基于spark学习通视频观看时长分析
1 项目概述
1.1 项目描述
1906年是第一台电视诞生的日子,1960年是第一台摄像机诞生的日子,从此视频开始走入人们的生活。站在2021年的今天,随着移动终端的普及、抖音与快手等短视频的崛起,人们观看视频的时长又会发生那些变化呢?
本次作业以学习通用户观看视频的时长为数据源,使用hdfs存储数据,spark分析数据,superSet可视化。分析30分钟的课程0-5min、5-10min。。。的用户观看比例,通过对比用户比例,得出结论
技术栈:hadoop, spark, mysql, superse
1.2 项目需求
1.2.1 功能需求
(1)kaggle获取数据并上传到hdfs
(2)spark分析计算
(3)superSet数据可视化
1.2.2 系统架构图
1.2.3 数据结构
(1)数据字段
(2)数据来源
Kaggle
地址:https://www.kaggle.com/
(3)数据样式
{\"biz\":\"bdfb58e5-d14c-45d2-91bc-1d9409800ac3\",\"chapterid\":\"1\",\"cwareid\":\"3\",\"edutypeid\":\"3\",\"pe\":\"55\",\"ps\":\"41\",\"sourceType\":\"APP\",\"speed\":\"2\",\"subjectid\":\"2\",\"te\":\"1563352166417\",\"ts\":\"1563352159417\",\"uid\":\"235\",\"videoid\":\"2\"}(4)数据量
142366条
2 系统设计与实现
2.1 实现系统功能所采覆盖知识点
序号功能点知识点
1数据上传hdfs命令
2数据分析Spark分析、保存
3数据可视化SuperSet
2.2 数据上传
2.2.1 实现过程
(1)直接使用hdfs的命令对文件上传
2.2.2 功能分析
数据上传使用的是hdfs自带的命令上传数据
2.3 数据分析
2.3.1 实现过程
(1)编写spark程序分析数据
package com.itbys.demo08import com.alibaba.fastjson.{JSON, JSONObject}import org.apache.spark.SparkConfimport org.apache.spark.rdd.RDDimport org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}case class DataModel(biz:String,chapterid:Int,cwareid:Int,edutypeid:Int,pe:Int,ps:Int,sourceType:String,speed:Int,subjectid:Int,te:Long,ts:Long,uid:Int,videoid:Int )object demo01 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster(\"local[*]\").setAppName(getClass.getName) val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate() //1.