区块链数据分析流程:从抽取到洞察
作为一名数据仓库工程师,结合区块链和以太坊数据分析的背景,我将详细讲解区块链数据分析的完整流程,涵盖数据抽取、数据加工和数据分析三个阶段。
区块链数据分析流程:从抽取到洞察
区块链数据分析是将链上数据转化为洞察的过程,主要包括数据抽取、加工和分析三个阶段。以太坊数据(如交易、合约、日志)通过运行节点或API抽取原始数据;加工阶段对数据进行清洗、解码和建模,存储到数据仓库;分析阶段利用SQL、机器学习等技术挖掘交易模式、Gas趋势或DeFi行为。挑战包括数据量大、格式复杂和实时性要求高,需借助工具如The Graph、Dune Analytics和BigQuery。区块链数据分析为Web3生态提供用户行为洞察、协议优化和风险监测,驱动去中心化应用的创新。
关键词:区块链、数据分析、以太坊、数据仓库、Web3
正文
一、区块链数据分析概述
区块链数据分析是指从区块链(如以太坊)中提取、处理和分析链上数据,以揭示交易模式、用户行为或协议性能等洞察。以太坊作为一个去中心化平台,生成大量公开数据,包括交易、区块、智能合约事件、账户余额等。这些数据为DeFi、NFT、治理等Web3应用提供了丰富的分析素材,但其分散性、复杂性和规模化挑战要求系统化的分析流程。
区块链数据分析的典型流程分为三个阶段:
- 数据抽取:从区块链节点或第三方服务获取原始数据。
- 数据加工:清洗、转换和建模数据,存储到可查询的数据库。
- 数据分析:通过查询、统计或机器学习挖掘洞察。
以下逐一详细讲解每个阶段。
二、数据抽取
1. 什么是数据抽取?
数据抽取是从区块链网络中获取原始数据的过程。以太坊数据主要包括:
- 区块数据:区块头(时间戳、Gas限制、难度等)、区块哈希。
- 交易数据:发送者、接收者、金额、Gas费用、输入数据(input data)。
- 智能合约数据:合约地址、代码、事件日志(logs)。
- 账户数据:地址余额、代币持有量。
- 事件日志:智能合约触发的日志(如ERC-20的Transfer事件)。
这些数据存储在以太坊区块链的分布式账本中,通过节点或API访问。
2. 数据抽取方法
抽取以太坊数据的常见方法包括:
a. 运行全节点
- 描述:运行以太坊全节点(如Geth、OpenEthereum)或存档节点,同步完整区块链数据。
- 优点:数据全面,可访问历史和实时数据,高度可信。
- 缺点:存储需求高(截至2025年6月,全节点约1TB,存档节点超10TB),同步耗时,维护成本高。
- 适用场景:需要原始、未加工数据的大型分析项目。
- 示例:使用Geth的JSON-RPC接口(如
eth_getBlockByNumber)获取区块数据。
代码示例(Python + Web3.py):
from web3 import Web3# 连接到本地Geth节点w3 = Web3(Web3.HTTPProvider(\'http://localhost:8545\'))# 获取最新区块block = w3.eth.get_block(\'latest\')print(f\"Block Number: {block[\'number\']}, Timestamp: {block[\'timestamp\']}\")b. 使用第三方API
- 描述:通过服务如Infura、Alchemy或Etherscan获取数据,无需运行节点。
- 优点:快速接入,低维护成本,支持批量查询。
- 缺点:受API限制(如速率限制、付费订阅),可能缺乏某些低级别数据。
- 适用场景:快速原型开发或中小规模分析。
- 示例:通过Etherscan API查询某地址的交易历史。
c. 索引协议
- 描述:使用The Graph等去中心化索引协议,查询预处理的事件日志或合约数据。
- 优点:高效查询事件数据,适合DApp分析。
- 缺点:依赖子图(Subgraph)定义,数据覆盖有限。
- 适用场景:分析特定合约或事件(如Uniswap的Swap事件)。
d. 预处理数据集
- 描述:使用Google BigQuery、Dune Analytics等平台提供的区块链数据集。
- 优点:无需自行抽取,数据已结构化,适合SQL查询。
- 缺点:可能滞后实时数据,需付费或受查询限制。
- 适用场景:快速分析或非实时需求。
3. 抽取挑战
- 数据量大:以太坊每日生成约100万笔交易,历史数据规模庞大。
- 实时性:实时分析需快速同步最新区块,延迟可能影响结果。
- 复杂格式:交易的输入数据和事件日志需解码(如解析ABI)。
4. 最佳实践
- 混合使用节点和API:用节点获取低级别数据,用API补充高频查询。
- 增量抽取:仅同步新区块,减少重复处理。
- 验证数据完整性:检查区块哈希和交易确认状态,避免数据丢失。
三、数据加工
1. 什么是数据加工?
