开源ChatBI : SuperSonic技术分析和使用文档
目录
1.项目背景与核心价值
1.1 项目定位
1.2.核心价值
2.技术架构解析
2.1 流程图
2.2 关键技术模块
2.2.1 自然语言处理层
2.2.2 语义解析引擎
2.2.3 可视化引擎
3.安装
3.1下载
3.2 安装
4.使用方法
4.1大模型管理
4.2 数据库管理
4.3 构建语义模型(核心)
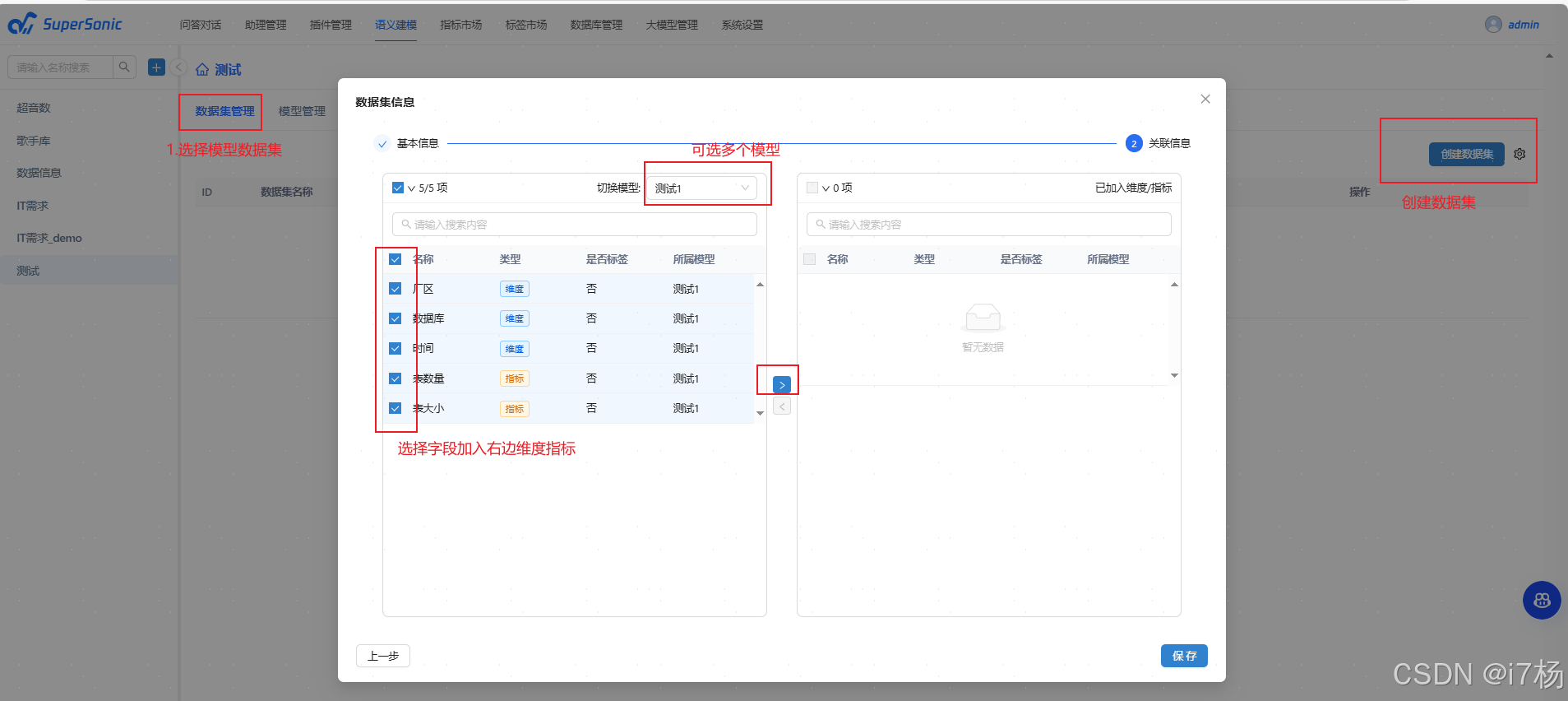
4.3.1创建数据集(原始数据)
4.3.2设置表字段含义
4.3.3 选择模型字段加入数据集
4.4 配置交流助理
