【python】爬虫基础练
目录
爬istudy
爬chinadaily
爬古诗
流程讲解以及代码构建
2. get_poem_data 函数
3. get_poem_links_by_type 函数
4. get_data 函数
5. save_data 函数
6. analyze_data 函数
7. visualize_data 函数
主程序逻辑
运行效果
完整代码
前言 在 AI 时代,爬虫作为数据获取的核心工具,其作用愈发关键 —— 它能从海量网页、API 接口或垂直平台中高效抓取结构化与非结构化数据(如文本、图像、音频等),为 AI 模型训练提供 “燃料”,比如为大语言模型收集语料、为计算机视觉任务积累图像样本,或是为推荐系统抓取用户行为数据以优化算法。同时,爬虫也助力企业进行市场分析、竞品监控等,通过实时数据更新让 AI 应用更贴合实际需求。入门爬虫的技术栈可从基础工具着手:编程语言首选 Python,搭配 Requests 库发起 HTTP 请求,Beautiful Soup 或 lxml 解析 HTML;若需处理动态网页(如 JavaScript 渲染内容),则需掌握 Selenium 或 Playwright 进行自动化操作;对于大规模数据抓取,可学习 Scrapy 框架实现高效爬虫管理,再辅以正则表达式处理文本匹配,最后了解 robots 协议和反爬机制(如 IP 代理、User - Agent 伪装),确保爬虫合规且稳定运行。
pip install requests bs4
爬istudy
import requestsfrom bs4 import BeautifulSoupimport timeimport randomimport csvfrom typing import List, Dictimport os# 配置常量BASE_URL = \"https://istudy.szpu.edu.cn/portal/schoolCourseInfo/columnCourse?columnId=1&pageNum=1\"HEADERS = { \'User-Agent\': \'Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1 Edg/134.0.0.0\'}DELAY_RANGE = (2, 5) # 随机延时范围def get_html(page_num: int) -> str: \"\"\" 获取指定页码的HTML内容 :param page_num: 页码 :return: HTML字符串 \"\"\" params = { \'columnId\': 1, \'pageNum\': page_num } try: response = requests.get(BASE_URL, params=params, headers=HEADERS, timeout=10) response.raise_for_status() return response.text except requests.exceptions.RequestException as e: print(f\"请求失败: {e}\") return \"\"def parse_courses(html: str) -> List[Dict]: \"\"\" 解析课程信息 :param html: 网页HTML内容 :return: 课程数据列表 \"\"\" soup = BeautifulSoup(html, \'html.parser\') course_list = [] # 定位课程容器(根据实际网页结构调整选择器) course_blocks = soup.select(\'div.course-item\') # 示例选择器 for block in course_blocks: # 课程名称 name_elem = block.select_one(\'h3.course-title\') course_name = name_elem.text.strip() if name_elem else \"N/A\" # 教师团队 teacher_elem = block.select(\'div.teacher-list span\') teachers = \', \'.join([t.text.strip() for t in teacher_elem]) if teacher_elem else \"N/A\" # 图片链接 img_elem = block.select_one(\'img.course-cover\') img_url = img_elem[\'src\'] if img_elem and img_elem.has_attr(\'src\') else \"N/A\" course_list.append({ \'course_name\': course_name, \'teachers\': teachers, \'image_url\': img_url }) return course_list# def save_to_csv(data: List[Dict], filename: str = \'courses.csv\') -> None:# \"\"\"# 保存数据到CSV文件# :param data: 课程数据列表# :param filename: 输出文件名# \"\"\"# with open(filename, \'w\', newline=\'\', encoding=\'utf-8-sig\') as f:# writer = csv.DictWriter(f, fieldnames=[\'course_name\', \'teachers\', \'image_url\'])# writer.writeheader()# writer.writerows(data)def save_to_csv(data: List[Dict], filename: str = \'courses.csv\') -> None: \"\"\" 保存数据到CSV文件 :param data: 课程数据列表 :param filename: 输出文件名 \"\"\" # 指定保存路径 save_directory = r\'D:\\paistudy\' # 如果目录不存在,则创建 if not os.path.exists(save_directory): os.makedirs(save_directory) # 拼接完整文件路径 file_path = os.path.join(save_directory, filename) # 写入CSV文件 with open(file_path, \'w\', newline=\'\', encoding=\'utf-8-sig\') as f: writer = csv.DictWriter(f, fieldnames=[\'course_name\', \'teachers\', \'image_url\']) writer.writeheader() writer.writerows(data)def main(): all_courses = [] # 抓取2-3页数据 for page in range(1, 4): print(f\"正在抓取第{page}页...\") html = get_html(page) if html: courses = parse_courses(html) all_courses.extend(courses) print(f\"已获取{len(courses)}条课程数据\") else: print(f\"第{page}页抓取失败\") # 设置随机延时 time.sleep(random.uniform(*DELAY_RANGE)) # 保存数据 if all_courses: save_to_csv(all_courses) print(f\"共保存{len(all_courses)}条数据到courses.csv\") else: print(\"未获取到有效数据\")if __name__ == \"__main__\": main()爬chinadaily
先用解析网页的html结构,确定要抓取的对象在什么标签里
# 首先
next_page_element = soup.select_one(\'.next-page\') # 修改选择器以匹配“下一页”按钮
我在爬取下来的html中ctrl+f‘.next-page‘没有匹配结果
# 其次
网页的html最后几行为:
|<< 上一页
基于这些信息,有没有找到为什么往前爬的原因?
