【c++】布隆过滤器、海量数据处理的应用
小编个人主页详情<—请点击
小编个人gitee代码仓库<—请点击
c++系列专栏<—请点击
倘若命中无此运,孤身亦可登昆仑,送给屏幕面前的读者朋友们和小编自己!

目录
-
- 前言
- 一、概念引入
- 二、布隆过滤器
-
- 概念介绍
- 布隆过滤器的应用
- 三、布隆过滤器的模拟实现
-
- 为什么布隆过滤器不轻易支持reset
- 铺垫
- set
- test
-
- 测试一
- 测试二
- 四、海量数据处理的应用
-
- 题目一
-
- 精确算法
- 近似算法
- 题目二
- 总结
前言
【c++】STL容器-位图、位图关于海量数据处理的应用——书接上文 详情请点击<——
本文由小编为大家介绍——【c++】布隆过滤器、布隆过滤器关于海量数据处理的应用
布隆过滤器的底层就是位图,本文与位图的关联性极大,所以再阅读学习本文前,读者友友可以点击上方蓝字链接学习位图的内容
一、概念引入
在学习下面文章前,读者友友需要先了解哈希地址,哈希函数以及字符串转整形算法,如BKDR算法等
小编也已经为大家准备好了,哈希地址在哈希概念中有讲,哈希函数在第二点的哈希冲突中小编有进行介绍,字符串转整形算法,小编在第三点闭散列铺垫的第四小点中有讲 详情请点击<——
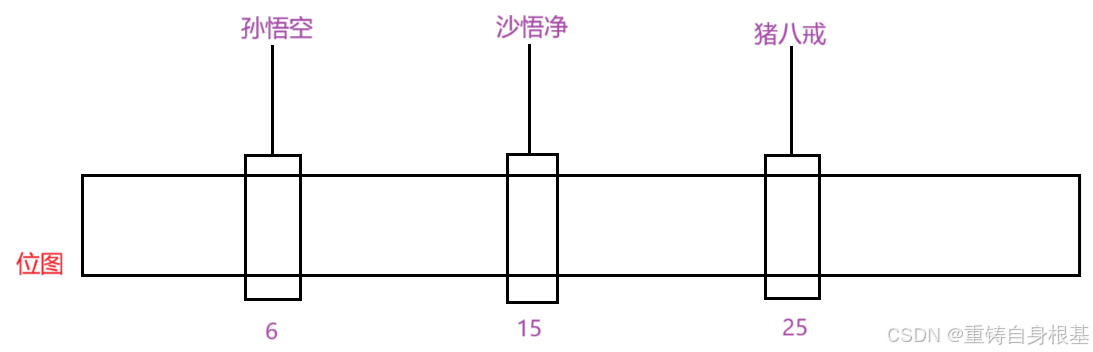
- 你有三个字符串孙悟空,沙悟净,猪八戒,要求是使用位图标记存在的状态,先使用字符串转整形算法,将字符串转化为整形,在利用哈希函数算出哈希地址,小编已经根据哈希地址将其标在位图中了
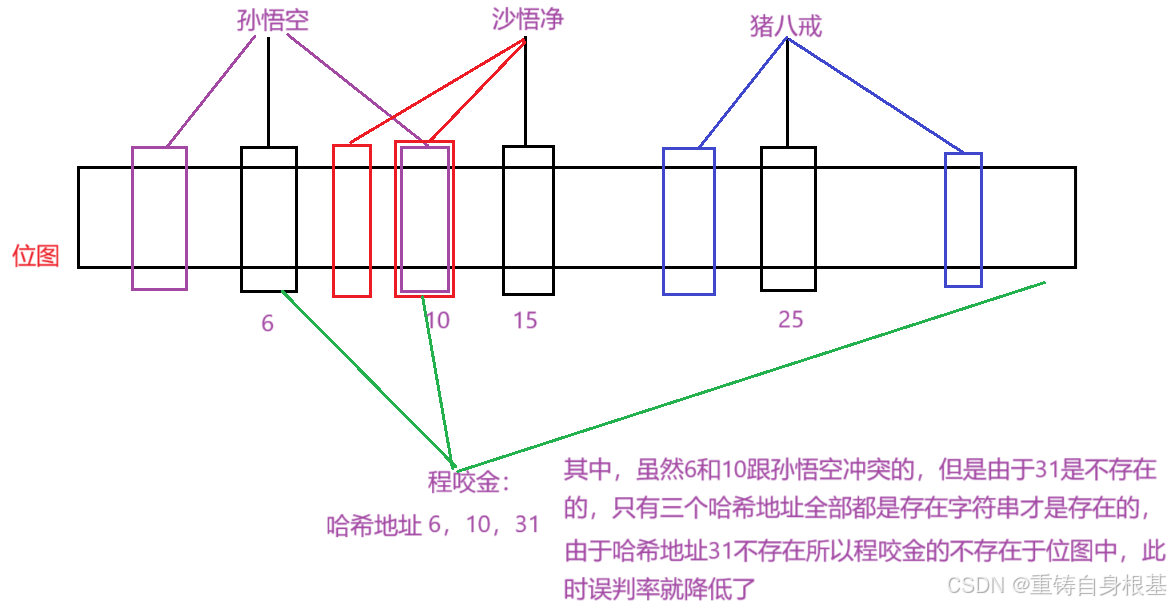
- 唐僧也来了,他想看一下自己是否在位图中,那么那么小编使用字符串转整形的算法将程咬金这个字符串转成整形之后,利用哈希函数算出哈希地址,算出的哈希地址为1,那么此时唐僧一定不存在于位图中,也就是说位图判断一个字符串是否不存在的结果是准确的
- 此时半路杀出个程咬金,他想看一下自己是否在位图中,那么小编使用字符串转整形的算法将程咬金这个字符串转成整形之后,利用哈希函数算出哈希地址,算出的哈希地址为6,使用位图的test进行检验,程咬金发现他自己在位图中,实际上在位图中并没有程咬金,那么这就存在了误判,也就是说位图判断一个字符串的存在是不准确的,也就是类似于哈希冲突,但是在哈希中我们可以使用哈希桶进行挂起,这里却不行,那么位图究竟可以表示字符串的状态吗?
- 其实位图只适用于表示不重复整数,对于这种字符串并不能进行状态表示
- 使用如果使用位图去表示字符串是否存在,则会存在误判,这个误判有二,一是使用字符串转整数算法计算出来的结果可能相同,二是使用哈希函数取模计算的时候的结果可能相同,并且这个误判也就类似于哈希冲突,使用好的哈希函数可以降低哈希冲突,但是不能消除哈希冲突,同样的有人就想既然误判不能消除,那我是否可以设计一个数据结构极大的降低误判率呢?于是布隆在1970年就提出了布隆过滤器
