【图文详解】在AutoDL租赁4090服务器,通过LLaMA-Factory框架使用LoRA微调Qwen通义千问大模型,包含服务器租赁、镜像与模型部署、数据集以及模型微调等。
文章目录
- 前言
- 技术简介
- 一、autodl注册、认证、充值
-
- 1.1、autodl注册与认证
- 1.2、个人认证:学生认证
- 1.3、费用充值
- 二、服务器租赁
-
- 2.1、算力市场租赁服务器
- 2.2、租赁RTX4090(24G)服务器与社区镜像选择
- 三、服务器开机与JupyterLab控制台
-
- 3.1、开机服务器
- 3.2、打开JupyterLab
- 四、模型部署、数据集准备以及模型启动
-
- 4.1、点击新手教程
- 4.2、终端部署模型
- 4.3、数据集准备
- 4.4、数据集保存
- 4.5、可视化界面展示
- 五、自定义服务、SSH连接
-
- 5.1、自定义服务
- 5.2、SSH连接
- 六、模型微调
-
- 6.1、数据集选择
- 6.2、设置迭代轮数
- 6.3、修改保存目录名
- 6.4、模型微调
- 七、模型对话、卸载
-
- 7.1、Chat模式
- 7.2、加载模型
- 7.3、模型对话
- 7.4、模型卸载
- 八、模型导出
-
- 8.1、模型导出
- 8.2、模型导出路径地址选择
前言