加载数据 val dataModelRDD: RDD[DataModel] = spark.sparkContext.textFile(\"hdfs://hdp:9000/input/study/\") .map { x => val jSONObject: JSONObject = JSON.parseObject(x) val biz: String = jSONObject.getString(\"biz\") val chapterid: Int = jSONObject.getInteger(\"chapterid\") val cwareid: Int = jSONObject.getInteger(\"cwareid\") val edutypeid: Int = jSONObject.getInteger(\"edutypeid\") val pe: Int = jSONObject.getInteger(\"pe\") val ps: Int = jSONObject.getInteger(\"ps\") val sourceType: String = jSONObject.getString(\"sourceType\") val speed: Int = jSONObject.getInteger(\"speed\") val subjectid: Int = jSONObject.getInteger(\"subjectid\") val te: Long = jSONObject.getLong(\"te\") val ts: Long = jSONObject.getLong(\"ts\") val uid: Int = jSONObject.getInteger(\"uid\") val videoid: Int = jSONObject.getInteger(\"videoid\") DataModel(biz, chapterid, cwareid, edutypeid, pe, ps, sourceType, speed, subjectid, te, ts, uid, videoid) } //2.转换成DataFrame import spark.implicits._ val frame: DataFrame = dataModelRDD.toDF() frame.createTempView(\"course_learn\") //3.spark sql 分析 val resDf: DataFrame = spark.sql( \"\"\" | SELECT learn_time, | case | when learn_time>=0 and learn_time<5 then \'0-5\' | when learn_time>=5 and learn_time<10 then \'5-10\' | when learn_time>=10 and learn_time<15 then \'10-15\' | when learn_time>=15 and learn_time<20 then \'15-20\' | when learn_time>=20 and learn_time<25 then \'20-25\' | when learn_time>=25 and learn_time<30 then \'25-30\' | else \'30up\' | end | as time_interval,\'2021-05-23\' dt from (SELECT (te-ts)/1000 learn_time from course_learn) t \"\"\".stripMargin) resDf.show() //4.