- 小编先讲一下做法,特定的使用三个针对字符串转整数的算法,算出三个关于字符串的整数,然后再分别使用相同的哈希函数计算出三个哈希地址,使用三个哈希地址标记一个字符串的状态,当且仅当三个哈希地址全部都为1的时候,字符串的状态才为存在,那么这样相对于使用一个字符串转整形的算法算出的一个哈希地址来讲,一个哈希地址容易冲突,这里算出的三个哈希地址就不那么容易冲突,这样一来误判率就被极大的降低了,但是当数据量足够大的时候,不可避免的仍然存在三个哈希地址都冲突的情况
- 此时我们回顾程咬金的情况,并且利用三个字符串转整数的算法,将字符串孙悟空,沙悟净,猪八戒分别转化三个成整数,再利用同一个哈希函数根据三个整数算出三个哈希地址,那么对应如图,同时程咬金也使用类似的操作,算出三个哈希地址进行验证他是否存在于位图中,验证如下,同时满足三个哈希地址都存在于位图的时候,字符串才存在,由于哈希地址31不存在,所以字符串程咬金不存在,那么误判率也就被降低了,但是误判不能被消除
二、布隆过滤器
概念介绍
布隆过滤器:布隆过滤器是由布隆在1970年提出的一种紧凑型的,比较巧妙的概念型数据结构,特点的高效的插入和查询,它可以用来告诉你“某种东西一定不存在或者可能存在”。它是利用多个哈希函数,将一个数据映射到位图结构中去,此方法提高查询的效率,同时也节约大量的内存空间
布隆过滤器的应用
- 布隆过滤器可以准确的判断一个数据不在,同时对于数据存在的情况判断存在一定的误判,所以对于一些场景,例如判断id是否注册过,准确的判断用户输入的id不存在,那么用户一定是可以进行注册id的,同时对于部分用户输入的id实际上不存在,但是误判为存在,那么也无伤大雅,因为反馈给用户这个id已经存在了,那么用户再去换一个id去注册不就好了
- 布隆过滤器,布隆过滤器,顾名思义,它具有过滤的作用,对于一些用户要求得到准确的在或者不在的场景,使用布隆过滤器过滤一定不存在的情况,例如对于一些数据库查询请求,数据是放到数据库中的,由于布隆过滤器的内存占用小,所以对于数据我们可以提前存放到布隆过滤器里面,当用户进行查询的时候,布隆过滤器过滤一定不存在的情况,直接反馈给用户,对于使用布隆过滤器判断存在的情况,由于布隆过滤器判断存在是存在误判的,所以并不能直接反馈给用户,要去数据库上进行查询这个数据是否存在,将数据库的准确查询结果反馈给用户,这样可以一定程度避免数据库拥堵,卡顿,因为对于一定不存在的情况使用布隆过滤器就可以判断出来反馈给用户,布隆过滤器的查询的时间复杂度是O(1)级别的,十分高效,那么此时数据库就只需要判断布隆过滤器判断为存在的不准确数据即可,这样就极大的降低了数据库的查询负载压力,提高了效率
三、布隆过滤器的模拟实现
为什么布隆过滤器不轻易支持reset
布隆过滤器小编会实现set和test,对于删除指定位置的接口reset小编并不会实现,读者友友可以先思考一下为什么?
