zookeeper+kafka集群部署
Zookeeper与Kafka是两个在大数据处理领域至关重要的组件,它们分别扮演着不同的角色。Zookeeper是一款分布式的,开放源码的协调服务,它为分布式应用程序提供一致性服务,而Kafka则是一个高吞吐量的分布式消息系统,被广泛应用于实时数据流处理。 让我们深入理解Zookeeper。Zookeeper的核心功能包括命名服务、配置管理、集群同步和分布式锁。它的设计基于一个简单的模型,即每个节点(称为ZNode)都可以存储数据,并且具有版本控制和ACL(访问控制列表)安全特性。Zookeeper的强一致性模型使得它在分布式环境中特别可靠,能确保数据的一致性和准确性。在Linux或Windows环境下部署Zookeeper,,解压后进行配置并启动服务,以便为其他分布式系统提供可靠的协调服务。 接下来,我们来看看Kafka。Kafka是一种分布式流处理平台,由LinkedIn开源并贡献给Apache软件基金会。它的设计目标是支持实时数据流处理,具备高吞吐量、低延迟和可持久化等特点。Kafka主要由生产者、消费者和主题(Topic)组成,其中生产者负责发布消息,消费者订阅并消费这些消息,而主题则像数据库中的表,用于存储消息。在部署Kafka时,我们需要设置环境变量,创建 Zookeeper 配置,然后启动Kafka服务器
一:前期环境准备
1:准备三台服务器:
master:192.168.158.129
slave1:192.168.158.130
slave2:192.168.158.131
2:三台服务器之间设置免密登录
博客:Linux多节点间的免密码登录-CSDN博客文章浏览阅读78次,点赞2次,收藏3次。CentOS主机配置SSH无密码通信的方法。先修改主机名和IP主机名映射,重启计算机。接着在外网环境下安装并查看SSH安装结果。通过每台机器生成秘钥,将公钥复制到master节点,master追加到authorized_keys后分发给其余节点,实现各节点间无密码通信https://blog.csdn.net/lyz135110950115/article/details/149570607?spm=1011.2415.3001.5331
二、zookeeper集群
1:软件下载:
将软件下载到本地后,分别上传到 master、slave1、slave2节点上
