Python与WebDriver自动化测试配置指南
本文还有配套的精品资源,点击获取 
简介:本文详细介绍了如何结合Python和WebDriver进行网页自动化操作,涵盖了Python开发环境的搭建、包管理工具pip的安装和使用、selenium库的安装以及ChromeDriver等WebDriver的选择和配置。通过这些步骤,读者可以编写并运行Selenium脚本,自动化控制浏览器以进行网页操作,这在Web应用测试和数据抓取方面非常实用。 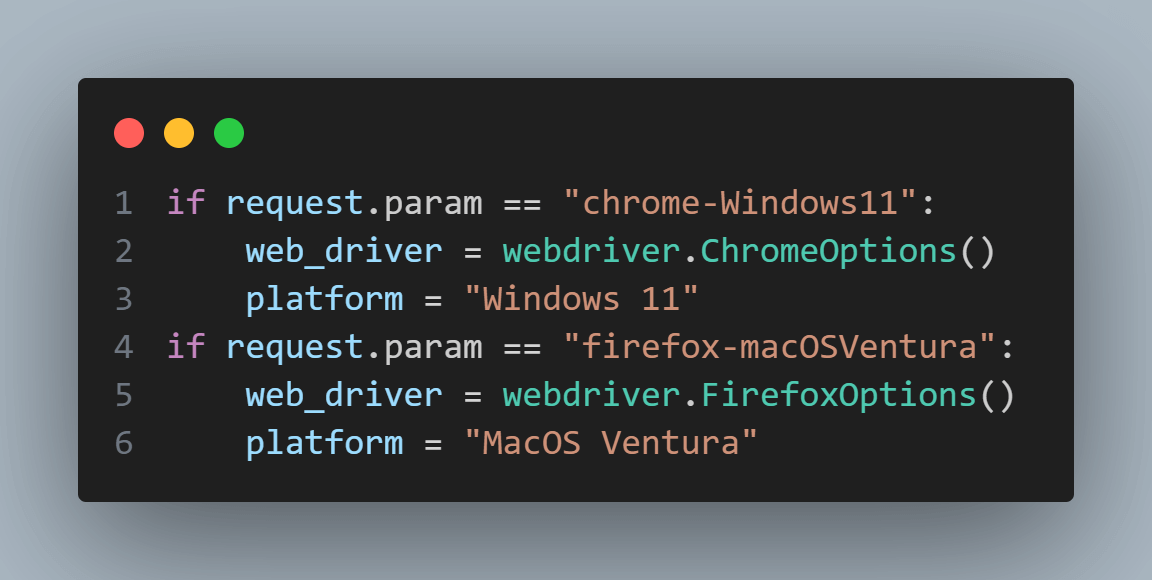
1. Python开发环境搭建
在本章中,我们将详细介绍如何从零开始搭建一个适合Python开发的工作环境。这不仅包括Python解释器的安装,还包括开发工具、依赖管理和代码编辑器的配置,确保你的开发过程既高效又顺畅。
1.1 Python安装
Python安装是开发环境搭建的第一步。对于大多数操作系统而言,我们可以从Python的官方网站下载最新版本的安装包,并遵循安装向导完成安装。需要注意的是,我们建议同时安装 virtualenv 工具,它可以帮助我们管理不同项目的依赖环境。
1.2 开发工具的配置
安装完Python解释器后,选择一个合适的代码编辑器或者集成开发环境(IDE)是至关重要的。在Python开发中, Visual Studio Code , PyCharm , 和 Sublime Text 都是不错的选择。每种工具都有其特色功能,例如 PyCharm 提供了对代码分析和调试的深入支持,而 VS Code 则因其高度的可定制性而受到许多开发者的喜爱。
1.3 依赖管理和虚拟环境
Python的包管理工具 pip 允许我们轻松地安装和管理第三方库。为了避免不同项目间依赖的冲突,推荐使用 virtualenv 来创建隔离的环境。通过以下命令可以安装 virtualenv :
pip install virtualenv随后,可以创建一个虚拟环境,并激活它:
virtualenv venv# 激活虚拟环境取决于操作系统 以上步骤为Python开发环境的搭建奠定了基础。从第二章开始,我们将深入探讨如何使用 pip 来管理和优化你的Python项目。
2. Python包管理工具pip安装与使用
2.1 pip的基本概念和作用
2.1.1 pip的安装和配置
在Python的世界中,pip(Python package installer)是不可或缺的工具。它负责安装、升级、配置和卸载Python包。它是Python默认的包管理系统,可以通过命令行界面方便地进行各种操作。在安装Python时,pip通常会自动配置好,但是有时需要手动安装或验证pip是否已正确安装。
对于Windows系统,可以通过以下步骤来安装pip:
# 1. 下载 get-pip.py 脚本curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py# 2. 运行 get-pip.py 脚本以安装或升级 pippython get-pip.py# 3. 验证 pip 是否安装成功pip --versionLinux或Mac系统则通常不需要单独安装pip,因为它们可能是通过内置的包管理器(如Ubuntu的apt-get)安装的Python的一部分。
安装完成后,可能需要对pip进行一些配置,比如设置国内镜像源来提高下载速度,具体方法如下:
# 设置国内镜像源pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple配置完成后,使用pip安装包时会从镜像源下载,这样可以显著提高下载速度。
2.1.2 pip的使用方法和技巧
pip安装Python包的基本命令是:
pip install package_name如果需要卸载已安装的包,可以使用:
pip uninstall package_name包的更新可以通过以下命令完成:
pip install --upgrade package_name 除了基本的安装和卸载,pip还有一些有用的选项: - -v 或 --verbose :显示详细执行过程,有助于调试。 - -q 或 --quiet :不输出执行过程。 - --no-cache-dir :不使用缓存,直接从源安装。 - --user :只在用户目录下安装包,而不是全局安装。
示例:安装并查看版本,确认包已正确安装:
# 安装 requests 包pip install requests# 查看 requests 包的版本pip show requests这些方法和技巧是pip中最常用的,了解和掌握它们对于高效的包管理至关重要。
2.2 Python包的安装和管理
2.2.1 常用Python包的安装方法
在Python开发中,安装一些常用的包能极大提高开发效率。例如, requests 用于发起网络请求, numpy 用于科学计算等。安装这些包的命令形式如下:
pip install requests numpy pandas可以一次安装多个包,使用空格分隔每个包名。
如果需要安装特定版本的包,可以通过 == 指定版本号:
pip install requests==2.25.1如果系统中已安装该包的其他版本,pip会自动处理依赖关系并升级或降级至指定版本。
2.2.2 包的更新、卸载和依赖管理
随着项目的进展,可能会发现需要更新已安装的包来获得新的功能或修复缺陷。更新包可以使用:
pip install --upgrade requests卸载包使用:
pip uninstall requests 在某些情况下,包之间的依赖关系可能变得复杂。如果卸载或更新一个包会破坏其他包的依赖关系,pip会阻止这一操作。在这种情况下,可以使用 --ignore-installed 参数强制安装一个已存在的版本:
pip install --ignore-installed requests 此外,使用 requirements.txt 文件可以管理项目依赖,这是一种常见的依赖管理方式。在文件中列出所有需要的包及其版本号,通过以下命令安装:
pip install -r requirements.txt这保证了所有开发者和部署环境中的依赖一致,有助于减少因环境不同造成的bug。
通过本节的介绍,我们了解了pip安装和管理Python包的基本操作。掌握了这些方法,可以更高效地管理项目依赖,从而专注于代码开发本身。
3. Selenium库的安装
3.1 Selenium库的作用和特性
3.1.1 Selenium库在自动化测试中的应用
在Web自动化测试领域,Selenium 是一款非常受欢迎的框架。它支持自动化测试浏览器中的各种操作,如点击按钮、输入文本、导航页面等,使测试人员能够快速模拟用户交互,验证Web应用的正确性。Selenium 自身不执行任何自动化测试任务,而是提供一个用于编写测试脚本的API,这些脚本可以用来与浏览器进行交云,并检查Web页面的各个方面是否符合预期。
3.1.2 Selenium库的主要功能和特性
Selenium库支持多种编程语言,如Java、Python、C#、Ruby等,但以Python使用最为广泛。其主要功能包括:
- 跨浏览器测试:Selenium可以与多种浏览器配合,如Chrome、Firefox、Edge等。
- Web应用的UI自动化:通过Selenium,可以自动化执行浏览器端的各种操作,如填写表单、搜索文本、上传文件等。
- 集成持续集成系统:如Jenkins、Travis CI等,使自动化测试成为持续集成流程的一部分。
- 支持多种操作系统平台:Windows、Linux、Mac等,确保Web应用在不同环境下的兼容性。
3.2 Selenium库的安装和配置
3.2.1 Selenium库的安装方法
Selenium库在Python中的安装非常简单,可以通过Python的包管理工具pip来完成安装。打开命令行工具,并执行以下命令:
pip install selenium此命令会下载Selenium库及其依赖,并安装到Python环境中。
3.2.2 Selenium库的配置和使用
安装完成后,需要下载对应浏览器的WebDriver,这是一段能够与浏览器进行交云的程序。以Chrome为例,需要下载ChromeDriver,并确保其路径添加到系统的环境变量中,或者在代码中指定路径。
以下是一个简单的Python脚本,展示如何导入Selenium库并初始化ChromeDriver:
from selenium import webdriver# 指定ChromeDriver的路径chromedriver_path = \'/path/to/chromedriver\'# 创建一个Chrome浏览器实例driver = webdriver.Chrome(executable_path=chromedriver_path)# 打开一个网页driver.get(\'http://www.example.com\')# 关闭浏览器driver.quit() 在上述代码中,首先导入了 webdriver 模块,然后创建了一个Chrome浏览器的实例,并通过 get 方法打开了指定的URL。最后,通过 quit 方法关闭了浏览器实例。
为了确保代码执行的连贯性,建议在使用Selenium时,先了解Python的基础知识,包括面向对象编程和基本的库使用。同时,了解HTML和CSS选择器的知识也有助于更高效地定位页面元素。
从Selenium的安装到基本使用,我们可以看到一个清晰的操作路径:首先,通过pip安装Selenium库;其次,下载对应的WebDriver,并配置到系统或代码中;最后,通过简单的Python脚本演示如何启动和控制浏览器。这个流程的每个步骤都有其目的,并为自动化测试的深入打下了基础。随着学习的深入,我们将在后续章节中探讨Selenium更多的高级特性,如页面元素定位、等待机制、测试用例的组织等。
4. WebDriver的选择与配置
