前端富文本编辑器能否支持从Word复制多张图片并上传?
一个C#程序员的UEditor+Word导入奇幻漂流:从.NET到Vue的魔幻联动
第一章:需求降临——老板的\"简单\"需求
\"小王啊,咱们后台编辑器得加个Word导入功能,要保留格式和图片啊!“老板轻描淡写的一句话,让我手里的拿铁差点变成\"拿铁喷泉”。
作为一枚在C#后端摸爬滚打四年的程序员,我深知这个\"简单\"需求背后的技术栈碰撞有多刺激。前端Vue2+UEditor,后端ASP.NET,数据库SQL Server——这组合就像把火锅、披萨和寿司拼成一桌,得小心别串味儿!
第二章:前端探路——Vue2里的UEditor初体验
2.1 与UEditor的\"包办婚姻\"
项目用的是vue2-cli,我首先得在前端集成UEditor。GitHub上翻了一圈,发现vue-ueditor-wrap这个\"官方认证\"的包,就像发现相亲对象居然是自己小学同学——既熟悉又陌生。
// main.js里的\"婚礼誓言\"import VueUEditorWrap from \'vue-ueditor-wrap\'Vue.component(\'vue-ueditor-wrap\', VueUEditorWrap)// 组件里的\"蜜月期\"data() { return { editorConfig: { serverUrl: \'/api/ueditor/upload\', // 后端接口 UEDITOR_HOME_URL: \'/static/UEditor/\' // UEditor资源路径 } }}2.2 寻找Word导入的\"魔法棒\"
UEditor官方没Word导入功能,我像哈利波特在禁书区乱翻:
- 发现个
docx-to-html的npm包,但前端处理大文件会卡爆 - 看到个用Open XML SDK的方案,但需要后端配合
- 终于在CodeProject找到线索——有个用C#实现的Word解析器,就像找到藏在阁楼的魔法书
第三章:后端攻坚——ASP.NET的文档处理大冒险
3.1 文件上传接口初体验
首先得实现UEditor的上传接口,按照官方文档(翻译版):
// UEditorController.cs - 我们的\"魔法部\"[Route(\"api/ueditor/upload\")][ApiController]public class UEditorController : ControllerBase{ private readonly IWebHostEnvironment _env; public UEditorController(IWebHostEnvironment env) { _env = env; } [HttpPost] public async Task Upload(IFormFile upfile) { try { // 1. 确保目录存在 var uploadsPath = Path.Combine(_env.WebRootPath, \"uploads\"); if (!Directory.Exists(uploadsPath)) { Directory.CreateDirectory(uploadsPath); } // 2. 生成唯一文件名 var fileName = $\"{Guid.NewGuid()}{Path.GetExtension(upfile.FileName)}\"; var filePath = Path.Combine(uploadsPath, fileName); // 3. 保存文件 using (var stream = new FileStream(filePath, FileMode.Create)) { await upfile.CopyToAsync(stream); } // 4. 返回UEditor需要的格式 return Ok(new { state = \"SUCCESS\", url = $\"/uploads/{fileName}\", title = fileName, original = upfile.FileName }); } catch (Exception ex) { return BadRequest(new { state = \"ERROR\", message = ex.Message }); } }}3.2 Word转HTML的终极方案
经过多次尝试,发现C#处理Word文档的几种方案:
- Microsoft.Office.Interop.Word:需要安装Office,服务器部署噩梦
- Open XML SDK:微软官方,但API复杂得像迷宫
- NPOI:开源但功能有限
- DocX:简单但商业用途要付费
最终选择了Open XML SDK+HtmlAgilityPack的组合,就像拿着魔杖和扫帚并肩作战:
// WordConverterService.cs - 我们的\"咒语书\"public class WordConverterService{ public async Task ConvertDocxToHtmlAsync(IFormFile file) { using (var stream = new MemoryStream()) { await file.CopyToAsync(stream); using (var wordDocument = WordprocessingDocument.Open(stream, false)) { // 1. 获取文档主体 var body = wordDocument.MainDocumentPart.Document.Body; // 2. 转换为HTML字符串 var htmlBuilder = new StringBuilder(); htmlBuilder.AppendLine(\"\"); // 3. 