zookeeper+kafka软件下载:https://download.csdn.net/download/lyz135110950115/91461548
2:对zookeeper软件进行解压,
进入软件所在目录对进行解压,cd /soft 进入文件所在目录;(三台节点都要操作)
tar -zxvf apache-zookeeper-3.9.3-bin.tar.gz 3:修改解压后的文件夹名称;
(三台节点都要操作)
mv apache-zookeeper-3.9.3-bin/ /soft/zookeeper4:创建一个数据存储目录;
(三台节点都要操作)
cd /data/soft/zookeeper ; mkdir data5:创建唯一标识
分别进入刚才所创建的data目录,在该目录下创建一个myid的唯一身份标识
master服务器:
echo 1 > myid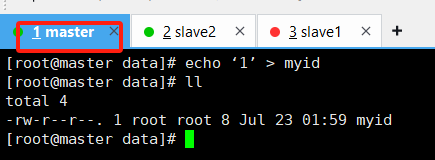
slave1服务器:
echo 2 > myid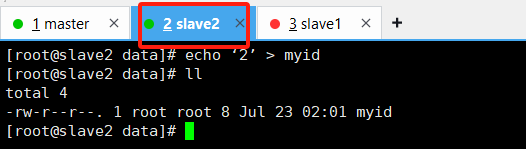
slave2服务器:
echo 3 > myid 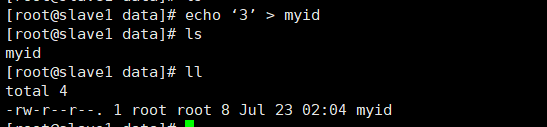
注意每台服务data目录下的myid里面的值是数值型,不要有双引号,如果有双引号记得删除,三台服务器都一样,不删除 否则启动不了
6:修改zoo.cfg配置
进入/soft/zookeeker/conf 进行修改配置文件,将软件自带默认配置文件修改成正式的名称;三台服务器均要操作
mv zoo_sample.cfg zoo.cfg修改后的名称
编辑该文件配置数据存储路径与设计集群IP与端口两个知识点;三台服务器均要操作
# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial # synchronization phase can takeinitLimit=10# The number of ticks that can pass between # sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just # example sakes.dataDir=/soft/zookeeper/data# the port at which the clients will connectclientPort=2181# the maximum number of client connections.