Datawhale AI夏令营2025 大模型技术领域--task2
一、赛事背景
在电商直播爆发式增长的数字化浪潮下,短视频平台积累了海量带货视频及用户互动数据。这些数据不仅是消费者对商品体验的直接反馈,更蕴含着驱动商业决策的深层价值。在此背景下,基于带货视频评论的用户洞察分析,已成为品牌优化选品策略、评估网红带货效能的关键突破口。
带货视频评论用户洞察的核心逻辑,在于对视频内容与评论数据的联合深度挖掘。通过智能识别视频中推广的核心商品,结合评论区用户的情感表达与观点聚合,企业能够精准捕捉消费者对商品的真实态度与需求痛点。这种分析方式不仅能揭示用户对商品功能、价格、服务的多维评价,还可通过情感倾向聚类,构建消费者偏好画像,为选品策略优化和网红合作评估提供数据支撑。
本挑战赛聚焦\"商品识别-情感分析-聚类洞察\"的完整链条:参赛者需先基于视频内容建立商品关联关系,进而从非结构化评论中提取情感倾向,最终通过聚类总结形成结构化洞察。这一研究路径将碎片化的用户评论转化为可量化分析的商业智能,既可帮助品牌穿透数据迷雾把握消费心理,又能科学评估网红的内容种草效果与带货转化潜力,实现从内容营销到消费决策的全链路价值提升。在直播电商竞争白热化的当下,此类分析能力正成为企业构建差异化竞争优势的核心武器。
二、赛事任务
参赛者需基于提供的带货视频文本及评论文本数据,完成以下三阶段分析任务:
1)【商品识别】精准识别推广商品;
2)【情感分析】对评论文本进行多维度情感分析,涵盖维度见数据说明;
3)【评论聚类】按商品对归属指定维度的评论进行聚类,并提炼类簇总结词。
三、评审规则
1.平台说明
参赛选手可基于星火大模型Spark 4.0 Ultra、星火文本向量化模型、其他开源大模型,或采用传统机器学习与深度学习方法完成任务,亦可通过微调开源模型进行洞察分析。
关于星火大模型Spark 4.0 Ultra和文本向量化模型的资源,组委会将为报名参赛选手统一发放API资源福利,选手用参赛账号登录讯飞开放平台个人控制台:控制台-讯飞开放平台 ,点击应用,查询API能力和接口文档。
微调资源不统一发放,参赛期间选手如希望使用讯飞星辰MaaS平台进行微调,可前往讯飞星辰MaaS平台-官网 ,完成实名认证后领取微调代金券资源并开启答题。请注意统一用参赛账号登录星辰MaaS平台;如在比赛前已参与活动则无法重复领取。星辰代金券消耗完毕后,如需继续使用,选手自行选择按需付费。
2.数据说明
本次挑战赛为参赛选手提供包含85条脱敏后的带货视频数据及6477条评论文本数据,数据包括少量有人工标注结果的训练集(仅包含商品识别和情感分析的标注结果)以及未标注的测试集。所有数据均经过脱敏处理,确保信息安全,其格式说明如下:
1)带货视频内容文本信息的数据格式
注:product_name需根据提供的视频信息进行提取,并从匹配到商品列表[Xfaiyx Smart Translator, Xfaiyx Smart Recorder]中的一项。
2)评论区文本信息的数据格式
注:
a.需进行情感分析的字段包括sentiment_category、user_scenario、user_question和user_suggestion。训练集中部分数据已提供标注,测试集需自行预测。其中字段sentiment_category情感倾向分类的数值含义见下表:
b.需进行聚类的字段包括:
- positive_cluster_theme:基于训练集和测试集中正面倾向(sentiment_category=1 或 sentiment_category=3)的评论进行聚类并提炼主题词,聚类数范围为 5~8。
- negative_cluster_theme:基于训练集和测试集中负面倾向(sentiment_category=2 或 sentiment_category=3)的评论进行聚类并提炼主题词,聚类数范围为 5~8。
- scenario_cluster_theme:基于训练集和测试集中用户场景相关评论(user_scenario=1)进行聚类并提炼主题词,聚类数范围为 5~8。
- question_cluster_theme:基于训练集和测试集中用户疑问相关评论(user_question=1)进行聚类并提炼主题词,聚类数范围为 5~8。
- suggestion_cluster_theme:基于训练集和测试集中用户建议相关评论(user_suggestion=1)进行聚类并提炼主题词,聚类数范围为 5~8。
注意,聚类样本包含训练集和测试集的全部满足上述条件的评论样本。
3.评估指标
本挑战赛依据参赛者提交的结果文件,采用不同评估方法对各阶段任务进行评分。最终得分由三部分相加,总分300分。具体评估标准如下:
1)商品识别(100分)