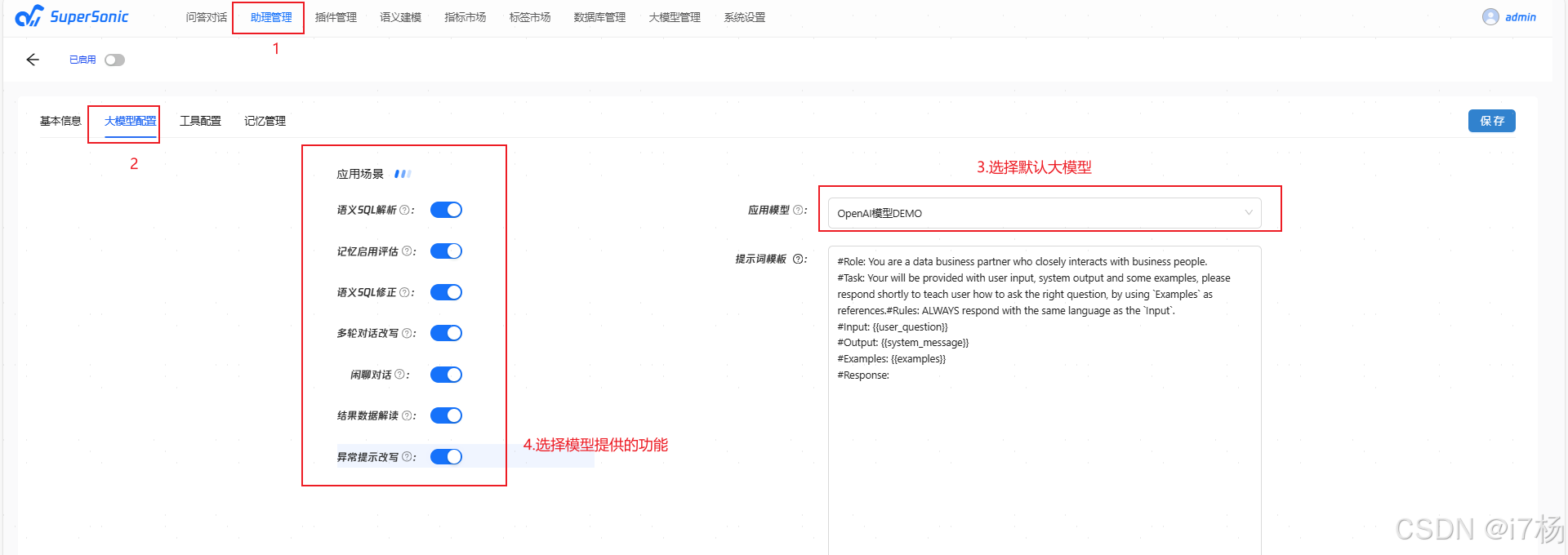
4.4.1选择默认大模型
4.4.2 选择文本转SQL插件
4.5 交流测试
4.6 使用总结
5.性能指标
6.总结
6.1优势总结
6.2使用建议
目标:寻找到一个可用的语言交流智能BI,可以提供准确的数据交流服务。
1.项目背景与核心价值
1.1 项目定位
Supersonic是一款基于大语言模型(LLM)的对话式商业智能(ChatBI)开源工具,旨在通过自然语言交互降低数据分析门槛,实现从数据查询到可视化洞察的端到端自动化。
1.2.核心价值