问题出在分页链接的解析上。当前代码逻辑试图通过 .next-page 选择器找到“下一页”链接,但在实际HTML中并没有匹配的结果。相反,HTML中使用的是 .pagestyle 类来标记分页链接。
问题分析
选择器不匹配:
当前代码使用 .next-page 作为选择器,但在HTML中并没有这样的类。
实际HTML中使用的是 .pagestyle 类来标记分页链接
分页逻辑问题:
HTML中显示的分页链接是“上一页”和具体页码的链接,而不是明确的“下一页”链接。
需要重新调整逻辑,找到正确的“下一页”链接
解决方法
我们需要重新调整分页链接的解析逻辑,确保能够正确找到“下一页”链接
从HTML中可以看到,分页链接使用的是 .pagestyle 类,但并没有明确的“下一页”链接。我们需要找到一种方法来动态获取“下一页”链接
动态解析分页链接
我们可以根据当前页的页码动态生成“下一页”的链接。例如,如果当前页是 page_39.html,那么下一页应该是 page_40.html
爬古诗
唐诗作为中国古典文学的巅峰之作,现存五万余首诗歌蕴含着丰富的历史文化信息。传统的人工整理方式效率低下,难以应对大规模文本分析需求。本项目通过构建自动化爬虫系统,实现对古诗数据的高效采集与多维度分析,为文学研究、文化传播提供数据支持。
系统目标
数据采集:实现五言绝句、七言绝句等典型诗体的全量爬取
信息结构化:建立包含诗歌标题、作者、朝代、正文、创作背景的标准化数据集
文本分析:揭示唐诗创作规律,挖掘高频词汇与作者分布特征
可视化呈现:通过词云图等形式直观展示统计结果
技术方案
网络爬虫:使用 requests 库实现 HTTP 请求
通过 BeautifulSoup 进行 HTML 解析
内置重试机制与延迟策略提升鲁棒性
数据处理:pandas 完成数据清洗与结构化存储
Counter 实现字符频率统计
可视化分析:matplotlib 进行基础图表绘制
wordcloud 生成词云可视化
古诗网址:https://so.gushiwen.cn/gushi/tangshi.aspx
流程讲解以及代码构建
- get_html 函数
def get_html(url, params=None, timeout=3): \"\"\" 发送 HTTP 请求获取网页内容 :param url: 请求的 URL :param params: 请求参数 :param timeout: 超时时间 :return: 网页内容,如果出错则返回 None \"\"\" print(f\"正在抓取: {url}, params = {params}\") # 设置重试次数 requests.DEFAULT_RETRIES = 3 # 增加重试次数,提高成功率 headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0\' } try: response = requests.get(url, params=params, headers=headers, timeout=timeout) # 检查请求是否成功 response.raise_for_status() # 自动检测编码 response.encoding = chardet.detect(response.content)[\'encoding\'] return response.text except Exception as e: print(f\"请求出错: {e}\") return None finally: # 延迟避免频繁请求 time.sleep(3)作用和逻辑
- 此函数的作用是发送 HTTP 请求并获取网页内容
- 首先打印出正在抓取的 URL 和参数信息
- 设置请求的重试次数为 3 次,以提高请求的成功率
- 构造请求头,模拟浏览器的 User-Agent,避免被网站识别为爬虫而拒绝请求
- 使用 requests.get 方法发送请求,设置了超时时间
- 通过 response.raise_for_status() 检查请求是否成功,如果请求失败会抛出异常
- 使用 chardet 库自动检测网页内容的编码,并设置 response 的编码
- 如果请求过程中出现异常,打印错误信息并返回 None
- 最后使用 time.sleep(3) 进行延迟,避免对目标网站造成频繁请求
扩展应用
- 可以添加更多的请求头信息,如 Referer 等,以更好地模拟浏览器行为
- 可以根据不同的错误类型进行不同的处理,例如当遇到 404 错误时可以记录该 URL 等
2. get_poem_data 函数
