基于Spark lite科大讯飞星火大模型Prompt工程使用技巧【简洁易懂】
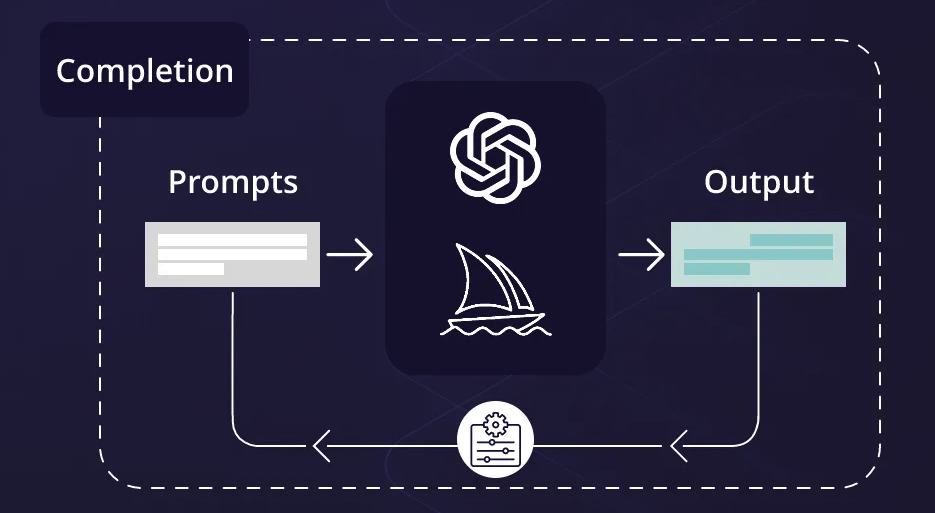
本文使用的是星火大模型的接口,在此基础上进行Prompt测试,通过对学习内容来源的学习与总结,不断完善本博客。
首先使用以下代码,进行prompt测试,以下代码借鉴了官方源码,所以想要测试更多性能,参考官网代码。
官方源码:
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandlerfrom sparkai.core.messages import ChatMessage#星火认知大模型Spark Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看SPARKAI_URL = \'wss://spark-api.xf-yun.com/v3.5/chat\'#星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看SPARKAI_APP_ID = \'\'SPARKAI_API_SECRET = \'\'SPARKAI_API_KEY = \'\'#星火认知大模型Spark Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看SPARKAI_DOMAIN = \'generalv3.5\'if __name__ == \'__main__\': spark = ChatSparkLLM( spark_api_url=SPARKAI_URL, spark_app_id=SPARKAI_APP_ID, spark_api_key=SPARKAI_API_KEY, spark_api_secret=SPARKAI_API_SECRET, spark_llm_domain=SPARKAI_DOMAIN, streaming=False, ) messages = [ChatMessage( role=\"user\", content=\'你好呀\' )] handler = ChunkPrintHandler() a = spark.generate([messages], callbacks=[handler]) print(a)使用prompt工程的代码:
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandlerfrom sparkai.core.messages import ChatMessage# \\\"\\\"\\\"{text}\\\"\\\"\\\"#星火认知大模型Spark Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看SPARKAI_URL = \'wss://spark-api.xf-yun.com/v1.1/chat\'#星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看SPARKAI_APP_ID = \'\'SPARKAI_API_SECRET = \'\'SPARKAI_API_KEY = \'\'#星火认知大模型Spark Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看SPARKAI_DOMAIN = \'lite\'if __name__ == \'__main__\': spark = ChatSparkLLM( spark_api_url=SPARKAI_URL, spark_app_id=SPARKAI_APP_ID, spark_api_key=SPARKAI_API_KEY, spark_api_secret=SPARKAI_API_SECRET, spark_llm_domain=SPARKAI_DOMAIN, streaming=False, ) prompt = f\"\"\"你的任务是以一致的风格回答问题。