零代码交互:业务人员无需SQL技能,通过自然语言对话完成数据分析。
多源支持:支持MySQL、PostgreSQL、ClickHouse等多种数据源,可以自定义链接器。
智能可视化:自动生成图表并给出分析建议(如趋势预测、异常检测)。
开源可扩展:Apache 2.0协议,支持插件化开发与私有化部署。
2.技术架构解析
2.1 流程图
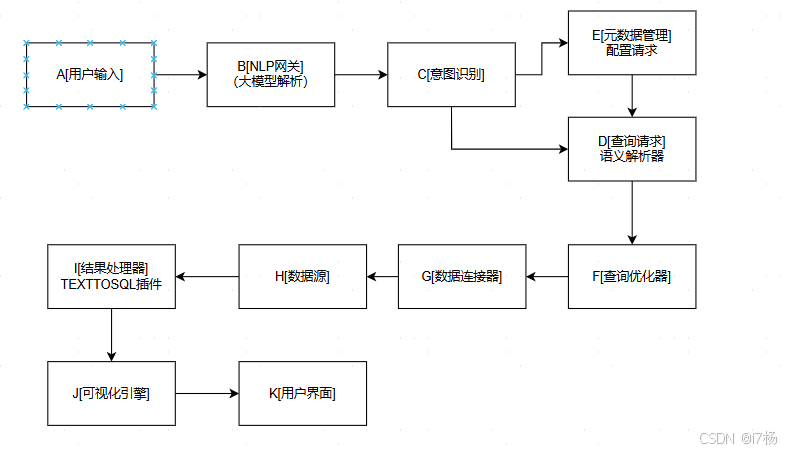
2.2 关键技术模块
2.2.1 自然语言处理层
意图识别模块:基于微调的BERT模型(准确率>92%)
实体抽取:BiLSTM-CRF + 领域词典增强
