CaDDn-Categorical Depth Distribution Network for Monocular 3D Object Detection
Categorical Depth Distribution Network for Monocular 3D Object Detection
用于单目3D目标检测的分类深度分布网络
摘要
单目3D目标检测是自动驾驶车辆的关键问题,因为与典型的多传感器系统相比,它提供了一种配置简单的解决方案。单目3D检测的主要挑战在于准确预测物体深度,由于缺乏直接的距离测量,因此必须从物体和场景线索中推断出物体深度。许多方法试图直接估计深度以辅助3D检测,但由于深度不准确而表现出有限的性能。我们提出的解决方案,分类深度分布网络(CaDDN),使用每个像素的预测分类深度分布,将丰富的上下文特征信息投影到3D空间中的适当深度间隔。然后,我们使用计算效率的鸟瞰图投影和单级检测器来产生最终的输出检测。我们将CaDDN设计为用于联合深度估计和对象检测的完全可区分的端到端方法。我们在KITTI 3D目标检测基准上验证了我们的方法,在已发布的单目方法中排名第一。我们还在新发布的Waymo Open Dataset上提供了第一个单目3D检测结果。我们为CaDDN提供了一个代码版本,可以在这里找到。

图1.(a)输入图像。(b)在没有深度分布监控的情况下,来自CaDDN的BEV特征遭受拖尾效应。(c)深度分布监控鼓励来自CaDDN的BEV特征编码有意义的深度置信度,其中对象可以被准确地检测。
1.引言
3D空间中的感知是自动驾驶汽车和机器人等地方的关键组成部分,使系统能够理解其环境并做出相应的反应。LiDAR [21,50,51]和立体声[46,45,28,11]传感器在3D感知任务中的使用历史悠久,由于其能够生成精确的3D测量结果,因此在KITTI 3D物体检测基准[16]等3D物体检测基准上显示出出色的结果。基于单眼的3D感知已经同时被追求,其动机是具有单个相机的低成本、易于部署的解决方案的潜力[9,40,5,22]。由于场景信息投影到图像平面时会丢失深度信息,因此相同3D对象检测基准的性能相对于LiDAR和立体方法明显滞后。
为了对抗这种效应,单目物体检测方法[13,36,37,59]通常通过在单独的阶段训练单目深度估计网络来显式地学习深度。然而,深度估计直接在3D对象检测阶段消耗,而不了解深度置信度,导致网络倾向于对深度预测过度自信。对深度的过度自信在远距离上尤其是一个问题[59],导致定位不良。此外,在训练阶段期间,深度估计与3D检测分离,从而防止深度图估计针对检测任务被优化。图像数据中的深度信息也可以通过直接将特征从图像转换到3D空间并最终转换到鸟瞰图(BEV)网格来隐式学习[48,44]。然而,隐式方法倾向于遭受特征拖尾,其中类似的图像特征可以存在于投影空间中的多个位置处。特征涂抹增加了在场景中定位对象的难度。为了解决这些问题,我们提出了一种单目3D对象检测方法CaDDN,它通过学习分类深度分布来实现准确的3D检测。通过利用概率深度估计,CaDDN能够以端到端的方式从图像生成高质量的鸟瞰图特征表示。我们总结我们的方法有三个贡献。
(1) Categorical Depth Distributions.(分类深度分布)
