复现VideoPose3D(3D Human Pose Estimation in Video With Temporal Convolutions and Semi-Supervised)
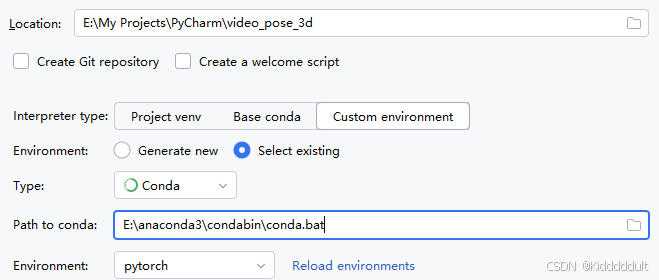
1.搭建PyTorch环境

2.新建PyCharm项目
3.把项目代码拷贝到自己项目里
项目在这里:GitHub - facebookresearch/VideoPose3D: Efficient 3D human pose estimation in video using 2D keypoint trajectories
4.下载Human3.6M数据集
方式一:官方下载地址是Human3.6M Dataset(注册审核好像不太容易,我没试)
方式二:https://gitcode.com/open-source-toolkit/7e198(CSDN大佬分享的下载链接,稍慢)。
方式三:https://1drv.ms/u/s!ArduJP09htIpcqqR-ySfpmE56eQ?e=kdOreD(GitHub大佬分享的下载链接,神速)。
把下载好的h36m.zip放在data目录下。
5.设置数据集
安装cdflib库(pip install cdflib):
![]()
修改一下prepare_data_h36m.py文件里的h5py部分:

(切换到data目录下)运行预处理脚本:

python prepare_data_h36m.py --from-archive h36m.zip运行细节如下:
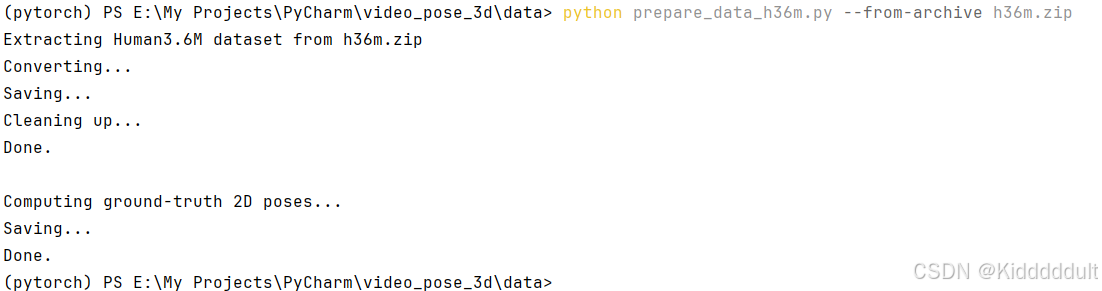
然后data目录下多出了data_2d_h36m_gt.npz和data_3d_h36m.npz两个文件。
同样在data目录里,下载CPN(Cascaded Pyramid Network)检测结果:
wget https://dl.fbaipublicfiles.com/video-pose-3d/data_2d_h36m_cpn_ft_h36m_dbb.npz执行完这个命令之后,data目录里应该出现data_2d_h36m_cpn_ft_h36m_dbb.npz的。如果没有的话就直接在浏览器输入https://dl.fbaipublicfiles.com/video-pose-3d/data_2d_h36m_cpn_ft_h36m_dbb.npz,下载完移动到data目录下。
6.下载预训练模型
在项目根目录下创建checkpoint目录,切换到checkpoint目录下运行下面的命令:
wget https://dl.fbaipublicfiles.com/video-pose-3d/pretrained_h36m_cpn.bin执行完这个命令之后,checkpoint目录里应该出现pretrained_h36m_cpn.bin的。如果没有的话就直接在浏览器输入https://dl.fbaipublicfiles.com/video-pose-3d/pretrained_h36m_cpn.bin,下载完移动到checkpoint目录下。
7.评估预训练模型
退到根目录下运行下面的命令:
python run.py -k cpn_ft_h36m_dbb -arc 3,3,3,3,3 -c checkpoint --evaluate pretrained_h36m_cpn.bin






可以看到训练结果MPJPE达到了46.8mm。
8.从头训练模型(可选,我没训)
python run.py -e 80 -k cpn_ft_h36m_dbb -arc 3,3,3,3,3在高端Pascal GPU上跑上面这个命令需要24h。适当减小感受野或者减小epoch的话时间会短一点,-arc 3,3,3,3需要11h,-arc 3,3,3需要6h,但是对模型训练结果肯定有影响。
