命令行输入输出重定向编程实现
本文还有配套的精品资源,点击获取 
简介:本教程介绍如何控制命令行输入输出流,将其重定向到当前进程。涉及操作系统级别的I/O重定向和管道原理,包括标准输入、标准输出和标准错误的重定向方法,以及管道的使用。在C语言等编程环境中,通过调用操作系统API(如Windows API的CreateProcess函数)来实现对进程输入输出的控制。这对于自动化任务、数据处理、日志管理等具有重要意义。
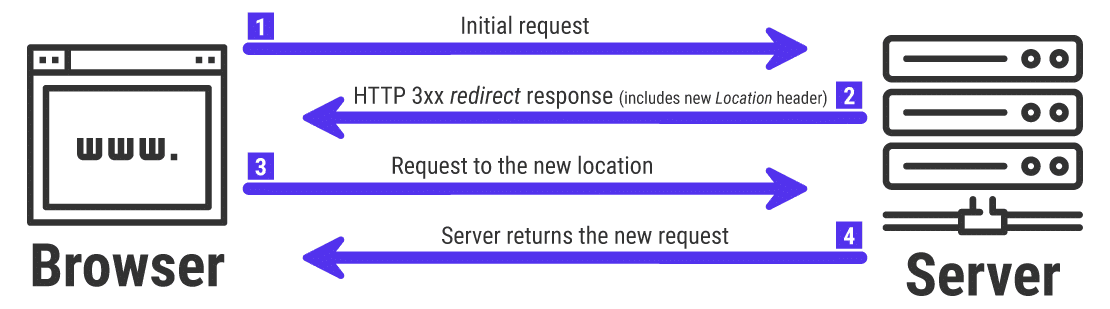
1. I/O重定向概念介绍
在计算机系统中,I/O重定向是一种强大的特性,允许程序将数据从标准输入(stdin)、标准输出(stdout)和标准错误(stderr)传输到不同的位置。它不仅提高了程序的灵活性,还使得命令行用户能够对程序的输入输出进行精细控制。
1.1 I/O重定向的基础知识
I/O重定向允许用户将文件、命令输出或者输入信息重新定位到不同的位置。例如,可以将一个命令的输出保存到文件中而不是显示在屏幕上,或者从文件读取输入而不是从键盘。
1.2 I/O重定向的常见用途
在日常的开发和运维工作中,I/O重定向常用于数据备份、日志记录、自动化脚本的编写等。它不仅优化了工作流程,也提高了数据处理的效率。
# 示例:将命令输出重定向到文件ls > directory_list.txt 在这个例子中, ls 命令的输出被重定向并保存在 directory_list.txt 文件中,而不是直接打印到终端屏幕。这样,我们就可以轻松地创建文件系统的备份或者用于后续的数据分析。
2. 标准输入(stdin)的重定向方法
2.1 标准输入重定向基础
2.1.1 输入重定向的定义
输入重定向是操作系统中一个简单却强大的特性,它允许程序从不同于键盘的标准输入设备接收输入。它提供了一种方式,将文件内容、其他程序的输出或者用户自定义的数据流作为输入传递给程序。在许多情况下,输入重定向被用于批处理任务、自动化测试和简化用户与程序的交互。
2.1.2 输入重定向的类型和应用场景
输入重定向通常分为两种类型:单文件输入重定向和多文件输入重定向。单文件输入重定向适用于从单个文件中读取数据,而多文件输入重定向适用于同时从多个文件或数据源中读取输入。在编写测试脚本、数据清洗和处理程序时,这些功能特别有用。
2.2 实现标准输入重定向的技术细节
2.2.1 Shell层面上的输入重定向
在Shell层面上,使用输入重定向非常简单。例如,将文件内容重定向到 wc 命令(用于计数字、行和字符):
wc -l < example.txt 这行命令将 example.txt 文件的行数输出。符号 < 是输入重定向操作符,它告诉Shell将 example.txt 的内容传递给 wc -l 命令。
2.2.2 C语言层面的输入重定向
在C语言中,可以通过标准库函数如 freopen() 来实现输入重定向:
#include int main() { // 打开文件并重定向标准输入 freopen(\"example.txt\", \"r\", stdin); char buffer[100]; // 从文件读取数据 fgets(buffer, 100, stdin); printf(\"Read from file: %s\", buffer); fclose(stdin); // 关闭重定向的文件,恢复标准输入 return 0;} 这段代码将标准输入重定向到 example.txt 文件,并从文件中读取一行数据。使用完毕后, fclose(stdin); 可以关闭文件并恢复标准输入。
2.2.3 其他编程语言的输入重定向实现
几乎所有的现代编程语言都提供了输入重定向的支持。在Python中,可以使用 sys.stdin 重定向输入流:
import sys# 将标准输入重定向到文件sys.stdin = open(\'example.txt\', \'r\')line = sys.stdin.readline()print(\'Read from file:\', line)sys.stdin.close() # 关闭文件并重置标准输入# 以下代码使用原始的标准输入original_input = input(\"Enter something: \")print(\"Original input:\", original_input) 在上述Python脚本中,我们首先将 sys.stdin 重定向到 example.txt 文件,然后读取该文件的一行数据。之后,关闭文件并恢复标准输入。
