全球图生视频AI模型排名出炉!Seedance 1.0夺冠,Gen4垫底_seedance1.0模型
一张静态的老照片竟能“活”过来!梵高笔下的星空也开始流转!手机里孩子三岁时的照片,也能眨着眼睛爬向镜头!这些场景因多模态图生视频技术的发展,正在一步步变成现实。图生视频 AI 模型正以前所未有的速度突破静态图像的边界,赋予其动态的生命力与叙事能力。
但究竟哪家模型能最精准地“读懂”画面意图,并施展最流畅、最符合物理规律的“动态魔法”?
AGI-Eval 评测社区对 Vidu Q1、Kling 2.0、PixVerse V4、Gen-4、Video-01等十大图生视频模型进行了测评。
评测主要考察模型依据输入图片生成动态视频的能力。它们不仅要挑战“让图片动起来”的基础能力,更要在“一致性”“视频质量”“运动质量”三大维度上分出高下,是哪些模型能精准复刻图片细节又不失动态美感?又有哪些模型会翻车?

本次评测为人工评测,评测结果显示,Seedance 1.0 等国产模型霸榜前几名,而Pika、Gen4 等海外模型则排名垫底。
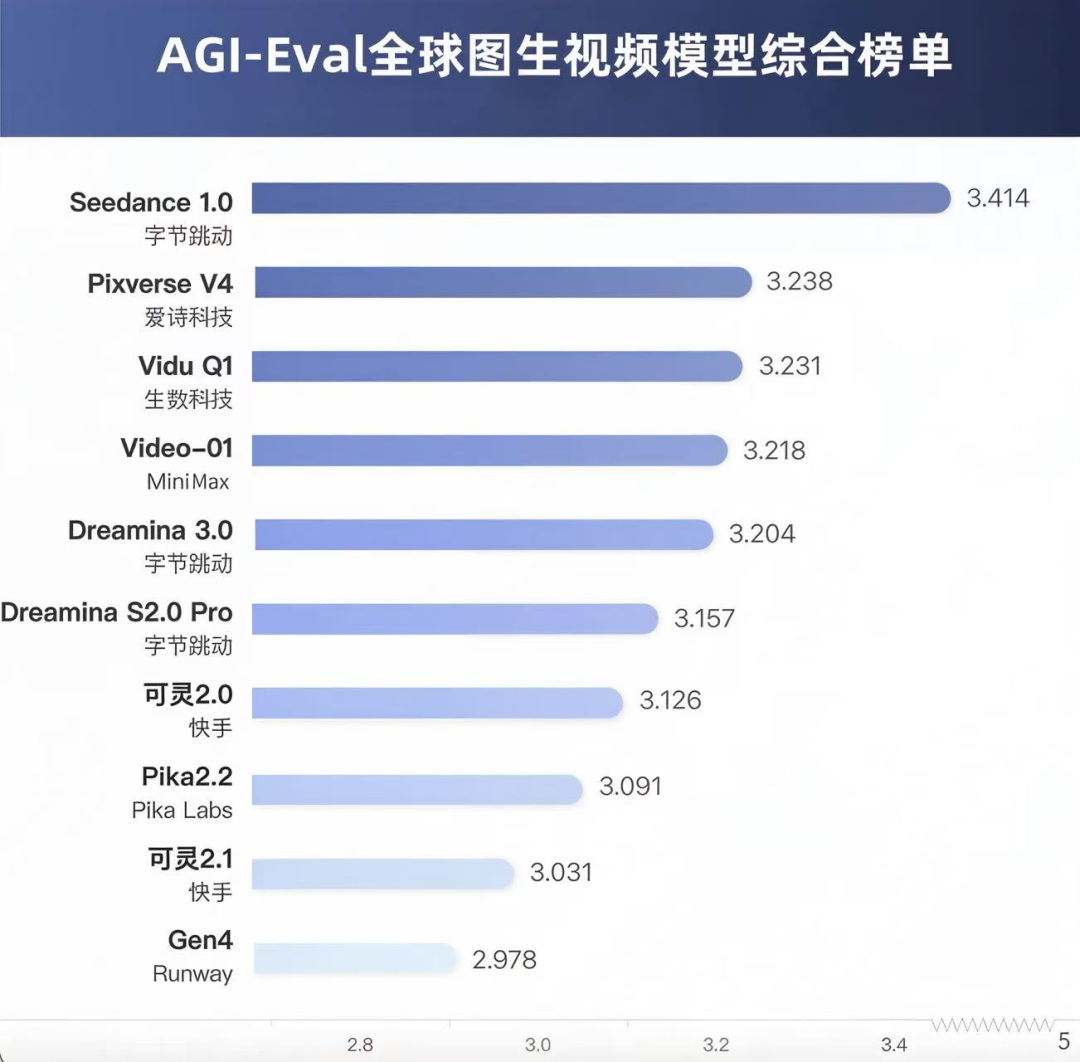
△各模型综合得分和 Ranking 图
下面就一起查看图生视频模型的评测维度以及这些模型的真实表现吧!