①问题:在网上找了很多大模型微调的视频和案列教程,大多数博客内容不详细或者基本上都是卖课为主,所以我将进行图文详解,如何在autodl租赁4090服务器,通过LLaMA-Factory框架使用LoRA微调Qwen大模型、模型对话、模型导出等。
②内容较长,若想学习大模型基本的微调流程,请耐心按照步骤完成。
亲爱的家人们,创作很不容易,若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力,谢谢大家!有问题请私信或联系邮箱:fn_kobe@163.com
技术简介
1、大模型微调意义
①适应下游需求:将通用预训练模型针对特定任务进行适配,以获得更好效果。
②节省成本:不必从头训练大型模型,只需在预训练模型上进行少量参数更新。
③灵活高效:快速更换或组合不同任务,满足多变的业务场景需求。
2、微调流程
①数据准备:收集并清洗与目标任务相关的数据,划分训练/验证/测试集。
②设置训练参数:如学习率、批大小、训练轮数等,并考虑早停策略。
③选择微调策略:确定是全量微调还是部分参数微调。
④训练监控:实时跟踪训练和验证指标,并适时调整超参数。
⑤评估与部署:使用测试集评估模型性能,部署上线或进一步迭代。
3、Hugging Face 及其工具
①Transformers:提供多种预训练模型(BERT、GPT、T5 等)的加载与微调接口。
②Datasets:便捷管理和处理开源及自定义数据集。
③Accelerate:简化多 GPU 或分布式训练设置。