def get_poem_data(poem_html, poem_id): \"\"\" 从诗歌页面的 HTML 中提取诗歌信息 :param poem_html: 诗歌页面的 HTML 内容 :param poem_id: 诗歌的 ID :return: 诗歌标题、作者、朝代、内容、创作背景 \"\"\" poem_bs = BeautifulSoup(poem_html, \'lxml\') # 提取标题 title_tag = poem_bs.select_one(f\'#zhengwen{poem_id} > h1\') title = title_tag.text.strip() if title_tag else \'\' # 提取作者 author_tag = poem_bs.select_one(f\'#zhengwen{poem_id} > p.source > a\') author = author_tag.text.strip() if author_tag else \'\' # 提取朝代 dynasty_tag = poem_bs.select_one(f\'#zhengwen{poem_id} > p.source > a:nth-child(2)\') dynasty = dynasty_tag.text.strip() if dynasty_tag else \'\' # 提取诗歌内容 content_tag = poem_bs.select_one(f\'#zhengwen{poem_id} > div.contson\') content = content_tag.text.strip() if content_tag else \'\' # 提取创作背景 background = \"\" # 查找所有可能包含创作背景的元素 background_divs = poem_bs.select(\'div.contyishang\') for div in background_divs: # 查找标题中包含\"创作背景\"的元素 title_element = div.select_one(\'p.title, div > h2\') if title_element and \'创作背景\' in title_element.text: # 获取内容 - 可能在p标签或div.contson中 content_elements = div.select(\'p:not(.title), div.contson\') if content_elements: # 合并所有内容元素 background = \' \'.join([el.text.strip() for el in content_elements]) break return title, author, dynasty, content, background作用和逻辑
- 该函数用于从诗歌页面的 HTML 内容中提取诗歌的相关信息
- 使用 BeautifulSoup 库将 HTML 内容解析为可操作的对象
- 通过 CSS 选择器分别提取诗歌的标题、作者、朝代、内容和创作背景
- 对于创作背景的提取,先查找所有可能包含创作背景的 div 元素,然后在这些元素中查找标题包含 “创作背景” 的元素,最后提取其内容
扩展应用
- 可以提取更多的诗歌相关信息,如诗歌的赏析、注释等
- 可以对提取的内容进行进一步的清洗和处理,比如去除多余的空格、换行符等
3. get_poem_links_by_type 函数
def get_poem_links_by_type(html, poem_type): \"\"\" 从唐诗主页的 HTML 中提取特定类型诗歌的链接 :param html: 唐诗主页的 HTML 内容 :param poem_type: 诗歌类型,如\"五言绝句\"或\"七言绝句\" :return: 诗歌链接列表 \"\"\" bs = BeautifulSoup(html, \'lxml\') poem_links = [] # 根据提供的HTML结构调整选择器 type_divs = bs.select(\'div.typecont\') for div in type_divs: # 查找类型标题 title_tag = div.select_one(\'div.bookMl > strong\') if title_tag and poem_type in title_tag.text: # 找到对应类型的诗歌链接 links = div.select(\'span > a\') poem_links.extend(links) return poem_links作用和逻辑
- 此函数用于从唐诗主页的 HTML 内容中提取特定类型诗歌的链接
- 使用 BeautifulSoup 库解析 HTML 内容
- 首先查找所有包含诗歌类型的 div 元素,然后在每个 div 元素中查找类型标题
- 如果类型标题中包含指定的诗歌类型,则提取该 div 元素下的所有诗歌链接
扩展应用
- 可以支持提取多种诗歌类型的链接,而不仅仅是一种
- 可以对提取的链接进行去重处理,避免重复爬取
4. get_data 函数
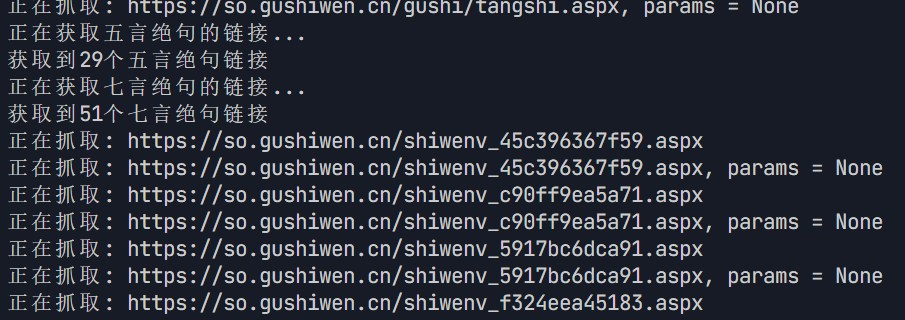