# increase this if you need to handle more clients#maxClientCnxns=60## Be sure to read the maintenance section of the # administrator guide before turning on autopurge.## https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to \"0\" to disable auto purge feature#autopurge.purgeInterval=1## Metrics Providers## https://prometheus.io Metrics Exporter#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider#metricsProvider.httpHost=0.0.0.0#metricsProvider.httpPort=7000#metricsProvider.exportJvmInfo=trueelectionPortBindRetry=10server.1=192.168.158.129:2888:3888server.2=192.168.158.130:2888:3888server.3=192.168.158.131:2888:3888 其他配置解读:
tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit = 10 :LF 初始通信时限 只领导者与从节点 初始连接时容忍的最多心跳数
syncLimit = 5 :LF 同步通信时限 领导节点和从节点之间的通信时间, 如果超过该时间就会将从节点剔除
server.A=B:C:D
A 是一个数字,表示这个是第几号服务器;集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个 server。
B 是这个服务器的地址;
C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
注意:server.1对应的就是data下面 myid写的机器,
涉及端口; 三台服务器均要开放该三个端口
- 2181:客户端连接端口用于客户端与服务端之间的通信支持分布式系统中的节点协调管理。
- 2888:集群内部通信端口,Leader节点监听此端口与Follower节点进行数据同步和其他通信。
- 3888:集群选举端口,用于当Leader节点故障时进行集群领导权重新选举的
查看端口是否开启:
sudo firewall-cmd --query-port=2181/tcp![]()
分别对上述三个端口进行开放
sudo firewall-cmd --add-port=2181/tcp --permanentsudo firewall-cmd --add-port=2888/tcp --permanentsudo firewall-cmd --add-port=3888/tcp --permanent开放后重新载入防火墙
sudo firewall-cmd --reload查看是否开放成功
sudo firewall-cmd --list-all 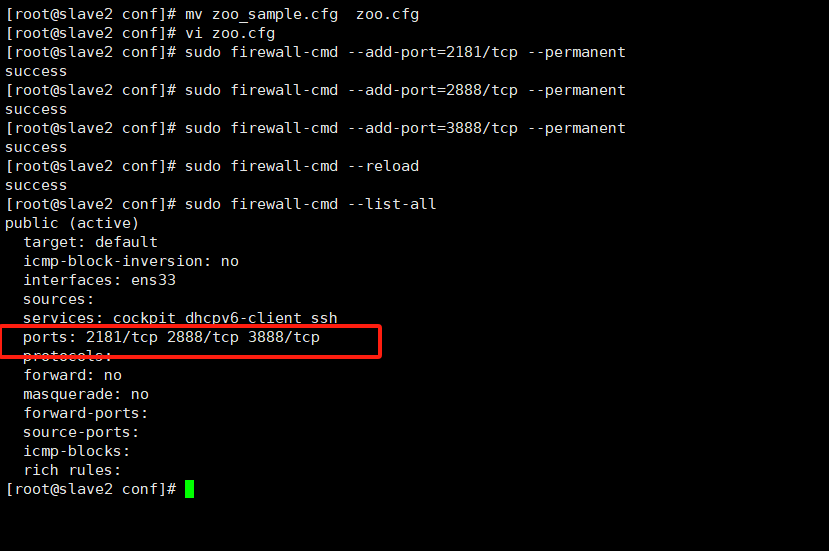
7:编写启动脚本
编写一个集群启动的sh文件,可以自定义一个专门存放sh文件的目录本案例在 /soft/allSh,进入该目录;最好三台服务器都创建该脚本,这样后续在哪一台服务器都可以进行启动停止等操作
vi zkCluster.sh#!/bin/bashcase $1 in\"start\"){ #遍历集群所有机器for i in 192.168.158.129 192.168.158.130 192.168.158.131do#控制台输出日志echo =============zookeeper $i 启动====================#启动命令ssh $i \"/soft/zookeeper/bin/zkServer.sh start\"done};;\"stop\"){for i in 192.168.158.129 192.168.158.130 192.168.158.131doecho =============zookeeper $i 停止====================ssh $i \"/soft/zookeeper/bin/zkServer.sh stop\"done};;\"status\"){for i in 192.168.158.129 