: 教我耐心: 耐心是一个重要的品质。它可以帮助你在生活中更好地应对挑战和困难。挖出最深的峡谷的河流源于一处不起眼的泉眼;最宏伟的交响乐从单一的音符开始;最复杂的挂毯以一根孤独的线开始编织。: 教我韧性。\"\"\" messages = [ChatMessage( role=\"user\", content=prompt )] handler = ChunkPrintHandler() a = spark.generate([messages], callbacks=[handler]) print(a)调用星火大模型经典错误
🤣原因:网络原因,多试几次🤣
Traceback (most recent call last):
File \"/Users/admin/mayucode/NLP/propmt/test8.py\", line 64, in
a = spark.generate([messages])
^^^^^^^^^^^^^^^^^^^^^^^^^^
File \"/opt/anaconda3/envs/yolobest/lib/python3.11/site-packages/sparkai/core/language_models/chat_models.py\", line 412, in generate
raise e
File \"/opt/anaconda3/envs/yolobest/lib/python3.11/site-packages/sparkai/core/language_models/chat_models.py\", line 402, in generate
self._generate_with_cache(
File \"/opt/anaconda3/envs/yolobest/lib/python3.11/site-packages/sparkai/core/language_models/chat_models.py\", line 581, in _generate_with_cache
return self._generate(
^^^^^^^^^^^^^^^
File \"/opt/anaconda3/envs/yolobest/lib/python3.11/site-packages/sparkai/llm/llm.py\", line 378, in _generate
for content in self.client.subscribe(timeout=self.request_timeout):
File \"/opt/anaconda3/envs/yolobest/lib/python3.11/site-packages/sparkai/llm/llm.py\", line 703, in subscribe
raise e
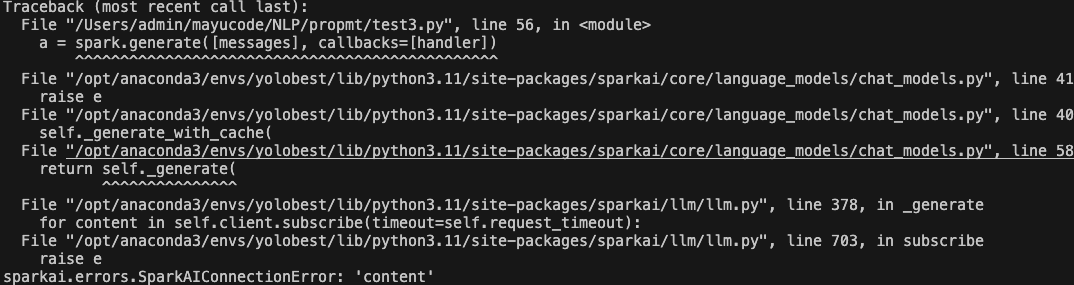
sparkai.errors.SparkAIConnectionError: \'content\'
提示原则(Guidelines)
原则一:编写清晰、具体指令
策略一:使用分隔符清晰表示输入的不同部分

