SA-BEV: Generating Semantic-Aware Bird’s-Eye-View Feature for Multi-view 3D Object Detection_sa-bev: generating semantic-aware bird鈥檚-eye-view
背景
对于显式深度估计,他会把伪点云投影到BEV平面压扁,但这个操作并没有利用图像特征的语义信息,并且会将大量的背景信息注入到BEV特征图中。因此本篇文章充分图像的语义信息,提出了Semantic-Aware的BEV Pooling,在投影到BEV空间前,首先预测特征图的语义分割,如果该点属于背景空间,则不会投影到BEV图中;此外,深度分数低的点也不会被投影。总的来说,SA-BEVPool能够有效过滤大多数背景BEV特征从而缓解背景信息淹没前景信息的问题,这里的语义分割是在深度分支上同时预测小尺寸图像特征的语义。
GT-Paste是Second等方法中常用的一种数据增强方法,具体就是预先建立一个数据库,保存了多个物体的GT框信息以及它们包含的点云信息。之后将其复制到其他数据帧中,从而增加数据多样性。但是这在相机视图上不适用。在该方法中,由于可靠深度估计以及语义分割两者作用,SA-BEV能够表示BEV空间中所有物体的信息,因此将其他帧BEV特征图加到当前BEV特征图等同于将其他帧的物体传过来,称之为BEV-Paste,与GT-Paste类似提升数据多样性。
使用同个分支去预测深度和语义分割是方便的,但这样会导致一个次优的SA-BEV特征,而多任务学习说明将具体任务与跨任务信息结合起来有益于多预测任务的最优解法,因此这里设计了多尺度跨任务头MSCT,它通过多任务蒸馏将具体任务与跨任务信息结合起来,并且对不同尺度的预测进行双流监督。
贡献
- 它考虑到背景点淹没前景点的问题,因此在BEV生成上只把前景点投影过来。这是通过语义分割,并手工设置阈值实现的。
- 提出了BEV-Paste数据增强方法,它是基于BEV视图描述的是前景点信息这一前提,将多帧BEV视图加在一块其实就是把其他帧物体聚合到该帧,将其他帧BEV图经过BDA后与当前帧相加,但还存在遮挡重叠问题。
- 提出多尺度跨任务头,用两个分支分别预测深度与语义分割,并且用多任务蒸馏方法传递跨任务信息,且双流监督多尺度信息。
方法
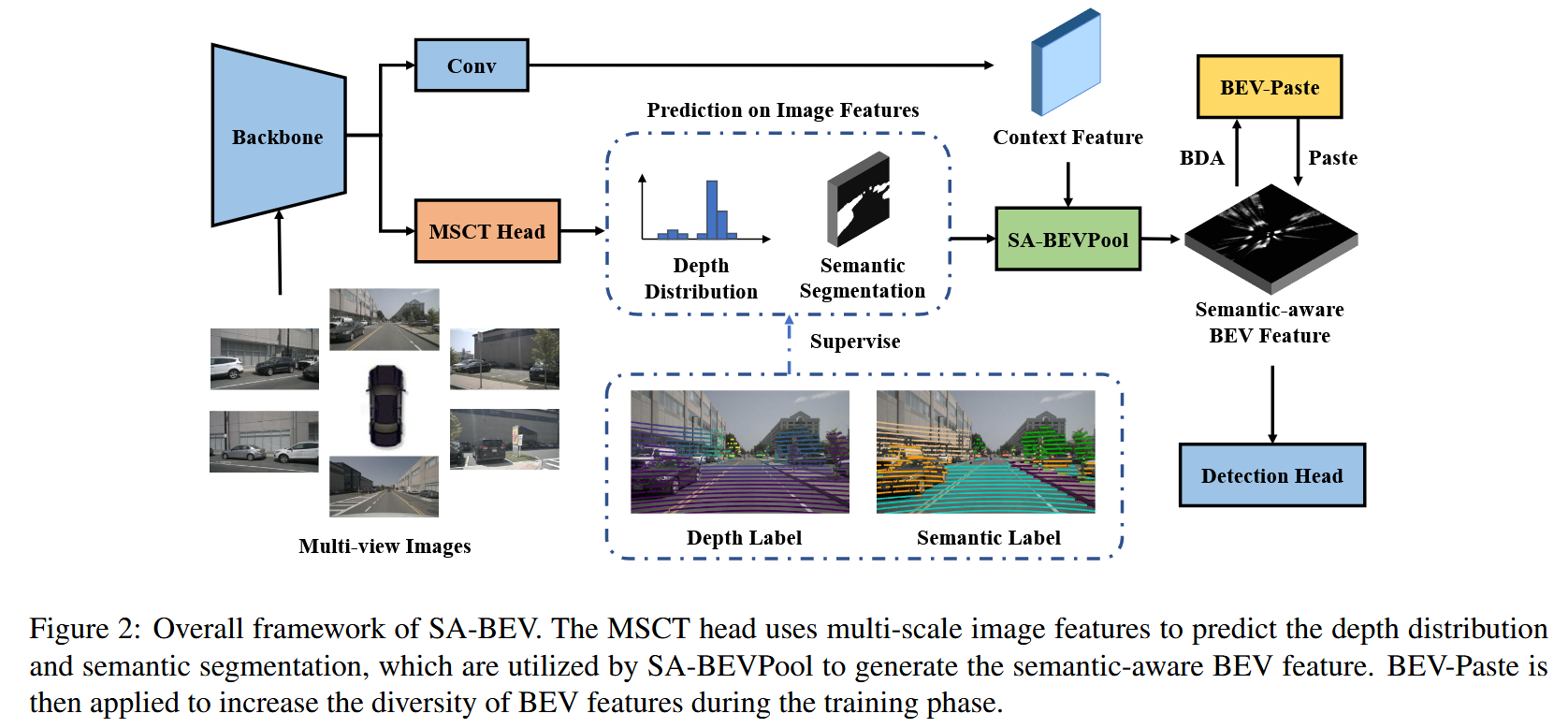
