【开源解析】基于深度学习的双色球预测系统:从数据获取到可视化分析_训练预测系统
基于深度学习的双色球预测系统:从数据获取到可视化分析

🌈 个人主页:创客白泽 - CSDN博客
🔥 系列专栏:🐍《Python开源项目实战》
💡 热爱不止于代码,热情源自每一个灵感闪现的夜晚。愿以开源之火,点亮前行之路。
👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更多人哦


概述
在当今大数据和人工智能时代,机器学习技术已广泛应用于各个领域。本文将介绍一个基于PyQt5和TensorFlow开发的双色球预测系统,该系统集数据获取、深度学习模型训练、预测分析和可视化展示于一体。
本项目采用Python语言开发,主要技术栈包括:
- PyQt5:构建美观的图形用户界面
- TensorFlow/Keras:实现LSTM、GRU等深度学习模型
- Pandas/Numpy:数据处理与分析
- WebEngineView:现代化的结果展示方式
系统通过分析历史开奖数据,运用多种神经网络模型预测下一期可能的开奖号码,并提供直观的数据可视化功能。本文将从功能设计、实现原理、代码解析等多个维度详细介绍该系统。
功能特点
1. 数据获取模块
系统内置网络爬虫功能,能够自动从官方数据源获取最新的双色球开奖数据。主要特点包括:
- 自动处理网络请求和JSON数据解析
- 数据清洗和异常处理机制
- 本地CSV文件缓存
- 进度条实时显示获取进度
2. 预测分析模块
核心预测功能基于TensorFlow深度学习框架,提供三种预测策略:
- LSTM模型:长短期记忆网络,擅长捕捉时间序列中的长期依赖关系
- GRU模型:门控循环单元,比LSTM更轻量高效
- 混合模型:结合CNN、LSTM、GRU和注意力机制的多层次特征提取
3. 可视化分析模块
系统采用现代化的Web技术展示分析结果:
- 交互式HTML表格展示历史数据
- 动态气泡图展示号码频率分布
- 响应式设计适配不同屏幕尺寸
- 动画效果增强用户体验
4. 参数配置界面
用户友好的参数配置界面,可调整:
- 训练集比例(50%-95%)
- 训练轮次(50-1000)
- 批量大小(16-128)
- 回溯期数(5-30)
- 预测策略(LSTM/GRU/混合模型)
系统展示
主界面截图
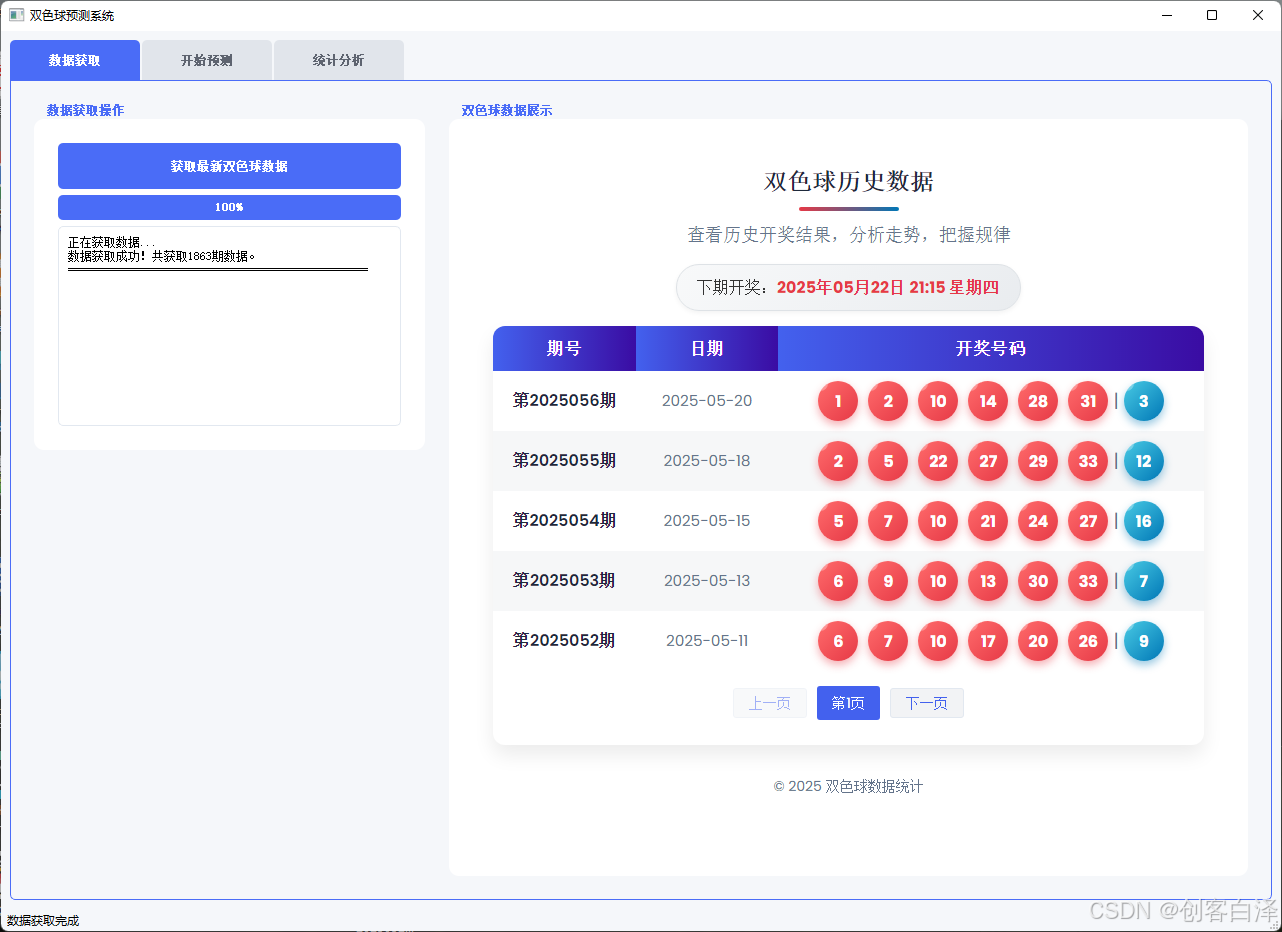
主界面采用标签页设计,分为\"数据获取\"、\"开始预测\"和\"统计分析\"三个主要功能区域。界面风格现代化,配色以蓝色和红色为主,符合双色球主题。
数据获取界面
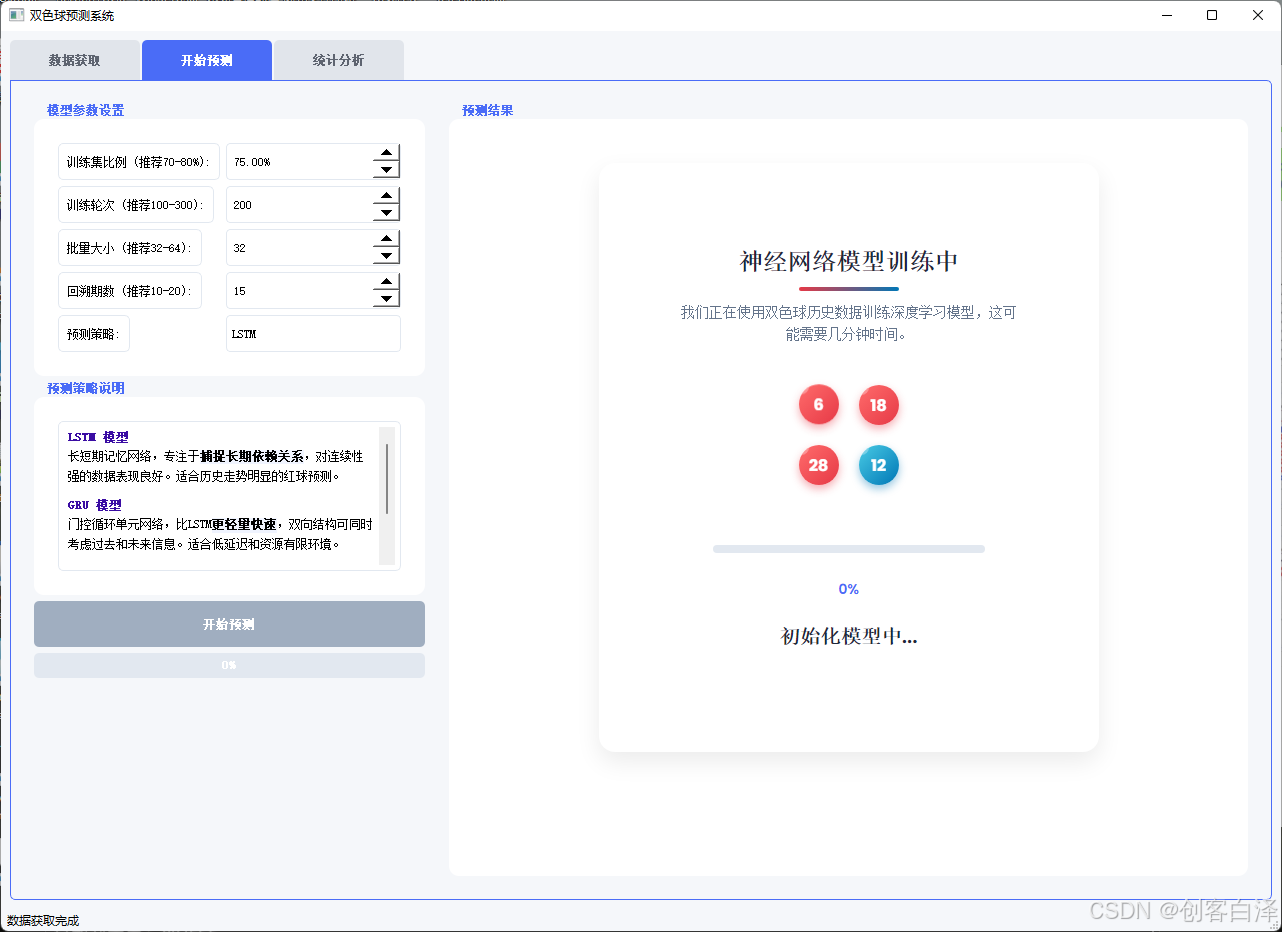
左侧为操作面板,右侧以卡片式布局展示获取到的历史数据,支持分页浏览。数据表格采用响应式设计,在移动设备上也能良好显示。
预测结果展示
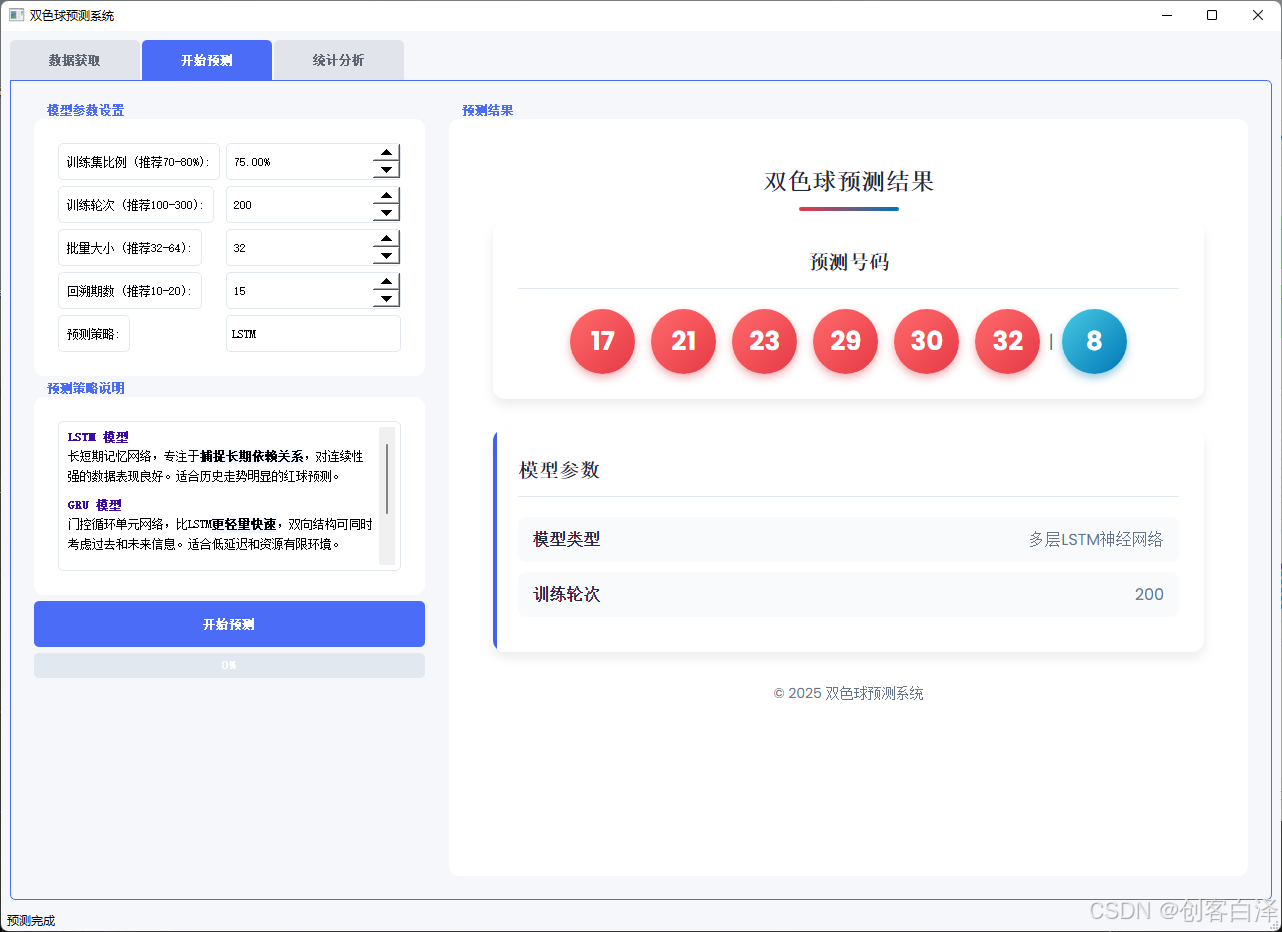
预测结果以醒目的红蓝球号码展示,并附带模型参数和训练信息。页面加载时有精美的加载动画,提升用户体验。
统计分析可视化

采用气泡图直观展示各号码的出现频率,高频号码会有脉冲动画效果。同时提供TOP10号码列表和详细统计数据。
实现原理
1. 整体架构
系统采用MVC(Model-View-Controller)设计模式:
- Model:数据处理和预测算法(
DataFetcher,EnhancedPredictor) - View:PyQt5界面和Web展示(
MainWindow, HTML模板) - Controller:事件处理和业务逻辑(
MainWindow方法)
2. 数据流图
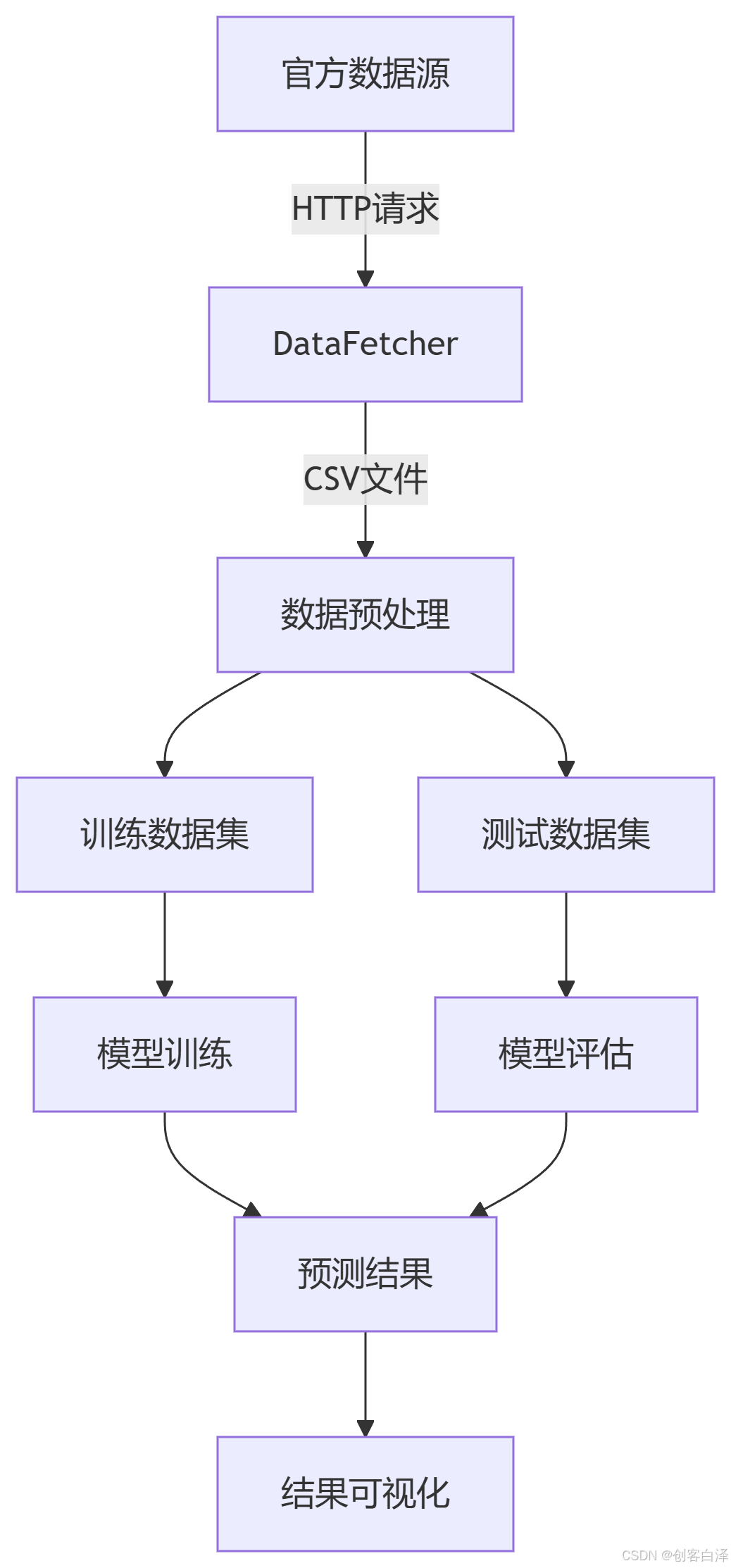
3. 关键技术点
- 惰性导入:仅在需要时导入TensorFlow等重型库,加快启动速度
- 多线程处理:使用QThread防止界面卡顿
- 异常处理:全面的错误捕获和备用方案
