python之数据结构与算法篇_python数据结构与算法
一、排序算法
快排,堆排,归并排序详细原理参考这篇这或许是东半球分析十大排序算法最好的一篇文章,下面我将用 Python 快速实现出来。话不多说,Show Me
Code!
- 冒泡排序
def bubble_sort(alist):for i in range(len(alist)-1):for j in range(len(alist)-1-i):if alist[j]>alist[j+1]:alist[j],alist[j+1]=alist[j+1],alist[j]alist=[54,26,93,17,77,31,44,55,20]bubble_sort(alist)print(alist)- 选择排序
def select_sort(alist):for i in range(len(alist)-1):min_index=ifor j in range(i+1,len(alist)):if alist[j]<alist[min_index]:min_index=jif i!=min_index:alist[i],alist[min_index]=alist[min_index],alist[i]alist=[54,26,93,17,77,31,44,55,20]select_sort(alist)print(alist)- 插入排序
def insert_sort(alist):for i in range(1,len(alist)):for j in range(i,0,-1):if alist[j]<alist[j-1]:alist[j],alist[j-1]=alist[j-1],alist[j]else:breakalist=[54,26,93,17,77,31,44,55,20]insert_sort(alist)print(alist)- 希尔排序
# 变换步长(增量)的插入排序->(n ~ n^2,不稳定)def shell_sort(alist):gap=len(alist)//2while gap>=1:for i in range(gap,len(alist)):j=iwhile(j-gap)>=0:if alist[j]<alist[j-gap]:alist[j],alist[j-gap]=alist[j-gap],alist[j]j-=gapelse:breakgap//=2alist=[54,26,93,17,77,31,44,55,20]shell_sort(alist)print(alist)- 归并排序
#分而治之,递归分解/递归合并 (nlogn)def merge_sort(alist):if len(alist)<=1:return alistmid = len(alist)//2left_alist = merge_sort(alist[:mid])right_alist = merge_sort(alist[mid:])return merge(left_alist,right_alist)def merge(left_list,right_list):result=[]j=0i=0while i<len(left_list) and j < len(right_list):if left_list[i]<=right_list[j]:result.append(left_list[i])i+=1else:result.append(right_list[j])j+=1result+=left_list[i:]result+=right_list[j:]return resultalist=[54,26,93,17,77,31,44,55,20]print(merge_sort(alist))- 快速排序
# 有可能列表不能被分成两半。当这种情况发生时,性能降低def quick_sort(alist, start, end):if start>= end:return#基准mark = alist[start]left = startright = endwhile left < right:while left<right and alist[right]>mark:right-=1alist[left]=alist[right]while left<right and alist[left]<mark:left+=1alist[right]=alist[left]alist[right]=markquick_sort(alist,start,left-1)quick_sort(alist,left+1,end)alist=[54,26,93,17,77,31,44,55,20]quick_sort(alist,0,len(alist)-1)print(alist)二、链表算法
- 输出/删除 单链表倒数第 K 个节点