数据加工是将原始区块链数据清洗、转换和建模,生成适合分析的结构化数据集。加工的目标是:
- 统一数据格式,解决原始数据的十六进制编码或嵌套结构。
- 解码复杂数据,如合约的输入数据或事件日志。
- 存储到数据仓库,优化查询性能。
2. 加工步骤
a. 数据清洗
- 任务:处理缺失值、重复数据或无效记录(如失败交易)。
- 示例:过滤状态为“失败”的交易,仅保留成功记录。
- 工具:Python(Pandas)、SQL。
b. 数据解码
- 任务:将原始数据(如十六进制输入数据)解码为可读格式。
- 示例:解析ERC-20的
Transfer事件,提取from、to和value字段。 - 工具:Web3.py、ethers.js、ABI解码库。
代码示例(解码事件日志):
from web3 import Web3from eth_abi import decode_abiw3 = Web3(Web3.HTTPProvider(\'https://mainnet.infura.io/v3/YOUR_API_KEY\'))# 假设已知Transfer事件签名topic = \'0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef\'log = { \'topics\': [topic, \'0x...from\', \'0x...to\'], \'data\': \'0x00000000000000000000000000000000000000000000000000000000000003e8\'}# 解码data字段amount = decode_abi([\'uint256\'], bytes.fromhex(log[\'data\'][2:]))[0]print(f\"Transfer Amount: {amount}\") # 输出:1000c. 数据转换
- 任务:将数据标准化,如时间戳转为日期、Wei转为ETH。
- 示例:将交易金额从Wei(10^18)转换为ETH。
- 工具:ETL框架(Airflow、dbt)、Python。
d. 数据建模
- 任务:设计数据表结构,优化查询性能。
- 常见模型:
- 事实表:存储交易、事件日志等核心数据。
- 维度表:存储账户、合约、时间等上下文信息。
- 示例:为交易设计表结构:
CREATE TABLE transactions ( tx_hash VARCHAR(66) PRIMARY KEY, block_number BIGINT, from_address VARCHAR(42), to_address VARCHAR(42), value DECIMAL(36, 18), gas_price BIGINT, timestamp TIMESTAMP); - 工具:数据仓库(Snowflake、BigQuery)、PostgreSQL。
e. 数据存储
- 任务:将加工后的数据存储到数据仓库或数据库。
- 选择:
- 云数据仓库:BigQuery、Snowflake,适合大规模分析。
- 本地数据库:PostgreSQL、ClickHouse,适合中小项目。
- 分布式存储:Hadoop、Parquet,适合海量历史数据。
3. 加工挑战
- 复杂性:智能合约的输入数据和事件日志格式各异,需针对性解码。
- 性能:处理TB级数据需高效的ETL管道。
- 一致性:链上数据可能因分叉或重组而变化,需定期校验。
4. 最佳实践
- 使用ETL工具(如Airflow)自动化加工流程。
- 缓存常见解码结果(如合约ABI),减少重复计算。
- 分层建模:原始层(raw)、中间层(staging)、分析层(mart)。
- 监控数据质量,确保一致性和完整性。
四、数据分析
1. 什么是数据分析?
数据分析是从加工后的数据中提取洞察,回答业务或研究问题。以太坊数据分析的目标包括:
- 监测网络健康(如Gas费用趋势、区块填充率)。
- 分析用户行为(如DeFi参与度、NFT交易模式)。
- 优化协议(如Uniswap的流动性池效率)。
- 风险评估(如异常交易检测、套利行为)。
2. 分析方法
a. 描述性分析
- 目标:总结历史数据,揭示趋势和模式。
- 示例:计算每日交易量和平均Gas费用。
- SQL示例:
SELECT DATE(timestamp) AS date, COUNT(*) AS tx_count, AVG(gas_price * gas_used / 1e18) AS avg_gas_fee_ethFROM transactionsGROUP BY DATE(timestamp)ORDER BY date DESC; - 工具:Dune Analytics、Metabase、Tableau。
b. 诊断性分析
- 目标:探究现象原因,如Gas费用激增的驱动因素。
- 示例:分析DeFi协议活动与Gas费用之间的相关性。
- 工具:Python(Pandas、Matplotlib)、R。
c. 预测性分析
- 目标:预测未来趋势,如交易量或代币价格。
- 示例:使用时间序列模型预测Uniswap的日交易量。
- 工具:Python(scikit-learn、Prophet)、TensorFlow。
d. 探索性分析
- 目标:发现未知模式,如异常交易或套利机会。
- 示例:检测跨交易所的三角套利行为。
- 工具:Jupyter Notebook、GraphQL(The Graph)。
3. 分析场景示例
场景1:DeFi协议分析
- 问题:Uniswap V3的流动性池效率如何?
- 数据:Swap事件日志、池子余额、交易费用。
- 分析:
- 抽取Swap事件,解码
amount0、amount1。 - 计算每笔交易的手续费收益和无常损失。
- 绘制收益曲线:
- 抽取Swap事件,解码
场景2:NFT市场洞察
- 问题:Bored Ape Yacht Club(BAYC)的交易活跃度如何?