- 响应式设计:适配不同尺寸屏幕
- 动画效果:增强用户体验
代码解析
1. 数据获取模块
class DataFetcher(QThread): finished = pyqtSignal(str) progress = pyqtSignal(int) def run(self): try: import requests import pandas as pd url = \'http://www.cwl.gov.cn/cwl_admin/front/cwlkj/search/kjxx/findDrawNotice\' params = { \'name\': \'ssq\', \'issueCount\': \'\', \'issueStart\': \'\', \'issueEnd\': \'\', \'dayStart\': \'\', \'dayEnd\': \'\', \'pageNo\': \'1\', \'pageSize\': \'9999\', \'week\': \'\', \'systemType\': \'PC\' } response = requests.get(url, params=params) jsondata = response.json() # 数据处理逻辑... df.to_csv(\'data.csv\', index=False, encoding=\'utf-8-sig\') self.finished.emit(f\"数据获取成功!共获取{ len(data)}期数据。\") except Exception as e: self.finished.emit(f\"数据获取失败:{ str(e)}\")关键点:
- 继承QThread实现多线程
- 使用requests库获取数据
- 完善的数据清洗和异常处理
- 进度信号实时更新界面
2. 预测模型模块
class EnhancedPredictor(QThread): # ...初始化代码... def create_lstm_model(self, input_shape): import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, LSTM, BatchNormalization, Dropout model = Sequential([ Input(shape=input_shape), LSTM(512, return_sequences=True, kernel_regularizer=l2(0.01), recurrent_regularizer=l2(0.01), dropout=0.2, recurrent_dropout=0.2), BatchNormalization(), LSTM(256, return_sequences=True), # ...更多层... Dense(7, activation=\'sigmoid\') ]) model.compile(loss=\'mean_squared_error\', optimizer=Adam(learning_rate=0.001), metrics=[\'mae\']) return model关键点:
- 三种模型架构可选
- 添加正则化和Dropout防止过拟合
- BatchNormalization加速训练
- 自定义Attention层增强关键特征
3. 界面交互设计