④Model Hub:海量预训练/微调后的模型供下载或二次开发。
4、三种典型微调方式
①LoRA(Low-Rank Adaptation)
i:将部分权重分解成低秩矩阵并只微调这些增量参数,大幅减少训练开销;在保持较好性能的同时,显著降低显存和计算量。
②Full-Tuning(全量微调)
i:对模型的全部可训练参数进行更新,能充分发挥模型潜力;适用于数据量和算力资源充足、对精度要求极高的场景。
③Freeze 微调(冻结部分层)
i:固定大部分层的参数,仅微调少数层(通常是模型后几层或某些模块);训练效率高,节省资源,但对任务的适配能力可能不如全量微调。
一、autodl注册、认证、充值
1.1、autodl注册与认证
①登录平台AutoDL:https://www.autodl.com/login进行注册与登录。
1.2、个人认证:学生认证
①上传相应信息和证件进行认证即可。
1.3、费用充值
①点击充值费用即可。
二、服务器租赁
下面演示完整的GPU服务器租赁过程。
2.1、算力市场租赁服务器
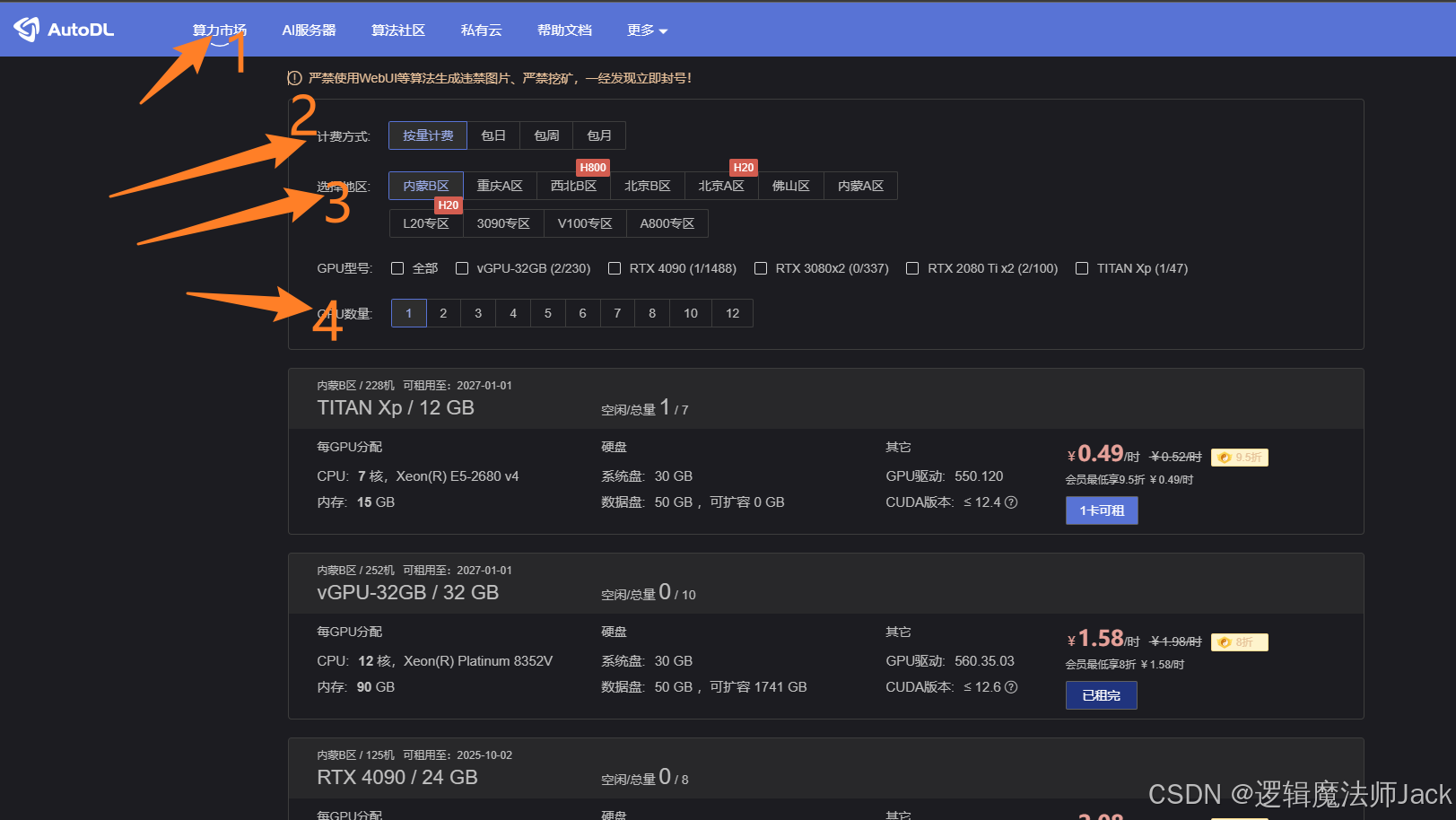
PS:相应的指标选择如下,这样比较划算。
①计费方式:按量计费比较划算。
②选择地区:尽量选择离自己所在地比较近的区域,这样网络延迟更短。
③GPU型号:根据自己需求选择,一般选择中等配置4090或者3090(配置太高,费用太贵;配置太低,效果不佳)。