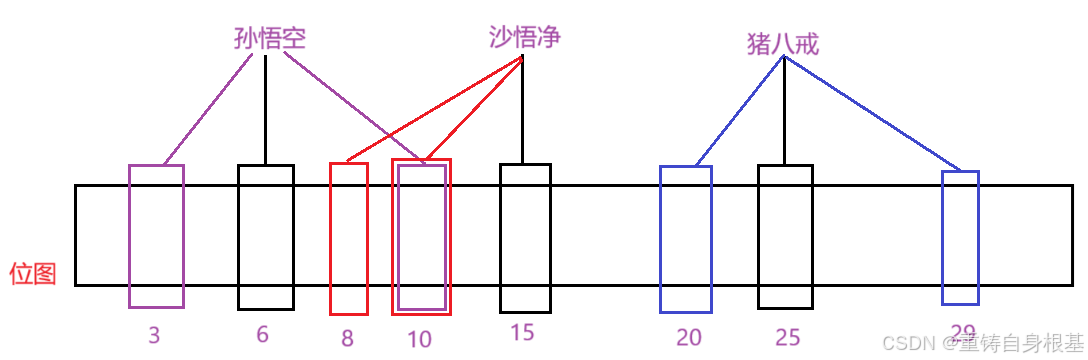
- 以上图为例,如果小编要支持reset,那么小编使用reset删除孙悟空,孙悟空的三个哈希地址是3,6,10,那么就会将3, 6, 10这三个哈希地址的状态由1置为了0,表示孙悟空不存在,那么请看沙悟净,沙悟净的哈希地址是8,10,15,此时沙悟净的查询就受到了影响,首先明确沙悟净使用布隆过滤器进行查询要求使用三个哈希函数计算出的哈希地址的状态都为1的时候沙悟净才存在,沙悟净的三个哈希地址是8, 10, 15,那么进行查询沙悟净,此时8,15都存在状态都为1,但是10因为孙悟空被reset删除将10的状态从1设置为了0,而孙悟空和沙悟净的10又是是共用的一个位图的一个比特位,所以此时查询沙悟净的哈希地址8和15的状态都为1,10的状态为0,此时不满足三个哈希地址对应的状态都存在都为1,所以查询沙悟净的结果是不存在,我们没有仅仅是对孙悟空进行reset删除,却将沙悟净也删除了,此时就祸及无辜了!
- 所以我们不敢轻易的支持reset删除数据,因为使用reset删除数据后,将删除的数据对应的三个哈希地址上的状态置为0之后,类似于上面的情况,可能影响其它数据,即将其它原本存在的数据也意外的删除了,因为其它数据的三个哈希地址可能会和删除数据的哈希地址共用一个位图的一个比特位,那么由于使用reset删除数据会将这三个哈希地址的状态表示从0表示为1,此时其它数据进行查询状态不满足使用哈希函数算出的三个哈希地址的状态为1,所以其它原本存在的数据就不在布隆过滤器了,reset删除数据后,意外影响造成原本存在的数据也被删除了,所以布隆过滤器不敢轻易的支持reset
- 所以对于布隆过滤器小编只会实现set和test,并不会实现reset
- 当然如果非要实现布隆过滤器的reset删除,可以采用多个位标识一个值采用引用计数的方式,那么进行reset就是将多个位上的数进行- -即可
铺垫
- 由于小编编写的布隆过滤器是特定的针对字符串的,对于哈希函数,我们仅需要使用三个字符串转整形的算法来替代即可,因为同一个字符串使用三个不同的字符串转整形算法算出的整形大多不相同,算出三个整形后使用同一个取模的哈希函数来计算出对应的哈希地址即可
- 那么如何去找三个字符串转整形的算法呢?小编在博客园找到了关于字符串哈希算法供大家参考 ,详情请点击<——文章引用自博客园-clq
- 在上面文章中评分最高的分别是BKDRHash算法,APHash算法,DJBHash算法,那么小编将会使用这三种算法通过模板类通过仿函数的形式作为实现布隆过滤器的字符串转整形算法
template<class T>struct BKDRHash{ size_t operator()(const T& str) { size_t hash = 0; for (auto ch : str) { hash = hash * 131 + ch; } return hash; }};template<class T>struct APHash{ size_t operator()(const T& str) { size_t hash = 0; for (size_t i = 0; i < str.size(); i++) { size_t ch = str[i]; if ((i & 1) == 0) { hash ^= ((hash << 7) ^ ch ^ (hash >> 3)); } else { hash ^= (~((hash << 11) ^ ch ^ (hash >> 5))); } } return hash; }};template<class T>struct DJBHash{ size_t operator()(const T& str) { size_t hash = 5381; for(auto ch : str) { hash += (hash << 5) + ch; } return hash; }};- 布隆过滤器的底层是对位图的封装,所以我们需要给布隆过滤器定义一个类型为位图bitset私有成员变量_bs,这个位图的小编采用的是STL库中的位图进行实现的,并且位图的实例化去开多少大小的比特位需要有非类型模板参数,所以我们也要给布隆过滤器的模板参数添加一个非类型模板参数,这里小编实现的布隆过滤器是针对字符串进行设计的,所以K的缺省值小编给了字符串,如果读者友友想要实现针对其它类型进行设计,那么可以显示传入其它类型,同时再传入可以针对其它类型的三个哈希函数即可
#pragma once#include #include using namespace std;template<size_t N, class K = string, class Hash1 = BKDRHash<K>, class Hash2 = APHash<K>, class Hash3 = DJBHash<K>>class bloomfilter{public:private:bitset<N> _bs;};set
- 布隆过滤器的set是将一个str字符串表示在位图中,通过三个哈希函数算出哈希地址,调用底层的位图_bs将算出的哈希地址设置为1存在
- 以Hash1为例解析一下这里的哈希函数,Hash1是模板参数,Hash1()是定义了匿名对象,匿名对象(str)是调用匿名对象的operator(),传入str,% N是由于匿名对象的operator()计算出的范围可能超过当前底层位图的范围,所以使用% N,将计算出的结果映射到位图中
- 那么就通过了三个哈希函数计算出了三个哈希地址,将这三个哈希地址调用底层位图_bs的set将其设置成1存在即可将字符串str使用三个哈希地址表示出来了
void Set(const string& str) { size_t hash1 = Hash1()(str) % N; _bs.set(hash1); size_t hash2 = Hash2()(str) % N; _bs.set(hash2); size_t hash3 = Hash3()(str) % N; _bs.set(hash3); }test
- test是检验字符串str是否存在于布隆过滤器中,也就是str通过哈希函数计算出的三个哈希地址是否在底层位图_bs中的状态都为1存在
- 这里我们逐个验证,依次验证三个哈希函数计算出来的哈希地址,从第一个哈希地址进行验证,如果第一个哈希地址使用底层位图的test进行验证后为false,那么就直接返回false,同理第二个和第三个哈希地址也是这样,当且仅当三个哈希地址都经过底层位图_bs验证后都是1存在,我们才返回true
- 思考一下为什么小编要这样编写,直接采用return _bs.test(hash1) && _bs.test(hash2) && _bs.test(hash3)的方式不行吗?