class MainWindow(QMainWindow): def __init__(self): super().__init__() self.setWindowTitle(\"红篮球预测系统\") self.setGeometry(100, 100, 1280, 900) self.setStyleSheet(\"\"\" QMainWindow { background-color: #f5f7fa; } /* 更多样式... */ \"\"\") # 初始化UI组件 self.initUI() def initUI(self): # 创建标签页 self.tabs = QTabWidget() # 数据获取页 data_tab = QWidget() # ...布局和组件... # 预测页 predict_tab = QWidget() # ...布局和组件... # 统计页 stats_tab = QWidget() # ...布局和组件... self.tabs.addTab(data_tab, \"数据获取\") self.tabs.addTab(predict_tab, \"开始预测\") self.tabs.addTab(stats_tab, \"统计分析\")关键点:
- 现代化CSS样式
- 响应式布局
- 标签页导航
- WebEngineView集成
使用教程
1. 数据获取步骤
- 点击\"数据获取\"标签页
- 点击\"获取最新红篮球数据\"按钮
- 等待进度条完成
- 查看右侧表格展示的历史数据
2. 预测分析步骤
- 调整模型参数:
- 训练集比例:70-80%
- 训练轮次:100-300
- 批量大小:32-64
- 回溯期数:10-20
- 预测策略:根据需求选择
- 点击\"开始预测\"按钮
- 等待训练完成(有进度显示)
- 查看预测结果
3. 统计分析查看
- 数据获取完成后自动生成统计信息
- 点击\"统计分析\"标签页
- 查看号码频率分布和TOP10列表
源码解析
1. 核心类关系
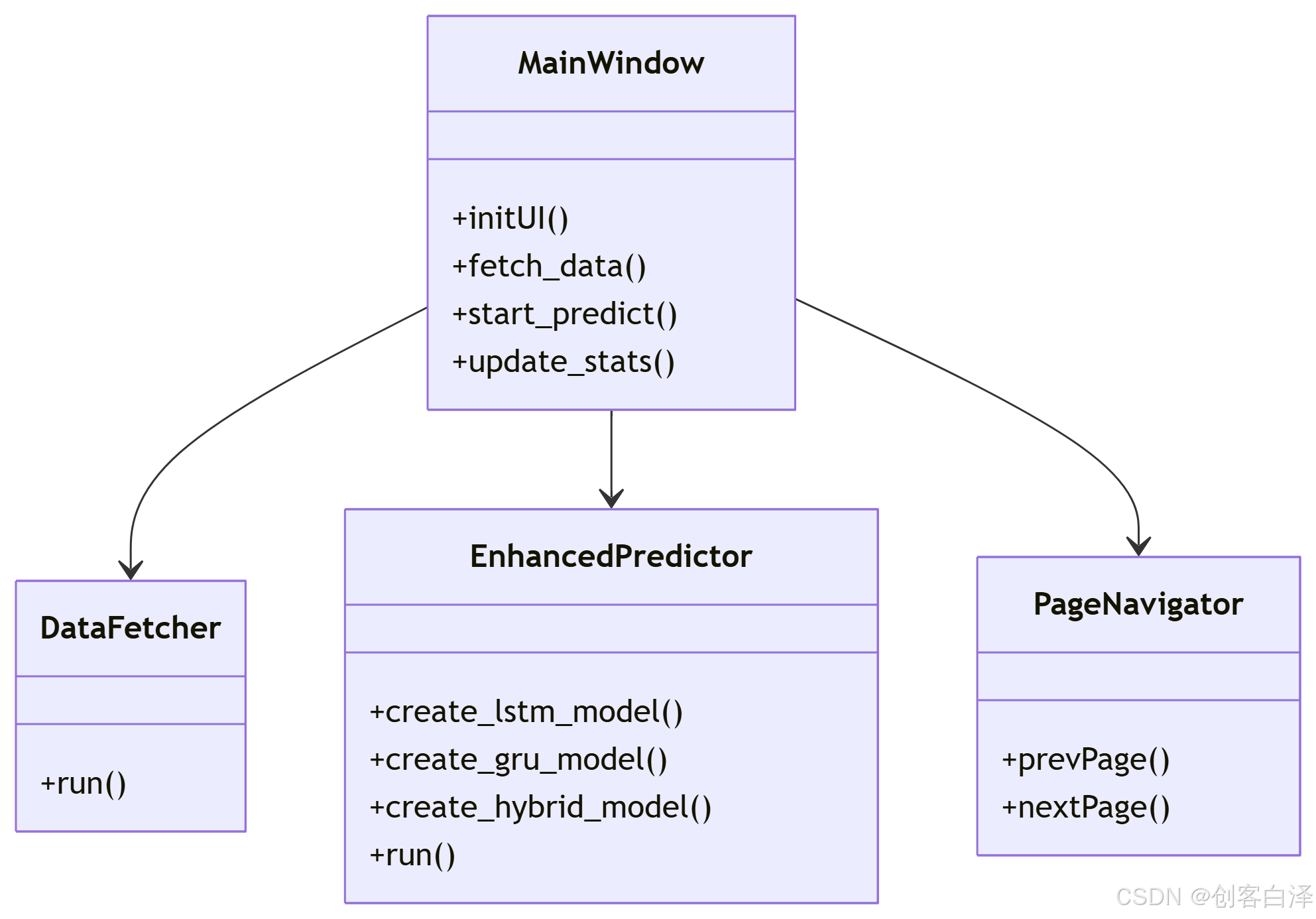
2. 关键方法说明
数据预处理
def preprocess_data(self, df): # 日期处理 df[\'date\'] = pd.to_datetime(df[\'日期\'], errors=\'coerce\') # 添加时间特征 df[\'year\'] = df[\'date\'].dt.year df[\'month\'] = df[\'date\'].dt.month # ...其他特征... # 数值标准化 numeric_cols = [col for col in df.columns if col not in non_numeric_cols] self.scaler = MinMaxScaler() scaled_data = self.scaler.fit_transform(df[numeric_cols]) return scaled_data, numeric_cols序列数据生成
def generate_sequences(self, data, lookback): X, y = [], [] for i in range(len(data) - lookback): X.append(data[i:i + lookback]) y.append(data[i + lookback, :7]) # 预测7个号码(6红+1蓝) return np.array(X), np.array(y)结果后处理
def enhanced_postprocessing(self, prediction): # 处理预测结果 prediction = np.nan_to_num(prediction, nan=0.5) # 映射到实际号码范围 red_balls = [] for i in range(6): ball = int(round(prediction[0][i] * 32 + 1)) ball = max(1, min(33, ball)) red_balls.append(ball) # 处理蓝球 blue_ball = int(round(prediction[0][6] * 15 + 1)) blue_ball = max(1, min(16, blue_ball)) return sorted(red_balls), blue_ball源码下载