def get_data(html, base_url): \"\"\" 从唐诗主页的 HTML 中提取诗歌链接,并获取每首诗歌的信息 :param html: 唐诗主页的 HTML 内容 :param base_url: 基础 URL :return: 包含所有诗歌信息的列表 \"\"\" # 获取五言绝句和七言绝句的链接 poem_types = [\"五言绝句\", \"七言绝句\"] all_poem_links = [] for poem_type in poem_types: print(f\"正在获取{poem_type}的链接...\") links = get_poem_links_by_type(html, poem_type) all_poem_links.extend(links) print(f\"获取到{len(links)}个{poem_type}链接\") data = [] for link in all_poem_links: poem_url = urljoin(base_url, link.get(\'href\')) print(f\"正在抓取: {poem_url}\") # 获取诗歌页面的 HTML poem_html = get_html(poem_url) if poem_html: # 提取诗歌 ID poem_id = poem_url.split(\'_\')[-1].split(\'.\')[0] # 提取诗歌信息 poem_data = get_poem_data(poem_html, poem_id) data.append(poem_data) return data作用和逻辑
- 该函数用于从唐诗主页的 HTML 内容中提取五言绝句和七言绝句的链接,并获取每首诗歌的详细信息
- 定义了要提取的诗歌类型列表 poem_types
- 遍历诗歌类型列表,调用 get_poem_links_by_type 函数获取每种类型诗歌的链接,并将其添加到 all_poem_links 列表中
- 遍历 all_poem_links 列表,使用 urljoin 函数将相对链接转换为绝对链接
- 调用 get_html 函数获取诗歌页面的 HTML 内容
- 如果获取到 HTML 内容,则提取诗歌 ID,并调用 get_poem_data 函数提取诗歌的详细信息,将其添加到 data 列表中
扩展应用
- 可以支持提取更多类型的诗歌,只需修改 poem_types 列表即可
- 可以添加多线程或异步编程来提高爬取效率
5. save_data 函数
def save_data(data, file_name): \"\"\" 将诗歌信息保存到 CSV 文件中 :param data: 包含诗歌信息的列表 :param file_name: 保存的 CSV 文件名 \"\"\" df = pd.DataFrame(data, columns=[\'古诗\', \'作者\', \'朝代\', \'内容\', \'创作背景\']) if not os.path.exists(file_name): # 如果文件不存在,创建并写入表头 df.to_csv(file_name, encoding=\'utf-8-sig\', header=True, index=False) else: # 如果文件存在,追加数据不写表头 df.to_csv(file_name, encoding=\'utf-8-sig\', header=False, index=False, mode=\'a\') return df作用和逻辑
- 此函数用于将包含诗歌信息的列表保存到 CSV 文件中
- 使用 pandas 库将数据转换为 DataFrame 对象
- 检查文件是否存在,如果文件不存在,则创建文件并写入表头;如果文件存在,则追加数据,不写入表头
扩展应用
- 可以支持保存到其他格式的文件,如 Excel、JSON 等
- 可以对数据进行进一步的处理,如数据清洗、数据转换等,再保存到文件中
6. analyze_data 函数
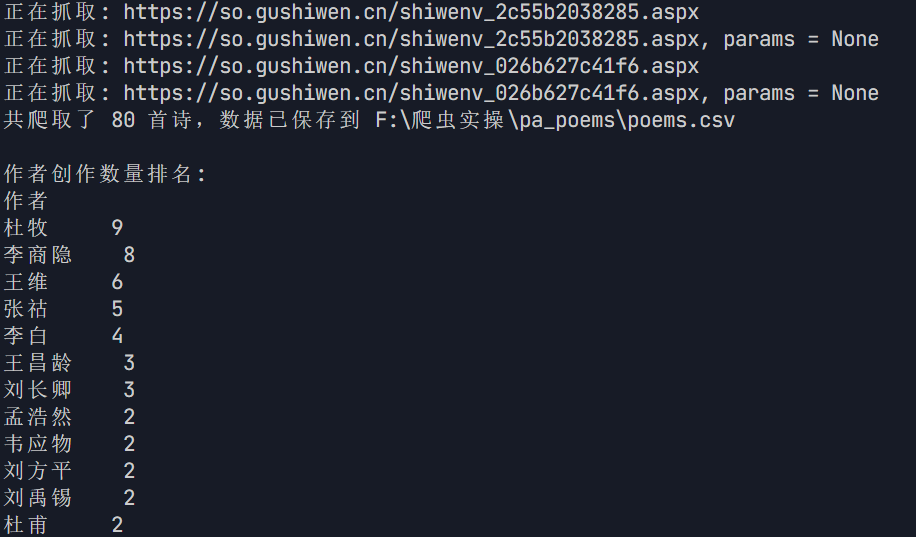
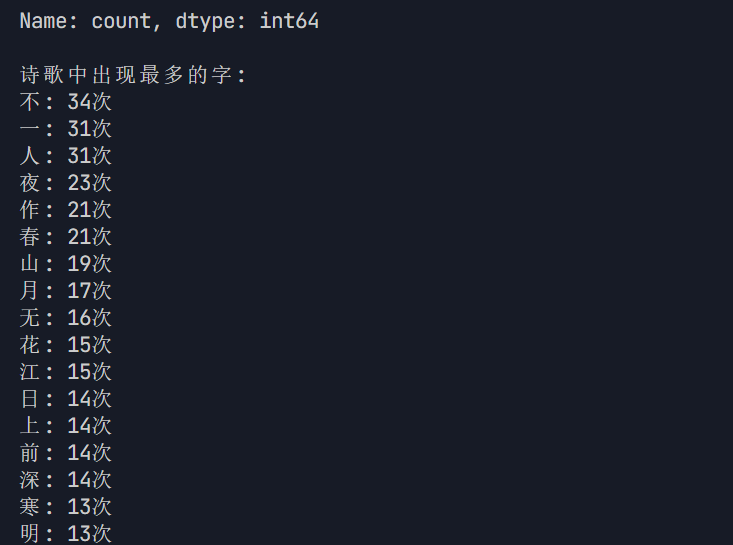
def analyze_data(df): \"\"\" 对诗歌数据进行统计分析 :param df: 包含诗歌数据的DataFrame \"\"\" # 统计作者创作数量 author_counts = df[\'作者\'].value_counts() print(\"\\n作者创作数量排名:\") print(author_counts) # 统计诗歌中出现最多的字 all_content = \'\'.join(df[\'内容\'].tolist()) # 去除标点符号和空白字符 all_content = re.sub(r\'[^\\u4e00-\\u9fa5]\', \'\', all_content) char_counts = Counter(all_content) print(\"\\n诗歌中出现最多的字:\") for char, count in char_counts.most_common(): print(f\"{char}: {count}次\") return author_counts, char_counts作用和逻辑
- 该函数用于对诗歌数据进行统计分析
- 使用 value_counts 方法统计每个作者的创作数量,并打印出作者创作数量排名
- 将所有诗歌的内容合并为一个字符串,使用正则表达式去除标点符号和空白字符
- 使用 Counter 类统计每个字符的出现次数,并打印出出现最多的字
扩展应用
- 可以进行更多的统计分析,如统计不同朝代的诗歌数量、不同类型诗歌的数量等
- 可以对统计结果进行进一步的处理,如筛选出出现次数超过一定阈值的字符等