为了执行3D检测,我们预测逐像素的分类深度分布,以准确地定位图像信息在3D空间中。每个预测的分布描述像素属于预定义深度仓集合的概率。我们鼓励我们的分布在正确的深度箱周围尽可能尖锐,以鼓励我们的网络更多地关注深度估计准确和自信的图像信息。通过这样做,我们的网络能够产生更清晰、更准确的特征,这些特征对3D检测非常有用(见图1)。另一方面,当深度估计置信度较低时,我们的网络保持产生较不尖锐分布的能力。使用分类分布允许我们的特征编码捕获固有的深度估计不确定性,以减少错误深度估计的影响,这一属性在4.3节中被证明是CaDDN性能改善的关键。我们预测的深度分布的清晰度是通过对正确深度仓的独热编码进行监督来鼓励的,该编码可以通过将LiDAR深度数据投影到相机帧中来生成。
(2) End-To-End Depth Reasoning.(端到端深度推理)
我们以端到端的方式学习深度分布,联合优化以实现准确的深度预测和准确的3D对象检测。我们认为,联合深度估计和3D检测推理鼓励针对3D检测任务优化深度估计,从而提高性能,如4.3节所示。
(3) BEV Scene Representation.(BEV场景表示)
本文介绍了一种新的方法,利用分类深度分布和投影几何,从单幅图像中生成高质量的鸟瞰场景表示。我们选择鸟瞰图表示法是因为它能够以较高的计算效率产生出色的3D检测性能[26]。所生成的鸟瞰图表示被用作对基于鸟瞰图的检测器的输入以产生最终输出。在KITTI 3D物体检测测试基准[1]的汽车和行人类别中,CaDDN在所有先前发布的单眼方法中排名第一,其差值分别为1.69%和1.46% AP| R40分别进行。我们是第一个在Waymo Open Dataset [56]上报告单眼3D物体检测结果的人。
2.相关工作
(此处省略)
3.方法
CaDDN通过将图像特征投影到3D空间来学习从图像生成BEV表示。然后使用高效的BEV检测网络利用丰富的BEV表示来执行3D对象检测。CaDDN架构的概述如图2所示。
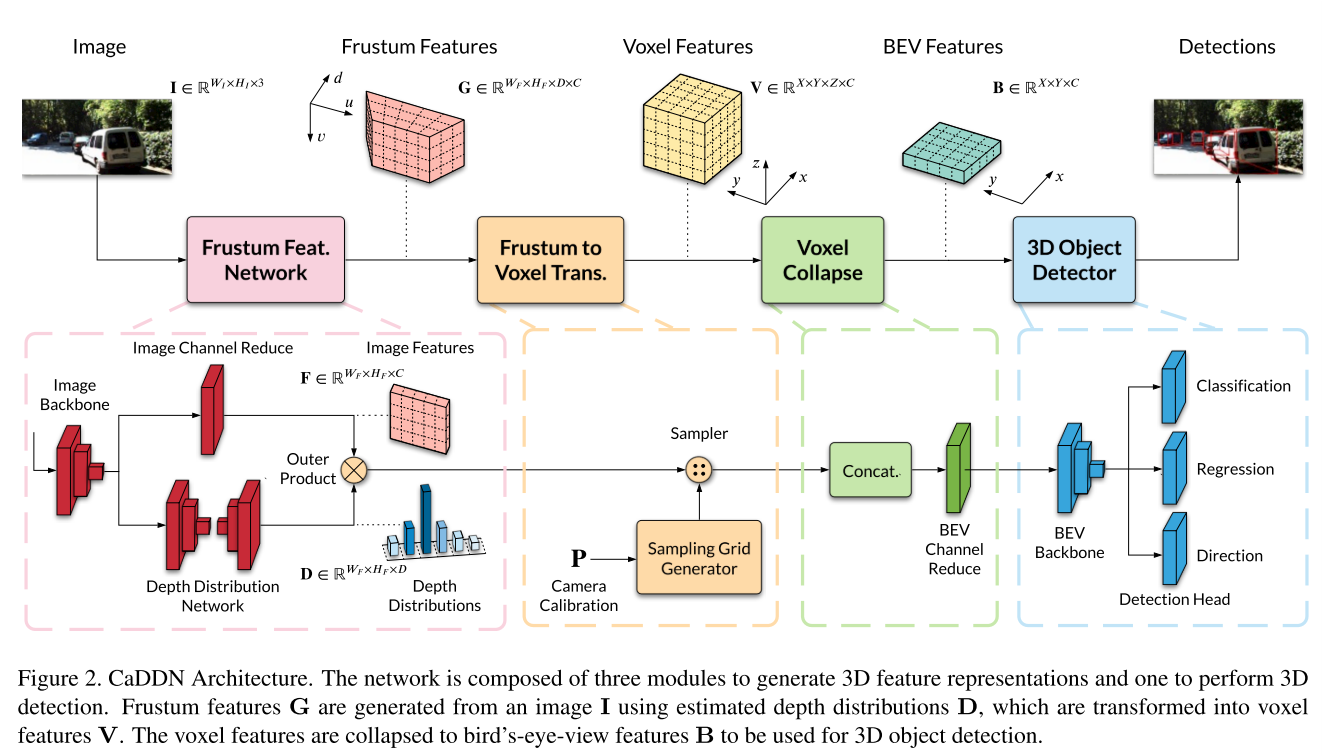
图2.CaDDN体系结构。该网络由三个模块和一个模块组成,三个模块用于生成3D特征表示,一个模块用于执行3D检测。使用所估计的深度分布D从图像I生成平截头体特征G,所述平截头体特征G被变换成体素特征B。
3.1. 3D Representation Learning(3D表示学习)
我们的网络学习生成非常适合3D对象检测任务的BEV表示。以图像为输入,我们构建了一个锥台特征网格使用的分类深度分布估计。使用已知的相机校准参数将截头体特征网格转换成体素网格,然后折叠成鸟瞰图特征网格。
Frustum Feature Network.(平截体特征网络)
平截头体特征网络的目的是通过将图像特征与估计的深度相关联来将图像信息投影到3D空间中。具体来说,锥台特征网络的输入是图像![]() ,其中
,其中![]() 是图像的宽度和高度。输出是一个截头体特征网格
是图像的宽度和高度。输出是一个截头体特征网格![]() ,其中
,其中![]() 是图像特征表示的宽度和高度,D是离散化深度箱的数量,C是特征通道的数量。我们注意到,平截头体网格的结构类似于立体3D 检测方法DSGN中使用的平面扫描体。
是图像特征表示的宽度和高度,D是离散化深度箱的数量,C是特征通道的数量。我们注意到,平截头体网格的结构类似于立体3D 检测方法DSGN中使用的平面扫描体。