通过以上章节,我们可以看到输入重定向的概念和基础用法,以及在不同编程语言中的实现。这些技术细节为IT专业人士提供了一种高效、灵活处理输入数据的方式,特别适用于需要批处理或自动化处理大量数据的场景。下一章节将探讨标准输出(stdout)的重定向方法,这将进一步扩展我们对输入输出重定向技术的理解。
3. 标准输出(stdout)的重定向方法
3.1 标准输出重定向基础
3.1.1 输出重定向的定义
标准输出重定向是一种将程序或命令的标准输出信息传输到非标准输出设备或文件的过程。在操作系统中,标准输出通常对应着屏幕或终端。通过重定向,我们可以改变输出目的地,例如保存到文件、另一个程序或设备等。这种机制极大地增强了程序的灵活性,允许我们控制输出的流向,并将输出内容用于进一步处理或分析。
3.1.2 输出重定向的类型和应用场景
输出重定向主要有以下几种类型:
-
>:将标准输出重定向到文件。如果文件已存在,将会被覆盖。 -
>>:将标准输出追加到文件。如果文件不存在,将创建文件。 -
2>:将标准错误也重定向到标准输出的位置。 -
2>&1:将标准错误和标准输出合并到同一位置。 -
|:管道重定向,将一个命令的标准输出作为另一个命令的标准输入。
输出重定向在数据处理、日志记录、自动化脚本中非常常见。例如,将程序的输出保存到日志文件中进行事后分析,或者在构建自动化测试时,将输出重定向到文件以便检查。
3.2 实现标准输出重定向的技术细节
3.2.1 Shell层面上的输出重定向
在Shell层面上,输出重定向是通过Shell提供的重定向运算符实现的。这些运算符可以改变命令行中程序的输出目的。
例如,将 ls 命令的输出重定向到一个文件:
ls > listing.txt 如果 listing.txt 文件已存在,上述命令会覆盖原有内容。使用 >> 运算符可以追加内容:
ls >> listing.txt 这里是一个使用 2> 的例子,将标准错误重定向到标准输出的位置:
some_command 2> error.log或者将标准错误和标准输出合并到同一个文件:
some_command > output.log 2>&13.2.2 C语言层面的输出重定向
在C语言中,输出重定向可以通过修改标准库函数的行为来实现。通常,我们可以使用 freopen 函数来改变 stdin 、 stdout 和 stderr 的默认流目的地。例如:
#include int main() { // 重定向stdout到文件 FILE *fp = fopen(\"output.txt\", \"w\"); if (fp != NULL) { freopen(\"output.txt\", \"w\", stdout); // 重定向stdout到fp printf(\"Hello, World!\\n\"); fclose(fp); } return 0;}此外,C语言程序可以通过创建子进程和使用管道技术来实现输出重定向。
3.2.3 其他编程语言的输出重定向实现
在其他编程语言中,如Python或Ruby,也有类似的机制来实现输出重定向。以Python为例,可以使用 sys.stdout 来实现:
import syswith open(\'output.txt\', \'w\') as f: old_stdout = sys.stdout # 保存原始stdout sys.stdout = f # 重定向stdout到文件 print(\"Hello, World!\") # 输出将被写入文件 sys.stdout = old_stdout # 恢复原始stdout 这段代码会将 print 函数的输出重定向到 output.txt 文件中。
表格和流程图展示
为了更好地理解输出重定向的类型和用法,我们提供一个表格说明:
> ls > listing.txt >> ls >> listing.txt 2> some_command 2> error.log 2>&1 some_command > output.log 2>&1 | ls -l | grep txt 接下来,我们展示一个简单的mermaid流程图,说明重定向过程:
graph LRA[开始] --> B{是否重定向}B -- 是 --> C[打开目标文件]B -- 否 --> D[执行命令]C --> E[改变标准输出目标]E --> DD --> F[命令执行完毕]F --> G[关闭文件]G --> H[结束]以上代码块解释了重定向的基本流程,其中我们首先判断是否需要重定向,然后根据选择执行不同的操作路径。
通过以上的内容,我们可以看到输出重定向在不同层面(命令行Shell、编程语言)中的实现原理与技术细节。利用输出重定向,我们可以有效地管理程序的输出,将数据导出到文件、处理日志或与其他程序进行数据交换。在下一章节,我们将探讨标准错误重定向的方法及其技术细节。
4. 标准错误(stderr)的重定向方法
4.1 标准错误重定向基础
4.1.1 错误重定向的定义和必要性
在Unix-like操作系统中,标准错误(stderr)是标准输出的一个变种,专门用于输出错误信息。当一个程序运行出错时,它会将错误信息输出到stderr,这允许开发者区分正常输出和错误输出。重定向stderr使得我们可以将这些错误信息输出到文件或另一个程序中,而不干扰正常的标准输出(stdout)。
错误重定向是必要的,因为它提供了灵活性,允许程序的输出可以被更细致地管理。比如,在一个脚本中,可以将错误信息统一记录到日志文件中,而将有用的数据流重定向到其他程序或文件进行进一步处理。
4.1.2 错误重定向的类型和应用场景
错误重定向主要有两种类型:
- 将stderr重定向到文件:这允许将错误信息持久化存储,便于后续分析或错误追踪。
- 将stderr重定向到stdout:这将错误信息和正常输出混合在一起,通常用于快速检查程序输出,了解是否存在问题。
应用场景包括但不限于:
- 脚本编程:自动化脚本中通常会将错误信息重定向到日志文件中,便于问题追踪。
- 软件测试:在测试阶段,将错误输出重定向可以帮助测试人员快速定位问题所在。
- 系统监控:通过定期检查错误日志文件,系统管理员可以监控系统运行状况。
4.2 实现标准错误重定向的技术细节
4.2.1 Shell层面上的错误重定向
在Shell命令行中,错误重定向的语法与标准输出重定向类似,但使用特定的文件描述符2表示stderr。例如,要将错误信息重定向到文件error.log中,可以使用以下命令:
command 2> error.log若要同时重定向stdout和stderr到同一个文件,可以使用:
command > output.log 2>&14.2.2 C语言层面的错误重定向
在C语言中,标准错误可以通过 stderr 对象使用,而错误重定向则需利用操作系统的系统调用。例如,在使用 popen 函数来执行外部命令时,可以通过管道来重定向stderr:
#include FILE *fp;fp = popen(\"command 2> error.log\", \"r\");另外,也可以直接使用文件操作函数来重定向stderr:
#include #include int main() { FILE *errlog; int fd = open(\"error.log\", O_CREAT | O_WRONLY, S_IRUSR | S_IWUSR); if (fd == -1) { perror(\"open\"); return -1; } if (dup2(fd, fileno(stderr)) == -1) { perror(\"dup2\"); return -1; } // 从这里开始,所有的stderr输出都会被写入到error.log文件中 fprintf(stderr, \"This is an error message\\n\"); // 关闭文件描述符 close(fd); return 0;}4.2.3 其他编程语言的错误重定向实现
其他编程语言如Python、Java等同样提供了标准错误重定向的功能。以Python为例,可以使用以下方式重定向标准错误:
import subprocess# 使用subprocess模块捕获命令输出with open(\'error.log\', \'w\') as f: subprocess.call(\'command\', stderr=f) 在Java中,可以通过 ProcessBuilder 类来实现:
import java.io.*;public class RedirectError { public static void main(String[] args) throws IOException { ProcessBuilder builder = new ProcessBuilder(\"command\"); builder.redirectError(new File(\"error.log\")); Process process = builder.start(); // 其他处理逻辑... }}重定向错误输出可以帮助开发者更好地管理程序的输出流,无论是为了日志记录、错误处理还是其他目的。这在构建复杂系统时尤其重要,因为它能够使系统的运行信息更加清晰,有助于监控、调试和优化。
5. 管道(Pipeline)的使用和原理
5.1 管道的概念与作用
5.1.1 管道的定义
管道(Pipeline)是Unix-like操作系统中用于进程间通信的一种机制,允许一个进程的输出直接作为另一个进程的输入。管道提供了一种方式,通过这种方式,可以在不同进程间传递数据流,而不需要将数据写入临时文件。这是实现进程间通信(IPC)的一种非常高效的方法。
5.1.2 管道在数据流中的作用
管道的作用在于它允许数据流在系统中的一系列处理步骤中顺利传递,无需等待整个数据集准备完毕才开始处理。这种即时的数据流处理机制,对于设计高效的数据处理系统至关重要。管道在数据流中的具体作用包括:
- 减少磁盘I/O操作,提高处理速度。
- 简化程序设计,因为它允许程序模块化,每个模块专注于一个特定的处理任务。
- 促进程序的并发性,因为可以在不同的处理步骤中并行执行多个进程。
5.2 管道的使用方法
5.2.1 在Shell命令行中的应用
在Shell命令行中,管道是最常用的工具之一,特别是在组合多个命令进行复杂的数据处理时。以下是几种常见的管道使用场景:
示例1:结合 ls , grep , 和 less
假设我们要查看一个目录中的所有 .txt 文件,并且想要以分页形式查看结果:
ls *.txt | grep some_pattern | less 这个命令序列首先列出当前目录下所有的 .txt 文件,然后使用 grep 过滤出包含特定模式的文件名,最后使用 less 以分页方式显示这些文件名。
示例2:使用 awk 进行文本处理
处理文本文件时,我们经常需要从文件中提取特定的数据行,并对其进行格式化处理。例如,假设我们有一个日志文件,并想提取错误信息:
cat log.txt | grep \'ERROR\' | awk \'{print $4}\' 这个命令序列通过 cat 查看日志文件内容,使用 grep 筛选包含”ERROR”的行,然后通过 awk 提取出每行的第四个字段。
5.2.2 管道在编程中的高级应用
在编程中,管道不仅仅局限于命令行。许多编程语言提供了自己的管道机制或库来实现类似的功能。以Node.js为例,它使用流(Streams)来实现类似管道的功能。下面是一个简单的Node.js管道示例:
示例:读取文件内容并通过HTTP响应发送
const fs = require(\'fs\');const http = require(\'http\');http.createServer((req, res) => { // 创建一个可读流来读取文件 const readStream = fs.createReadStream(\'example.txt\'); // 将可读流输出到响应中 readStream.pipe(res);}).listen(3000); 在这个例子中, pipe 方法将一个可读流连接到一个可写流,这里是从文件读取数据并发送到HTTP响应对象。
5.3 管道的高级技术细节
5.3.1 管道的实现机制
管道的实现依赖于操作系统提供的进程间通信机制。在Linux和Unix系统中,管道通常是由特殊的文件系统节点实现的,这些节点称为管道节点或命名管道(named pipe)。进程通过打开这些特殊的文件来创建管道。
5.3.2 管道与Shell脚本的集成