4.1 WebDriver的作用和特性
4.1.1 WebDriver的原理和工作方式
WebDriver是一种用于自动化的工具,它允许开发者编写脚本来控制浏览器行为。它的工作原理基于浏览器驱动,浏览器驱动负责与浏览器通信,解释WebDriver的命令,并将其转化为浏览器能够理解的操作。WebDriver API是标准化的,因此与特定的浏览器驱动无关,开发者可以使用相同的命令控制不同的浏览器。
WebDriver的工作方式如下: 1. 客户端与服务端通信 :客户端(通常是用户的自动化脚本)发送操作指令到服务端(浏览器驱动)。 2. 服务端解释指令 :浏览器驱动接收指令,并将其转换为浏览器能够执行的操作。 3. 浏览器执行操作 :浏览器执行具体的操作,如打开一个页面、查找元素、点击按钮等。 4. 返回结果 :浏览器将操作结果返回给驱动,驱动再传递给客户端。
WebDriver通过这种方式,能够模拟用户在浏览器中的各种操作,实现自动化的网页测试和操作。
4.1.2 WebDriver支持的浏览器和特性
不同的浏览器有自己的WebDriver实现,每个浏览器的WebDriver都有其特定的支持特性和限制。主流的WebDriver包括:
- ChromeDriver :支持谷歌浏览器(Google Chrome)的自动化。
- GeckoDriver :支持火狐浏览器(Mozilla Firefox)的自动化。
- SafariDriver :支持苹果Safari浏览器的自动化。
- Internet Explorer Driver :支持微软的Internet Explorer浏览器的自动化。
每种WebDriver都有一些特定的特性,例如,ChromeDriver支持Chrome浏览器的一些高级特性,如模拟移动设备视图。而GeckoDriver提供了对于Firefox附加组件的支持。在选择WebDriver时,需要考虑目标浏览器版本的兼容性,以及浏览器提供的特性是否满足自动化测试的需求。
4.2 WebDriver的选择与配置
4.2.1 如何选择合适的WebDriver
选择合适的WebDriver首先要确定目标浏览器。依据测试需求和目标用户群体使用的浏览器占比,通常会首先选择主流浏览器的WebDriver。比如,如果目标用户主要使用Chrome,那么ChromeDriver应该是首选。
以下是选择WebDriver时应考虑的因素: - 浏览器版本 :确保WebDriver与目标浏览器版本兼容。 - 测试需求 :根据测试案例的需求选择具有所需特性的WebDriver。 - 自动化框架兼容性 :确认WebDriver与使用的自动化测试框架兼容。 - 操作系统兼容性 :确保WebDriver支持目标操作系统。 - 社区支持和文档 :选择社区活跃、文档齐全的WebDriver以获得更好的支持。
4.2.2 WebDriver的配置方法和技巧
配置WebDriver一般包括下载对应的浏览器驱动程序、设置环境变量以及在自动化脚本中初始化WebDriver。以下是配置WebDriver的步骤:
- 下载WebDriver :
- 访问对应浏览器的WebDriver下载页面。
-
选择与你的浏览器版本相匹配的驱动程序版本下载。
-
设置环境变量 :
- 将下载的WebDriver可执行文件路径添加到系统环境变量中,确保可以从命令行中访问。
- 在Windows系统中,可能需要配置系统变量
PATH;在Linux或MacOS中,使用export命令添加路径。
bash # Linux or MacOS example export PATH=$PATH:/path/to/your/webdriver
- 在脚本中初始化WebDriver :
```python from selenium import webdriver
# 设置chromedriver的路径 chromedriver_path = \'/path/to/chromedriver\' # 初始化webdriver driver = webdriver.Chrome(executable_path=chromedriver_path) # 导航至目标网页 driver.get(\"http://www.example.com\") ```
在上述代码中,我们首先从 Selenium 库导入了 webdriver 模块,然后设置了 chromedriver 的路径,并实例化了 Chrome 类来创建浏览器驱动对象。最后,使用 get 方法导航到了示例网站。
- 运行脚本前的检查 :
- 确保已经安装了所有必要的依赖库。
- 在运行脚本之前进行手动测试,验证WebDriver是否正确配置。
通过以上步骤,可以完成WebDriver的选择与配置,并顺利进行自动化测试。在实际的使用过程中,可能还会遇到各种问题,需要根据具体情况调整和优化配置策略。
5. Selenium脚本编写与运行
5.1 Selenium脚本的基本结构和语法
5.1.1 Selenium脚本的基本结构
