基于CentOS 7系统搭建Hadoop(伪分布式安装)
本篇将说明如何给新创建的CentOS 7系统搭建Hadoop伪分布式
目录
前期准备
正式开始
解压Hadoop文件
修改环境配置
修改Hadoop配置
前往配置目录
修改hadoop-env.sh文件
修改core-site.xml文件
创建并修改mapred-site.xml文件
修改yarn-site.xml文件
修改hdfs-site.xml文件
修改slaves文件
hdfs格式化
启动Hadoop
关闭Hadoop并设置免密
完成配置
前期准备
1、centos7操作系统(如何操作可看:VMware中安装centos7操作系统(图文超详细))
2、SecureCRT链接centos7系统终端(如何操作可看:SecureCRT中文版如何连接centos7系统终端(图文超易懂))
3、Java环境(如何配置可看:CentOS7系统如何配置JDK(图文配合,详细易懂) )
4、hadoop-2.7.3.tar.gz压缩包下载:Linux系统使用的Hadoop2.7.3版本压缩包
正式开始
解压Hadoop文件
将hadoop-2.7.3.tar.gz压缩包上传至/opt/app目录下,完成后在终端会话中使用‘cd /opt/app’命令前往/opt/app目录下再使用ls命令确认上传完成
cd /opt/appls
