语音转文字-免费的开源模型部署_python中语音转文本用什么模型
文章目录
- 一、介绍(whisper模型)
- 二、快速部署使用
- 三、whisper的使用
-
- 3.1 简单使用
- 3.2 效果调节
- 3.3 问题
-
- 3.3.1Numpy报错
一、介绍(whisper模型)
Whisper是由OpenAI研发的开源自动语音识别(ASR)系统,于2022年9月首次发布。目标是通过大规模数据训练实现高精度、多语言的语音转文本功能,同时支持翻译等扩展任务。基于Transformer的编码器-解码器架构,采用端到端训练方式。训练数据达68万小时,覆盖多语种、多场景语音(1/3为非英语数据),显著提升对口音、背景噪声的鲁棒性。(由于是在github上下载资源,需要使用代理,最好是有科学上网工具)
核心功能包括:
- 语音识别:支持99种音频转文本,自动检测输入语言。
- 翻译功能:将非英语语音实时翻译为英语文本(例如中文→英文)
- 字幕制作:语音活动检测(VAD),说话人分离
应用场景:
- 会议记录:自动转录多人讨论,生成结构化文本
- 教育直播:为在线课程生成实时字幕,辅助听障学生
- 字幕生成:为视频/播客添加精准时间轴字幕
- 媒体转播:赛事解说、新闻直播的实时字幕
- 听障辅助工具:将语音转换为文字,提升信息获取平等性
- 智能家居/车载系统:语音指令控制设备(如导航、空调调节)
- 司法取证:庭审录音转文本
- 客户服务:自动记录通话内容,优化服务分析
二、快速部署使用
2.1 Miniconda安装
Conda 是一个开源的软件包管理系统和环境管理系统,由 Anaconda 公司(原 Continuum Analytics)开发,旨在解决多语言项目中的依赖冲突和环境隔离问题。Anaconda 预装大量包,若磁盘空间有限建议选 Miniconda,我此处使用miniconda。
官网下载:https://docs.conda.io/en/latest/miniconda.html(需要科学上网和注册账号)