7. visualize_data 函数
def visualize_data(author_counts, char_counts): \"\"\" 可视化诗歌数据 :param author_counts: 作者创作数量统计 :param char_counts: 字符出现频率统计 \"\"\" # 设置中文字体 plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 用来正常显示中文标签 plt.rcParams[\'axes.unicode_minus\'] = False # 用来正常显示负号 # 作者词云图 plt.figure(figsize=(10, 8)) # 将作者数据转换为词云所需的格式 author_dict = author_counts.to_dict() # 创建词云对象 author_wordcloud = WordCloud( font_path=\'simhei.ttf\', # 使用黑体字体,确保能显示中文 width=800, height=600, background_color=\'white\', max_words=100, max_font_size=200, random_state=42 ).generate_from_frequencies(author_dict) # 显示词云图 plt.imshow(author_wordcloud, interpolation=\'bilinear\') plt.axis(\'off\') plt.title(\'唐诗作者创作数量词云图\') plt.tight_layout() plt.savefig(\'F:\\\\爬虫实操\\\\pa_poems\\\\author_wordcloud.png\') # 字符词云图 plt.figure(figsize=(10, 8)) # 创建词云对象 char_wordcloud = WordCloud( font_path=\'simhei.ttf\', # 使用黑体字体,确保能显示中文 width=800, height=600, background_color=\'white\', max_words=100, max_font_size=200, random_state=42 ).generate_from_frequencies(char_counts) # 显示词云图 plt.imshow(char_wordcloud, interpolation=\'bilinear\') plt.axis(\'off\') plt.title(\'唐诗中字符出现频率词云图\') plt.tight_layout() plt.savefig(\'F:\\\\爬虫实操\\\\pa_poems\\\\char_wordcloud.png\') print(\"\\n统计图表已保存到 F:\\\\爬虫实操\\\\pa_poems\\\\author_wordcloud.png、F:\\\\爬虫实操\\\\pa_poems\\\\char_wordcloud.png\") print(\"F:\\\\爬虫实操\\\\pa_poems\\\\author_wordcloud.png 和 F:\\\\爬虫实操\\\\pa_poems\\\\char_wordcloud.png\")作用和逻辑
- 此函数用于可视化诗歌数据,主要是生成作者创作数量和字符出现频率的词云图
- 设置中文字体,确保中文标签能正常显示
- 创建作者创作数量的词云图,将作者数据转换为词云所需的字典格式,使用 WordCloud 类生成词云对象,并显示和保存词云图
- 同样的方法创建字符出现频率的词云图,并显示和保存
扩展应用
- 可以使用其他可视化工具,如 seaborn 库绘制更美观的图表
- 可以生成更多类型的可视化图表,如柱状图、饼图等,以展示不同的统计信息
主程序逻辑
if __name__ == \'__main__\': # 唐诗主页的 URL url = \'https://so.gushiwen.cn/gushi/tangshi.aspx\' # 获取唐诗主页的 HTML html = get_html(url) if html: # 提取诗歌信息 data = get_data(html, url) # 保存诗歌信息到 CSV 文件 df = save_data(data, \'F:\\\\爬虫实操\\\\pa_poems\\\\poems.csv\') print(f\"共爬取了 {len(data)} 首诗,数据已保存到 F:\\\\爬虫实操\\\\pa_poems\\\\poems.csv\") # 数据分析与可视化 author_counts, char_counts = analyze_data(df) visualize_data(author_counts, char_counts)作用和逻辑
- 首先定义唐诗主页的 URL,调用 get_html 函数获取该页面的 HTML 内容
- 如果获取到 HTML 内容,则调用 get_data 函数提取诗歌信息
- 调用 save_data 函数将诗歌信息保存到 CSV 文件中