多轮对话管理:基于状态机的上下文跟踪(DST)
2.2.2 语义解析引擎
Text2SQL:基于模板的混合方法(LLM生成 + 语法校验)
查询优化:
自动方言适配(MySQL -> PostgreSQL)
联邦查询下推(通过Apache Calcite)
2.2.3 可视化引擎
自动图表推荐:基于字段类型和统计特征的规则引擎
交互式叙事:通过Vega-Lite生成可复用的可视化模板
3.安装
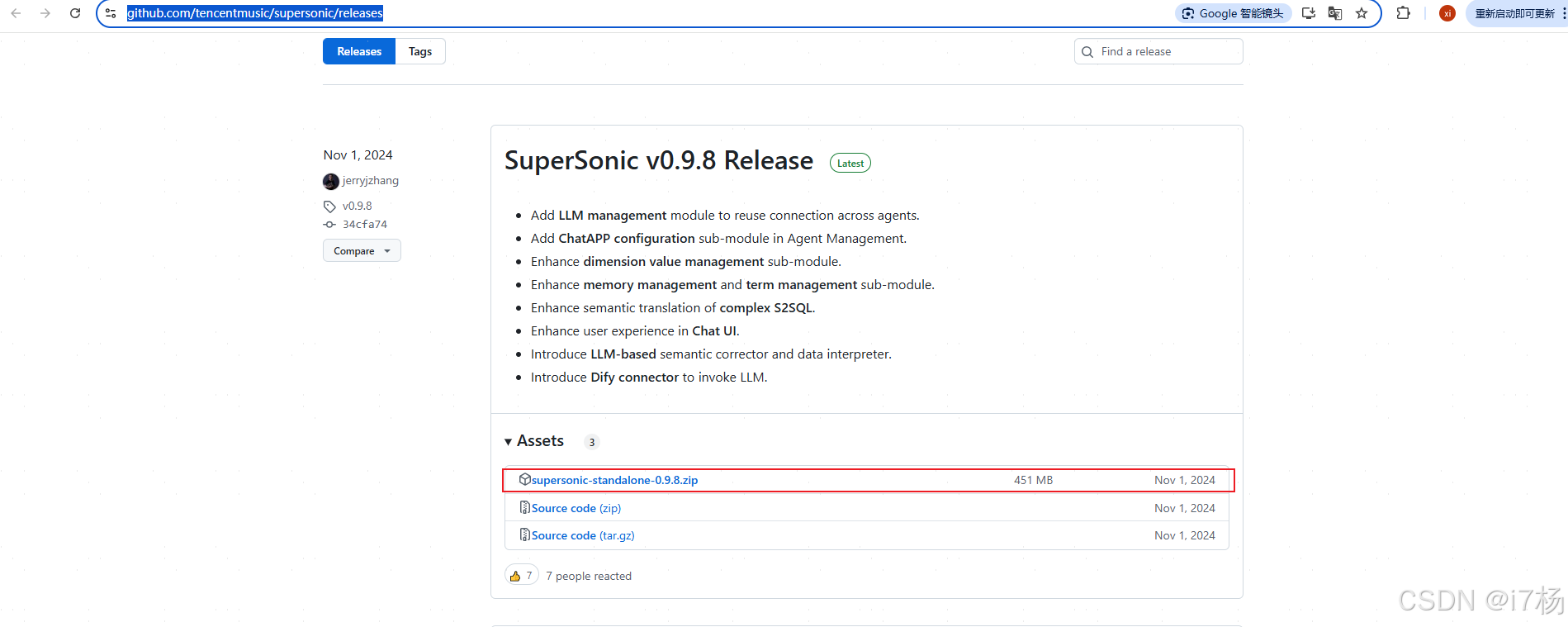
3.1下载
git下载地址:Releases · tencentmusic/supersonic · GitHub