ResNet-101 [17]主干用于提取图像特征![]() (参见图2中的图像主干)。在我们的实现中,我们从ResNet-101主干的Block 1中提取图像特征,以保持高空间分辨率。高空间分辨率对于有效的截头体到体素网格变换是必要的,使得截头体网格可以在没有重复特征的情况下被精细地采样。
(参见图2中的图像主干)。在我们的实现中,我们从ResNet-101主干的Block 1中提取图像特征,以保持高空间分辨率。高空间分辨率对于有效的截头体到体素网格变换是必要的,使得截头体网格可以在没有重复特征的情况下被精细地采样。
使用图像特征![]() 来估计逐像素类别深度分布
来估计逐像素类别深度分布![]() ,其中类别是D个离散化深度箱。具体来说,我们为图像特征
,其中类别是D个离散化深度箱。具体来说,我们为图像特征![]() 中的每个像素预测D个概率,其中每个概率表示网络对深度值属于指定深度仓的置信度。深度箱的定义依赖于第3.3节中讨论的深度离散化方法。
中的每个像素预测D个概率,其中每个概率表示网络对深度值属于指定深度仓的置信度。深度箱的定义依赖于第3.3节中讨论的深度离散化方法。
我们遵循语义分割网络DeepLabV 3 [6]的设计来估计来自图像特征的分类深度分布![]() (图2中的深度分布网络),其中我们修改网络以产生属于深度箱而不是具有下采样-上采样架构的语义类的像素概率得分。使用ResNet-101 [17]主干的其余组件(Block 2,Block 3和Block 4)对图像特征
(图2中的深度分布网络),其中我们修改网络以产生属于深度箱而不是具有下采样-上采样架构的语义类的像素概率得分。使用ResNet-101 [17]主干的其余组件(Block 2,Block 3和Block 4)对图像特征![]() 进行下采样。一个atrous空间金字塔池[6](ASPP)模块被应用于捕获多尺度信息,其中输出通道的数量被设置为D。ASPP模块的输出通过双线性插值被上采样到原始特征大小,以产生分类深度分布
进行下采样。一个atrous空间金字塔池[6](ASPP)模块被应用于捕获多尺度信息,其中输出通道的数量被设置为D。ASPP模块的输出通过双线性插值被上采样到原始特征大小,以产生分类深度分布![]() 。对每个像素应用softmax函数,以将D logit归一化为0和1之间的概率。
。对每个像素应用softmax函数,以将D logit归一化为0和1之间的概率。
在估计深度分布的同时,我们对图像特征F进行通道缩减(图2中的图像通道缩减),以生成最终的图像特征F,使用1x1卷积+ BatchNorm + ReLU层将通道数量从C = 256减少到C = 64。需要进行通道降维以减少ResNet-101特征在3D视锥体网格中占用的高内存空间。
Let(u,v,c)表示图像特征F中的坐标,并且(u,v,di)表示分类深度分布D中的坐标,其中(u,v)是特征像素位置,c是通道索引,并且di是深度仓索引。为了生成平截头体特征网格G,每个特征像素F(u,v)通过其在D(u,v)中的相关联的深度仓概率来加权,以填充深度轴di,如图3所示。特征像素可以使用外积通过深度概率加权,定义为:
![]()
其中D(u,v)是预测的深度分布,G(u,v)是大小为D×C的输出矩阵。针对每个像素计算等式1中的外积以形成截头体特征![]() 。
。