- 最后调用 analyze_data 函数进行数据分析,调用 visualize_data 函数进行数据可视化
运行效果
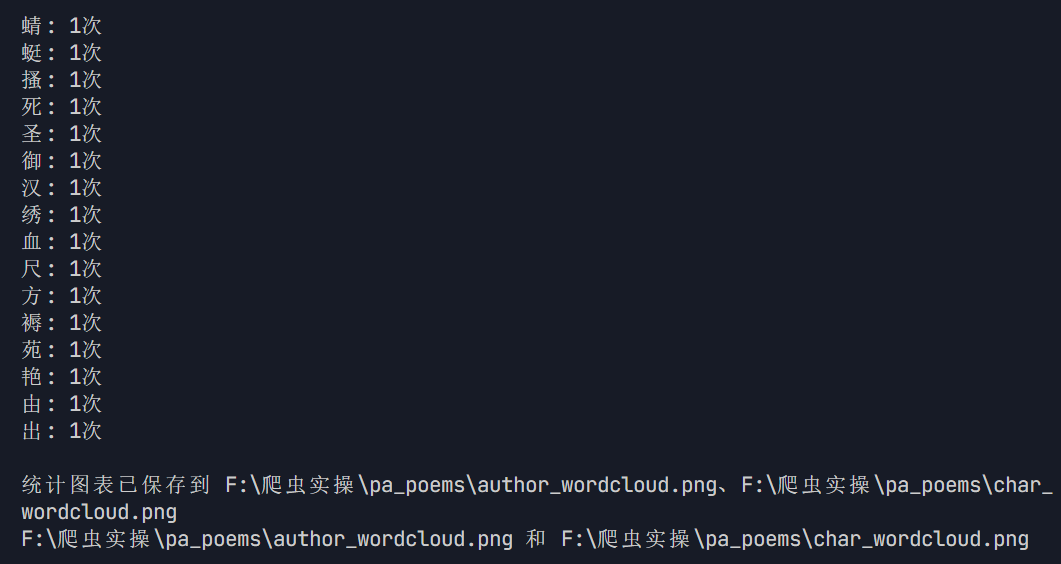
完整代码
import timefrom urllib.parse import urljoinimport requestsimport chardetimport pandas as pdfrom bs4 import BeautifulSoupimport osimport refrom collections import Counterimport matplotlib.pyplot as pltfrom wordcloud import WordClouddef get_html(url, params=None, timeout=3): \"\"\" 发送 HTTP 请求获取网页内容 :param url: 请求的 URL :param params: 请求参数 :param timeout: 超时时间 :return: 网页内容,如果出错则返回 None \"\"\" print(f\"正在抓取: {url}, params = {params}\") # 设置重试次数 requests.DEFAULT_RETRIES = 3 # 增加重试次数,提高成功率 headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0\' } try: response = requests.get(url, params=params, headers=headers, timeout=timeout) # 检查请求是否成功 response.raise_for_status() # 自动检测编码 response.encoding = chardet.detect(response.content)[\'encoding\'] return response.text except Exception as e: print(f\"请求出错: {e}\") return None finally: # 延迟避免频繁请求 time.sleep(3)def get_poem_data(poem_html, poem_id): \"\"\" 从诗歌页面的 HTML 中提取诗歌信息 :param poem_html: 诗歌页面的 HTML 内容 :param poem_id: 诗歌的 ID :return: 诗歌标题、作者、朝代、内容、创作背景 \"\"\" poem_bs = BeautifulSoup(poem_html, \'lxml\') # 提取标题 title_tag = poem_bs.select_one(f\'#zhengwen{poem_id} > h1\') title = title_tag.text.strip() if title_tag else \'\' # 提取作者 author_tag = poem_bs.select_one(f\'#zhengwen{poem_id} > p.source > a\') author = author_tag.text.strip() if author_tag else \'\' # 提取朝代 dynasty_tag = poem_bs.select_one(f\'#zhengwen{poem_id} > p.source > a:nth-child(2)\') dynasty = dynasty_tag.text.strip() if dynasty_tag else \'\' # 提取诗歌内容 content_tag = poem_bs.select_one(f\'#zhengwen{poem_id} > div.contson\') content = content_tag.text.strip() if content_tag else \'\' # 提取创作背景 background = \"\" # 查找所有可能包含创作背景的元素 background_divs = poem_bs.select(\'div.contyishang\') for div in background_divs: # 查找标题中包含\"创作背景\"的元素 title_element = div.select_one(\'p.title, div > h2\') if title_element and \'创作背景\' in title_element.text: # 获取内容 - 可能在p标签或div.contson中 content_elements = div.select(\'p:not(.title), div.contson\') if content_elements: # 合并所有内容元素 background = \' \'.join([el.text.strip() for el in content_elements]) break return title, author, dynasty, content, backgrounddef get_poem_links_by_type(html, poem_type): \"\"\" 从唐诗主页的 HTML 