import sysimport os# Simple Python modules firstimport jsonfrom collections import Counter# Core PyQt imports for UIfrom PyQt5.QtWidgets import (QApplication, QMainWindow, QWidget, QVBoxLayout, QHBoxLayout, QLabel, QPushButton, QTextEdit, QSpinBox, QDoubleSpinBox, QProgressBar, QMessageBox, QTabWidget, QGroupBox, QFormLayout, QComboBox)from PyQt5.QtCore import QThread, pyqtSignal, Qt, QUrl, QObject, pyqtSlotfrom PyQt5.QtGui import QIconfrom PyQt5.QtWebEngineWidgets import QWebEngineView, QWebEnginePagefrom PyQt5.QtWebChannel import QWebChannel# Import custom module for bubble charts# from bubbles import generate_bubble_chart_htmldef resource_path(relative_path): \"\"\" 解决打包后资源文件路径问题 \"\"\" if hasattr(sys, \'_MEIPASS\'): return os.path.join(sys._MEIPASS, relative_path) return os.path.join(os.path.abspath(\".\"), relative_path)class AttentionLayer: def __init__(self, **kwargs): # Import TensorFlow here when the class is instantiated import tensorflow as tf from tensorflow.keras.layers import Layer self.tf = tf super(Layer, self).__init__(**kwargs) def build(self, input_shape): self.W = self.add_weight(name=\'attention_weight\', shape=(input_shape[-1], 1), initializer=\'random_normal\', trainable=True) self.b = self.add_weight(name=\'attention_bias\', shape=(input_shape[1], 1), initializer=\'zeros\', trainable=True) super(AttentionLayer, self).build(input_shape) def call(self, x): e = self.tf.tanh(self.tf.matmul(x, self.W) + self.b) a = self.tf.nn.softmax(e, axis=1) output = x * a return self.tf.reduce_sum(output, axis=1)def is_prime(n): \"\"\"判断是否为质数\"\"\" if n <= 1: return False for i in range(2, int(n ** 0.5) + 1): if n % i == 0: return False return Trueclass