Shell脚本中的管道通常与Shell内置的I/O重定向功能集成。Shell允许我们将一个命令的标准输出重定向到另一个命令的标准输入。当使用管道符号 | 时,Shell会创建一个匿名管道,并将前一个命令的输出直接传输给后一个命令。
5.3.3 管道的性能与限制
管道虽然强大,但也存在一些限制和性能考量。例如,管道只能用于单向通信,并且由于管道数据存储在内存中,因此必须注意内存的使用量。在处理大数据流时,如果没有正确管理,管道可能会耗尽系统的内存资源。
5.4 管道技术的挑战和未来展望
5.4.1 管道在大规模数据处理中的挑战
在处理大规模数据时,管道可能会遇到性能瓶颈,尤其是在网络I/O受限的环境中。当数据量超出单个机器的处理能力时,分布式系统(如Hadoop或Spark)的管道技术就成了一个挑战。
5.4.2 管道技术的未来趋势
随着云计算和容器技术的发展,管道技术也在向更灵活、更高性能的方向发展。例如,Kubernetes的管道操作允许容器间的无缝数据流处理。未来,我们可以预见,管道技术将更加集成在分布式计算框架中,支持更复杂的数据处理任务。
5.5 实际案例分析
5.5.1 管道在数据处理流水线中的应用
在大数据处理中,管道技术被广泛应用于数据处理流水线。例如,在ELT(Extract, Load, Transform)过程中,管道可以用来连接数据的提取、加载和转换步骤,提供一个高效且灵活的数据处理流程。
5.5.2 管道与复杂数据处理算法的结合
在需要处理复杂算法的场景中,管道可以用于算法的不同阶段,允许数据在各个阶段间高效传递。这在机器学习或金融分析等数据密集型行业中尤其重要。
通过本章节的介绍,我们可以看到管道技术在操作系统级和编程级应用的广泛性,以及在实现高效数据处理和数据流管理方面的关键作用。在本章节结束之际,希望读者已经对管道技术有一个全面的认识,且能够有效地在实际项目中应用这一技术。
6. 编程实现命令行输入输出重定向的实战应用
6.1 编程实现重定向的原理
6.1.1 重定向在程序执行中的机制
在操作系统中,每个运行的程序都拥有三个默认的文件描述符:stdin(标准输入),stdout(标准输出)和stderr(标准错误)。重定向的实质是更改这些文件描述符所指向的文件或设备。当一个程序进行输入或输出操作时,它实际上是读写与这些文件描述符相关联的文件。通过修改这些文件描述符的关联,程序的输入和输出可以被重定向到其他文件或设备。
例如,在C语言中,当你使用 scanf 函数时,你的程序默认从stdin读取数据,而当你使用 printf 函数时,数据则默认写入到stdout。你可以通过系统调用来改变这些文件描述符的目标,例如使用 dup2 函数将stdout重定向到一个文件。
#include #include int main() { // 假设我们希望将标准输出重定向到一个名为\"output.txt\"的文件中 int result; int saved_stdout = dup(STDOUT_FILENO); // 备份原始的stdout FILE *fp = fopen(\"output.txt\", \"w\"); result = dup2(fileno(fp), STDOUT_FILENO); // 重定向标准输出到文件 if (result == -1) { perror(\"dup2 failed\"); return 1; } // 现在使用printf将输出到文件而不是终端 printf(\"Hello, world!\\n\"); fflush(stdout); // 确保输出写入到文件 // 恢复标准输出到原始的状态 dup2(saved_stdout, STDOUT_FILENO); fclose(fp); return 0;}6.1.2 重定向在操作系统中的实现
操作系统实现重定向主要依赖于文件描述符的概念。文件描述符是一个用于表述打开文件的抽象化概念,实际上是一种引用计数的链接,指向内核中的一个文件表。每个进程默认打开三个文件描述符:0(stdin),1(stdout),和2(stderr)。
当进行重定向操作时,操作系统修改这些文件描述符指向的文件表条目,将其指向新的目标。例如,当你在shell中运行 ls > listing.txt 命令时,shell将 ls 进程的stdout文件描述符重新指向了 listing.txt 文件。