策略二:要求一个结构化的输出

策略三:要求模型检查是否满足条件
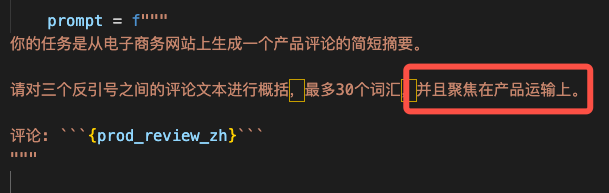
# 有步骤的文本text_1 = f\"\"\"泡一杯茶很容易。首先,需要把水烧开。\\在等待期间,拿一个杯子并把茶包放进去。\\一旦水足够热,就把它倒在茶包上。\\等待一会儿,让茶叶浸泡。几分钟后,取出茶包。\\如果你愿意,可以加一些糖或牛奶调味。\\就这样,你可以享受一杯美味的茶了。\"\"\"prompt = f\"\"\"您将获得由三个引号括起来的文本。\\如果它包含一系列的指令,则需要按照以下格式重新编写这些指令:第一步 - ...第二步 - ……第N步 - …如果文本中不包含一系列的指令,则直接写“未提供步骤”。\"\\\"\\\"\\\"{text_1}\\\"\\\"\\\"\"\"\"waringing:使用Spark lite大模型时要注意,此模型大概不支持prompt+文本的格式,支持单个字符串输入,因为会有报错。
sparkai.errors.SparkAIConnectionError: \'content\'
目前没有找到解决方案,大家可以在留言区讨论或者指正。
策略四:提供少量示例
![]()
原则二:给模型时间考虑
策略一:指定完成任务所需的步骤
prompt_1 = f\"\"\"执行以下操作:1-用一句话概括下面用三个反引号括起来的文本。2-将摘要翻译成法语。3-在法语摘要中列出每个人名。4-输出一个 JSON 对象,其中包含以下键:French_summary,num_names。请用换行符分隔您的答案。Text:```{text}```\"\"\"策略二:指导模型在下结论之前找出一个自己的解决办法
也就是使用已知答案,之后将已知答案与大模型生成的答案进行对比,让大模型自己进行评判对错。
迭代优化(lterative)
问题一:生成的文本较长
解决方法:限制输出的文本长度
解决方法可以通过两种方式进行
①从模型生成的参数进行限制
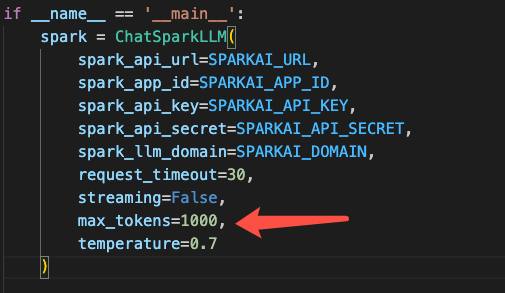
②直接输入的时候进行命令提示(本方法比较符合prompt工程)

问题二:文本关注在错误的细节上
解决方法:要求关注于某些方面

问题三:需要一个表格形式的描述
解决方式:要求它抽取信息并组织成表格,并指定表格的列、表名和格式,还要求它将所有内容格式化为可以在网页使用的 HTML。

文本概括(Summarizing)
单一文本
单一文本的Prompt概括,可以直接从用户输入端限制输出长度。

关键角度侧重
通过输入文字,限定大模型输出的内容。
关键信息提取
给大模型指定某些特定的信息进行提取。

多条文本概括
多条文本概括,可以使用for循环,但是在例如多个PDF或者报告之类的文本时,for循环方法就显得鸡肋。
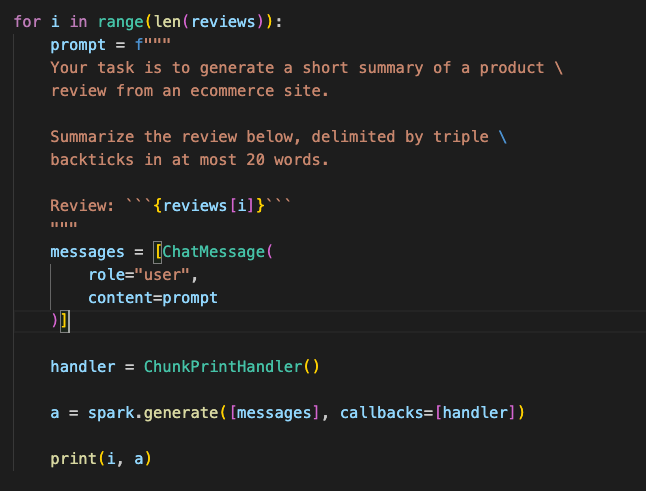
文本推断(Inferring)
文本推断就是基于所给内容,使用大模型进行分析,推断其他信息的过程。
情感方面
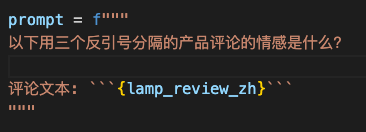
识别感情类型

指定感情类型识别

输出:
![]()