- 其实也是可以的,但是小编编写的第一种方式的话当多次调用布隆过滤器的test的时候,会在一定层度上减少计算量,提高效率,因为当第一个哈希地址使用底层位图_bs的test算出为假的时候那么就直接返回了,后面的第二个和第三个哈希地址就不用进行计算了,而采用_bs.test(hash1) && _bs.test(hash2) && _bs.test(hash3)第二种方式则必须将三个哈希地址都算出来,当第一个或第二个哈希地址假的时候就没有必要往后进行计算了直接返回为假即可,相对来讲小编编写第一种的代码的方式更优
bool Test(const string& str) { size_t hash1 = Hash1()(str) % N; if (_bs.test(hash1) == false) { return false; } size_t hash2 = Hash2()(str) % N; if (_bs.test(hash2) == false) { return false; } size_t hash3 = Hash3()(str) % N; if (_bs.test(hash3) == false) { return false; } return true; }测试一
- 使用如下代码测试布隆过滤器是否可以表示字符串
#include \"BloomFilter.h\"void TestBloomFilter1(){const size_t N = 3;bloomfilter<5 * N> bf;bf.Set(\"星期一\");bf.Set(\"星期三\");bf.Set(\"星期五\");cout << bf.Test(\"星期一\") << endl;cout << bf.Test(\"星期三\") << endl;cout << bf.Test(\"星期五\") << endl;cout << bf.Test(\"星期日\") << endl;}int main(){TestBloomFilter1();return 0;}运行结果如下,正确

测试二
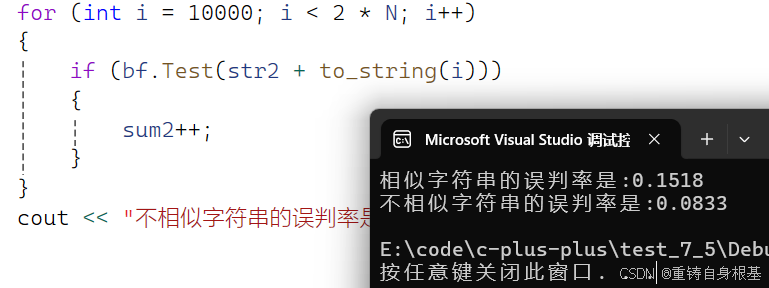
- 使用如下代码分别测试布隆过滤器对相似数据和不相似数据的误判率
- 通常来讲了布隆过滤器的存储空间m和实际字符串的个数n,通常是m是n的四倍,即空间要开字符串个数的四倍,通常来讲,空间越大,误判率越低,但是误判不能消除,一般我们使用布隆过滤器的就是为了节省空间,一味的扩大空间,使用布隆过滤器的意义就没有了,而且布隆过滤器判断数据存在会有误判,使用map/set进行判断是精确的,当空间足够的时候使用map/set难道不香吗?
- 测试逻辑,测试1万个数据,开4万个比特位的空间,首先小编使用字符串str1接收小编博客主页的网址,使用for循环循环0到9999,使用to_string将0到9999的整数转化成字符串,使用str1在for循环内加上0到9999生成的字符串,放入布隆过滤器中,那么此时布隆过滤器就有了1万个测试数据
- 那么接下来小编for循环从1万开始到2万结束,使用to_string将其转化成字符串添加在小编主页的字符串str1中,调用布隆过滤器的test进行检验是否存在,同时使用一个变量sum1记录,如果test的结果为真,那么就是误判,这时候我们对sum1加加即可
- 统计完成后,那么使用(double)sum1 / N计算相似数据的误判率进行打印即可
- 接下来测试不相似字符串的误判率,那么同样的方式,只不过不相似字符串的原始数据是使用str2接收的星期一,同样类似于相似字符串的套路进行测试即可
- 统计完成后,那么使用(double)sum2 / N计算不相似数据的误判率进行打印即可
- 注:小编的测试方法存在一定的局限性,例如测试不相似数据的数据,为了更准确实际应该随机爬取数据,这样不相似数据的样本才更有参考价值,小编的测试做法仅供参考
#include \"BloomFilter.h\"void TestBloomFilter2(){const size_t N = 10000;bloomfilter<N * 4> bf;string str1 = \"https://blog.csdn.net/2301_80751958?spm=1000.2115.3001.5343\";for (int i = 0; i < N; i++){bf.Set(str1 + to_string(i));}size_t sum1 = 0;for (int i = 10000; i < 2 * N; i++){if (bf.Test(str1 + to_string(i))){sum1++;}}cout << \"相似字符串的误判率是:\" << (double)sum1 / N << endl;size_t sum2 = 0;string str2 = \"星期一\";for (int i = 10000; i < 2 * N; i++){if (bf.Test(str2 + to_string(i))){sum2++;}}cout << \"不相似字符串的误判率是:\" << (double)sum2 / N << endl;}int main(){//TestBloomFilter1();TestBloomFilter2();return 0;}测试结果如下
四、海量数据处理的应用
题目一
题目:给两个文件,分别由100亿个query(查询)(类似于MySQL中的SQL语句,query查询语句是字符串,一个字符串的大小大约有30byte),我们只有1G内存,如何找出两个文件的交集?给出精确算法和近似算法
我们先看一下100亿个query有多大,query查询语句是字符串,一个字符串的大小大约有30byte,那么100亿个query大约就是3000亿byte,1G大约等于10亿字节byte,那么3000亿byte就是有300G
精确算法
-
我们先使用精确算法进行处理,精确算法不应该使用布隆过滤器,虽然布隆过滤器判断不存在是精确的,但是由于布隆过滤器判断数据的存在是误判的,所以使用布隆过滤器是不精确的,布隆过滤器应该是近似算法
-
那么精确算法就要使用set进行处理了,可是要使用set那么set中就要实际存储这个字符串进行处理,我们的一个文件足足有300G啊,两个文件就有600G,实际使用内存却只有1G
-
假设找两个数组的交集(交集不包括重复元素),那么要先将两个数组放到两个set中去,遍历一个set,从另一个set中找是否存在,如果存在,那么则是两个数组的交集之一,当set遍历完成之后,两个数组的交集便被找出来了,回归题目,这里采用的方式也和数组找交集类似,同样两个文件需要分别放到两个set中找交集,但是两个文件太大了,实际使用内存就只有1G,那么平均一个文件的set只能使用0.5G的内存,而一个文件有足足300G,所以我们应该将一个文件平均分成600份小文件,这样一份小文件的大小就是0.5G,满足我们的需求,但是读者友友请思考一个类似于这样平均分成600份的小文件虽然可行,但是效率如何?
