Spring Batch:提升数据处理效率
前言
在企业级应用开发领域,数据量正以前所未有的速度增长。面对海量数据,批处理任务就显得尤为重要,它能够在后台自动处理大量数据,无需人工实时干预,极大地提高了数据处理的效率和准确性。从数据仓库的构建到日常报表的生成,从大数据分析到数据迁移,批处理任务无处不在。
而 Spring Batch,作为 Spring 家族中专门用于批处理的框架,应运而生。它继承了 Spring 框架的优秀特性,如依赖注入、面向切面编程等,使得开发者能够以一种简洁、高效的方式构建批处理应用。Spring Batch 提供了丰富的功能和灵活的配置选项,能够满足各种复杂的批处理需求。无论是简单的数据读取和写入,还是复杂的数据转换和业务逻辑处理,Spring Batch 都能轻松应对。
Spring Batch 零基础入门
核心概念解析
Spring Batch 的核心概念主要包括 Job(作业)、Step(步骤)、ItemReader(数据读取器)、ItemProcessor(数据处理器)和 ItemWriter(数据写入器)。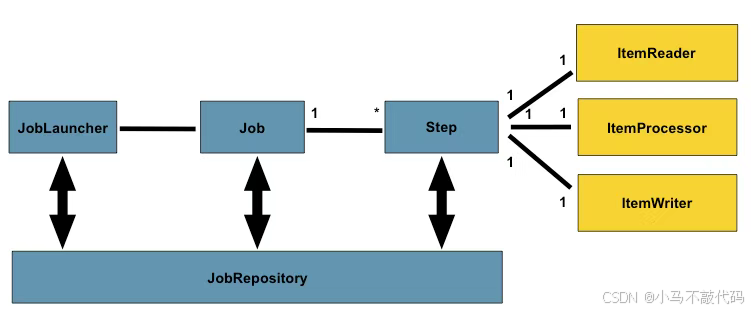
Job 是批处理的核心概念,它代表了一个完整的批处理任务。一个 Job 可以由一个或多个 Step 组成,这些步骤按照特定的顺序依次执行,共同完成一个复杂的批处理操作。例如,在一个数据迁移的批处理任务中,Job 可以包含从源数据库读取数据、对数据进行清洗和转换、将处理后的数据写入目标数据库等多个 Step。
Step 是 Job 的基本构建块,它定义了一个独立的、原子性的操作。每个 Step 都包含一个 ItemReader、一个 ItemProcessor(可选)和一个 ItemWriter。ItemReader 负责从数据源读取数据,它可以从文件、数据库、消息队列等各种数据源中获取数据,并将数据封装成一个个的 Item 传递给 ItemProcessor。比如,FlatFileItemReader 可以从 CSV 文件中读取数据,JdbcCursorItemReader 可以从数据库中读取数据。ItemProcessor 对从 ItemReader 读取的数据进行处理或转换,它可以对数据进行清洗、过滤、计算等操作,然后将处理后的数据传递给 ItemWriter。ItemWriter 负责将数据写入目标系统,它可以将数据写入文件、数据库、消息队列等。例如,JdbcBatchItemWriter 可以将数据写入数据库,FlatFileItemWriter 可以将数据写入文件。
架构探秘
Spring Batch 的架构分为三层:应用层、核心层和基础层。
应用层包含了所有自定义的批处理作业和业务流程代码。在这个层,开发者根据具体的业务需求编写作业配置、定义步骤、读写器等。比如,定义一个从 CSV 文件读取用户数据,经过处理后写入数据库的作业,就需要在应用层编写相应的配置和代码,包括定义 Job、Step,配置 ItemReader、ItemProcessor 和 ItemWriter 等。
核心层提供了启动和管理批处理作业的运行环境。核心层包含了 JobLauncher、JobRepository 等重要组件。JobLauncher 负责启动作业,它可以通过命令行、定时任务、REST API 等方式触发作业的执行。JobRepository 负责存储作业的元数据和执行状态信息,包括作业的定义、参数、执行历史、当前状态等。通过 JobRepository,Spring Batch 可以实现作业的重启、恢复、监控等功能。
基础层提供了基础的读写器、处理器和写入器实现,以及重试、跳过等异常处理机制。基础层还提供了对数据库、文件系统等数据源的支持。Spring Batch 在基础层提供了丰富的内置组件,如各种类型的 ItemReader、ItemProcessor 和 ItemWriter,开发者可以直接使用这些组件,也可以根据需要进行自定义扩展。例如,在处理数据时,如果遇到某些异常情况,基础层的异常处理机制可以决定是重试操作、跳过当前数据还是终止作业。
优势展示
Spring Batch 在多个方面展现出强大的优势。
在事务管理方面,Spring Batch 基于 Spring 框架的事务管理机制,能够确保批处理操作的原子性、一致性、隔离性和持久性。比如在数据写入数据库的过程中,如果出现错误,事务可以回滚,保证数据的完整性,避免数据不一致的情况发生。
扩展性上,Spring Batch 支持通过多种方式进行扩展。开发者可以通过实现自定义的 ItemReader、ItemProcessor 和 ItemWriter 来满足特定的业务需求。同时,Spring Batch 还支持作业的分区和并行处理,能够充分利用多核 CPU 的优势,提高批处理的性能和效率,轻松应对大规模数据处理的挑战。
可配置性也是 Spring Batch 的一大亮点。它支持多种配置方式,包括 XML 配置、注解配置和 Java 配置,开发者可以根据项目的实际情况和个人喜好选择合适的配置方式。通过灵活的配置,Spring Batch 可以适应不同的数据源、数据格式和业务逻辑,满足各种复杂的批处理场景。