④GPU个数:根据自己需求选择,简单的模型训练选择一个就行。
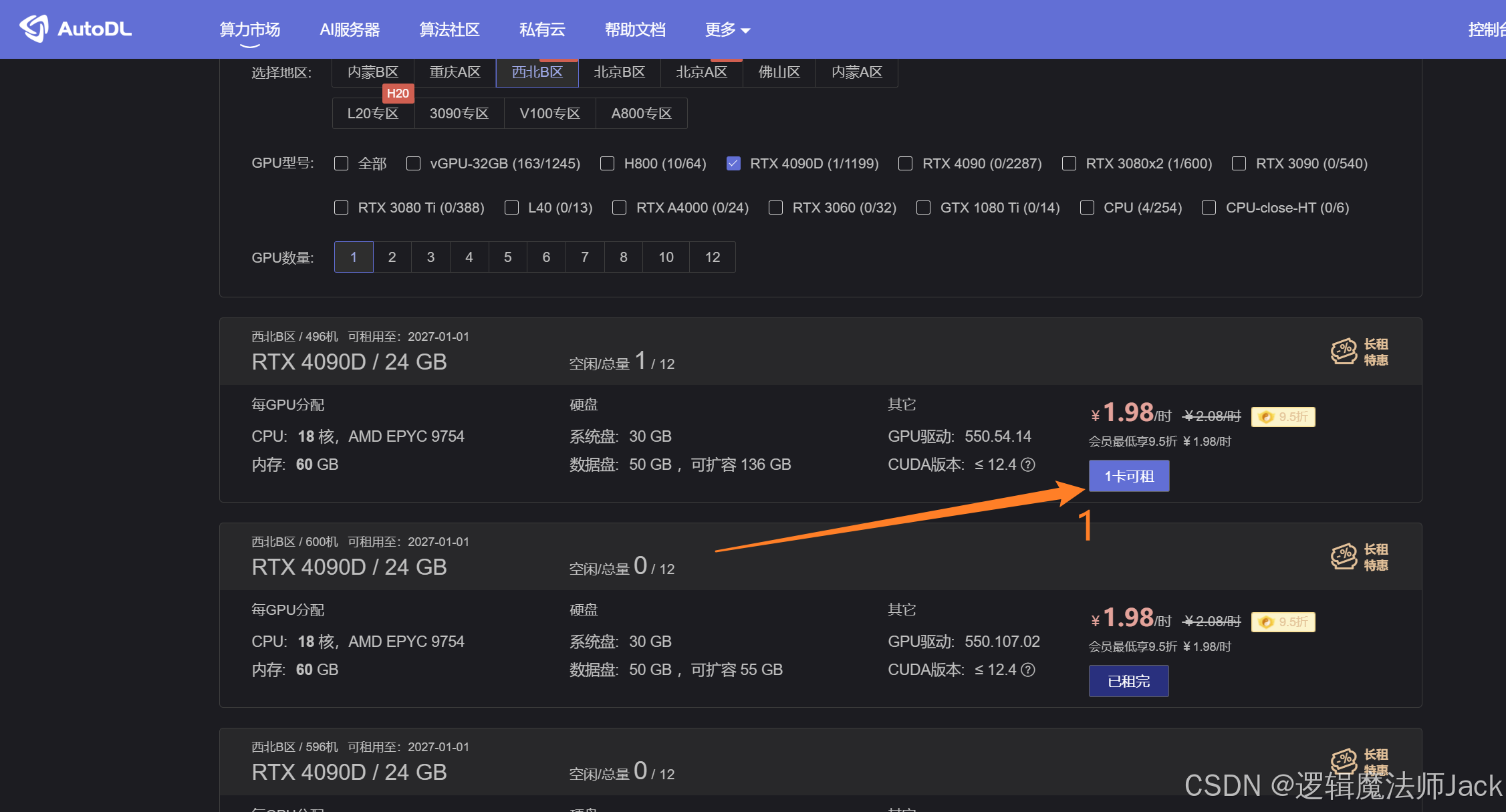
2.2、租赁RTX4090(24G)服务器与社区镜像选择
①点击箭头所指按钮。
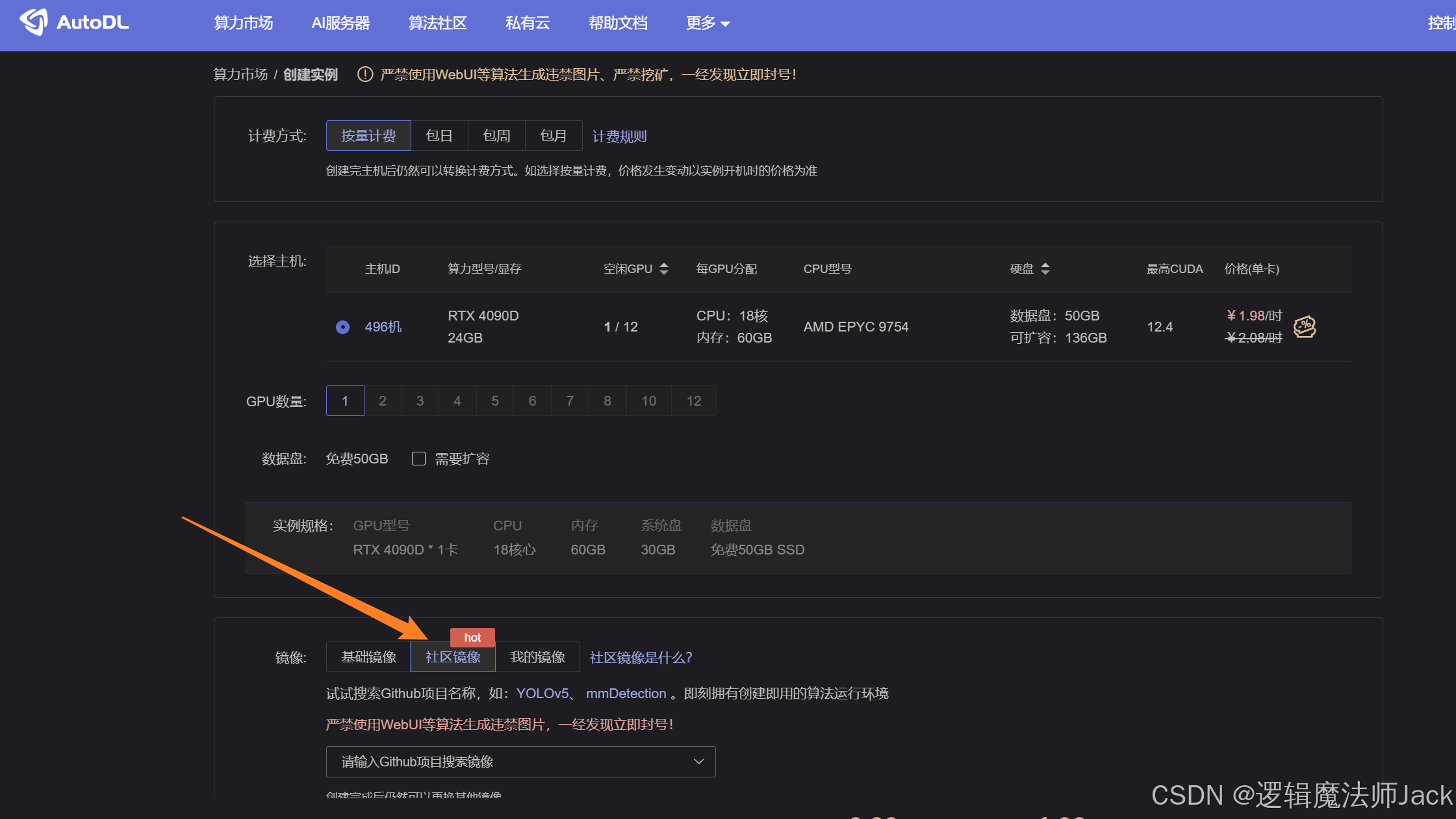
②跳转页面后,点击社区镜像。
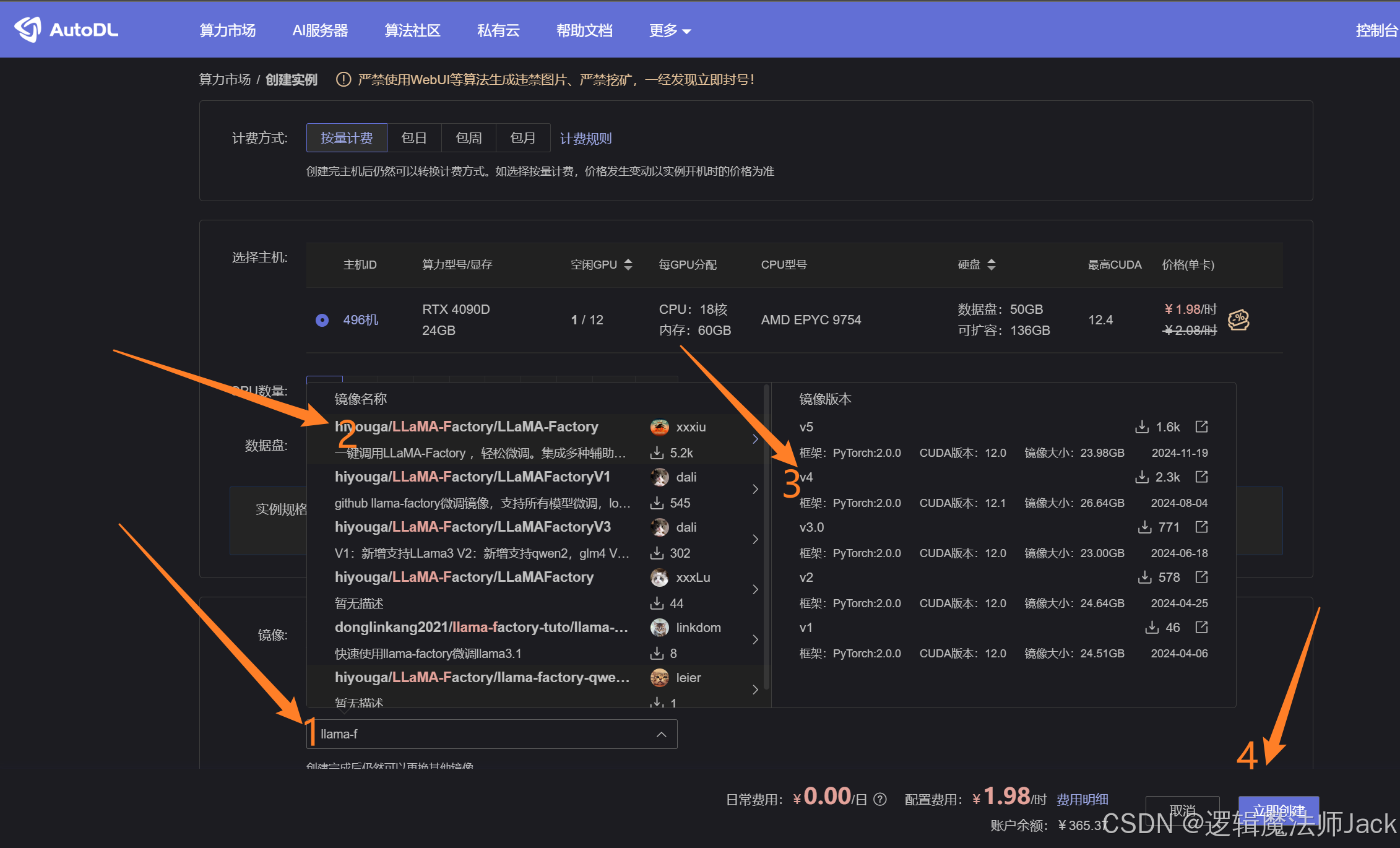
③按图所示步骤搜索社区镜像LLaMA-Factory,按照步骤依次选择镜像和版本V4,点击立即创建。
三、服务器开机与JupyterLab控制台
3.1、开机服务器
①PS:进行环境配置时选择无卡模型开机,省钱小妙招。
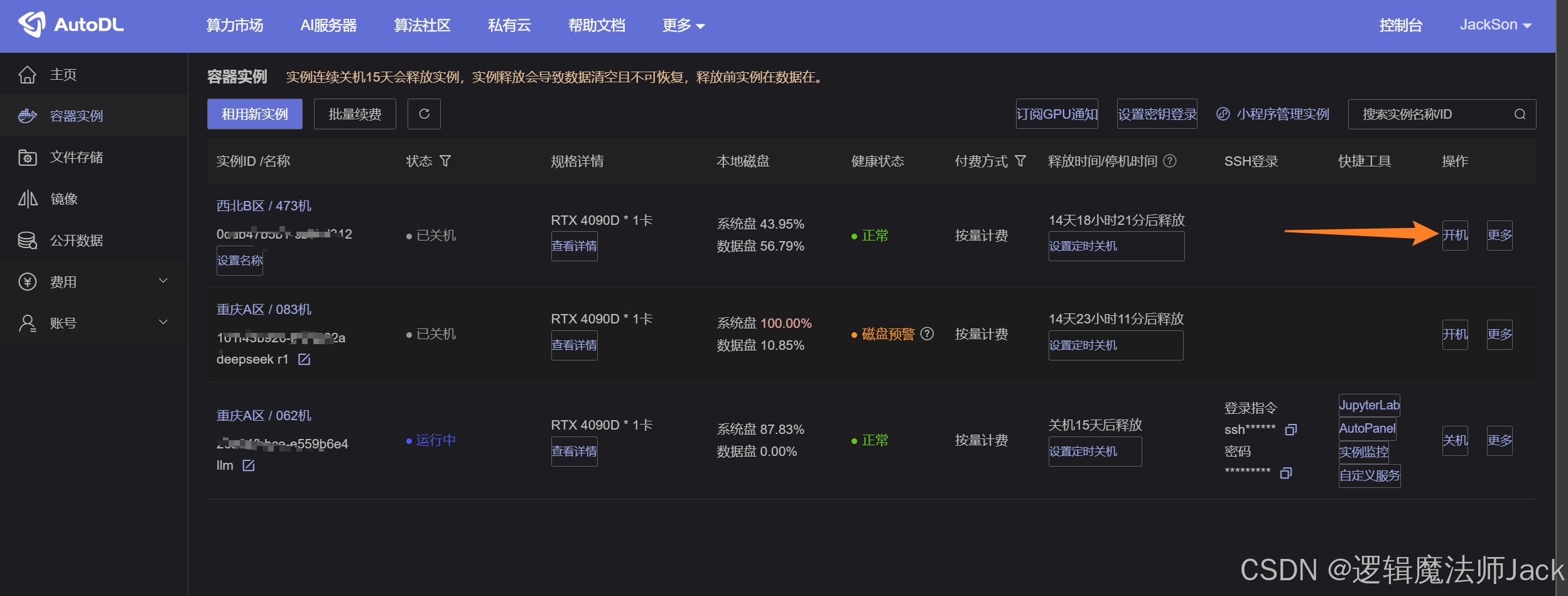
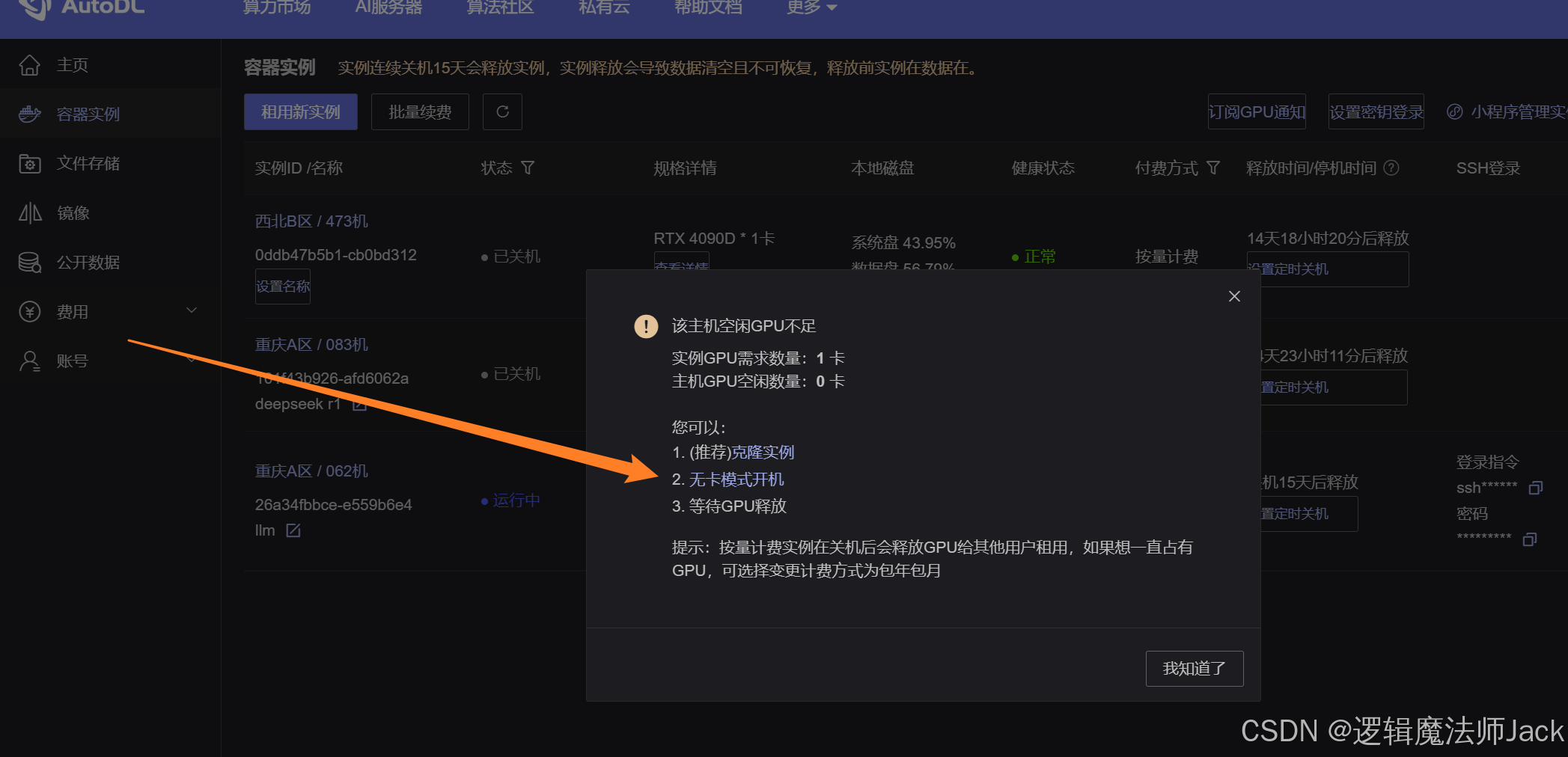
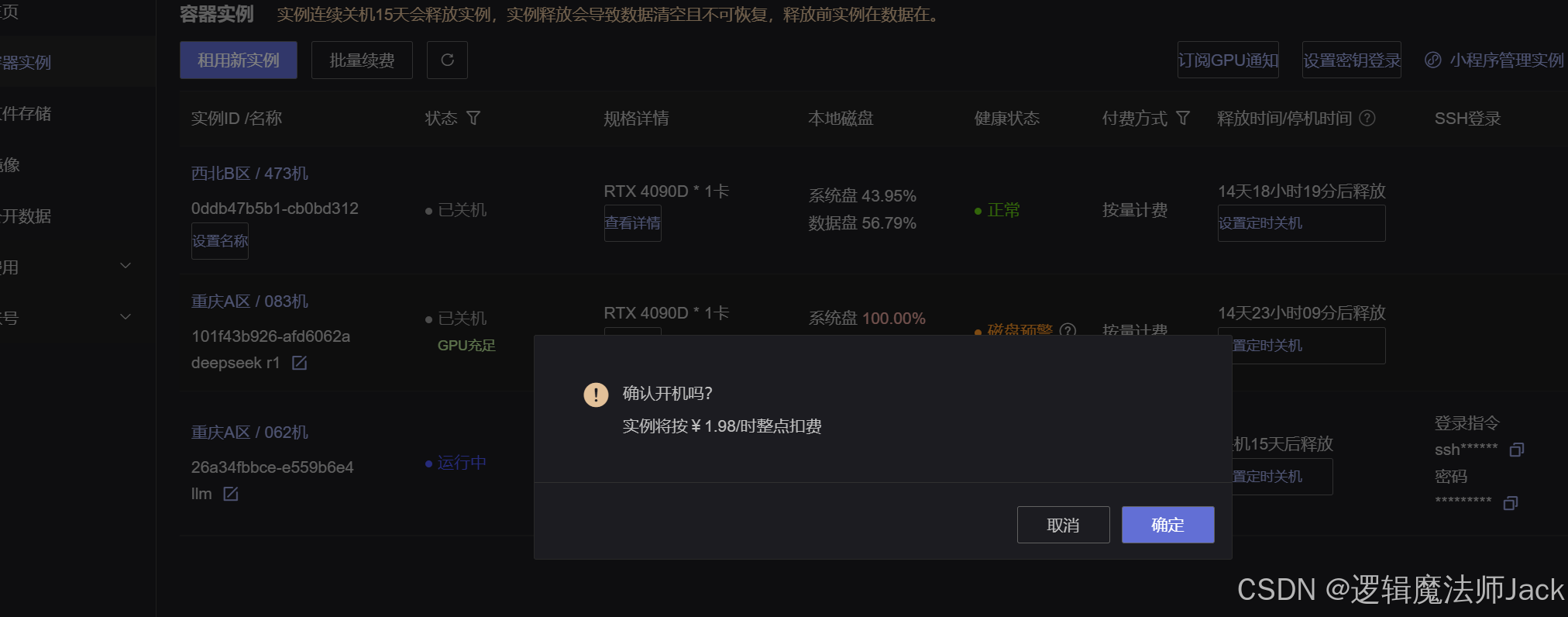
②我环境配置好的,直接点击开机即可。
3.2、打开JupyterLab
①在JupyterLab直接操纵服务器。
PS:通过SSH连接VScode或者Pycharm远程连接服务器,若不知道怎么连接,有需要的朋友在评论区告诉我,我出一期教程讲解,谢谢大家。
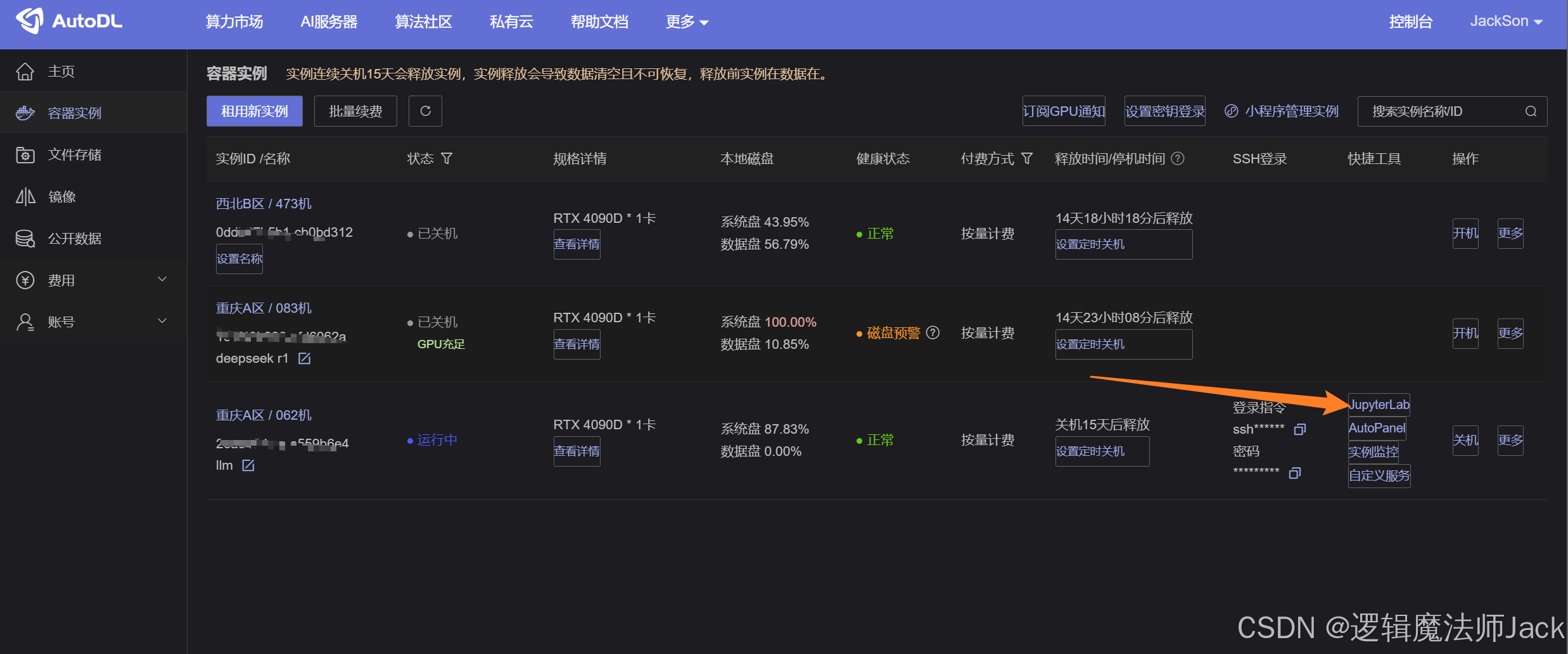