使用‘tar -zxvf hadoop-2.7.3.tar.gz -C /usr/local/bigdata’命令将hadoop-2.7.3.tar.gz解压至/usr/local/bigdata目录下(按需求自行指定存放位置,没有目录可使用‘mkdir -p /usr/local/bigdata’命令进行创建),完成后使用‘cd /usr/local/bigdata’命令进入解压后的目录查看文件
tar -zxvf hadoop-2.7.3.tar.gz -C /usr/local/bigdatacd /usr/local/bigdata
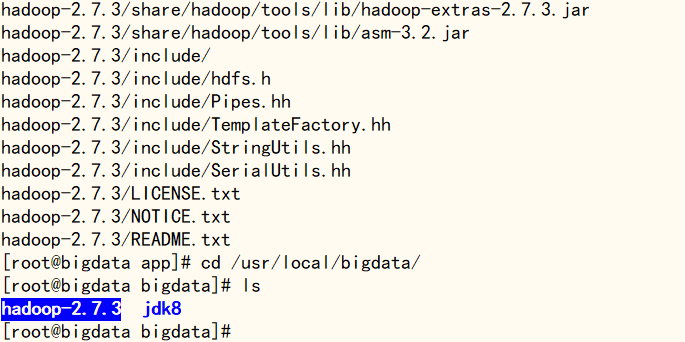
确认文件解压成功,使用‘mv hadoop-2.7.3/ /usr/local/bigdata/hadoop_2.7.3’命令修改文件夹名称(可自行设定),完成后再使用ls命令查看修改情况
mv hadoop-2.7.3/ /usr/local/bigdata/hadoop_2.7.3ls
修改环境配置
使用‘vi /etc/profile’编辑配置文件,在文件末尾加入以下内容(HADOOP_HOME需根据hadoop文件夹所在的完整目录进行配置):
vi /etc/profile
#HADOOP
export HADOOP_HOME=/usr/local/bigdata/hadoop_2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