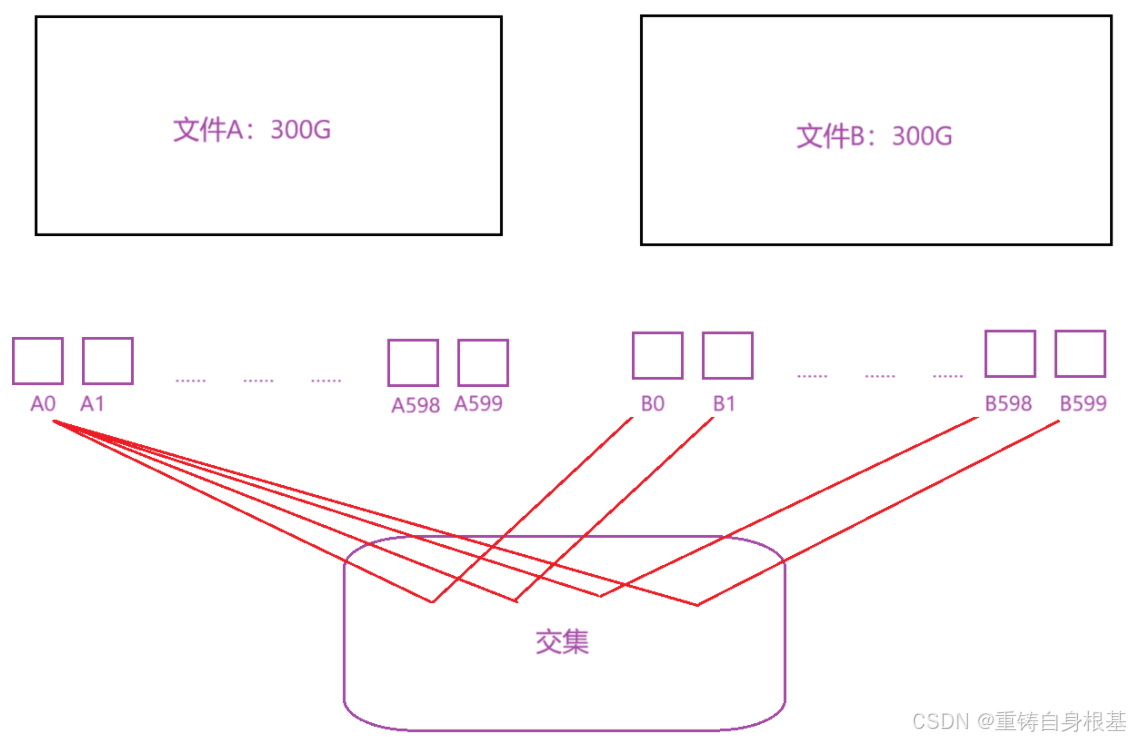
-
如上图,两个大文件分别为A文件和B文件,那么将文件A和文件B分别均分成600份,那么就转化成了使用A0依次与B文件的600个小文件依次放入set中找交集,接下来是A1,……,A598,A6599,这种方式是不是消耗太大了,效率低,读者友友可以思考一下有什么解决方法可以提高效率吗?