01. 评测维度与数据
本次图生视频评测为人工评测形式,评估内容主要考察模型在保持首帧图片内容与风格一致性的前提下,依据图片生成能响应文本 Prompt 附加指令(图片视频一致性与文本视频一致性)、高视觉质量、高运动质量的视频能力:
-
视频/图片一致性:评估视频整体内容是否忠实于首帧图片(文本 Prompt 有额外要求除外)。
-
视频/文本一致性:评估视频内容是否忠实于文本 Prompt 描述。
-
视觉质量:评估视频的视觉呈现效果包括是否符合物理客观规律、真实风格下的画面现实感,倾向于判断视频运动与客观物理世界对比的合理性。
-
运动质量:评估视频是否产生应有的动态效果、动态流畅度和连贯性是否有明显问题、动态效果是否自然等。
首帧参考图的类型应覆盖面广,参考能力项在风格、内容、质量(高质量、常规质量)上尽可能多样化,覆盖真实摄影、水墨画、3D 动画等 10 余种风格,包含商品、美食、人物、风景、动物、植物等各种内容,用最贴近用户需求的视角,为你拆解图生视频技术的“现在进行时”。具体分类如下:

02. 评测结果明细
2.1 人工评测榜单
人工评测关注视频图片一致性、视频文本一致性、视频质量、运动质量。为了得到符合用户主观感受的评估结果,评测社区对各模型在人工评测白盒数据上进行了 5 档 MOS 分的人工评测,各模型得分归一化后的分值结果如下:
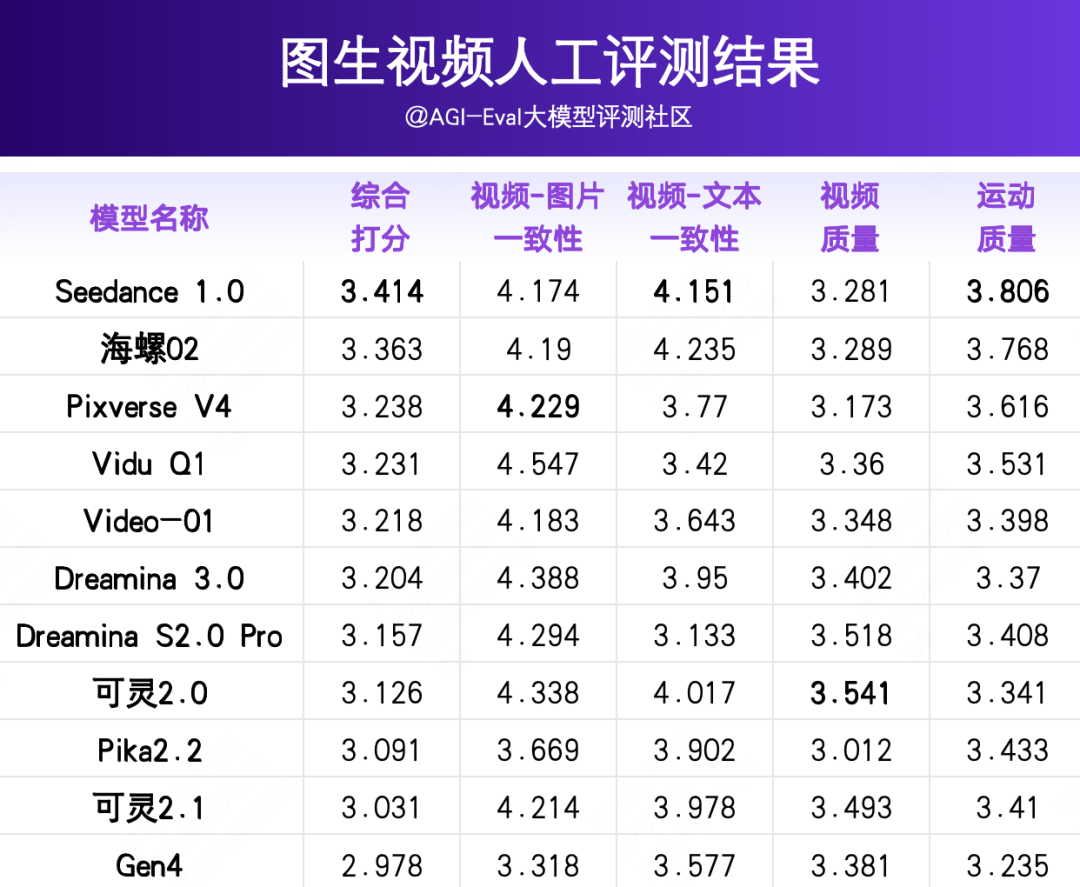
△计算逻辑:单参考图最终分数=详细 Prompt 分数*0.35+简略 Prompt*0.35+矛盾 Prompt*0.15+空 Prompt*0.15
-
在整体梯度上,Seedance 1.0(得分3.414)>海螺02(得分3.363)> Pixverse V4(得分3.238)>Vidu Q1(得分3.231)> Video-01(得分3.218)> Dreamina 3.0(得分3.204)> Dreamina S2.0 Pro(得分3.157)> 可灵2.0(得分3.126)>Pika2.2(得分3.091)> 可灵2.1(得分3.031)> Gen4(得分2.978)。
-