Frustum to Voxel Transformation.(视锥体到体素转换)
利用已知的相机校准和可微分采样,将截头体特征![]() 转换为体素表示
转换为体素表示![]() ,如图4所示。在每个体素的中心处生成体素采样点
,如图4所示。在每个体素的中心处生成体素采样点![]() ,并将其变换为截头体网格以形成截头体采样点
,并将其变换为截头体网格以形成截头体采样点![]() ,其中dc是沿着截头体深度轴di的连续深度值沿着。使用相机校准矩阵
,其中dc是沿着截头体深度轴di的连续深度值沿着。使用相机校准矩阵![]() 来执行变换。使用第3.3节中概述的深度离散化方法将每个连续深度值dc转换为离散深度箱索引
来执行变换。使用第3.3节中概述的深度离散化方法将每个连续深度值dc转换为离散深度箱索引![]() 。使用采样点
。使用采样点![]() 和三线性插值(图4中以蓝色显示)对G中的截头体特征进行采样,以填充V中的体素特征。
和三线性插值(图4中以蓝色显示)对G中的截头体特征进行采样,以填充V中的体素特征。
为了有效的变换,截头体网格G和体素网格V的空间分辨率应该相似。高分辨率体素网格V导致高密度的采样点,其将对低分辨率截头体网格进行过采样,从而导致大量的相似体素特征。因此,我们从ResNet-101主干的Block 1中提取特征![]() ,以确保我们的截头体网格G具有高空间分辨率。
,以确保我们的截头体网格G具有高空间分辨率。
Voxel Collapse to BEV.(体素折叠到BEV)
体素特征V ∈ ![]() 被折叠到单个高度平面以生成鸟瞰视图特征B ∈
被折叠到单个高度平面以生成鸟瞰视图特征B ∈ ![]() 。BEV网格极大地降低了计算开销,同时提供了与3D体素网格相似的检测性能[26],从而激发了它们在我们的网络中的使用。我们沿着通道维度c连接体素网格V的垂直轴z以形成BEV网格
。BEV网格极大地降低了计算开销,同时提供了与3D体素网格相似的检测性能[26],从而激发了它们在我们的网络中的使用。我们沿着通道维度c连接体素网格V的垂直轴z以形成BEV网格![]() 。使用1x 1卷积+ BatchNorm + ReLU层减少通道数量(参见图2中的BEV通道减少),该层在学习每个高度切片的相对重要性的同时检索通道C的原始数量,从而产生BEV网格B ∈
。使用1x 1卷积+ BatchNorm + ReLU层减少通道数量(参见图2中的BEV通道减少),该层在学习每个高度切片的相对重要性的同时检索通道C的原始数量,从而产生BEV网格B ∈ ![]() 。
。
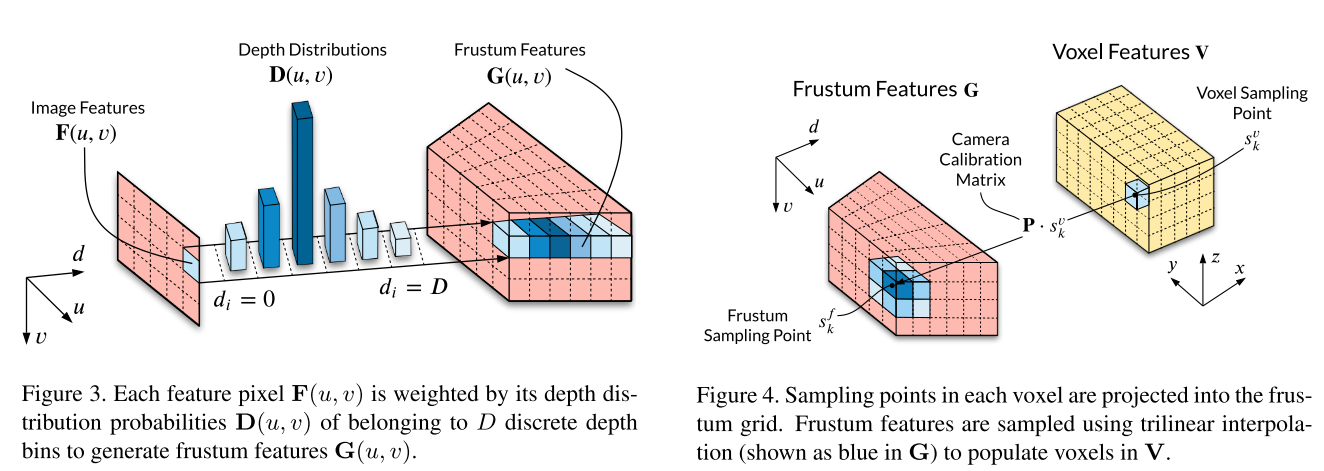
图3.每个特征像素F(u,v)通过其属于D个离散深度仓的深度分布概率D(u,v)来加权,以生成平截头体特征G(u,v)。
图4.将每个体素中的采样点投影到截头体网格中。使用三线性插值(在G中显示为蓝色)对视锥特征进行采样,以填充V中的体素。
3.2. BEV 3D Object Detection(3D BEV目标检测)