处理段落和样式 foreach (var paragraph in body.Descendants()) { htmlBuilder.AppendLine(\"\"); foreach (var run in paragraph.Descendants()) { // 处理文本 var text = run.GetFirstChild()?.Text ?? \"\"; if (!string.IsNullOrEmpty(text)) { // 处理粗体 if (run.Descendants().Any()) { htmlBuilder.Append(\"\"); } // 处理斜体 if (run.Descendants().Any()) { htmlBuilder.Append(\"\"); } htmlBuilder.Append(HttpUtility.HtmlEncode(text)); // 关闭标签 if (run.Descendants().Any()) htmlBuilder.Append(\"\"); if (run.Descendants().Any()) htmlBuilder.Append(\"\"); } // 处理图片(后续实现) } htmlBuilder.AppendLine(\"\"); } // 4. 处理图片(简化版) await HandleImagesAsync(wordDocument, htmlBuilder); htmlBuilder.AppendLine(\"\"); return htmlBuilder.ToString(); } } } private async Task HandleImagesAsync(WordprocessingDocument wordDocument, StringBuilder htmlBuilder) { // 实际项目中需要更复杂的图片处理逻辑 // 这里只是示例:记录图片存在并返回占位符 var imageParts = wordDocument.MainDocumentPart.ImageParts; if (imageParts.Count() > 0) { htmlBuilder.AppendLine(\"文档包含图片(功能开发中)\"); } }}3.3 图片处理的\"魔法阵\"
Word里的图片是最棘手的,我尝试了:
- 直接提取:Open XML SDK可以访问图片,但关联关系复杂
- 内存中转换:将图片保存到服务器并返回URL
- 最终方案:
// 增强版图片处理private async Task HandleImagesAsync(WordprocessingDocument wordDocument, StringBuilder htmlBuilder, string uploadPath){ var imageIndex = 0; foreach (var imagePart in wordDocument.MainDocumentPart.ImageParts) { // 1. 生成唯一文件名 var extension = Path.GetExtension(imagePart.Uri.OriginalString); extension = string.IsNullOrEmpty(extension) ? \".png\" : extension; var fileName = $\"word-image-{Guid.NewGuid()}{extension}\"; // 2. 保存图片到服务器 var imagePath = Path.Combine(uploadPath, fileName); using (var fileStream = new FileStream(imagePath, FileMode.Create)) { await imagePart.GetData().CopyToAsync(fileStream); } // 3. 在HTML中替换图片引用(简化版) // 实际需要解析文档中的图片关系ID并替换 htmlBuilder.Replace($\"[IMAGE_{imageIndex}]\", $\"\"); imageIndex++; }}第四章:前后端联调——魔法与现实的碰撞
4.1 前端调用后端接口
在Vue组件中添加导入按钮:
methods: { async importWord() { try { // 1. 触发文件选择 const fileInput = this.$refs.fileInput; fileInput.click(); fileInput.onchange = async (e) => { const file = e.target.files[0]; if (!file) return; // 2. 显示加载状态 this.$refs.ueditor.editor.execCommand(\'insertHtml\', \'正在导入Word文档...\'); // 3. 上传并转换 const formData = new FormData(); formData.append(\'file\', file); const response = await fetch(\'/api/word/convert\', { method: \'POST\', body: formData }); const html = await response.text(); this.$refs.ueditor.editor.setContent(html); }; } catch (error) { console.error(\'导入失败:\', error); this.$message.error(\'Word导入失败\'); } }}4.2 样式冲突大作战
Word生成的HTML带有大量内联样式,与UEditor默认样式冲突严重。解决方案:
- CSS重置:
/* 在UEditor的css中添加 */.word-import-content * { all: initial; /* 核武器级重置 */}.word-import-content p { margin: 1em 0; /* 保留段落间距 */}.word-import-content strong { font-weight: bold;}.word-import-content em { font-style: italic;}- 后端样式过滤:
// 在转换时清理样式private string CleanStyles(string html){ var doc = new HtmlAgilityPack.HtmlDocument(); doc.LoadHtml(html); // 移除所有style属性(保留特定样式) var nodes = doc.DocumentNode.SelectNodes(\"//[@style]\"); if (nodes != null) { foreach (var node in nodes) { // 保留字体相关的简单样式 var style = node.GetAttributeValue(\"style\", \"\"); if (!string.IsNullOrEmpty(style)) { // 简单示例:只保留font-family和color var newStyle = new StringBuilder(); if (style.Contains(\"font-family\")) { newStyle.Append(\"font-family: \"); // 提取font-family值(简化版) var match = Regex.Match(style, @\"font-family\\s*:\\s*([^;]+)\"); if (match.Success) { newStyle.Append(match.Groups[1].Value.Trim()); } newStyle.Append(\"; \"); } if (style.Contains(\"color\")) { newStyle.Append(\"color: \"); var match = Regex.Match(style, @\"color\\s*:\\s*([^;]+)\"); if (match.Success) { newStyle.Append(match.Groups[1].Value.Trim()); } } if (newStyle.Length > 0) { node.SetAttributeValue(\"style\", newStyle.ToString().Trim()); } else { node.Attributes.Remove(\"style\"); } } } } using (var writer = new StringWriter()) { doc.Save(writer); return writer.ToString(); }}第五章:数据库设计——给HTML找个SQL Server的家
5.1 简单方案
CREATE TABLE Article ( Id INT IDENTITY(1,1) PRIMARY KEY, Title NVARCHAR(200) NOT NULL, Content NVARCHAR(MAX) NOT NULL, -- 直接存HTML CreateTime DATETIME DEFAULT GETDATE());5.2 高级方案(带图片管理)
CREATE TABLE Article ( Id INT IDENTITY(1,1) PRIMARY KEY, Title NVARCHAR(200) NOT NULL, Content NVARCHAR(MAX) NOT NULL, HtmlFilePath NVARCHAR(500), -- 大内容存文件路径 WordSourcePath NVARCHAR(500), -- 原始Word路径 CreateTime DATETIME DEFAULT GETDATE());CREATE TABLE ArticleImage ( Id INT IDENTITY(1,1) PRIMARY KEY, ArticleId INT NOT NULL, ImageUrl NVARCHAR(500) NOT NULL, AltText NVARCHAR(200), SortOrder INT DEFAULT 0, FOREIGN KEY (ArticleId) REFERENCES Article(Id));第六章:最终胜利与经验宝典
经过三周的奋战,项目终于上线。现在回想起来,关键点有:
-
技术选型:
- 前端:Vue2 + vue-ueditor-wrap
- 后端:ASP.NET Core + Open XML SDK
- 数据库:SQL Server 2019
- 构建工具:.NET CLI + webpack
-
避坑指南:
- 不要试图完美还原Word所有样式(特别是表格和页眉页脚)
- 图片处理要尽早考虑存储方案(推荐使用Blob存储或CDN)
- 转换后的HTML一定要做XSS过滤
-
性能优化:
- 大文件分块上传
- 异步处理转换任务
- 使用缓存避免重复转换
现在,当看到用户顺利导入Word文档,格式和图片都完美保留时,那种成就感就像用C#写出了Python的简洁——虽然过程艰辛,但结果甜美!附上完整技术栈图:
前端: Vue2 ↔ UEditor ↔ ASP.NET Core API ↑ ↓ └──── SQL Server ────┘ ↑ ↓ 文件存储 ← Open XML SDK这趟奇幻漂流让我明白:在.NET和Vue的世界里,只要魔法(代码)够强,就没有实现不了的需求!
