vLLM+Qwen3+OpenWebUI保姆级教程!搭建属于你的智能助手_openwebui 启动 huggingface 的模型
本地部署大模型,其实很简单:只需三步!
- 下载模型
- 选择推理引擎
- 启动服务
本期将手把手教你如何使用 vLLM 部署 Qwen3 模型,并结合 Open-WebUI 搭建一个本地可用、交互友好、功能强大的 AI 对话界面。
无论你是 AI 小白还是有一定基础的技术爱好者,都可以轻松上手,打造属于自己的本地大模型智能助手!
为什么选择 vLLM?
vLLM 是一个高效、易用的大型语言模型(LLM)推理与服务框架,最初由加州大学伯克利分校的 Sky 计算实验室 开发,现已成为由学术界与工业界共同维护的开源社区项目。
vLLM 的核心优势在于其卓越的性能和广泛的兼容性:
🚀 为什么 vLLM 推理速度如此出众?
- PagedAttention 技术:通过分页管理注意力机制中的键值缓存,极大提升了内存使用效率,有效降低延迟。
- 优化的 CUDA 内核:集成了 FlashAttention 和 FlashInfer 等高效计算技术,显著提升推理吞吐量。
- 高吞吐量解码算法:支持多种解码策略,如并行采样、束搜索(Beam Search)等,灵活适应不同场景。
🎯 为什么 vLLM 被广泛使用?
- 与 HuggingFace 模型无缝集成:无需额外转换,直接加载主流模型。
- 兼容 OpenAI API 接口:方便开发者快速迁移或集成已有项目。
- 支持 Prefix Caching(前缀缓存)与 Multi-LoRA:显著提升服务响应速度与多模型并发能力。
参考vllm官网
一、Huggingface下载模型
安装包Huggingface
pip install -U huggingface_hub添加环境变量,就不存在“需要科学”的问题
export HF_ENDPOINT=https://hf-mirror.com命令行下载
huggingface-cli download Qwen/Qwen3-32B --local-dir /NV/models_hf/Qwen/QwQ-32B/其中,--local-dir 是本地模型的存放路径
更多模型下载方式参考
地表最强SGLang部署本地Qwen3-32B大模型–实战教程
二、vLLM安装&启动
vLLM安装方式主要有两种:pip 安装 和 Docker 安装。
⚙️ 如何选择安装方式?
- pip 安装:适合已经配置好 PyTorch 环境、不想折腾 Docker 的用户。优点是本地部署更轻量、灵活。