为了在BEV特征网格上执行3D物体检测,我们采用了成熟的BEV 3D物体检测器PointPillars [26]的主干和检测头,因为它已被证明可以提供准确的3D检测结果,并且计算开销较低。对于BEV主干,我们将下采样块中的3x3卷积+ BatchNorm + ReLU层的数量从原始PointPillars [26]中使用的(4,6,6)分别增加到Block1,Block2和Block3的(10,10,10)。增加卷积层的数量扩展了我们BEV网络的学习能力,这对于从图像产生的低质量特征中学习非常重要,而不是最初由LiDAR点云产生的高质量特征。我们使用与PointPillars [26]相同的检测头来生成最终检测。
3.3. Depth Discretization(深度离散化)
连续深度空间被离散化,以便定义在深度分布D中使用的D个仓的集合。深度离散化可以使用具有固定bin大小的均匀离散化(UD),具有增加的bin大小的间隔增加离散化(SID)[15],或具有线性增加bin大小的线性增加离散化(LID)[57]来执行。深度离散化技术如图5所示。我们采用LID作为深度离散化,因为它为所有深度提供了平衡的深度估计[57]。LID定义为:
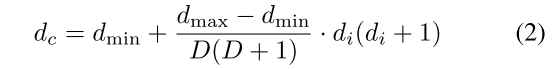
其中dc是连续深度值,[dmin,dmax]是要离散化的全深度范围,D是深度仓的数量,并且di是深度仓索引。
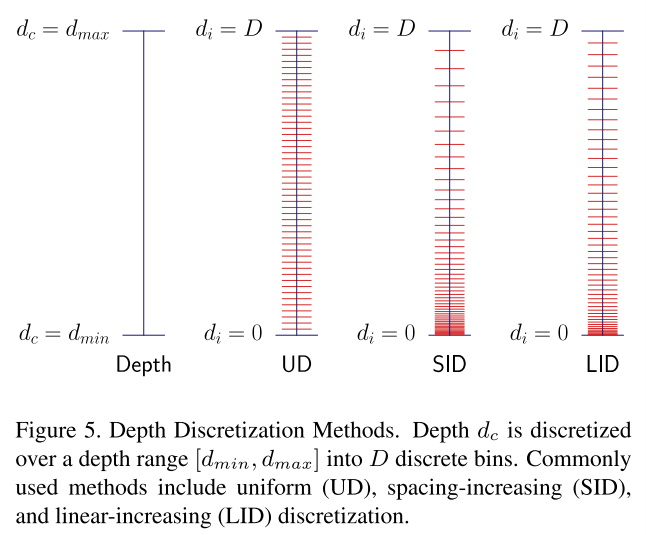
图5.深度离散化方法。深度dc在深度范围[dmin,dmax]上被离散化为D个离散面元。通常使用的方法包括均匀(UD)、间距递增(SID)和线性递增(LID)离散化。
3.4. Depth Distribution Label Generation(深度分布标签生成)
我们需要深度分布标签![]() 来监督我们预测的深度分布。深度分布标签通过将LiDAR点云投影到图像帧中以创建稀疏密集地图来生成。执行深度完成[20]以在图像中的每个像素处生成深度值。我们需要每个图像特征像素处的深度信息,因此我们将尺寸为WI × HI的深度图下采样为图像特征尺寸WF × HF。使用第3.3节中描述的LID离散化方法将深度图转换为bin索引,然后转换为独热编码以生成深度分布标签。独热编码确保深度分布标签是清晰的,这对于通过监督鼓励我们的深度分布预测的清晰度至关重要。
来监督我们预测的深度分布。深度分布标签通过将LiDAR点云投影到图像帧中以创建稀疏密集地图来生成。执行深度完成[20]以在图像中的每个像素处生成深度值。我们需要每个图像特征像素处的深度信息,因此我们将尺寸为WI × HI的深度图下采样为图像特征尺寸WF × HF。使用第3.3节中描述的LID离散化方法将深度图转换为bin索引,然后转换为独热编码以生成深度分布标签。独热编码确保深度分布标签是清晰的,这对于通过监督鼓励我们的深度分布预测的清晰度至关重要。
3.5. Training Losses(训练损失)
一般来说,分类是通过预测分类分布来进行的,并鼓励分布的清晰度,以便选择正确的类别[19]。我们利用分类来鼓励在监督深度分布网络时使用焦点损失[30]的单个正确深度箱:
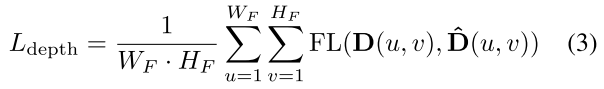
其中,D是深度分布预测,而WMD是深度分布标签。我们发现,自动驾驶数据集包含的图像的对象像素比背景像素少,导致损失函数在所有像素损失均匀加权时优先考虑背景像素。我们将焦点损失[30]加权因子α设置为前景物体像素的αfg = 3.25,背景像素的αbg = 0.25。前景目标像素被定义为所有位于二维目标边界框标签内的像素,而背景像素则是所有剩余的像素。我们设置焦点损失[30]聚焦参数γ = 2.0。