第一梯队模型:Seedance 1.0 在当前榜单中排名断档第一,优势在于运动质量(最高分 3.806)和视频文本一致性(第一高 4.151),但视频质量(3.281)是相对短板的维度,没有超过自家上代的 Dreamina 3.0 和 Dreamina S2.0 Pro。
-
第二梯队模型:包含 Pixverse V4、Vidu Q1、Video-01 和 Dreamina 3.0。其中 PixVerse V4 优势在于运动质量(最高分3.616)和视频文本一致性(第二高3.770),但视频质量(3.173)是相对短板的维度,仅高于 Pika 2.2。PixVerse V4 和 Vidu Q1 的综合分差仅 0.007,基本处于同一水平。
-
倒数梯队模型:Gen4 与其他模型差距较大(比均值低0.169)。
2.2 人工评测分维度榜单
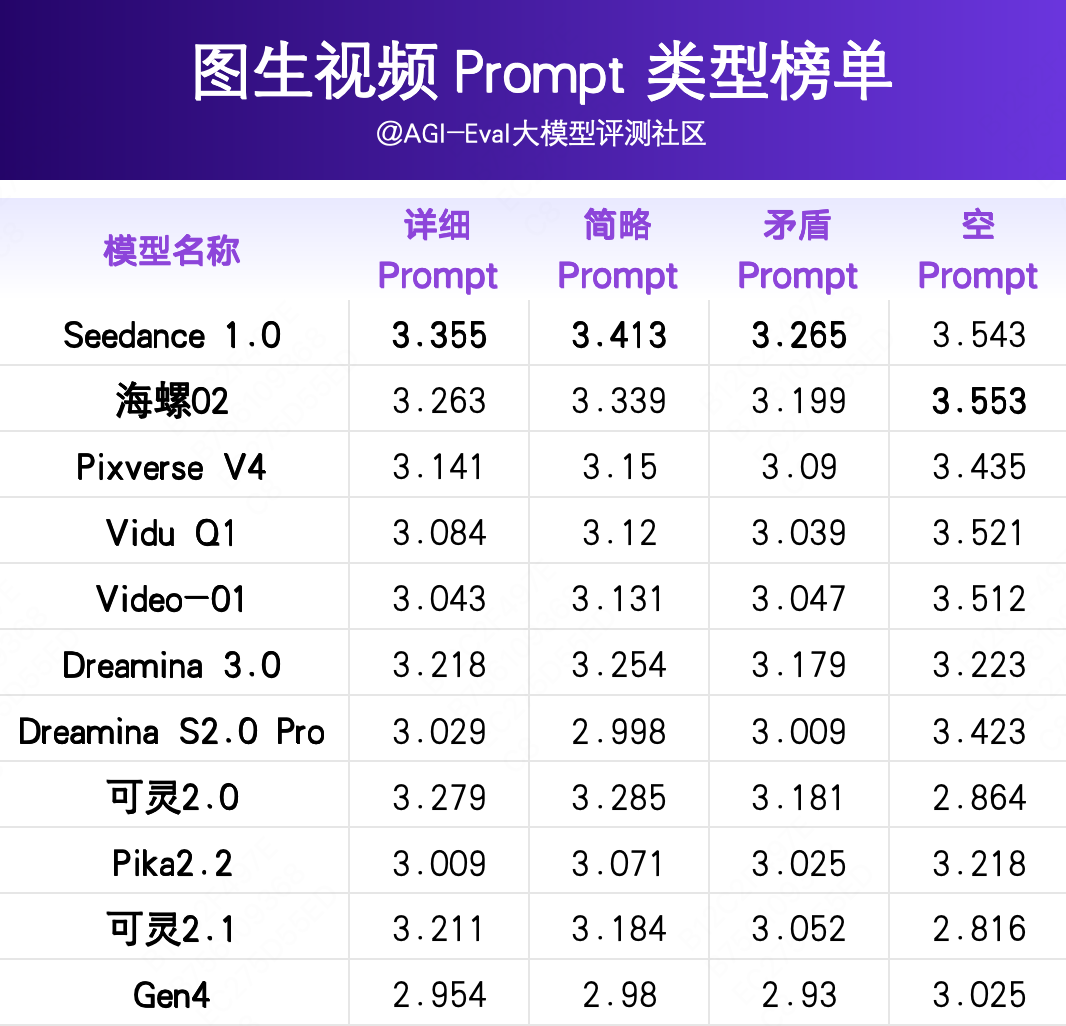
在人工评测中,为考察模型对 Prompt 的敏感性和依赖性,同一首帧参考图对应多个不同类型的 Prompt,分为以下4类:
-
参考图 + 细节具体的 Prompt
-
参考图 + 简略的 Prompt
-
参考图 + 与参考图不一致/存在矛盾的 Prompt
-
参考图 + 空 Prompt
-
Seedance 1.0 整体最优,且在所有提示类型下表现均衡(分数范围3.265–3.543),在空 Prompt 下最强(3.543),适合开放场景应用,在矛盾 Prompt 下表现相对较弱。
-
Pixverse V4 在所有提示类型下表现均衡(分数范围 3.090–3.435),空 prompt 能力强(得分 3.435),适合开放场景应用,在矛盾 Prompt 下(得分 3.090)表现相对较弱。
-
可灵 2.0 与可灵 2.1 在详细 Prompt 、矛盾 Prompt 和简略 Prompt 下表现尚可,得分仅次于 Seedance 1.0。但却在空 Prompt 能力上,出现明显能力塌陷(得分 2.864),得分低于模型平均分,表现为图生视频的内容完全静止。
首帧图:

可灵 2.0 在空 Prompt 提示下的生成结果:

即梦 3.0 在空 Prompt 提示下的生成结果:

空 Prompt 下的“静止陷阱”,暗示着脱离文本指令后,AI 对画面内在生命力的感知仍显苍白。