3.2 安装
- 解压后运行 \"bin/supersonic-daemon.sh start\"启动standalone模式的Java服务
- 在浏览器访问http://ip:9080 开启探索(admin/123456)
4.使用方法
4.1大模型管理
可创建自己安装的大模型,但是常规大模型语义解析准确度不高;

私有deepseek32b大模型的作用在supersonic仅限于交流,语义解析暂不适配;
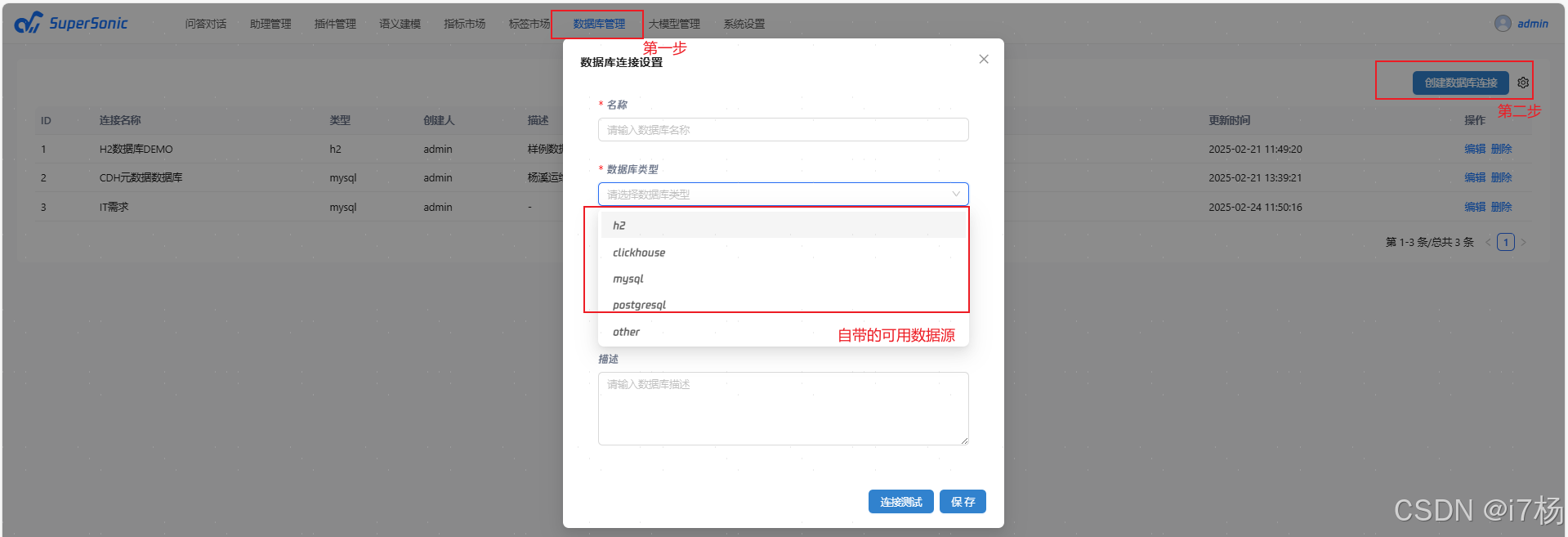
4.2 数据库管理
配置数据库,创建可用的数据库;如下:常用的有H2,ClickHouse,Mysql,PG。
