Python遗传算法解决旅行商问题项目代码
本文还有配套的精品资源,点击获取 
简介:旅行商问题(TSP)是一个要求寻找最短路线以访问所有城市一次并返回起点的组合优化问题。遗传算法是一种基于自然选择的搜索技术,适用于TSP等复杂优化问题。在Python中实现遗传算法涉及定义种群初始化、适应度函数、选择操作和遗传操作等步骤。本项目代码涵盖从CSV文件读取城市位置数据,通过Python编码执行遗传算法以优化解决问题的过程。用户还可以通过改进适应度函数、调整算法参数或采用新的编码方式来进一步优化代码性能。
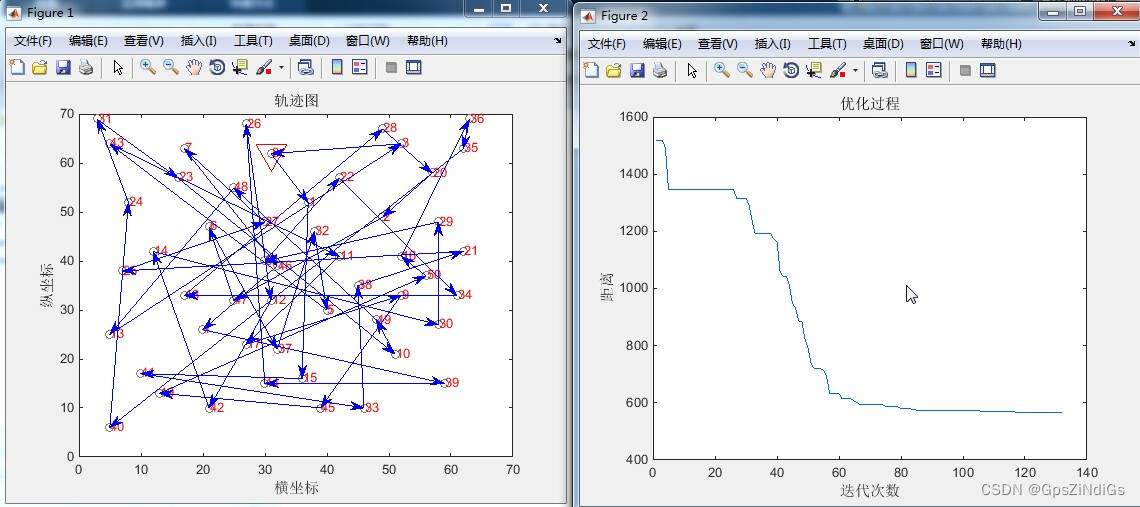
1. 旅行商问题(TSP)概述
旅行商问题(TSP)是一个在组合优化和计算机科学领域广为人知的问题。其核心要求非常直观:给定一系列城市和每对城市之间的距离,旅行商需要找到一条最短的路线,这条路线必须访问每个城市一次,并最终返回出发城市。尽管其定义简单,TSP问题却是NP-hard的,意味着目前还没有已知能在多项式时间内解决所有TSP案例的算法。这使得研究者们提出了多种启发式和近似算法来寻求可接受的解决方案。
从历史角度来看,TSP起源于1930年代,当时人们在寻找高效邮递路线和生产调度计划中遇到了这个问题。此后,TSP迅速成为一个具有挑战性的案例研究,推动了运筹学、计算机科学以及相关学科的大量研究工作。
TSP的应用场景非常广泛,从物流路径规划到电路板布线设计,从DNA测序到机器人路径规划,TSP的相关理念和技术被应用到各种问题中,展现出巨大的实用价值。随着计算能力的增强和算法的进化,TSP问题的解决方法不断进步,也为其他复杂问题的解决提供了宝贵的思路和手段。
2. 遗传算法基础概念
遗传算法是一种启发式搜索算法,通过模拟生物进化过程中自然选择、遗传和突变等机制来解决问题。它在多个领域,尤其是复杂优化问题中得到了广泛应用。本章深入探讨了遗传算法的基本原理、核心组成部分和在解决优化问题时的优势与局限性。
2.1 遗传算法的工作原理
2.1.1 自然选择与适者生存
自然选择是达尔文进化论的核心概念,指的是在一定的环境条件下,适应环境的个体更可能生存并繁衍后代。在遗传算法中,每一个潜在的解可以被视为一个个体,而这些个体的适应度则反映了它们的生存能力。
通过模拟这一过程,算法反复地选择适应度高的个体进行“繁殖”(即交叉和变异操作),产生下一代解。这样,算法能够逐渐地淘汰掉适应度低的个体,而适应度高的个体得到保留并逐渐占据种群的主导地位。
2.1.2 遗传机制与染色体编码
在生物遗传中,染色体是遗传信息的载体。遗传算法借鉴这一概念,将问题的潜在解编码为染色体,通常是一个二进制串,但也可以是其他形式的编码(如整数串或实数串)。一个染色体代表了一个具体的解。
编码的目的是为了使得算法可以通过交叉和变异操作在解空间中进行有效搜索。染色体的编码方式直接影响算法的性能,因此设计一个合适的编码策略对于遗传算法的成功至关重要。
2.1.3 交叉、变异与种群进化
在生物遗传中,交叉(或称为杂交)是指两个个体的染色体按照某种方式交换片段,从而产生新的后代。变异则是指染色体在复制过程中发生的随机变化,导致遗传信息的改变。在遗传算法中,交叉和变异是产生新解的关键操作。
种群进化是指通过选择、交叉和变异操作,种群中的个体不断进化,逐渐趋向于更优解的过程。这一过程中,优秀的基因组合被保留并传递到下一代,而较差的基因组合则被淘汰。
2.2 遗传算法的关键参数
2.2.1 种群大小和代数设定
种群大小(Population Size)是指算法中同时存在的个体数量。这个参数对算法的搜索效率和解的质量都有重要影响。如果种群太小,算法可能无法有效地覆盖解空间;而如果种群太大,则会导致计算量剧增。
代数(Number of Generations)是指算法迭代的次数,即种群进化多少代。代数越多,算法运行时间越长,理论上解的质量越高,但同时也会增加计算资源的消耗。
2.2.2 选择、交叉和变异率的调整
选择率(Selection Rate)决定了多少比例的当前种群会参与到下一代的产生中。选择压力过大可能导致早熟收敛,即算法过快地陷入局部最优解而无法跳出。
交叉率(Crossover Rate)和变异率(Mutation Rate)是控制交叉和变异操作发生的频率。通常,交叉率设置得较高,因为交叉是产生新解的主要方式。而变异率则相对较低,因为过度的变异会破坏已有的优秀基因组合。
2.2.3 适应度函数的设计原则
适应度函数(Fitness Function)是评价个体适应度的标准,也是指导算法搜索方向的关键。设计一个好的适应度函数需要确保其能够有效地区分个体的适应度差异,并且与问题目标紧密对应。
在TSP问题中,适应度函数通常是最短路径长度的倒数或负数,因为路径越短,适应度应该越高。设计时需要注意函数的尺度和溢出问题,以及确保适应度与问题目标正相关。
