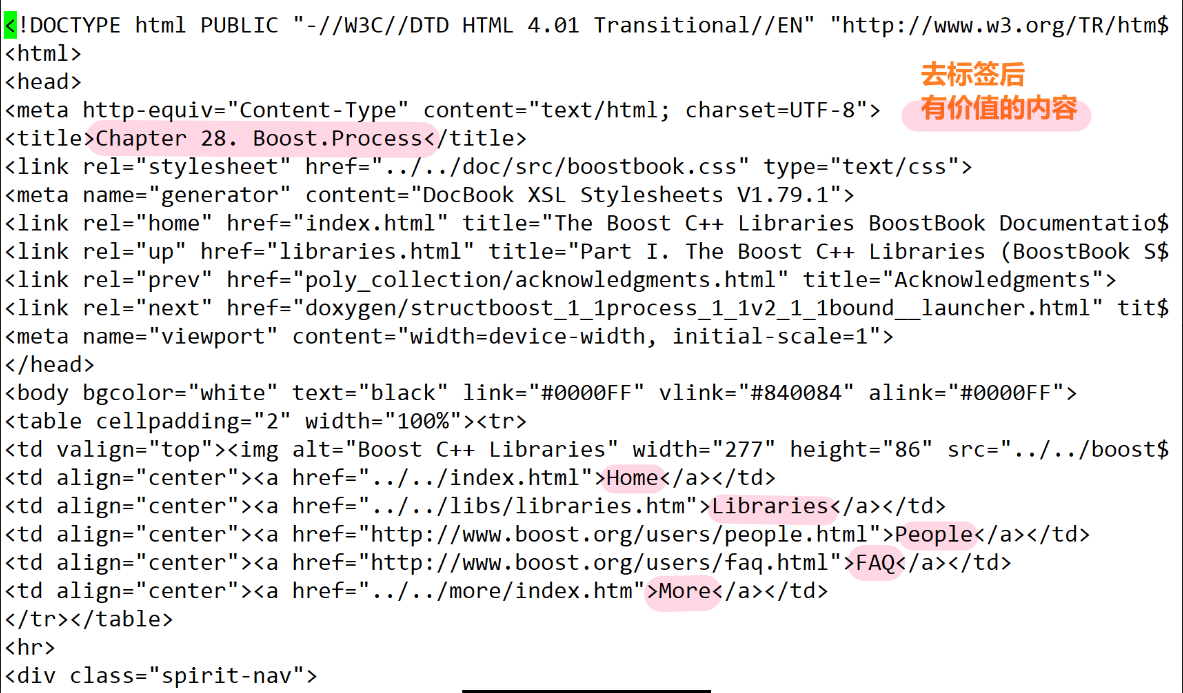
- 退出 nano 的方法: Ctrl + X 。做了修改并且想要保存,输入 Y(是),不保存,直接按 N(否)然后回车
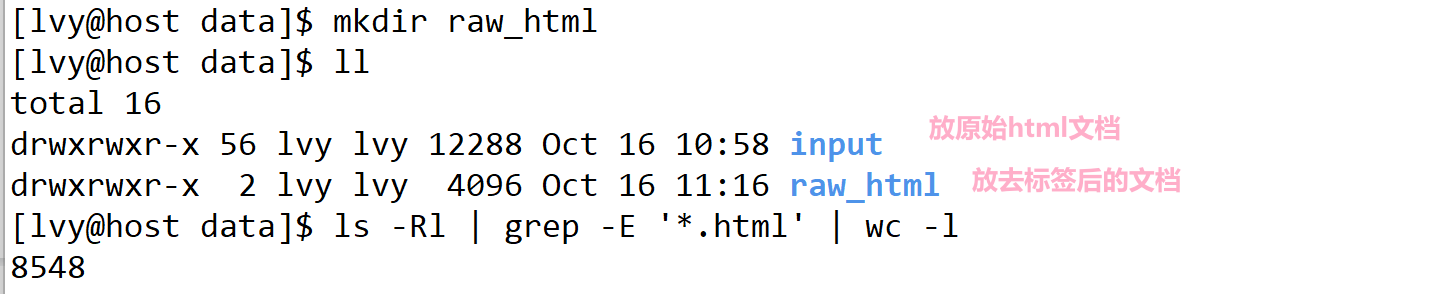
- 我们在 data目录 下的 raw_html目录下 创建有一个 raw.txt文件,用来存储干净的数据文档
- <> : html的标签,这个标签对我们进行搜索是没有价值的,需要去掉这些标签,一般标签都是成对出现的!但是也有单独出现的,我们也是不需要的。
采用下面的方案:
- 写入文件中,一定要考虑下一次在读取的时候,也要方便操作!
- 类似:title\\3content\\3url \\n title\\3content\\3url \\n title\\3content\\3url \\n ...