- Docker 安装:适合环境管理复杂、想快速部署的用户。Docker 镜像通常已经集成好依赖库,开箱即用。
方式1:pip安装和部署
✅ 安装步骤:
- 确保你已安装好 PyTorch,并且版本与你的 CUDA 环境兼容。
- 使用 pip 安装 vLLM
有时候安装vLLM,会顺带安装了torch
pip install vllm启动本地模型服务
nohup vllm serve /NV/models_hf/Qwen/Qwen3-32B \\--tensor-parallel-size 4 \\--max-model-len 131072 \\--port 6001 \\--enforce-eager \\--uvicorn-log-level debug \\--gpu-memory-utilization 0.95 \\--served-model-name Qwen3-32B \\ 2>&1 &注意:路径
/NV/models_hf/Qwen/QwQ-32B/为你之前使用 HuggingFace CLI 下载并保存模型的本地路径。
✅ 参数总结表格
模型路径--tensor-parallel-size N--max-model-len N--port N--enforce-eager--uvicorn-log-leveldebug, info 等--gpu-memory-utilization0.8~0.95--served-model-name/v1/models 接口方式2:docker安装和部署
搜索合适的镜像,拉取vllm镜像。
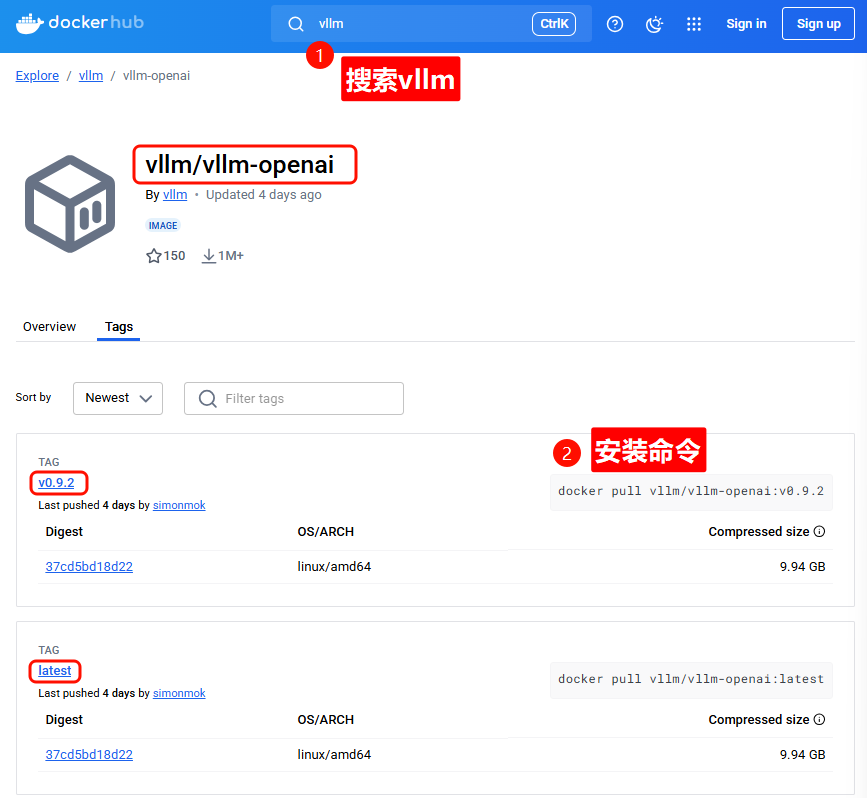
✅安装步骤:
- 访问 Docker Hub 官网:
打开 https://hub.docker.com/,搜索vLLM。 - 拉取合适的镜像:
根据你的硬件配置和需求,选择对应 CUDA 版本的镜像 - 启动容器并加载模型
docker run --gpus all -v /NV/models_hf/Qwen/Qwen3-32B/:/models/Qwen3-32B \\ -p 6001:8000 \\ vllm/vllm-openai:latest \\ --host 0.0.0.0 \\ --model /models/Qwen3-32B📌 参数说明:
-v:将本地模型挂载到容器内-p:将服务端口映射到主机--model:指定模型路径--gpus all:启用所有 GPU 资源(确保已安装 NVIDIA Docker 支持)
🧩 可能有的小伙伴有疑问:如何选择适合我 CUDA 版本的 vLLM 镜像?