# 示例:TSP问题中适应度函数的一个简单实现def calculate_fitness(tour, distance_matrix): \"\"\"计算个体的适应度值\"\"\" total_distance = sum([distance_matrix[tour[i]][tour[i+1]] for i in range(len(tour)-1)]) return 1 / total_distance # 路径越短,适应度越高# 假设distance_matrix为城市间距离矩阵,tour为一条路径distance_matrix = [[0, 2, 9, 10], [1, 0, 6, 4], [15, 7, 0, 8], [6, 3, 12, 0]]tour = [0, 2, 1, 3] # 一条初始路径# 计算适应度fitness = calculate_fitness(tour, distance_matrix)print(fitness) # 输出适应度值以上代码展示了如何定义一个简单的适应度函数,用于评价TSP问题中一条路径的质量。适应度函数的设计是遗传算法中非常关键的一个环节,它直接影响到算法的搜索效率和结果质量。在实际应用中,可能需要根据具体问题调整适应度函数,以获得更好的效果。
3. 遗传算法的四个主要步骤
3.1 种群初始化
种群初始化是遗传算法的第一步,它涉及到创建一个初始种群,这些种群代表了问题可能解空间中的一组候选解。种群初始化的质量直接影响到算法的全局搜索能力和收敛速度。
3.1.1 初始化策略的选择
初始化策略的选取非常重要,因为它决定了搜索过程的起点。常见的初始化方法包括随机初始化和启发式初始化。随机初始化简单易行,但可能需要较多的迭代次数才能收敛到优质解。启发式初始化则利用问题的特定知识来生成初始种群,例如根据城市间的距离分布来构造初始路径,这有助于算法快速定位到优质解区域。
3.1.2 种群多样性的保持
保持种群多样性是避免算法过早陷入局部最优解的关键。如果种群中个体的相似度过高,算法的搜索能力会降低。因此,在初始化种群时,应采取措施确保个体之间的差异。一种常见的方法是使用随机种子并结合多样性控制机制,如引入变异操作来增加种群的遗传多样性。
3.2 适应度函数的定义与应用
适应度函数是评估个体优劣的标尺,对于TSP而言,适应度函数通常是路径长度的倒数,即路径越短,适应度越高。
3.2.1 适应度函数的构建方法
适应度函数需要精确地反映出个体的适应程度,以指导算法搜索。对于TSP,路径长度是最直观的适应度指标。然而,适应度函数可以根据实际问题灵活设计,例如可以加入惩罚项来处理特定约束条件。
3.2.2 适应度函数在TSP中的特殊考虑
在TSP问题中,除了路径长度以外,可能还需考虑其他约束条件,如时间窗口、车辆容量等。为此,适应度函数需要扩展来处理这些复杂条件。例如,可以对超时的路径施加额外的惩罚,以此确保在寻找最短路径的同时,其他约束条件也能得到满足。
3.3 选择操作的设计
选择操作用于从当前种群中选出较优的个体,遗传到下一代中,它直接影响到优秀基因的保留概率。
3.3.1 轮盘赌选择、锦标赛选择等方法
轮盘赌选择方法通过计算每个个体的选择概率来模拟生物的自然选择过程。锦标赛选择则是随机选择若干个体,从中选出最佳的一个进入下一代。这两种方法各有优势,轮盘赌选择可能会让适应度较高的个体过度遗传,而锦标赛选择则可以在一定程度上保留种群多样性。
3.3.2 选择压力的调整与控制
选择压力指的是选择过程对个体适应度差异的敏感程度。过高或过低的选择压力都会对算法性能产生负面影响。一般通过调整选择操作中使用的参数(如轮盘赌的选择概率分布或锦标赛选择的大小)来控制选择压力。
3.4 遗传操作的实现细节
遗传操作是遗传算法中用于模拟生物遗传机制的过程,包括交叉和变异两个主要环节。
3.4.1 交叉操作的技术要点
交叉操作是通过组合父代个体的部分染色体来生成子代的过程。对于TSP问题,常见的交叉技术有顺序交叉(OX)、部分映射交叉(PMX)等。选择合适的交叉策略可以有效避免无效路径的产生,确保子代个体的遗传质量。
3.4.2 变异操作的实现策略
变异操作是在个体的染色体上引入小的随机改变,以保持种群多样性并可能发现更优解。对于TSP问题,常用的变异策略包括交换变异、逆转变异等。合理设置变异率和变异策略对于平衡算法的探索和开发能力至关重要。
4. Python中遗传算法的实现方法
遗传算法在解决优化问题上,尤其是在旅行商问题(TSP)上的应用已经相当广泛。这一章节会深入探讨如何利用Python语言和它的库来实现遗传算法,并通过代码示例和分析来加深理解。
4.1 Python实现遗传算法的框架搭建
在Python中实现遗传算法涉及几个核心组件,包括环境搭建、库的使用和核心函数的定义。下面会按照这个思路逐步展开。
4.1.1 Python环境和库的准备
为了更好地实现遗传算法,首先需要确保我们的Python环境已经准备好了一些常用的库。比如:
-
numpy: 用于高效的数值计算; -
matplotlib: 用于绘制路径和结果展示; -