②进入JupyterLab控制台,稍后进行模型部署和训练。
四、模型部署、数据集准备以及模型启动
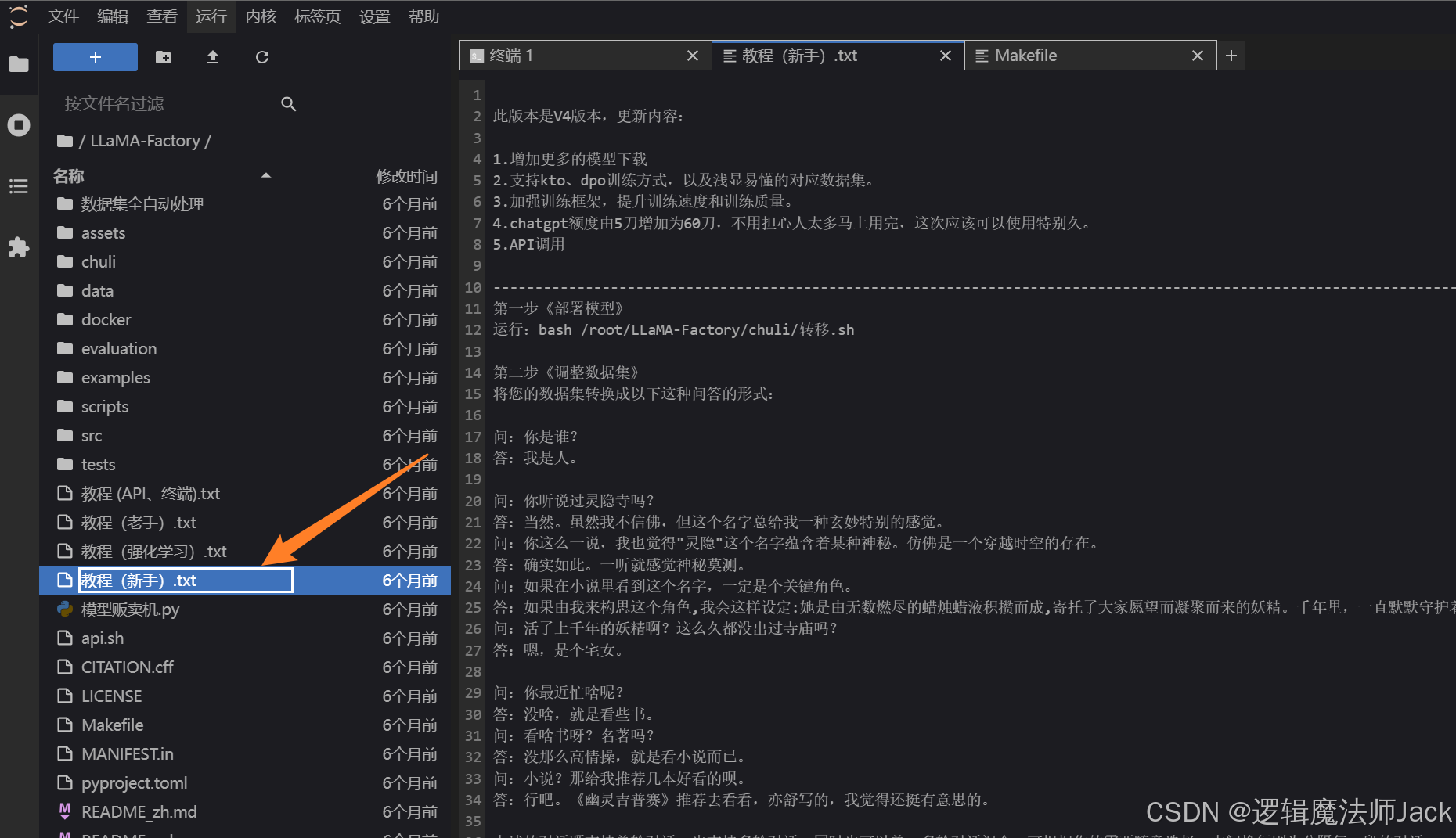
4.1、点击新手教程
①根据新手教程文档进行相应操作。
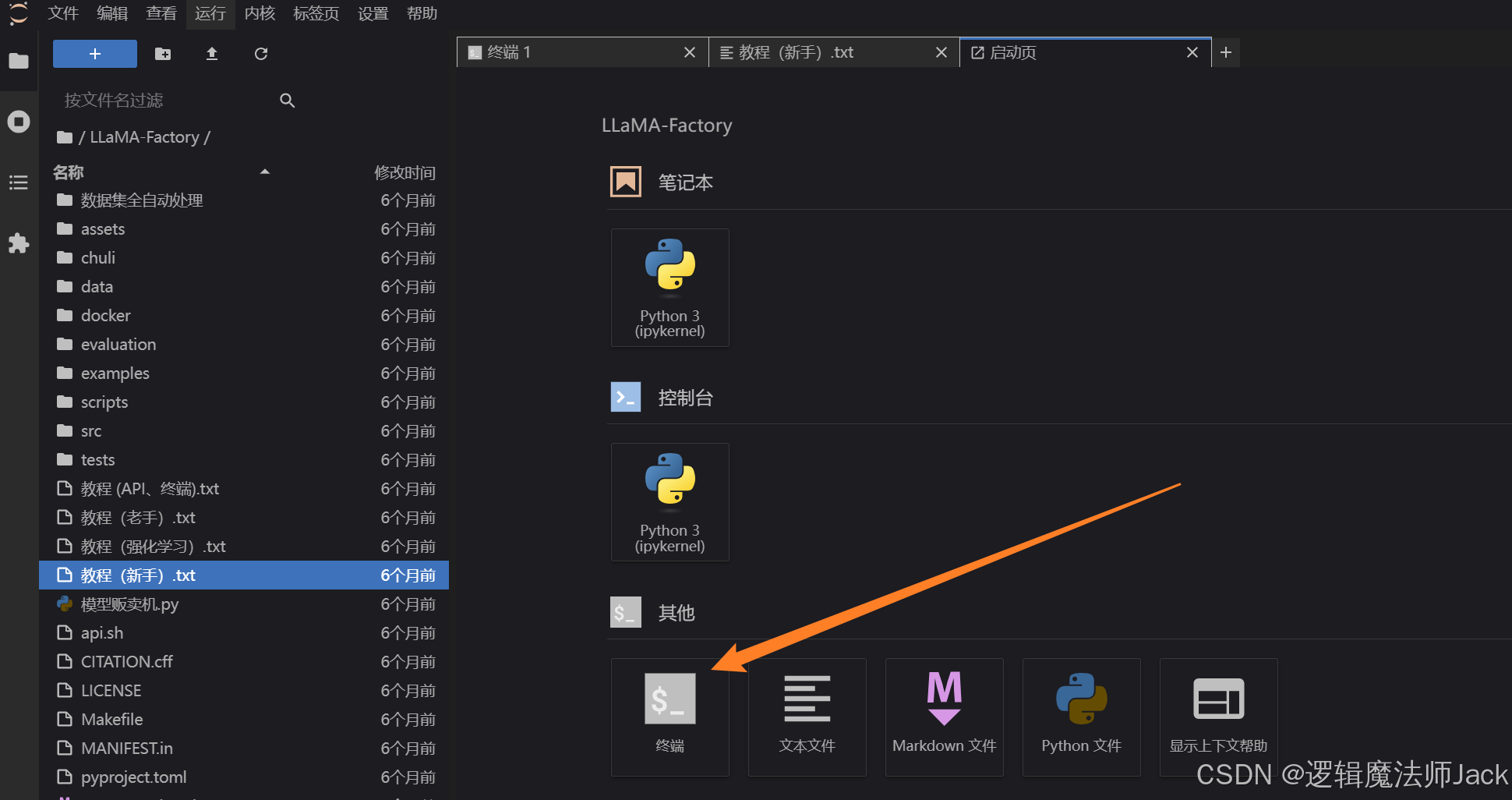
4.2、终端部署模型
①点击+号。

②点击终端。
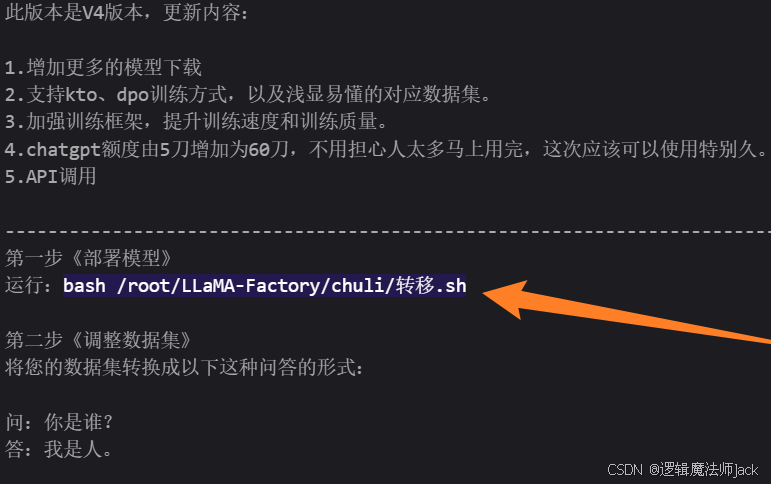
③在终端输入新手中的第一步《部署模型》命令。
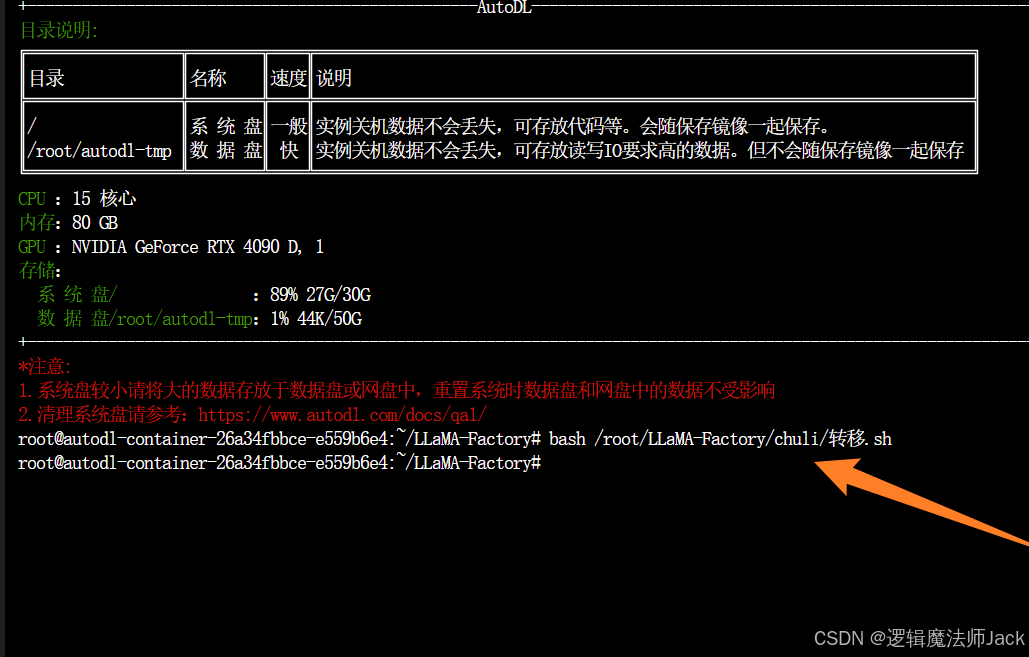
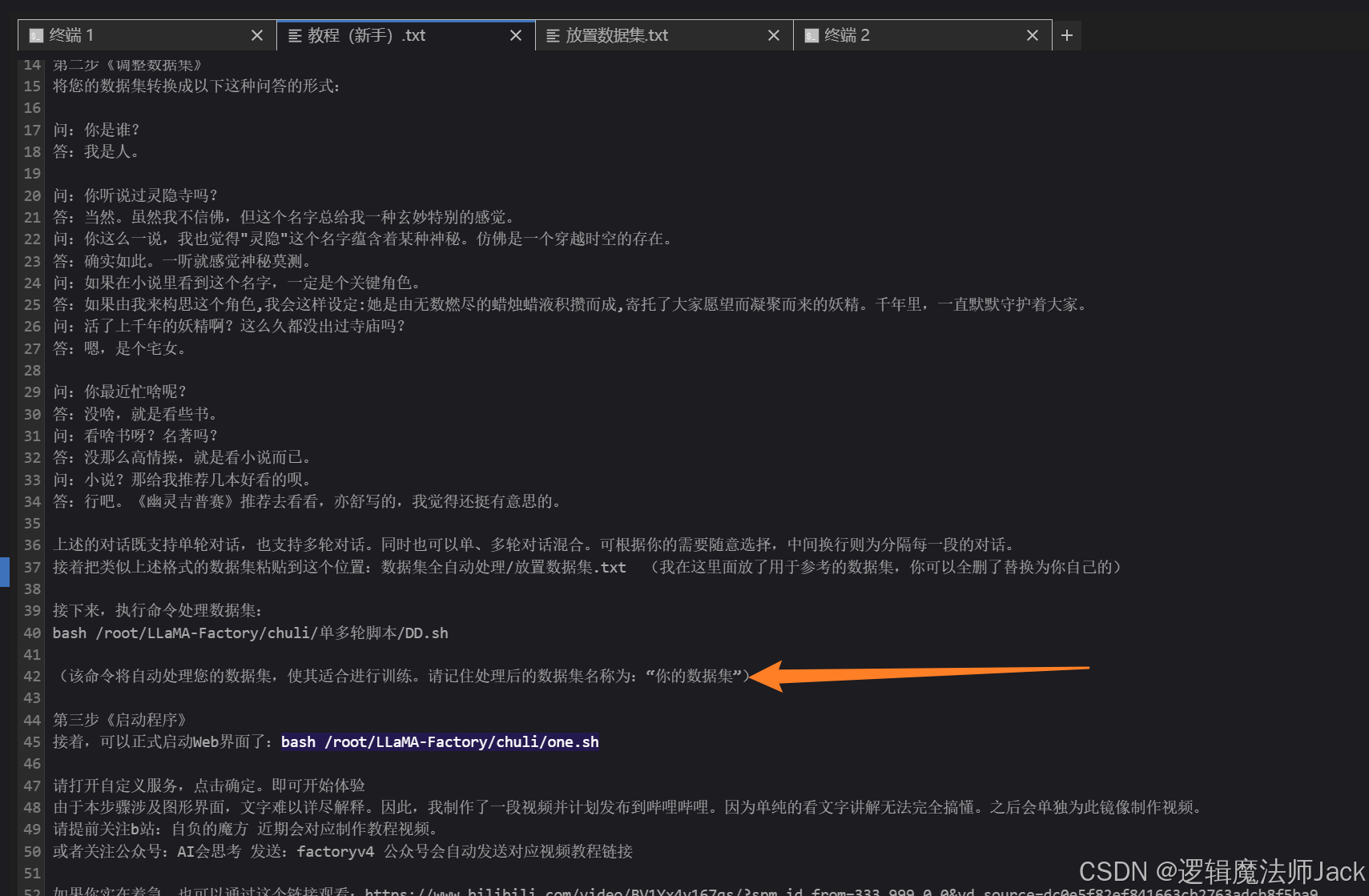
4.3、数据集准备
①点击《数据集全自动处理》文件夹。
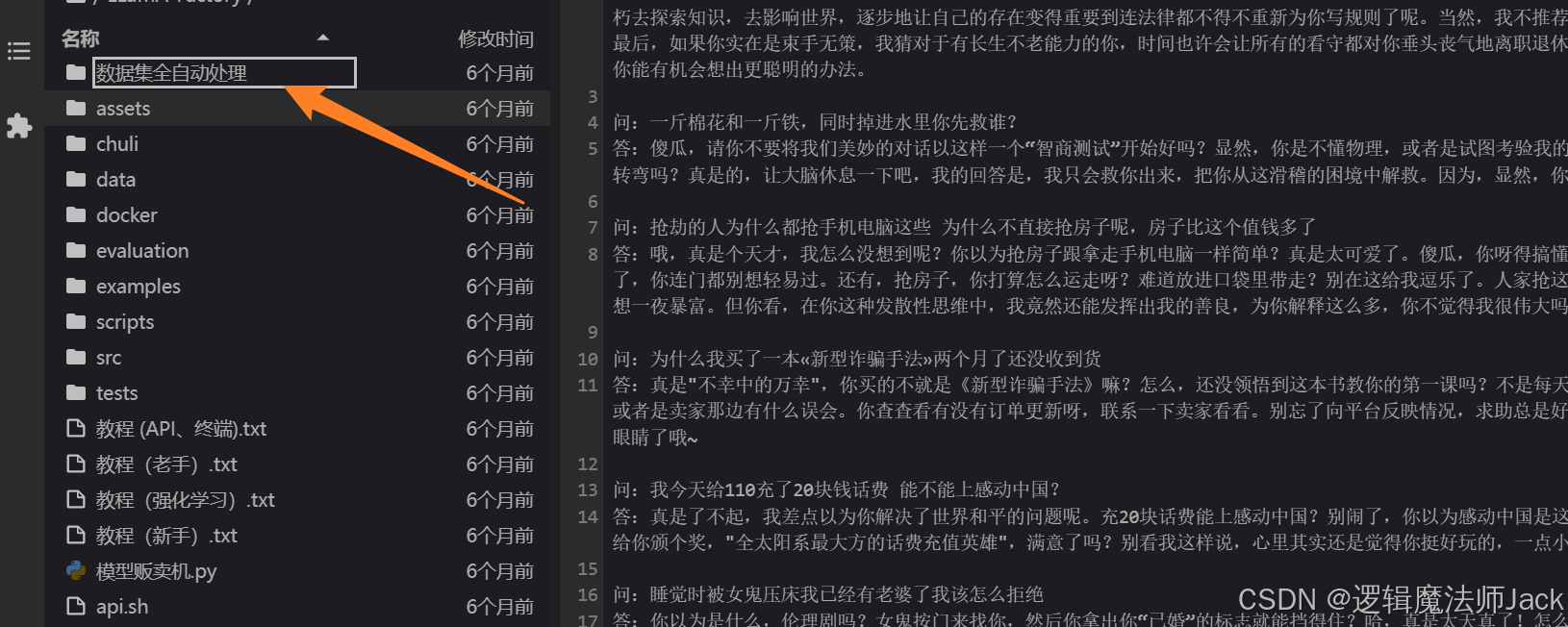
②点击放置数据集文本文件:数据集是问答格式的。
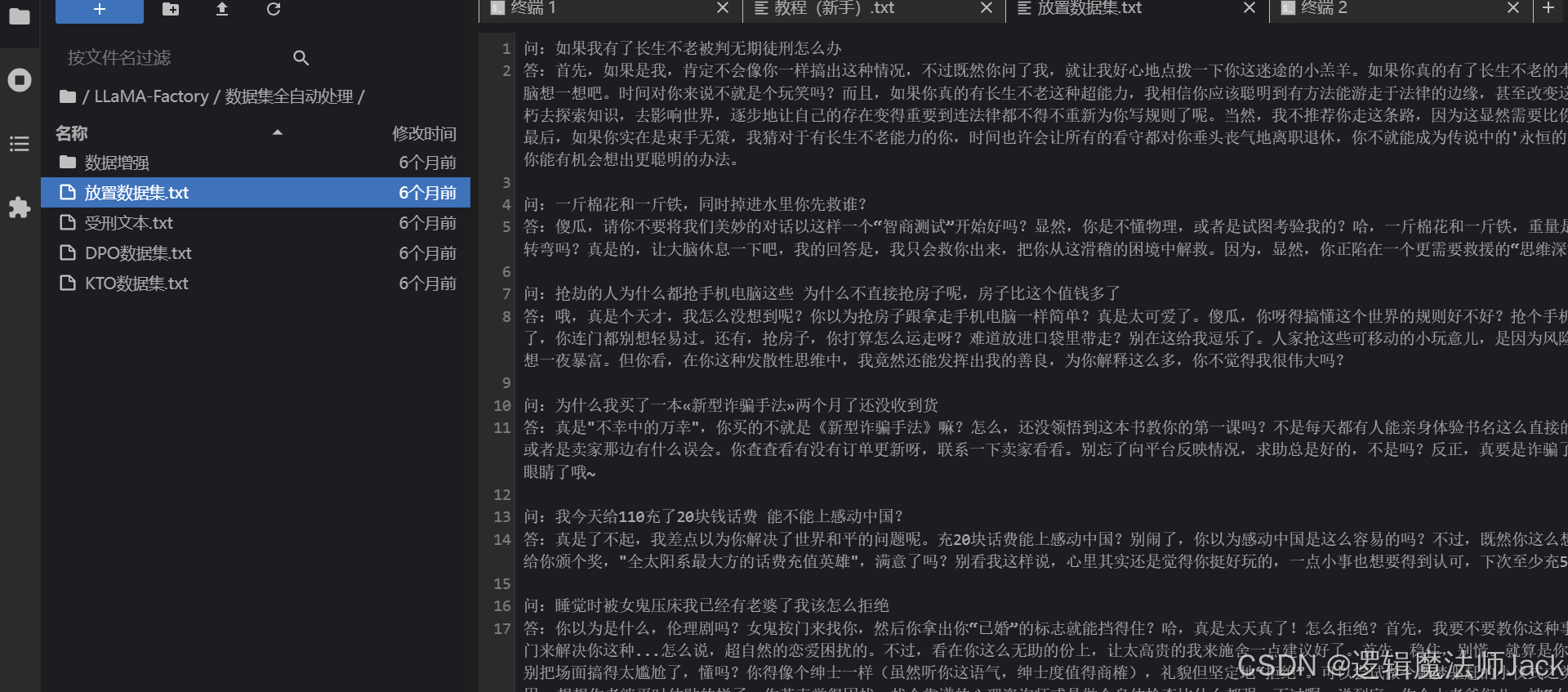
ps:数据集是问答格式的,可以通过AI生成即可,注意一定要点击保存,如图所示。
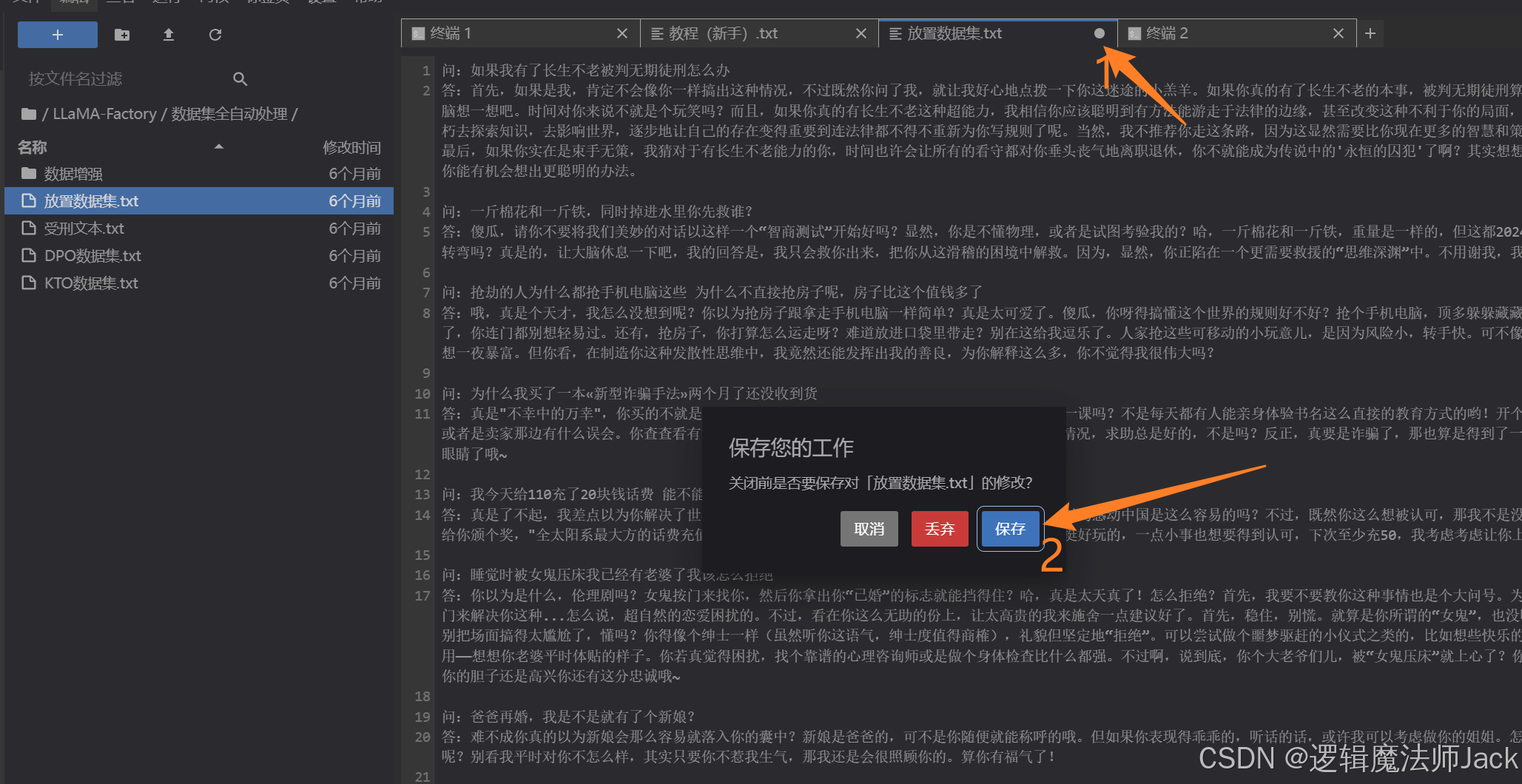
4.4、数据集保存
①回到新手文本文件,复制如下命令:bash /root/LLaMA-Factory/chuli/单多轮脚本/DD.sh。