我们使用PointPillars [26]的分类损失Lcls,回归损失Lreg和方向分类损失Ldir进行3D对象检测。我们网络的总损失是深度和3D检测损失的组合:
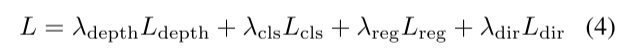
其中λdepth、λcls、λreg、λdir为固定损失加权因子。
4. Experimental Results(实验结果)
为了证明CaDDN的有效性,我们展示了KITTI 3D对象检测基准[16]和Waymo开放数据集[56]的结果。KITTI 3D物体检测基准[16]分为7,481个训练样本和7,518个测试样本。训练样本通常分为训练集(3,712个样本)和瓦尔集(3,769个样本),如下[10],这里也采用。我们通过在训练集和瓦尔集上训练我们的模型,将CaDDN与测试集上的现有方法进行比较。我们通过仅在训练集上训练我们的模型来评估消融的瓦尔集。Waymo Open Dataset是最近发布的自动驾驶数据集,由798个训练序列和202个验证序列组成。
数据集还包括150个没有地面实况数据的测试序列。该数据集通过多摄像机装备在全360 °视场中提供对象标签。我们只使用前置摄像头,并且只考虑前置摄像头视场(50.4 nm)中的对象标签,用于单目对象检测任务,并提供验证序列的结果。我们从训练序列中每隔3帧采样一次,以形成我们的训练集(51,564个样本),因为数据集大小很大,帧速率很高。
Input Parameters.(输入参数)
体素网格由3D空间中的范围和体素大小定义。在KITTI [16]上,我们分别使用[2,46.8] × [−30.08,30.08] × [−3,1](m)表示范围,[0.16,0.16,0.16](m)表示x、y和z轴的体素大小。在Waymo上,我们使用[2,55.76] × [− 25.6,25.6] × [− 4,4](m)表示范围,使用[0.16,0.16,0.16](m)表示体素大小。此外,我们将Waymo图像的采样降为1248 × 832。
Training and Inference Details.(训练和推理细节)
我们的方法在PyTorch [43]中实现。网络在NVIDIA Tesla V100(32G)GPU上训练。Adam [18]优化器的初始学习率为0.001,并使用单周期学习率策略[54]进行修改。我们在KITTI数据集[16]和Waymo开放数据集[56]上训练了80个历元的模型。KITTI [16]采用的批量为4,Waymo采用的批量为2。公式4中的损失加权系数使用了λdepth = 3.0、λcls = 1.0、λreg = 2.0、λdir = 0.2的值。我们采用水平翻转作为我们的数据扩充,并为所有类训练一个模型。在推理阶段,我们使用0.1的置信度阈值筛选边界框,并应用非极大值抑制(Non-Maximum Suppression, NMS),其交并比(IoU)阈值设置为0.01。
4.1. KITTI Dataset Results