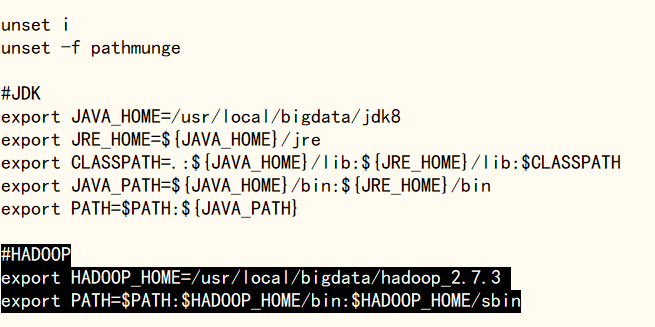
完成后使用‘:wq’保存退出,输入‘source /etc/profile’命令使修改的profile文件生效
source /etc/profile
修改Hadoop配置
前往配置目录
使用‘cd /usr/local/bigdata/hadoop_2.7.3/etc/hadoop’ 命令进入hadoop配置文件所在目录,使用ls命令可查看文件
cd /usr/local/bigdata/hadoop_2.7.3/etc/hadoopls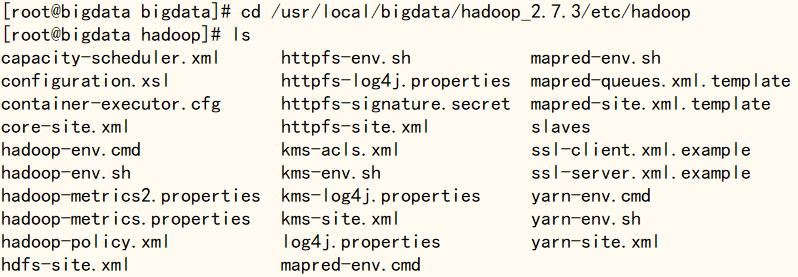
修改hadoop-env.sh文件
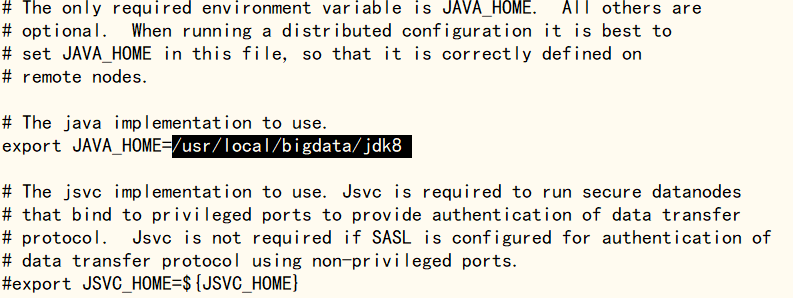
接下来使用‘vi hadoop-env.sh’命令编辑hadoop-env.sh文件,找到JAVA_HOME字段,添加jdk路径(可克隆新会话,输入‘echo $JAVA_HOME’命令查看),修改完成后使用‘:wq’命令保存退出
vi hadoop-env.shecho $JAVA_HOME![]()

修改core-site.xml文件
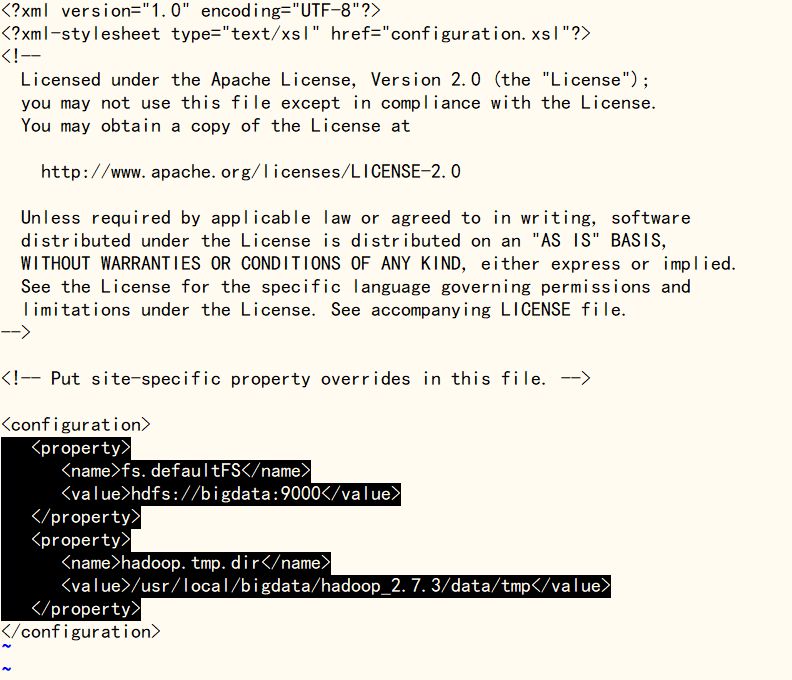