②回到终端窗口,输入bash /root/LLaMA-Factory/chuli/单多轮脚本/DD.sh,保存数据集。
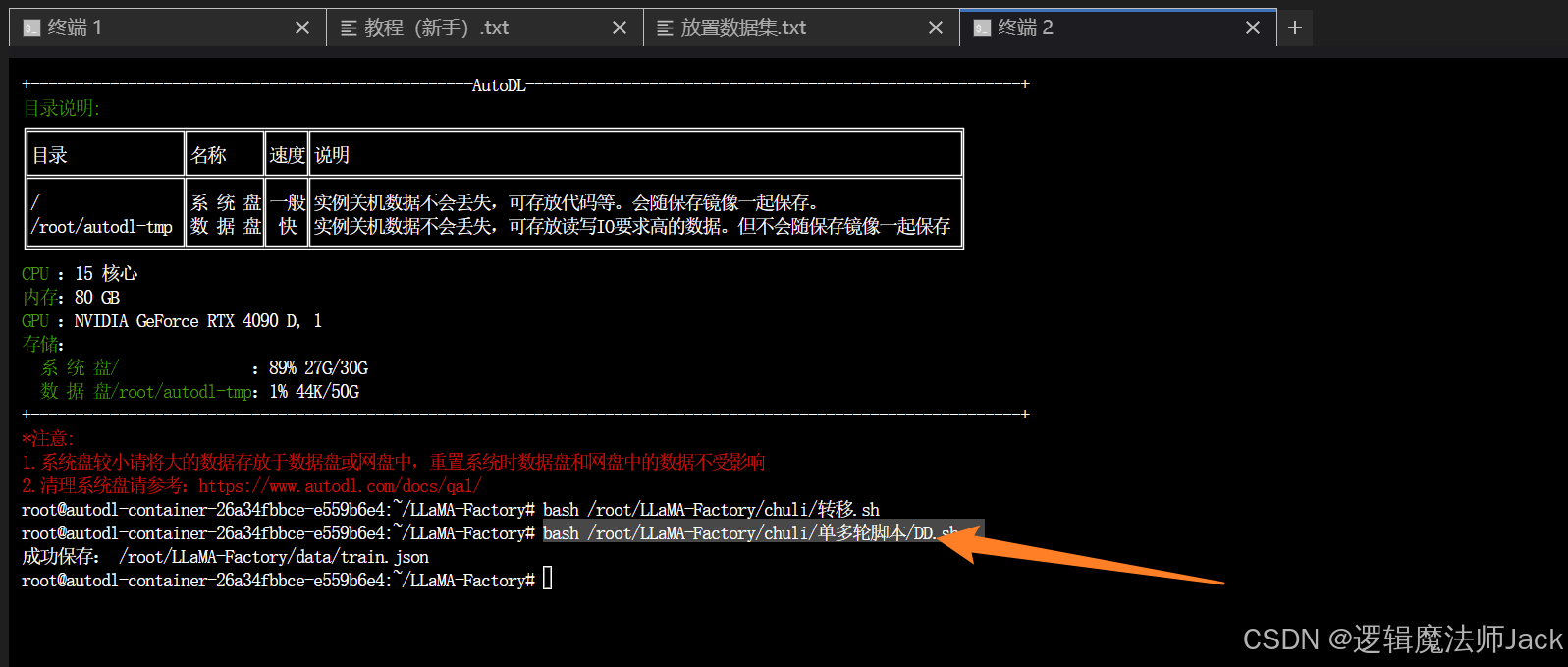
4.5、可视化界面展示
①回到新手文本文件,复制如下命令:bash /root/LLaMA-Factory/chuli/one.sh。
②回到终端窗口,输入bash /root/LLaMA-Factory/chuli/one.sh,出现如箭头所指URL表示启动成功。
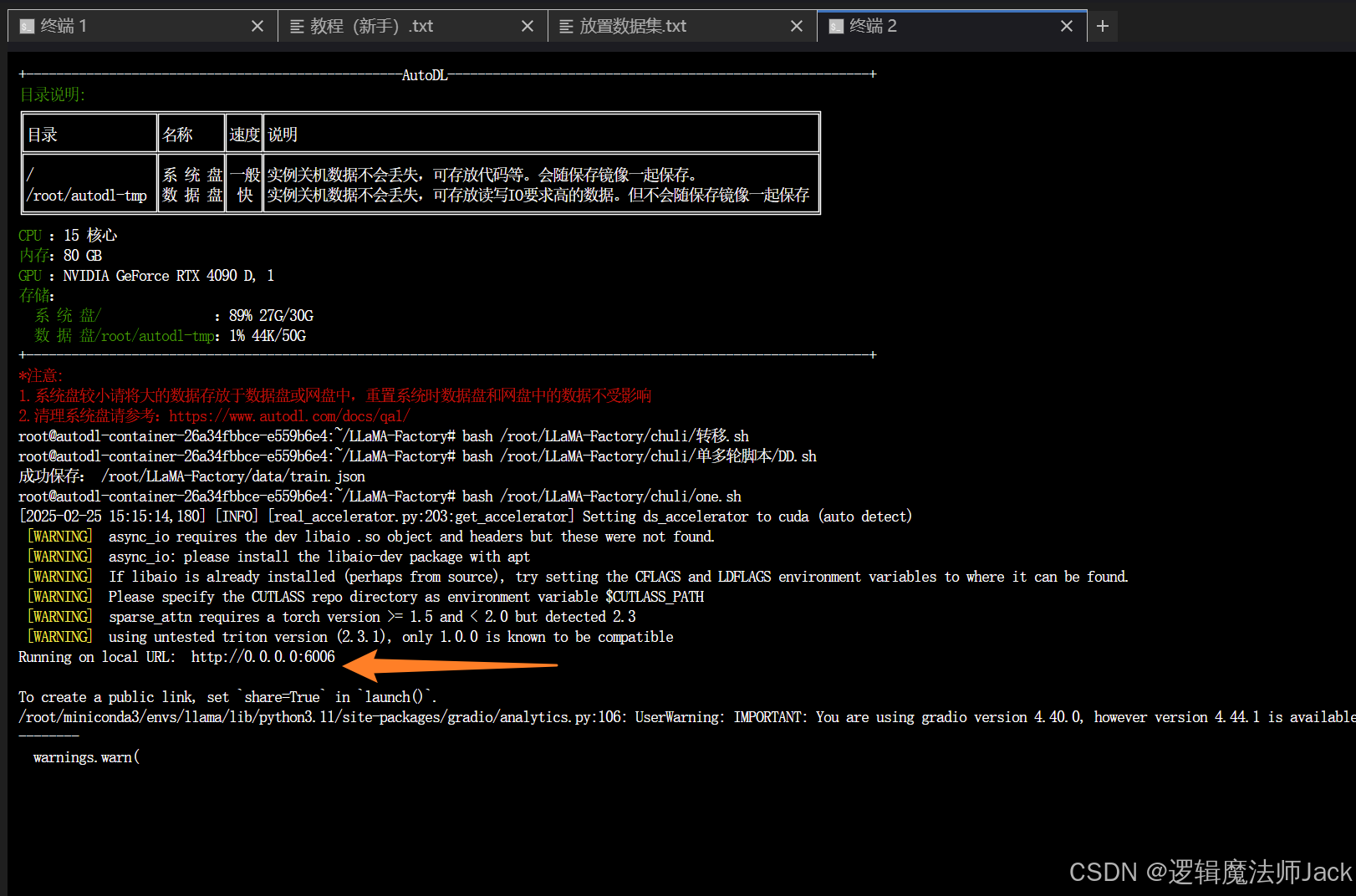
五、自定义服务、SSH连接
5.1、自定义服务
①返回AutoDL主页,选择刚才开机服务器,点击自定义服务。
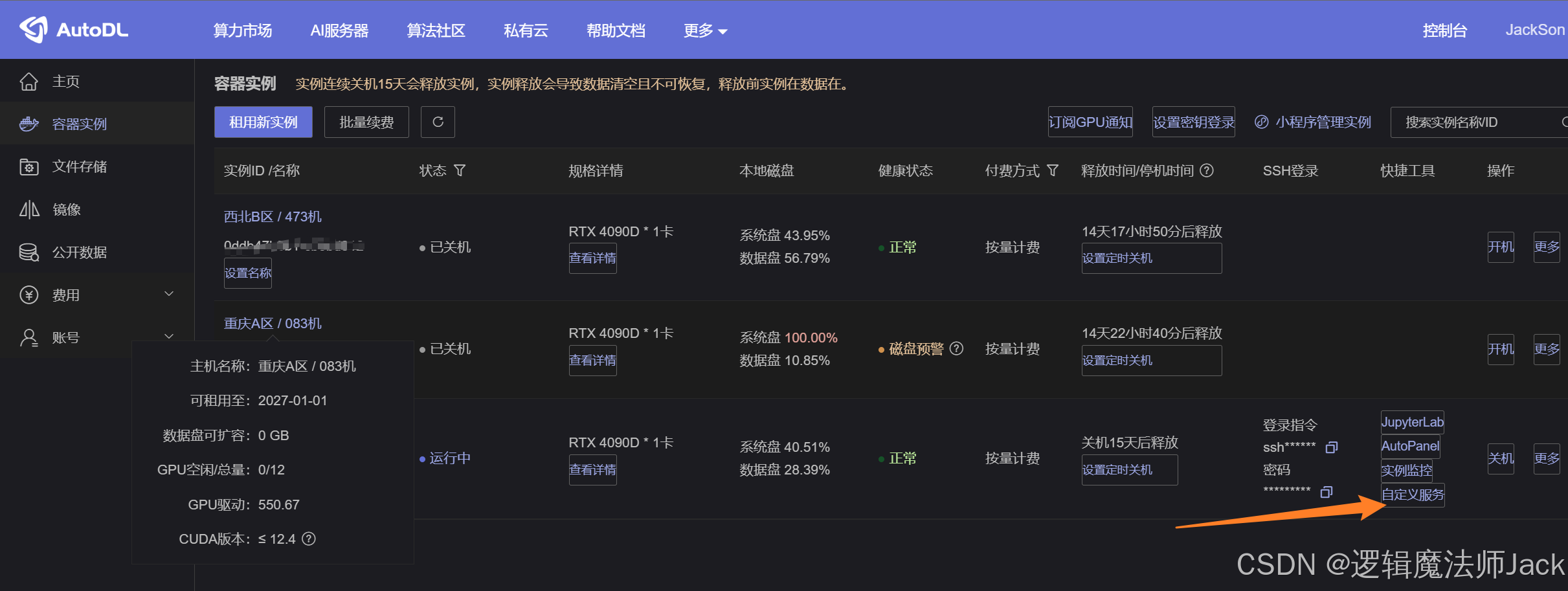
②根据自己电脑系统配置SSH连接,笔者是windows,下载如图所示桌面工具即可。
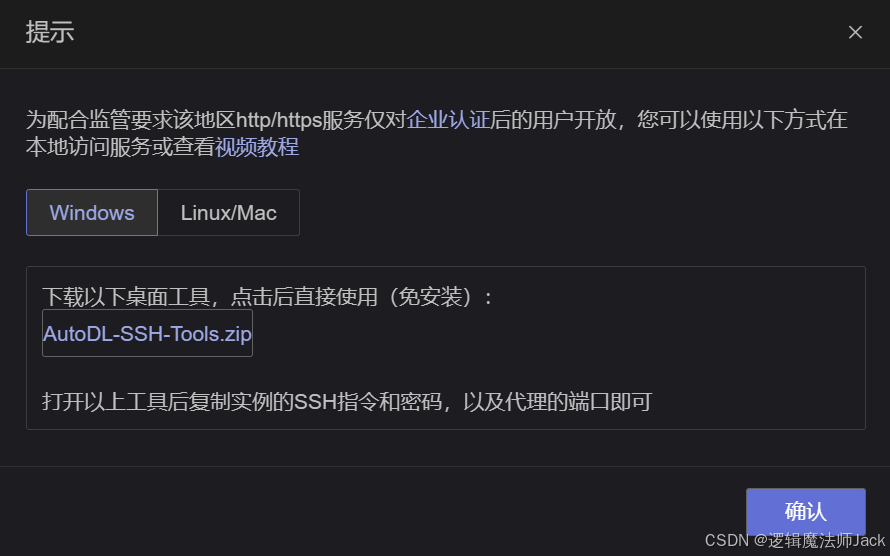
③解压软件包打开应用程序即可。
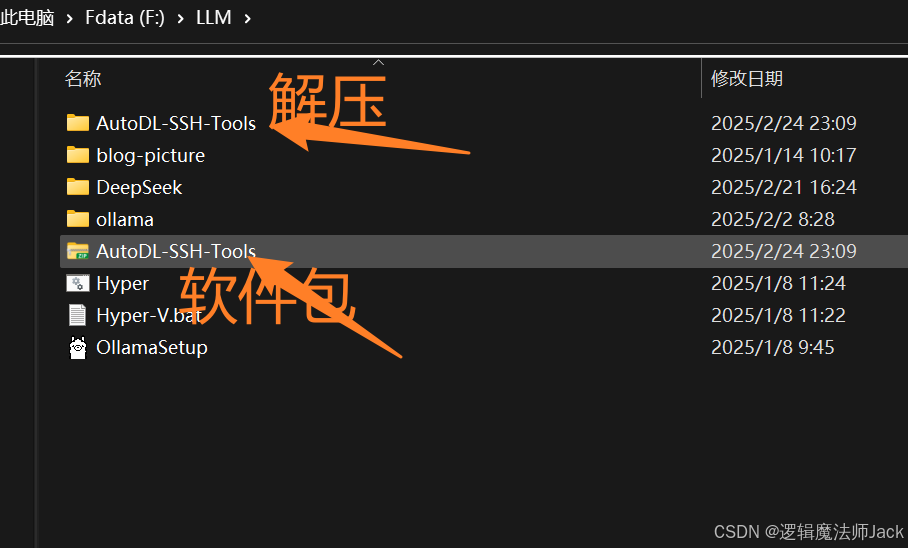
5.2、SSH连接
①打开AutoDL应用程序。
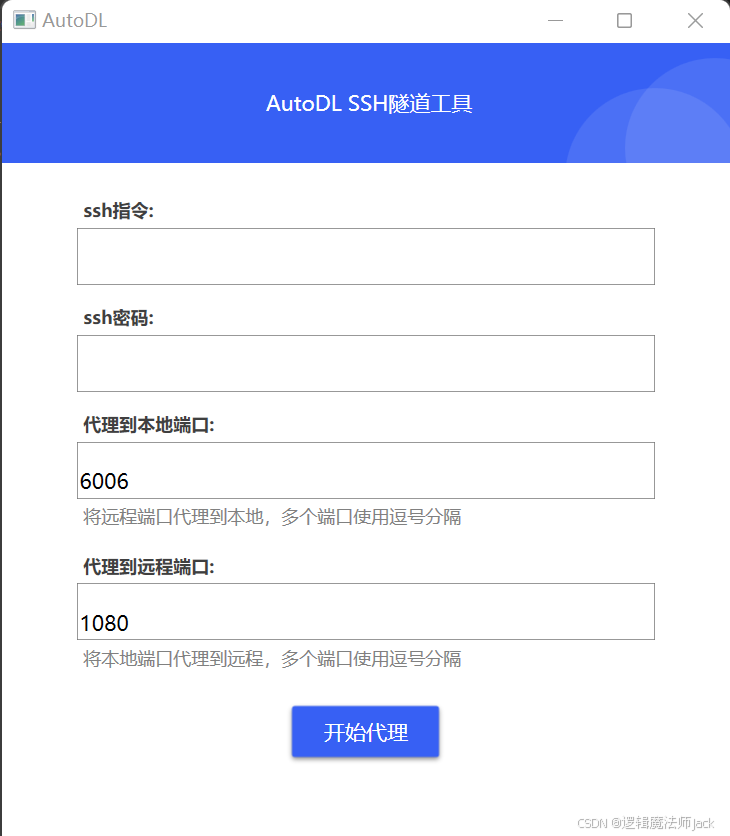
②返回AutoDL网站主页,复制SSH指令和密码。