中提取特定类型诗歌的链接 :param html: 唐诗主页的 HTML 内容 :param poem_type: 诗歌类型,如\"五言绝句\"或\"七言绝句\" :return: 诗歌链接列表 \"\"\" bs = BeautifulSoup(html, \'lxml\') poem_links = [] # 根据提供的HTML结构调整选择器 type_divs = bs.select(\'div.typecont\') for div in type_divs: # 查找类型标题 title_tag = div.select_one(\'div.bookMl > strong\') if title_tag and poem_type in title_tag.text: # 找到对应类型的诗歌链接 links = div.select(\'span > a\') poem_links.extend(links) return poem_linksdef get_data(html, base_url): \"\"\" 从唐诗主页的 HTML 中提取诗歌链接,并获取每首诗歌的信息 :param html: 唐诗主页的 HTML 内容 :param base_url: 基础 URL :return: 包含所有诗歌信息的列表 \"\"\" # 获取五言绝句和七言绝句的链接 poem_types = [\"五言绝句\", \"七言绝句\"] all_poem_links = [] for poem_type in poem_types: print(f\"正在获取{poem_type}的链接...\") links = get_poem_links_by_type(html, poem_type) all_poem_links.extend(links) print(f\"获取到{len(links)}个{poem_type}链接\") data = [] for link in all_poem_links: poem_url = urljoin(base_url, link.get(\'href\')) print(f\"正在抓取: {poem_url}\") # 获取诗歌页面的 HTML poem_html = get_html(poem_url) if poem_html: # 提取诗歌 ID poem_id = poem_url.split(\'_\')[-1].split(\'.\')[0] # 提取诗歌信息 poem_data = get_poem_data(poem_html, poem_id) data.append(poem_data) return datadef save_data(data, file_name): \"\"\" 将诗歌信息保存到 CSV 文件中 :param data: 包含诗歌信息的列表 :param file_name: 保存的 CSV 文件名 \"\"\" df = pd.DataFrame(data, columns=[\'古诗\', \'作者\', \'朝代\', \'内容\', \'创作背景\']) if not os.path.exists(file_name): # 如果文件不存在,创建并写入表头 df.to_csv(file_name, encoding=\'utf-8-sig\', header=True, index=False) else: # 如果文件存在,追加数据不写表头 df.to_csv(file_name, encoding=\'utf-8-sig\', header=False, index=False, mode=\'a\') return dfdef analyze_data(df): \"\"\" 对诗歌数据进行统计分析 :param df: 包含诗歌数据的DataFrame \"\"\" # 统计作者创作数量 author_counts = df[\'作者\'].value_counts() print(\"\\n作者创作数量排名:\") print(author_counts) # 统计诗歌中出现最多的字 all_content = \'\'.join(df[\'内容\'].tolist()) # 去除标点符号和空白字符 all_content = re.sub(r\'[^\\u4e00-\\u9fa5]\', \'\', all_content) char_counts = Counter(all_content) print(\"\\n诗歌中出现最多的字:\") for char, count in char_counts.most_common(): print(f\"{char}: {count}次\") return author_counts, char_countsdef visualize_data(author_counts, char_counts): \"\"\" 可视化诗歌数据 :param author_counts: 作者创作数量统计 :param char_counts: 字符出现频率统计 \"\"\" # 设置中文字体 plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 用来正常显示中文标签 