使用‘vi core-site.xml’命令修改core-site.xml文件,在文件末尾标签中加入下方块引用内容(bigdata为主机名,可设置主机名或IP名;9000为对外服务的通信端口,可自定义),完成后使用‘:wq’命令保存退出
vi core-site.xml
fs.defaultFS
hdfs://bigdata:9000
hadoop.tmp.dir
/usr/local/bigdata/hadoop_2.7.3/data/tmp
创建并修改mapred-site.xml文件
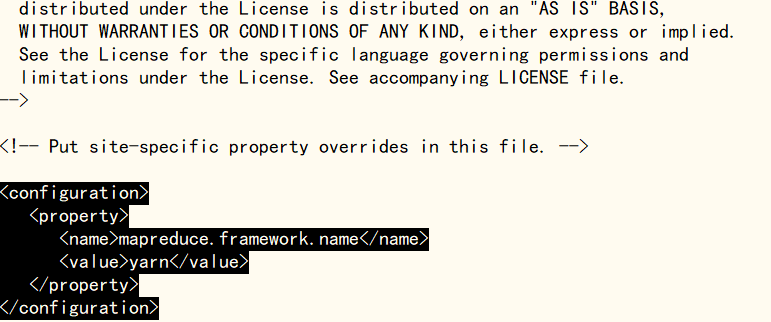
使用‘cp mapred-site.xml.template mapred-site.xml’命令创建mapred-site.xml文件,再使用‘vi mapred-site.xml’命令修改mapred-site.xml文件,在文件末尾标签中加入下方块引用内容(配置yarn表示集群模式,配置local为本地模式,建议配置为yarn),完成后使用‘:wq’命令保存退出
cp mapred-site.xml.template mapred-site.xmllsvi mapred-site.xml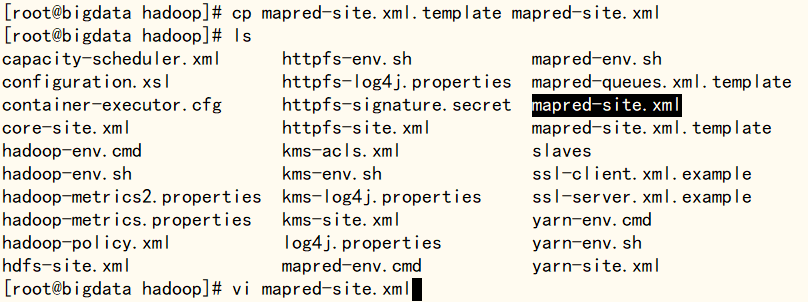
mapreduce.framework.name