这其实是一个很关键的步骤,因为如果选错了 CUDA 版本,可能导致模型无法运行或 GPU 无法识别。
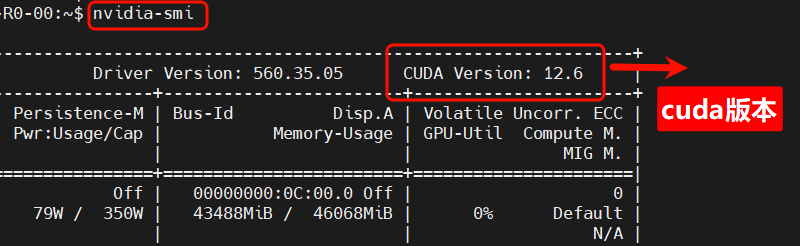
🔍 1.查看你的 CUDA 版本
在终端运行以下命令:
nvidia-smi在输出信息中,可以看到 CUDA Version,例如:CUDA Version: 12.6
🧮2.查找镜像版本与 CUDA 版本的对应关系
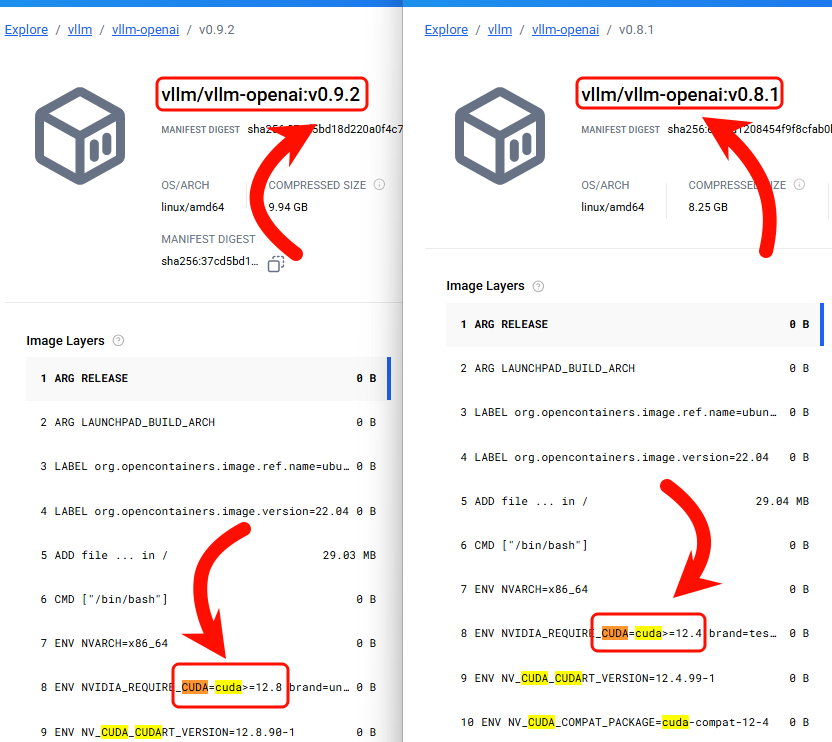
截图两个镜像信息中,可以看到,不同 TAG 对应的 CUDA 版本如下:
📌 注意:CUDA 版本是向后兼容的,但不能跨大版本运行。
✅ 3.选择正确的镜像版本
综上,本机应该选择 v0.8.2的vllm镜像,拉取命令应为
docker pull vllm/vllm-openai:v0.8.2拉取完成,docker images 可以看到vllm 版本为0.8.2的镜像。
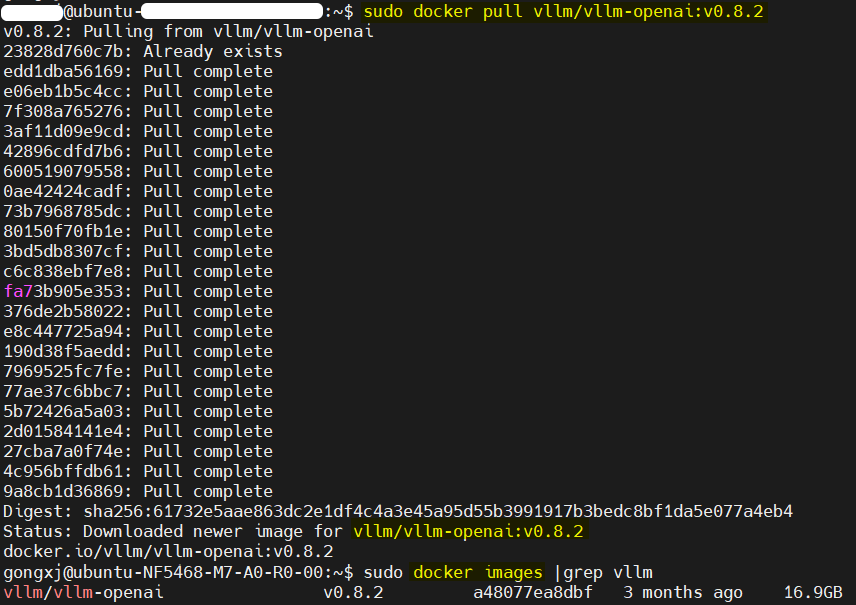
这样可以确保你的硬件与镜像中的预编译库版本一致,避免出现兼容性问题。
更多安装方式见 vLLM官方安装教程
三、部署 AI 对话界面:Open-WebUI
在成功部署 Qwen3 模型后,我们还需要一个可视化界面,方便自己或他人使用模型。
这时候,推荐使用 Open-WebUI,它是一个功能强大的开源 Web UI,支持 OpenAI API 风格的模型接入,界面简洁、功能丰富。
📍 Open-WebUI 官方资源
GitHub Open-WebUI:https://github.com/open-webui/open-webui
open-WebUI官方文档:https://docs.openwebui.com/getting-started/quick-start/
🧩 为什么选择 Open-WebUI?