清华镜像下载:https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/(推荐)
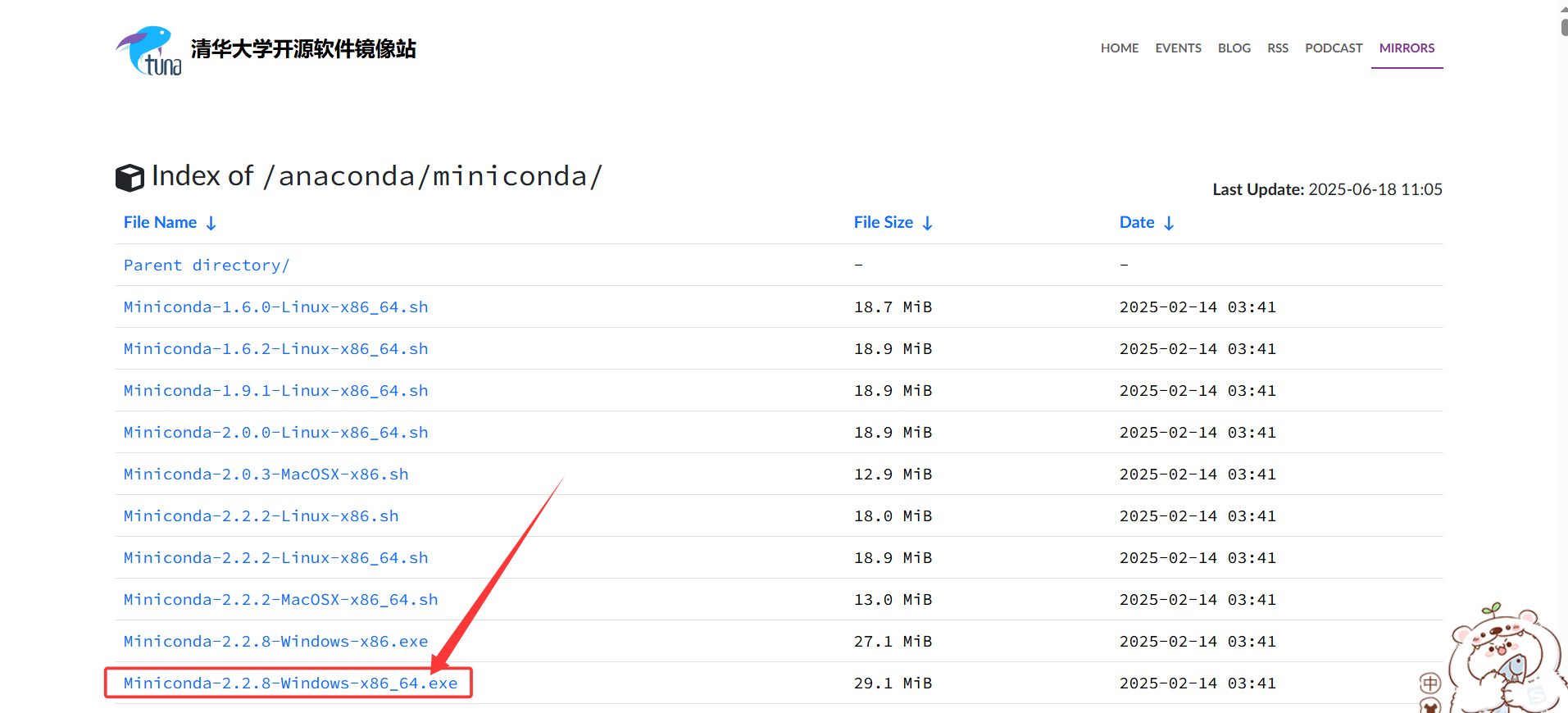
参考博客:
https://blog.csdn.net/qq_42951560/article/details/109035229?ops_request_misc=%257B%2522request%255Fid%2522%253A%25223fa1f1afc5484aaaba459093b256b9da%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=3fa1f1afc5484aaaba459093b256b9da&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-109035229-null-null.142v102pc_search_result_base2&utm_term=miniconda%E5%AE%89%E8%A3%85%E6%95%99%E7%A8%8B&spm=1018.2226.3001.4187
注意点:
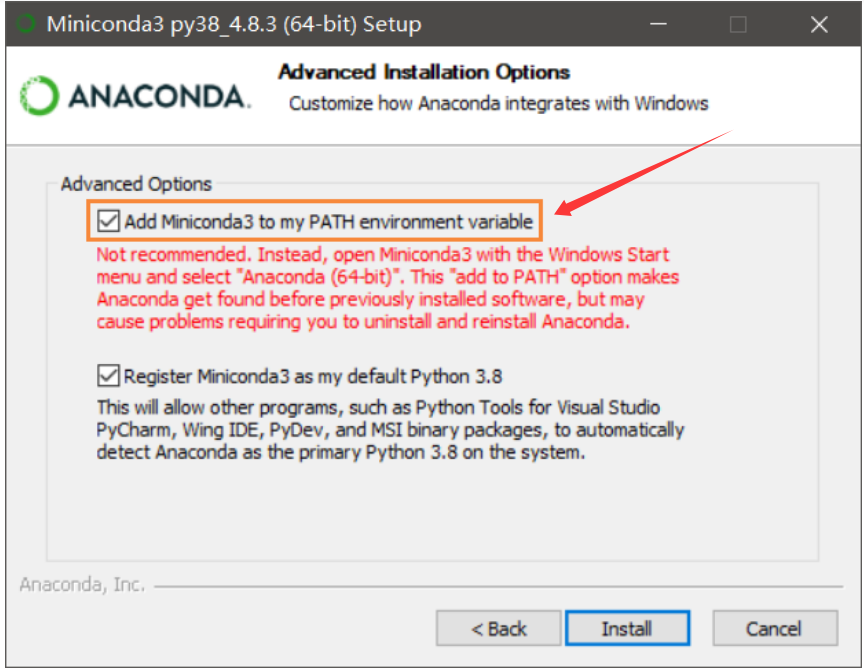
如果此处没有安装添加环境变量,则需要自己手动添加:
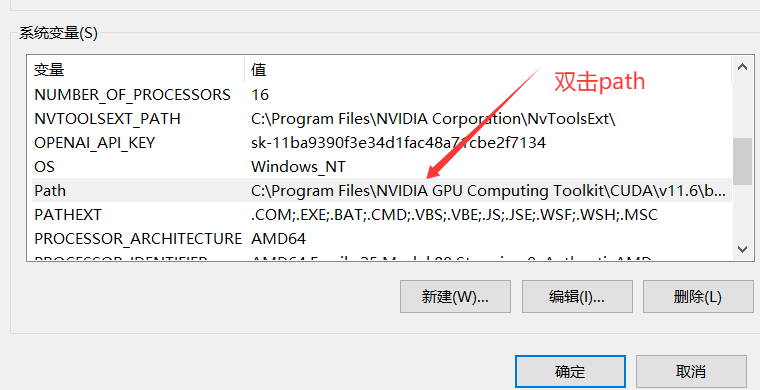
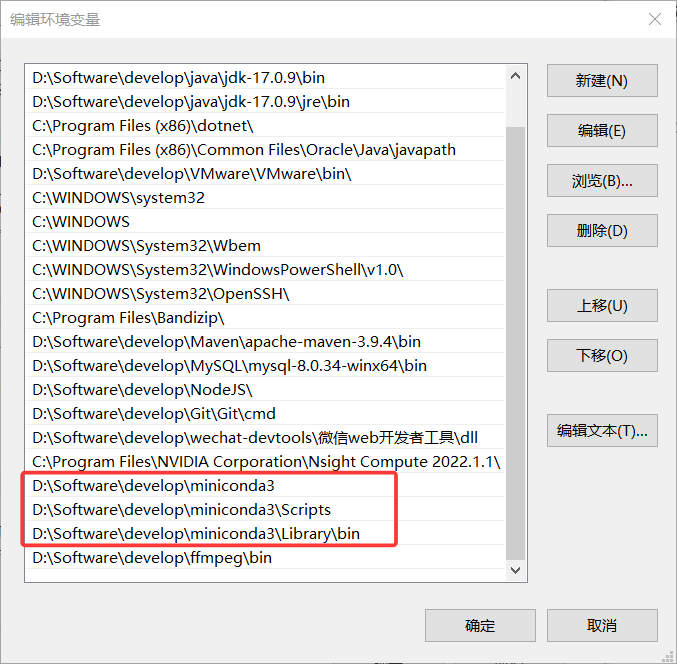
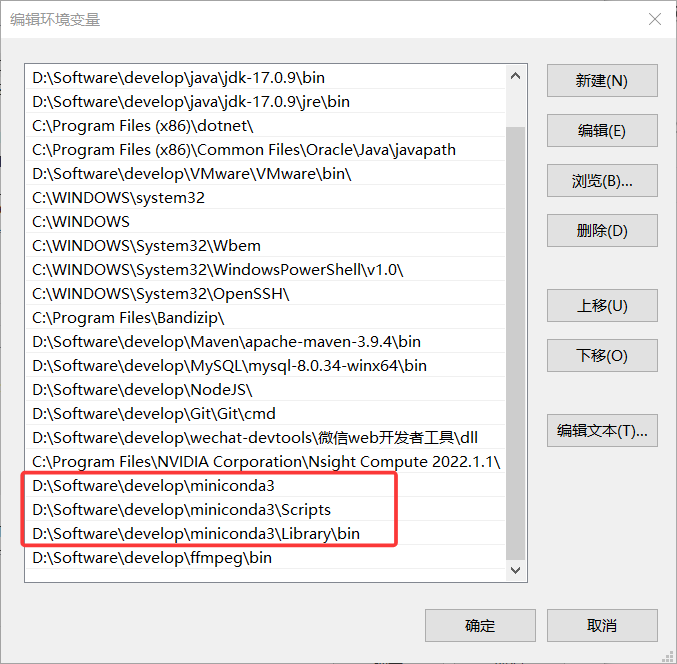
然后点击三个确定保存环境变量。其他类似。
2.2 FFmpeg
2.2.1 FFmpeg安装
FFmpeg 是一款开源的跨平台多媒体处理框架,被公认为音视频领域的“瑞士军刀”,提供从基础转码到复杂流媒体处理的完整解决方案。FFmpeg 是一套用于录制、转换、流化音视频的开源工具集,支持几乎所有主流编解码格式与容器封装(如 MP4、H.264、AAC 等)。