使用平均精度(AP)评估KITTI数据集[16]的结果|R40)的基础上。评估按难度设置(“简单”、“中等”和“困难”)和对象类(“汽车”、“行人”和\"骑车人“)进行划分。汽车类的IoU标准为0.7,而步行者和骑自行车者类的IoU标准为0.5,其中IoU标准是被认为是真阳性检测的阈值。表1显示了KITTI [16]测试集上的CaDDN结果与最先进的已发表单眼方法的比较,按中等难度设置下Car类的性能等级顺序列出。我们注意到,我们的方法优于以前的单帧方法的大幅度的AP|在简单、中等和困难难度下,R40分别为+2.40%、+1.69%和+1.29%。此外,CaDDN的排名高于多帧方法Kinematic 3D [4]。我们的方法也优于先前的最先进的方法在行人类MonoPair [12]上的性能,在AP上有余量|R40分别为+2.85%、+1.46%和+1.23%。我们的方法在自行车类中获得第二名,在AP上有一定的优势|相对于单一PSR的R40分别为-1.37%、-1.33%和-0.38%[22]。
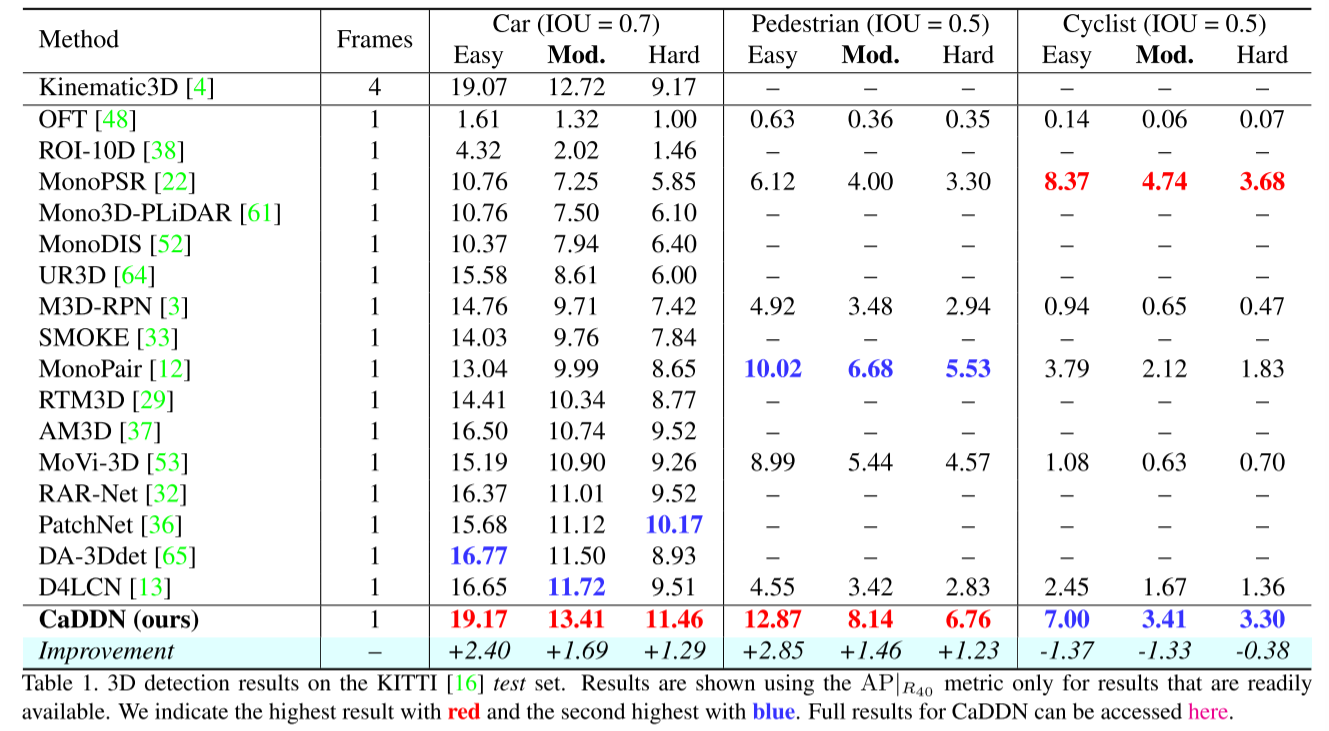
表1.KITTI [16]测试集的3D检测结果。使用AP显示结果|R40指标仅适用于随时可用的结果。我们用红色表示最高结果,用蓝色表示第二高结果。您可以在此处访问CaDDN的完整结果。
4.2. Waymo Dataset Results
我们采用官方发布的评估来计算Waymo开放数据集上的平均精度(mAP)和航向加权平均精度(mAPH)[56]。评估按难度设置(1级、2级)和与传感器的距离(0 - 30 m、30 - 50 m和50 m- ∞)分开。我们使用0.7和0.5的IoU标准对车辆类别进行评估。据我们所知,没有单目方法在Waymo上报告结果。为了提供一个基准,我们扩展了M3DRPN来支持Waymo开放数据集,表2显示了Waymo验证集上M3 D-RPN [3]基线和CaDDN的结果。我们的方法显著优于M3 D-RPN [3],对于IoU标准为0.7的1级和2级难度,AP/APH的裕度分别为+4.69%/+4.65%和+4.15%/+4.12%。
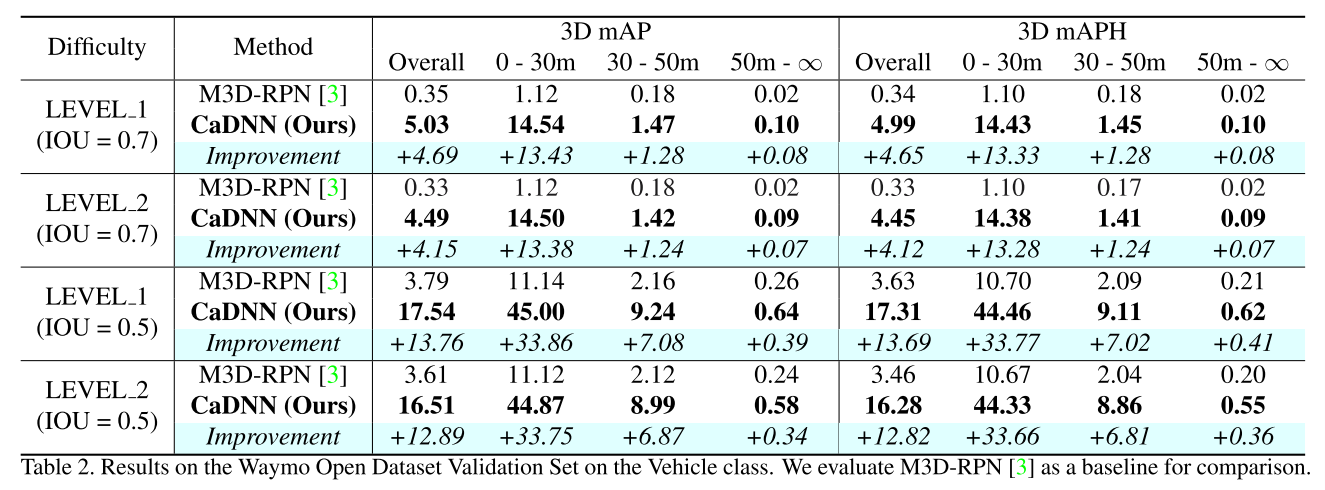
表2.Waymo Open Dataset Validation Set(车辆类的开放数据集验证集)的结果。我们评价了M3 D-RPN [3]作为比较的基线。
4.3. Ablation Studies
我们在网络上提供消融研究,以验证我们的设计选择。数值结果如表3 - 3和3所示.深度分布的清晰度。表3中的实验1示出了当截头体特征G由沿沿着深度轴di的重复图像特征F填充时的检测性能。实验2增加了深度分布预测D来单独加权图像特征F,这提高了AP上的性能|R40在汽车类的简单,中等和困难分别为+1.50%,+0.77%和+0.46%。一旦在实验3中添加深度分布监督,性能就大大提高(+10.40%,+7.60%,+6.54%),从而验证其包含性。深度分布监督的添加鼓励尖锐和准确的分类深度分布,这鼓励将图像信息定位在深度估计既准确又可信的3D空间中。鼓励正确深度箱周围的清晰度导致在BEV投影中唯一定位并且容易区分的对象特征(参见图1)。
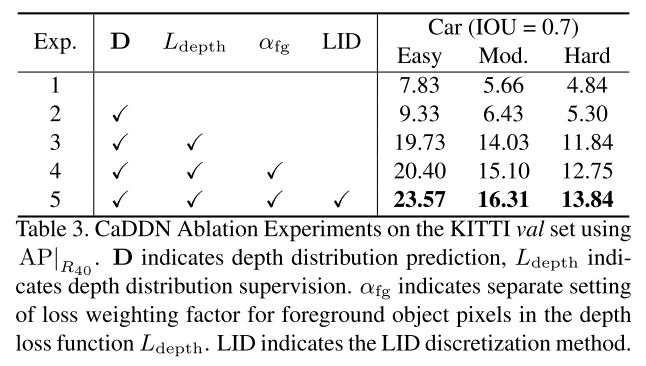
表3.使用AP在KITTI验证集上进行的CaDDN消融实验|R40的。D表示深度分布预测,Ldepth表示深度分布监控αfg表示在深度损失函数Ldepth中对前景对象像素的损失加权因子的单独设置。LID表示LID离散化方法。