yarn
修改yarn-site.xml文件
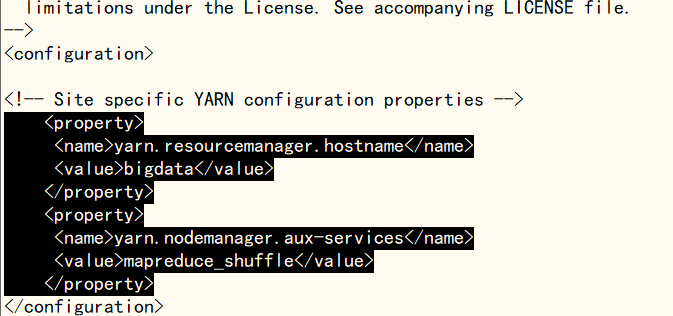
使用‘vi yarn-site.xml’命令修改yarn-site.xml文件,在文件末尾标签中加入下方块引用内容(bigdata为主机名,可设置主机名或IP名,推荐设置为主机名),完成后使用‘:wq’命令保存退出
vi yarn-site.xml
yarn.resourcemanager.hostname
bigdata
yarn.nodemanager.aux-services
mapreduce_shuffle
修改hdfs-site.xml文件
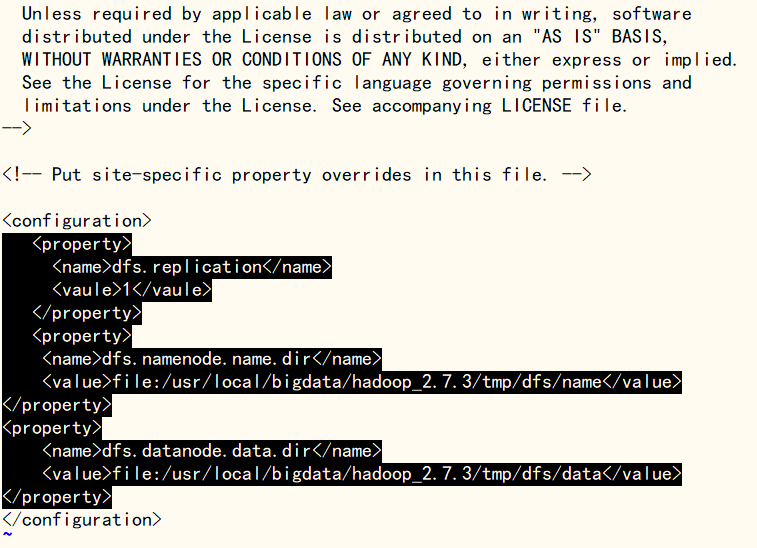
使用‘vi hdfs-site.xml’命令修改hdfs-site.xml文件,在文件末尾标签中加入下方块引用内容(注意路径名称),完成后使用‘:wq’命令保存退出
vi hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/bigdata/hadoop_2.7.3/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/bigdata/hadoop_2.7.3/tmp/dfs/data
修改slaves文件