FFmpeg安装官网:https://ffmpeg.org/download.html
- Essentials:基础功能版(推荐)。
- Full:完整功能版(需更多存储空间)。
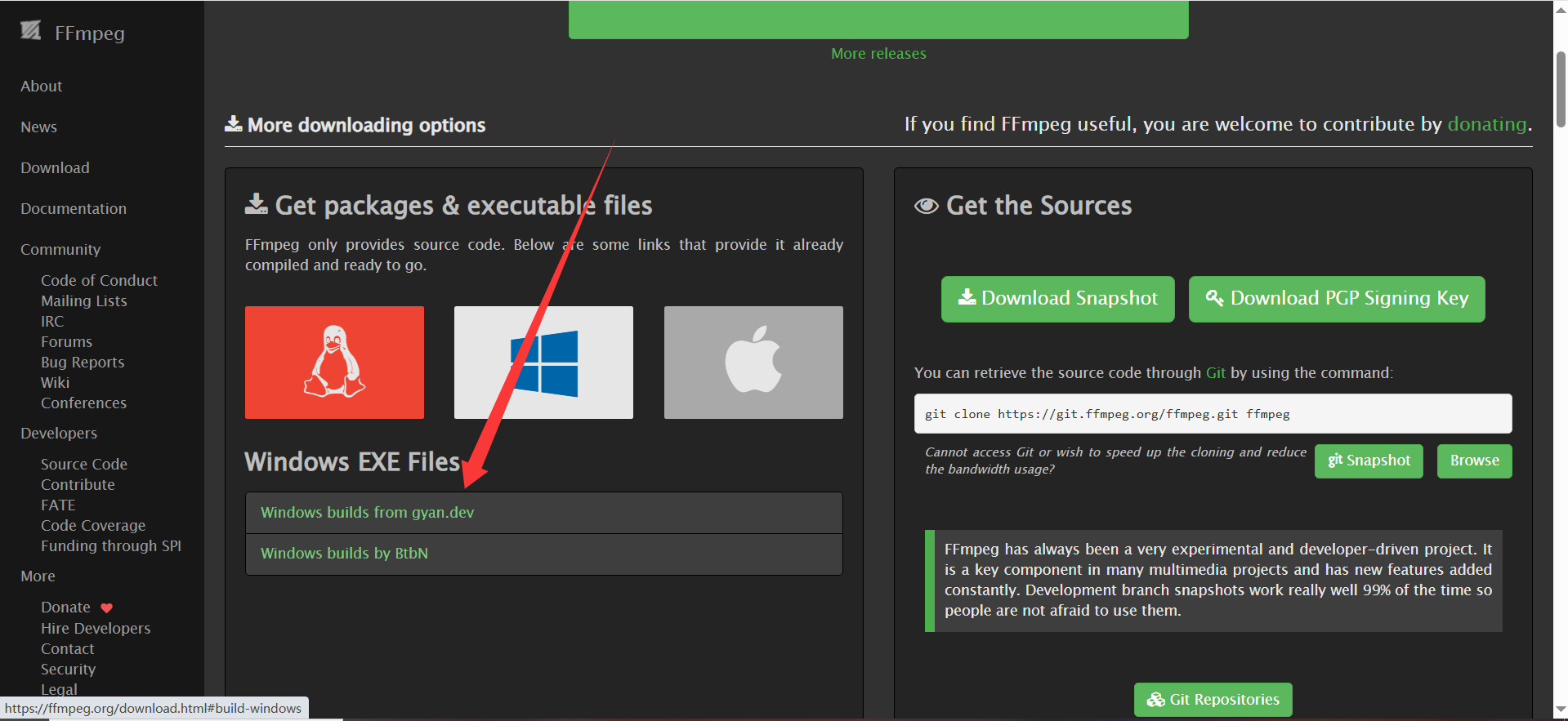
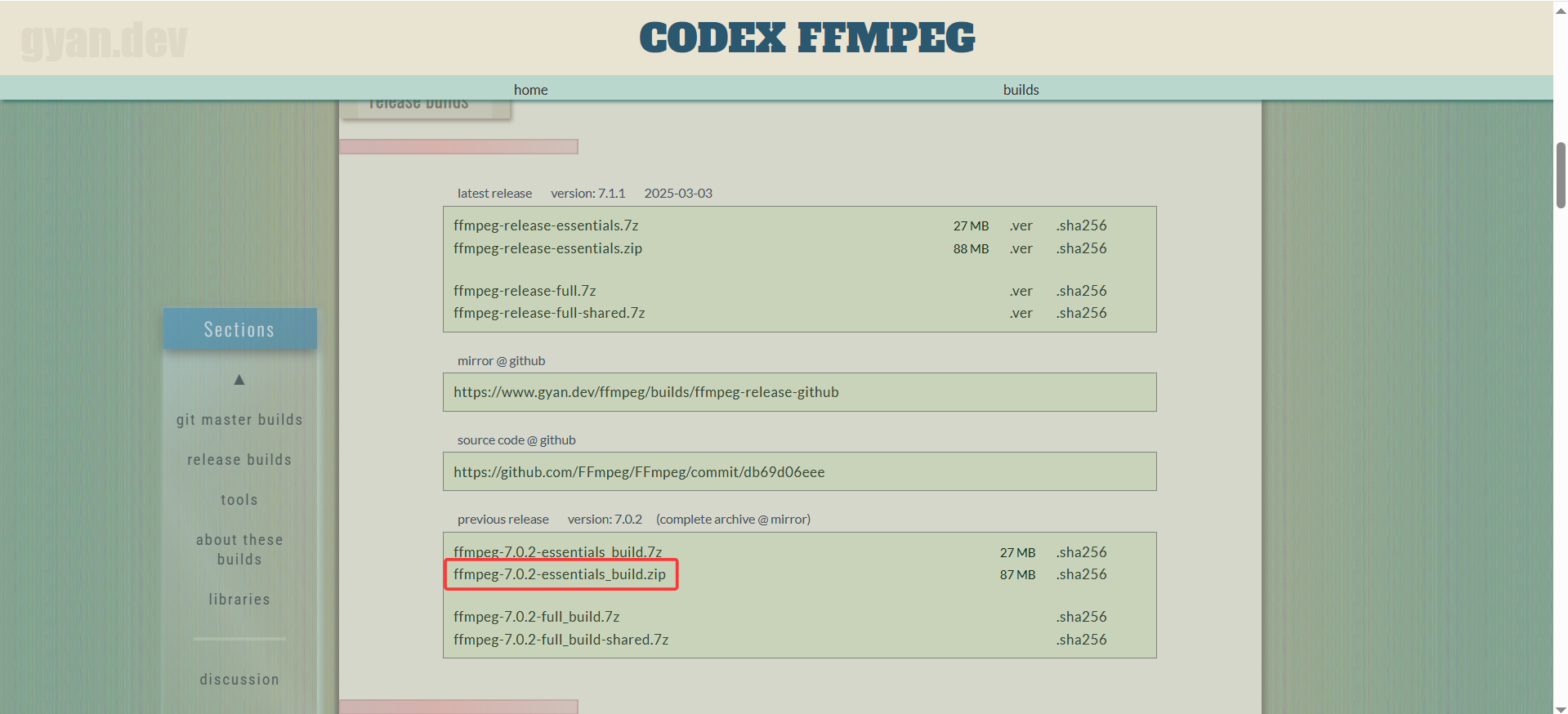
解压,然后配置环境变量:
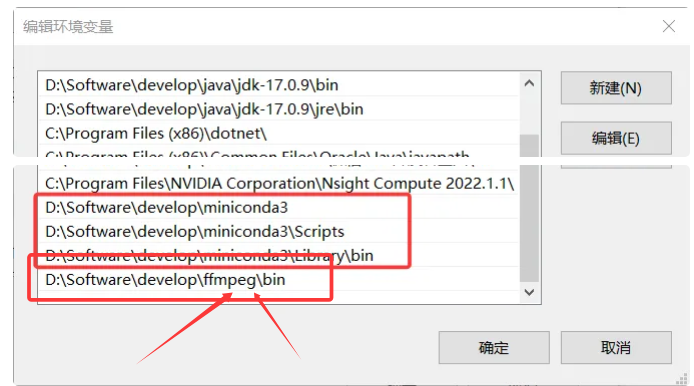
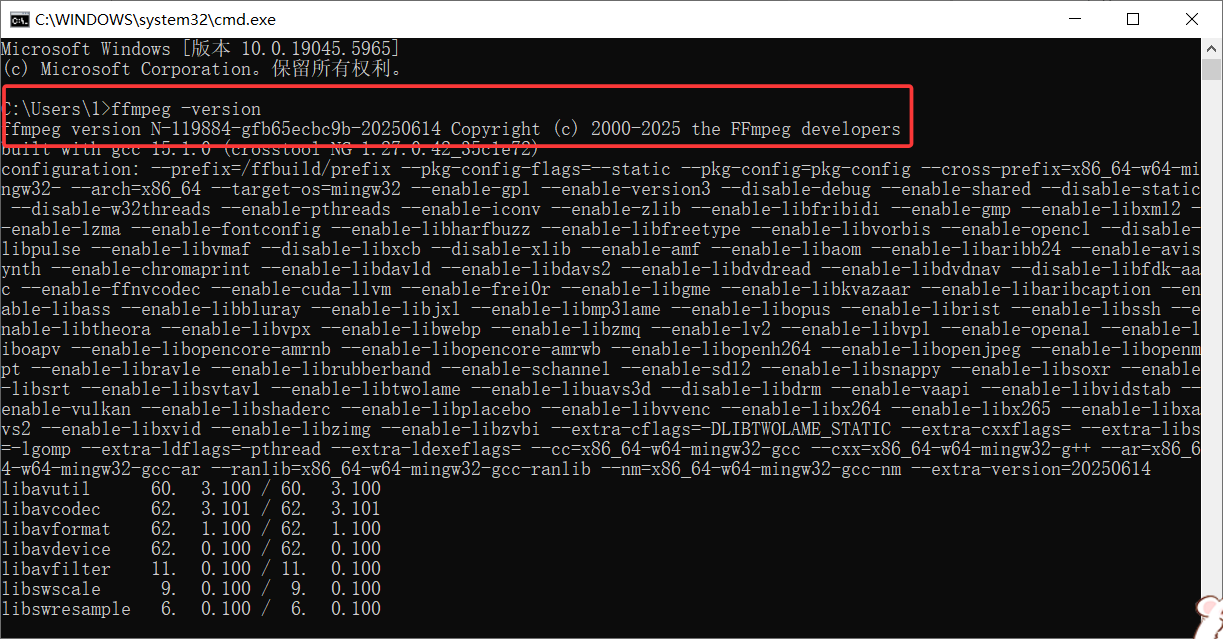
验证安装:
win+R->cmd->回车->输入ffmpeg -version
2.2.2 FFmpeg基础使用
视频转码(MP4 → MKV)
- ffmpeg -i input.mp4 -c:v libx264 -c:a aac output.mkv
- -c:v:视频编码器(如 libx265 为 H.265)。
- -c:a:音频编码器(如 mp3)。
调整分辨率(1080p → 480p)
- ffmpeg -i input.mp4 -vf scale=854:480 output.mp4
提取音频
- ffmpeg -i input.mp4 -vn -c:a copy output.aac
- -vn:忽略视频流。
剪切视频片段(截取 00:01:00 到 00:02:30)
- ffmpeg -i input.mp4 -ss 00:01:00 -to 00:02:30 -c:v copy -c:a copy output.mp4
2.3 运行环境安装
以下安装均在miniconda上进行安装,也就是conda的虚拟环境中进行安装。当然本地也可以安装,本地可能造成的环境冲突,因为每个人电脑的配置和环境不同,演示的话很难迅速和顺利部署,如果需要本地部署需要大家自己细心去解决。(注意:在安装以下环境的时候必须保证科学上网!!!)
