Python实战:基于Selenium的智联招聘数据爬虫项目(含源码)_智联招聘爬虫代码
写在开头
本项目中中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
一、项目背景
在求职过程中,及时获取大量的职位信息对于求职者来说至关重要。智联招聘作为国内知名的招聘平台,拥有大量的职位信息。然而,手动收集这些信息既耗时又容易出错。因此,本项目旨在开发一个自动化的爬虫程序,用于高效、准确地抓取智联招聘网站上特定职位的招聘信息。
二、技术栈
核心技术
Selenium:用于自动化浏览器操作,处理动态加载内容
ChromeDriver:驱动Chrome浏览器执行自动化任务
Python:主要编程语言(版本3.8+)
核心库
特点
- 无头浏览器模式:减少资源占用,提高爬取效率
- 随机延迟策略:避免触发网站反爬机制
- 异常处理机制:提高爬虫稳定性
- 结构化数据存储:CSV格式便于分析
- 可扩展性:支持多页爬取和分页控制
三、项目实现
核心功能
class ZhilianCrawler: def __init__(self): # 配置浏览器选项 self.options = webdriver.ChromeOptions() self.options.add_argument(\'--disable-blink-features=AutomationControlled\') self.options.add_argument( \'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36\') self.options.add_argument(\'--headless\') # 无头模式 # 初始化浏览器 self.driver = webdriver.Chrome(options=self.options) self.wait = WebDriverWait(self.driver, 15) # 创建CSV文件 timestamp = datetime.now().strftime(\"%Y%m%d_%H%M%S\") self.filename = f\"智联招聘_Java开发_{timestamp}.csv\" self.init_csv() def init_csv(self): \"\"\"初始化CSV文件并写入表头(调整字段顺序)\"\"\" with open(self.filename, \'w\', newline=\'\', encoding=\'utf-8-sig\') as f: writer = csv.writer(f) writer.writerow([ \'岗位名称\', \'公司名称\', \'薪资范围\', \'岗位地址\', \'工作经验\', \'学历要求\', \'岗位链接\', \'公司链接\', \'招聘岗位基础信息\' ]) def extract_job_info(self, job_element): \"\"\"从单个职位元素中提取核心信息(调整字段顺序)\"\"\" try: # 岗位名称和链接 title_elem = job_element.find_element(By.CSS_SELECTOR, \".jobinfo__name\") job_title = title_elem.text job_link = title_elem.get_attribute(\"href\") # 公司名称和链接 company_elem = job_element.find_element(By.CSS_SELECTOR, \".companyinfo__name\") company_name = company_elem.text company_link = company_elem.get_attribute(\"href\") # 薪资 salary = job_element.find_element(By.CSS_SELECTOR, \".jobinfo__salary\").text # 工作经验 location_items = job_element.find_elements(By.CSS_SELECTOR, \".jobinfo__other-info-item\") experience = location_items[1].text if len(location_items) > 1 else \"\" # 学历要求 education = location_items[2].text if len(location_items) > 2 else \"\" # 岗位地址(原工作地点) position_address = location_items[0].text if len(location_items) > 0 else \"\" # 招聘岗位基础信息 basic_info = f\"{job_title}|{company_name}|{position_address}\" return [ job_title, company_name, salary, position_address, experience, education, job_link, company_link, basic_info ] except Exception as e: print(f\"解析职位时出错: {str(e)}\") return None主运行函数
def run(self, start_page=2, end_page=6): \"\"\"主运行函数 :param start_page: 起始页码 :param end_page: 结束页码 \"\"\" print(\"=\" * 50) print(\"智联招聘数据爬虫启动\") print(f\"爬取范围: 第 {start_page} 页到第 {end_page} 页\") print(\"=\" * 50) # 计算总页数 total_pages = end_page - start_page + 1 for page in range(start_page, end_page + 1): print(f\"正在爬取第 {page} 页...