pandas: 用于方便地处理CSV文件数据。
可以通过pip安装这些库:
pip install numpy matplotlib pandas4.1.2 遗传算法核心函数的定义
遗传算法的核心函数包括种群初始化、适应度计算、选择、交叉和变异操作。这些函数将作为构建遗传算法框架的基础。下面是一个简单的框架示例:
import numpy as npimport randomdef initialize_population(num_cities): # 初始化种群 passdef calculate_fitness(route): # 计算适应度 passdef select(population, fitnesses): # 选择函数 passdef crossover(parent1, parent2): # 交叉函数 passdef mutate(route): # 变异函数 passdef genetic_algorithm(population_size, num_generations, num_cities): # 遗传算法主体 pass# 下面将会分别实现和分析这些函数。4.2 Python代码示例与分析
在这一部分,将给出种群初始化与适应度计算、选择、交叉、变异操作的代码实现,并进行详细的分析。
4.2.1 种群初始化与适应度计算的代码实现
种群初始化是指创建初始的种群个体,通常为随机生成。适应度计算则是根据TSP问题的目标,计算路径的总距离或总成本。
def initialize_population(num_cities, population_size): population = [] for _ in range(population_size): # 生成一条随机路径 route = list(range(num_cities)) random.shuffle(route) population.append(route) return populationdef calculate_fitness(route): # 这里为了简化问题,我们只是简单计算路径总距离 num_cities = len(route) return sum([abs(route[i % num_cities] - route[(i + 1) % num_cities]) for i in range(num_cities)])4.2.2 选择、交叉、变异操作的代码实践
选择操作是根据适应度来决定哪些个体能参与到下一代的生成中。交叉和变异是遗传算法中创造新个体的两种主要方式。
def select(population, fitnesses): # 轮盘赌选择 fitness_sum = sum(fitnesses) probability = [f/fitness_sum for f in fitnesses] indices = np.random.choice(range(len(population)), size=len(population), p=probability) return [population[index] for index in indices]def crossover(parent1, parent2): # 简单的单点交叉 size = min(len(parent1), len(parent2)) crossover_point = random.randrange(1, size) child = parent1[:crossover_point] + parent2[crossover_point:] return childdef mutate(route): # 随机交换变异 index1, index2 = random.sample(range(len(route)), 2) route[index1], route[index2] = route[index2], route[index1] return route4.2.3 算法运行流程的控制和结果展示
最后,我们将这些函数组织起来,形成遗传算法的主体,并运行算法来得到TSP问题的近似最优解。
def genetic_algorithm(population_size, num_generations, num_cities): population = initialize_population(num_cities, population_size) for generation in range(num_generations): fitnesses = [calculate_fitness(route) for route in population] population = select(population, fitnesses) new_population = [] for _ in range(population_size // 2): parent1, parent2 = random.sample(population, 2) child = crossover(parent1, parent2) child = mutate(child) new_population.extend([child, child]) # 在这里我们采用精英策略,保留了最好的个体 population = new_population # 打印当前代数和最佳适应度 best_fitness = min(fitnesses) print(f\"Generation {generation}: Best Fitness = {best_fitness}\") # 返回最佳路径 best_route_index = np.argmin(fitnesses) return population[best_route_index]best_route = genetic_algorithm(population_size=100, num_generations=500, num_cities=10)print(\"Best route found:\", best_route)这个简单的遗传算法实现为读者提供了理解遗传算法如何工作的一个基础,并且展示了如何将理论应用到实际的编程实践中。在实际应用中,为了得到更好的结果,往往还需要对算法的参数进行微调,或者加入更高级的交叉和变异策略。
5. CSV文件中城市数据的读取与处理
5.1 CSV文件数据读取技术
CSV文件由于其格式简单、易于编辑和交换数据等优点,在数据存储和传输中被广泛使用。对于旅行商问题(TSP),城市坐标数据通常以CSV格式存储,本节将重点讨论如何在Python中高效地读取这些数据。
5.1.1 Python中处理CSV文件的方法
Python的内置 csv 模块提供了读取和写入CSV文件的功能。使用该模块,我们可以轻松地将CSV文件中的数据读取到内存中,并转换成适合于遗传算法操作的格式。以下是一个简单的读取CSV文件的代码示例:
import csv# 定义一个函数来读取CSV文件def read_csv(file_path): with open(file_path, mode=\'r\') as file: csv_reader = csv.reader(file) data = [row for row in csv_reader] return data# 假设城市坐标存储在cities.csv中cities_data = read_csv(\'cities.csv\')print(cities_data)5.1.2 从CSV中提取城市坐标数据
从CSV文件中提取特定的列(如城市的经纬度坐标)是处理数据时的常见任务。假设CSV文件的格式如下:
CityID,Name,X_Coordinate,Y_Coordinate1,New York,-74.0060,40.71282,Los Angeles,-118.2437,34.0522我们可以修改上述代码来专门提取坐标数据:
def extract_coordinates(file_path): with open(file_path, mode=\'r\') as file: csv_reader = csv.DictReader(file) coordinates = {(row[\'CityID\'], row[\'Name\']): (float(row[\'X_Coordinate\']), float(row[\'Y_Coordinate\'])) for row in csv_reader} return coordinatescity_coordinates = extract_coordinates(\'cities.csv\')print(city_coordinates)5.2 数据预处理和格式化
在将数据集成到遗传算法中之前,确保数据的质量和格式是至关重要的。错误或不规范的数据可能会导致算法运行错误或结果不准确。
5.2.1 数据验证和清洗
在处理CSV文件时,数据验证是一个重要的步骤。我们需要检查数据的完整性和准确性,确保所有坐标都是有效的数值,并且没有遗漏。
def validate_data(data): for row in data: if not row[\'X_Coordinate\'].replace(\'.\', \'\', 1).isdigit() or not row[\'Y_Coordinate\'].replace(\'.\', \'\', 1).isdigit(): return False return True# 假设data是从CSV文件中读取的原始数据列表is_valid = validate_data(data)print(f\"Data is {\'valid\' if is_valid else \'invalid\'}\")5.2.2 坐标数据的标准化处理