DataFetcher(QThread): finished = pyqtSignal(str) progress = pyqtSignal(int) def run(self): try: # Import requests only when needed for data fetching import requests import pandas as pd url = \'http://www.cwl.gov.cn/cwl_admin/front/cwlkj/search/kjxx/findDrawNotice\' params = { \'name\': \'ssq\', \'issueCount\': \'\', \'issueStart\': \'\', \'issueEnd\': \'\', \'dayStart\': \'\', \'dayEnd\': \'\', \'pageNo\': \'1\', \'pageSize\': \'9999\', \'week\': \'\', \'systemType\': \'PC\' } response = requests.get(url, params=params) jsondata = response.json() if jsondata[\'state\'] == 0: data = [] total = len(jsondata[\'result\']) # 收集所有的日期字符串,用于日志记录 all_dates = [] for i, item in enumerate(jsondata[\'result\']): # 获取日期字符串 date_str = item[\'date\'] all_dates.append(date_str) # 更严格地处理日期格式 try: # 首先尝试分离掉括号部分(如果有) date_str = date_str.split(\'(\')[0].strip() # 移除日期字符串中的非法字符 clean_date = \'\'.join([c for c in date_str if c.isdigit() or c == \'-\']) # 确保日期格式为YYYY-MM-DD并且长度正确 if len(clean_date) >= 10: clean_date = clean_date[:10] else: # 对于格式不正确的日期,使用期号的前8位作为替代(如果可能) code = item[\'code\'] if len(code) >= 8: year = code[:4] month = code[4:6] day = code[6:8] clean_date = f\"{ year}-{ month}-{ day}\" else: # 最后的备选方案 clean_date = \"2020-01-01\" # 使用占位符 except Exception as e: print(f\"处理日期时出错: { str(e)}, 原始日期: { date_str}\") clean_date = \"2020-01-01\" # 使用占位符 # 获取蓝球和红球 try: blue_ball = int(item[\'blue\']) red_balls = [int(rb) for rb in item[\'red\'].split(\',\')] # 确保有足够的红球 while len(red_balls) < 6: red_balls.append(1) # 使用1作为占位符 # 添加到数据列表 data.append([item[\'code\'], clean_date, red_balls[0], red_balls[1], red_balls[2], red_balls[3], red_balls[4], red_balls[5], blue_ball]) except Exception as e: print(f\"处理球号时出错: { str(e)}, 期号: { item[\'code\']}\") # 跳过这条数据 continue self.progress.emit(int((i + 1) / total * 100)) # 记录日期收集情况 print(f\"收集到 { len(all_dates)} 个日期\") if len(all_dates) > 0: print(f\"示例日期: { all_dates[0]}\") df = pd.DataFrame(data, columns=[\'期号\', \'日期\', \'red1\', \'red2\', \'red3\', \'red4\', \'red5\', \'red6\', \'blue\']) # 检查数据有效性 print(f\"数据总行数: { len(df)}\") print(f\"日期列类型: { df[\'日期\'].dtype}\") print(f\"缺失值数量: { df.isna().sum().sum()}\") # 保存前排序 try: df[\'temp_date\'] = pd.to_datetime(df[\'日期\'], errors=\'coerce\') df = df.sort_values(by=\'temp_date\', ascending=False) # 修复链式赋值警告,避免使用 inplace=True df = df.drop(\'temp_date\', axis=1) except Exception as e: print(f\"排序数据时出错: { str(e)}\") df.to_csv(\'data.csv\', index=False, encoding=\'utf-8-sig\') self.finished.emit(f\"数据获取成功!共获取{ len(data)}期数据。\") else: self.finished.emit(\"数据获取失败:服务器返回错误状态。\") except Exception as e: import traceback error_details = traceback.format_exc() self.finished.emit(f\"数据获取失败:{ str(e)}\\n\\n详细错误信息:\\n{ error_details}\")class EnhancedPredictor(QThread): finished = pyqtSignal(str) progress = pyqtSignal(int) stats_ready = pyqtSignal(dict) model_trained = pyqtSignal(object) def __init__(self, train_ratio, epochs, batch_size, lookback, strategy, shared_css=None): super().__init__() self.train_ratio = train_ratio self.epochs = epochs self.batch_size = batch_size self.lookback = lookback self.strategy = strategy.lower() self.red_stats = None self.blue_stats = None self.scaler = None self.model = None self.shared_css = shared_css or \"\" # Default to empty string if None # We\'ll import tensorflow and other ML libraries on demand when run() is called def get_model_type(self): \"\"\"获取当前使用的模型类型\"\"\" if