今天两轮实习面试,谈谈主要问了那些问题?_java实习生数据库面试
这些都是我回答的比较含糊,比较差的,还有一些我认为比较重要的,因为一家是小厂,一家是实习一面,问的都比较基础。
-
说说Java的集合类?
Java中的集合有两个顶层父类接口Collection和Map


-
谈谈mySql的索引有哪些?
这里我答的很差,因为我只记得什么聚集索引和非聚集索引了。
1.按数据结构分类
B+-Tree索引:默认索引类型,InnoDB和MyISAM引擎的默认索引,适用于大多数场景。支持各种条件查询,像=, >, <, BETWEEN, LIKE \'prefix%\'(前缀匹配)等。范围查询和排序效率高(索引本身有序)。
Hash索引:基于哈希表,仅支持Memory引擎(InnoDB的自适应哈希是内部优化,用户不可见)。仅精确匹配(=、IN)。查询速度极快,不支持范围查询和排序,哈希冲突可能导致性能下降。
全文索引:对文本内容(如文章、日志)进行关键词搜索。
2.按逻辑分类(重点)
主键索引(PRIMARY KEY):唯一且非空(UNIQUE + NOT NULL)
唯一索引(UNIQUE):确保列值的唯一性(允许NULL值)
普通索引(INDEX/KEY):加速查询,无唯一性约束
组合索引(复合索引):遵循最左前缀原则(查询条件需包含索引最左侧列)
覆盖索引:将所有字段加上索引,无需回表查询
3.按索引的存储方式
聚集索引:索引的叶子节点直接存储整行数据(索引即数据文件)。每个表只能有唯一一个聚集索引,在innoDB中,主键自动成为聚集索引。如果未定义主键,InnoDB会选择第一个非空的唯一索引(UNIQUE NOT NULL)作为聚集索引,若既无主键也无唯一索引,InnoDB会隐式创建一个6字节的隐藏行ID(DB_ROW_ID)作为聚集索引。
非聚集索引:索引的叶子节点存储的是数据行的指针(主键值或物理地址)。在InnoDB中,非主键索引为非聚集索引。
-
MySQL索引失效?
这个只记起了最左前缀法则
-
不遵循最左前缀原则:特别是在组合索引中,如果查询条件没有使用索引的最左边的列,索引可能不会被使用。例如,组合索引是(A, B, C),但查询条件只用了B和C,没有A,这时候索引可能失效。
-
在索引列上进行计算或函数操作:如果在WHERE子句中对索引列使用函数或者计算,比如
WHERE YEAR(date_column) = 2023,这会导致索引失效,因为MySQL无法直接使用索引的值,而是需要计算每一行。 -
使用LIKE以通配符开头:比如
LIKE \'%abc\',这样的查询无法利用索引,因为索引是按照前缀构建的。如果是LIKE \'abc%\',则可能使用索引。 -
OR条件使用不当:如果OR条件中的某一列没有索引,可能导致整个查询不使用索引。例如,
WHERE indexed_column = \'value\' OR non_indexed_column = \'value\',这时候可能全表扫描。 -
类型转换:如果查询条件中的类型与索引列的类型不匹配,比如索引是字符串类型,但查询时使用了数字,导致隐式类型转换,索引可能失效。
-
全表扫描比使用索引更快:当表中数据量较小时,MySQL可能会认为全表扫描比使用索引更快,这时候即使有索引也不会使用。比如,当数据量非常小的时候,优化器可能选择全表扫描。
-
使用不等于(!= 或 )或者NOT IN:这些操作可能导致索引失效,因为需要扫描大部分数据,这时候优化器可能选择全表扫描。
-
索引列上使用IS NULL或IS NOT NULL:在某些情况下,如果索引列包含大量NULL值,使用IS NULL可能不会走索引。
-
JDBC的操作流程
这个我是真忘记了,因为平时用的是myBatis框架,上次写这个都是一年前了
不使用连接池的情况//1.注册驱动Class.forName(\"com.mysql.cj.jdbc.Driver\");//2.获取链接对象(url,user,password)Connection conn = DriverManager.getConnection(\"jdbc:mysql://localhost:3306/myDatabase\");//3.通过链接对象调用方法得到statement对象Statement statement = conn.createStatement();//4.通过statement对象调用execute方法可以对数据库数据库发起操作请求,查询操作会得到结果集ResultSetResultSet res = statement.executeQuery(\"select * from user\");//5.处理异常/关闭资源(已经抛出异常)res.close();statement.close();onn.close();使用连接池的情况dataSource = new DruidDataSource();// 基础配置dataSource.setUrl(\"jdbc:mysql://localhost:3306/my_database?useSSL=false&characterEncoding=utf8\");dataSource.setUsername(\"root\");dataSource.setPassword(\"123456\");dataSource.setDriverClassName(\"com.mysql.cj.jdbc.Driver\"); // 显式设置驱动类名 // 连接池参数dataSource.setInitialSize(5); // 初始连接数dataSource.setMinIdle(3); // 最小空闲连接dataSource.setMaxActive(20); // 最大活跃连接数dataSource.setMaxWait(3000); // 获取连接超时时间(毫秒)Connection conn = dataSource.getConnection();//3.通过链接对象调用方法得到statement对象Statement statement = conn.createStatement();//4.通过statement对象调用execute方法可以对数据库数据库发起操作请求,查询操作会得到结果集ResultSetResultSet res = statement.executeQuery(\"select * from user\");//5.处理异常/关闭资源(已经抛出异常)res.close();statement.close();onn.close();-
MyBatis的操作流程?在不使用连接池的情况下?