2.3.1 前置准备
2.3.1.2 科学上网
1.打开科学上网
2.打开anaconda Prommpt


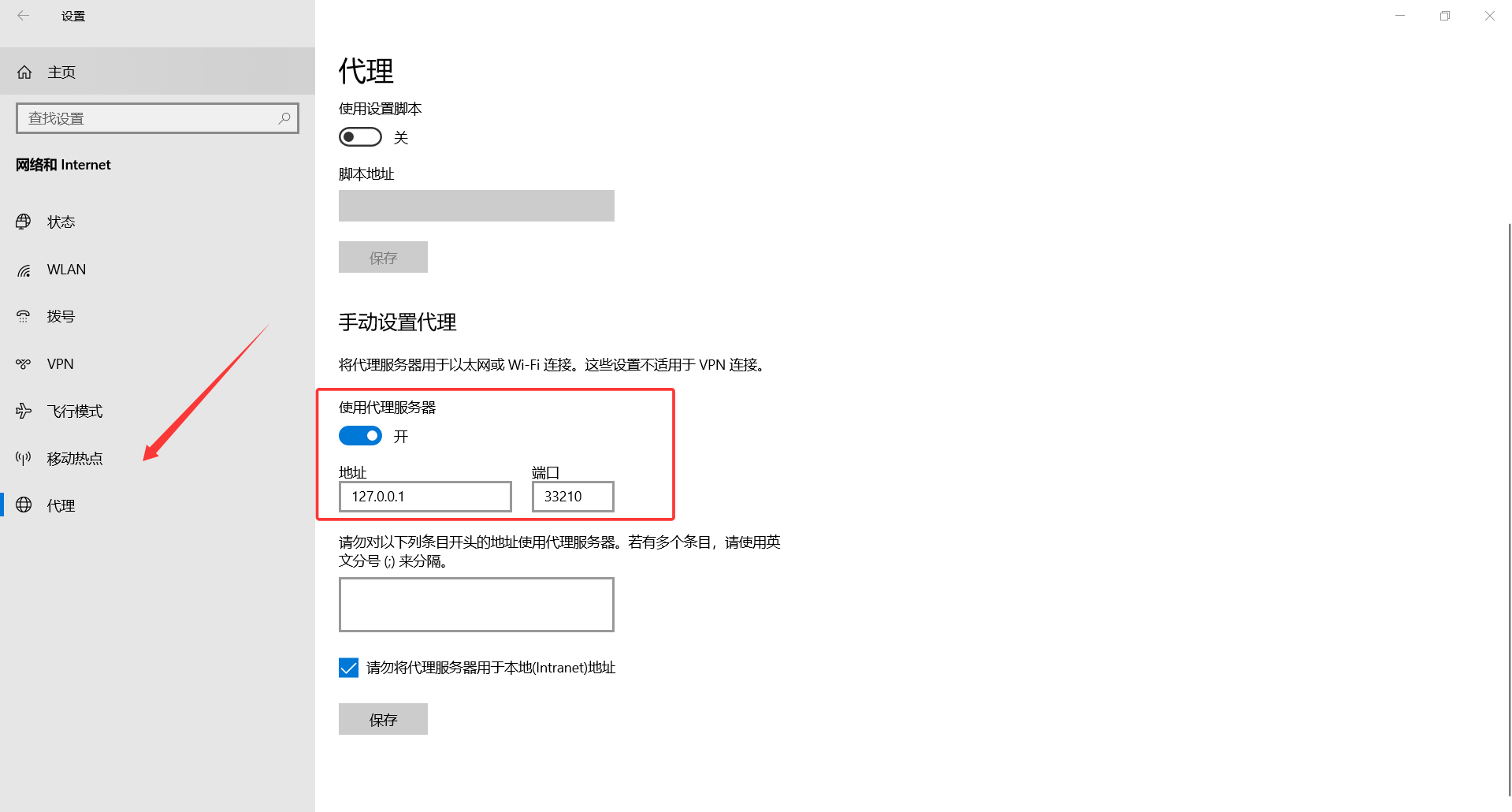
3.配置代理
打开设置->选择网络和Intenet->选择代理(打开科学上网后会自动开启,你只需要记住这个代理地址)
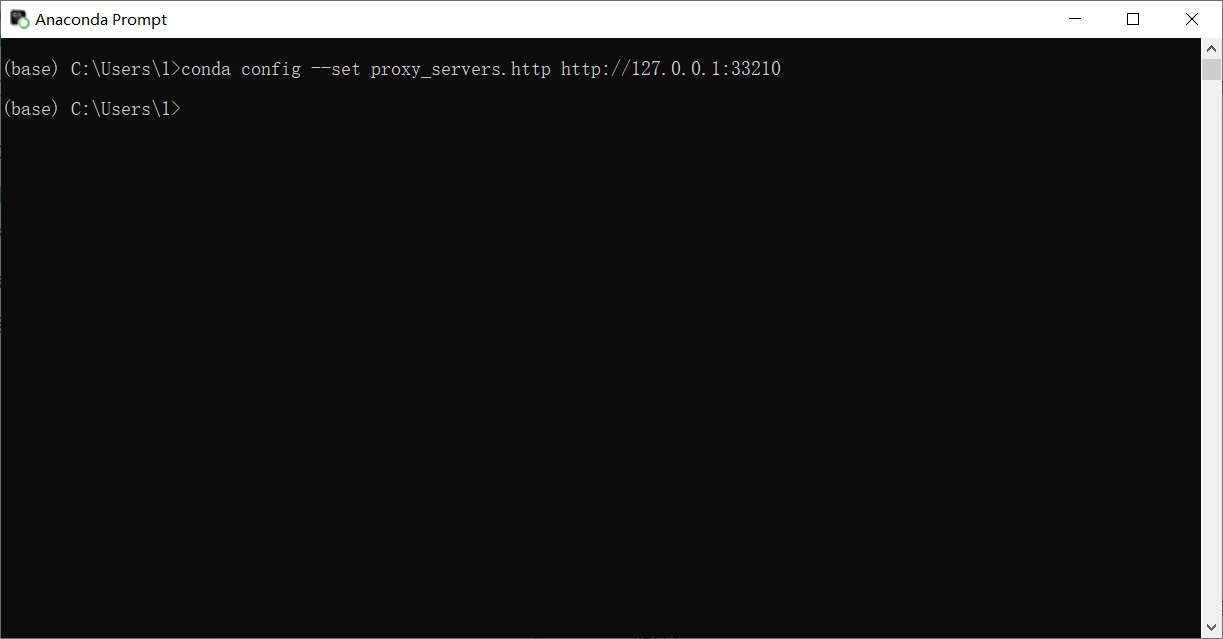
conda config --set proxy_servers.http http://127.0.0.1:7890(换成刚刚查看的代理地址)
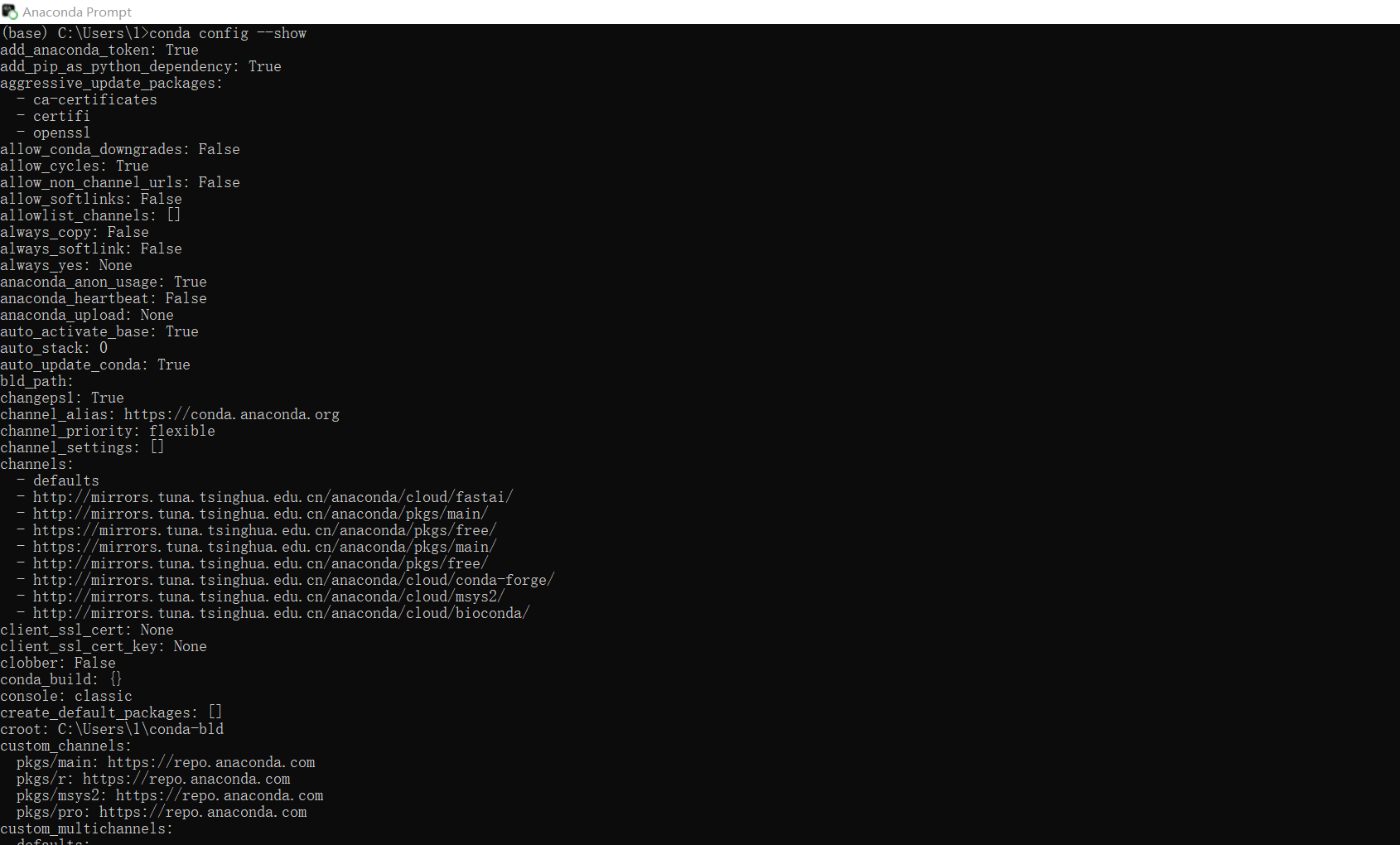
4.查看代理地址是否配置成功
conda config --show proxy_servers

conda config --show(查看所有配置)
5.查看虚拟环境
conda env list 或 conda info --envs
6.创建虚拟环境whisper(执行以下命令即可)
conda create --name whisper python=3.9
7.切换whisper环境
如果激活报错,我们先进行初始化,运行 conda init cmd.exe 命令。
接下来就是开始安装python(已安装)/pytorch/whisper
2.3.1.2 无科学上网
1.配置镜像源(在anaconda Prompt中执行如下命令)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
设置搜索时显示通道地址
conda config --set show_channel_urls yes
2.接着2.3.1.1第5步开始
2.3.2 安装python
Python 是一种高级、解释型、通用的编程语言,由荷兰程序员 Guido van Rossum 在 1991 年首次发布。它以简洁易读的语法和强大的功能生态著称,已成为全球最流行的编程语言之一。
在创建虚拟环境的时候已经安装!