9.在自己的视频上跑模型并且可视化预测结果
(1)配置FFmpeg:
在Download FFmpeg按下图所示步骤下载FFmpeg。
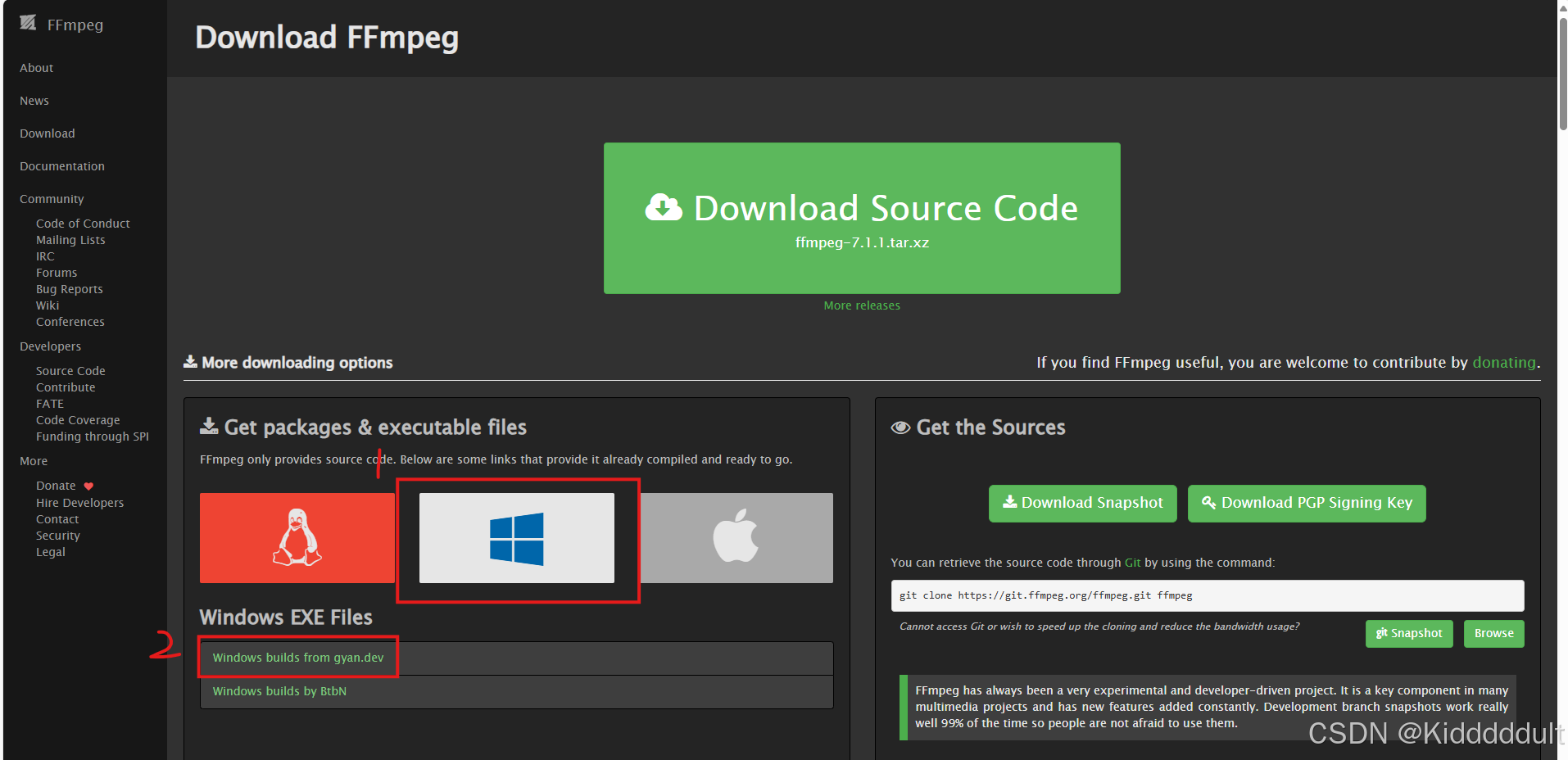
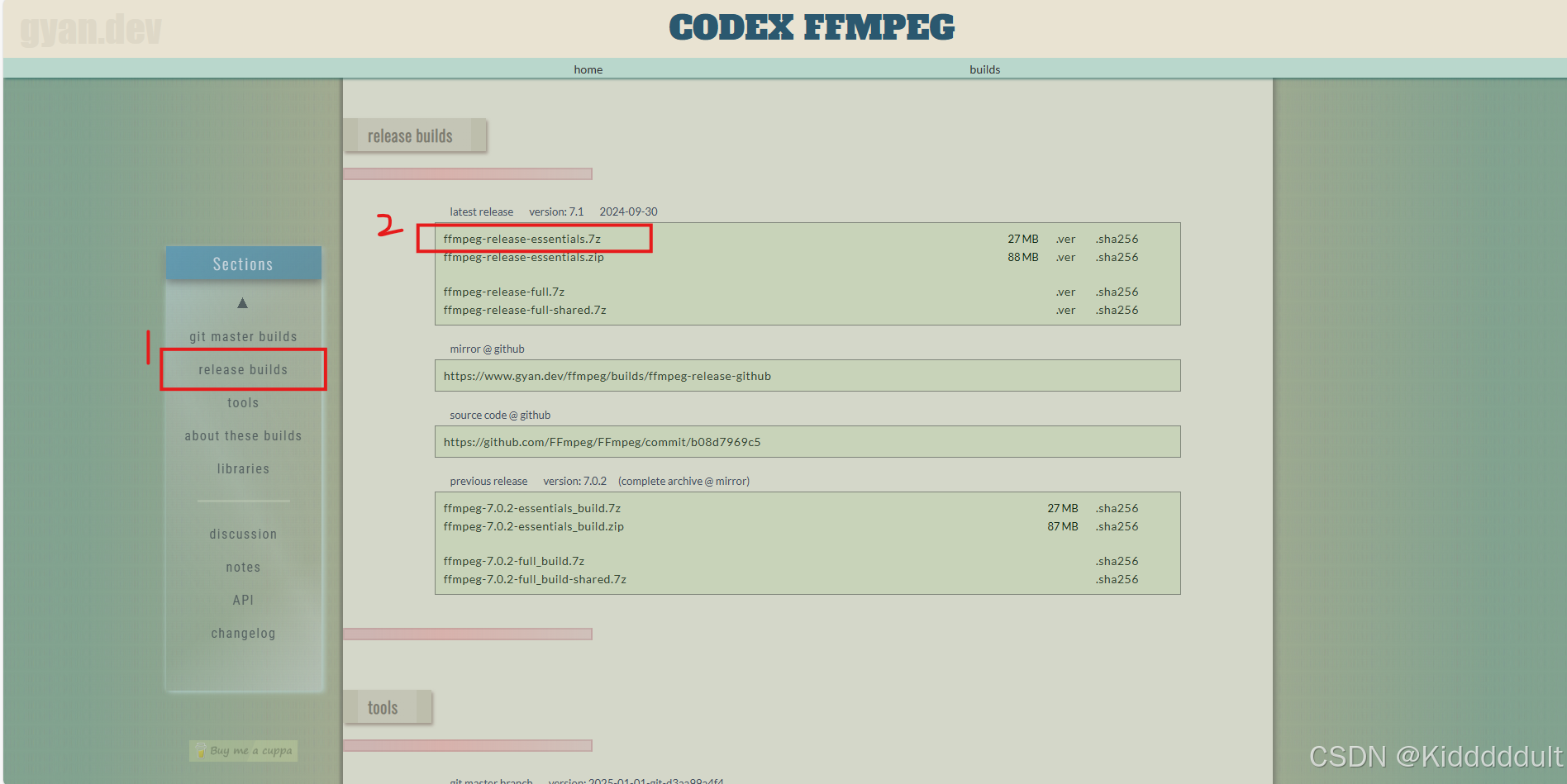
将ffmpeg-7.1-essentials_build.7z解压缩到C盘下,然后把C:\\ffmpeg-7.1-essentials_build\\bin添加到系统环境变量里面,此时Win+R打开cmd,输入ffmpeg -version如能正常显示版本号就OK了。
(2)下载预训练模型
点击https://dl.fbaipublicfiles.com/video-pose-3d/pretrained_h36m_detectron_coco.bin下载pretrained_h36m_detectron_coco.bin,移动到checkpoint目录下(需要注意的是,pretrained_h36m_detectron_coco.bin是不同于之前那个pretrained_h36m_cpn.bin的)。
(3)安装部署Detectron2
参考这个教程(也是我写的):Windows 11安装部署Detectron2-CSDN博客
注意: 我是Windows 11,这一步和其它操作系统的朋友可能不太一致,大家可以按需寻找适合自己的Detectron2安装部署教程。
(4)推理2D关键点
在inference目录下新建一个两个目录:input_directory和output_directory,然后把你的视频传入input_directory,注意:1.最好上传单人视频(多人视频的话会选择置信度最高的锚框框定的人,对预测效果产生影响);2.视频帧率最好调成50FPS(也可以不调,我没调)。