为了提高遗传算法的效率,通常需要对坐标数据进行标准化处理。例如,将所有城市坐标归一化到一个固定范围内,或者转换到欧几里得空间中的标准位置。
from sklearn.preprocessing import MinMaxScalerdef normalize_coordinates(coordinates): scaler = MinMaxScaler() # 将坐标列表转换为二维数组 coords_array = np.array(list(coordinates.values())) scaled_coords = scaler.fit_transform(coords_array) # 将标准化后的数据重新映射到坐标字典中 normalized_coords = {city: (x, y) for ((_, _), (x, y)) in zip(coordinates.items(), scaled_coords)} return normalized_coordscity_coordinates_normalized = normalize_coordinates(city_coordinates)print(city_coordinates_normalized)5.3 集成数据到遗传算法中
成功读取并预处理CSV中的城市坐标数据后,接下来我们将这些数据集成到遗传算法中,以优化TSP路径。
5.3.1 数据结构的设计与实现
为了将数据集成到遗传算法中,我们需要设计合适的数据结构。例如,我们可以使用字典来存储城市的名称和它们的标准化坐标。
# 在遗传算法中定义城市数据结构class CityData: def __init__(self): self.cities = {} # 存储城市名称和坐标 def load_from_csv(self, file_path): self.cities = extract_coordinates(file_path)# 示例使用city_data = CityData()city_data.load_from_csv(\'cities.csv\')5.3.2 遗传算法与数据处理的整合
最后一步是将遗传算法的核心逻辑与城市数据整合起来。我们需要确保遗传算法在操作过程中能够使用城市坐标数据,并且能够根据城市间距离计算适应度分数。
class GeneticAlgorithm: def __init__(self, city_data): self.city_data = city_data def calculate_fitness(self, individual): # 此处计算路径的适应度(总距离) # 个体是一系列城市ID的序列 total_distance = 0 for i in range(len(individual)): city1 = individual[i] city2 = individual[(i + 1) % len(individual)] total_distance += self.calculate_distance(city1, city2) return 1 / total_distance # 适应度与距离成反比 def calculate_distance(self, city1, city2): # 基于城市坐标计算两个城市间的距离 x1, y1 = self.city_data.cities[city1] x2, y2 = self.city_data.cities[city2] return ((x1 - x2) ** 2 + (y1 - y2) ** 2) ** 0.5# 示例使用ga = GeneticAlgorithm(city_data)individual = list(city_data.cities.keys()) # 假设路径为城市列表的一个排列fitness = ga.calculate_fitness(individual)print(f\"The fitness score for this individual is: {fitness}\")本章涵盖了从CSV文件中读取城市坐标数据、进行必要的预处理和格式化,以及将数据集成到遗传算法中的一系列步骤。这些步骤对于在实际应用中有效利用遗传算法求解TSP问题至关重要。
本文还有配套的精品资源,点击获取
简介:旅行商问题(TSP)是一个要求寻找最短路线以访问所有城市一次并返回起点的组合优化问题。遗传算法是一种基于自然选择的搜索技术,适用于TSP等复杂优化问题。在Python中实现遗传算法涉及定义种群初始化、适应度函数、选择操作和遗传操作等步骤。本项目代码涵盖从CSV文件读取城市位置数据,通过Python编码执行遗传算法以优化解决问题的过程。用户还可以通过改进适应度函数、调整算法参数或采用新的编码方式来进一步优化代码性能。
本文还有配套的精品资源,点击获取