6.2 实际案例分析
6.2.1 命令行工具开发中的重定向应用
命令行工具经常需要处理来自用户输入的参数以及产生输出到标准输出或文件。以一个简单的 cat 程序为例,它能够将文件的内容复制到标准输出或者复制一个文件到另一个文件。为了实现这样的功能,开发者需要处理文件描述符的复制与重定向逻辑。
使用C语言编写一个简单的 cat 程序,代码如下:
#include #include #include #include int main(int argc, char *argv[]) { if (argc < 2) { dprintf(STDOUT_FILENO, \"Usage: %s \\n\", argv[0]); return 1; } int fd = open(argv[1], O_RDONLY); if (fd == -1) { perror(\"open\"); return 1; } char buffer[128]; ssize_t bytesRead; while ((bytesRead = read(fd, buffer, sizeof(buffer))) > 0) { write(STDOUT_FILENO, buffer, bytesRead); } close(fd); return 0;} 在这个例子中, cat 程序打开指定的文件(用 argv[1] 指定),并读取其内容到缓冲区。然后,它将缓冲区的内容写入到标准输出(即屏幕)。如果想要将内容重定向到另一个文件,可以使用shell命令 ./cat > destination 。
6.2.2 复杂系统中重定向策略的设计与优化
在复杂的系统中,特别是在分布式系统或涉及多个进程间通信的系统中,重定向策略的设计可能变得较为复杂。这种情况下,通常需要一个更为复杂的中间件来管理输入输出流,并能够将数据流重定向到不同的目的地。例如,一个可能的设计思路是使用消息队列或者事件驱动的框架。
在这些系统中,重定向通常与日志管理、故障诊断和性能监控紧密相关。通常,日志管理会使用专门的库来实现输入输出流的重定向。例如,在Java中,使用SLF4J与Logback/Log4j结合使用,可以很灵活地对日志输出进行重定向和格式化。
6.2.3 编写代码时重定向的实践技巧
在编写代码时,理解和运用重定向技巧是十分重要的。这对于提高代码的灵活性和可测试性有着重要意义。以下是一些在代码中实现重定向的实践技巧:
- 测试时重定向输出到日志文件 :在开发和测试阶段,可以重定向标准输出到日志文件中,以便于跟踪程序运行情况。
- 使用单元测试框架模拟输入输出 :许多单元测试框架允许你重定向输入输出流,这样你就可以在测试用例中模拟输入数据并验证输出结果。
- 通过命令行参数或配置文件支持灵活的重定向 :允许用户通过命令行参数或者配置文件指定日志文件的路径或者错误输出的重定向。
例如,在Python中,使用 contextlib 库可以简化输出重定向的实践:
from contextlib import redirect_stdoutdef main(): print(\"This goes to stdout\") print(\"This goes to a file\", file=sys.stderr)with open(\'my_log.txt\', \'w\') as f: with redirect_stdout(f): main() 在这个例子中,我们通过 redirect_stdout 临时地将标准输出重定向到了文件 my_log.txt ,程序中的 print 语句的输出将写入到该文件而不是标准输出。
在程序设计时考虑到重定向的能力,能够极大地提高程序的可维护性和扩展性。这一点无论是在命令行工具的开发还是在大型复杂系统的设计中都是同样适用的。
本文还有配套的精品资源,点击获取
简介:本教程介绍如何控制命令行输入输出流,将其重定向到当前进程。涉及操作系统级别的I/O重定向和管道原理,包括标准输入、标准输出和标准错误的重定向方法,以及管道的使用。在C语言等编程环境中,通过调用操作系统API(如Windows API的CreateProcess函数)来实现对进程输入输出的控制。这对于自动化任务、数据处理、日志管理等具有重要意义。
本文还有配套的精品资源,点击获取