可视化监控方面,Spring Batch 提供了丰富的监控和管理功能。通过相关的监控工具,开发者可以实时查看作业的执行状态、进度、性能指标等信息,及时发现和解决问题。同时,Spring Batch 还支持对作业的历史记录进行查询和分析,有助于优化批处理作业的性能和稳定性。
实战:Spring Batch 实际演示
准备工作
搭建 Spring Batch 开发环境是开启我们技术之旅的第一步。首先,我们通过 Spring Initializr 创建一个 Spring Boot 项目。在创建过程中,记得勾选 Spring Batch 依赖,这样 Spring Initializr 会帮我们自动引入 Spring Batch 相关的库,大大节省了手动配置的时间和精力。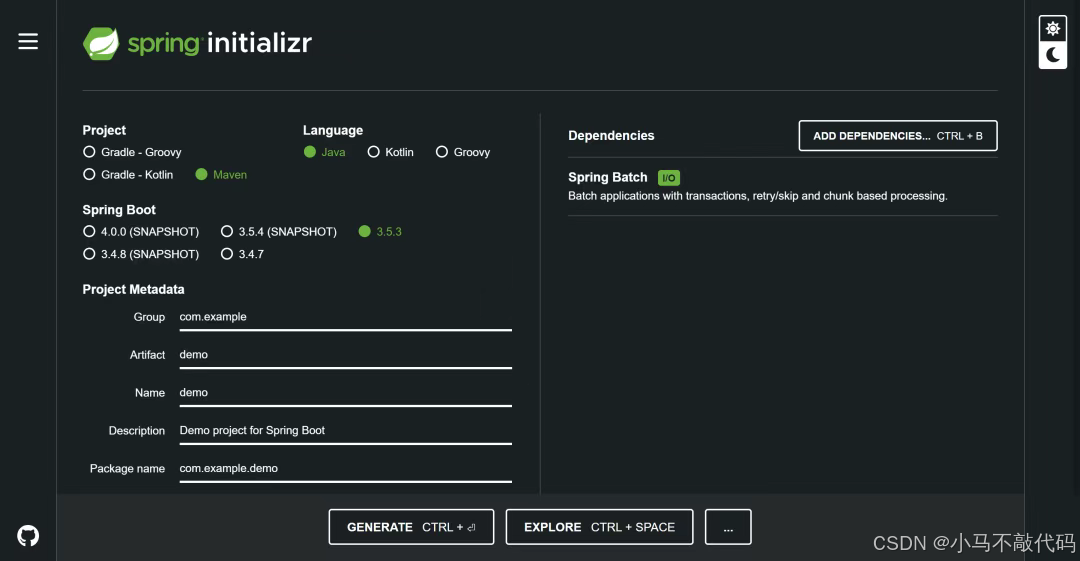
接下来,在项目的pom.xml文件中,确保添加了如下依赖:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId></dependency><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId></dependency><dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope></dependency><dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId></dependency>这里,spring-boot-starter-batch是 Spring Batch 的核心依赖,它包含了 Spring Batch 的各种核心组件和功能。spring-boot-starter-jdbc用于支持数据库操作,方便我们后续将数据写入数据库。h2是一个内存数据库,我们在这里使用它来简化开发和测试过程,当然在实际生产环境中,你可以根据需求替换为 MySQL、Oracle 等其他数据库。
然后,在application.properties文件中配置数据源:
spring.datasource.url=jdbc:h2:mem:testdbspring.datasource.driverClassName=org.h2.Driverspring.datasource.username=saspring.datasource.password=passwordspring.batch.jdbc.initialize-schema=always这段配置指定了数据源的 URL、驱动类、用户名和密码,spring.batch.jdbc.initialize-schema=always表示每次启动应用时,Spring Batch 会自动创建必要的数据库表,用于存储作业的元数据和执行状态信息。
开发批处理任务
现在,我们以从 CSV 文件读取数据、处理数据并写入数据库为例,来开发一个简单的批处理任务。
首先,创建一个实体类Customer,用于表示从 CSV 文件中读取的数据:
import lombok.Data;@Datapublic class Customer { private String firstName; private String lastName;}接着,配置ItemReader,从 CSV 文件中读取数据。这里我们使用FlatFileItemReader,它是 Spring Batch 提供的一个用于读取文本文件的读取器,非常适合读取 CSV 文件:
@Beanpublic FlatFileItemReader<Customer> reader() { return new FlatFileItemReaderBuilder<Customer>() .name(\"customerItemReader\") .resource(new ClassPathResource(\"customers.csv\")) .delimited() .names(new String[]{\"firstName\", \"lastName\"}) .fieldSetMapper(new BeanWrapperFieldSetMapper<Customer>() {{ setTargetType(Customer.class); }}) .build();}在这段代码中,我们通过FlatFileItemReaderBuilder来构建FlatFileItemReader。name指定了读取器的名称,resource指定了要读取的 CSV 文件路径,这里使用ClassPathResource表示从类路径下读取文件。delimited表示文件是分隔符分隔的,names指定了 CSV 文件中列的名称,fieldSetMapper用于将读取到的字段映射到Customer实体类的属性上。
然后,配置ItemProcessor,对读取到的数据进行处理。假设我们需要将客户的名字和姓氏都转换为大写:
@Componentpublic class CustomerProcessor implements ItemProcessor<Customer, Customer> { @Override public Customer process(Customer customer) throws Exception { customer.setFirstName(customer.getFirstName().toUpperCase()); customer.setLastName(customer.getLastName().toUpperCase()); return customer; }}在process方法中,我们获取到从ItemReader读取的Customer对象,将其名字和姓氏转换为大写后,再返回处理后的Customer对象。
最后,配置ItemWriter,将处理后的数据写入数据库。这里我们使用JdbcBatchItemWriter,它可以将数据批量写入数据库:
@Beanpublic JdbcBatchItemWriter<Customer> writer(DataSource dataSource) { return new JdbcBatchItemWriterBuilder<Customer>() .itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>()) .sql(\"INSERT INTO customers (first_name, last_name) VALUES (:firstName, :lastName)\") .dataSource(dataSource) .build();}在这段代码中,itemSqlParameterSourceProvider用于提供 SQL 参数源,这里使用BeanPropertyItemSqlParameterSourceProvider,它会根据Customer实体类的属性来生成 SQL 参数。sql指定了插入数据的 SQL 语句,dataSource指定了数据源。
接下来,配置Step和Job:
@Beanpublic Step step1(JdbcBatchItemWriter<Customer> writer, FlatFileItemReader<Customer> reader, CustomerProcessor processor) { return stepBuilderFactory.get(\"step1\") .<Customer, Customer>chunk(10) .reader(reader) .processor(processor) .writer(writer) .build();}@Beanpublic Job importCustomerJob(JobCompletionNotificationListener listener, Step step1) { return jobBuilderFactory.get(\"importCustomerJob\") .incrementer(new RunIdIncrementer()) .listener(listener) .flow(step1) .end() .build();}在step1中,我们通过chunk(10)指定每次读取和处理 10 条数据,然后将这 10 条数据批量写入数据库。reader、processor和writer分别指定了前面配置的读取器、处理器和写入器。在importCustomerJob中,我们定义了一个名为importCustomerJob的作业,incrementer用于生成唯一的作业实例 ID,listener用于监听作业的完成事件,flow指定了作业包含的步骤。
运行与监控
完成上述配置后,我们可以通过多种方式运行批处理任务。如果是在 Spring Boot 应用中,可以通过实现CommandLineRunner接口,在应用启动时自动运行作业:
@SpringBootApplicationpublic class BatchApplication implements CommandLineRunner { @Autowired private JobLauncher jobLauncher; @Autowired private Job importCustomerJob; public static void main(String[] args) { SpringApplication.run(BatchApplication.class, args); } @Override public void run(String... args) throws Exception { JobParameters jobParameters = new JobParametersBuilder() .addLong(\"time\", System.currentTimeMillis()) .toJobParameters(); jobLauncher.run(importCustomerJob, jobParameters); }}在run方法中,我们通过JobLauncher来启动作业,并传入一个包含时间戳的JobParameters,以确保每次运行作业时的参数不同,从而避免作业实例重复。