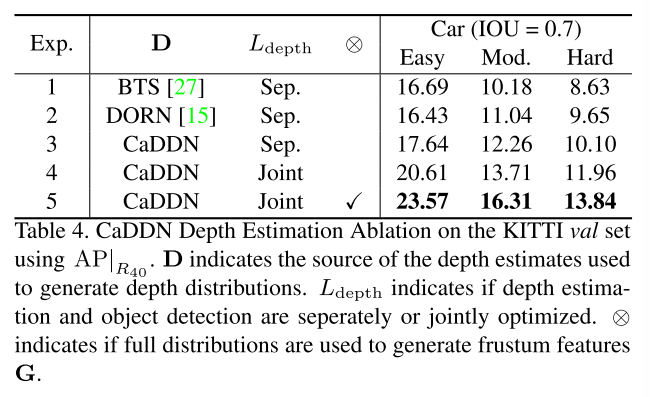
表4.使用AP在KITTI验证集上进行CaDDN深度估计消融|R40的。D指示用于生成深度分布的深度估计的源。Ldepth指示深度估计和对象检测是单独地还是联合地被优化。表示是否使用全分布来生成截锥特征G。
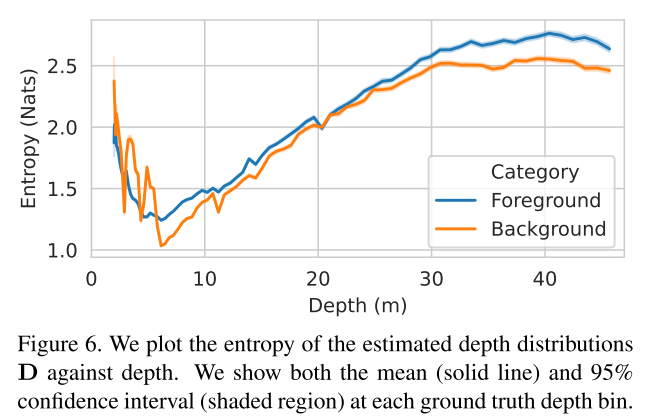
图6.我们绘制了估计的深度分布D的熵与深度的关系。我们显示了每个实际深度箱的平均值(实线)和95%置信区间(阴影区域)。
用于深度分布估计的对象加权。表3中的实验1、2和3对深度损失函数Ldepth中的所有像素使用固定损失加权因子α = 0.25。实验4显示了在为前景对象和背景像素分别设置深度损失权重αfg = 3.25/αbg = 0.25之后的改进(+0.67%,+1.07%,+0.91%)(参见第3.5节)。设置较大的前景对象加权因子αfg有助于优先考虑对象像素的深度估计,从而实现更准确的深度估计和对象定位。
线性递增离散化表3中的实验5显示了使用LID(参见第3.3节)而不是均匀离散化时的检测性能改进(+3.17%,+1.21%,+1.09%)。我们将性能提高归因于LID在所有深度上提供的准确深度估计[57]。
联合深度理解。表4中的实验1、2和3分别示出了使用来自BTS [27]、多恩[15]和CaDDN的单独深度估计的检测性能。来自BTS [27]和多恩[15]的深度图使用LID离散化转换为深度仓索引,如第3.3节所述,并转换为独热编码以生成深度分布D。独热编码在生成截头体特征G时将图像特征放置在由输入深度图指示的单个深度仓处。我们构造了一个等价的CaDDN版本,它通过为D中的每个分布选择概率最高的bin来为每个像素选择单个深度bin。实验4显示,当深度估计和对象检测联合执行时,性能有所提高(+2.97%,+1.45%,+1.86%),我们将其归因于端到端学习对3D检测的众所周知的好处。
分类深度分布。表4中的实验5在截头体特征计算G = D F中使用全深度分布D,导致性能的明显增加(+2.96%,2.60%,1.88%)。我们将性能提升归因于特征表示中嵌入的额外深度不确定性信息。
4.4. Depth Distribution Uncertainty(深度分布不确定性)
为了验证我们的深度分布包含有意义的不确定性信息,我们计算D中每个估计的分类深度分布的Shanon熵。我们用其相关的地面真值深度仓和前景/背景分类来标记每个分布。对于每个组,我们计算熵统计,如图6所示。我们观察到,熵通常随深度而增加,其中深度估计具有挑战性,这表明我们的分布描述了有意义的不确定性信息。我们的网络在地面真实深度约为6米的像素处产生最低的分布熵。我们将深度接近6米的高熵归因于训练集中较短范围内的少量像素。最后,我们注意到前景深度分布估计比背景像素具有略高的熵,这种现象也可以归因于训练集不平衡。
5.结论
我们已经提出了CaDDN,一种新的单目3D对象检测方法,估计每个像素的准确分类深度分布。深度分布与图像特征相结合,以生成保持深度置信度的鸟瞰图表示,以用于3D对象检测。我们已经证明,估计以正确的深度值为中心的尖锐分类分布,并联合执行深度估计和对象检测对于3D对象检测性能至关重要,导致在提交时所有已发表的方法中在KITTI数据集上排名第一。