- 方便我们getline(ifsream, line),直接获取文档的全部内容:title\\3content\\3url
- 文件内按照 \\3 作为分割符,每个文件再按照 \\n 进行区分
note: vim 下的中文注释:ctrl+space
编码
在 Boost_Searcher 目录下创建 parser.cpp 文件开始编写框架
三步走:
- 第⼀步EnumFile(src_path, &files_list): 递归式的把每个html⽂件名带路径,保存到文件 files_list中,⽅便后期进⾏⼀个⼀个的 ⽂件进⾏读取(预处理
- 第⼆步ParseHtml(files_list, &results): 按照files_list读取每个⽂件,并进⾏解析
- 第三步SaveHtml(results, output): 把解析完毕的各个⽂件内容,写⼊到output,按照\\3作为每个⽂档的分割符
#include #include #include // 首先我们肯定会读取文件,所以先将文件的路径名 罗列出来// 将 数据源的路径 和 清理后干净文档的路径 定义好 const std::string src_path = \"data/input\"; // 数据源的路径const std::string output = \"data/raw_html/raw.txt\"; // 清理后干净文档的路径 //DocInfo --- 文件信息结构体typedef struct DocInfo{ std::string title; //文档的标题 std::string content; //文档的内容 std::string url; //该文档在官网当中的url}DocInfo_t; // 命名规则// const & ---> 输入// * ---> 输出// & ---> 输入输出 //把每个html文件名带路径,保存到files_list中bool EnumFile(const std::string &src_path, std::vector *files_list); //按照files_list读取每个文件的内容,并进行解析bool ParseHtml(const std::vector &files_list, std::vector *results); //把解析完毕的各个文件的内容写入到outputbool SaveHtml(const std::vector &results, const std::string &output); int main(){ std::vector files_list; // 将所有的 html文件名保存在 files_list 中 // 第一步:递归式的把每个html文件名带路径,保存到files_list中,方便后期进行一个一个的文件读取 // 从 src_path 这个路径中提取 html文件,将提取出来的文件存放在 string 类型的 files_list 中 if(!EnumFile(src_path, &files_list)) //EnumFile--枚举文件 { std::cerr << \"enum file name