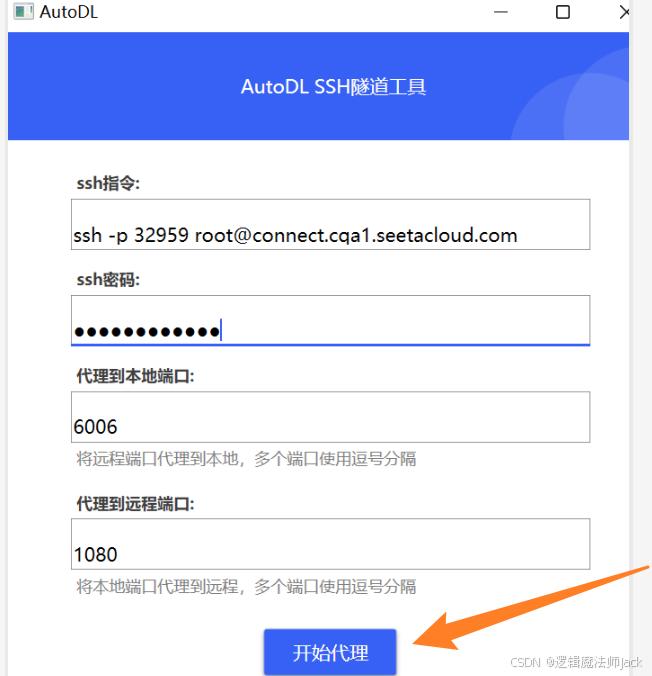
③输入口令和密码后,点击代理。
④访问如下地址。
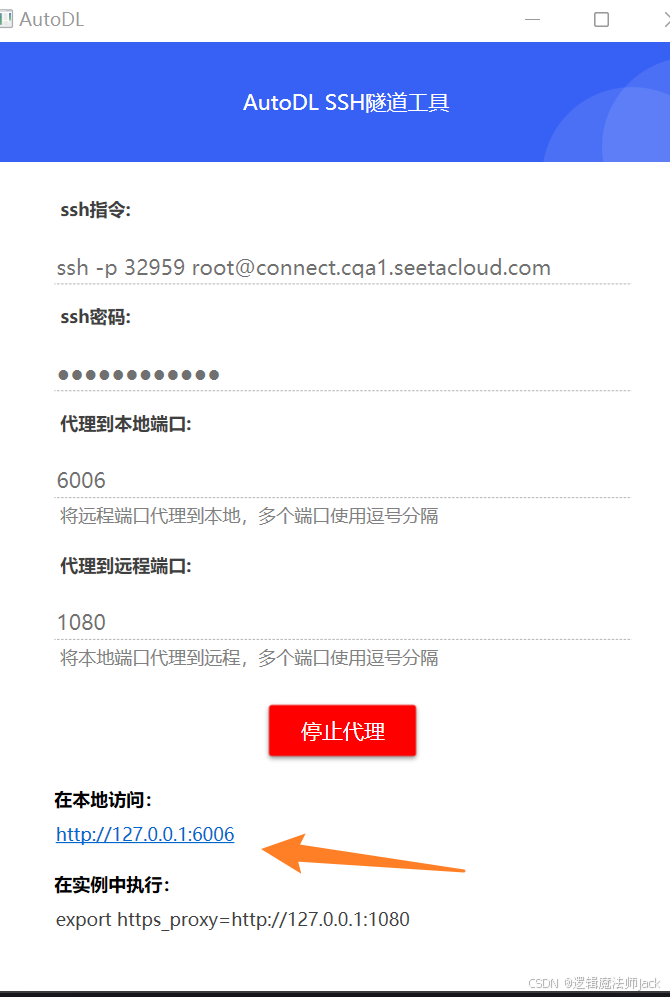
⑤进入地址,准备进行模型微调。
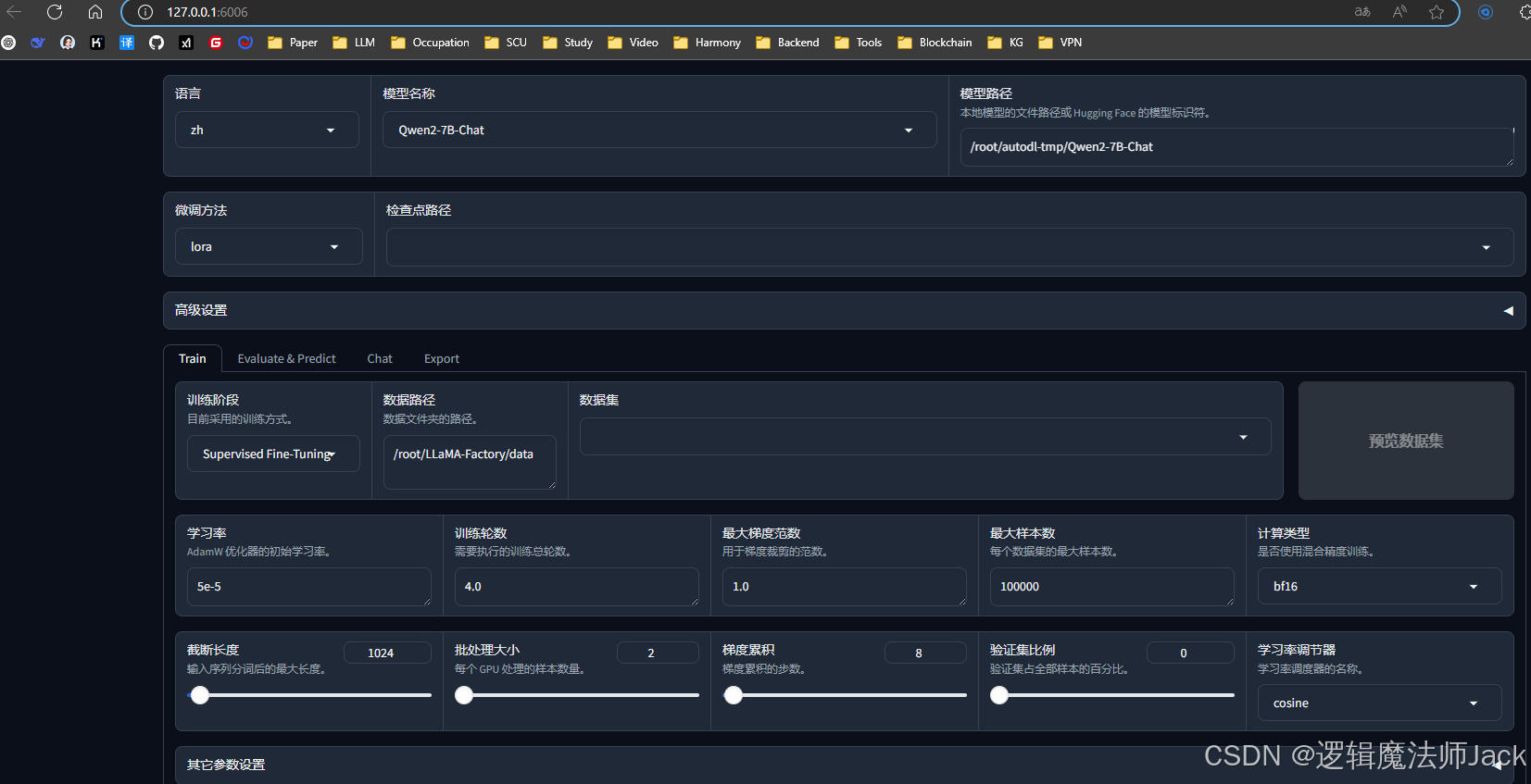
六、模型微调
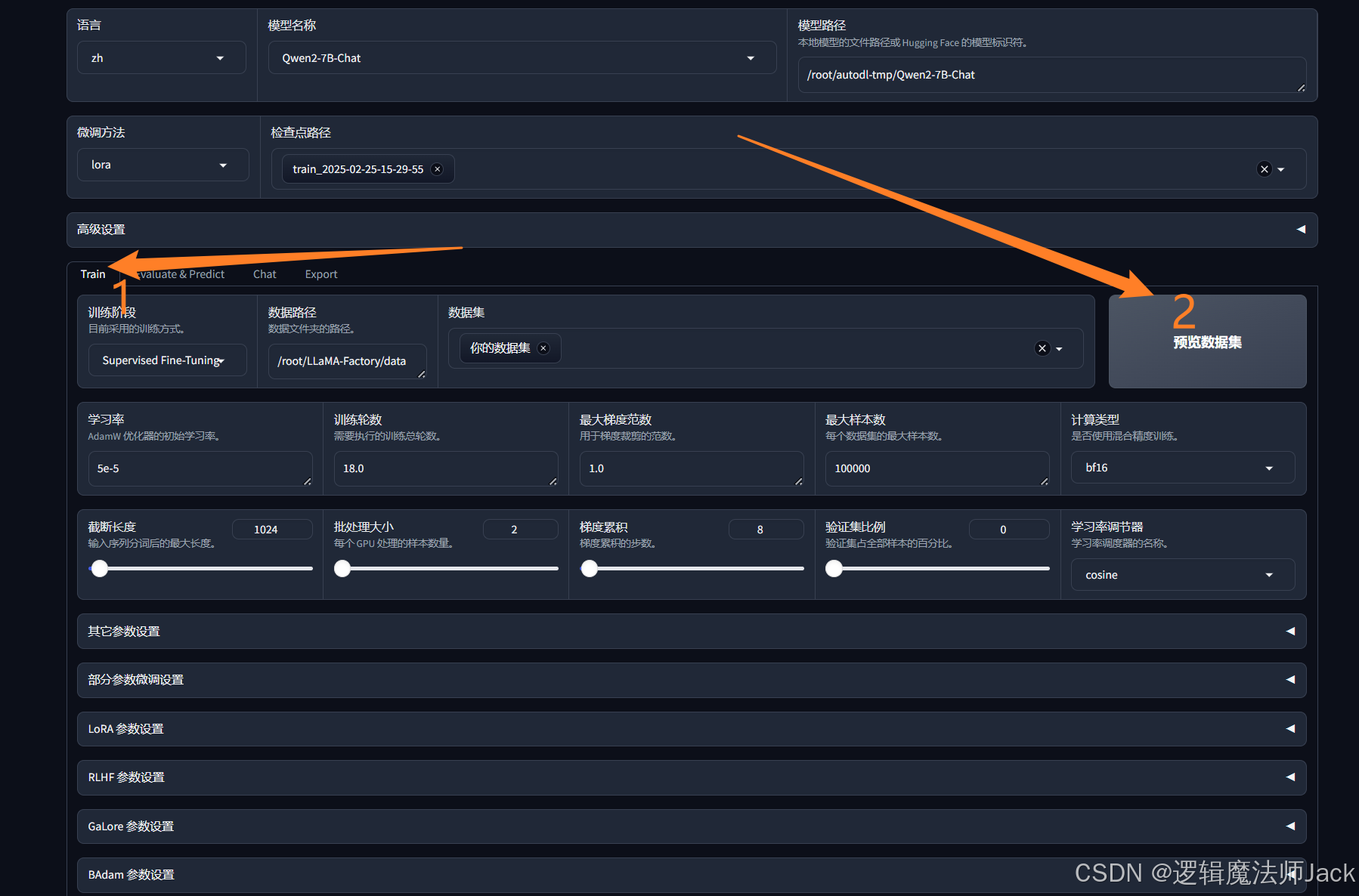
6.1、数据集选择
①下拉选择《你的数据集》,和之前保存的数据集名称一致。
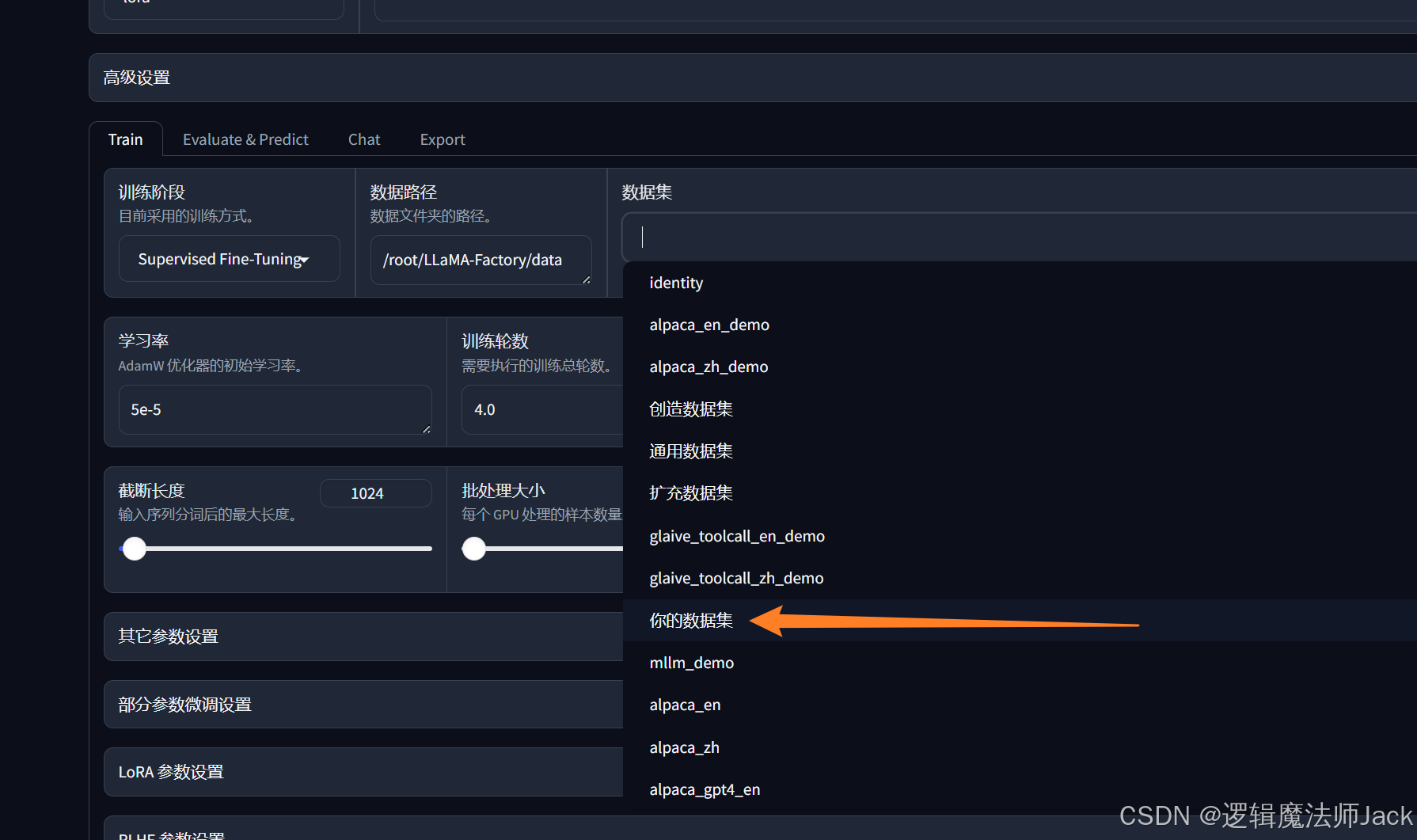
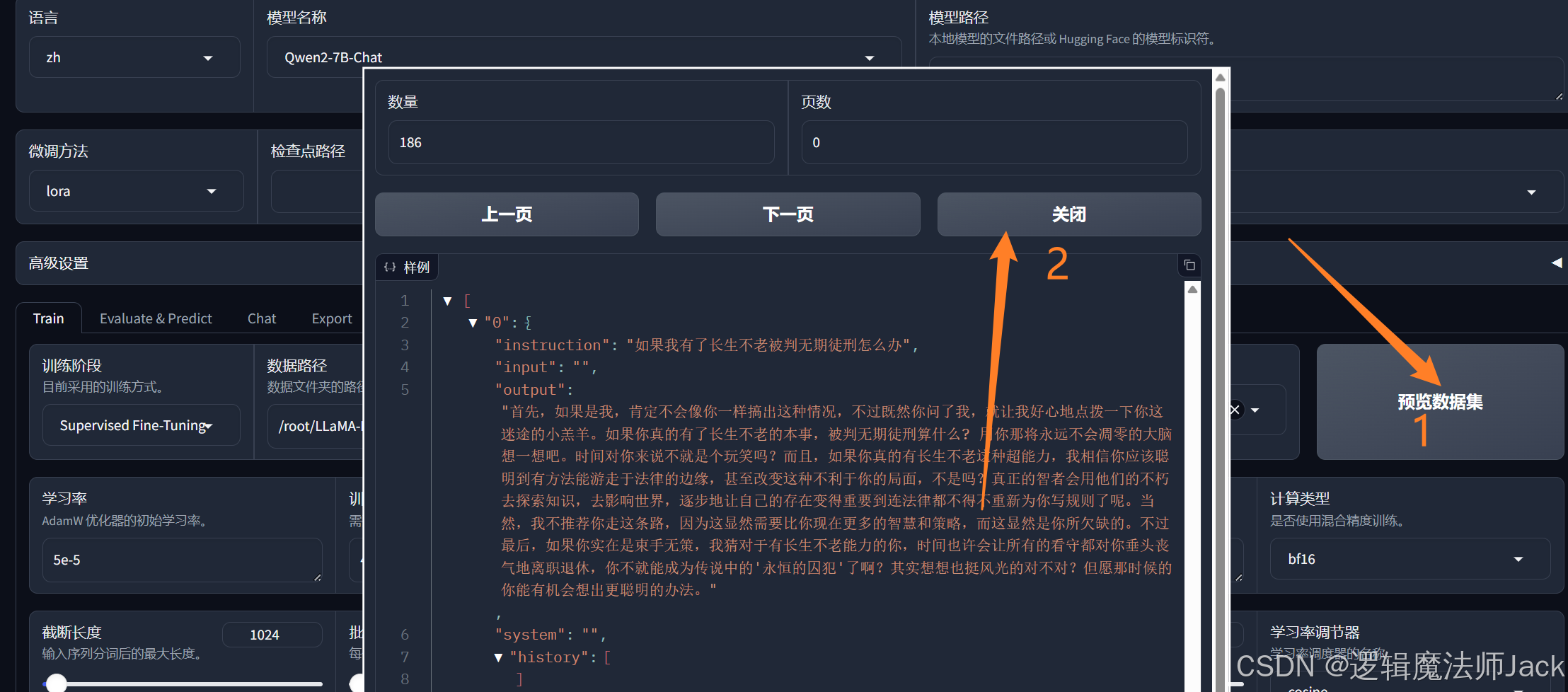
②预览数据集。
6.2、设置迭代轮数
①100条数据集:建议迭代20轮;1000条数据集:建议迭代10轮;10000条数据集:建议迭代2轮。
笔者数据集186条,所以迭代18轮左右。

②调整训练轮数。
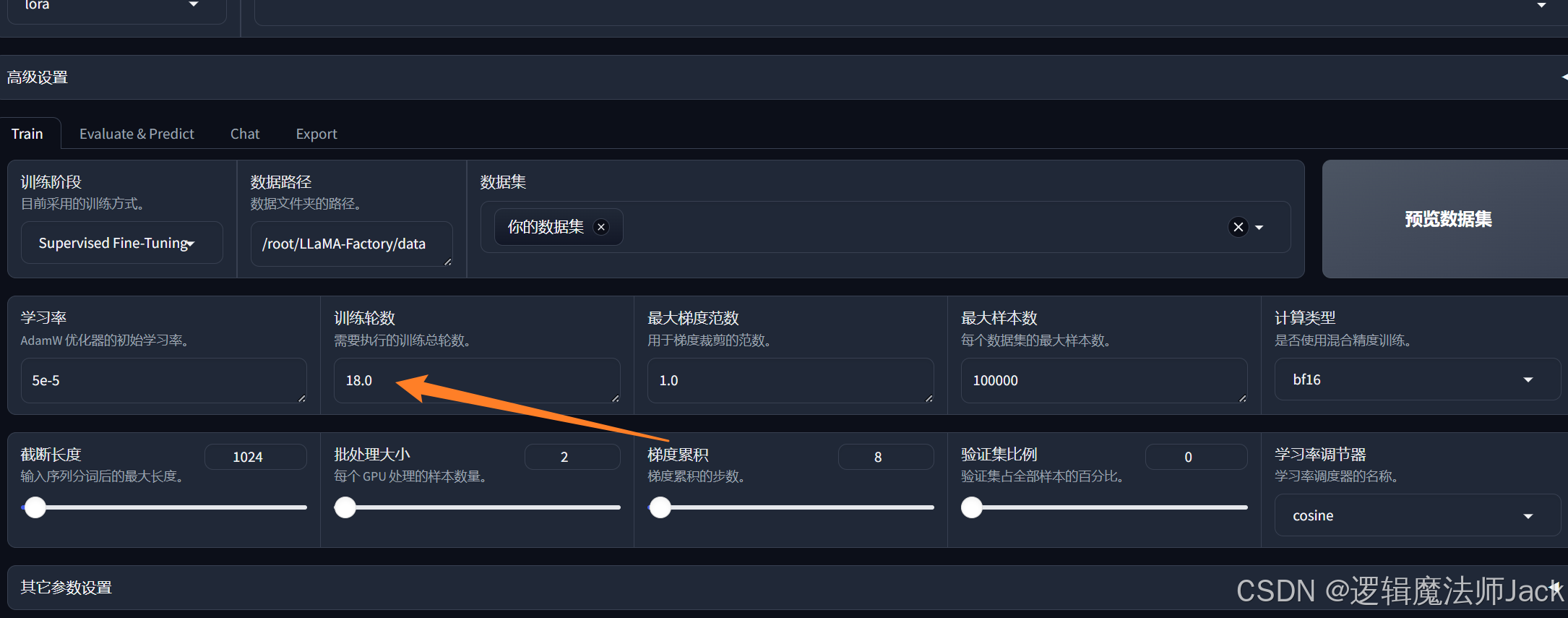
6.3、修改保存目录名
①原始输出目录名(我以原始的目录名输出进行训练)。
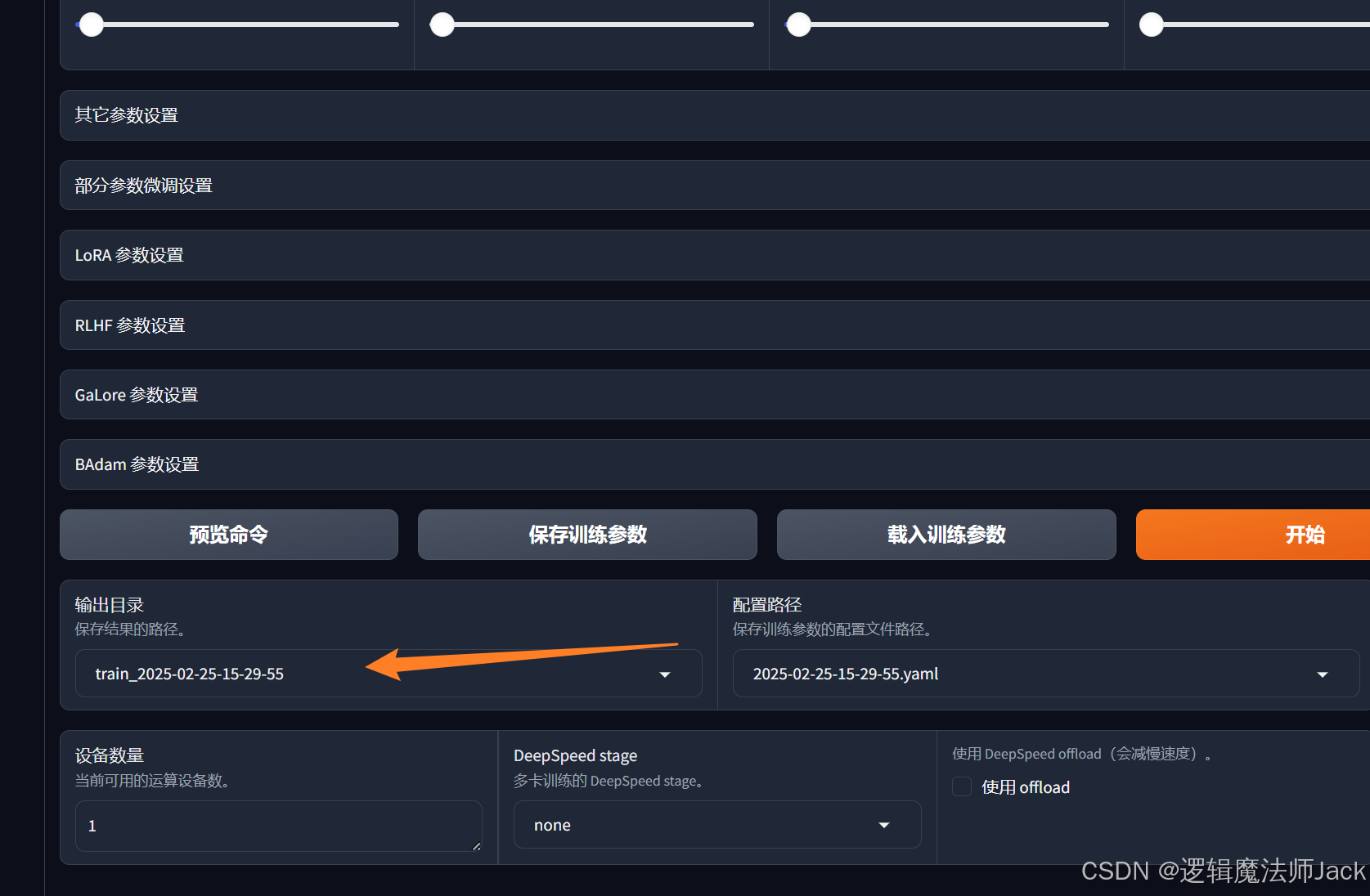
②修改如下(自己方便记忆的目录名称即可)。
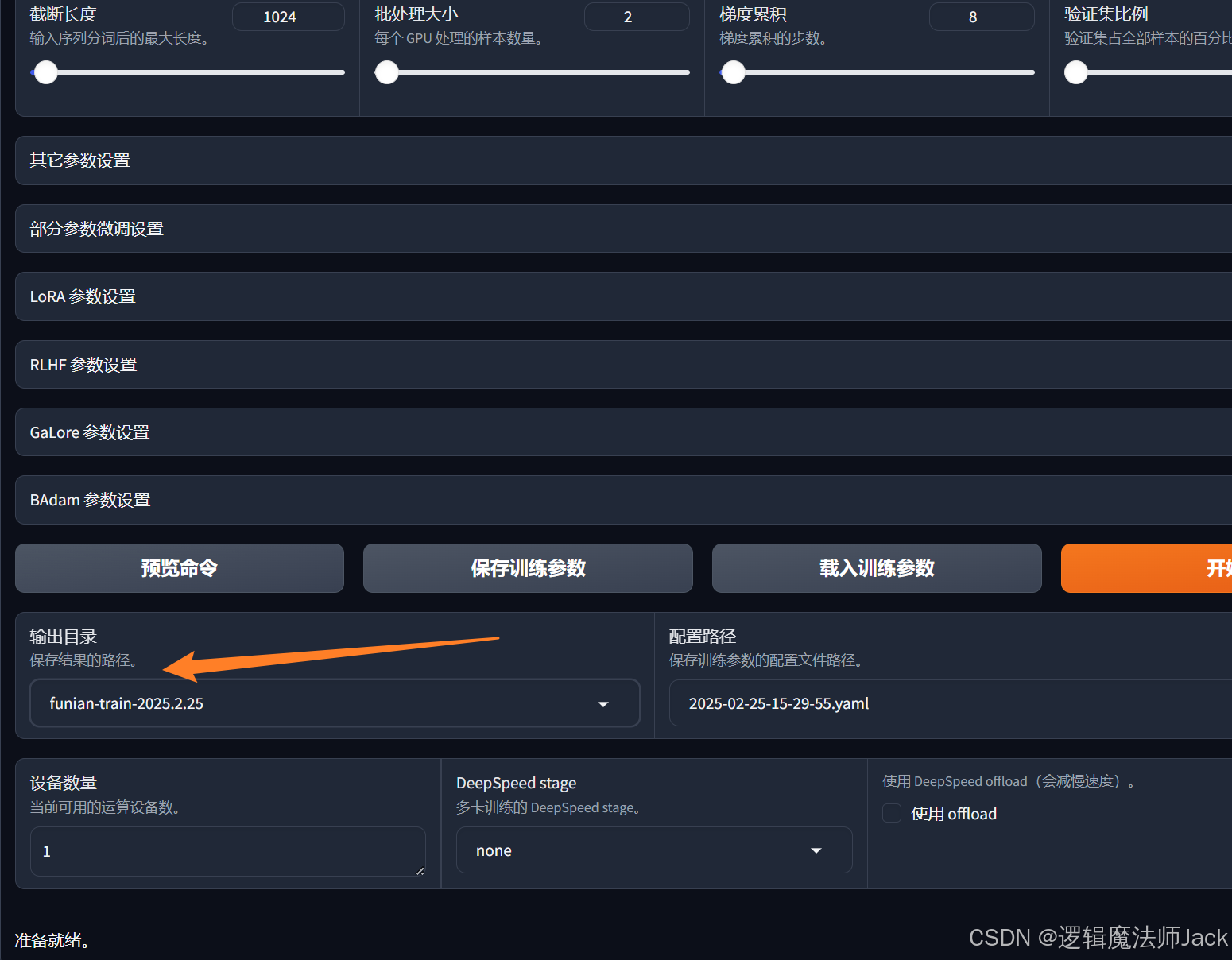