Selenium脚本通常由以下几个基本部分组成:
- 导入模块:必须的模块导入,如selenium中的webdriver。
- 测试设置:包括浏览器选择、驱动程序加载和目标网站打开。
- 功能实现:是测试的核心部分,包含各种操作网页元素和获取测试结果的代码。
- 测试结果:通常是输出日志或写入到文件中。
下面是一个简单的Selenium脚本示例:
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysdriver = webdriver.Chrome() # 创建一个Chrome浏览器实例driver.get(\"http://www.python.org\") # 打开目标网站assert \"Python\" in driver.title # 检查页面标题中是否含有\'Python\'elem = driver.find_element_by_name(\"q\") # 找到搜索框elem.clear() # 清空输入elem.send_keys(\"pycon\") # 输入关键词elem.send_keys(Keys.RETURN) # 模拟回车键操作assert \"No results found.\" not in driver.page_source # 检查页面源代码中是否含有特定文字driver.close() # 关闭浏览器窗口5.1.2 Selenium脚本的关键语法和使用方法
-
定位元素:
find_element_by_*和find_elements_by_*方法用于定位单个或多个元素。常见的定位方式有ID、NAME、CSS选择器、LINK_TEXT、PARTIAL_LINK_TEXT、TAG_NAME、CLASS_NAME和XPATH。 -
交互操作:通过调用元素的方法进行点击、输入文本、选择下拉菜单、提交表单等交互。
-
等待机制:Selenium提供了两种等待方式,即隐式等待和显式等待。隐式等待适用于等待某个条件发生,而显式等待提供了更灵活的等待条件。
-
断言操作:Selenium的断言用于验证网页的状态或内容,常用的断言方法有
assert_title、assert_text等。 -
异常处理:对可能发生的错误进行捕获和处理,使用try-except语句块来处理Selenium可能抛出的异常。
下面是一个使用显式等待的例子:
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECdriver = webdriver.Chrome()driver.get(\"http://example.com\")try: element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, \"myDynamicElement\")) )finally: driver.quit()5.2 Selenium脚本的编写与运行
5.2.1 Selenium脚本的编写技巧和注意事项
- 代码模块化:将重复使用的代码编写成函数或类,提高代码的复用率。
- 使用合适的等待:合理地使用显式等待可以提高脚本的稳定性,避免因元素未加载完成而引发错误。
- 考虑异常处理:在脚本中加入异常处理逻辑,使脚本在出错时能够提供更多的调试信息。
- 关注执行速度:避免不必要的等待和操作,使用更高效的方法完成同样的任务。
- 代码清晰易懂:使用有意义的变量名和注释来确保其他人或者未来的你可以轻易理解代码的含义。
5.2.2 Selenium脚本的运行方法和技巧
- 本地运行:确保本地安装了相应浏览器的WebDriver并配置环境变量,然后直接运行Python脚本。
- 持续集成工具:利用Jenkins、GitLab CI等持续集成工具设置自动化测试流程。
- 云测试平台:利用Sauce Labs、BrowserStack等云平台进行跨浏览器测试。
- 并行测试:同时运行多个测试脚本以加速测试过程。
- 报告生成:使用如Allure、TestNG等工具生成详细的测试报告。
下面是一个使用Python的 unittest 框架与Selenium结合进行测试的例子:
import unittestfrom selenium import webdriverclass PythonOrgSearch(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome() self.driver.implicitly_wait(10) self.driver.get(\"http://www.python.org\") def test_search_in_python_org(self): search_box = self.driver.find_element_by_name(\'q\') search_box.send_keys(\'pycon\') search_box.send_keys(Keys.RETURN) assert \"No results found.\" not in self.driver.page_source def tearDown(self): self.driver.quit()if __name__ == \'__main__\': unittest.main()运行上述测试脚本,即可实现一个基于Selenium的Python.org搜索测试用例。