192.168.158.130 192.168.158.131doecho =============查看 zookeeper $i 状态====================ssh $i \"/soft/zookeeper/bin/zkServer.sh status\"done};;esac给该脚本授权:
chmod +777 zkCluster.sh 启动服务器查看服务状态
ps -ef | grep zookeeper 
执行刚才创建的脚本
./zkCluster.sh start 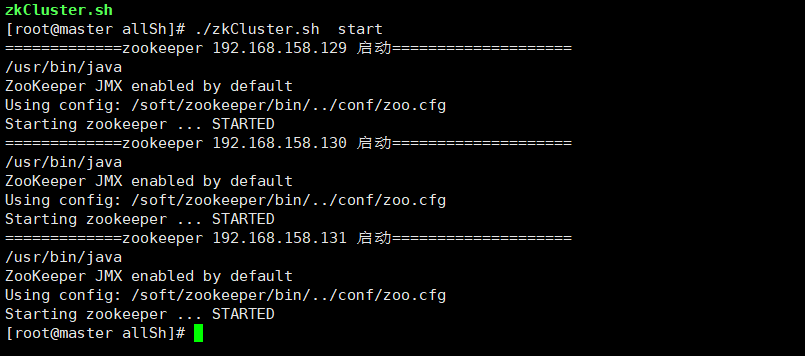
执行 ps | ef grep zookeeper ;三台服务器均启动成功
停止: ./zkCluster.sh stop
查看状态: ./zkCluster.sh status
到此zookeeper集群完成
三、kafka集群
1:软件下载:
将软件下载到本地后,分别上传到 master、slave1、slave2节点上
zookeeper+kafka软件下载:https://download.csdn.net/download/lyz135110950115/91461548
2:上传文件
将文件上传到三台节点服务上 本案例上传到:/soft 进入该目录进行解压
tar -zxvf kafka_2.13-3.9.0.tgz 3:将修改解压后的包名称
mv kafka_2.13-3.9.0/ /soft/kafka
4:创建数据卷
进入kafka目录下创建一个数据目录:data
cd kafka/mkdir data
5:修改配置
进入kafka下的conf目录,对server.properties修改
cd config/开始编辑配置文件:
vi server.properties #broker 的全局唯一编号不能重复只能是数字。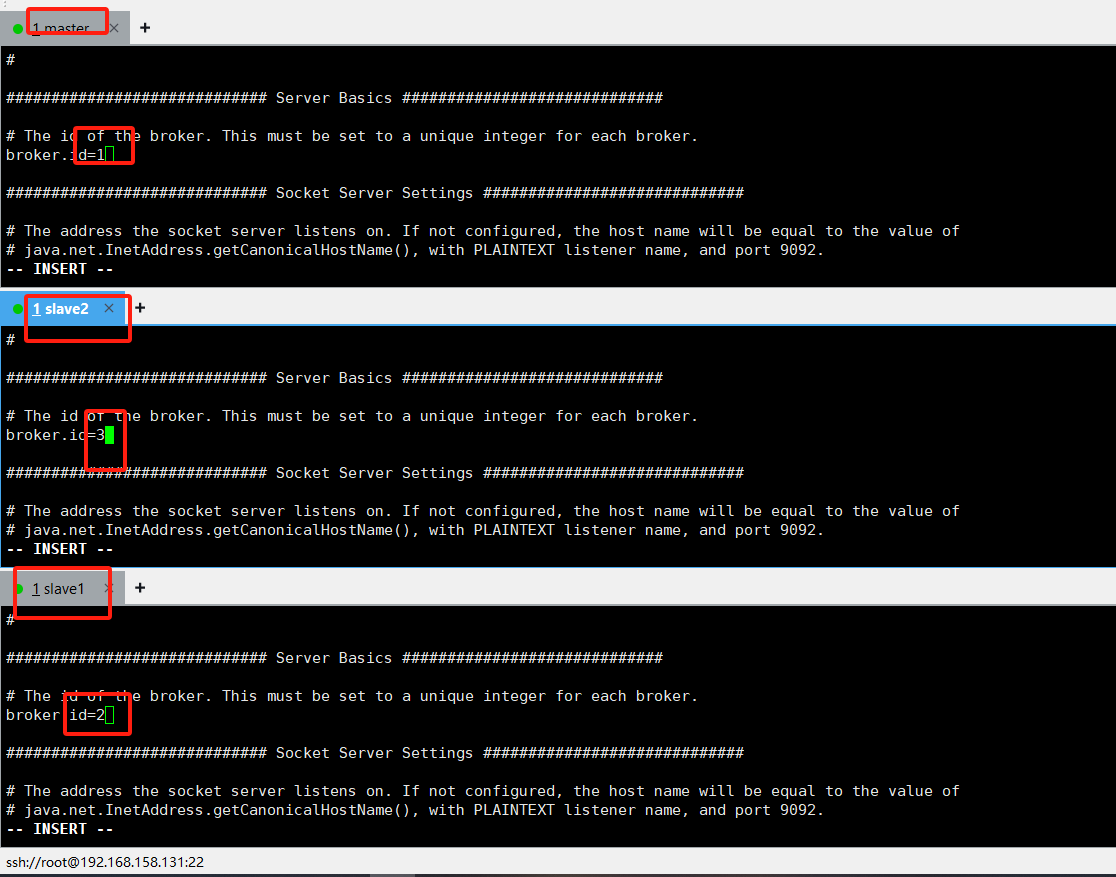
端口配置:9092;端口开放 参考zookeeper集群里面的2181 开放原则;
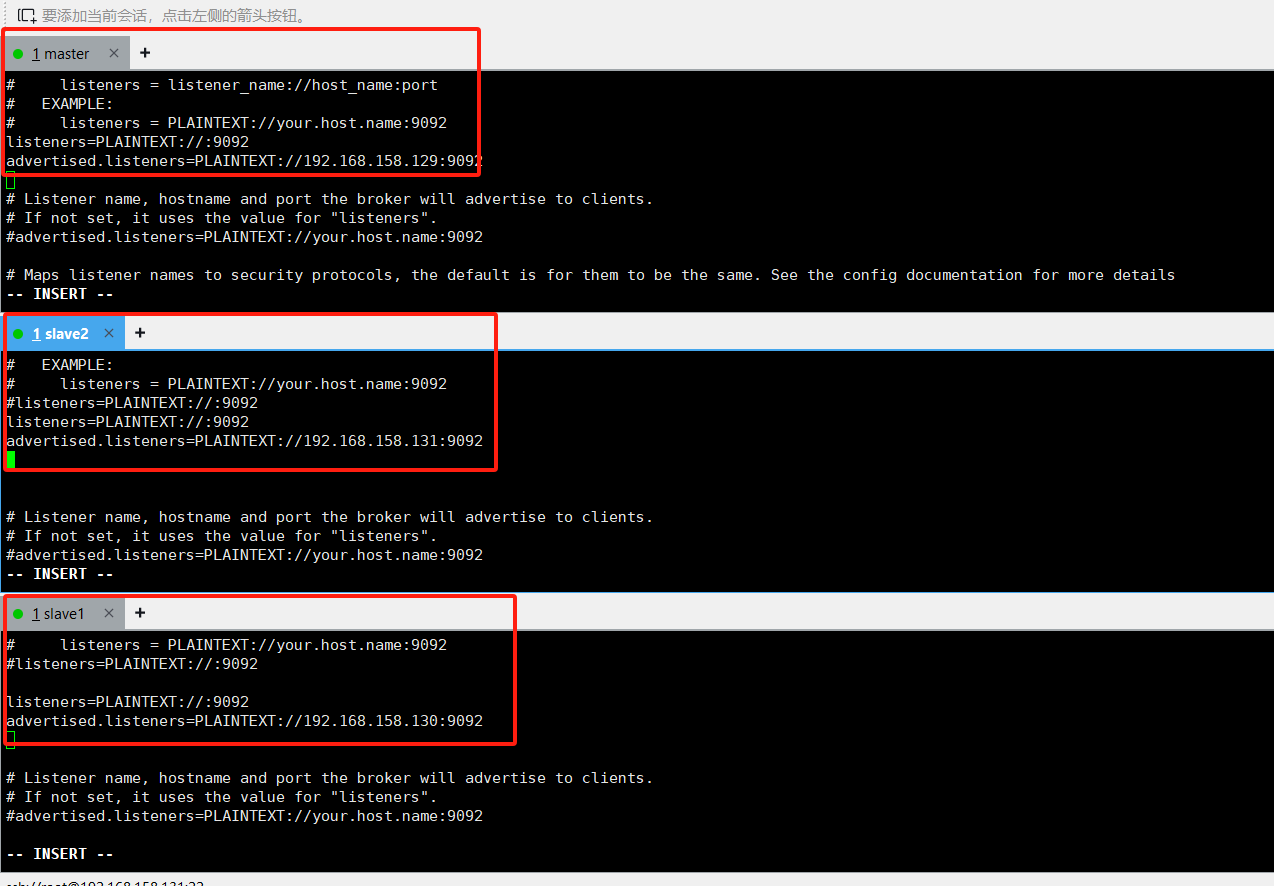
日志存放路径:还是上面的配置里面;三台服务器均要配置存放路径
log.dirs=/soft/kafka/data
配置zookeeper集群地址,还是同一个配置文件里面