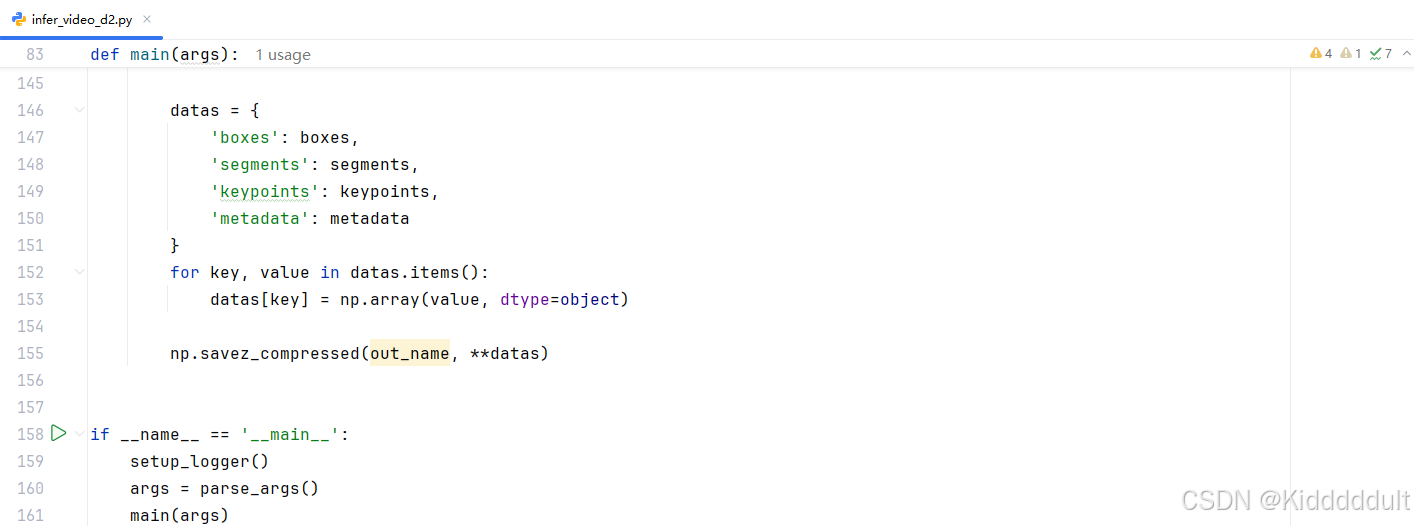
在infer_video_d2.py里找到np.savez_compressed(out_name, boxes=boxes, segments=segments, keypoints=keypoints, metadata=metadata),修改成:
datas = { \'boxes\': boxes, \'segments\': segments, \'keypoints\': keypoints, \'metadata\': metadata } for key, value in datas.items(): datas[key] = np.array(value, dtype=object) np.savez_compressed(out_name, **datas)不修改的话下一步执行指令时会报错ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 2 dimensions. The detected shape was (1005, 2) + inhomogeneous part,修改好后如下图所示:
进入inference目录,执行以下命令(传入视频的格式可以通过下面命令里的“--image-ext 视频格式”修改;首次执行这条命令会加载pkl文件,耐心等待就好):
python infer_video_d2.py --cfg COCO-Keypoints/keypoint_rcnn_R_101_FPN_3x.yaml --output-dir output_directory --image-ext mp4 input_directory

不知道为什么我后面的那些帧在处理的时候出现了那么多N/A,不过不影响后续操作。