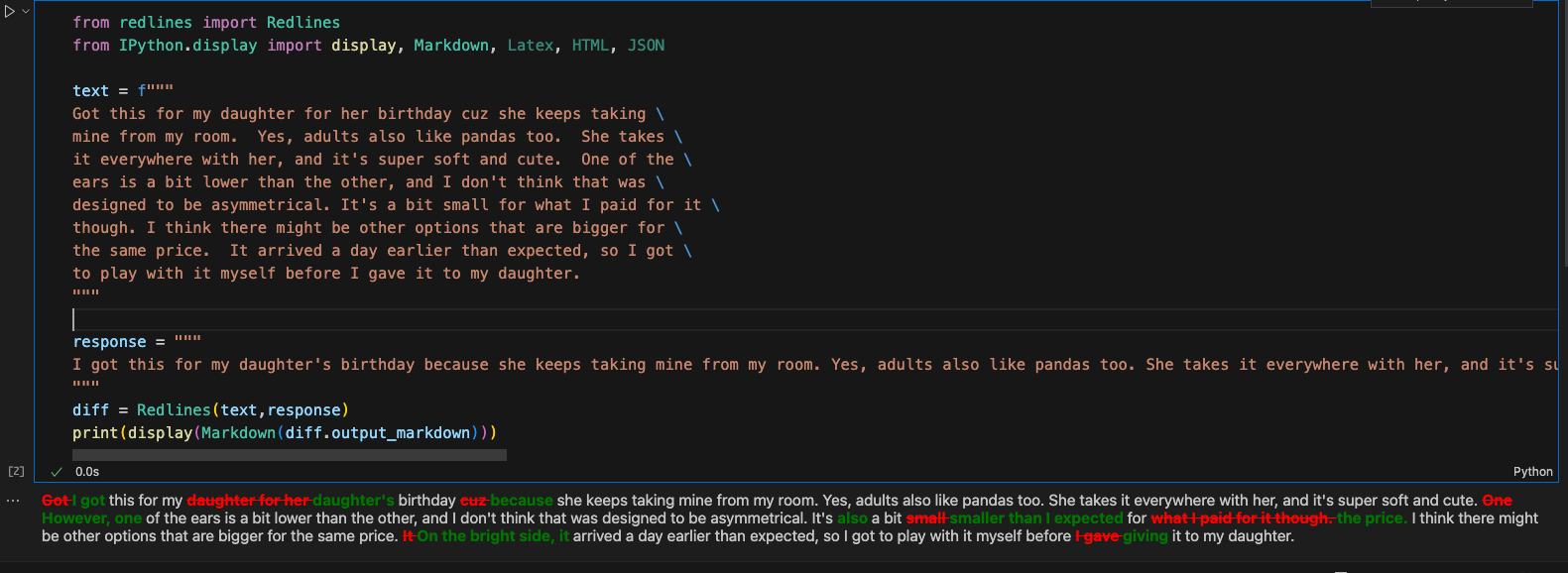
添加了原因之后,在进行输出,给出了更具体的原因。

小插曲
如何让大模型只显示输出的结果,而不是整个结构,如包括输出长度、输出结构信息等?
答案:print(a) 会显示整个对象,内容包括:生成文本、token 使用、响应元信息、函数调用结构等,非常冗杂。
使用a.generations[0][0].text可以只显示大模型的标准输出格式。
优化前:

优化后:

原因:
从文本中提取有用信息
也就是引用已知的文本,添加prompt提示词工程,提示大模型识别哪些内容,并进行输出,提示词应该进行严格且标准的格式。

一次完成多项任务
也就是在prompt里面写入多个任务,让模型自动识别

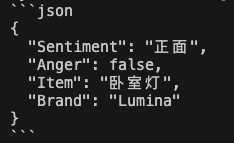
推断主题
从一段文本中让大模型自动推理出内容,并推理出主题等。

统计话题
统计文本内的话题,并进行记录(注意这个前后顺序很重要)