SA-BEV Pooling
以前的工作是把所有的伪点云都投影到BEV上,但对于目标检测任务这是不必要的,如果属于背景的所有点都被投影,那么前景点会被淹没,使检测头检测难度增加,降低检测精度。如图所示,

因此提出了Semantic-Aware BEV Pooling,对于图像特征使用语义分割获得每个元素前景分数β,有低β分数的点容易携带低有效信息,因此在投影时会忽略这个点;同样的,如果点的深度置信度较低,同样会被忽略掉。因此,这种过滤低分数的点的操作会赋予BEV特征图语义信息。
BEV-paste
GT-paste不能使用在图像中有以下原因:首先按照边界框采样图像会带有背景噪声,这与点云不同;第二是这可能造成视角遮挡导致信息丢失;第三是不同帧图片的光照不同,这会给物体不自然的外观。而我们提出的BBEV-paste是考虑到之前已经提取出前景信息,此时的BEV特征图相当于只描述物体的信息,因此将其他特征图加过来相当于将两帧物体聚合起来。具体来说,他将同一批次的一帧BEV数据首先进行数据增强,从而增加数据多样性,再与当前帧进行相加。再将这个结果与变化的GT值进行损失计算即可。但它也有不足,就是会有重叠与遮挡。
多尺度跨任务头
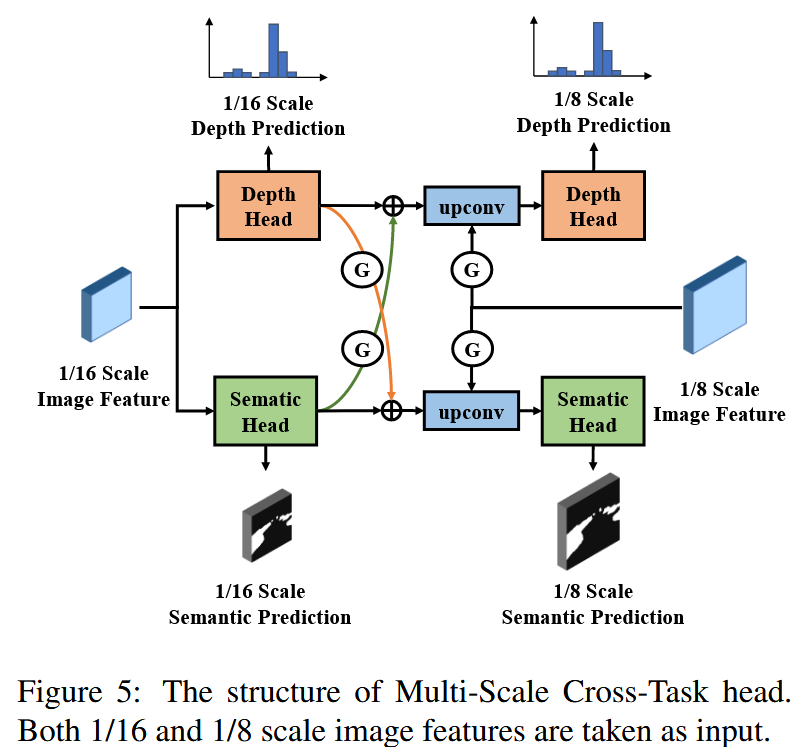
他这里使用多任务蒸馏,将BEV图的生成视为一个多任务学习应用,如果只用一个分支去预测深度与语义分割,则是次优的,它只能提取跨任务的信息,每个任务都不能做到最优。
本方法首先是经过两个head进行粗糙的预测,然后将原图像特征图Fi16F_i^{16}Fi16转换为深度与语义两方面的特征图FD16F_D^{16}FD16与FS16F_S^{16}FS16,此时他们都学习到具体任务的信息。接下来需要去学习跨任务信息,使用自注意块生成门控图,如下所示,代表对F使用卷积,再使用sigmod函数,这样就能对两个预测
G(F)=σ(WGF)G(F) = \\sigma(W_G F)G(F)=σ(WGF)
然后按照如图过程所示计算,这样得到了下面两个,这样使用自注意力块自动提取了跨任务信息。
F^D16=FD16+G(FD16)⊙(WtFS16)\\hat{F}^{16}_D = F^{16}_D + G(F^{16}_D) \\odot (W_t F^{16}_S) F^