结果采用精确匹配评估,每个正确识别的商品得1分,错误识别的商品得0分。该阶段总评分计算公式如下:

2)情感分析(100分)
结果评估采用加权平均F1-score,衡量分类模型的整体性能。该阶段总评分计算公式如下:
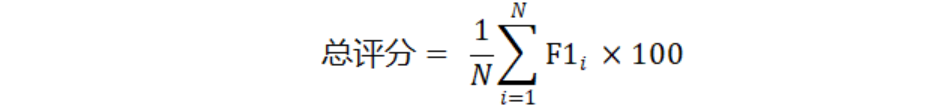
其中F1ᵢ为维度i的分析结果的加权F1-score,N为情感类别总数。
3)评论聚类(100分)
结果评估采用轮廓系数(仅计算商品识别和情感分析均正确的评论聚类结果,计算使用星火文本向量化模型的embedding),衡量聚类结果的紧密性和分离度。该阶段总评分计算公式如下:
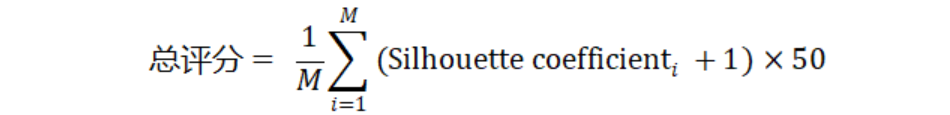
其中Silhouette coefficientᵢ为维度i的聚类结果的轮廓系数,M为需聚类的维度总数。
4.评测及排行
1)本赛题均提供下载数据,选手在本地进行算法调试,在比赛页面提交结果。
请注意:测试集仅可用于输出最终的推理结果,不可以任何形式参与训练过程。
2)排行按照得分从高到低排序,排行榜将选择团队的历史最优成绩进行排名。
四、作品提交要求
1.文件格式:提交submit.zip压缩包文件,内含submit文件夹,文件内为submit_videos.csv(内含字段video_id, product_name)和submit_comments.csv(内含字段video_id, comment_id, sentiment_category, user_scenario, user_question, user_suggestion, positive_cluster_theme, negative_cluster_theme, scenario_cluster_theme, question_cluster_theme, suggestion_cluster_theme)文件
2.文件大小:无要求
3.提交次数限制:每支队伍每天最多3次
4.文件详细说明:编码为UTF-8,第一行为表头
5.关于大模型的使用说明&限制
1)为了排除人工校验、修正等作弊方式,本次比赛除了提交答案之外,排行榜前3名选手需提供完整的源代码,要求洞察分析结果必须可以准确复现。
2)允许使用微调开源模型的方式进行洞察分析,微调的开源模型不做限制。
五、基于Baseline的优化
原先聚类模块的代码中,设定的聚类种数n=2不符合赛题要求(5-8个) 。同时,为了尽可能地提高聚类效果,可以考虑在5-8的聚类种数范围内对聚类数量动态调整,并分别选取三种指标进行判别,从而选取出相对来讲效果最佳的聚类数量参数。
1.使用轮廓系数自动选择最优聚类数
轮廓系数衡量样本与其所在聚类的紧密程度以及与其他聚类的分离程度,值越接近 1 表示聚类效果越好
from sklearn.metrics import silhouette_score# 定义要尝试的聚类数量范围cluster_range = range(5, 9) # 例如从2到10个聚类best_score = -1 # 轮廓系数范围是[-1, 1],初始化为最小值best_n_clusters = 2# 筛选数据filtered_comments = comments_data[comments_data[\"sentiment_category\"].isin([1, 3])][\"comment_text\"]# 对每个聚类数量进行评估for n in cluster_range: # 创建并训练模型 pipeline = make_pipeline( TfidfVectorizer(tokenizer=jieba.lcut), KMeans(n_clusters=n, random_state=42) ) pipeline.fit(filtered_comments) # 计算轮廓系数 cluster_labels = pipeline.predict(filtered_comments) if len(set(cluster_labels)) > 1: # 确保聚类数>1(轮廓系数要求) score = silhouette_score(pipeline.named_steps[\'tfidfvectorizer\'].transform(filtered_comments), cluster_labels) if score > best_score: best_score = score best_n_clusters = nprint(f\"最优聚类数量: {best_n_clusters},轮廓系数: {best_score:.4f}\")# 使用最优聚类数重新训练模型2.手肘法(Elbow Method)