error! \" << std::endl; return 1; } return 0; // 第二步:从 files_list 文件中读取每个.html的内容,并进行解析 std::vector results; // 从 file_list 中进行解析,将解析出来的内容存放在 DocInfo 类型的 results 中 if(!ParseHtml(files_list, &results))//ParseHtml--解析html { std::cerr << \"parse html error! \" << std::endl; return 2; } // 第三部:把解析完毕的各个文件的内容写入到output,按照 \\3 作为每个文档的分隔符 // 将 results 解析好的内容,直接放入 output 路径下 if(!SaveHtml(results, output))//SaveHtml--保存html { std::cerr << \"save html error! \" << std::endl; return 3; } return 0;}

主要实现:枚举文件、解析html文件、保存html文件三个工作。
这三个工作完成是需要我们使用boost库当中的方法的,我们需要安装一下boost的开发库:
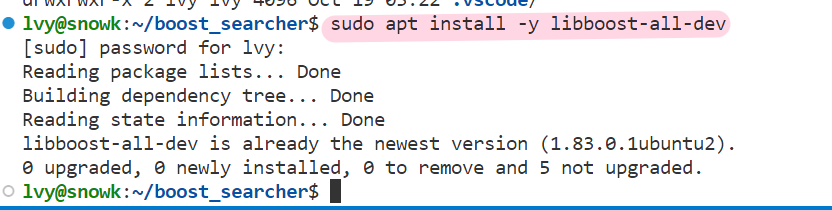
通过如上命令,我是已经安装过啦~
下图就是我们接下来编写代码需要用到的 boost库 当中的 filesystem方法。
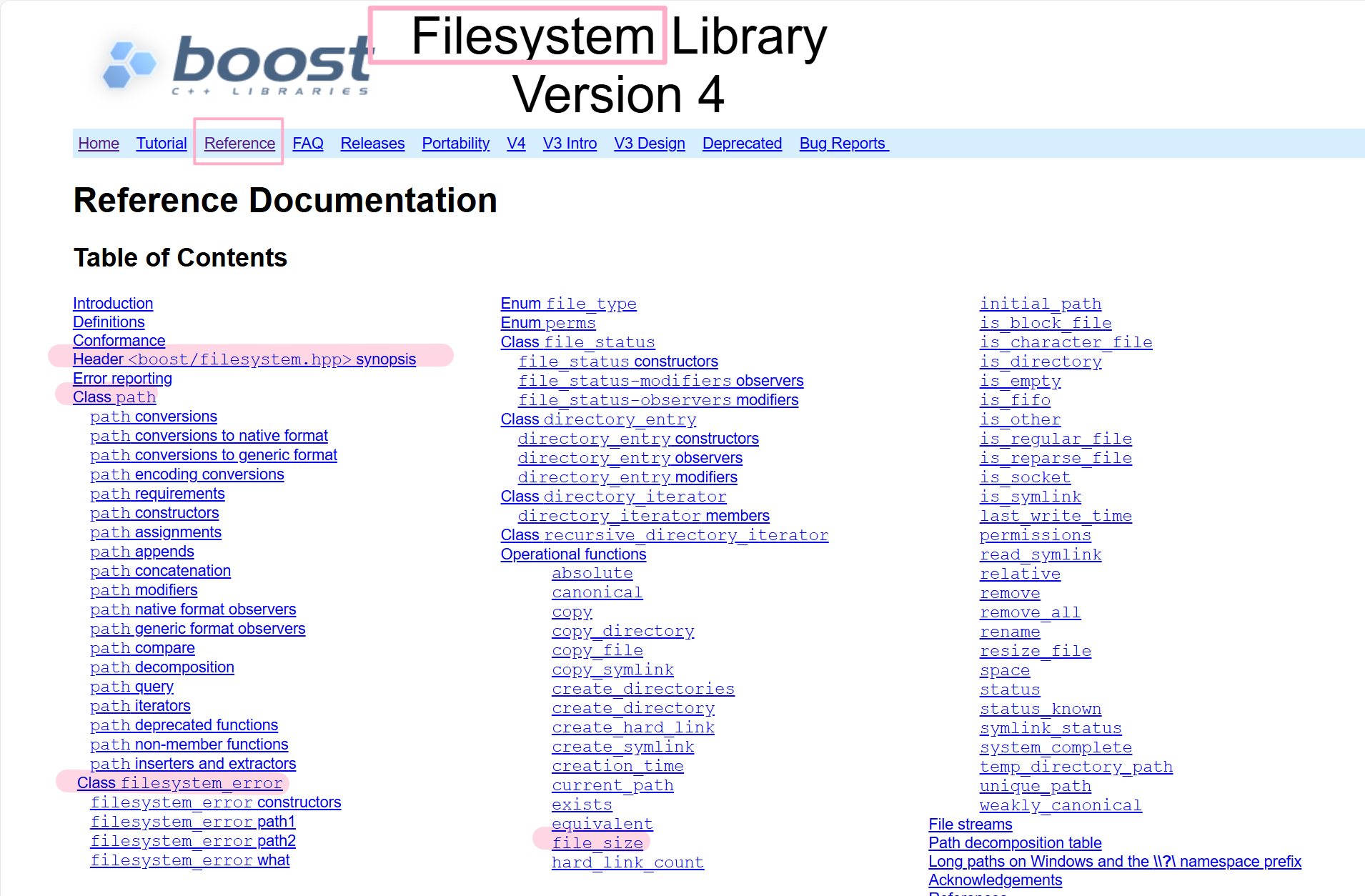
1.枚举文件 EnumFile
- 使用 boost 枚举文件名
//在原有的基础上添加这个头文件#include //把每个html文件名带路径,保存到files_list中bool EnumFile(const std::string &src_path, std::vector *files_list){ // 简化作用域的书写 namespace fs = boost::filesystem; fs::path root_path(src_path); // 定义一个path对象,枚举文件就从这个路径下开始 // 判断路径是否存在 if(!fs::exists(root_path)) { std::cerr << src_path << \" not exists\" <path().extension() != \".html\") { continue; } //std::cout << \"debug: \" <path().string() <push_back(iter->path().string()); // 将所有带路径的html保存在files_list中,方便后续进行文本分析 } return true;}- makefile 中连接 boost 库
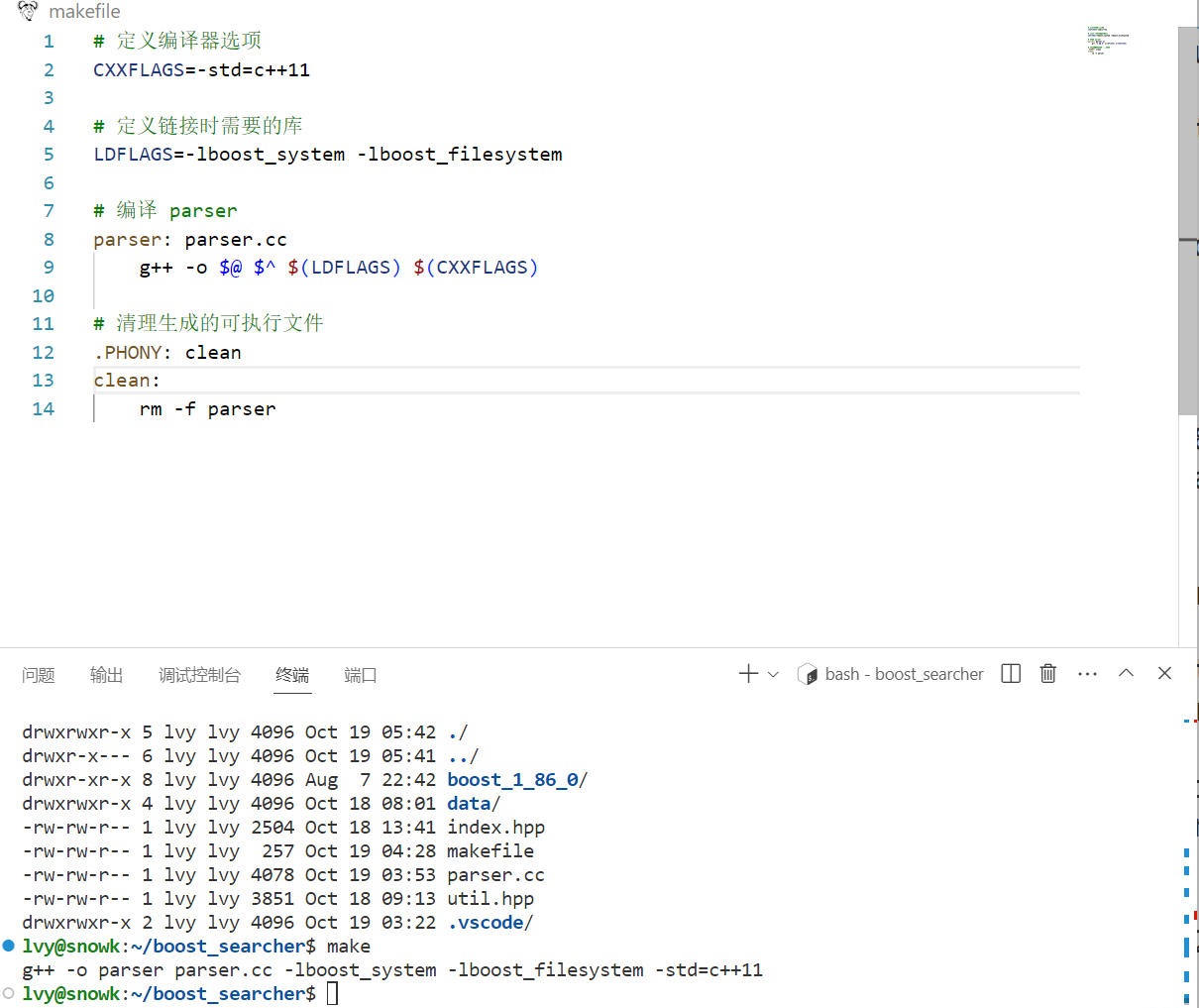
查看对外部库的连接:

运行:
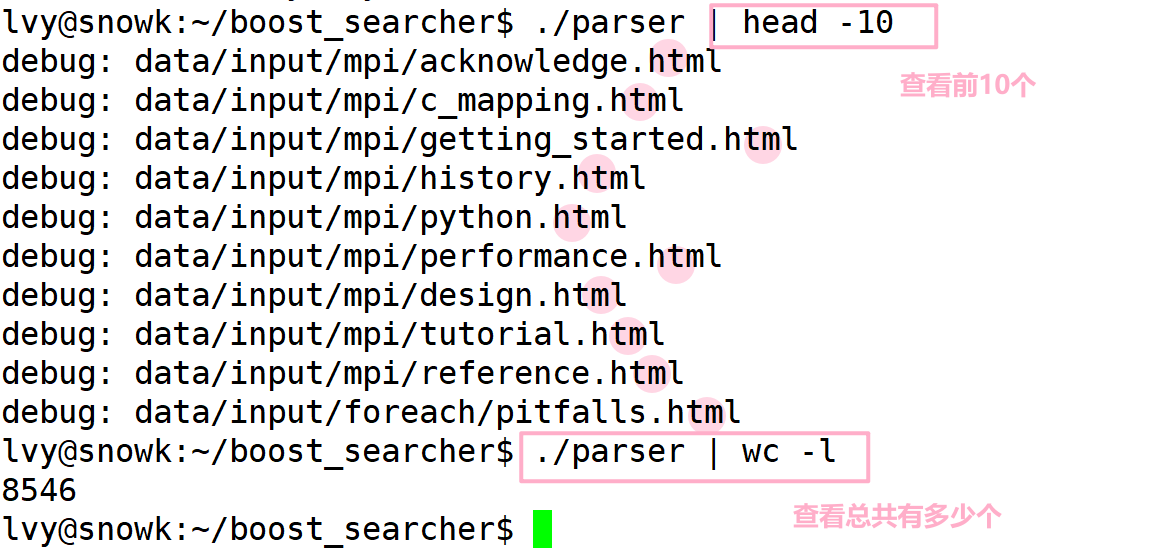
- 成功提取出了 html 文件~
- 测试成功后,将测试代码注释掉哦!