在众多本地模型前端工具中,Open-WebUI 是目前功能最全、用户体验最好的选择之一。它具备以下特点:
- 🎨 美观的 UI 界面,接近 ChatGPT 的交互体验
- 🧠 支持多种模型后端(OpenAI API、Ollama、vLLM、Transformers 等)
- 🧑🤝🧑 支持多用户注册、权限管理
- 📦 可集成插件、知识库、聊天模板等高级功能
- ⚙️ 支持自定义模型配置、API 密钥管理、模型代理等
步骤 1:拉取 Open-WebUI镜像
首先从 GitHub Container Registry 中提取最新的 Open WebUI Docker 镜像。
如:
docker pull ghcr.io/open-webui/open-webui:main步骤 2:运行容器
在当前路径下创建open-webui文件夹,使用默认设置运行容器。
mkdir open-webuidocker run -d \\ --gpus all \\ -p 8080:8080 \\ -v $(pwd)/open-webui:/app/backend/data \\ --name open-webui \\ ghcr.io/open-webui/open-webui:main📌参数说明:
-d:表示在后台运行容器--gpus all:指定容器使用所有可用的 GPU 资源,一般用于多卡环境启用 GPU 支持-p 8080:8080:[端口映射] 将本机的 8080 端口映射到容器的 8080 端口,实现外部访问容器内服务。在本地机器的端口 8080 上公开 WebUI。-v ./data:/app/backend/data:[卷映射] 将本地open-webui路径挂载到容器的/app/backend/data路径,实现数据持久化,防止容器重启期间数据丢失。--name:为容器命名,便于管理