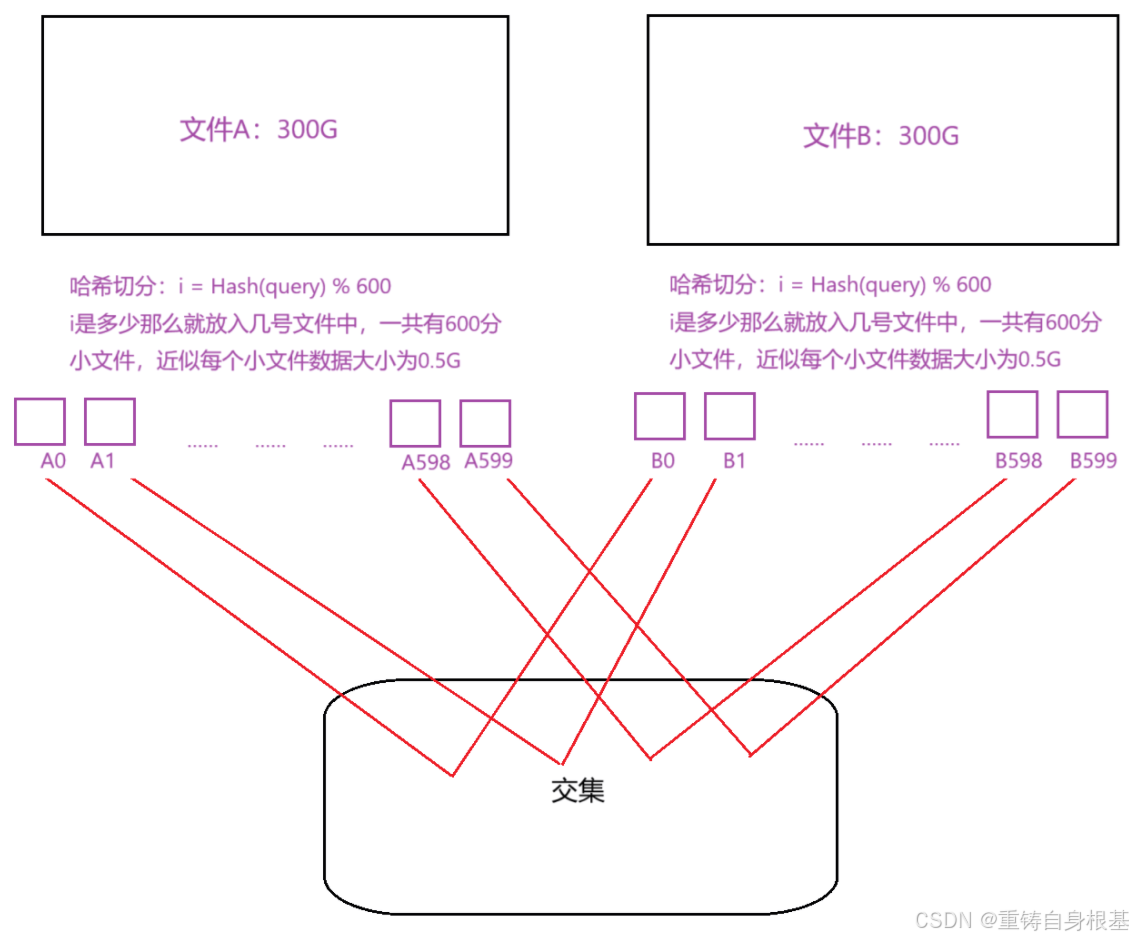
- 小编讲解一种方法,如上图,使用哈希切分(哈希切割)的方式进行分组,同样的将大文件分成600份小文件,但是分组方式采用哈希切分的方式进行分组,使用哈希函数算出哈希地址再取模小文件的分数600,那么这样就将数据近似分成了600小份,关键一点是在A文件和B文件中相同的query(字符串)使用了同一个哈希函数进行计算,那么就会分到同一个文件中,那么一个小文件中就有对应关系,A0小文件中相同元素就去B0中去找,不在需要去B1,……,B598,B599小文件中去找了,同样的A1小文件中的相同元素就去B1中去找,依次类推,直到A599去B599中去找,当所有的小文件对应找了一遍之后那么大文件A和B的所有的相同元素就被我们找出来了,是不是很圆满,可是实际上还有不足,读者友友可以思考一下哪里有不足?
- 实际上是内存不足,有没有可能出现一个小文件的占用内存很大,是完全有可能的,有两个场景,小文件占用内存都是5G
- 第一种情况:由于相同的元素经过哈希函数计算经过取模600后会被分入同一个小文件,但是如果极端情况下相同的元素十分多,相同元素累计足足有4G,并且还有1G的冲突元素
- 第二种情况:不同元素由于哈希函数计算后经过取模后产生了冲突,那么就会被分入一个小文件中,如果冲突过多,那么小文件的占用内存很大,假设冲突的数据十分多,足足有5G,那么针对上面的情况,我们应该如何处理呢?
