零基础本地部署Qwen3模型(ollama+Open-WebUI)_ollama部署qwen3
环境准备
操作系统
建议使用linux如ubuntu等
安装ollama
ollama是一个轻量化本地部署模型工具,对普通用户友好。借助 Docker 容器简化流程,像在本地电脑运行小模型做测试、开发,一条
ollama run 模型名命令就能快速启动 ,新手易上手。比如想体验 Qwen3 - 0.6B,装完 Ollama 直接敲命令就能下载运行。
-
方式一:直接安装
curl -fsSL https://ollama.com/install.sh | sh-
方式二:离线安装
点击进入ollama项目离线安装包Releases · ollama/ollama
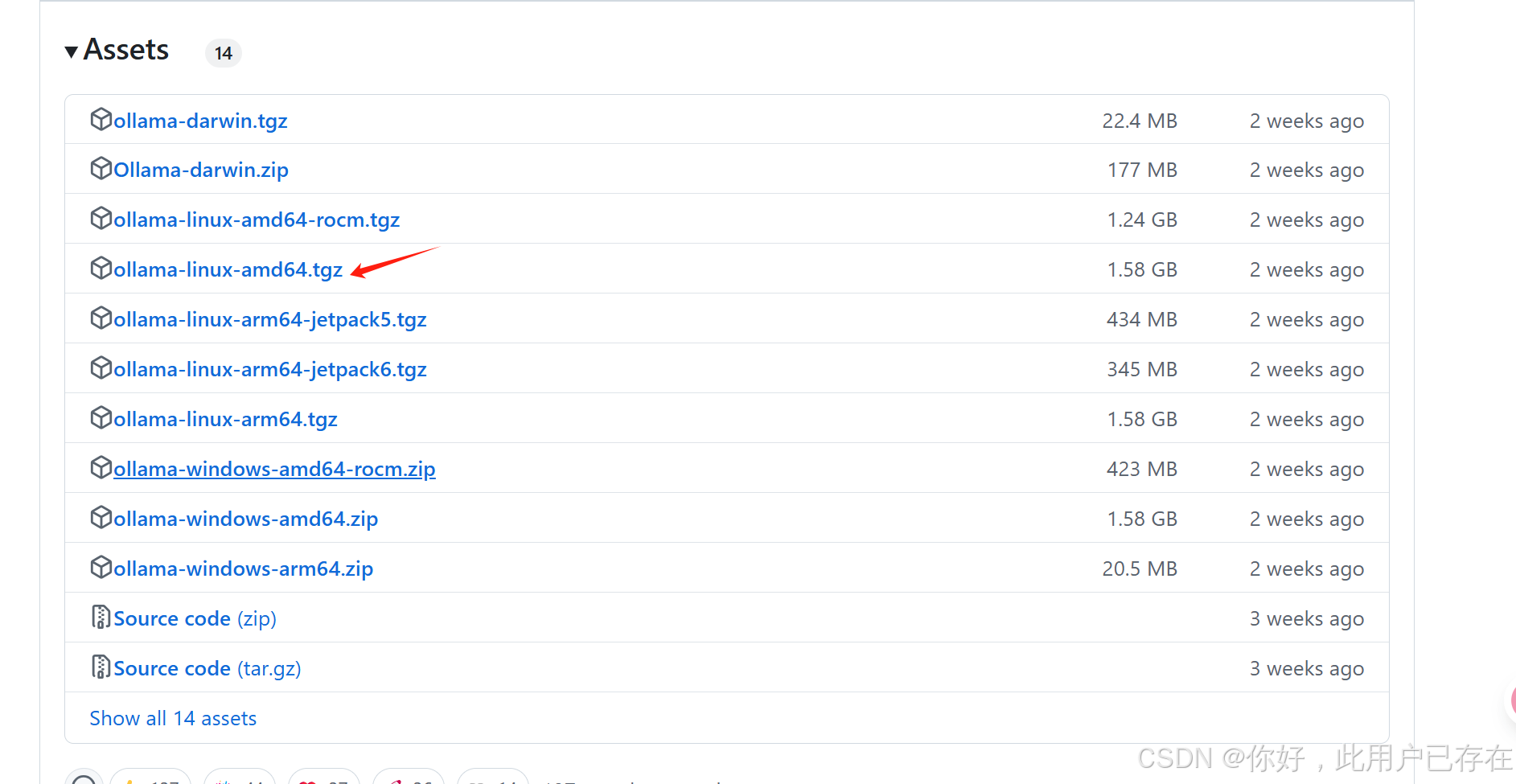
点击选择合适的版本进行下载,下载后直接解压即可使用
tar -zxvf ollama-linux-amd64.tgz解压后有两个文件夹,分别是bin目录和lib目录,其中bin目录下即存放着ollama的运行文件