6. Python自动化网页操作实例
自动化网页操作是自动化测试和数据采集中常见的需求。使用Python进行自动化网页操作可以显著提高效率和准确性。本章将围绕自动化网页操作的基本思路和方法,以及通过实例来具体解析实现步骤。
6.1 Python自动化网页操作的基本思路和方法
6.1.1 自动化网页操作的基本思路
在自动化网页操作之前,我们首先需要理解基本的操作思路。一般来说,操作包括以下几个步骤:
- 打开目标网页。
- 执行特定的元素查找(如点击、输入文本等)。
- 收集网页上的数据或验证某些信息。
- 关闭浏览器或打开新页面进行下一个操作。
理解这些基本思路有助于我们更好地编写自动化脚本。
6.1.2 常见网页操作的自动化方法
对于常见的网页操作,我们可以借助Selenium提供的API来实现自动化。以下是一些常见的操作方法:
- 页面导航 :使用
driver.get(url)来打开一个新的页面。 - 元素定位与操作 :通过
find_element_by_*系列函数来定位页面上的元素,之后可以使用click(),send_keys(),submit()等方法来模拟用户的点击和输入等操作。 - 数据收集 :获取元素的文本信息或其他属性,可以通过
get_attribute()方法。 - 等待机制 :由于页面加载速度不一,使用显式等待(
WebDriverWait)和隐式等待(time.sleep())来确保元素加载完成。 - 异常处理 :自动化过程中不可避免地会遇到元素无法找到等问题,使用try-except结构进行错误捕获和处理。
6.2 实际案例解析
接下来,我们将通过一个具体的例子,展示如何使用Selenium进行自动化网页操作。
6.2.1 实际案例的自动化实现
假设我们要自动化实现一个简单的登录流程,以下是实现步骤:
- 环境准备 :
- 确保已安装Python、Selenium库以及对应的WebDriver。
- 导入所需的Selenium模块。
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as EC- 初始化WebDriver :
driver = webdriver.Chrome() # 或使用其他浏览器driver.get(\"http://example.com/login\") # 打开登录页面- 定位元素并进行操作 :
username = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.NAME, \"username\")))password = driver.find_element_by_name(\"password\")username.send_keys(\"testuser\")password.send_keys(\"testpass\")password.send_keys(Keys.RETURN)- 数据收集和验证 :
# 假设页面跳转后有一个登录成功的提示信息success_message = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CLASS_NAME, \"success\")))assert \"登录成功\" in success_message.text- 结束自动化操作 :
driver.quit() # 关闭浏览器6.2.2 案例中的问题和解决方案
在实际操作中可能会遇到各种问题,例如:
- 元素未找到 :可能是因为页面还未加载完成,这时可以使用WebDriverWait配合expected_conditions来等待元素可操作。
- 元素定位方式 :不同的元素定位方式(如ID、NAME、CLASS_NAME等)需要根据页面元素的属性来选择。
- 动态元素处理 :页面中某些元素可能是动态加载的,需要先等待父容器加载完成再进行操作。
通过上述案例,我们可以看到自动化网页操作的基本流程和实现方法。在实际应用中,我们可能需要根据具体的网页结构和需求来调整脚本的细节。
本文还有配套的精品资源,点击获取
简介:本文详细介绍了如何结合Python和WebDriver进行网页自动化操作,涵盖了Python开发环境的搭建、包管理工具pip的安装和使用、selenium库的安装以及ChromeDriver等WebDriver的选择和配置。通过这些步骤,读者可以编写并运行Selenium脚本,自动化控制浏览器以进行网页操作,这在Web应用测试和数据抓取方面非常实用。
本文还有配套的精品资源,点击获取