- 运行测试成功,继续编写下一个模块
2.去标签
ParseHtml()
解析html文件
- 读取刚刚枚举好的文件
- 解析html文件中的title
- 解析html文件中的content
- 解析html文件中的路径,构建url

- 函数建构
bool ParseHtml(const std::vector &files_list, std::vector *results){ for(const std::string &file : files_list) { // 1.读取文件,Read() std::string result; if(!ns_util::FileUtil::ReadFile(file, &result)) { continue; } // 2.解析指定的文件,提取title DocInfo_t doc; if(!ParseTitle(result, &doc.title)) { continue; } // 3.解析指定的文件,提取content if(!ParseContent(result, &doc.content)) { continue; } // 4.解析指定的文件路径,构建url if(!ParseUrl(file, &doc.url)) { continue; } // 到这里,一定是完成了解析任务,当前文档的相关结果都保存在了doc里面 results->push_back(std::move(doc)); // 本质会发生拷贝,效率肯能会比较低,这里我们使用move后的左值变成了右值,去调用push_back的右值引用版本 } return true; }主要完成 4件事:
①根据路径名依次读取文件内容,②提取title,③提取content,④构建url。
2.1读取文件ReadFile()
- 遍历 files_list 中存储的文件名,从中读取文件内容到 result 中,由函数
ReadFile()完成该功能。该函数定义于头文件 util.hpp的类 FileUtil中。
#pragma once#include #include #include #include namespace ns_util{ class FileUtil { public: static bool ReadFile(const std::string &file_path, std::string *out) { std::ifstream in(file_path, std::ios::in); if(!in.is_open()) { std::cerr << \"open file \" << file_path << \" error\" << std::endl; return false; } std::string line; while(std::getline(in, line)) //如何理解getline读取到文件结束呢??getline的返回值是一个&,while(bool), 本质是因为重载了强制类型转化 { *out += line; } in.close(); return true; } };}⭕ 重点理解:C++的流读取 && getline 的使用
2.2 提取title ——
ParseTitle()
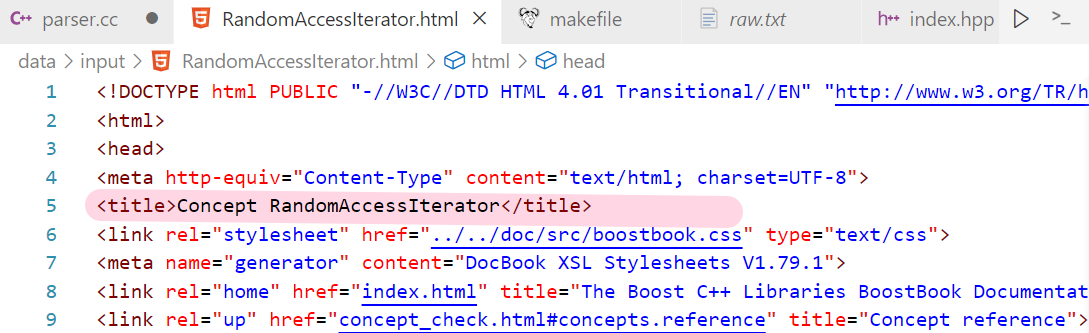
- 可以发现
标题 构成的 - find(
</span>)就能找到这个标签的左尖括号的位置</li> <li id="uf6b44ae8">然后加上<title>的长度,此时就指向了标题的起始位置</li> <li id="u0598f71b">同理,再去找到 的左尖括号,最后截取子串;
这里需要依赖函数 —— bool ParseTitle(const std::string& file,&doc.title),
//解析titlestatic bool ParseTitle(const std::string& file,std::string* title){ // 查找 位置 std::size_t begin = file.find(\"<title>\"); if(begin == std::string::npos) { return false; } // 查找 位置 std::size_t end = file.find(\"\"); if(end == std::string::npos) { return false; } // 计算中间的距离,截取中间的内容 begin += std::string(\"\").size(); if(begin > end) { return false; } *title = file.substr(begin, end - begin); return true;}</code></pre>
<blockquote>
<p id="u02407454"><span><strong>2.3 提取content--</strong><code><strong>ParseContent()</strong></code></span></p>
</blockquote>
<p id="u212c0185">
<p class="img-center"><img alt="" height="513" id="u5c9c335f" src="https://img-blog.csdnimg.cn/img_convert/8e31428a83e14da73e47815a2fceffeb.png" alt="[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp" width="1200" /></p>
<p id="udccac9e4">用一个<span><strong>简易的状态机</strong></span>来完成,状态机包括两种状态:<strong>LABLE(标签)和CONTENT(内容);</strong></p>
<ul>
<li id="u34d469e0">起始肯定是标签,我们逐个字符进行遍历判断</li>
<li id="uae8d25da">如果遇到<span><strong>“>”</strong>,</span>表明下一个即将是内容了,我们将状态机置为<span><strong>CONTENT</strong></span>,接着将内容保存起来</li>
<li id="ua3e46e2f">如果此时遇到了<strong>“<”</strong>,表明到了标签了,我们再将状态机置为<span><strong>LABLE</strong>;</span></li>
<li id="u6886a42f">不断的循环,知道遍历结束;</li>
</ul>
<pre id="zEVS3"><code>//去标签 -- 数据清洗static bool ParseContent(const std::string& file,std::string* content){ //去标签,基于一个简易的状态机 enum status // 枚举两种状态 { LABLE, // 标签 CONTENT // 内容 }; enum status s = LABLE; // 刚开始肯定会碰到 \"\') s = CONTENT; break; case CONTENT: if(c == \'push_back(c); } break; default: break; } } return true;}</code></pre>
<blockquote>
<p id="ucdc82047"><span><strong>2.4 解析 html 的 url</strong></span></p>
</blockquote>
<ul>
<li id="u84dca2e2"><span><strong>boost库</strong> 在网页上的 <strong>url</strong>,和我们 <strong>下载的文档的路径</strong> 是 <strong>有对应关系</strong>的</span></li>
</ul>
<p id="ufb919363">探寻官方文档路径和我们路径的关系,以 <strong><code>Accumulators</code>.html </strong>为例</p>
<p id="u464da104">
<p class="img-center"><img alt="" height="80" id="u66fb3bc2" src="https://img-blog.csdnimg.cn/img_convert/8bc32d6e9edbba3cee2d583fa94d36a9.png" alt="[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp" width="784" /></p>
<p id="u7986c243">在我们路径下的查找</p>
<p id="u44da0e01">
<p class="img-center"><img alt="" height="39" id="u9baece2b" src="https://img-blog.csdnimg.cn/img_convert/47a8641670dd001734e5f103d5580ffb.png" alt="[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp" width="1200" /></p>
<p id="ubbcc621f">在 input 中</p>
<p id="u42cb92f7">
<p class="img-center"><img alt="" height="151" id="ub9fe6b99" src="https://img-blog.csdnimg.cn/img_convert/6594ad041009320eaed0d4f3e4322e1d.png" alt="[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp" width="1200" /></p>
<p id="uf9767ca9"><strong>我们之前已经定义好了两个路径嘛!</strong><span><strong>源数据路径 </strong><strong>和 </strong><strong>清理后干净文档的路径</strong></span></p>
<p id="uc94d164c">1. 拿 官网的部分网址作为 头部的 url</p>
