【Hive面试必知】Hive中的表类型详解:内部表、外部表、分区表与分桶表_hive表
目录
前言
1 Hive表类型概述
2 内部表(管理表)
2.1 基本概念
2.2 特点
2.3 创建语法示例
2.4 数据加载过程
2.5 使用场景
2.6 注意事项
3 外部表(External Table)
3.1 基本概念
3.2 特点
3.3 创建语法示例
3.4 数据关联过程
3.5 使用场景
3.6 注意事项
4 分区表(Partitioned Table)
4.1 基本概念
4.2 特点
4.3 创建语法示例
4.4 分区结构
4.5 数据加载示例
4.6 使用场景
4.7 注意事项
5 分桶表(Bucketed Table)
5.1 基本概念
5.2 特点
5.3 创建语法示例
5.4 分桶原理
5.5 数据加载
5.6 使用场景
5.7 注意事项
6 表类型对比与组合使用
6.1 四种表类型对比
6.2 组合使用示例
6.3 组合使用场景
7 实践j建议与注意事项
7.1 表类型选择指南
7.2 性能优化建议
7.3 常见问题解决方案
8 总结
前言
在Hadoop生态系统中,Hive作为数据仓库工具扮演着至关重要的角色。它通过类SQL语言(HiveQL)简化了大数据处理,而表作为Hive中最基本的数据组织单元,其类型和特性直接影响着数据管理和查询效率。本文将全面剖析Hive中的四种主要表类型:内部表(管理表)、外部表、分区表和分桶表,深入探讨它们的特点、区别、使用场景及注意事项。
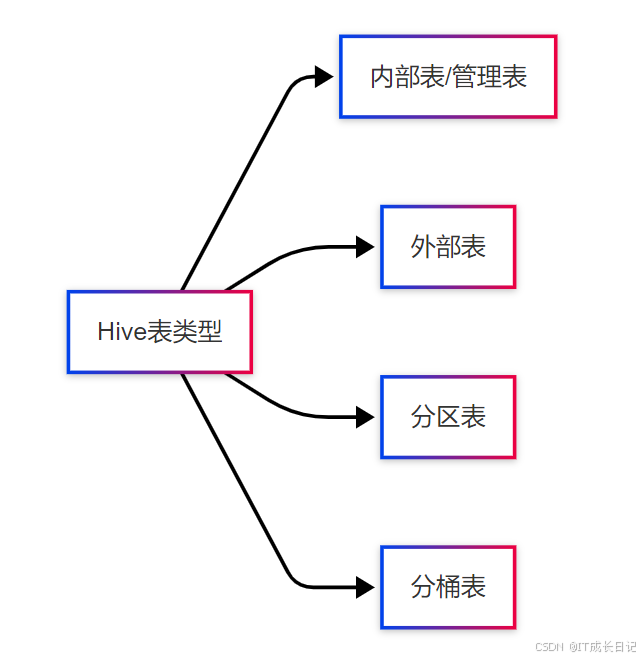
1 Hive表类型概述
- Hive中的表主要分为四种基本类型:
2 内部表(管理表)
2.1 基本概念
内部表(Internal Table),也称为管理表(Managed Table),是Hive默认创建的表类型。Hive对这类表拥有完全控制权,包括数据的存储和生命周期管理。
2.2 特点
- 元数据与数据统一管理:Hive同时管理表的元数据(存储在Metastore中)和实际数据
- 数据存储位置固定:默认存储在Hive配置的warehouse目录下(hive.metastore.warehouse.dir)
- 删除操作影响:删除表时,元数据和实际数据都会被删除
- 数据加载方式:加载数据到内部表时,Hive会将数据移动到其warehouse目录
2.3 创建语法示例
CREATE TABLE managed_table ( id INT, name STRING, age INT)ROW FORMAT DELIMITEDFIELDS TERMINATED BY \',\'STORED AS TEXTFILE;2.4 数据加载过程
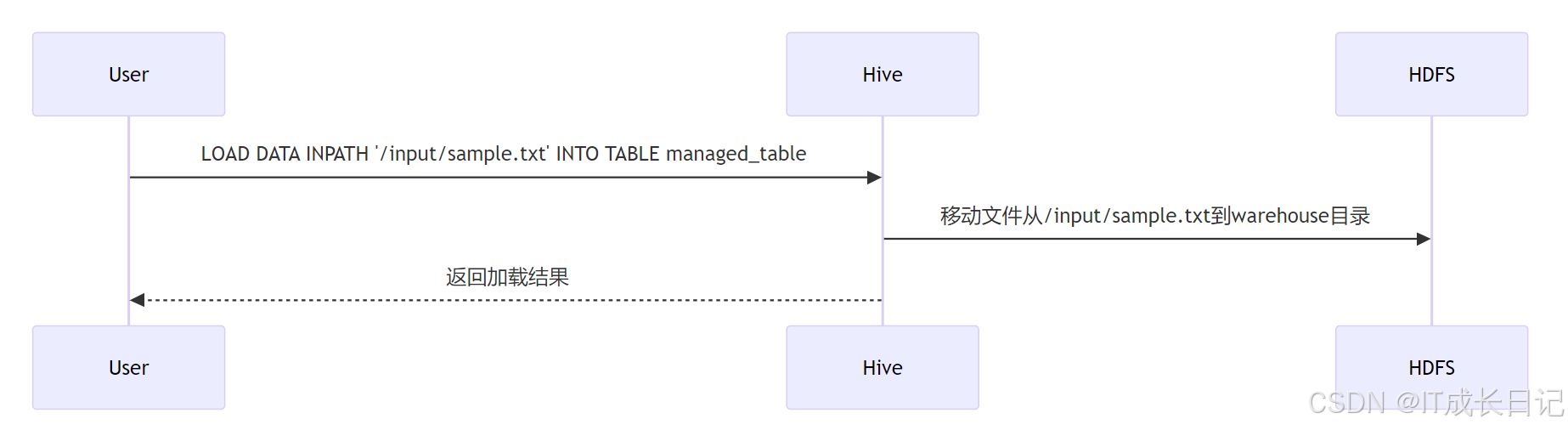
2.5 使用场景