Spring Batch 提供了丰富的监控功能,帮助我们实时了解作业的执行情况。通过查看数据库中 Spring Batch 自动创建的表,如BATCH_JOB_INSTANCE、BATCH_JOB_EXECUTION、BATCH_STEP_EXECUTION等,我们可以获取作业的实例信息、执行历史、步骤执行情况等。例如,BATCH_JOB_EXECUTION表记录了每个作业执行的开始时间、结束时间、状态等信息,通过查询该表,我们可以了解作业是否成功执行,以及执行过程中是否出现错误。
此外,Spring Batch 还支持与 Spring Boot Admin 等监控工具集成,通过可视化界面展示作业的执行状态、进度、性能指标等信息,让我们更加直观地监控和管理批处理作业。
与其他框架的魔法较量
主流批处理框架介绍
在批处理的江湖中,Spring Batch 并非一枝独秀,还有许多其他优秀的框架。
Hadoop MapReduce 是大数据领域的先驱,它采用 “分而治之” 的思想,将大规模数据处理任务分解为 Map 和 Reduce 两个阶段。在 Map 阶段,数据被分割成多个小块,每个小块由一个 Map 任务独立处理,生成一系列的键值对。例如,在处理海量文本数据统计单词出现次数的场景中,Map 任务会将每一行文本拆分成单词,并为每个单词生成一个键值对,其中键是单词,值是 1。在 Reduce 阶段,具有相同键的键值对会被聚合在一起进行处理,得到最终的结果。比如,将所有单词的键值对按照单词进行分组,然后统计每个单词对应的出现次数总和。Hadoop MapReduce 的优势在于能够充分利用集群资源,实现大规模数据的并行处理,适用于离线大数据处理场景,如数据仓库的构建、海量日志分析等。
Apache Spark 是近年来备受瞩目的大数据处理框架,它基于内存计算,大大提高了数据处理的速度。Spark 不仅支持批处理,还提供了强大的流处理、机器学习、图计算等功能。Spark 的核心数据结构是 RDD(弹性分布式数据集),它可以在内存中进行快速的计算和操作。在处理实时流数据时,Spark Streaming 通过将流数据分割成小的时间片,以微批处理的方式进行处理,实现了低延迟的实时处理。同时,Spark 的机器学习库 MLlib 提供了丰富的机器学习算法和工具,方便开发者进行数据分析和模型训练。
Apache Flink 是一个分布式流处理和批处理框架,它以流处理为核心,将批处理视为流处理的特殊情况。Flink 支持事件时间语义,能够准确处理乱序到达的数据,这在处理实时流数据时非常重要。例如,在物联网场景中,传感器数据可能由于网络延迟等原因导致到达时间不一致,Flink 可以根据事件发生的时间进行准确的处理。Flink 还提供了丰富的窗口操作,如滑动窗口、滚动窗口、会话窗口等,能够满足各种复杂的流处理需求。此外,Flink 在内存管理和资源利用方面表现出色,能够实现高效的分布式计算。
对比分析
不同的批处理框架在功能、性能和适用场景上各有千秋。
从功能上看,Spring Batch 专注于批处理任务的构建和管理,提供了丰富的批处理组件和功能,如作业的定义、执行、监控等,适合处理传统的批处理任务。Hadoop MapReduce 主要用于大规模数据的分布式处理,其核心功能是 Map 和 Reduce 操作,适用于离线大数据处理场景。Apache Spark 功能更加全面,不仅支持批处理,还在流处理、机器学习等地方表现出色,能够满足多种大数据处理需求。Apache Flink 则以流处理为核心,在流处理方面具有强大的功能和优势,同时也能很好地处理批处理任务。
性能方面,Spring Batch 在处理小规模到中等规模的数据时表现良好,通过合理的配置和优化,能够满足大多数企业级批处理的性能要求。Hadoop MapReduce 由于采用分布式计算,在处理大规模数据时具有较高的吞吐量,但由于其基于磁盘的计算模型,在处理速度上相对较慢。Apache Spark 基于内存计算,大大提高了数据处理的速度,尤其在迭代计算和交互式数据分析方面表现出色。Apache Flink 在流处理性能上表现卓越,能够实现低延迟、高吞吐量的实时处理,同时在批处理性能上也有不错的表现。
适用场景上,Spring Batch 适用于企业级应用中的常规批处理任务,如数据备份、报表生成、数据同步等。当数据量较小,对实时性要求不高,且需要与 Spring 生态系统紧密集成时,Spring Batch 是一个很好的选择。Hadoop MapReduce 适用于大规模离线数据处理,如大数据分析、数据挖掘等场景,当数据量达到 PB 级,需要利用集群进行分布式计算时,Hadoop MapReduce 能够发挥其优势。Apache Spark 适用于需要进行复杂数据分析和处理的场景,如机器学习、实时流处理与批处理结合等。如果应用需要进行实时数据分析、模型训练和预测等任务,Spark 可以提供一站式的解决方案。Apache Flink 则更适合实时流处理场景,如实时监控、实时推荐、金融交易处理等,当数据以流的形式持续产生,且对处理延迟要求严格时,Flink 能够准确、高效地处理数据。