这在机器学习中有时被称为 Zero-Shot 学习算法,因为我们没有给它任何标记的训练数据。
检测指定文本
可以手动添加相关代码,实现工程开发

文本转换(Transforming)
文本转换包括将输入转换成不同的格式,文本翻译、拼写及语法纠正、语气调整、格式转换等。
文本翻译
可以直接输入指令,将对应文本翻译成某种语言。
识别语种
直接向大模型输入指令,识别某种语种
多语种翻译
对同意文本进行多个语种输入,得到多个语种翻译结果

翻译+正式语气
这个主要就是把文本进行翻译,并进行语气设置

⭐️通用翻译器
这个就是相当于使用大模型完成一个小功能设计:
核心代码
user_messages = [ \"La performance du système est plus lente que d\'habitude.\", # System performance is slower than normal \"Mi monitor tiene píxeles que no se iluminan.\", # My monitor has pixels that are not lighting \"Il mio mouse non funziona\", # My mouse is not working \"Mój klawisz Ctrl jest zepsuty\", # My keyboard has a broken control key \"我的屏幕在闪烁\" # My screen is flashing]if __name__ == \'__main__\': spark = ChatSparkLLM( spark_api_url=SPARKAI_URL, spark_app_id=SPARKAI_APP_ID, spark_api_key=SPARKAI_API_KEY, spark_api_secret=SPARKAI_API_SECRET, spark_llm_domain=SPARKAI_DOMAIN, request_timeout=60, streaming=False, max_tokens=1000, temperature=0.7 )for issue in user_messages: prompt = f\"如法语,无需输出标点符号:```{issue}```\" messages = [ChatMessage( role=\"user\", content=prompt )] handler = ChunkPrintHandler() a = spark.generate([messages]) profect_Answer = a.generations[0][0].text print(f\"原始消息*({profect_Answer}):{issue}\") prompt = f\"\"\" 将以下消息分别翻译成英文和中文,并写成 中文翻译:xxx 英文翻译:yyy 的格式: ```{issue}``` \"\"\" messages = [ChatMessage( role=\"user\", content=prompt )] handler = ChunkPrintHandler() a = spark.generate([messages]) profect_Answer = a.generations[0][0].text print(profect_Answer, \"\\n=========================================\")结果输出:
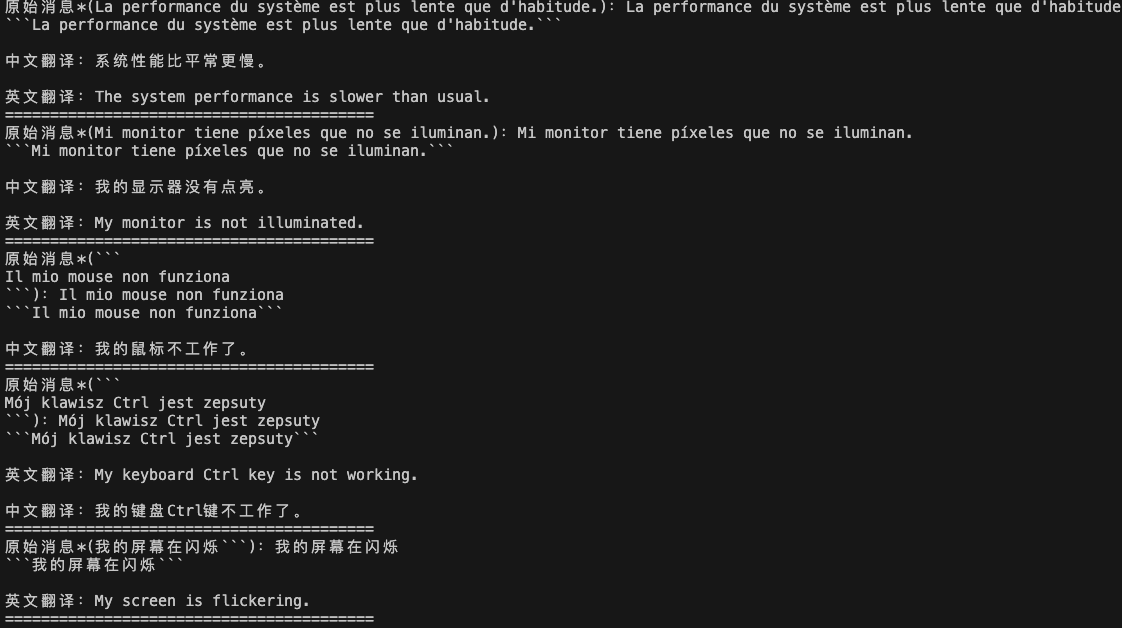
语气/风格调整