<ul>
<li id="u427c8e2d">url_head = \"https://www.boost.org/doc/libs/1_86_0/doc/html\"</li>
</ul>
<p id="uad3f82ce">2. 将我们项目的路径 data/input 删除后得到 /accumulators.html;</p>
<ul>
<li id="udb7b2070">url_tail = [data/input(删除)] /accumulators.html -> url_tail = /accumulators.html;</li>
</ul>
<p id="ueb890fb5">3. 将<strong><span> url_head + url_tail == 官网的 url</span></strong></p>
<pre id="AqaVf"><code>//构建官网url :url_head + url_tailstatic bool ParseUrl(const std::string& file_path,std::string* url){ std::string url_head = \"https://www.boost.org/doc/libs/1_85_0/doc/html\"; std::string url_tail = file_path.substr(src_path.size());//将data/input截取掉 *url = url_head + url_tail;//拼接 return true;}</code></pre>
<p id="uc8161710">到这里我们写的 <strong>ParseHtml 解析部分</strong>就已经写完啦,那定是我们要先测试一下它的正确性啦!</p>
<blockquote>
<h4 id="M7mPn">测试</h4>
</blockquote>
<ul>
<li id="udf7399c1">向源代码中加入了<strong> ShowDoc </strong>测试代码,测试完注释掉即可</li>
</ul>
<pre id="hszRo"><code>// for debugvoid ShowDoc(const DocInfo_t& doc){ std::cout<<\"title: \"<<doc.title<<std::endl; std::cout<<\"content: \"<<doc.content<<std::endl; std::cout<<\"url: \"<<doc.url<<std::endl;} //按照files_list读取每个文件的内容,并进行解析bool ParseHtml(const std::vector &files_list, std::vector *results){ // 首先在解析文件之前,肯定需要 遍历 读取文件 for(const std::string &file : files_list) { // 1.读取文件,Read() --- 将文件的全部内容全部读出,放到 result 中 std::string result; if(!ns_util::FileUtil::ReadFile(file, &result)) { continue; } // 2.解析指定的文件,提取title DocInfo_t doc; if(!ParseTitle(result, &doc.title)) { continue; } // 3.解析指定的文件,提取content if(!ParseContent(result, &doc.content)) { continue; } // 4.解析指定的文件路径,构建url if(!ParseUrl(file, &doc.url)) { continue; } // 到这里,一定是完成了解析任务,当前文档的相关结果都保存在了doc里面 results->push_back(std::move(doc)); // 本质会发生拷贝,效率肯能会比较低,这里我们使用move后的左值变成了右值,去调用push_back的右值引用版本 // for debug -- 在测试的时候,将上面的代码改写为 results->push_back(doc); ShowDoc(doc); break; // 只截取一个文件打印 } return true;}</code></pre>
<p id="uffa71de0">接下来就可以 make , 然后运行:</p>
<p id="u62abe273">
<p class="img-center"><img alt="" height="390" id="u3516549f" src="https://img-blog.csdnimg.cn/img_convert/ecddd7fe929abebde8fd6c39bfc8bd90.png" alt="[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp" width="1160" /></p>
<ul>
<li id="u978562ed">为了进一步验证正确性,我们可以将网页复制下来,在浏览器中打开,看是否成功</li>
</ul>
<p id="uf34b5217">
<p class="img-center"><img alt="" height="574" id="ua84fdd31" src="https://img-blog.csdnimg.cn/img_convert/3347f108755c15b2483226321da2c120.png" alt="[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp" width="1200" /></p>
<p id="uaaa8fc50">成功ヾ(≧▽≦*)o</p>
<hr id="EQJhL" />
<p id="u1a8c9654">对于项目写有一个重点,就是<strong>做好对错误的处理~</strong></p>
<p id="u147ae4ce">遇见的一个小问题:</p>
<p id="uc7acf600">之前的服务器 free -h 查看后发现,在 vscode 下内存有点不够用,然后换了一台朋友的服务器</p>
<p id="u2d1612c8">
<p class="img-center"><img alt="" height="522" id="ud8b25e7c" src="https://img-blog.csdnimg.cn/img_convert/7bfd3dab029a2a9567a1389ea6770ebc.png" alt="[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp" width="1200" /></p>
<p id="ueee70718">所以要<strong>传一下之前写的文件</strong></p>
<h4 id="Yo1x2">使用SCP命令在两台Linux服务器之间传输文件</h4>
<h5 id="dDDYq">适用场景</h5>
<p id="u9dc20a6e">当你需要将大文件从一台服务器直接传输到另一台服务器,而不想通过本地中转时,可以使用<code>scp</code>(secure copy)命令。</p>
<h5 id="A3w7l">命令格式</h5>
<pre id="LVoGF"><code>scp -r [源文件路径] [目标用户名]@[目标IP]:[目标路径]</code></pre>
<ul>
<li id="u0135f4c6"><code>-r</code>:递归复制整个目录。</li>
<li id="ucbbf28f6"><code>[源文件路径]</code>:要传输的文件或目录的完整路径。</li>
<li id="u7effca3c"><code>[目标用户名]</code>:接收文件服务器上的用户名。</li>
<li id="u69f5d187"><code>[目标IP]</code>:接收文件服务器的IP地址。</li>
<li id="u9fbd1d0d"><code>[目标路径]</code>:在接收方服务器上存放文件的路径。</li>
</ul>
<h5 id="VoTtT">示例</h5>
<p id="uf5b49c2c">假设你要把位于<code>/usr/local/testFile/</code>目录下的所有内容复制到IP为<code>100.10.20.30</code>的目标服务器的<code>/root/</code>目录下,并且目标服务器的登录用户名是<code>root</code>,那么你可以运行以下命令:</p>
<pre id="WhOGj"><code>scp -r /usr/local/testFile/* root@100.10.20.30:/root/</code></pre>
<p id="u13b25fba">执行这个命令后,系统会提示你输入目标服务器的用户密码。</p>
<h5 id="Mnr1U">将scp任务放入后台执行</h5>
<p id="u8d256b4b">如果文件量很大,传输可能需要很长时间。为了不阻塞终端,可以将<code>scp</code>进程放到后台执行:</p>
<ol>
<li id="ud4c3d578"><strong>暂停任务</strong>:按下 <code>Ctrl + Z</code> 暂停当前正在执行的<code>scp</code>任务。</li>
<li id="u8e3a881b"><strong>查看任务</strong>:使用 <code>jobs</code> 查看已暂停的任务及其编号。</li>
<li id="u0b4724b0"><strong>后台继续执行</strong>:使用 <code>bg %a</code> 命令让任务在后台继续执行,其中<code>a</code>是<code>jobs</code>返回的任务编号。</li>
<li id="u8edb8b17"><strong>再次检查状态</strong>:再次运行 <code>jobs</code> 可以看到任务现在处于“Running”状态,表示它正在后台执行。</li>
</ol>
<p id="uad59b310">这样,即使关闭终端窗口,文件传输也会继续进行,直到完成。如果你想要终止后台任务,可以使用<code>kill</code>命令加上相应的进程ID。</p>