\") success = self.crawl_page(page) if not success: print(f\"第 {page} 页爬取失败,终止爬取\") break # 随机延时防止封禁 delay = random.uniform(2, 5) print(f\"等待 {delay:.1f} 秒后继续...\") time.sleep(delay) print(\"=\" * 50) print(f\"爬取完成! 结果保存至: {os.path.abspath(self.filename)}\") print(f\"共爬取 {end_page - start_page + 1} 页数据\") print(\"=\" * 50) self.driver.quit()if __name__ == \"__main__\": crawler = ZhilianCrawler() # 爬取范围 crawler.run(start_page=2, end_page=6)关键爬取逻辑
1.使用CSS选择器定位关键元素:
- 岗位名称:.jobinfo__name
- 公司名称:.companyinfo__name
- 薪资范围:.jobinfo__salary
- 其他信息:.jobinfo__other-info-item
2.分页处理机制:
- 通过URL参数控制访问页码
- 智能等待页面加载完成
- 出错重试机制
3.数据存储
岗位名称,公司名称,薪资范围,岗位地址,工作经验,学历要求,岗位链接,公司链接,招聘岗位基础信息四、结果输出
控制台输出
==================================================智联招聘数据爬虫启动爬取范围: 第 2 页到第 6 页==================================================正在爬取第 2 页...第 2 页完成,获取 20 个职位等待 4.4 秒后继续...正在爬取第 3 页...第 3 页完成,获取 20 个职位等待 2.0 秒后继续...正在爬取第 4 页...第 4 页完成,获取 20 个职位等待 4.5 秒后继续...正在爬取第 5 页...第 5 页完成,获取 20 个职位等待 3.2 秒后继续...正在爬取第 6 页...第 6 页完成,获取 20 个职位等待 4.0 秒后继续...==================================================爬取完成! 结果保存至: E:\\IDE\\work\\智联招聘_Java开发_20250606_123224.csv共爬取 5 页数据==================================================进程已结束,退出代码为 0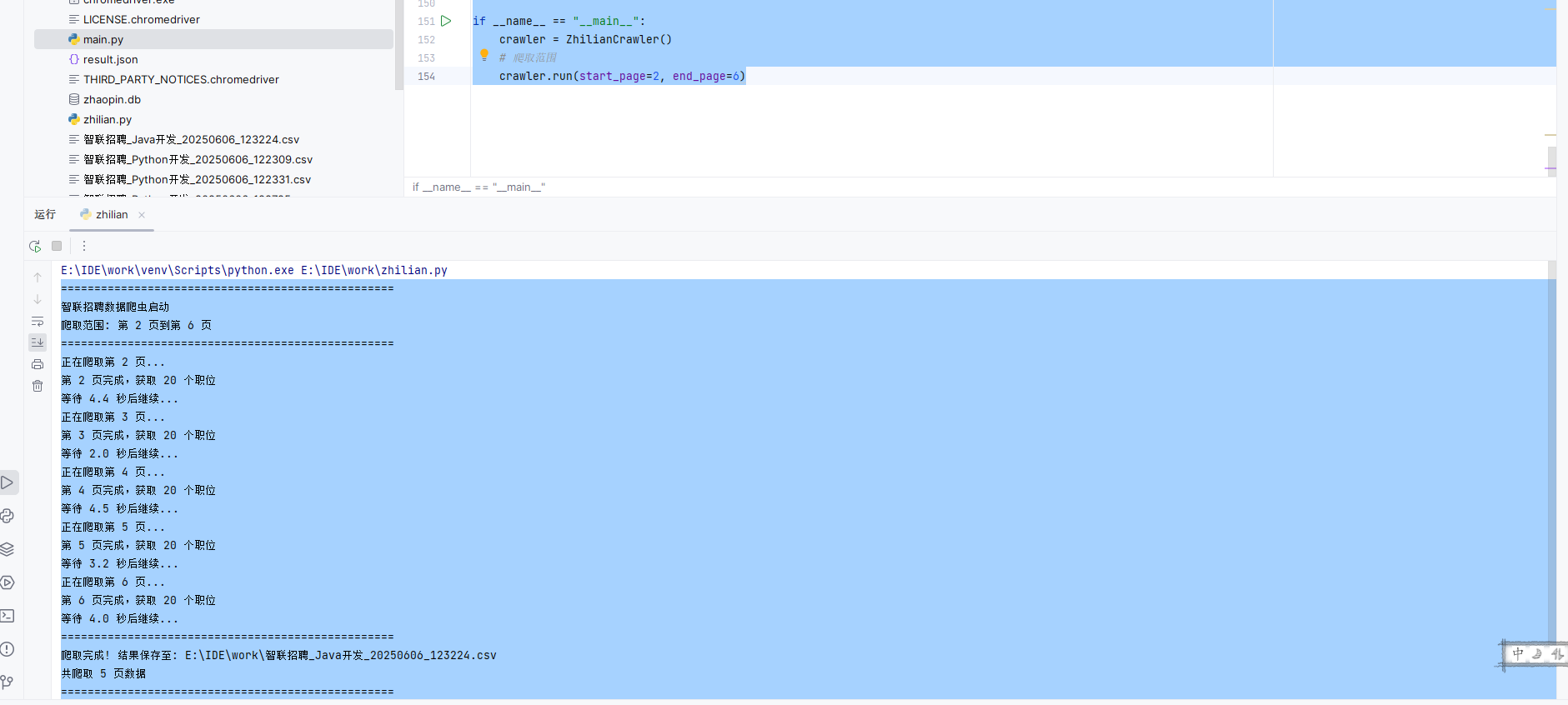
csv文件展示

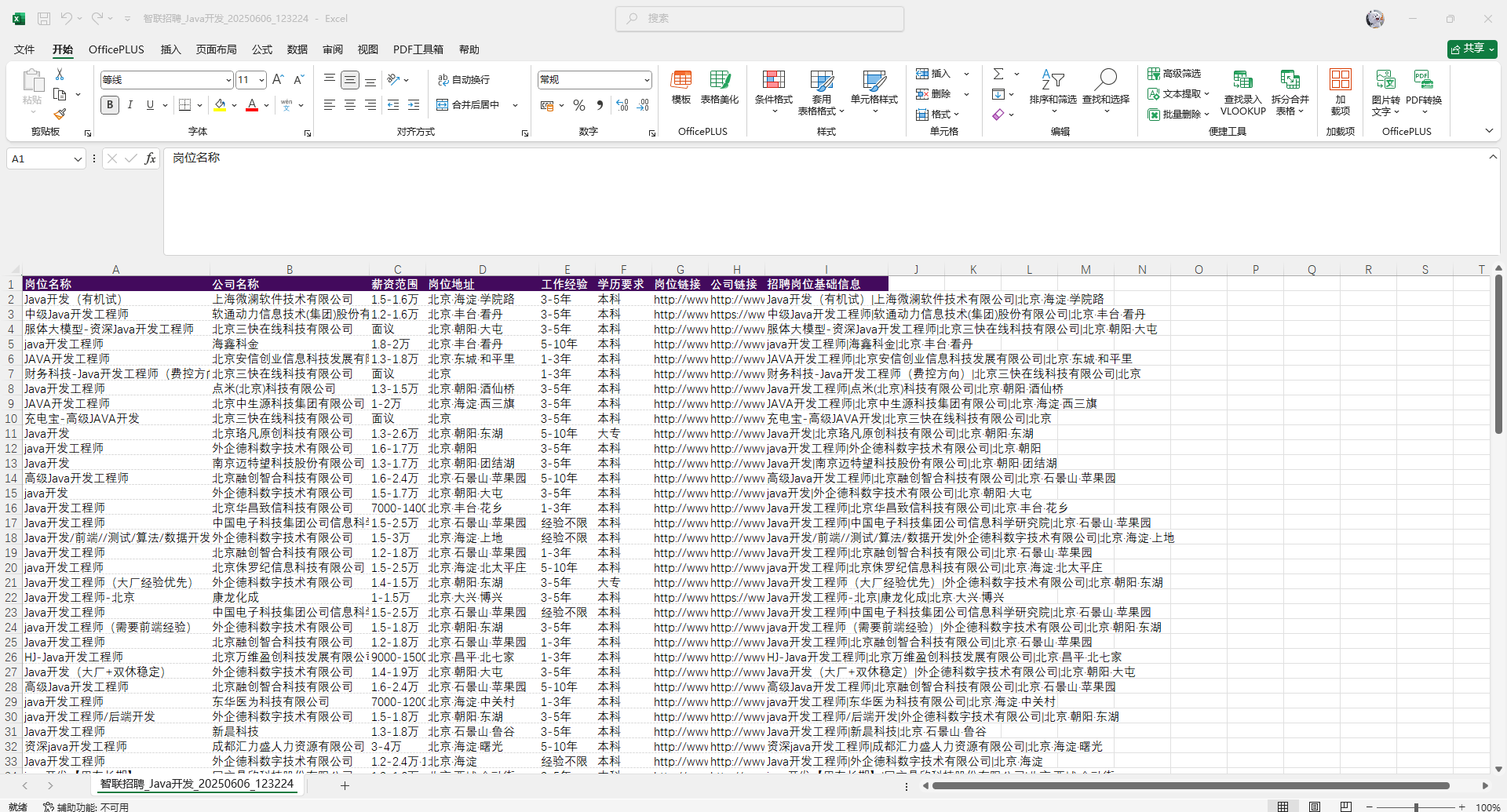
项目结果
自动化采集:成功爬取2-6页智联招聘北京市Java开发职位数据
结构化存储:生成包含9个关键字段的CSV文件
效率提升:单次运行可采集150+个职位信息(可按需修改)
数据分析基础:提供原始数据供进一步分析