- 数据:ERC-721 Transfer事件、交易金额。
- 分析:
- 聚合每日转账次数和平均价格。
- 识别高频交易者,分析市场投机行为。
SELECT DATE(timestamp) AS date, COUNT(*) AS transfer_count, AVG(value / 1e18) AS avg_price_ethFROM nft_transfersWHERE contract_address = \'0xBC4CA0EdA7647A8aB7C2061c2E118A18a936f13D\' -- BAYC地址GROUP BY DATE(timestamp);
4. 分析挑战
- 数据延迟:实时分析受区块确认时间(约12秒)限制。
- 隐私限制:链上数据公开,但用户身份难以关联,限制行为分析。
- 计算复杂性:分析TB级数据需高性能计算资源。
5. 最佳实践
- 使用可视化工具(如Dune、Looker)呈现结果。
- 结合链上和链下数据(如价格feeds),丰富分析维度。
- 定期更新模型,适应区块链协议升级(如EIP-1559)。
- 共享社区仪表板(如Dune Analytics),复用现有分析。
五、工具与技术栈
以下是区块链数据分析的常用工具和技术栈:
推荐技术栈:
- 初学者:Infura + Dune Analytics + SQL。
- 高级用户:Geth + Airflow + BigQuery + Python。
六、案例研究:以太坊Gas费用分析
目标:分析2024-2025年以太坊Gas费用趋势,评估EIP-1559的影响。
流程:
-
抽取:
- 使用Infura API获取2024-2025年的交易数据。
- 提取
gasPrice、gasUsed和baseFeePerGas(EIP-1559引入)。
-
加工:
- 清洗:过滤失败交易,转换Wei为Gwei。
- 建模:创建
gas_fees表,包含tx_hash、block_number、base_fee、tip。 - 存储:导入BigQuery。
-
分析:
- 计算每日平均Base Fee和Tip:
SELECT DATE(timestamp) AS date, AVG(base_fee_per_gas / 1e9) AS avg_base_fee_gwei, AVG(max_priority_fee_per_gas / 1e9) AS avg_tip_gweiFROM gas_feesGROUP BY DATE(timestamp); - 可视化Gas趋势:
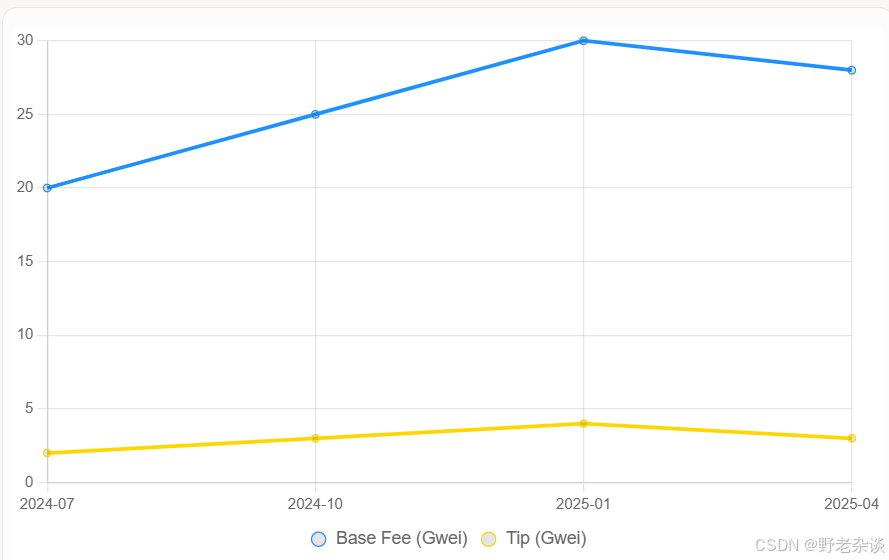
- 计算每日平均Base Fee和Tip:
-
洞察:
- EIP-1559后,Base Fee波动反映网络拥堵,Tip稳定在低水平。
- 高Gas费用与DeFi和NFT热潮相关。
七、未来趋势
- Layer 2数据分析:随着Rollups(如Optimism、Arbitrum)普及,需分析跨层数据。
- AI驱动分析:结合大模型(如Grok)解析链上行为,生成自然语言洞察。
- 隐私保护分析:零知识证明(如zk-SNARKs)可能限制公开数据,需新方法。
- 实时流处理:使用Kafka、Flink处理实时区块链数据,满足高频交易需求。
八、总结
区块链数据分析是一个从抽取到洞察的系统化过程,以太坊数据分析尤为复杂但价值巨大。数据抽取需平衡实时性和成本,选择节点、API或索引协议;数据加工通过清洗、解码和建模,将原始数据转为可查询格式;数据分析利用SQL、统计或机器学习,揭示交易模式、协议效率或风险信号。工具如The Graph、Dune Analytics和BigQuery极大简化了流程,但开发者仍需应对数据规模、复杂性和实时性挑战。通过结构化的分析流程,区块链数据为Web3生态提供了驱动创新的洞察力。