2.3.3 安装pytorch
PyTorch是Facebook开发的深度学习框架,基于Python语言,具有动态计算图、自动求导等特性。它支持GPU加速计算,广泛用于图像识别、自然语言处理等地方。PyTorch的前身是Torch框架,但使用Python重新编写了很多内容,它于2016年发布,2017年1月正式推出。PyTorch的核心优势在于其动态计算图机制,这使得它比TensorFlow等使用静态图的框架更灵活。
pytorch有两种版本,独立显卡使用GPU版本,集成显卡使用CPU版本。
CPU版本的安装(如下):
- pip install torch torchvision torchaudio(使用pip list可以查看是否安装成功)
GPU版本的安装:(稍微有点麻烦,但是速度比纯CPU快得多)
1.在cmd命令行终端输nvidia-smi查看版本信息
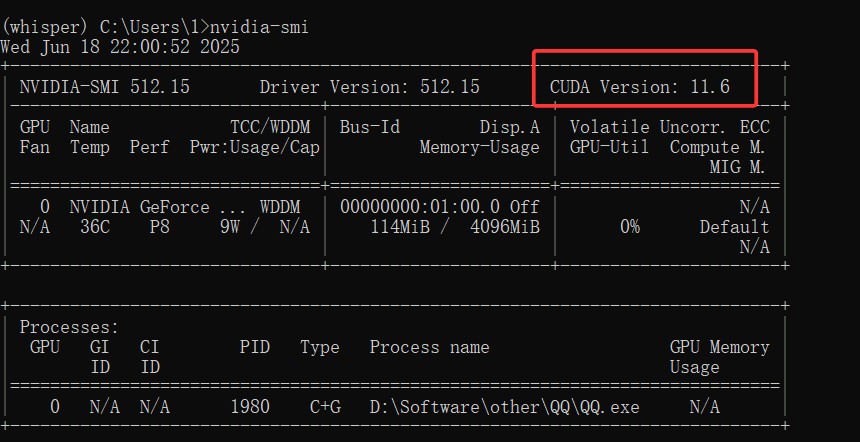
2.安装CUDA和CuDNN(正常安装软件,没啥好说的)
参考博客:https://blog.csdn.net/weixin_44779079/article/details/141528972
3.安装对应cuda的的pytorch
https://pytorch.org/get-started/locally/(cuda安装小于等于自己系统的版本即可)
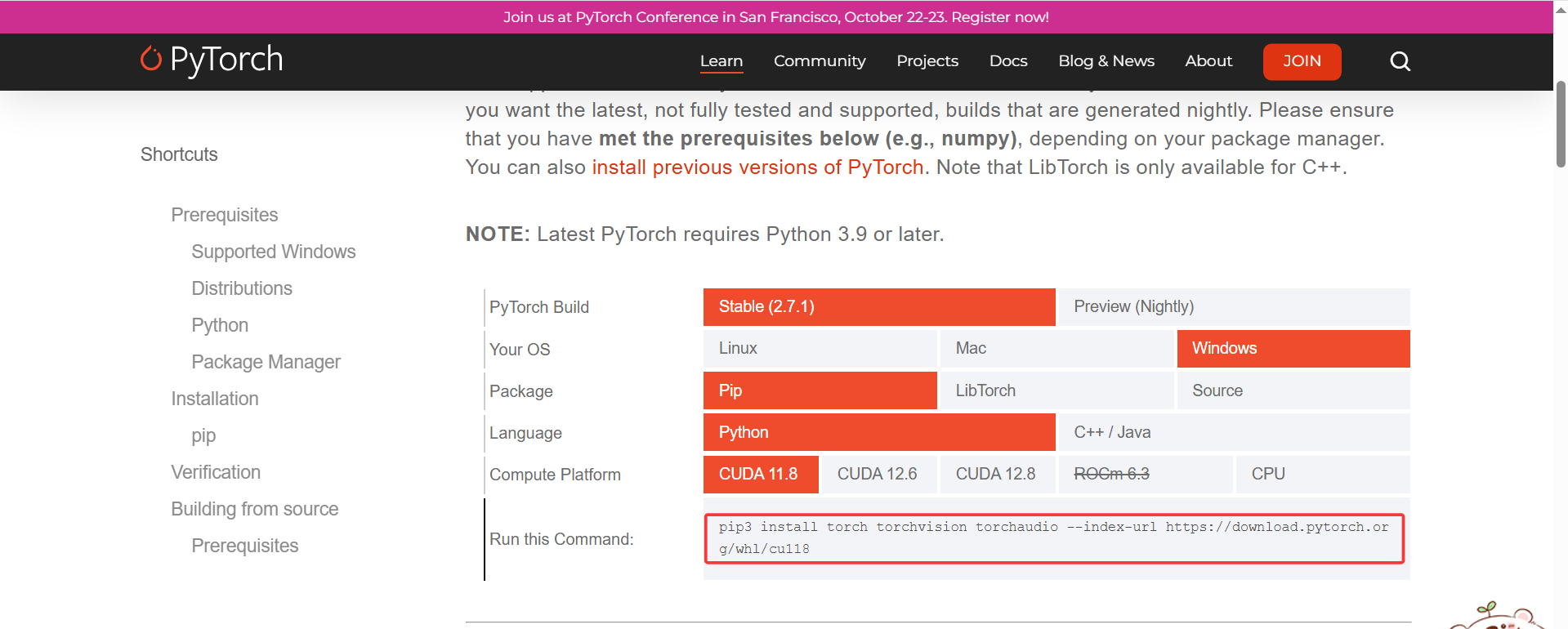
由于我这里是11.6,所以只能安装以前的版本。
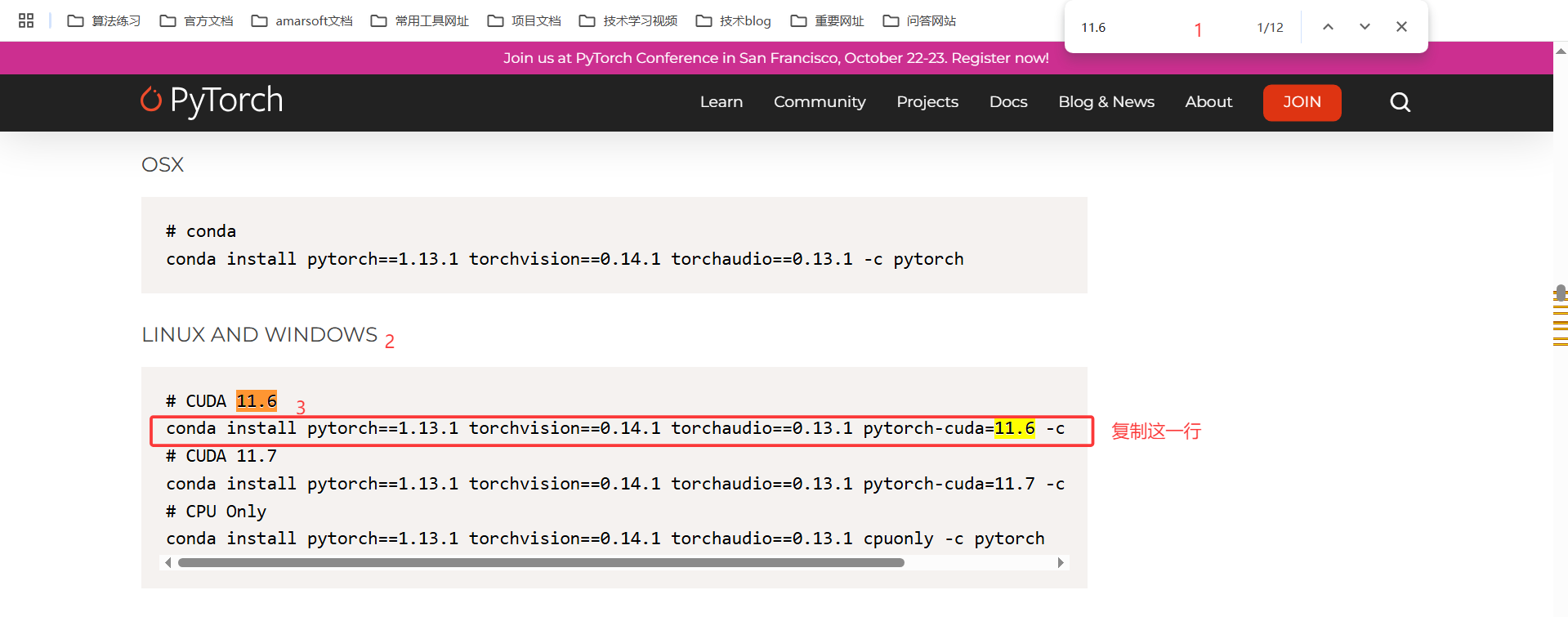
在conda的虚拟环境中执行:(我的是11.6,读者根据自己的电脑实际安装)
conda install pytorch1.13.1 torchvision0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia

验证安装:
python -c \"import torch; print(f\'PyTorch版本: {torch.__version__}\')\"python -c \"import torch; print(f\'CUDA可用: {torch.cuda.is_available()}\')\"python -c \"import torch; print(f\'可用设备数: {torch.cuda.device_count()}\')\"
2.3.4 安装whisper
whipser官方:https://github.com/openai/whisper
虚拟环境中执行如下两条命令即可:
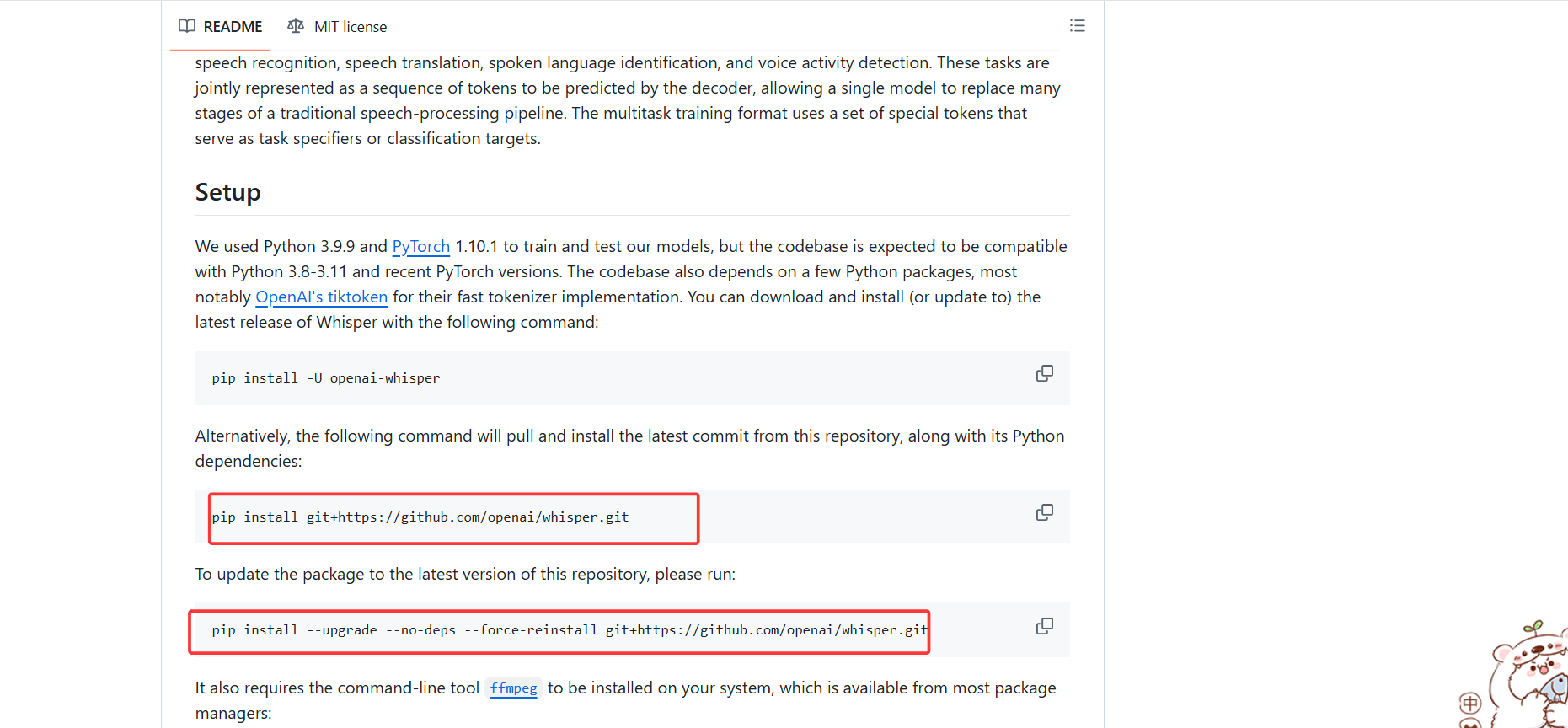
pip install git+https://github.com/openai/whisper.gitpip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git如果有其他包需要安装,请查阅官网,个人的环境这些包已经可以正常使用了。
验证:

2.3.5 相关问题
2.3.5.1 为什么安装pytorch-GPU前一定要安装CUDA和CuDNN呢?
- CUDA是NVIDIA推出的并行计算平台和API模型,它使得显卡可以用于图像渲染和计算以外的目的,例如通用并行计算。PyTorch通过CUDA可以充分利用GPU的计算能力,加速深度神经网络的学习和推理过程。
- cuDNN是CUDA的扩展库,专门针对深度神经网络中的基础操作提供高度优化的实现方式,例如卷积、池化、规范化以及激活层的前向和后向过程。使用cuDNN可以大大提高深度学习模型在GPU上的运行效率。
- 因此,在安装PyTorch-GPU之前,需要先安装CUDA和cuDNN,以便能够充分利用GPU的计算能力,加速深度神经网络的学习和推理过程。如果不安装CUDA和cuDNN,PyTorch-GPU将无法正常工作。
2.3.5.2 为什么要安装python3.9,其他版本不行吗?