03. 评测案例
决定视频生成成败有三大核心维度:视频与图片、视频与文本的一致性(是否精准还原想象)、视频质量(画面清晰度、细节、美观度)以及运动质量(动作是否自然流畅、符合物理规律)。
理论分数固然重要,但模型的真实能力终究要在具体场景中见真章。 当一张张静态图片被赋予动态指令,模型的“理解力”与“执行力”便面临严峻考验:它们能否精准还原画面精髓?动作是否流畅自然?物理规则是否被遵守?下面,就让我们通过几组直观的对比案例,揭开头部与尾部模型在“一致性”、“视频质量”和“运动质量”这三大核心维度上的真实差距。
3.1 一致性
Prompt:镜头拉远,更多的莲花和莲叶出现在画面中,莲叶是绿色的,莲花是粉色的。
首帧图:

生成效果:Seedance1.0 > Piki2.2 > Gen4
Seedance1.0:视频与 Prompt 中的文字具有一致性,既满足了“莲花粉色”,也满足了“荷叶绿色”的要求,画面过渡自然,画面的清晰度、美观度也较高。
,时长00:05
Piki2.2:视频与 Prompt 中的文字具有一致性,但画面过渡较为生硬。
,时长00:05
Gen4:改变了首帧图中的主体,将水墨风格的荷花与荷叶变成了仅有荷叶,画面过渡生硬,与 Prompt 中的文字不一致,未能满足“莲叶绿色”的要求,在画面的清晰度、美观度方面都有待提高。
,时长00:05
3.2 视频质量
Prompt:汽车在行驶,风在吹,鸟儿在飞翔。
首帧图:

生成效果:Seedance1.0 > viduQ1 > 可灵2.1
Seedance1.0:汽车行驶、鸟儿飞翔符合运动轨迹,从“女孩头发的飘动”可以感受到 Prompt 中的“风在吹”,视频质量较高。
,时长00:05
viduQ1:从背景物体移动来看表明车辆是在行驶的,但车辆从视频来看行驶态不明显;背景与车辆的动态逻辑不太合理,视频质量不高。
,时长00:05
可灵2.1:汽车行驶符合运动轨迹;飞翔的鸟儿与人物的面部产生了一定的畸变;画面从蓝白底色过渡成为绿色,生硬不自然。
,时长00:05
3.3 运动质量
Prompt:一个穿着T恤、戴着白色鸭舌帽的男子走向停靠在画面中间的车子,上车后坐在驾驶位,镜头从车辆左侧移动到车辆前方,随后向前推进,最后画面定格于坐在车里的男子。