self.strategy == \'lstm\': return \"多层LSTM神经网络\" elif self.strategy == \'gru\': return \"双向GRU神经网络\" else: return \"混合模型(CNN+LSTM+GRU+Attention)\" def get_model_architecture(self): \"\"\"获取模型架构描述\"\"\" if self.strategy == \'lstm\': return \"LSTM(512)→LSTM(256)→Dense(128)\" elif self.strategy == \'gru\': return \"BiGRU(256)→GRU(128)→Dense(64)\" else: return \"Conv1D→BiLSTM→GRU→Attention→Dense\" def calculate_enhanced_stats(self, data): \"\"\"增强的统计分析\"\"\" try: # Import pandas here to use within this function import pandas as pd import numpy as np stats = { } # 确保数据是数值型 for i in range(1, 7): if f\'red{ i}\' in data.columns: data[f\'red{ i}\'] = pd.to_numeric(data[f\'red{ i}\'], errors=\'coerce\') if \'blue\' in data.columns: data[\'blue\'] = pd.to_numeric(data[\'blue\'], errors=\'coerce\') # 填充可能的NaN值 - 修复链式赋值警告 for i in range(1, 7): if f\'red{ i}\' in data.columns: # 使用推荐的方式替代 inplace=True data[f\'red{ i}\'] = data[f\'red{ i}\'].fillna(data[f\'red{ i}\'].median()) if \'blue\' in data.columns: # 使用推荐的方式替代 inplace=True data[\'blue\'] = data[\'blue\'].fillna(data[\'blue\'].median()) # 红球分析 red_balls = [] for i in range(1, 7): if f\'red{ i}\' in data.columns: red_balls.extend(data[f\'red{ i}\'].values) # 计算所有红球出现次数 red_counts = pd.Series(red_balls).value_counts().sort_index() red_probs = (red_counts / red_counts.sum()).sort_values(ascending=False) # 近期分析(最近100期) recent_data = data.tail(min(100, len(data))) recent_red = [] for i in range(1, 7): if f\'red{ i}\' in recent_data.columns: recent_red.extend(recent_data[f\'red{ i}\'].values) recent_red_counts = pd.Series(recent_red).value_counts() recent_red_probs = (recent_red_counts / recent_red_counts.sum()).sort_values(ascending=False) # 