使用‘vi slaves’命令修改slaves文件,将localhost改为bigdata(伪分布式可不配置,按需求自定),完成后使用‘:wq’命令保存退出
vi slaves
bigdata

hdfs格式化
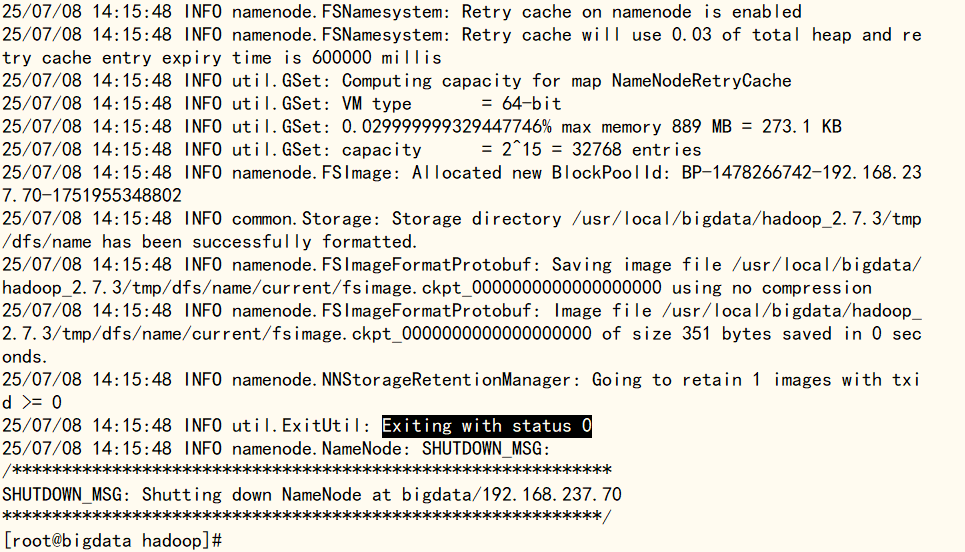
完成上述hadoop文件配置后,使用‘hdfs namenode -format’对hdfs进行格式化,内容出现Exiting with status 0,则表示格式化成功;如果失败需重新查看是否是Hadoop的配置文件出现问题,比如少了个字母、路径错误等
hdfs namenode -format
启动Hadoop
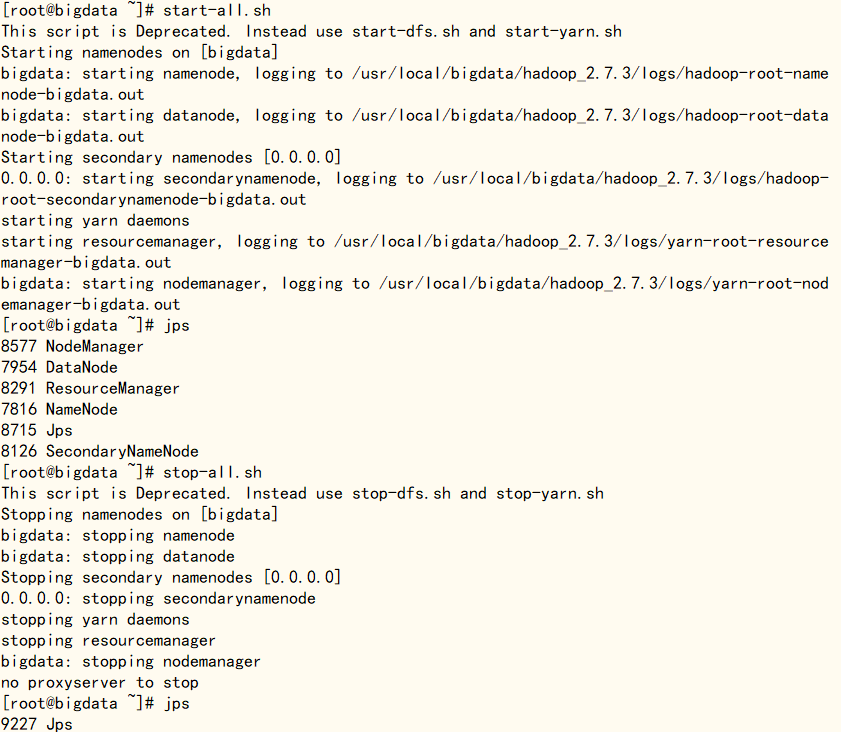
运行‘start-all.sh’ 命令启动Hadoop,过程中出现yes/no选项的统一为yes,同时还需要输入root用户密码,密码输入过程不会显示,直接输就行。完成后输入‘jps’查看进程,如果下图的所有进程都有,同时在浏览器输入地址‘http://IP:50070’出现了hadoop内容则表明Hadoop配置成功(需要提前关闭防火墙,临时关闭使用‘system stop firewalld’命令,永久关闭使用‘systemctl disable firewalld’命令)