1.编写MyBatis的配置文件(mybatis-config.xml)文件名固定,且最好放在项目的根路径下
2.创建一个mapper接口,并编写方法
public interface UserMapper { // 根据 ID 查询用户信息 User getUser(int id);}3.为这个mapper接口编写一个xml配置文件
SELECT * FROM users WHERE id = #{id} 4.调用mapper方法
public class MyBatisExample { public static void main(String[] args) throws IOException { String resource = \"mybatis-config.xml\"; //读取mybatis的配置文件 Reader reader = Resources.getResourceAsReader(resource); //通过SqlSessionFactoryBuilder对象的.build()方法,传递reader对象,实现 //sqlSession的工厂对象的创建 SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader); try ( //由工厂对象创建SqlSession对象 SqlSession session = sqlSessionFactory.openSession()) { //向SqlSession对象传递想要创建的mapper接口的字节码文件,得到mapper对象 UserMapper mapper = session.getMapper(UserMapper.class); //在调用方法即可 User user = mapper.getUser(100); System.out.println(user.getUsername()); } }-
MyBatis的优缺点?
这个真给我问到了。
大家都知道MyBatis的最大优点是灵活,因为可以编写动态sql,那么缺点呢?
缺点:虽然支持多数据库,但 SQL 需针对不同数据库进行调整(全自动 ORM 可自动适配方言)。(这是面试官想让我答的,因为他问过我 “你除了使用过mybatis还使用过那些orm框架(Hibernate)”)
-
你在那些场景下用过redis?
这个就要结合自己的项目业务回答了
1.缓存数据,查询的时候先查缓存,如果不存在,在查数据库,在同步缓存。降低数据库压力。
2.分布式锁,用setnx命令或者redisson分布式锁为查询数据库到同步缓存这一步加上锁,可以防止缓存击穿。
3.发送异步消息,基于redis的发布订阅Pub/Sub模式可以实现异步消息的发送。
-
redis的优缺点?
这个问题也搞的我很无语,我回答的缺点是成本高,但是面试官来了一句内存成本也不高,搞得我也不知道答案了。下面是我网上搜的:
Redis 的优点
1. 极高性能
- 内存存储:数据存储在内存中,读写速度极快(10万+ QPS)。
- 单线程模型:避免多线程竞争,简化设计(Redis 6.0+ 支持多线程网络 IO,但核心操作仍单线程)。
2. 支持丰富的数据结构
- 多样化数据类型:
- 字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)。
- 位图(Bitmap)、HyperLogLog(基数统计)、地理空间索引(GEO)等。
- 适用场景广泛:如排行榜(Sorted Set)、消息队列(List/Stream)、实时统计(HyperLogLog)。
3. 持久化与高可用
- 持久化机制:
- RDB(快照):定期生成数据快照,适合备份。
- AOF(追加日志):记录所有写操作,数据可靠性更高。
- 高可用架构:
- 主从复制(Master-Slave) + 哨兵(Sentinel)自动故障转移。
- Redis Cluster 分片集群,支持横向扩展。
4. 功能丰富
- 事务支持:通过
MULTI/EXEC实现简单事务(非 ACID)。 - Lua 脚本:原子性执行复杂逻辑。
- 发布订阅(Pub/Sub):轻量级消息队列。
- 分布式锁:通过
SETNX或 Redisson 实现(解决并发竞争)。
5. 生态成熟
- 客户端支持广泛(Java、Python、Go 等)。
- 与 Spring、Kafka 等中间件集成方便。
- 云服务支持完善(如 AWS ElastiCache、阿里云 Redis)。
Redis 的缺点
1. 内存成本高
- 数据完全存储在内存中,存储海量数据时硬件成本较高。
- 需配合淘汰策略(如 LRU、TTL)或持久化机制管理内存。
2. 持久化性能权衡
- RDB:生成快照时可能阻塞主线程(大数据量时延迟明显)。
- AOF:写入频繁时影响吞吐量(可通过
everysec配置平衡性能与安全)。
3. 单线程的局限性
- CPU 密集型操作阻塞:如
KEYS *、复杂 Lua 脚本会阻塞其他请求。 - 多核利用率低(Redis Cluster 可通过分片解决)。
4. 数据规模受限
- 单实例内存容量受物理限制,超大规模数据需分片(Redis Cluster)。
- 不适合存储大文件(如图片、视频)。
5. 复杂查询能力弱
- 无 SQL 支持,复杂查询需客户端处理(如排序、JOIN)。
- 不适合替代关系型数据库(如 MySQL)作为主存储。
-
如何查看mysql在查表时是否用过索引?