<p id="ue57599cb">请注意,在执行任何文件传输操作之前,请确保你有权限访问源和目标服务器,并且目标路径对于指定的用户是可写的。</p>
<p id="u3000523d">
<p class="img-center"><img alt="" height="93" id="u70dfaf17" src="https://img-blog.csdnimg.cn/img_convert/da59d787c121e481a9757b8c69fbce71.png" alt="[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp" width="1200" /></p>
</div>
<div class="clear"></div>
<div class="article_tags">
<div class="tagcloud">
网络标签:<a href="http://www.csdndoc.com/tag/wj" rel="tag">文件</a> <a href="http://www.csdndoc.com/tag/wd" rel="tag">文档</a> <a href="http://www.csdndoc.com/tag/lj" rel="tag">路径</a> </div>
</div>
</div>
</div>
<div>
<ul class="post-navigation row">
<div class="post-previous twofifth">
上一篇 <br> <a href="http://www.csdndoc.com/thread/14584.html" rel="prev">Elasticsearch常用指令(kibana)_kibana查看所有数据</a> </div>
<div class="post-next twofifth">
下一篇 <br> <a href="http://www.csdndoc.com/thread/14587.html" rel="next">Before you can run VMware, several modules must be compiled andloaded into the running kernel.GCCGNU_before you can run vmware,serveral modules must be</a> </div>
</ul>
</div>
<div class="article_container row box article_related">
<div class="related">
<div class="newrelated">
<h2>相关问题</h2>
<ul>
<li><a href="http://www.pcgg.com.cn/lol/32985.html">英雄联盟f9录制的视频在哪</a></li>
<li><a href="http://www.pcgg.com.cn/wzlb/60031.html">2023年10月14日重庆市疫情大数据-今日/今天疫情全网搜索最新实时消息动态情况通知播报</a></li>
<li><a href="http://www.pcgg.com.cn/lol/31660.html">为什么lol不显示伤害数字</a></li>
<li><a href="http://www.pcgg.com.cn/aedfh/37978.html">艾尔登法环赛尔韦斯在哪</a></li>
<li><a href="http://www.pcgg.com.cn/gpqq/9403.html">和平精英怎样调镜头灵敏度好(和平精英镜头左右晃动调什么)</a></li>
<li><a href="http://www.pcgg.com.cn/cf/35123.html">cf几级才能领福利</a></li>
<li><a href="http://www.pcgg.com.cn/ys/43427.html">原神40级怎么发育</a></li>
<li><a href="http://www.pcgg.com.cn/xjzb/57456.html">星际争霸二对决第一集</a></li>
<li><a href="http://www.pcgg.com.cn/lol/19757.html">lol比赛对内语音在哪看</a></li>
<li><a href="http://www.pcgg.com.cn/lol/22989.html">lol视频录制怎么传到手机上</a></li>
</ul>
</div>
</div>
</div>
<div class="clear"></div>
<div id="comments_box">
</div>
</div>
<div id="sidebar">
<div id="sidebar-follow">
<div class="search box row">
<div class="search_site">
<form id="searchform" method="get" action="http://www.csdndoc.com/index.php">
<button type="submit" value="" id="searchsubmit" class="button"><i class="fasearch">☚</i></button>
<label><input type="text" class="search-s" name="s" x-webkit-speech="" placeholder="请输入搜索内容"></label>
</form></div></div>
<div class="widget_text widget box row widget_custom_html"><h3>公告</h3><div class="textwidget custom-html-widget"><a target="_blank" href="http://www.5d.ink/deepseek/?d=DeepseekR1_local.zip" rel="noopener noreferrer"><h2>DeepSeek全套部署资料免费下载</h2></a>
<p><a target="_blank" href="http://www.5d.ink/deepseek/?d=DeepseekR1_local.zip" rel="noopener noreferrer"><img src="http://css.5d.ink/img/deep.png" alt="DeepSeekR1本地部署部署资料免费下载"></a></p><br /><br />
<a target="_blank" href="http://www.5d.ink/freefonts/?d=FreeFontsdown.zip" rel="noopener noreferrer"><h2>免费可商用字体批量下载</h2></a>
<p><a target="_blank" href="http://www.5d.ink/freefonts/?d=FreeFontsdown.zip" rel="noopener noreferrer"><img src="http://css.5d.ink/img/freefont.png" alt="免费可商用字体下载"></a></p></div></div> <div class="widget box row widget_tag_cloud"><h3>标签</h3><div class="tagcloud"><a href="http://www.csdndoc.com/tag/ck-2" class="tag-cloud-link tag-link-237 tag-link-position-1" style="font-size: 8.4329896907216pt;" aria-label="仓库 (527个项目)">仓库</a>
<a href="http://www.csdndoc.com/tag/dm" class="tag-cloud-link tag-link-47 tag-link-position-2" style="font-size: 16.515463917526pt;" aria-label="代码 (1,900个项目)">代码</a>
<a href="http://www.csdndoc.com/tag/ys" class="tag-cloud-link tag-link-62 tag-link-position-3" style="font-size: 10.309278350515pt;" aria-label="元素 (708个项目)">元素</a>
<a href="http://www.csdndoc.com/tag/hs" class="tag-cloud-link tag-link-38 tag-link-position-4" style="font-size: 14.20618556701pt;" aria-label="函数 (1,319个项目)">函数</a>
<a href="http://www.csdndoc.com/tag/gn" class="tag-cloud-link tag-link-48 tag-link-position-5" style="font-size: 9.2989690721649pt;" aria-label="功能 (606个项目)">功能</a>
<a href="http://www.csdndoc.com/tag/qk" class="tag-cloud-link tag-link-324 tag-link-position-6" style="font-size: 9.2989690721649pt;" aria-label="区块 (600个项目)">区块</a>
<a href="http://www.csdndoc.com/tag/cs" class="tag-cloud-link tag-link-25 tag-link-position-7" style="font-size: 9.1546391752577pt;" aria-label="参数 (591个项目)">参数</a>
<a href="http://www.csdndoc.com/tag/ml" class="tag-cloud-link tag-link-4 tag-link-position-8" style="font-size: 11.752577319588pt;" aria-label="命令 (888个项目)">命令</a>