start-all.shjpssystemctl stop firewalldsystemctl disable firewalldhttp://192.168.237.70:50070
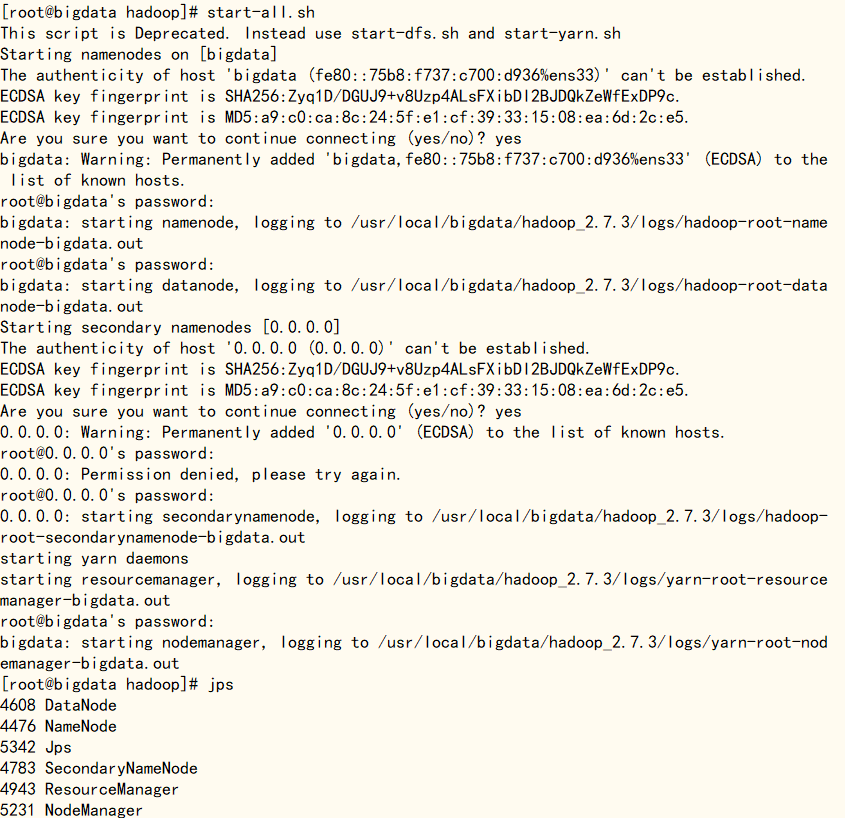

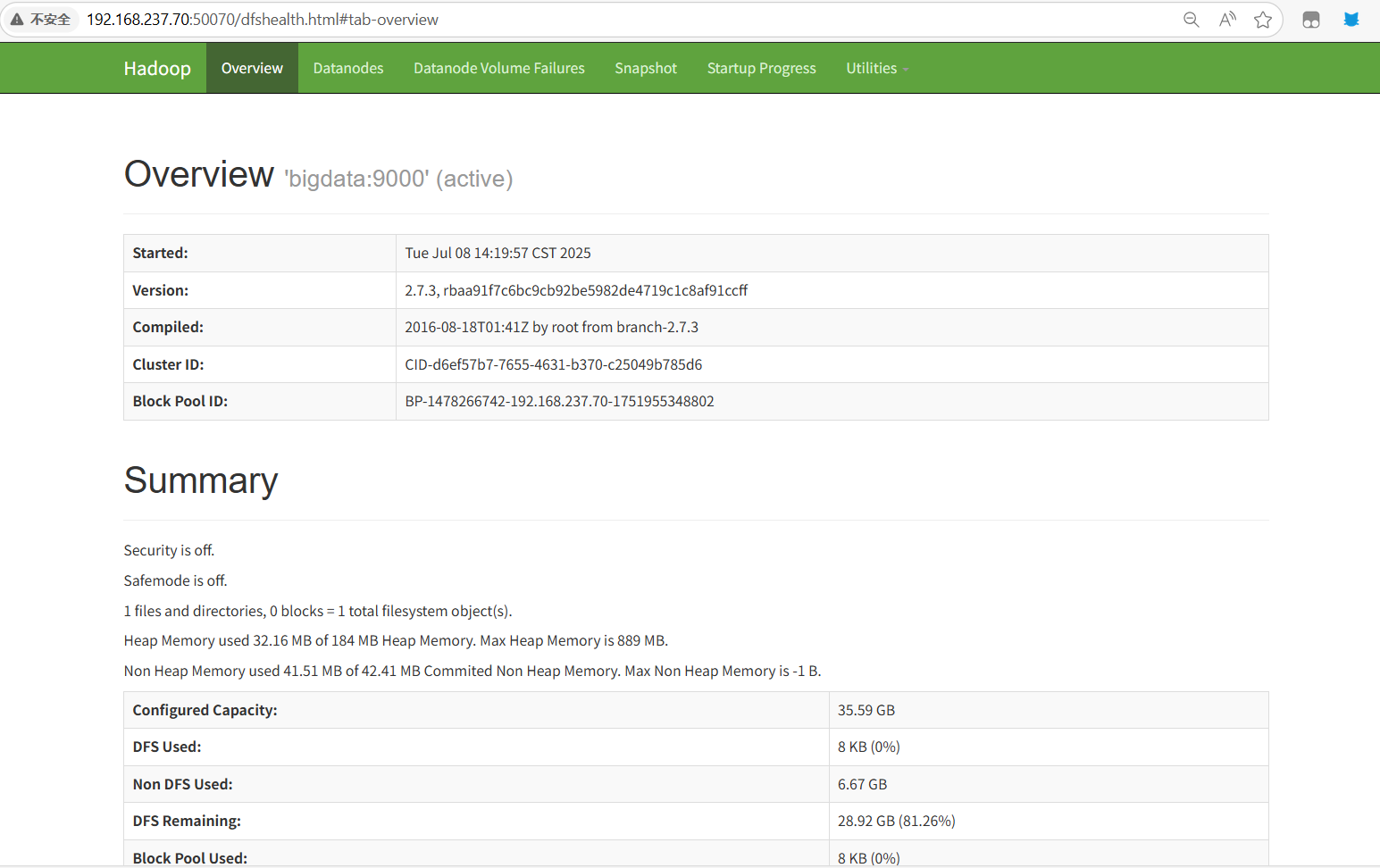
关闭Hadoop并设置免密
使用‘stop-all.sh’命令将hadoop进程关闭,过程中需要输入root用户密码, 执行‘ssh-keygen -t rsa’生成密钥对,有要输入的情况直接回车,使用‘ls ~/.ssh’查看生成的文件,再执行‘ssh-copy-id bigdata’命令把本地主机的公钥复制到bigdata上,需要输入一次root用户密码,最后输入‘ssh bigdata’命令验证是否成功
stop-all.sh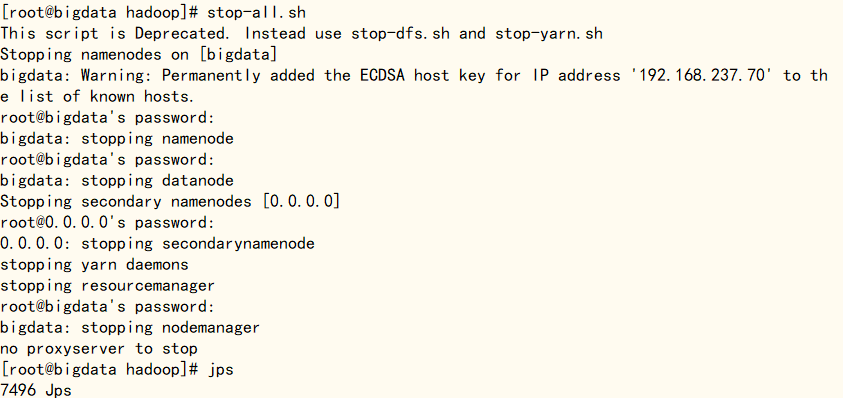
ssh-keygen -t rsals ~/.sshssh-copy-id bigdatassh bigdata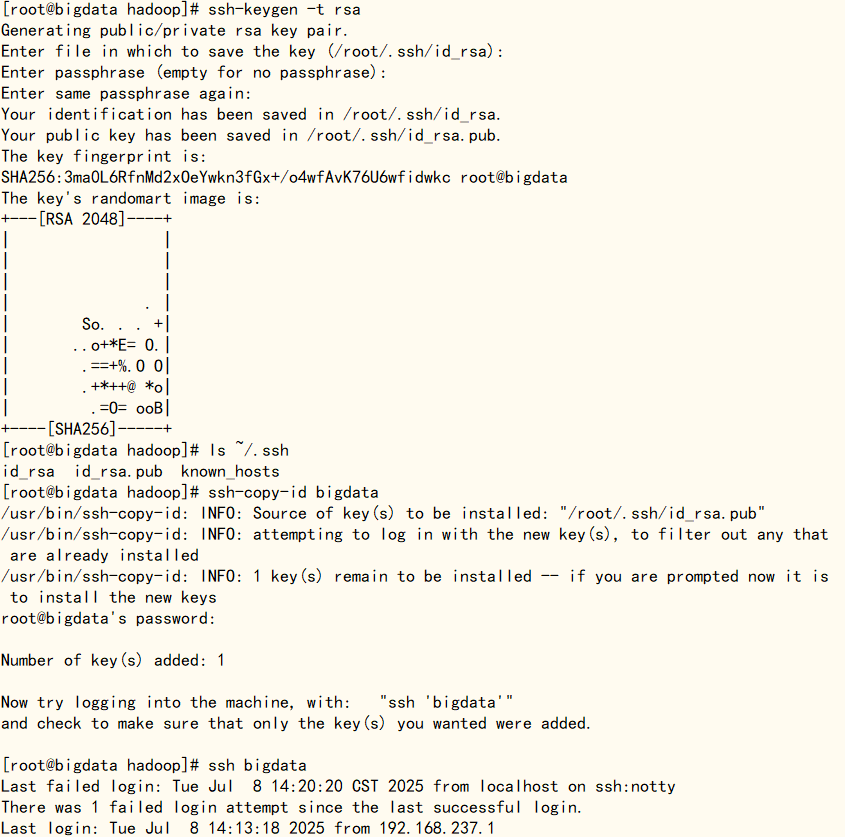
完成配置
完成密钥设置后再启动hadoop或关闭hadoop均不需要使用密码
最后,如果想搭建Hadoop完全分布式和集群部署,可参考:基于CentOS 7系统搭建Hadoop(完全分布式安装)