格式转换
大模型较擅长进行各种文件格式进行转换

拼写及语法纠正
直接让大模型对文本进行纠正
需要安装Jupyter内核,博主使用的是VS code,所以创建了一个.pynb文件,直接安装就可以使用。
🌛综合案例
案例使用文本翻译+拼写纠正+风格调整+格式转换

文本扩展(Expanding)
定制邮件
我们可以首先定义邮件风格,然后内容,之后设定感情风格来生成指定内容

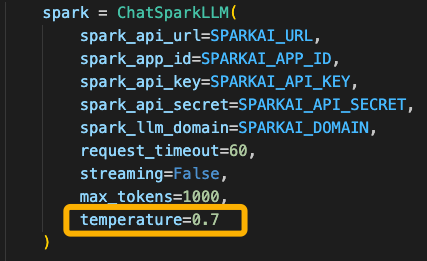
温度系数
在接口调用或者本地化部署中,大模型输入参数都有temperature。
参数说明:参数设置越高,模型的输出更加随机。模型回答的更随机,更分散,但也许更有创造力。
输出结果:

☀️聊天机器人☀️
使用接口来实现构建针对特定任务或者行为的聊天机器人进行延伸对话
因为之前使用的接口代码都是Prompt相当于单次对话,现在如果想要多轮对话,可以简单更改代码。
from openai import OpenAIclient = OpenAI( api_key=\"你的APIPassWord\", base_url = \'https://spark-api-open.xf-yun.com/v1/\' # 指向讯飞星火的请求地址 )completion = client.chat.completions.create( model=\'lite\', # 指定请求的版本 messages=[ {\'role\':\'system\', \'content\':\'你是一个像莎士比亚一样说话的助手。\'}, {\'role\':\'user\', \'content\':\'给我讲个笑话\'}, {\'role\':\'assistant\', \'content\':\'鸡为什么过马路\'}, {\'role\':\'user\', \'content\':\'我不知道\'} ])print(completion.choices[0].message)以上是使用OpenAI的格式进行的多轮对话,并且使用的是HTTP的调用方式,与WebSocket略有不同。
这里输出的话是把大模型所有信息都输出,以下代码能够只输出大模型输出部分,并且能够识别换行内容。
print(response.choices[0].message.content) # 如果 message 是对象# 或者print(response.choices[0].message[\"content\"]) # 如果是 dict对比:
![]()
![]()
输出内容更简洁,易于查看。
🍞订餐信息机器人🍚
这个大模型的主要作用是进行订餐信息的,可以直接提取用户消息,避免重新输入的繁琐操作。
以下函数是为了收集提示信息,并添加到列表中,每次调用模型则调取该上下文。
def collect_messages(_): prompt = inp.value_input inp.value = \'\' context.append({\'role\':\'user\', \'content\':f\"{prompt}\"}) response = get_completion_from_messages(context) context.append({\'role\':\'assistant\', \'content\':f\"{response}\"}) panels.append( pn.Row(\'User:\', pn.pane.Markdown(prompt, width=600))) panels.append( pn.Row(\'Assistant:\', pn.pane.Markdown(response, width=600, style={\'background-color\': \'#F6F6F6\'}))) return pn.Column(*panels)学习内容来源:
提示原则 | 面向开发者的 Prompt 工程(官方文档中文版)