<a href="http://www.csdndoc.com/tag/tx" class="tag-cloud-link tag-link-130 tag-link-position-9" style="font-size: 9.5876288659794pt;" aria-label="图像 (630个项目)">图像</a>
<a href="http://www.csdndoc.com/tag/zzl" class="tag-cloud-link tag-link-20 tag-link-position-10" style="font-size: 21.134020618557pt;" aria-label="在这里 (3,985个项目)">在这里</a>
<a href="http://www.csdndoc.com/tag/dz" class="tag-cloud-link tag-link-196 tag-link-position-11" style="font-size: 10.020618556701pt;" aria-label="地址 (677个项目)">地址</a>
<a href="http://www.csdndoc.com/tag/khd" class="tag-cloud-link tag-link-28 tag-link-position-12" style="font-size: 8.7216494845361pt;" aria-label="客户端 (544个项目)">客户端</a>
<a href="http://www.csdndoc.com/tag/rq" class="tag-cloud-link tag-link-215 tag-link-position-13" style="font-size: 11.030927835052pt;" aria-label="容器 (792个项目)">容器</a>
<a href="http://www.csdndoc.com/tag/dx" class="tag-cloud-link tag-link-34 tag-link-position-14" style="font-size: 8.5773195876289pt;" aria-label="对象 (542个项目)">对象</a>
<a href="http://www.csdndoc.com/tag/gj" class="tag-cloud-link tag-link-43 tag-link-position-15" style="font-size: 10.309278350515pt;" aria-label="工具 (703个项目)">工具</a>
<a href="http://www.csdndoc.com/tag/kfz" class="tag-cloud-link tag-link-294 tag-link-position-16" style="font-size: 11.463917525773pt;" aria-label="开发者 (842个项目)">开发者</a>
<a href="http://www.csdndoc.com/tag/js" class="tag-cloud-link tag-link-283 tag-link-position-17" style="font-size: 10.742268041237pt;" aria-label="技术 (762个项目)">技术</a>
<a href="http://www.csdndoc.com/tag/jk" class="tag-cloud-link tag-link-252 tag-link-position-18" style="font-size: 8.4329896907216pt;" aria-label="接口 (528个项目)">接口</a>
<a href="http://www.csdndoc.com/tag/cj" class="tag-cloud-link tag-link-68 tag-link-position-19" style="font-size: 8.1443298969072pt;" aria-label="插件 (496个项目)">插件</a>
<a href="http://www.csdndoc.com/tag/crtp" class="tag-cloud-link tag-link-42 tag-link-position-20" style="font-size: 16.226804123711pt;" aria-label="插入图片 (1,825个项目)">插入图片</a>
<a href="http://www.csdndoc.com/tag/cz-3" class="tag-cloud-link tag-link-513 tag-link-position-21" style="font-size: 8.8659793814433pt;" aria-label="操作 (562个项目)">操作</a>
<a href="http://www.csdndoc.com/tag/sj" class="tag-cloud-link tag-link-55 tag-link-position-22" style="font-size: 22pt;" aria-label="数据 (4,611个项目)">数据</a>
<a href="http://www.csdndoc.com/tag/sjk" class="tag-cloud-link tag-link-124 tag-link-position-23" style="font-size: 10.164948453608pt;" aria-label="数据库 (696个项目)">数据库</a>
<a href="http://www.csdndoc.com/tag/sz-3" class="tag-cloud-link tag-link-186 tag-link-position-24" style="font-size: 9.1546391752577pt;" aria-label="数组 (593个项目)">数组</a>
<a href="http://www.csdndoc.com/tag/wj" class="tag-cloud-link tag-link-81 tag-link-position-25" style="font-size: 18.103092783505pt;" aria-label="文件 (2,450个项目)">文件</a>
<a href="http://www.csdndoc.com/tag/ff" class="tag-cloud-link tag-link-18 tag-link-position-26" style="font-size: 11.030927835052pt;" aria-label="方法 (792个项目)">方法</a>
<a href="http://www.csdndoc.com/tag/fwq" class="tag-cloud-link tag-link-147 tag-link-position-27" style="font-size: 13.484536082474pt;" aria-label="服务器 (1,163个项目)">服务器</a>
<a href="http://www.csdndoc.com/tag/mk" class="tag-cloud-link tag-link-111 tag-link-position-28" style="font-size: 8pt;" aria-label="模块 (486个项目)">模块</a>
<a href="http://www.csdndoc.com/tag/mx" class="tag-cloud-link tag-link-69 tag-link-position-29" style="font-size: 19.40206185567pt;" aria-label="模型 (3,021个项目)">模型</a>
<a href="http://www.csdndoc.com/tag/cs-2" class="tag-cloud-link tag-link-58 tag-link-position-30" style="font-size: 13.051546391753pt;" aria-label="测试 (1,107个项目)">测试</a>
<a href="http://www.csdndoc.com/tag/bb" class="tag-cloud-link tag-link-6 tag-link-position-31" style="font-size: 13.051546391753pt;" aria-label="版本 (1,094个项目)">版本</a>
<a href="http://www.csdndoc.com/tag/hj" class="tag-cloud-link tag-link-3 tag-link-position-32" style="font-size: 9.5876288659794pt;" aria-label="环境 (631个项目)">环境</a>
<a href="http://www.csdndoc.com/tag/yh" class="tag-cloud-link tag-link-44 tag-link-position-33" style="font-size: 14.494845360825pt;" aria-label="用户 (1,381个项目)">用户</a>
<a href="http://www.csdndoc.com/tag/sl" class="tag-cloud-link tag-link-17 tag-link-position-34" style="font-size: 10.020618556701pt;" aria-label="示例 (668个项目)">示例</a>
<a href="http://www.csdndoc.com/tag/cx" class="tag-cloud-link tag-link-31 tag-link-position-35" style="font-size: 9.7319587628866pt;" aria-label="程序 (652个项目)">程序</a>