zookeeper.connect=192.168.158.129:2181,192.168.158.130:2181,192.168.158.131:2181
6:配置环境变量
分别为三台服务器配置kafka环境变量
vi /etc/profileexport KAFKA_HOME=/soft/kafkaexport PATH=$PATH:$KAFKA_HOME/bin重新载入环境变量
source /etc/profile7:编写启动脚本
创建集群启动sh脚本;在/soft/allSh目录下面 创建
vi kafkaCluster.sh#!/bin/bashcase $1 in\"start\"){ #遍历集群所有机器for i in 192.168.158.129 192.168.158.130 192.168.158.131 do#控制台输出日志echo =============kafka$i 启动====================#启动命令ssh $i \"/soft/kafka/bin/kafka-server-start.sh -daemon /soft/kafka/config/server.properties\"done};;\"stop\"){for i in 192.168.158.129 192.168.158.130 192.168.158.131 doecho =============kafka $i 停止====================ssh $i \"/soft/kafka/bin/kafka-server-stop.sh\"done};;\"status\"){for i in 192.168.158.129 192.168.158.130 192.168.158.131 doecho =============查看 kafka $i 状态====================ssh $i \"netstat -nalpt | grep 9092 \"done};;esac给执行脚本授权
chmod +777 kafkaCluster.sh 操作命令
启动:./kafkaCluster.sh start
停止:./kafkaCluster.sh stop
查看:./kafkaCluster.sh status
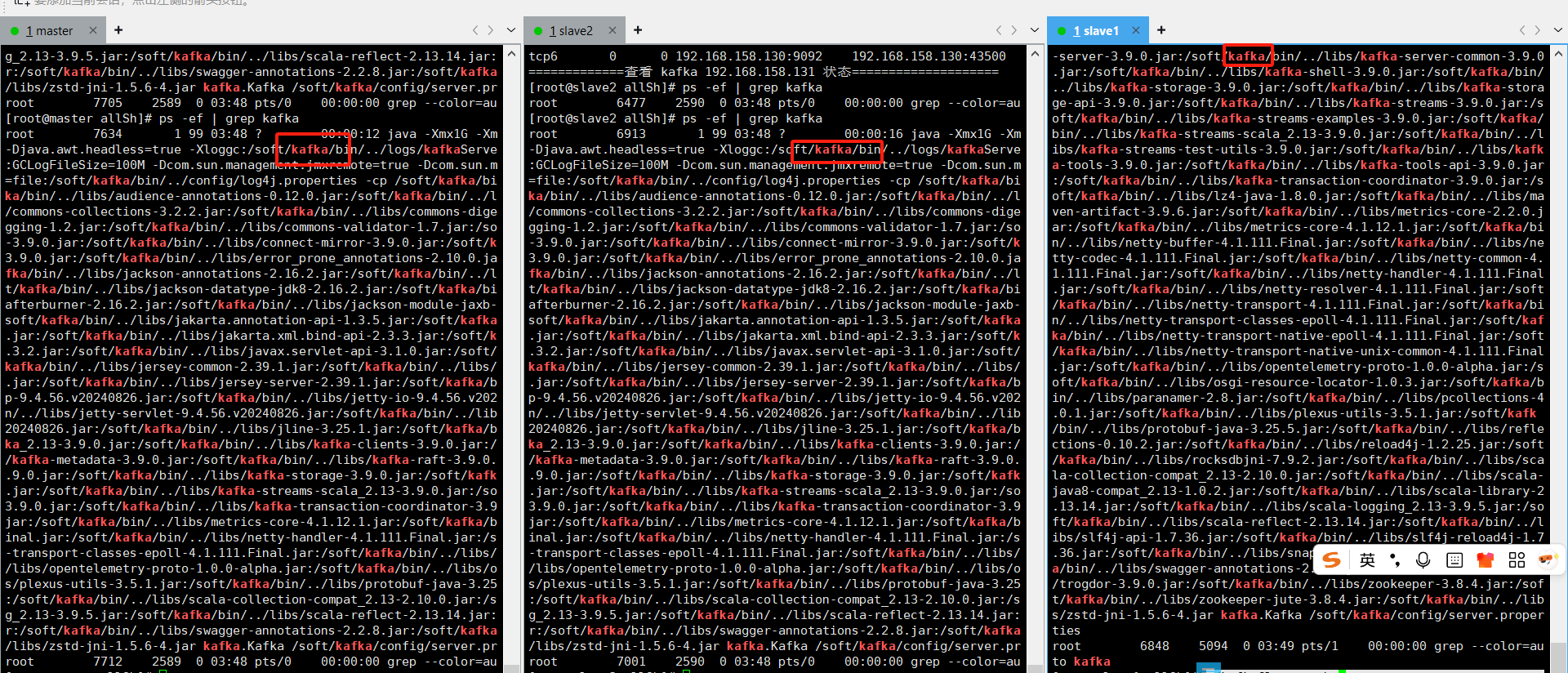
集群到此结束,如有疑问可以留言,欢迎一起探讨