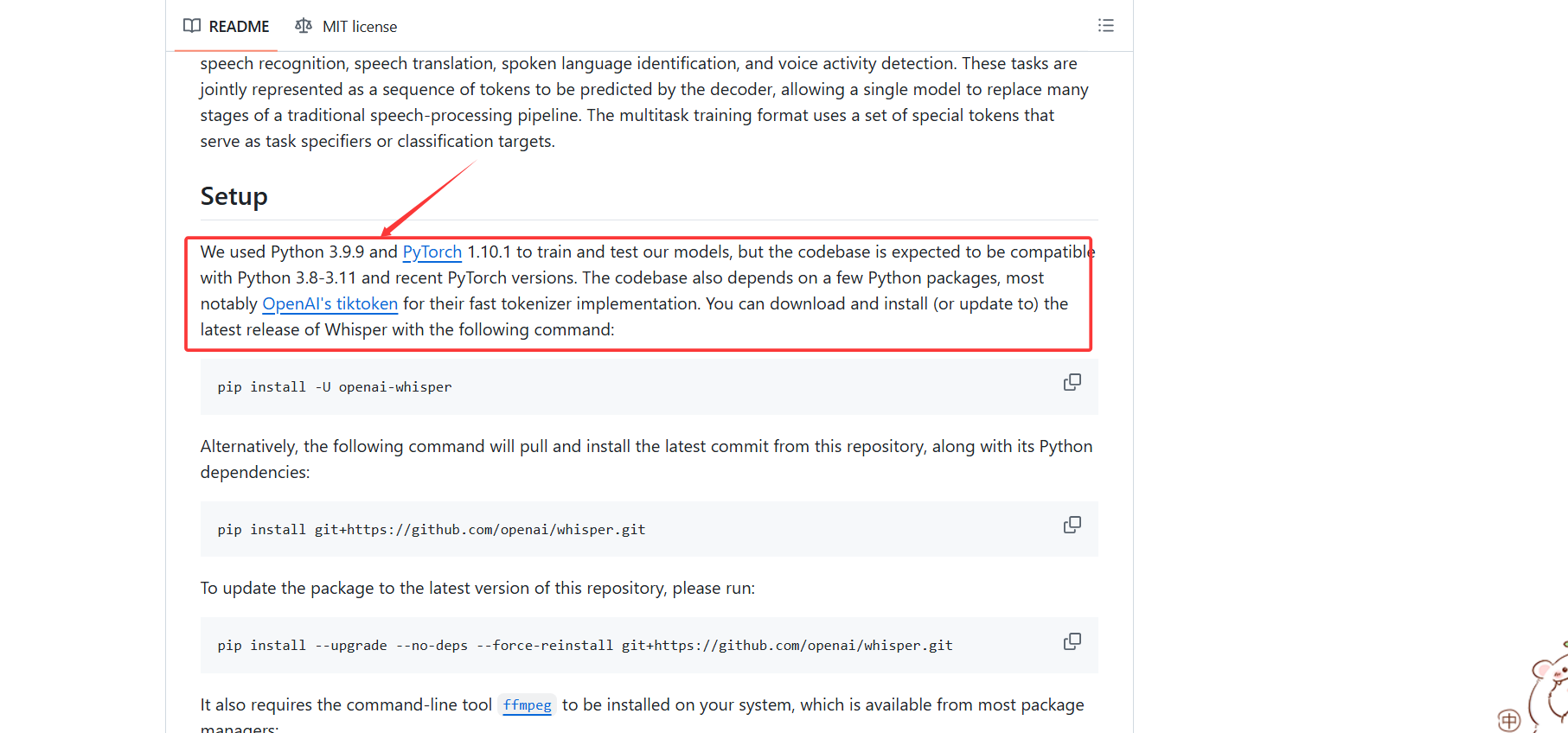
因为whisper官方说明,他们使用的是python3.9进行训练和测试的,保持一致为最佳。
2.3.5.3 安装whisper网络错误

这是网络问题,github有时候进不去,可以直接安装官方的PyPI:
pip install openai-whisper三、whisper的使用
3.1 简单使用
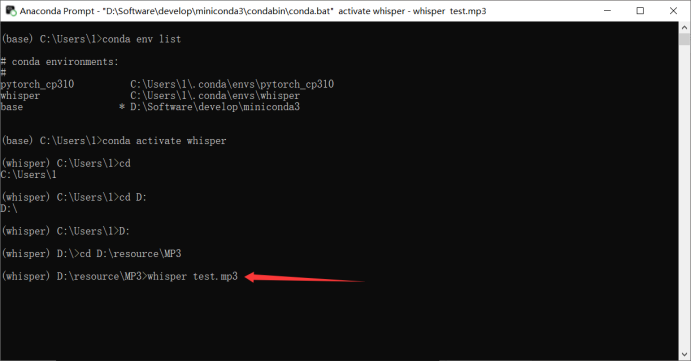
好了,到了最终环节。使用whisper录音转文字。
- 打开Anaconda Prompt
- 查看虚拟环境
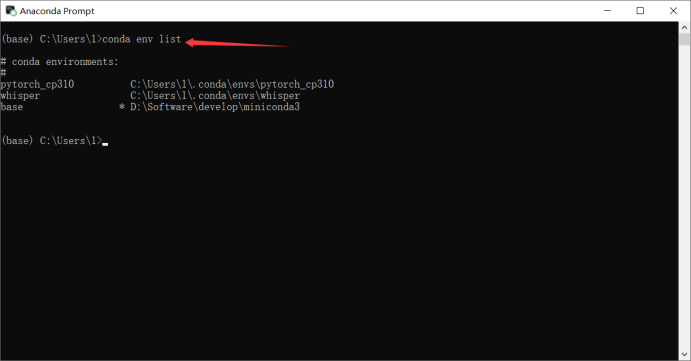
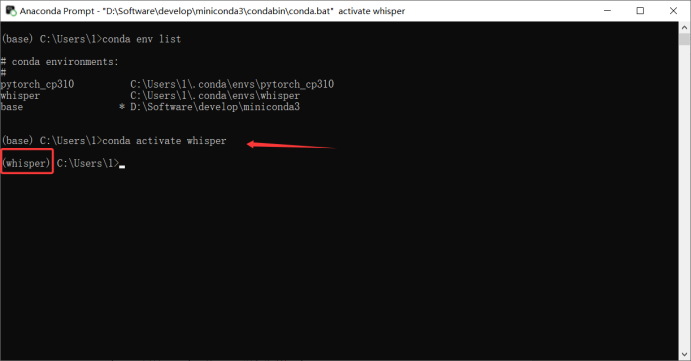
- 由于whisper是部署在whisper容器上,所以切换为whisper
- 打开需要转换的文件位置
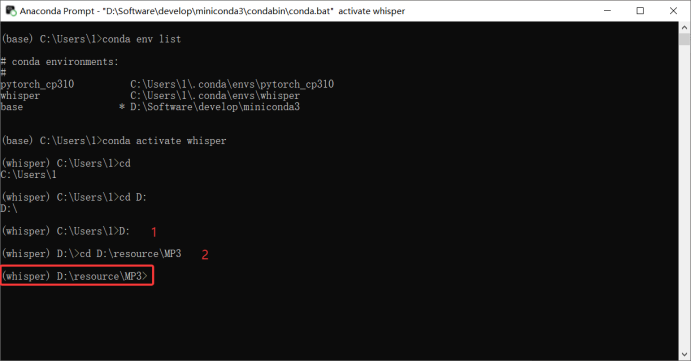
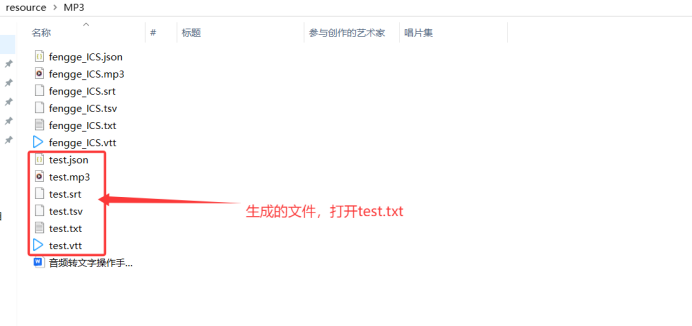
- 使用whisper模型语音转文字(whisper会将生成的文件自动保存到.mp3统计目录)
3.2 效果调节
主要是针对安装了pytorch的GPU版本的加速,当然CPU版本也可以指定参数后更精准
1.先安装python库opencc
在使用Whisper进行推理时,发现对于中文音频返回的结果部分是繁体字,查找了whisper选取的language选项,其中只有chinese选项,并不区分简体和繁体字的区别,所以在返回的结果进行简体字转换。
pip install opencc2.使用python脚本进行转换准备
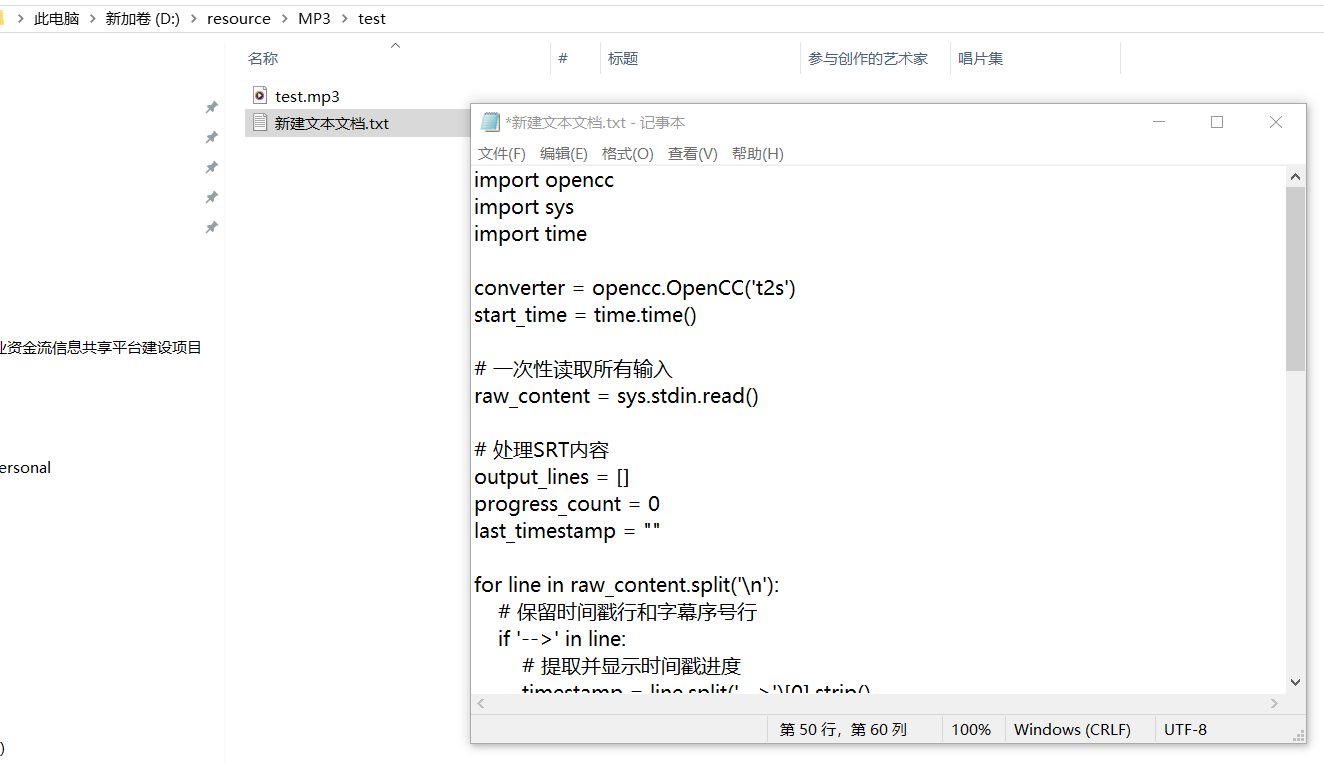
建议创建一个Python脚本 chinese_convert_simplify.py:(想要什么效果让AI给你改)
import openccimport sysimport timeimport datetimeimport reconverter = opencc.OpenCC(\'t2s\')start_time = time.time()last_reported = NoneMIN_INTERVAL = 5.0 # 最小报告间隔(秒)def format_seconds(seconds): \"\"\"将秒数转换为 HH:MM:SS 格式\"\"\" return str(datetime.timedelta(seconds=seconds))# 一次性读取所有输入内容raw_content = sys.stdin.read()print(f\"已接收 {len(raw_content)} 字符输入,开始转换...\", file=sys.stderr)# 处理进度状态last_timestamp = \"\"time_points = []output_lines = []for line in raw_content.split(\'\\n\'): # 检测时间戳行并收集时间点 if \'-->\' in line: try: # 提取开始时间 (00:30:10,500) start_str = line.split(\'-->\')[0].strip() # 转换成秒数 time_part = start_str.split(\',\')[0] # 00:30:10 h, m, s = time_part.split(\':\') current_seconds = int(h)*3600 + int(m)*60 + int(s) time_points.append(current_seconds) last_timestamp = start_str except: # 时间戳解析错误时的备用方案 last_timestamp = line.split(\'-->\')[0].strip() # 处理时间戳行 if \'-->\' in line: # 每隔一段时间显示一次进度 current_time = time.time() if last_reported is None or (current_time - last_reported) > MIN_INTERVAL: last_reported = current_time elapsed = current_time - start_time # 计算剩余时间估算 if len(time_points) > 2: # 基于已处理内容比例估算 processed_ratio = min(1.0, max(0.0, time_points[-1] / max(1, sum(time_points)/len(time_points)*2))) estimated_total = elapsed / processed_ratio remaining = estimated_total - elapsed est_str = f\",预计剩余 {format_seconds(remaining)}\" else: est_str = \"\" print( f\"处理进度: {len(time_points)} 段 | 时间点: {last_timestamp} | \" f\"已用时: {format_seconds(elapsed)}{est_str}\", file=sys.stderr ) # 转换内容 if \'-->\' in line: output_lines.append(line) elif line.strip().isdigit(): output_lines.append(line) elif line.strip(): output_lines.append(converter.convert(line)) else: output_lines.append(line)simplified_content = \'\\n\'.join(output_lines)# 保存简体文件with open(\"output_simplified.srt\", \"w\", encoding=\"utf-8\") as f: f.write(simplified_content)# 输出简体结果到终端print(simplified_content)# 性能统计end_time = time.time()total_time = end_time - start_timechar_count = len(raw_content)rate = char_count / total_time if total_time > 0 else 0print(f\"\\n转换完成! 共处理 {len(time_points)} 段时间点\", file=sys.stderr)print(f\"最长段持续时间: {max(time_points) if time_points else 0}秒\", file=sys.stderr)print(f\"平均段持续时间: {sum(time_points)/len(time_points) if time_points else 0:.1f}秒\", file=sys.stderr)print(f\"处理速度: {rate:,.0f} 字符/秒\", file=sys.stderr)print(f\"总耗时: {total_time:.1f}秒\", file=sys.stderr)保存:
修改文件后缀:
3.运行 Whisper 并管道转换:
whisper test.mp3 --language Chinese --model small --device cuda:0 --initial_prompt \"以下 是普通话的句子\" --output_format txt --output_dir . | python chinese_convert_simplify.py常用参数说明:
whispertest.mp3--language Chinese--model small是平衡精度与速度的模型(需约 5GB GPU 显存)
--device cuda:0表示第一个显卡)而非 CPU(计算速度提升 5-10倍)
--initial_prompt \"以下是普通话的句子\"模型内存需求参考:
3.3 问题
3.3.1Numpy报错
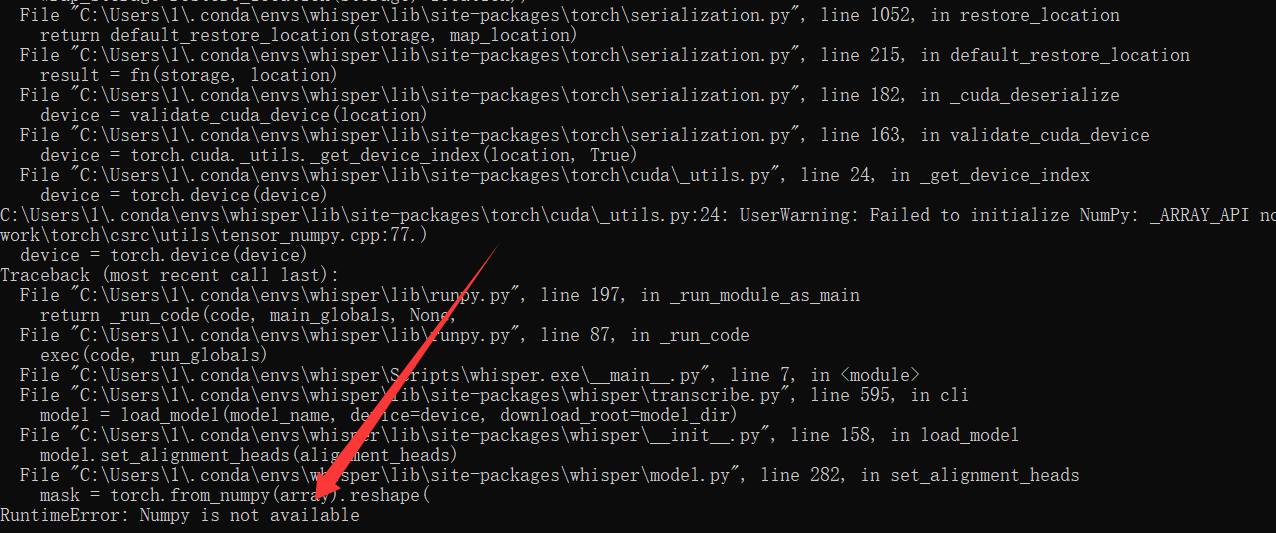
通常是由于NumPy安装损坏或与当前Python环境不兼容导致的。
# 先卸载现有 NumPypip uninstall -y numpy# 清理缓存并重新安装pip install --no-cache-dir --force-reinstall numpy==1.24.3 # 使用兼容性好的版本