<a href="http://www.csdndoc.com/tag/sf" class="tag-cloud-link tag-link-108 tag-link-position-36" style="font-size: 9.5876288659794pt;" aria-label="算法 (633个项目)">算法</a>
<a href="http://www.csdndoc.com/tag/xt" class="tag-cloud-link tag-link-96 tag-link-position-37" style="font-size: 14.061855670103pt;" aria-label="系统 (1,287个项目)">系统</a>
<a href="http://www.csdndoc.com/tag/xc" class="tag-cloud-link tag-link-19 tag-link-position-38" style="font-size: 8.1443298969072pt;" aria-label="线程 (504个项目)">线程</a>
<a href="http://www.csdndoc.com/tag/zj" class="tag-cloud-link tag-link-192 tag-link-position-39" style="font-size: 10.020618556701pt;" aria-label="组件 (680个项目)">组件</a>
<a href="http://www.csdndoc.com/tag/jd" class="tag-cloud-link tag-link-12 tag-link-position-40" style="font-size: 14.350515463918pt;" aria-label="节点 (1,336个项目)">节点</a>
<a href="http://www.csdndoc.com/tag/sp" class="tag-cloud-link tag-link-484 tag-link-position-41" style="font-size: 8pt;" aria-label="视频 (489个项目)">视频</a>
<a href="http://www.csdndoc.com/tag/sb" class="tag-cloud-link tag-link-160 tag-link-position-42" style="font-size: 10.164948453608pt;" aria-label="设备 (687个项目)">设备</a>
<a href="http://www.csdndoc.com/tag/lj" class="tag-cloud-link tag-link-22 tag-link-position-43" style="font-size: 10.020618556701pt;" aria-label="路径 (671个项目)">路径</a>
<a href="http://www.csdndoc.com/tag/jx" class="tag-cloud-link tag-link-213 tag-link-position-44" style="font-size: 11.752577319588pt;" aria-label="镜像 (884个项目)">镜像</a>
<a href="http://www.csdndoc.com/tag/xm" class="tag-cloud-link tag-link-171 tag-link-position-45" style="font-size: 14.639175257732pt;" aria-label="项目 (1,403个项目)">项目</a></div>
</div> <div class="widget box row">
<div id="tab-title">
<div class="tab">
<ul id="tabnav">
<li class="selected">猜你想看的文章</li>
</ul>
</div>
<div class="clear"></div>
</div>
<div id="tab-content">
<ul>
<li><a href="http://www.pcgg.com.cn/gl/5503.html">原神雷泽和刻晴养谁好</a></li>
<li><a href="http://www.pcgg.com.cn/gpqq/8211.html">和平精英体验服官网怎么登录怎么申请</a></li>
<li><a href="http://www.pcgg.com.cn/lol/24026.html">现在英雄联盟没有钻5了吗</a></li>
<li><a href="http://www.pcgg.com.cn/lol/29514.html">lol怎么设置离开</a></li>
<li><a href="http://www.pcgg.com.cn/gpqq/6410.html">和平精英在哪里下载?(请问和平精英在哪里下载)</a></li>
<li><a href="http://www.pcgg.com.cn/gpqq/7909.html">和平精英体验服抢号时间什么时候结束</a></li>
<li><a href="http://www.pcgg.com.cn/lol/15793.html">如何显示英雄联盟桌面图标</a></li>
<li><a href="http://www.pcgg.com.cn/lol/19857.html">美服英雄联盟手游出来了吗</a></li>
<li><a href="http://www.pcgg.com.cn/lol/31740.html">lol是哪个国家出的游戏</a></li>
<li><a href="http://www.pcgg.com.cn/gl/847.html">云原神能不能登b服</a></li>
</ul>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="clear"></div>
<div id="footer">
<div class="container">
<div class="twothird">
</div>
</div>
<div class="container">
<div class="twothird">
<div class="copyright">
<p> Copyright © 2012 - 2025 <a href="http://www.csdndoc.com/"><strong>程序员档案馆</strong></a> Powered by <a href="/lists">网站分类目录</a> | <a href="/top100.php" target="_blank">精选推荐文章</a> | <a href="/sitemap.xml" target="_blank">网站地图</a> | <a href="/post/" target="_blank">疑难解答</a>
<a href="https://beian.miit.gov.cn/" rel="external">京ICP备05034492号</a>
</p>
<p>声明:本站内容来自互联网,如信息有错误可发邮件到f_fb#foxmail.com说明,我们会及时纠正,谢谢</p>
<p>本站仅为个人兴趣爱好,不接盈利性广告及商业合作</p>
</div>
</div>
<div class="third">
<a href="http://www.xiaoboy.cn" target="_blank">小男孩</a>
</div>
</div>
</div>
<!--gototop-->
<div id="tbox">
<a id="home" href="http://www.csdndoc.com" title="返回首页"><i class="fa fa-gohome"></i></a>
<a id="pinglun" href="#comments_box" title="前往评论"><i class="fa fa-commenting"></i></a>
<a id="gotop" href="javascript:void(0)" title="返回顶部"><i class="fa fa-chevron-up"></i></a>
</div>
<script src="//css.5d.ink/body5.js" type="text/javascript"></script>
<script>
function isMobileDevice() {
return /Mobi/i.test(navigator.userAgent) || /Android/i.test(navigator.userAgent) || /iPhone|iPad|iPod/i.test(navigator.userAgent) || /Windows Phone/i.test(navigator.userAgent);
}
// 加载对应的 JavaScript 文件
if (isMobileDevice()) {
var script = document.createElement('script');
script.src = '//css.5d.ink/js/menu.js';
script.type = 'text/javascript';
document.getElementsByTagName('head')[0].appendChild(script);
}
</script>
<script>
$(document).ready(function() {
$("#sidebar-follow").pin({
containerSelector: ".main-container",
padding: {top:64},
minWidth: 768
});
$(".mainmenu").pin({
containerSelector: ".container",
padding: {top:0}
});
$(".swipebox").swipebox();
});
</script>
</body></html>
<!-- Theme by Xiaoboy -->
<!-- made in China! -->
<!-- super cache -->