玫红色的[out#0/image2pipe @ 0000024b73a6a080]不是报错,是FFmpeg输出的日志信息,后面的参数表示视频的总大小、音频大小、字幕大小等。
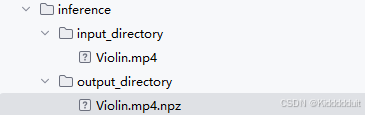
运行结束后output_directory下会出现一个npz文件:
(5)创建自定义数据集
进入data目录,运行以下命令(myvideos是自定义的数据集名称):
python prepare_data_2d_custom.py -i ../inference/output_directory -o myvideos
myvideos数据集保存在data目录下的data_2d_custom_myvideos.npz中。
(6)渲染自定义视频并导出坐标
回到根目录,执行以下命令(按需自己调整里面的参数):
python run.py -d custom -k myvideos -arc 3,3,3,3,3 -c checkpoint --evaluate pretrained_h36m_detectron_coco.bin --render --viz-subject Violin.mp4 --viz-action custom --viz-camera 0 --viz-video inference/input_directory/Violin.mp4 --viz-output output.mp4 --viz-size 6


玫红色的[out#0/image2pipe @ 00000166bf709e80]同样不是报错,是FFmpeg输出的日志信息。
运行结束以后,项目根目录下出现了一个output.mp4,播放效果如下:
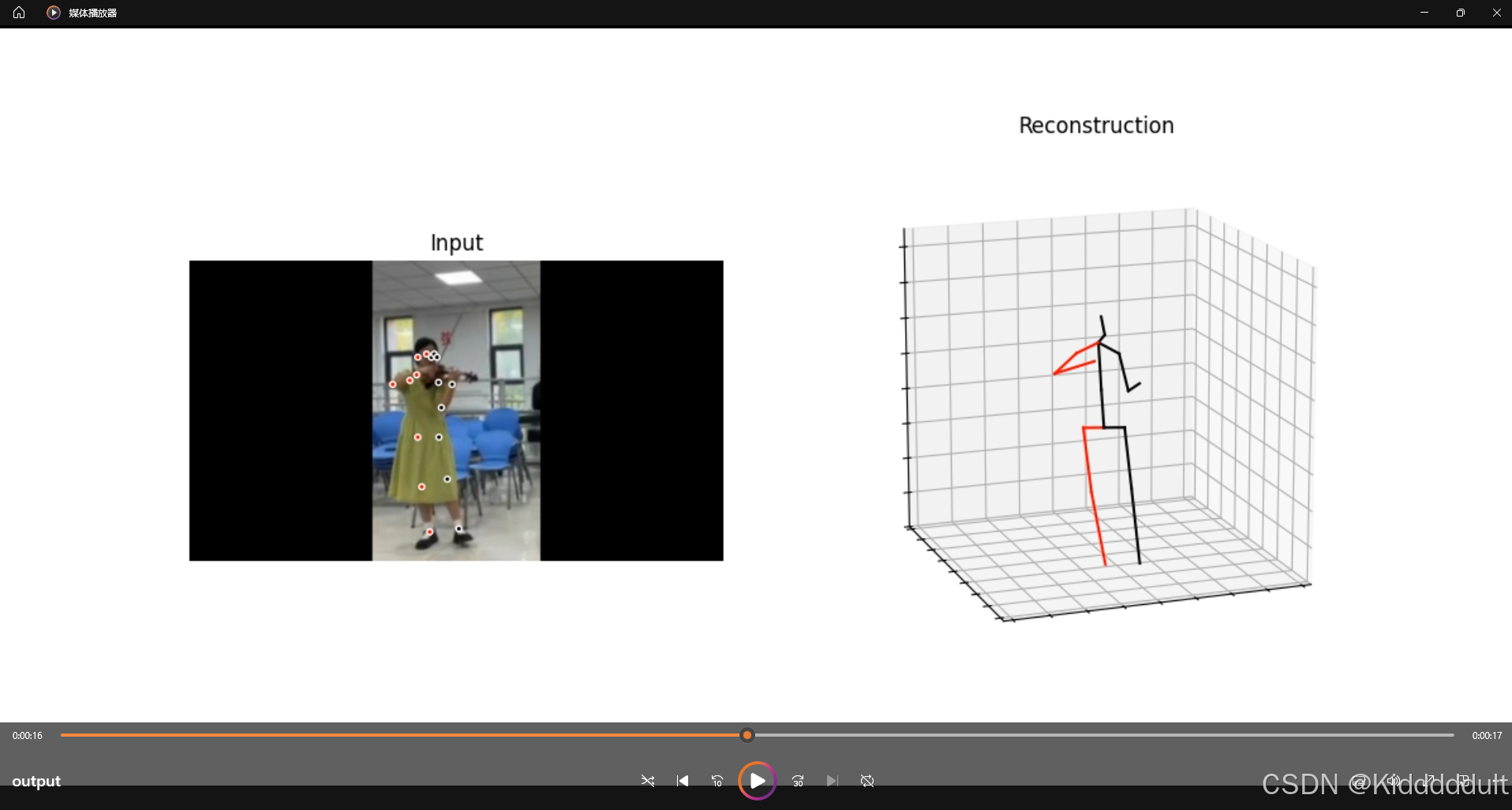
到这里VideoPose3D的复现就大功告成啦~