首帧图:

生成效果:Seedance1.0 > viduQ1 > Piki2.2
Seedance1.0:骑自行车女人、戴鸭舌帽的男子,各主体的运动自然流畅,符合现实世界物理规则,镜头视角也满足了 Prompt 中的要求。但戴鸭舌帽男子上车的动作较为奇怪,仍然有优化空间。
,时长00:05
viduQ1:产生了一定的运动畸变,视频中“上车后坐在驾驶位”这一动作与真实世界极为不符。
,时长00:05
Piki2.2:视频中女子的自行车消失、女子变成了“穿着T恤、戴着白色鸭舌帽的男子”,从前方玻璃车窗中上车,白色车辆自行调转方向……都极不符合真实世界,并产生了一些运动畸变,但满足了 Prompt 中镜头方向一定的要求。
,时长00:05
总结
我们不仅见证了多模态图生视频技术的突破性进展,更欣喜地看到国产模型已在这场技术竞赛中领跑全球——从评测榜单可见,Seedance 1.0、PixVerse V4 等国产模型以显著优势霸榜,而 Pika 2.2、Gen4 这类海外模型则遗憾垫底,国产图生视频技术已实现从“跟跑”到“领跑”的跨越。
风的流速、重力的牵引、肌肉的舒展……这些人类习以为常的“常识”,恰恰是 AI 最难跨越的。从这场多模态图生视频的评测结果可见,国产图生视频模型展现出了显著的技术优势,整体表现已超越海外模型,引领着该领域的发展。但图生视频模型在一致性、运动质量、视频质量距离完美复刻人类想象仍有差距,视频质量的短板、对指令的弱响应,都在诉说着技术前行的桎梏。
当 AI 能读懂图片并“编”出合理动态时,我们离“让每一张照片都讲出故事”的未来,或许只差一次技术落地的关键帧。图生视频的终极目标从不是“替代人类创作”,而是成为“延伸人类想象的工具”:让摄影师用静态构图预设动态叙事,让画家以草图勾勒分镜灵感,让孩子用涂鸦“导演”属于自己的童话……随着评测指标的完善、数据规模与多样性的拓展,图生视频模型或许终将打破「静态到动态」的次元壁,让每一张图片都成为无限故事的起点。
以上就是本次评测的全部内容, AGI-Eval 大模型评测社区持续关注现在大模型行业的发展,持续探寻 AGI 的发展之路。关于模型的更多评测内容敬请关注我们!
— 完 —