# leetcode 19:快慢双指针class Solution:def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:second = fist = headfor i in range(n): # 第一个指针先走 n 步fist = fist.nextif fist == None: # 如果现在第一个指针已经到头了,那么第一个结点就是要删除的结点。return second.nextwhile fist.next: # 然后同时走,直到第一个指针走到头fist = fist.nextsecond = second.nextsecond.next = second.next.next # 删除相应的结点return head- 有序链表合并
# leetcode 21# 解题思路:合并后的链表仍然是有序的,可以同时遍历两个链表,# 每次选取两个链表中较小值的节点,依次连接起来,就能得到最终的链表class Solution:def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:if not l1 or not l2:return l1 or l2head=cur=ListNode(0)while l1 and l2:if l1.val<l2.val:cur.next=l1l1=l1.nextelse:cur.next=l2l2=l2.nextcur=cur.nextcur.next=l1 or l2return head.next- 链表有环问题
# leetcode 142:判断链表是否有环/定位环入口/环长度,快慢双指针class Solution(object):def detectCycle(self, head):if head is None:returnslow=fast=headhas_cycle=Falsewhile fast and fast.next:slow=slow.nextfast=fast.next.nextif slow==fast:has_cycle=Truebreakif has_cycle:slow_p=headfast_p=fastwhile slow_p !=fast_p:fast_p=fast_P.nextslow_p=slow_p.nextreturn slow_preturn# 环长度slow=slow.nextfast=fast.next.nextlength=1while slow!=fast:slow=slow.nextfast=fast.next.nextlength+=1return length- 使用链表实现大数加法
# leetcode 2class Solution:def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:flag=0root=n=ListNode(0)while l1 or l2 or flag:v1=v2=0if l1:v1=l1.vall1=l1.nextif l2:v2=l2.vall2=l2.nextflag,val=divmod(v1+v2+flag,10)n.next=ListNode(val)n=n.nextreturn root.next- 删除链表中节点,要求时间复杂度为O(1)
# leetcode 237class Solution:def deleteNode(self, node):\"\"\":type node: ListNode:rtype: void Do not return anything, modify node in-place instead.\"\"\"next_node=node.nextnext_nextnode=next_node.nextnode.val=next_node.valnode.next=next_nextnode- 从尾到头打印链表
# 根据栈的特性class Solution:def printListFromTailToHead(self, listNode):if listNode is None:return []sta=list()res=list()while listNode:sta.append(listNode.val)listNode=listNode.nextwhile sta:res.append(sta.pop())return res# 递归class Solution:def printListFromTailToHead(self, listNode):if listNode is None:return []return self.printListFromTailToHead(listNode.next)+[listNode.val]- 反转链表
# leetcode 206class Solution:def reverseList(self, head: ListNode) -> ListNode:pre=None# 不断取出和向后移动头节点,并将头节点连接到新头节点后面while head:next_node=head.nexthead.next=prepre=headhead=next_nodereturn pre- LRU缓存机机制
# leetcode 146:# 字典(哈希)+双端链表class Node(object):def __init__(self, key, val):self.key = keyself.val = valself.next = Noneself.prev = Noneclass LRUCache(object):def __init__(self, capacity):self.dic = {}self.capacity = capacityself.dummy_head = Node(0, 0)self.dummy_tail = Node(0, 0)self.dummy_head.next = self.dummy_tailself.dummy_tail.prev = self.dummy_headdef get(self, key):if key not in self.dic:return -1node = self.dic[key]self.remove(node)self.append(node)return node.valdef put(self, key, value):if key in self.dic:self.remove(self.dic[key])node = Node(key, value)self.append(node)self.dic[key] = nodeif len(self.dic) > self.capacity:head = self.dummy_head.nextself.remove(head)del self.dic[head.key]def append(self, node):tail = self.dummy_tail.prevtail.next = nodenode.prev = tailself.dummy_tail.prev = nodenode.next = self.dummy_taildef remove(self, node):prev = node.prevnext = node.nextprev.next = nextnext.prev = prev三、栈和队列算法
- 以下几个算法原理详解
- 有效的括号
# leetcode 20class Solution:def isValid(self, s: str) -> bool:chars={\'(\':\')\',\'[\':\']\',\'{\':\'}\'}stack=[]for i in s:if i in chars:stack.append(i)else:if not stack or chars[stack.pop()]!=i:return Falsereturn not stack- 用两个栈实现队列
# leetcode 232: 一个栈作为缓存区class MyQueue:def __init__(self):\"\"\"Initialize your data structure here.\"\"\"self.stack1=[]self.stack2=[]def push(self, x: int) -> None:\"\"\"Push element x to the back of queue.\"\"\"self.stack1.append(x)def pop(self) -> int:\"\"\"Removes the element from in front of queue and returns that element.\"\"\"if len(self.stack2)==0:while(self.stack1):self.stack2.append(self.stack1.pop())return self.stack2.pop()def peek(self) -> int:\"\"\"Get the front element.\"\"\"if len(self.stack2)==0:while(self.stack1):self.stack2.append(self.stack1.pop())return self.stack2[-1]def empty(self) -> bool:\"\"\"Returns whether the queue is empty.\"\"\"return not self.stack1 and not self.stack2- 栈的压入、弹出序列
# leetcode 946:借用一个辅助的栈tmp,遍历压栈顺序class Solution:def validateStackSequences(self, pushed: List[int], popped: List[int]) -> bool:tmp=[]while pushed:tmp.append(pushed.pop(0))while tmp and tmp[-1]==popped[0]:popped.pop(0)tmp.pop()return not tmp- 包含 min 函数的栈
# leetcode 155:实际上就是实现最小栈(重点是连续弹出最小值时的问题)class MinStack:def __init__(self):\"\"\"initialize your data structure here.\"\"\"self.stack=[]self.minstack=[]def push(self, x: int) -> None:self.stack.append(x)if self.minstack:self.minstack.append(x)else:if x<self.minstack[-1]:self.minstack.append(x)else:self.minstack.append(self.minstack[-1])def pop(self) -> None:self.stack.pop()self.minstack.pop()def top(self) -> int:return self.stack[-1]def getMin(self) -> int:return self.minstack[-1]- 验证栈序列
# leetcode 946class Solution:def validateStackSequences(self, pushed: List[int], popped: List[int]) -> bool:tmp=[]while pushed:tmp.append(pushed.pop(0))while tmp and tmp[-1]==popped[0]:popped.pop(0)tmp.pop()return not tmp约瑟夫环(双端队列实现)from pythonds.basic.queue import Queuedef hotPotato(namelist,num):simple_queue = Queue()for name in namelist:simple_queue.enqueue(name)while simple_queue.size()>1:for i in range(num):simple_queue.enqueue(simple_queue.dequeue())simple_queue.dequeue()return simple_queue.dequeue()print(hotPotato([\"Bill\",\"David\",\"Susan\",\"Jane\",\"Kent\",\"Brad\"],2))- 合并K个排序链表
# leetcode 23from Queue import PriorityQueueclass Solution(object):def mergeKLists(self, lists):head = point = ListNode(0)q = PriorityQueue()for l in lists:if l:q.put((l.val, l))while not q.empty():val, node = q.get()point.next = ListNode(val)point = point.nextnode = node.nextif node:q.put((node.val, node))return head.next四、二叉树算法
四种遍历方式
- 二叉树的四种遍历方式分别是:前序、中序、后序和层次。它们的时间复杂度都是O(n),其中n是树中节点个数,因为每一个节点在递归的过程中,只访问了一次。
- 三种深度优先遍历方法的空间复杂度是O(h),其中h是二叉树的深度,额外空间是函数递归的调用栈产生的,而不是显示的额外变量。空间复杂度,通常是指完成算法所用的辅助空间的复杂度,而不用管算法前置的空间复杂度。比如在树的遍历算法中,整棵树肯定要占O(n)的空间,n是树中节点的个数。
- 层次遍历的空间复杂度是O(w),其中w是二叉树的宽度(拥有最多节点的层的节点数)。
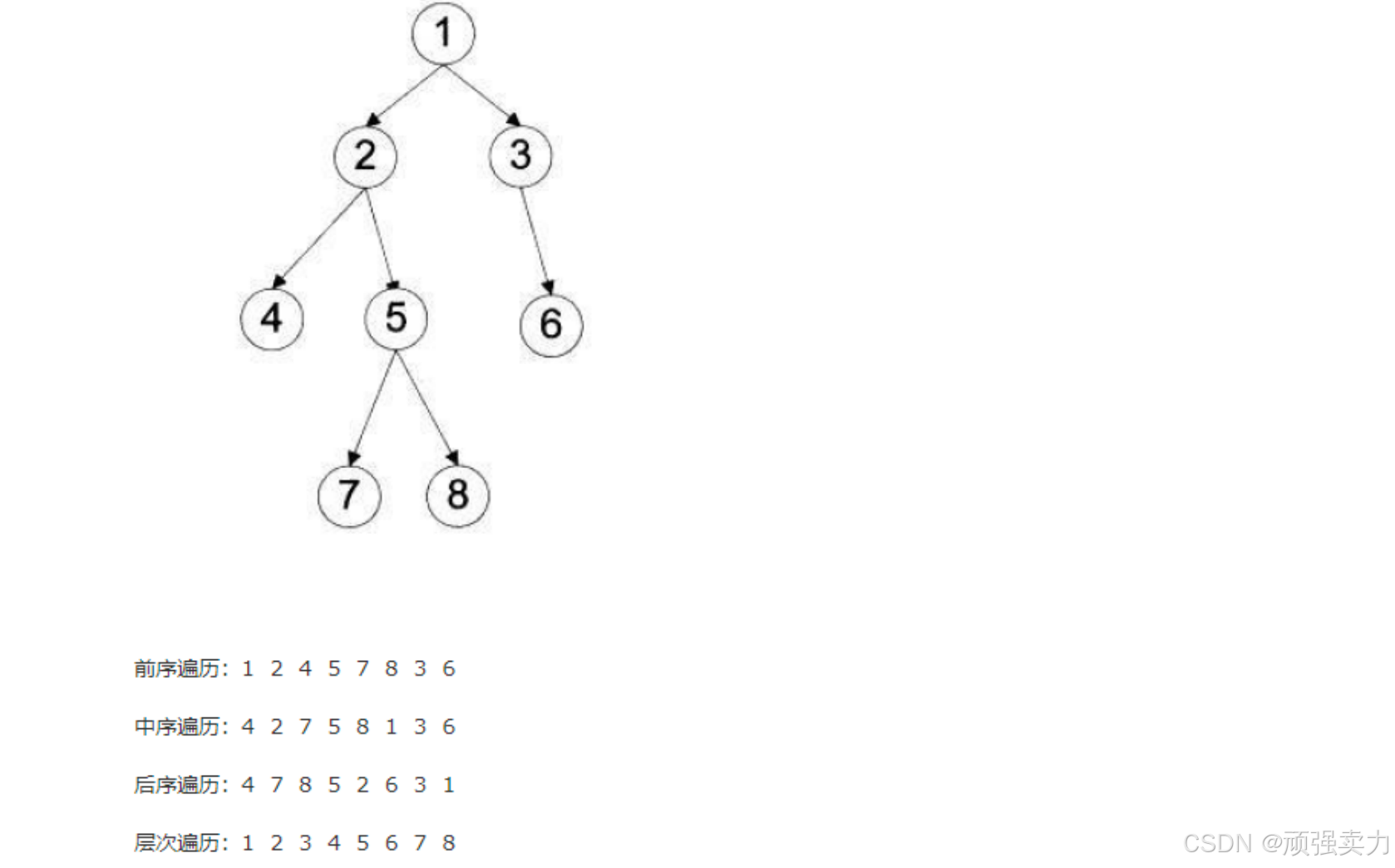
- 前序遍历
# 递归解法class Solution:def preorderTraversal(self, root: TreeNode) -> List[int]:ret=[]if root:ret=ret+[root.val]ret=ret+self.preorderTraversal(root.left)ret=ret+self.preorderTraversal(root.right)return ret# 迭代算法思路:使用栈的思想,从根节点开始以此使用ret添加根节点值,stack添加右节点,# curr=左节点,如果左节点为None,则获取其上一个右节点(一直输出根节点,添加其右节点,# 遍历左节点,右节点的输出顺序为从下往上)class Solution:def preorderTraversal(self, root: TreeNode) -> List[int]:ret=[]if root==None:return retstack=[]curr=rootwhile curr or stack:if curr:ret.append(curr.val)stack.append(curr.right)curr=curr.leftelse:curr=stack.pop()return ret- 中序遍历
# 递归解法同上# 迭代解法class Solution:def inorderTraversal(self, root: TreeNode) -> List[int]:res=[]if root==None:return resstack=[] #添加根节点curr=rootwhile curr or stack:if curr:stack.append(curr)curr=curr.leftelse:curr=stack.pop()res.append(curr.val)curr=curr.rightreturn res- 后序遍历
# 递归解法同上# 迭代算法思路:后序遍历方式为:左右中,将其进行反转 中右左,# 那么我们可以实现一个中右左,其原理与前序遍历一样class Solution:def postorderTraversal(self, root: TreeNode) -> List[int]:ret=[]if root==None:return retstack=[]curr=rootwhile curr or stack:if curr:ret.append(curr.val)stack.append(curr.left)curr=curr.rightelse:curr=stack.pop()return ret[::-1]- 层次遍历
class Solution:def levelOrder(self, root: TreeNode) -> List[List[int]]:level=[root]ret=[]if root==None:return []while level:ret.append([i.val for i in level])level=[kid for node in level for kid in (node.left,node.right) if kid]return ret二叉树中的一些重要属性