使用explain命令查看执行计划。在sql查询语句前添加explain即可。
-
你知道那些互联网的通信协议?udp和tcp的区别?你自己解析过tcp协议吗?

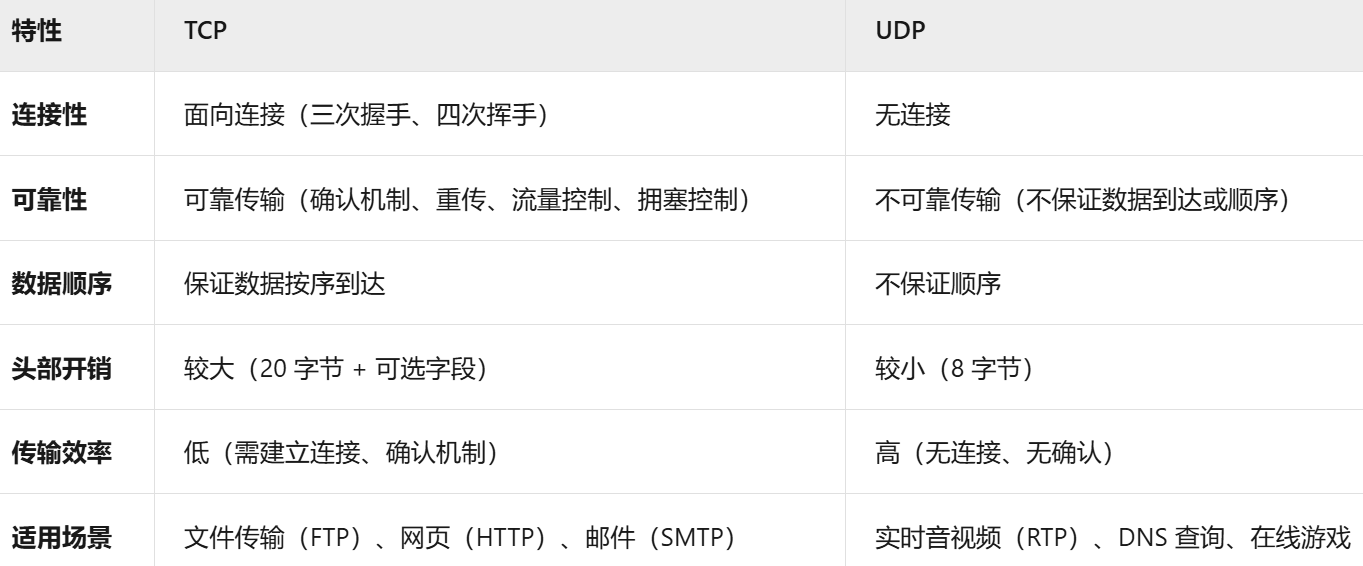
Java 提供了原生 API 直接处理 TCP 协议,至于对TCP数据包的解析,我确实不知道了。
// 客户端try (Socket socket = new Socket(\"localhost\", 8080)) { OutputStream out = socket.getOutputStream(); out.write(\"Hello TCP!\".getBytes());}// 服务端try (ServerSocket serverSocket = new ServerSocket(8080)) { Socket clientSocket = serverSocket.accept(); InputStream in = clientSocket.getInputStream(); // 读取 TCP 数据流(字节级别) byte[] buffer = new byte[1024]; int bytesRead = in.read(buffer); System.out.println(\"收到数据:\" + new String(buffer, 0, bytesRead));}