手肘法通过计算不同聚类数下的惯性(Inertia,样本到其所属聚类中心的距离平方和),选择 “手肘点”(曲线急剧变缓的点)作为最优聚类数。
import matplotlib.pyplot as plt# 定义要尝试的聚类数量范围cluster_range = range(5, 9)inertia_values = []# 筛选数据filtered_comments = comments_data[comments_data[\"sentiment_category\"].isin([2, 3])][\"comment_text\"]# 计算不同聚类数下的惯性for n in cluster_range: pipeline = make_pipeline( TfidfVectorizer(tokenizer=jieba.lcut), KMeans(n_clusters=n, random_state=42) ) pipeline.fit(filtered_comments) inertia = pipeline.named_steps[\'kmeans\'].inertia_ inertia_values.append(inertia)# 可视化手肘曲线plt.plot(cluster_range, inertia_values, \'o-\')plt.xlabel(\'聚类数量\')plt.ylabel(\'惯性\')plt.title(\'手肘法选择最优聚类数\')plt.show()# 自动选择手肘点(简化版:选择二阶导数最大的点)diffs = [inertia_values[i] - inertia_values[i+1] for i in range(len(inertia_values)-1)]second_diffs = [diffs[i] - diffs[i+1] for i in range(len(diffs)-1)]best_n_clusters = cluster_range[second_diffs.index(max(second_diffs)) + 1]print(f\"通过手肘法选择的最优聚类数量: {best_n_clusters}\")# 使用最优聚类数重新训练模型(后续代码同上)3.Calinski-Harabasz 指数
Calinski-Harabasz 指数衡量类间离散度与类内离散度的比值,值越大表示聚类效果越好。
from sklearn.metrics import calinski_harabasz_score# 定义要尝试的聚类数量范围cluster_range = range(5, 9)best_score = 0best_n_clusters = 2# 筛选数据filtered_comments = comments_data[comments_data[\"user_scenario\"].isin([1])][\"comment_text\"]# 计算不同聚类数下的Calinski-Harabasz指数for n in cluster_range: pipeline = make_pipeline( TfidfVectorizer(tokenizer=jieba.lcut), KMeans(n_clusters=n, random_state=42) ) pipeline.fit(filtered_comments) cluster_labels = pipeline.predict(filtered_comments) score = calinski_harabasz_score(pipeline.named_steps[\'tfidfvectorizer\'].transform(filtered_comments).toarray(), cluster_labels) if score > best_score: best_score = score best_n_clusters = nprint(f\"最优聚类数量: {best_n_clusters},Calinski-Harabasz指数: {best_score:.4f}\")# 使用最优聚类数重新训练模型(后续代码同上)对于5个聚类模块,分别使用不同的最优聚类数优化方法,最终分数提升了50多分。
六、后续优化思路
后续优化更多考虑针对数据集进行优化。包括数据集内有很多缺失值等等情况,考虑借助开源大模型技术持续性优化数据集。同时,分词器(Baseline中给的是jieba,但是实际上数据集中更多的数据项都不是中文,有不少其他语言,考虑使用MosesTokenizer、spaCy等)。再然后的优化就是基于pipeline的优化了。