蓝球分析 if \'blue\' in data.columns: blue_counts = data[\'blue\'].value_counts().sort_index() blue_probs = (blue_counts / blue_counts.sum()).sort_values(ascending=False) recent_blue_counts = recent_data[\'blue\'].value_counts() recent_blue_probs = (recent_blue_counts / recent_blue_counts.sum()).sort_values(ascending=False) else: # 创建默认值 blue_probs = pd.Series([1/16]*16, index=range(1, 17)).sort_values(ascending=False) recent_blue_probs = blue_probs.copy() stats[\'red\'] = { \'all_time_top10\': dict(list(red_probs.head(10).items())), \'recent_top10\': dict(list(recent_red_probs.head(10).items())), \'all_time_sorted\': dict(red_probs.sort_index()) } stats[\'blue\'] = { \'all_time_top10\': dict(list(blue_probs.head(10).items())), \'recent_top10\': dict(list(recent_blue_probs.head(10).items())), \'all_time_sorted\': dict(blue_probs.sort_index()) } return stats except Exception as e: print(f\"统计分析出错: { str(e)}\") # 创建一个默认统计结果 default_stats = { \'red\': { \'all_time_top10\': { i: 1/33 for i in range(1, 11)}, \'recent_top10\': { i: 1/33 for i in range(1, 11)}, \'all_time_sorted\': { i: 1/33 for i in range(1, 34)} }, \'blue\': { \'all_time_top10\': { i: 1/16 for i in range(1, 11)}, \'recent_top10\': { i: 1/16 for i in range(1, 11)}, \'all_time_sorted\': { i: 1/16 for i in range(1, 17)} } } return default_stats def create_lstm_model(self, input_shape): \"\"\"创建LSTM模型\"\"\" # Import TensorFlow components when the model is actually being created import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, LSTM, BatchNormalization, Dropout, Input from tensorflow.keras.regularizers import l2 from tensorflow.keras.optimizers import Adam model = Sequential([ Input(shape=input_shape),