- 当数据完全由Hive管理,不需要与其他工具共享时
- 临时数据集,测试和开发环境
- 当需要Hive完全控制数据生命周期时
2.6 注意事项
- 重要数据慎用内部表,误删可能导致数据丢失
- 与其他系统共享数据时不建议使用内部表
- 内部表适合ETL过程中的中间表
3 外部表(External Table)
3.1 基本概念
外部表(External Table)与内部表相对,Hive只管理其元数据,而不管理实际数据。删除外部表时,仅删除元数据,实际数据保持不变。
3.2 特点
- 元数据与数据分离管理:Hive只管理元数据,不管理实际数据
- 数据位置灵活:数据可以存储在HDFS任意位置
- 删除操作影响:删除表仅删除元数据,不影响实际数据
- 数据加载方式:创建表时指定数据位置,不需要移动数据
3.3 创建语法示例
CREATE EXTERNAL TABLE external_table ( id INT, name STRING, age INT)ROW FORMAT DELIMITEDFIELDS TERMINATED BY \',\'STORED AS TEXTFILELOCATION \'/user/hadoop/external_data\';3.4 数据关联过程

3.5 使用场景
- 数据需要被多个工具共享(如Pig、MapReduce等)
- 数据需要长期保留,不被表删除操作影响
- 数据由外部进程生成和管理
- 生产环境中的原始数据存储
3.6 注意事项
- 确保指定的LOCATION路径存在且数据格式正确
- 删除外部表前确认不再需要该表的元数据
- 外部表适合存储基础数据,内部表适合存储中间结果
- 数据一致性需要外部进程维护
4 分区表(Partitioned Table)
4.1 基本概念
分区表(Partitioned Table)是通过将表数据按分区键(如日期、地区等)组织到不同目录的表类型,可显著提高查询效率。
4.2 特点
- 物理分目录存储:每个分区对应一个HDFS目录
- 查询效率提升:分区裁剪(Partition Pruning)可减少扫描数据量
- 多级分区支持:支持按多字段分区(如年/月/日)
- 动态静态分区:支持动态分区和静态分区两种加载方式
4.3 创建语法示例
CREATE TABLE partitioned_table ( id INT, name STRING, sales DECIMAL)PARTITIONED BY (dt STRING, region STRING)ROW FORMAT DELIMITEDFIELDS TERMINATED BY \',\';4.4 分区结构
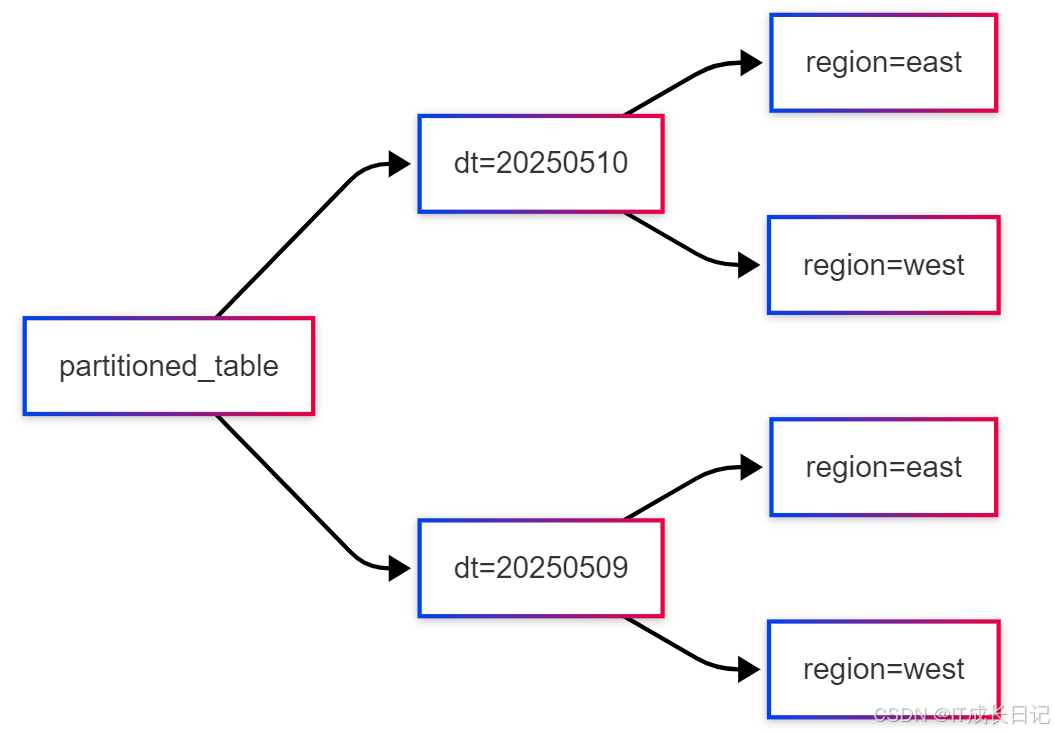
4.5 数据加载示例
- 静态分区加载:
LOAD DATA INPATH \'/data/sales_east_20250510.csv\'INTO TABLE partitioned_tablePARTITION (dt=\'20250510\', region=\'east\');- 动态分区加载(需要设置相关参数):
INSERT INTO TABLE partitioned_tablePARTITION (dt, region)SELECT id, name, sales, dt, region FROM source_table;4.6 使用场景
- 数据量大的事实表
- 可按时间、地区等维度自然划分的数据
- 需要频繁按某些字段过滤查询的场景
- 需要管理数据生命周期(按分区删除)
4.7 注意事项
- 避免分区过多导致Metastore压力大(小文件问题)
- 合理选择分区字段(高基数字段不适合)
- 动态分区需要配置相关参数如hive.exec.dynamic.partition
- 分区字段是虚拟字段,不存储在数据文件中
5 分桶表(Bucketed Table)
5.1 基本概念
分桶表(Bucketed Table)是通过哈希函数将数据分散到固定数量的桶(文件)中的表类型,可提高采样效率、连接性能等。
5.2 特点
- 数据哈希分桶:按分桶键的哈希值分配到不同桶
- 固定桶数量:建表时指定桶数,不易修改
- 高效连接:相同分桶方式的表可高效连接(Map-side join)
- 高效采样:支持快速随机采样
5.3 创建语法示例
CREATE TABLE bucketed_table ( id INT, name STRING, age INT)CLUSTERED BY (id) INTO 4 BUCKETSROW FORMAT DELIMITEDFIELDS TERMINATED BY \',\';5.4 分桶原理
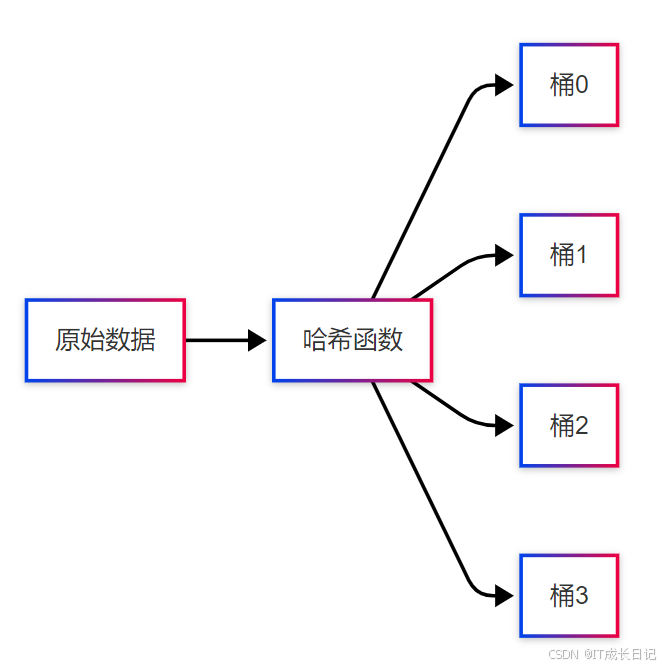
5.5 数据加载
- 分桶表需要先设置参数并强制分桶:
SET hive.enforce.bucketing = true;INSERT OVERWRITE TABLE bucketed_tableSELECT * FROM source_table;5.6 使用场景
- 大表连接优化(Map-side join)
- 需要高效随机采样的场景
- 数据倾斜优化
- 需要更细粒度数据组织的场景(可与分区结合)
5.7 注意事项
- 分桶键选择高基数、分布均匀的字段
- 桶数不宜过多或过少(与HDFS块大小协调)
- 数据加载必须通过INSERT方式
- 与分区表结合使用时效果更佳
6 表类型对比与组合使用
6.1 四种表类型对比
特性
内部表
外部表
分区表
分桶表
数据管理
Hive管理
外部管理
可组合
可组合
元数据管理
Hive管理