4.3 构建语义模型(核心)
4.3.1创建数据集(原始数据)
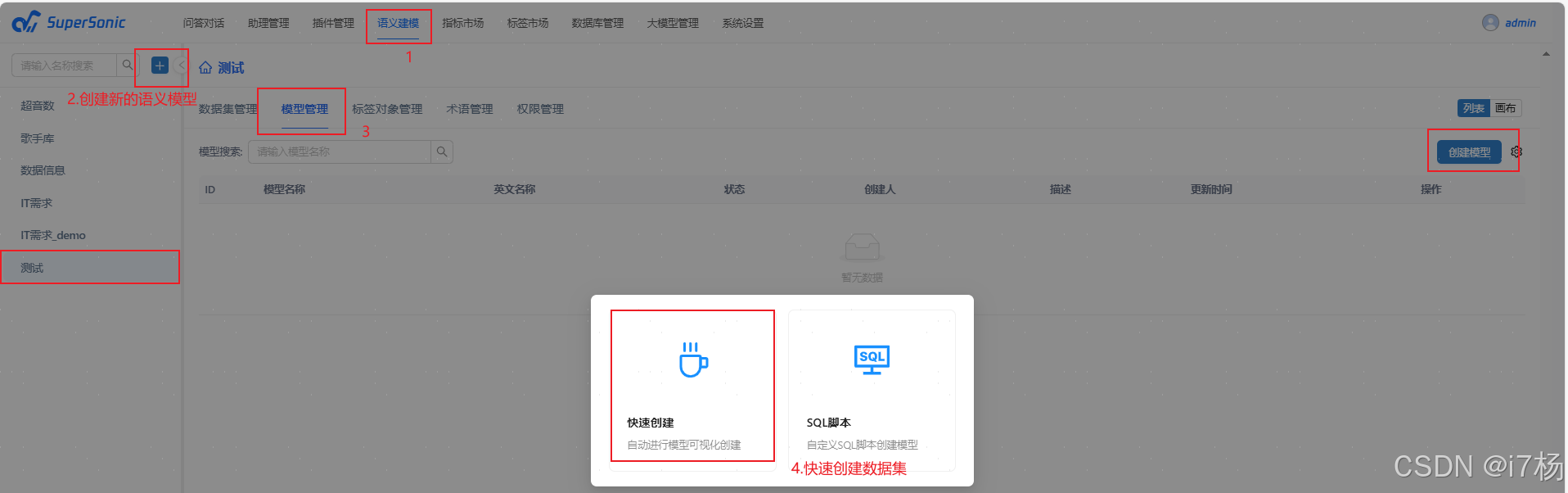
4.3.2设置表字段含义
这个模型最好将宽表按最小场景,拆分成多个小模型。
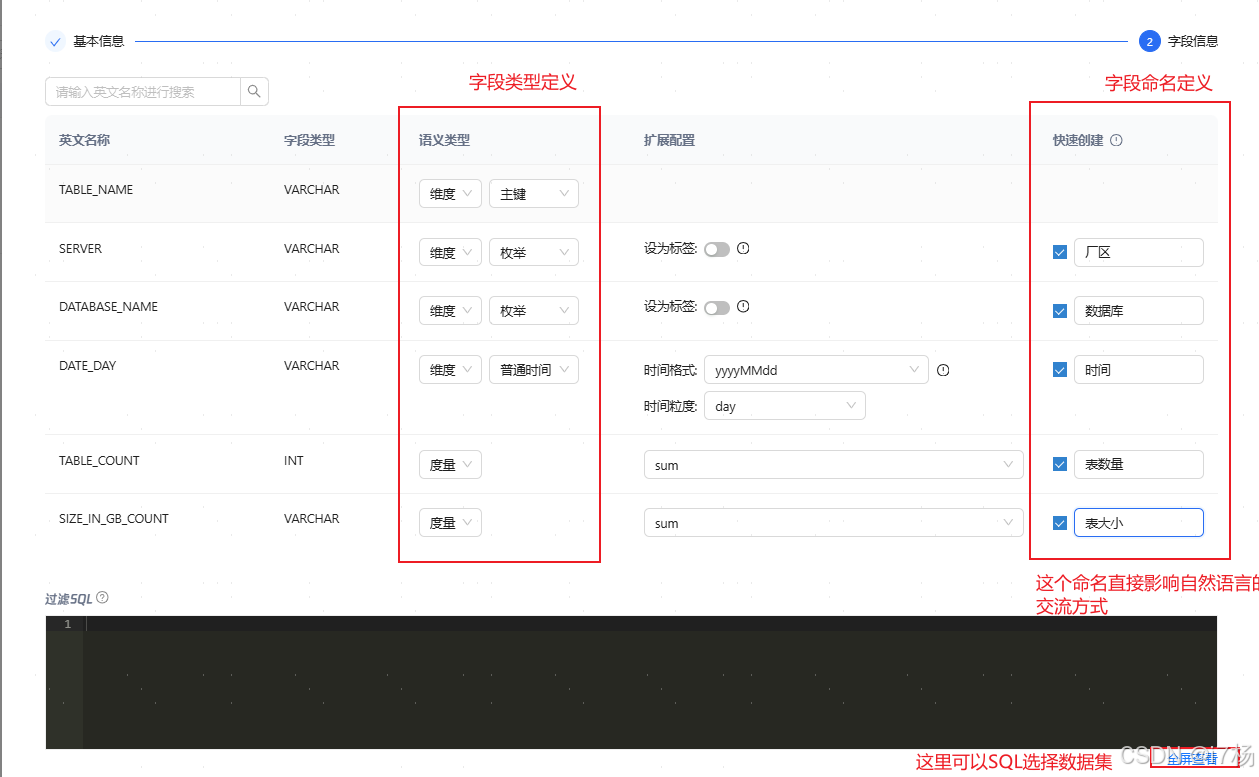
4.3.3 选择模型字段加入数据集
按模型里配置的字段挑选,只有选择的维度和指标才能通过交流获取。(交流助手的数据均来自这里)。
4.4 配置交流助理
4.4.1选择默认大模型
4.4.2 选择文本转SQL插件