浏览器中输入网址
127.0.0.1:8080就能看到,妥妥的openai风格的对话界面。

注册登录之后,我们开始配置模型
步骤3. 配置本地模型
✅ 场景一:仅供自己使用
点击设置–编辑外部连接–设置本地大模型的URL,保存成功即可。
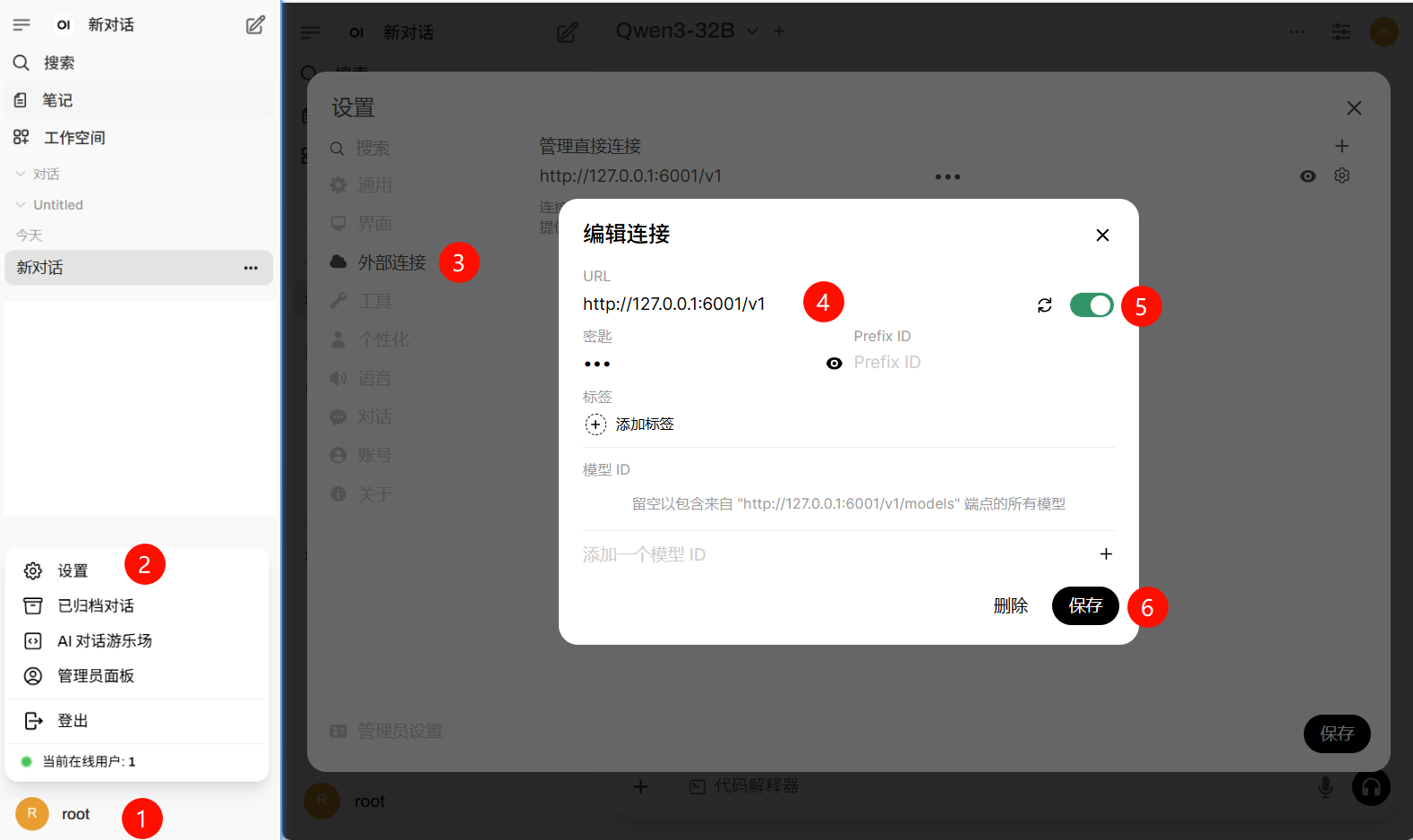
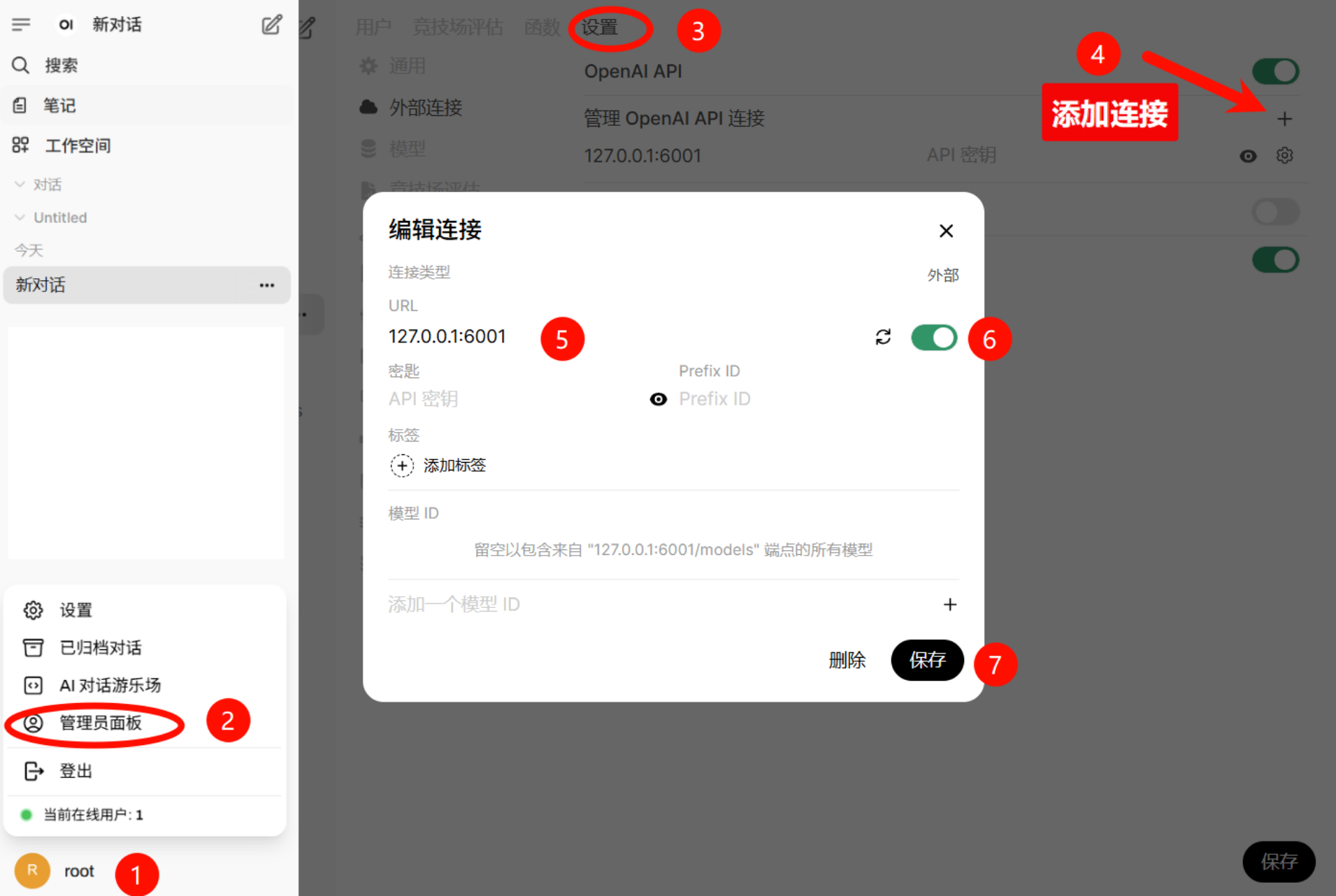
✅场景二:供其他用户使用
就像ChatGPT、Qwen那样式的,用户一注册就能看到可用模型,点击“管理员面板”–设置–添加连接,保存成功即可。
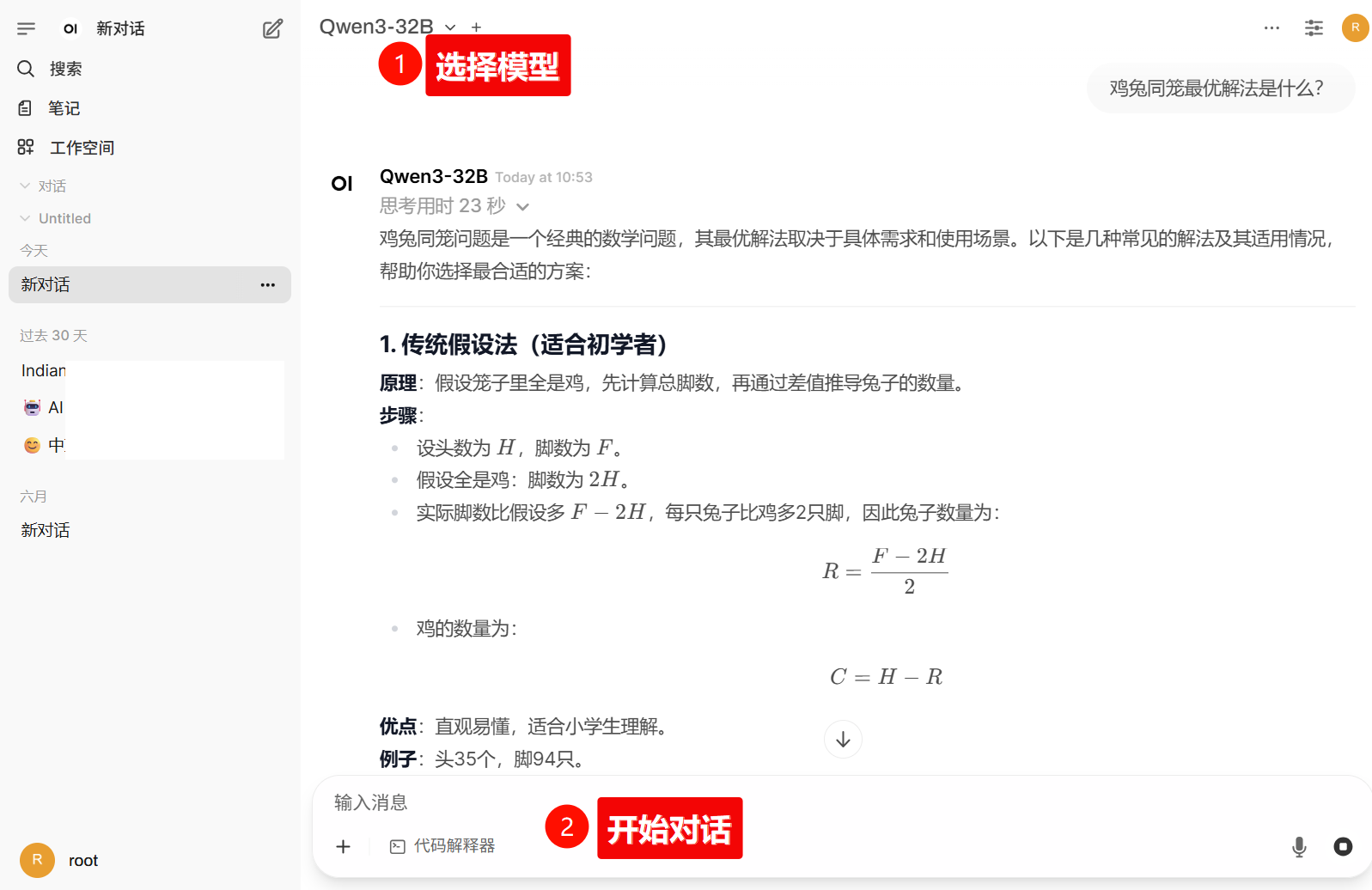
步骤4.开始对话
来到对话界面,选择可用模型后,就能与你的本地模型对话啦~🤡
open-webui的用户和权限管理也很实用

其他功能也非常丝滑~
推荐各位小伙伴试试👍
🚀小结:Open-WebUI 是本地模型部署的“最后一公里”
部署完模型服务后,Open-WebUI 提供了直观、美观、功能强大的前端,让本地模型真正“活”起来。无论是个人使用、团队协作,还是对外服务,它都能满足需求。
📢下集预告:主流推理引擎怎么选?
最近收到不少粉丝私信👇:
“我在 HuggingFace 拉取模型后,好像可以直接跑,为啥还要用 vLLM、SGLang 这些推理框架?”
“部署 Qwen3-32B 或 DeepSeek-8B 这样的大模型,到底该选 vLLM 还是 SGLang?区别在哪里?”
🤔其实,部署模型不只是“能跑就行”
选择不同的推理引擎,会直接影响你的模型速度、资源占用和使用体验!
蹲一个的小伙伴评论区举个手👋,我们下期见🔍~
实践出真知,与君共勉