- 二叉树的最小深度
class Solution:def minDepth(self, root: TreeNode) -> int:if not root:return 0if root.left==None or root.right==None:return self.minDepth(root.left)+self.minDepth(root.right)+1else:return min(map(self.minDepth,(root.left,root.right)))+1- 二叉树的层平均值
class Solution:def averageOfLevels(self, root: TreeNode) -> List[float]:average=[]if root:level=[root]while level:average.append(sum(i.val for i in level)/len(level))level=[kid for node in level for kid in (node.left,node.right) if kid]return average- 二叉树的直径
- 采用分治和递归的思想:根节点为root的二叉树的直径 = max(root-left的直径, root->right的直径,root->left的最大深度+root->right的最大深度+1)。
- 分两种情况,1,最大直径经过根节点,则直径为左子树最大深度+右子树最大深度 2.如果不经过根节点,则取左子树或右子树的最大深度。
class Solution:def diameterOfBinaryTree(self, root: TreeNode) -> int:self.diameter=0def dfs(root):if root==None:return 0left=dfs(root.left)right=dfs(root.right)self.diameter=max(self.diameter,left+right)return max(left,right)+1dfs(root)return self.diameter- 两个二叉树的最低公共祖先节点
\'\'\' 思路:递归,如果当前节点就是p或q,说明当前节点就是最近的祖先;如果当前节点不是p或p,就试着从左右子树里找pq;如果pq分别在一左一右被找到,那么当前节点还是最近的祖先返回root就好了;否则,返回它们都在的那一边。\'\'\'class Solution:def lowestCommonAncestor(self, root: \'TreeNode\', p: \'TreeNode\', q: \'TreeNode\') -> \'TreeNode\':if root==None:returnif root==p or root==q:return rootleft=self.lowestCommonAncestor(root.left,p,q)right=self.lowestCommonAncestor(root.right,p,q)if left and right:return rootif left:return leftif right:return rightelse:return五、字符串算法
- 最长公共前缀
# leetcode 14class Solution:def longestCommonPrefix(self, strs: List[str]) -> str:temp_str=\"\"zip_obj = zip(*strs)for obj in zip_obj:if(len(set(obj)))>1:breaktemp_str+=obj[0]return temp_str- 最长回文子串
# leetcode 5class Solution:def longestPalindrome(self, s: str) -> str:start=0maxstr=0for i in range(len(s)):if i-maxstr>=1 and s[i-maxstr-1:i+1]==s[i-maxstr-1:i+1][::-1]:start = i-maxstr-1maxstr+=2continueif i-maxstr>=0 and s[i-maxstr:i+1]==s[i-maxstr:i+1][::-1]:start = i-maxstrmaxstr+=1return s[start:start+maxstr]- 无重复字符的最长子串
# leetcode 3 :滑动窗口法class Solution:def lengthOfLongestSubstring(self, s: str) -> int:max_str=0for i in range(len(s)):if len(s[i-max_str:i+1])==len(set(s[i-max_str:i+1])):max_str+=1return max_str六、哈希算法
- 哈希函数特性:确定性、哈希冲突,不可逆性,混淆特性