Hive管理
Hive管理
Hive管理
删除影响
数据删除
仅删元数据
依赖表类型
依赖表类型
存储组织
普通目录
普通目录
分区目录
桶文件
主要优势
简单易用
数据共享
查询性能
连接效率
典型场景
中间表
原始数据
事实表
大表连接
6.2 组合使用示例
-- 创建外部分区表CREATE EXTERNAL TABLE sales_ext ( order_id BIGINT, product_id BIGINT, amount DECIMAL)PARTITIONED BY (dt STRING, region STRING)STORED AS PARQUETLOCATION \'/data/warehouse/sales\';-- 创建内部分区分桶表CREATE TABLE sales_analytics ( order_id BIGINT, product_id BIGINT, amount DECIMAL, category STRING)PARTITIONED BY (dt STRING)CLUSTERED BY (product_id) INTO 32 BUCKETSSTORED AS ORC;6.3 组合使用场景
- 外部表+分区表:存储原始数据,按时间分区管理
- 内部表+分区+分桶:存储中间分析结果,优化查询性能
- 外部表+分区+分桶:大型生产环境的事实表存储
7 实践j建议与注意事项
7.1 表类型选择指南
- 优先考虑外部表:生产环境基础数据建议使用外部表,避免误删
- 合理使用分区:大数据量表必须考虑分区,但避免过度分区
- 慎用分桶表:只在特定场景(如大表连接)使用分桶表
- 内部表用于ETL中间结果:ETL过程中的临时表可使用内部表
7.2 性能优化建议
- 分区裁剪:确保查询条件包含分区字段
- 分桶优化连接:相同分桶字段和桶数的表连接更高效
- 存储格式选择:ORC/Parquet格式比文本格式性能更好
- 分区粒度平衡:分区不宜过粗或过细,考虑HDFS块大小
7.3 常见问题解决方案
小文件问题:
- 合并小文件:ALTER TABLE table_name CONCATENATE;
- 使用HAR归档
- 调整分区粒度
分区过多问题:
- 采用分层分区(如年/月/日)
- 使用分桶作为补充
元数据性能问题:
- 限制分区数量
- 定期清理不再使用的分区
8 总结
Hive提供了灵活多样的表类型以满足不同场景需求。理解内部表、外部表、分区表和分桶表的特点及区别,是高效使用Hive的基础。实际应用中,应根据数据生命周期、访问模式、性能需求等因素综合选择合适的表类型,并常常组合使用这些类型以达到最佳效果:
- 内部表简单但风险高,外部表安全适合生产
- 分区表是大数据处理的必备技术
- 分桶表是高级优化手段,特定场景使用
- 组合使用这些表类型可以发挥最大效益