修改环境变量
vim ~/.bashrc添加ollama可执行文件路径
# ollamaexport PATH=$PATH:/data1/sx/jl/ollama/bin验证安装
直接启动ollama服务
ollama serve模型下载与部署
使用ollama部署模型
可参考以下配置选择自己的模型
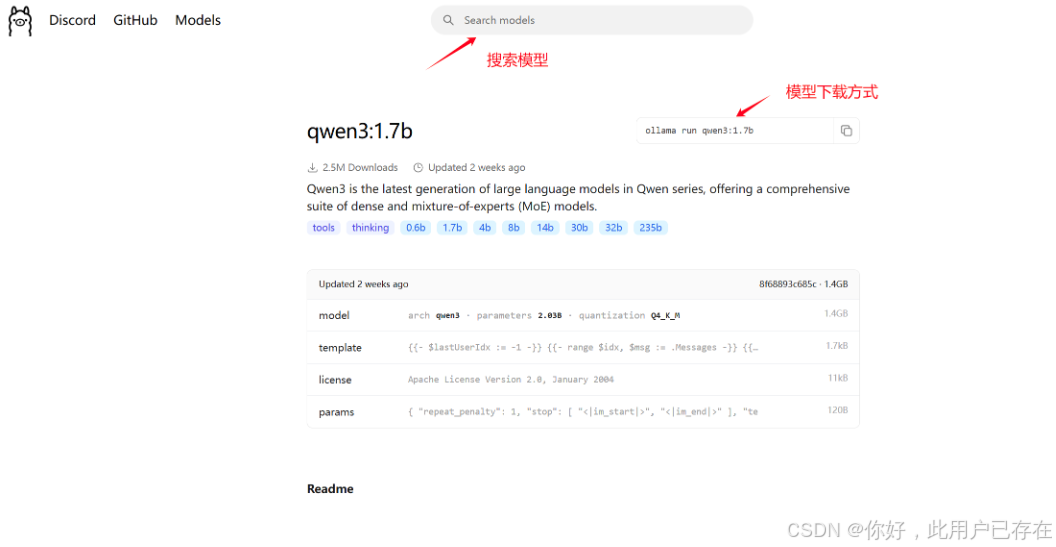
这里为方便做测试,仅下载Qwen3-1.7B使用
ollama run qwen3:1.7bollama的使用类似于docker,上述命令执行后ollama会自行拉取qwen3-1.7B模型并部署到本地,下次再次执行该命令时就直接运行模型

默认情况下,模型的下载存放路径在
~/.ollama/models另外,用户可进入ollama官网查看ollama对各种开源模型的支持
qwen3:1.7b
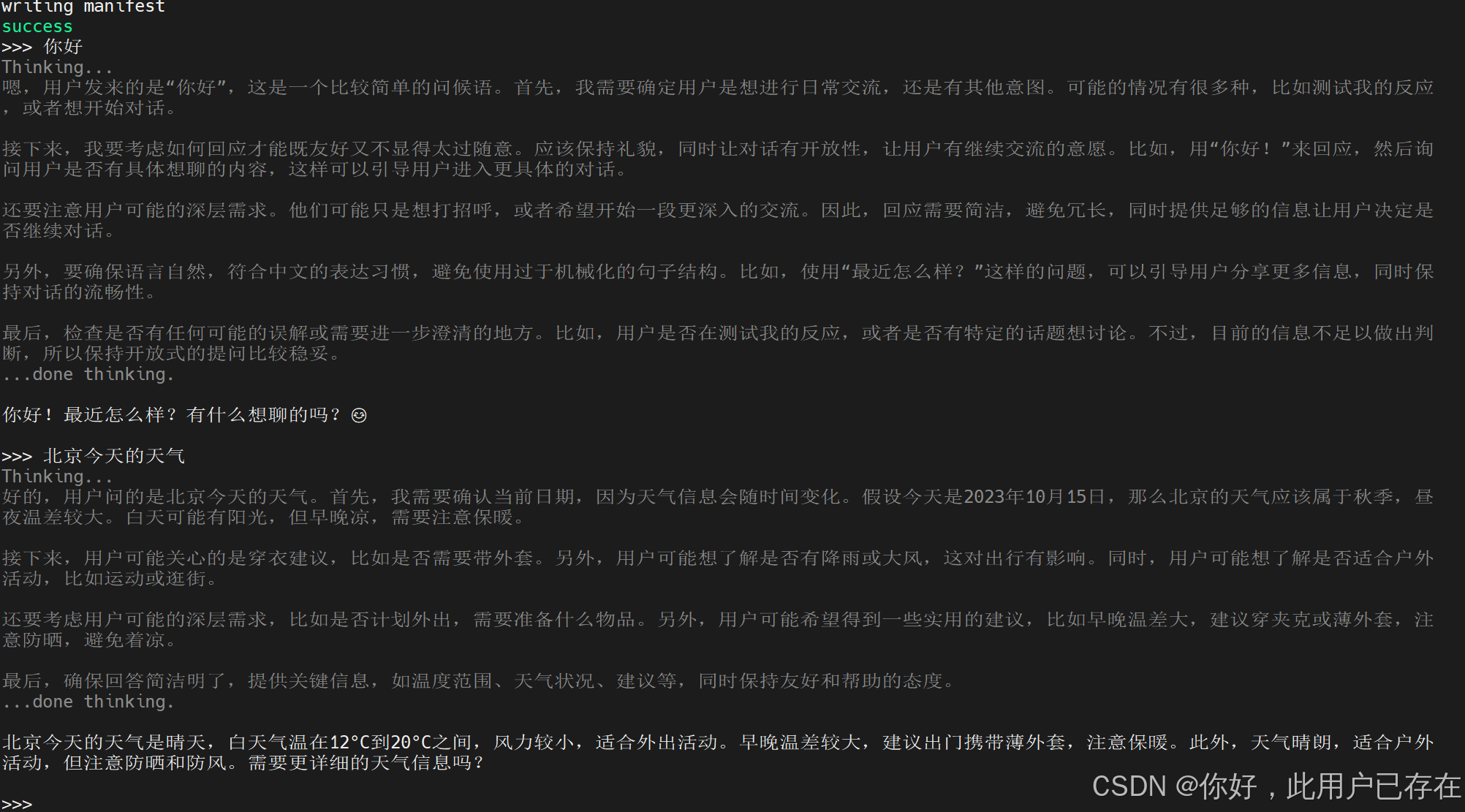