- 哈希表的 load factor(负载因子),越大表明哈希表中填的元素越多,越容易发生冲突
- 解决哈希冲突:开放寻址法(线性探测、二次探测、双重哈希),链表法
-哈希洪水攻击
- 实现哈希表
class HashMap:def __init__(self):self.size = 11self.slots = [None]*self.sizeself.data = [None]*self.sizedef put(self, key, data):hash_value = self.hash(key, len(self.slots))if self.slots[hash_value] == None:self.slots[hash_value] = keyself.data[hash_value] = dataelse:# 键一样时替换if self.slots[hash_value] == key:self.data[hash_value] = dataelse:# 重新散列,+1线性探测next_slot = self.rehash(hash_value, len(self.slots))while self.slots[next_slot] != None and self.slots[next_slot] != key:next_slot = self.rehash(next_slot, len(self.slots))if self.slots[next_slot] != None:self.slots[next_slot] = keyself.data[next_slot] = dataelse:self.data[next_slot] = datadef get(self, key):start_slot = self.hash(key, len(self.slots))found = Falsedata = Nonestop = Falseposition = start_slotwhile self.slots[position] != None and not stop and not found:if self.slots[position] == key:data = self.data[position]found = Trueelse:position = self.rehash(position,len(self.slots))if position==start_slot:stop = Truereturn datadef hash(self, key, size):return key % sizedef rehash(self, oldhash, size):return (oldhash+1) % sizedef __getitem__(self, key):return self.get(key)def __setitem__(self, key, data):return self.put(key, data)hashmap=HashMap()hashmap[0]=\'cat\'hashmap[1]=\'dog\'hashmap[2]=\'bird\'print(hashmap.slots)print(hashmap.data )- 两数之和
# leetcode 1class Solution:def twoSum(self, nums: List[int], target: int) -> List[int]:#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)# 组合为一个索引序列,同时列出数据和数据下标demo_dict = dict((num,i)for i,num in enumerate(nums))for i,num in enumerate(nums):#get()方法和[key]方法的主要区别在于[key]在遇到不存在的key时会抛出KeyError错j=demo_dict.get(target-num)if j and i!=j:return [i,j]- 三数之和
# leetcode 15class Solution:def threeSum(self, nums: List[int]) -> List[List[int]]:nums.sort()res = []# 排序后遍历for t in range(len(nums)- 2):# 跳过相同的情况if t > 0 and nums[t] == nums[t - 1]:continue# i向后判断,j向前判断i, j = t + 1, len(nums) - 1while i < j:_sum = nums[t] + nums[i] + nums[j]if _sum == 0:res.append([nums[t], nums[i], nums[j]])i += 1j -= 1# 跳过相同的情况while i < j and nums[i] == nums[i - 1]:i += 1while i < j and nums[j] == nums[j + 1]:j -= 1elif _sum < 0:i += 1else:j -= 1return res- 重复的 DNA 序列
# leetcode 187class Solution:def findRepeatedDnaSequences(self, s: str) -> List[str]:res=dict()for i in range(len(s)-9):res[s[i:i+10]]=res.get(s[i:i+10],0)+1return [k for k,v in res.items() if v>=2]- 两个数组的交集
# leetcode 350class Solution:def intersect(self, nums1: List[int], nums2: List[int]) -> List[int]:res=[]num_dict={}for num in nums1:if num not in num_dict:num_dict[num]=1else:num_dict[num]+=1for num in nums2:if num in num_dict and num_dict[num]>0:num_dict[num]-=1res.append(num)return res七、常见算法基本思想
- 回溯
# leetcode 17class Solution(object):def letterCombinations(self, digits):\"\"\":type digits: str:rtype: List[str]\"\"\"if not digits:return []d = {\'2\':\"abc\",\'3\':\"def\",\'4\':\"ghi\",\'5\':\"jkl\",\'6\':\"mno\",\'7\':\"pqrs\",\'8\':\"tuv\",\'9\':\"wxyz\"}res = []self.dfs(d, digits, \"\", res)return resdef dfs(self, d, digits, tmp , res):if not digits:res.append(tmp)else:for num in d[digits[0]]:self.dfs(d, digits[1:], tmp + num, res)- 分而治之
# leetcode 215\'\'\' 任意选定数组内一个数mark,将比其大和比其小的值分别放在左右两个数组里,接着判断两边数字的数量,如果左边的数量大于k个,说明第k大的数字存在于mark及mark左边的区域,对左半区执行partition函数;如果左边的数量小于k个,说明第k大的数字在mark和mark右边的区域之内,对右半区执行partition函数。直到左半区刚好有k-1个数,那么第k大的数就已经找到了。\'\'\'class Solution(object):def findKthLargest(self, nums, k):mark = random.choice(nums)num1,num2=list(),list()for num in nums:if num>mark:num1.append(num)if num<mark:num2.append(num)if k<=len(num1):return self.findKthLargest(num1,k)if k>len(nums)-len(num2):return self.findKthLargest(num2,k-(len(nums)-len(num2)))return mark- 动态规划
#硬币找零# leetcode 322class Solution(object):def coinChange(self, coins, amount):# 建一个长度是 amount + 1的dp数组,构成面额从0到 amount需要使用的最少硬币数量。dp = [0] + [-1] * amountfor x in range(amount):if dp[x] < 0:continuefor c in coins:if x + c > amount:continueif dp[x + c] < 0 or dp[x + c] > dp[x] + 1:dp[x + c] = dp[x] + 1return dp[amount]1. 排序算法
作用:将一组数据按特定顺序(升序/降序)排列,便于后续查找、统计或分析。
常见应用:数据库查询优化、排行榜生成、数据预处理等。
代表算法:快速排序、归并排序、冒泡排序。
2. 链表算法
作用:通过节点间的指针关系高效管理动态数据,支持快速插入、删除操作。
常见应用:实现内存管理、LRU缓存淘汰策略、浏览器历史记录。
代表算法:反转链表、合并有序链表、检测环形链表。
3. 栈和队列
作用:管理数据的“先进后出”(栈)或“先进先出”(队列)操作顺序。
常见应用:函数调用栈、括号匹配校验(栈);消息队列、广度优先搜索(队列)。
4. 二叉树算法
作用:通过树形结构分层组织数据,支持高效查找、插入和遍历。
常见应用:数据库索引(B树)、文件系统目录、决策树模型。
代表算法:二叉搜索树、AVL树、层序遍历。
5. 字符串算法
作用:处理文本匹配、模式识别、压缩或加密等字符串操作。
常见应用:搜索引擎关键词匹配、DNA序列比对、敏感词过滤。
代表算法:KMP算法、正则表达式、字典树(Trie)。
6. 哈希算法
作用:将任意长度数据映射为固定长度的唯一值(哈希值),实现快速查找和数据校验。
常见应用:密码加密存储、分布式系统一致性哈希、数据指纹(如MD5)。
想深入算法与数据结构,解锁大厂面试秘籍?
👉 扫描下方二维码,或知识星球搜索【野生数据分析师】
从零到Offer,带你用算法打开编程思维! 🚀