plt.rcParams[\'axes.unicode_minus\'] = False # 用来正常显示负号 # # 绘制作者创作数量柱状图 # plt.figure(figsize=(12, 6)) # top_authors = author_counts.head(10) # top_authors.plot(kind=\'bar\', color=\'skyblue\') # plt.title(\'唐诗作者创作数量排名前10\') # plt.xlabel(\'作者\') # plt.ylabel(\'创作数量\') # plt.tight_layout() # plt.savefig(\'d:\\\\Project\\\\author_stats.png\') # # 绘制字符频率柱状图 # plt.figure(figsize=(15, 8)) # top_chars = dict(Counter(char_counts).most_common(20)) # plt.bar(top_chars.keys(), top_chars.values(), color=\'lightgreen\') # plt.title(\'唐诗中出现频率最高的20个字\') # plt.xlabel(\'字\') # plt.ylabel(\'出现次数\') # plt.tight_layout() # plt.savefig(\'d:\\\\Project\\\\char_stats.png\') # 添加词云图可视化 # 作者词云图 plt.figure(figsize=(10, 8)) # 将作者数据转换为词云所需的格式 author_dict = author_counts.to_dict() # 创建词云对象 author_wordcloud = WordCloud( font_path=\'simhei.ttf\', # 使用黑体字体,确保能显示中文 width=800, height=600, background_color=\'white\', max_words=100, max_font_size=200, random_state=42 ).generate_from_frequencies(author_dict) # 显示词云图 plt.imshow(author_wordcloud, interpolation=\'bilinear\') plt.axis(\'off\') plt.title(\'唐诗作者创作数量词云图\') plt.tight_layout() plt.savefig(\'F:\\\\爬虫实操\\\\pa_poems\\\\author_wordcloud.png\') # 字符词云图 plt.figure(figsize=(10, 8)) # 创建词云对象 char_wordcloud = WordCloud( font_path=\'simhei.ttf\', # 使用黑体字体,确保能显示中文 width=800, height=600, background_color=\'white\', max_words=100, max_font_size=200, random_state=42 ).generate_from_frequencies(char_counts) # 显示词云图 plt.imshow(char_wordcloud, interpolation=\'bilinear\') plt.axis(\'off\') plt.title(\'唐诗中字符出现频率词云图\') plt.tight_layout() plt.savefig(\'F:\\\\爬虫实操\\\\pa_poems\\\\char_wordcloud.png\') print(\"\\n统计图表已保存到 F:\\\\爬虫实操\\\\pa_poems\\\\author_wordcloud.png、F:\\\\爬虫实操\\\\pa_poems\\\\char_wordcloud.png\") print(\"F:\\\\爬虫实操\\\\pa_poems\\\\author_wordcloud.png 和 F:\\\\爬虫实操\\\\pa_poems\\\\char_wordcloud.png\")if __name__ == \'__main__\': # 唐诗主页的 URL url = \'https://so.gushiwen.cn/gushi/tangshi.aspx\' # 获取唐诗主页的 HTML html = get_html(url) if html: # 提取诗歌信息 data = get_data(html, url) # 保存诗歌信息到 CSV 文件 df = save_data(data, \'F:\\\\爬虫实操\\\\pa_poems\\\\poems.csv\') print(f\"共爬取了 {len(data)} 首诗,数据已保存到 F:\\\\爬虫实操\\\\pa_poems\\\\poems.csv\") # 数据分析与可视化 author_counts, char_counts = analyze_data(df) visualize_data(author_counts, char_counts) 