以下是使用ollama运行模型,并使用模型的案例
可视化终端open-webui
上述我们使用ollama部署模型并使用模型的方式是使用交互式终端,如果我们想使用类似于gpt这种网页的方式使用我们本地部署的模型,需要使用另外一个工具open-webui,open-webui调用的是ollama的服务,因此需要事先安装好ollama
安装
open-webui的安装较为简单
方式一:在conda环境中安装
pip install open-webui方式二:使用docker安装
可参考
在Ubuntu上部署Open WebUI和Ollama,打造你的私人GPT - 教程分享 / 云服务器 RCS - 雨云论坛
启动open-webui
如果你的服务器可直接使用浏览器,则直接启动即可,注意,一定要首先在后台启动ollama服务、
ollama serve然后再启动open-webui
open-webui serve启动open-webui时可能会报错,这是因为第一次使用open-webui,open-webui需要从huggingface下载RAG模型,但是服务器连接外网不通畅导致,如果用户需要进行科学上网即可,如果用户不需要,忽略该错误(不影响本节使用)或者使用以下命令设置环境变量即可
export HF_HUB_OFFLINE=1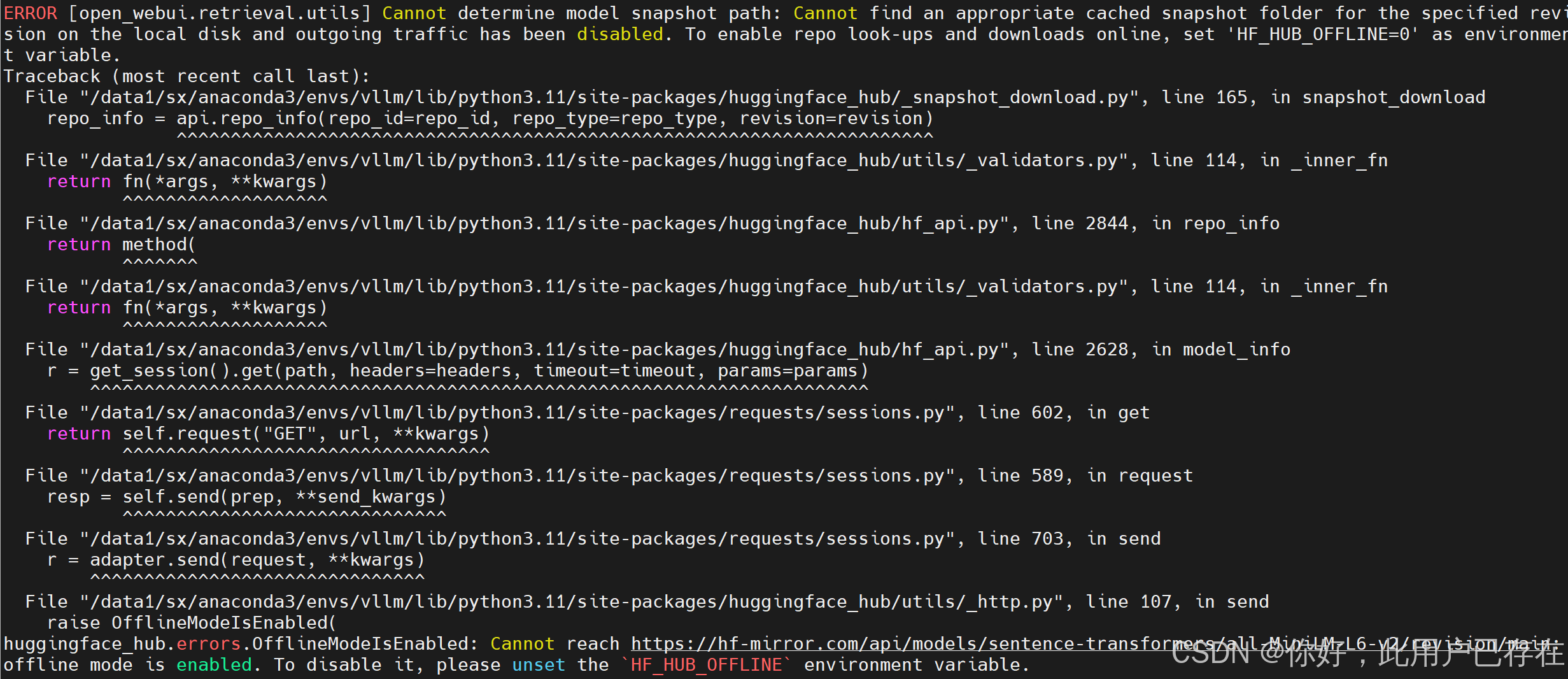
启动浏览器
在本地打开浏览器,首次打开需要进行注册,按照流程进行注册即可
http://localhost:8080/
如果open-webui安装在服务端,不能打开浏览器界面,需要在本地机器(如windows打开浏览器),则需要进行端口映射,如下,在本地cmd窗口执行
# 本地端口 8080 → 远程服务器 8080 端口ssh -L 8080:localhost:8080 username@server_ip
8080:本地监听端口(可自定义)8080:远程服务器上open-webui服务的端口username:你的服务器用户名server_ip:服务器公网 IP 地址