复制插件目录
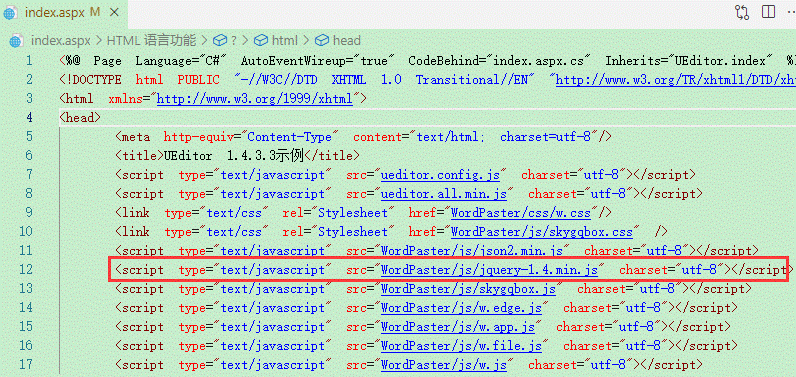
引入插件文件
UEditor 1.4.3.3示例 注意:不要重复引入jquery,如果您的项目已经引入了jq,则不用再引入jq-1.4
在工具栏中增加插件按钮
//工具栏上的所有的功能按钮和下拉框,可以在new编辑器的实例时选择自己需要的重新定义 toolbars: [ [ \"fullscreen\", \"source\", \"|\", \"zycapture\", \"|\", \"wordpaster\",\"importwordtoimg\",\"netpaster\",\"wordimport\",\"excelimport\",\"pptimport\",\"pdfimport\", \"|\", \"importword\",\"exportword\",\"importpdf\" ] ]初始化控件
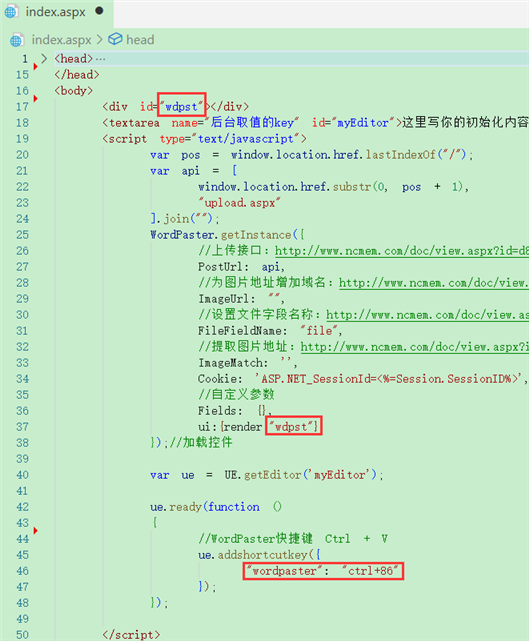
var pos = window.location.href.lastIndexOf(\"/\"); var api = [ window.location.href.substr(0, pos + 1), \"asp/upload.asp\" ].join(\"\"); WordPaster.getInstance({//上传接口:http://www.ncmem.com/doc/view.aspx?id=d88b60a2b0204af1ba62fa66288203ed PostUrl: api,//为图片地址增加域名:http://www.ncmem.com/doc/view.aspx?id=704cd302ebd346b486adf39cf4553936 ImageUrl: \"\", //设置文件字段名称:http://www.ncmem.com/doc/view.aspx?id=c3ad06c2ae31454cb418ceb2b8da7c45 FileFieldName: \"file\", //提取图片地址:http://www.ncmem.com/doc/view.aspx?id=07e3f323d22d4571ad213441ab8530d1 ImageMatch: \'\' });//加载控件注意
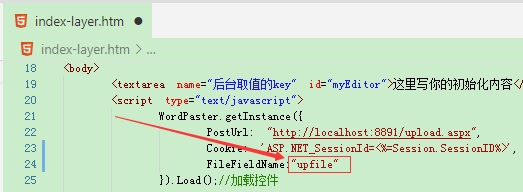
如果接口字段名称不是file,请配置FileFieldName。ueditor接口中使用的upfile字段
点击查看详细教程
配置ImageMatch
匹配图片地址,如果服务器返回的是JSON则需要通过正则匹配
ImageMatch: \'\',点击参考链接
配置ImageUrl
为图片地址增加域名,如果服务器返回的图片地址是相对路径,可通过此属性添加自定义域名。
ImageUrl: \"\",点击查看详细教程
配置SESSION
如果接口有权限验证(登陆验证,SESSION验证),请配置COOKIE。或取消权限验证。
参考:http://www.ncmem.com/doc/view.aspx?id=8602DDBF62374D189725BF17367125F3
粘贴效果

导入效果

下载示例
点击下载完整示例