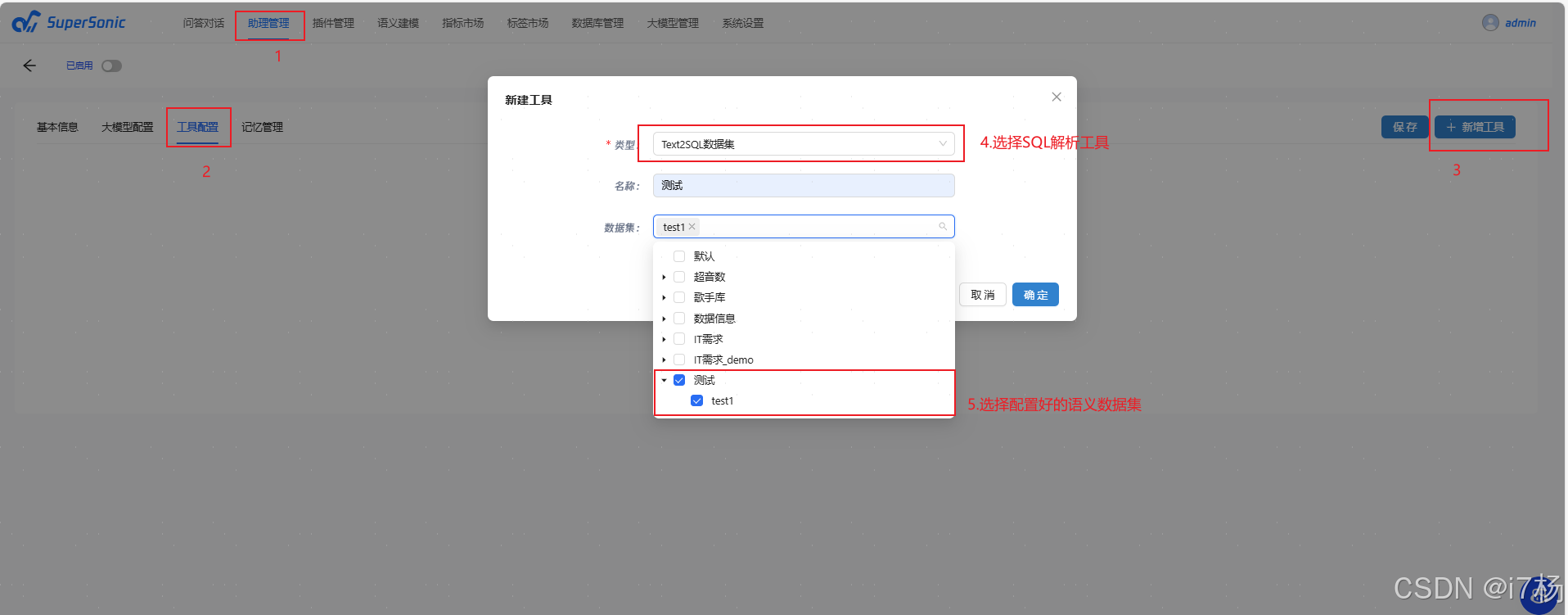
4.5 交流测试
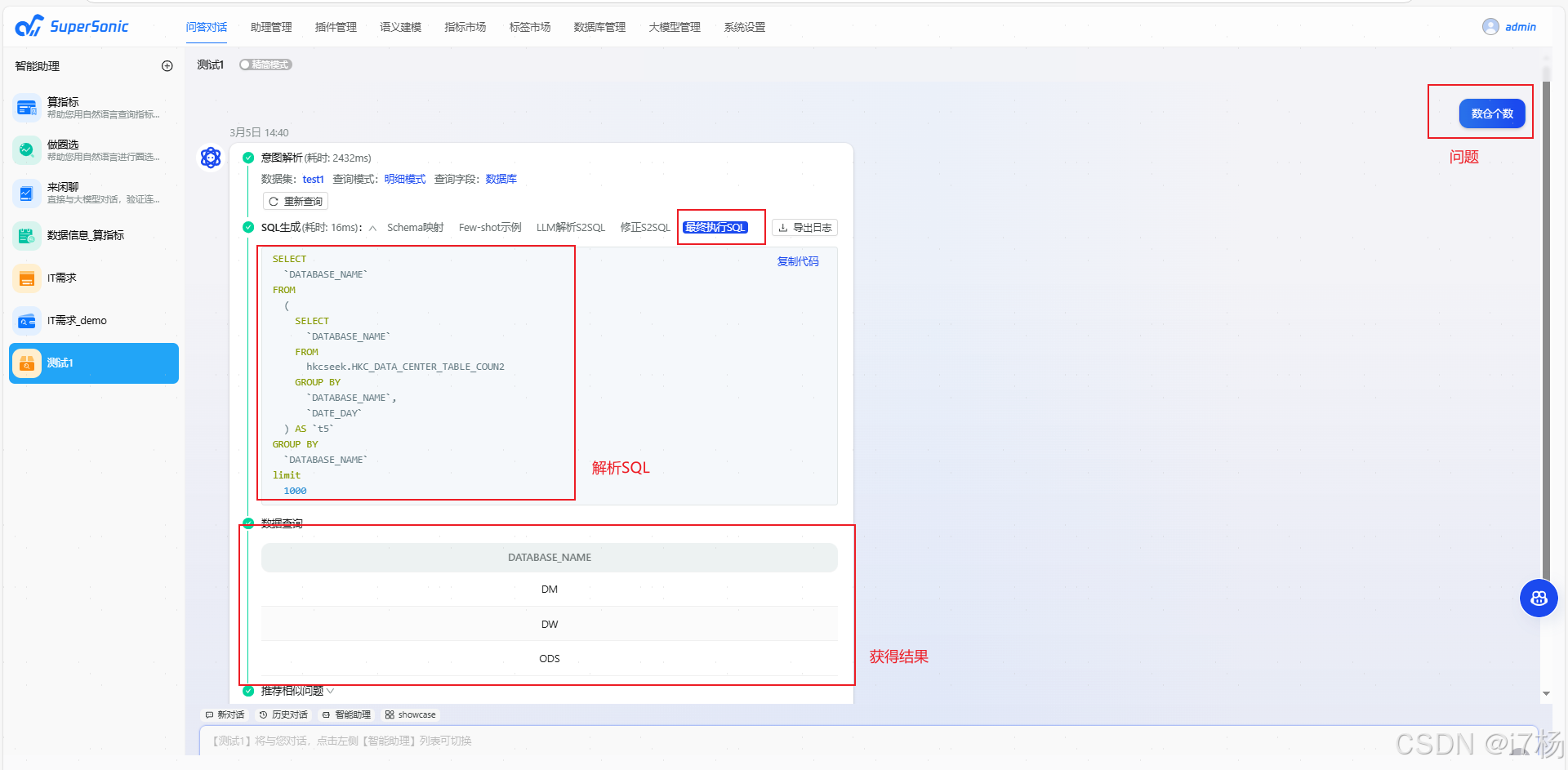
4.6 使用总结
为了提高SQL的准确度,保证4.3语义模型的规范性和可识别性。
一些使用经验:
a.模型管理,尽量拆解大宽表,不要让一个模型里存在两个含义相近的字段;
比如:存在两个包含人含义的字段,需求者和开发者,这会导致话术使用额外的标识区分;
b.调试助手时,字段和问题要一个一个增加,不要想一次性吃个胖子,直接输入所有字段;字段越多,模型的理解需要字段描述就需要越精确;
比如时间类型的字段,每个时间字段不去特别说明,语义解析的时候都会自动默认每个时间字段最近三个月的条件;
c.SQL的解析,可以从模型字段定义的清晰度上优化解析准确度;
d.数据库的数据字段存在某种命名规范,需要和字段值含义匹配;
比如是否逾期,值不是“是否”,而是包含多种解释,就会导致模型解析失真;
5.性能指标
来自官网用户使用分析:
6.总结
6.1优势总结
- 通过LLM实现真正的自然语言交互
- 灵活的多数据源支持架构
- 企业级可视化与安全管控能力
6.2使用建议
- 优先在业务部门试点简单场景(如销售日报分析)
- 结合内部数据字典进行领域微调
- 通过插件机制对接现有数据中台