- 我们可以巧妙利用c++的异常机制,先对小文件进行数据读取,读入到set中,当set抛异常,由于set具有去重的作用,所以相同元素不会插入到set中去,说明这种情况是情况二,那么我们使用另一种哈希函数并且进行取模接下来进行二次切分处理即可,如果是情况一,那么经过去重后冲突元素十分多占用内存有1G,此时由于set的空间只有0.5G,所以同样会转化成情况二进行二次切分处理即可
近似算法
- 近似算法是使用布隆过滤器进行处理,布隆过滤器可以标记字符串是否存在的状态,布隆过滤器判断不存在是精确的,但是由于布隆过滤器判断数据的存在是误判的,所以使用布隆过滤器是不精确的
- 同样采用精确算法进行处理即可,只不过是将set换成布隆过滤器进行标记即可
题目二
题目:给一个超过100G大小的log file,log存着IP地址,如何设计算法找到出现次数最多的IP地址?(IP地址的本质底层存储是整形,在形式上表示为字符串,如果使用字符串进行表示,那么计算机在处理前会先将其解析为整数形式,所以小编会使用字符串进行存储IP地址)
同样的条件和上面一样,如何设计算法找到出现次数最多的K个IP地址
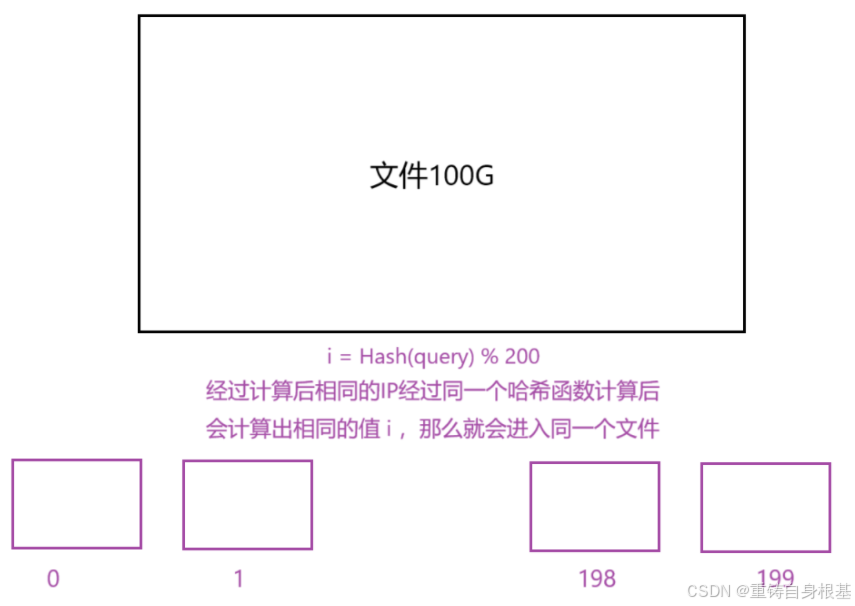
- 如何设计算法找到出现次数最多的IP地址?如上图,同样使用哈希切分,将100G的文件切分成200份小文件,近似一个小文件大小约0.5G,使用map统计小文件中相同IP的次数,map中的key是IP类型为字符串,value是int即IP出现的次数,同时维护两个变量一个是出现最多的次数count类型是int,一个是出现次数最多对应的字符串str类型是string,同样的这里也会出现一个小文件的占用内存太大,这时候使用类似于题目一中的精确算法中的set使用抛异常加进行二次切分即可,当每次将小文件的数据ip依次放入map中后,看一下放入数据ip后map中的ip对应的出现次数是否大于维护的变量count,如果大于那么更新count为ip对应map中的次数,同时更新str为ip即可,当遍历完成所有小文件后,那么str就为出现次数最多的IP地址
- 如何设计算法找到出现次数最多的K个IP地址,其实关于就是一个关于设计算法找到出现次数最多的IP地址变形加入的TopK问题,要维护的只不过这里需要变一下,使用一个堆,优先级队列,统计出现次数最多的,那么就应该开小堆,优先级队列默认是大堆,同时堆的中存储的类型是pair,int是次数,string是IP地址,由于我们存储的类型是一个pair,需要取出pair中的int进行比较,所以我们还应该给优先级队列提供一个仿函数用于取出pair中的int即IP地址出现的次数进行比较,调整为小堆,接下来遍历小文件使用map统计IP出现的次数,map统计完成一个小文件后,遍历map,依次将次数和IP字符串和堆顶的pair中的int进行比较,如果大于堆顶元素,那么进堆,否则不进堆
- 当所有的小文件使用map遍历并且进堆之后,此时堆中的pair,即堆中的存储的pair中的second就为我们想要的出现次数最多的K个IP地址
总结
以上就是今天的博客内容啦,希望对读者朋友们有帮助
水滴石穿,坚持就是胜利,读者朋友们可以点个关注
点赞收藏加关注,找到小编不迷路!