写入mysql resDf.write .format(\"jdbc\") .option(\"url\", \"jdbc:mysql://hdp:3306/test?useUnicode=true&characterEncoding=utf8\") .option(\"dbtable\", \"course_learn_time\") .option(\"user\", \"root\") .option(\"password\", 111111) .mode(SaveMode.Append) .save() }}2.3.2 功能分析
Spark获取hdfs上的数据、spark sql分析,保存到数据库中
2.4 数据可视化
2.4.1 实现过程
(1)将分析的数据存为到mysql中,并配置superSet可视化
2.4.2 功能分析
在superSet配置饼图,读取mysql数据可视化
3 系统构建与部署
3.1 具体项目思路
(1)下载数据保存到hdfs
(2)Spark数据分析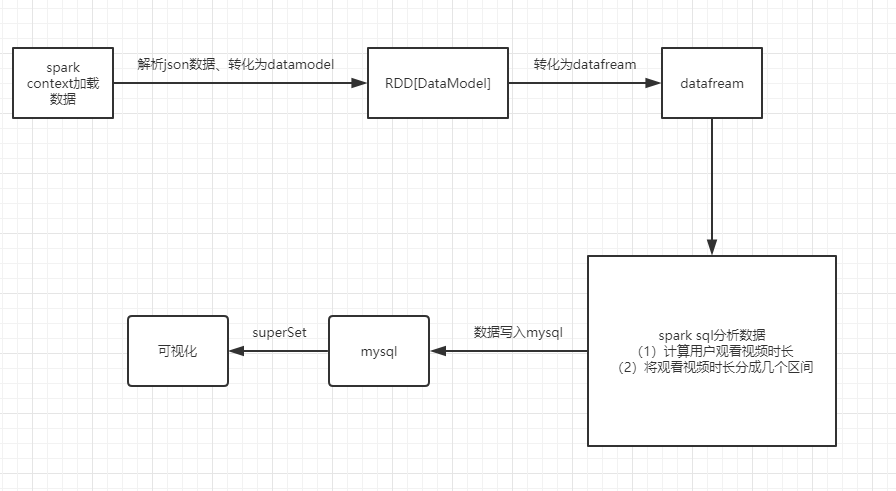
(3)superSet可视化
3.2 Hadoop伪分布环境
(1)hadoop进程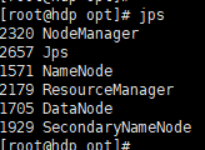
(2)Namenode前端页面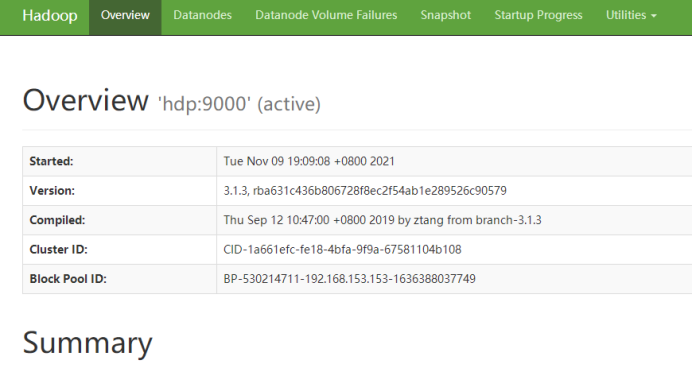
(3)Yarn前端页面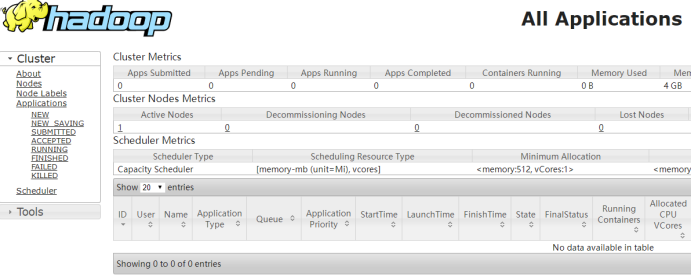
3.3 Spark开发环境
(1)spark进程
(2)spark-shell窗口
(3)spark前端页面
4 项目总结
4.1 运行结果
(1)数据分析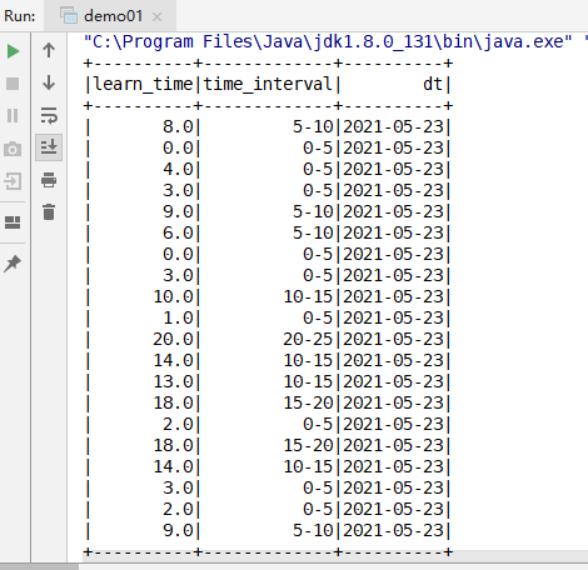
(2)spark分析,将数据保存在mysql中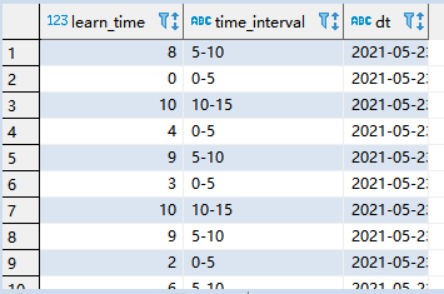
(3)superSet可视化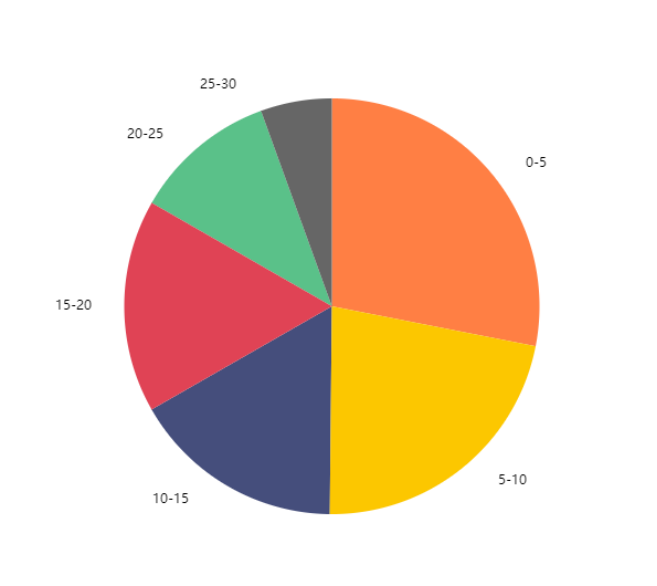
(1)通过观察图可分析得出:
用户观看视频超1/4都在0-5min内,超1/2都在10min内,时间越长的比例越小
(2)分析原因可能如下:
1.如今快节奏的生活中,人们系统性的学习时间越来越少,取而代之的是碎片化的学习时间,比如地铁公交,吃饭聚餐等场合拿出设备学习一小会
2.抖音、快手等短视频的崛起深刻的改变了人们观看视频的习惯,人们变得越来越没有“耐心”去看完一部视频
4.2 项目特色
本次作业的优势和难度在于数据过滤、清洗,以及spark core、sql的转换,
SuperSet的配置使用
以后的学习中,我将更加深入学习spark mllib包下的算法相关内容,如分类聚类。回归分析,k-means等
其他
疑问、完整代码和数据等可留言或ping我:ari.chen.cn@gmail.com