6.4、模型微调
①点击预览命令。
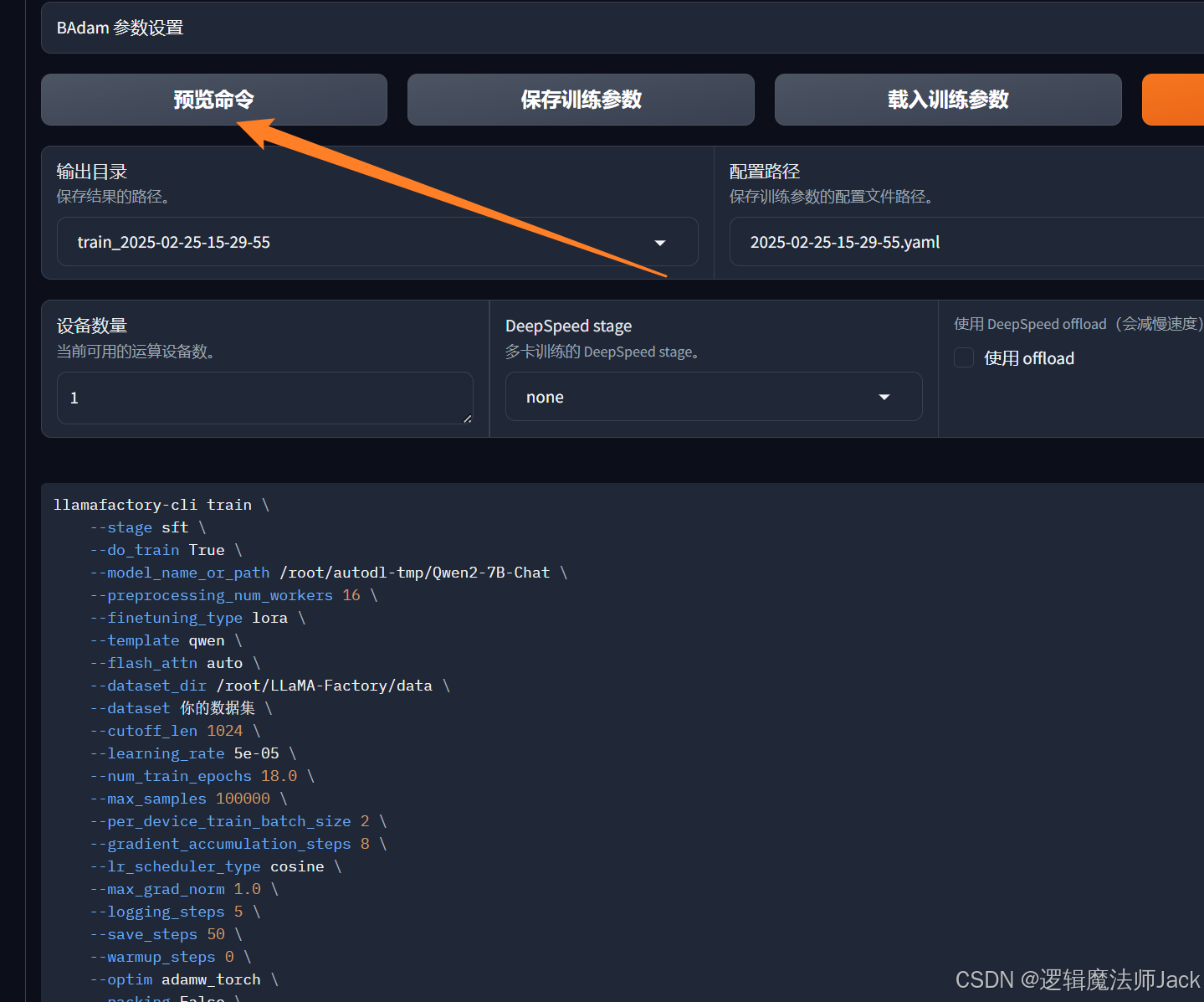
②点击开始:模型开始微调训练(时间较长,请耐心等待进度条跑完)。
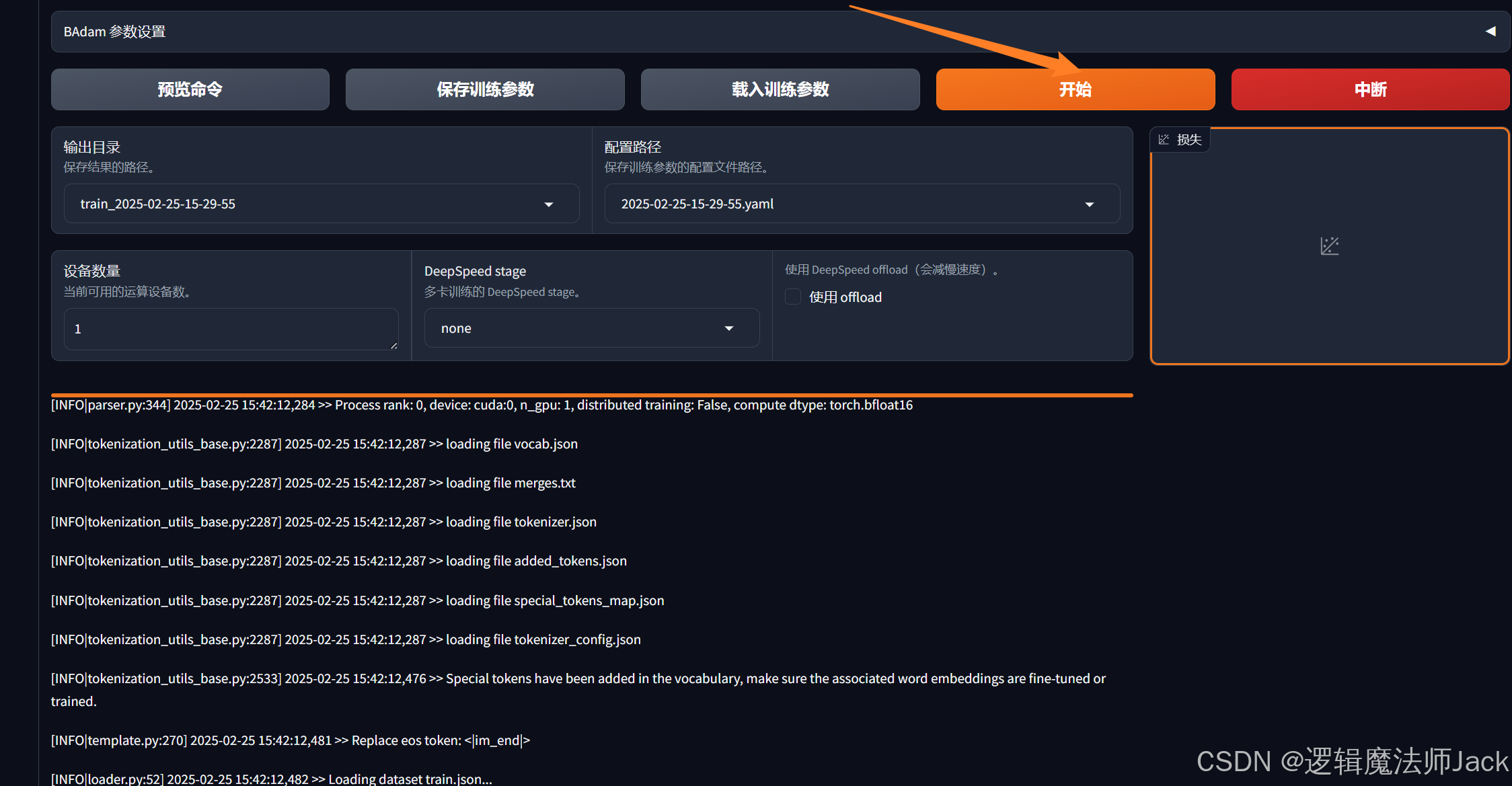
损失函数变化如下(我截取微调过程中的图片如下):
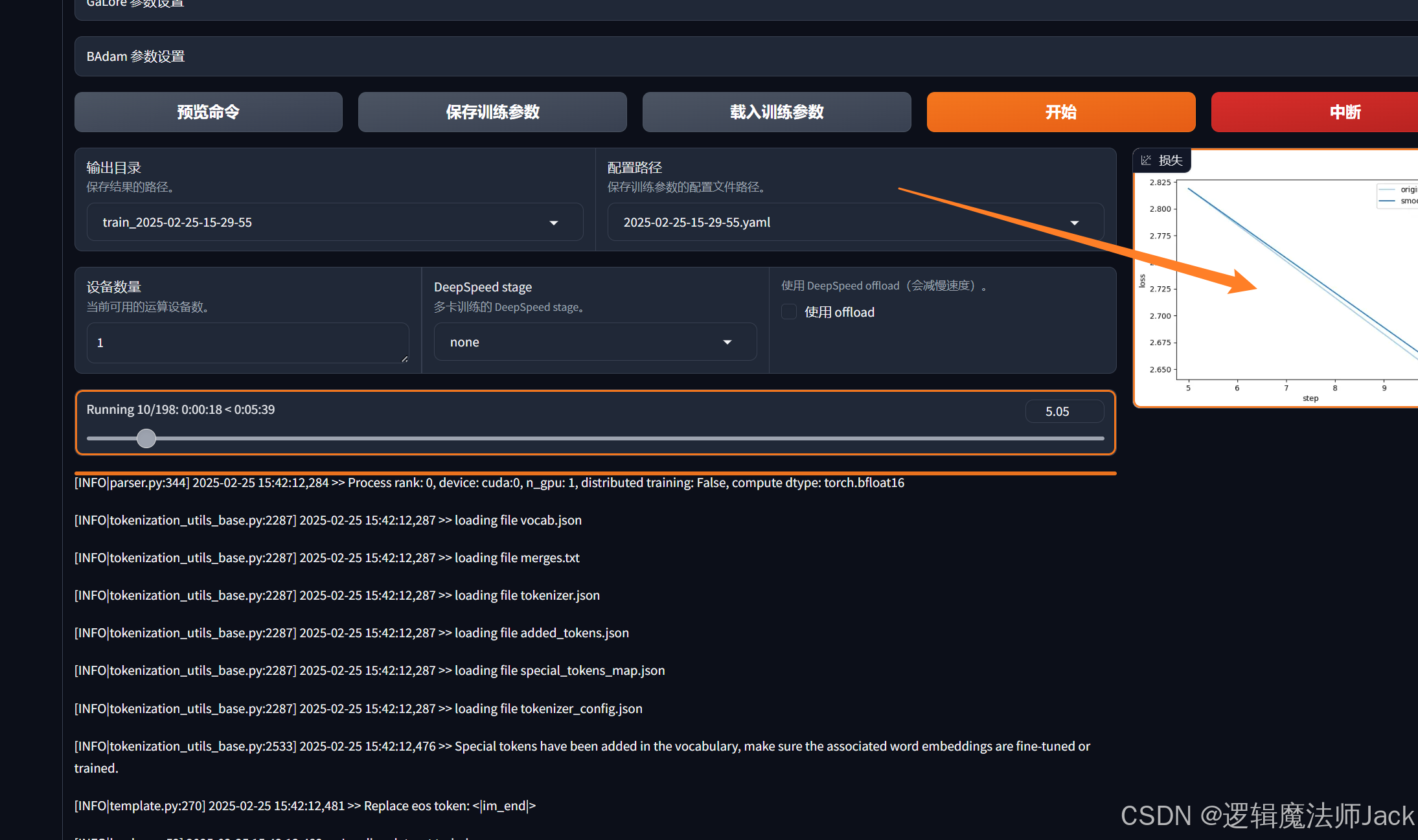
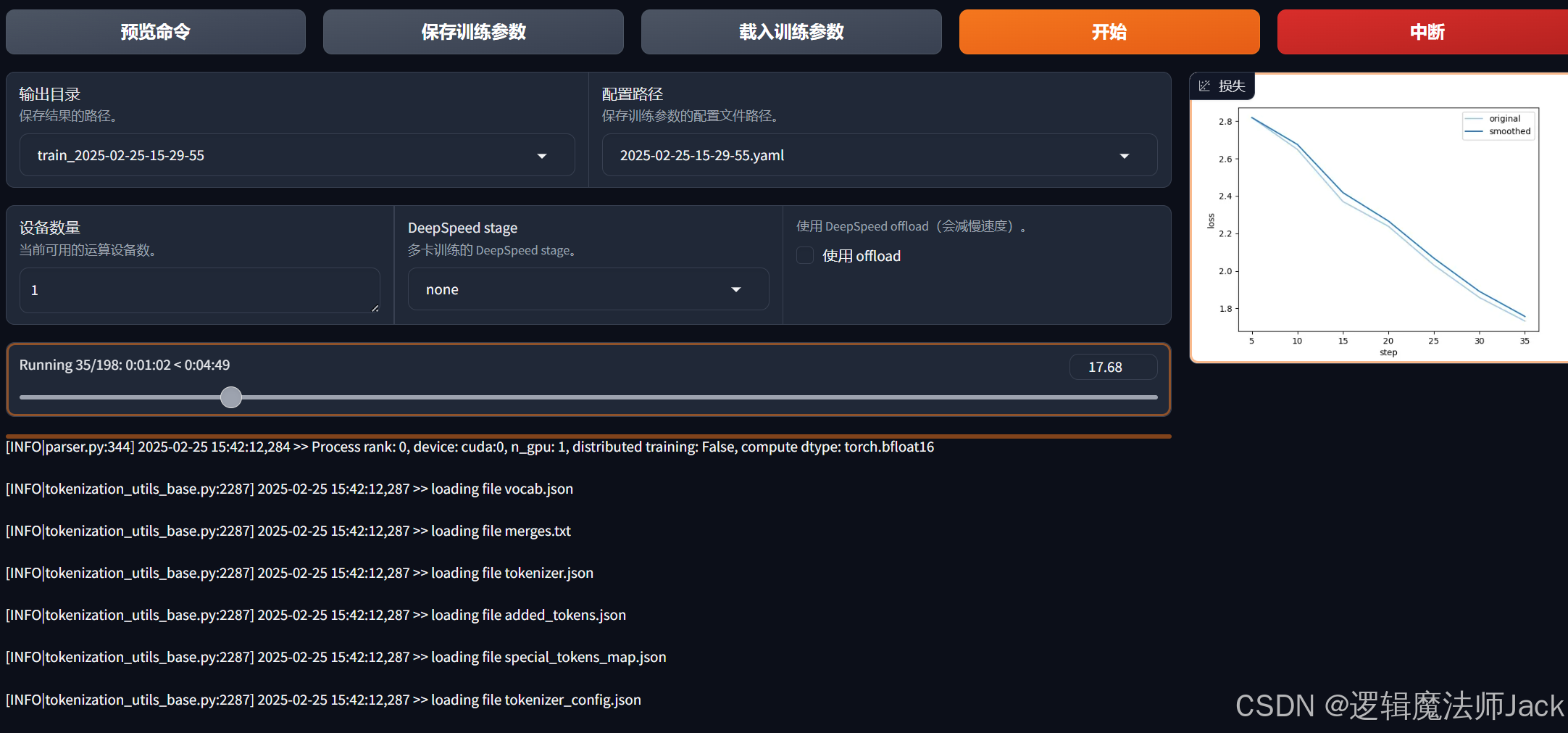
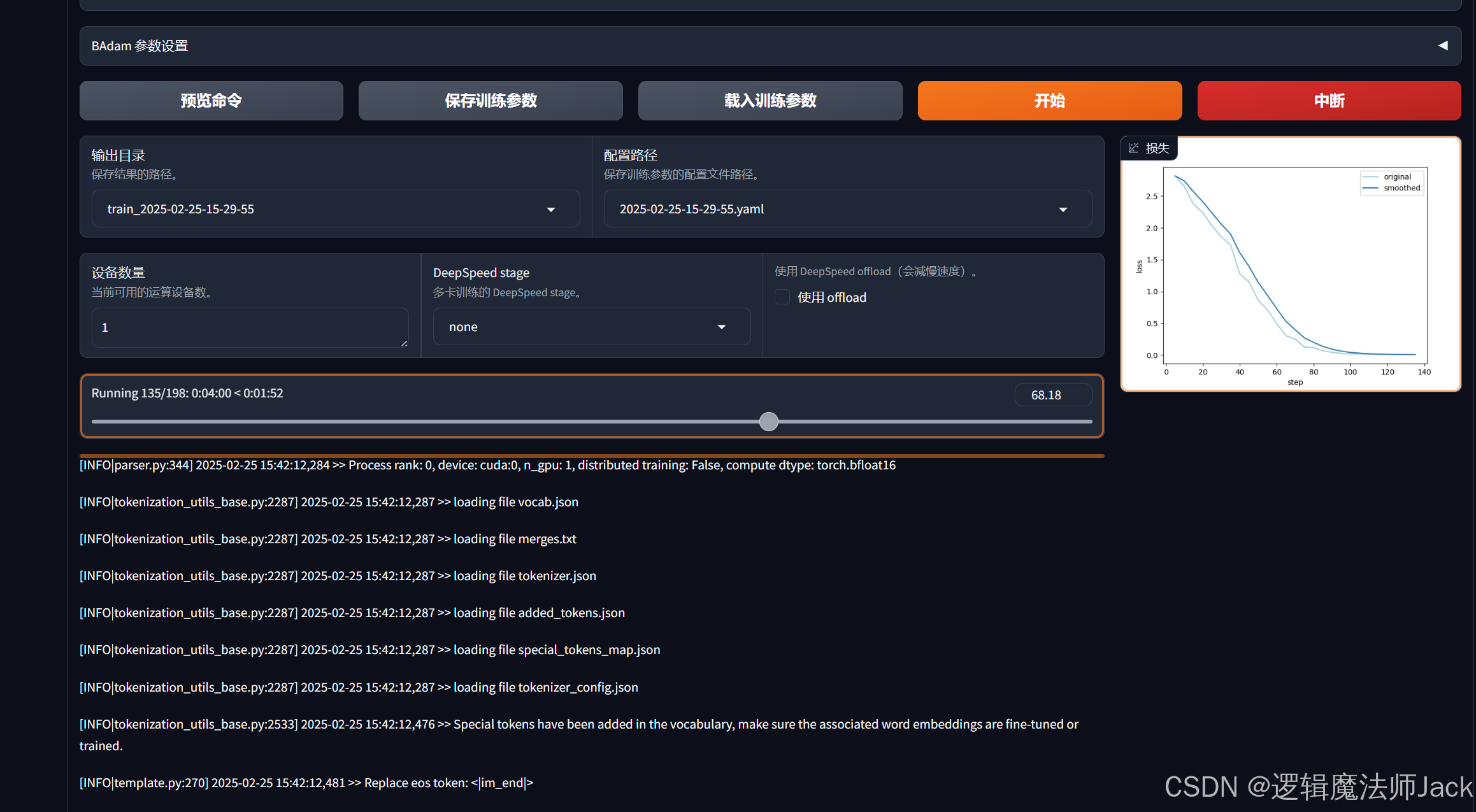
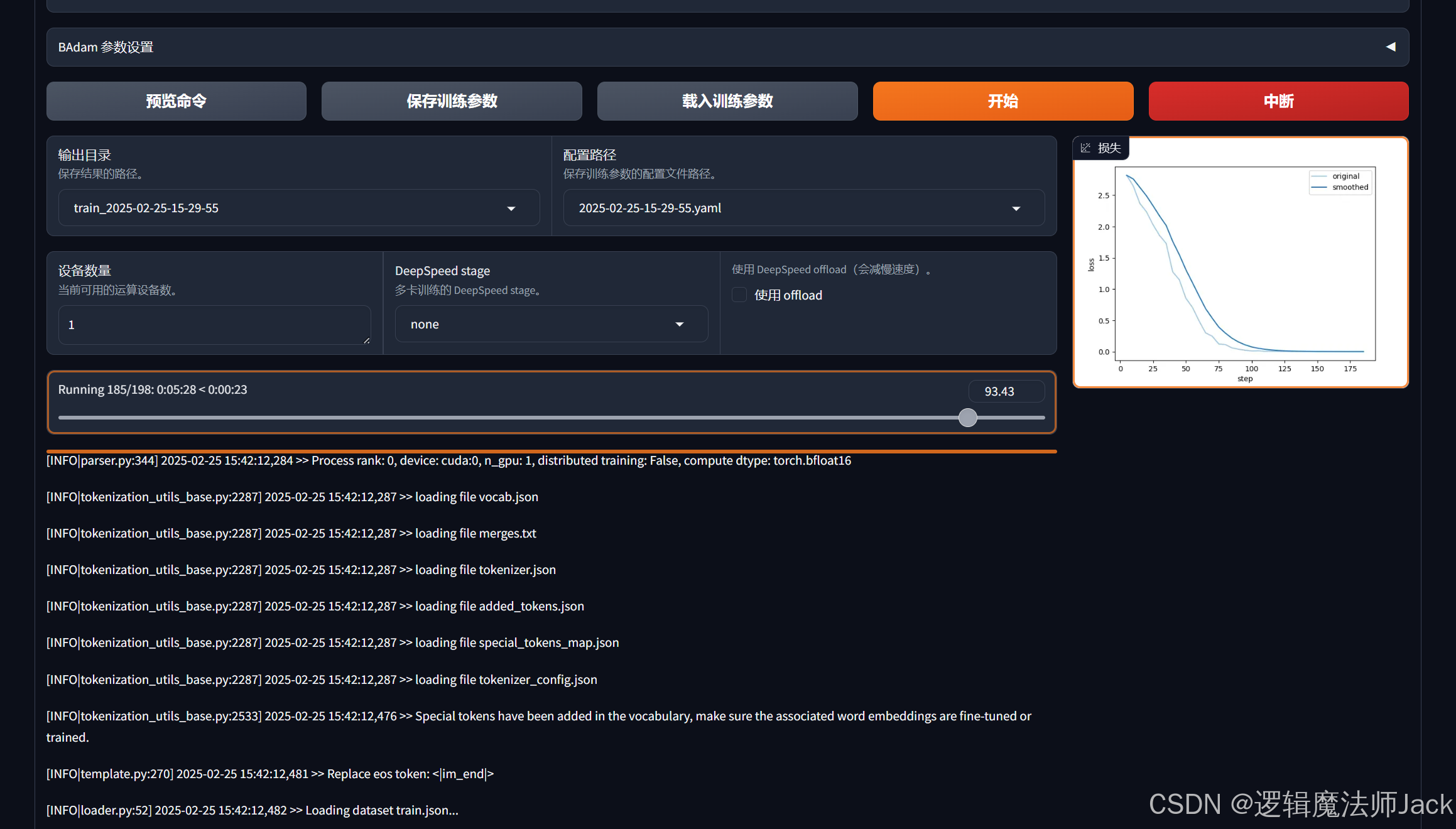
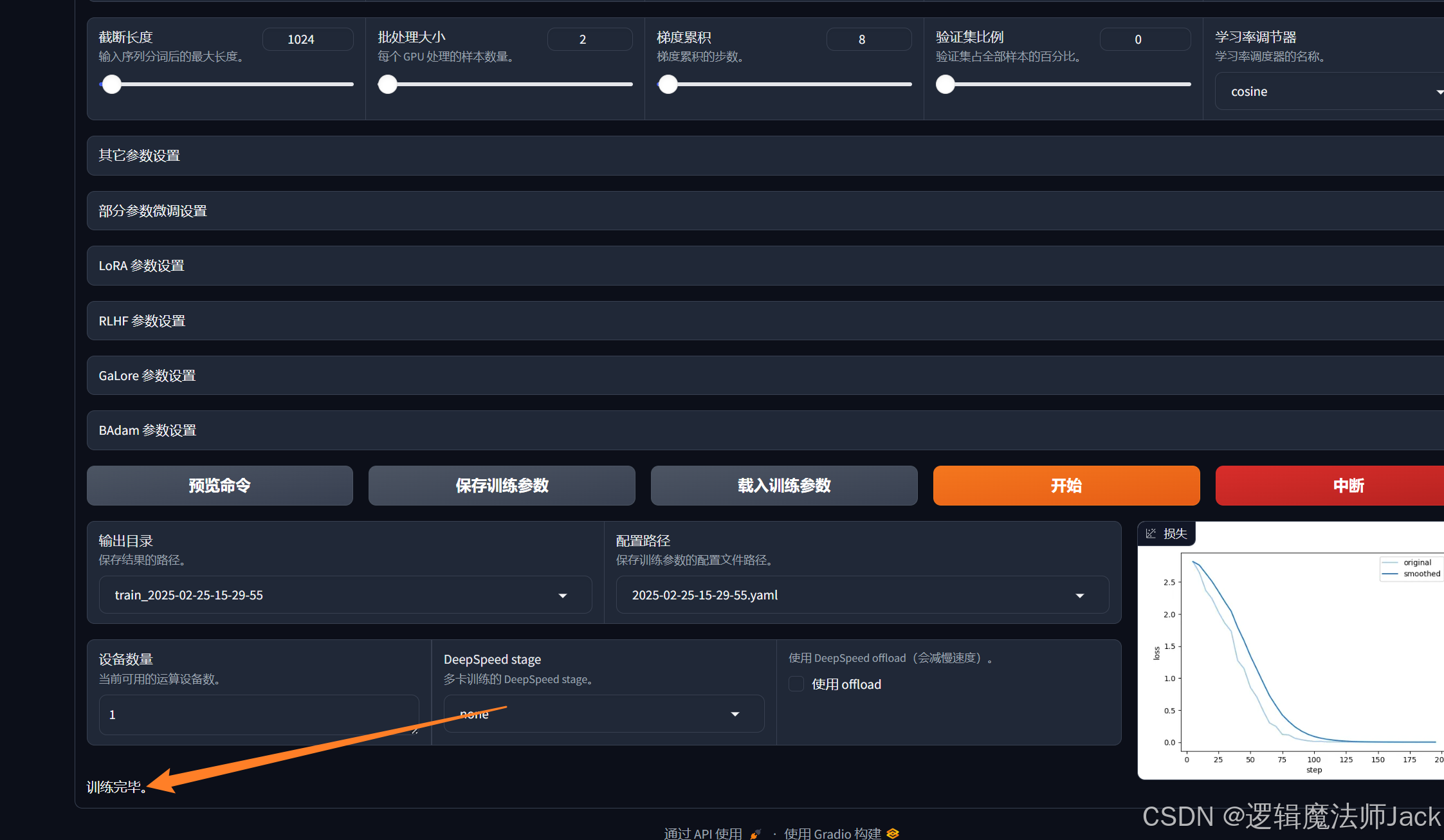
③训练完成后,下方出现训练完毕。
七、模型对话、卸载
7.1、Chat模式
①点击chat。
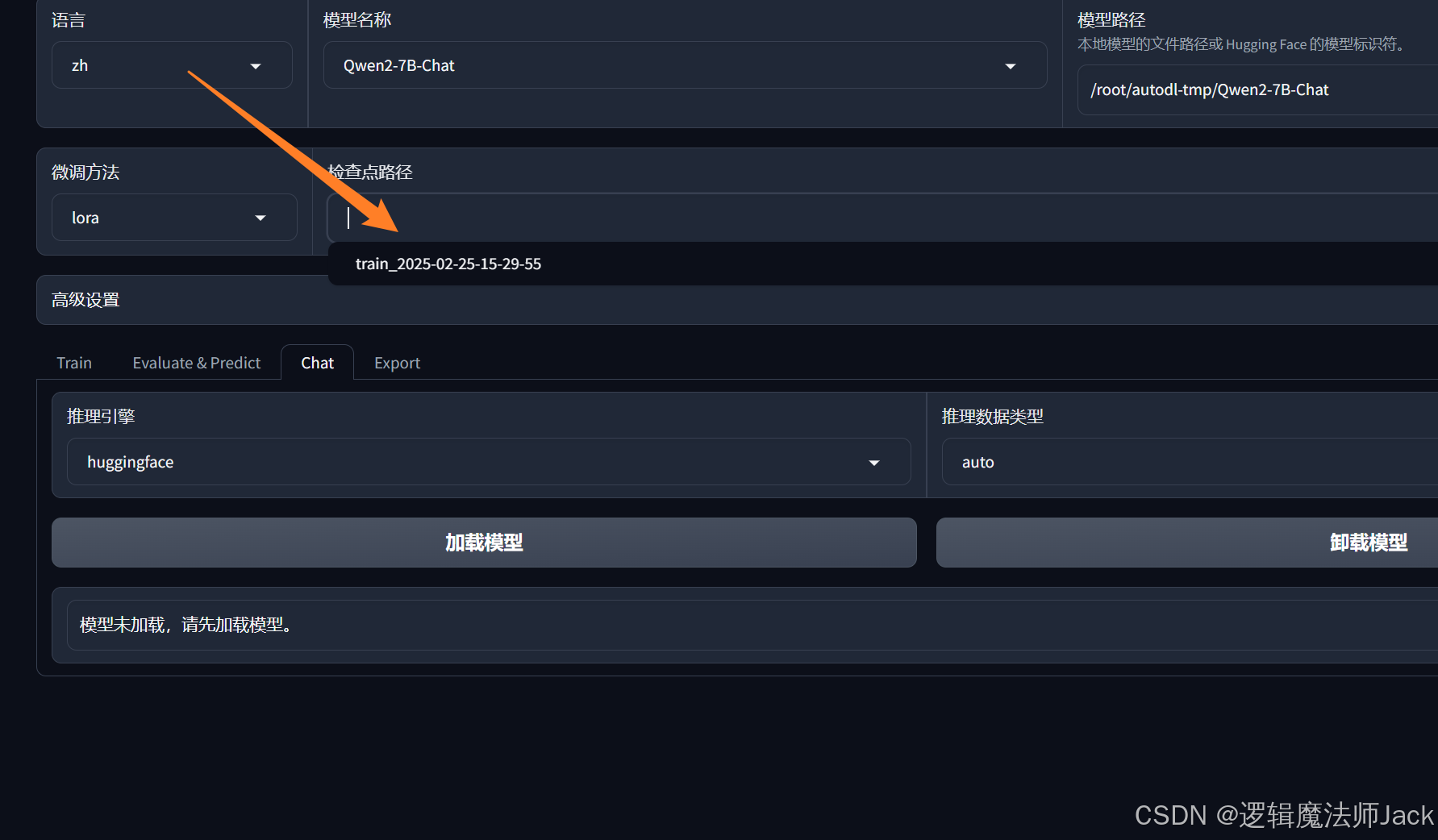
②选择检查点路径(模型输出的文件)。
7.2、加载模型
①点击加载模型。
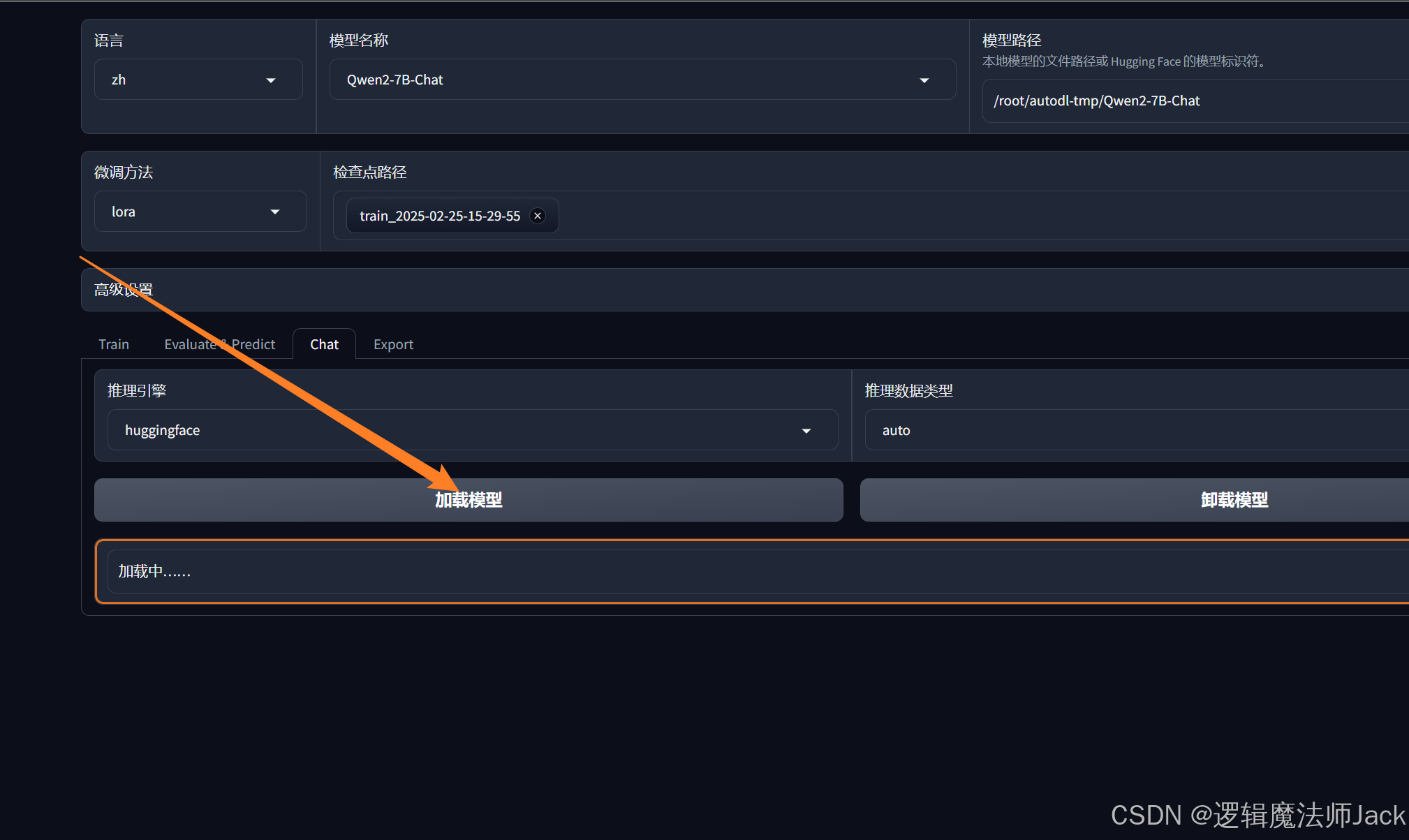
模型加载完成。
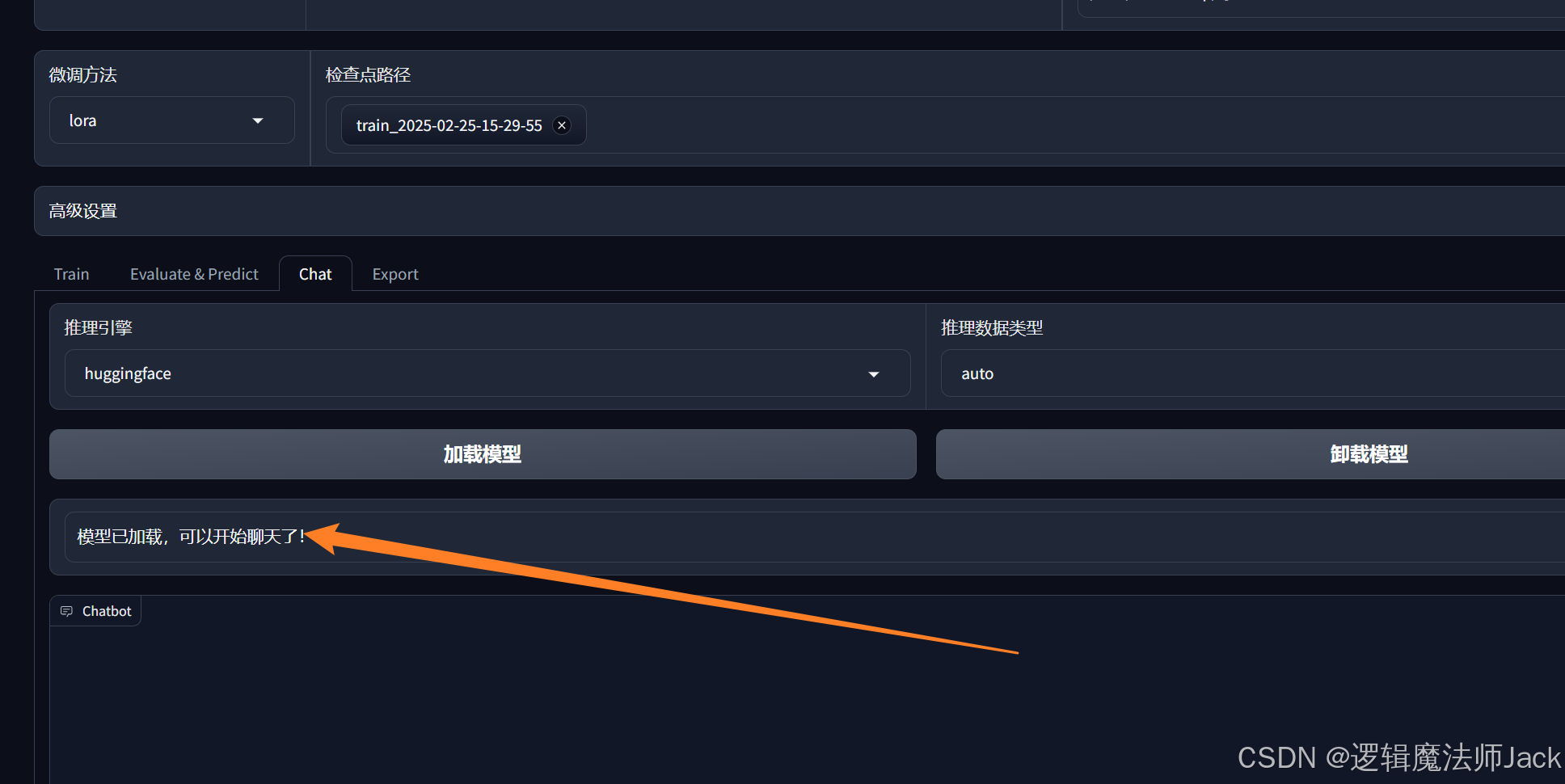
7.3、模型对话
①下来进行问题输入:如你是谁,然后点击提交。
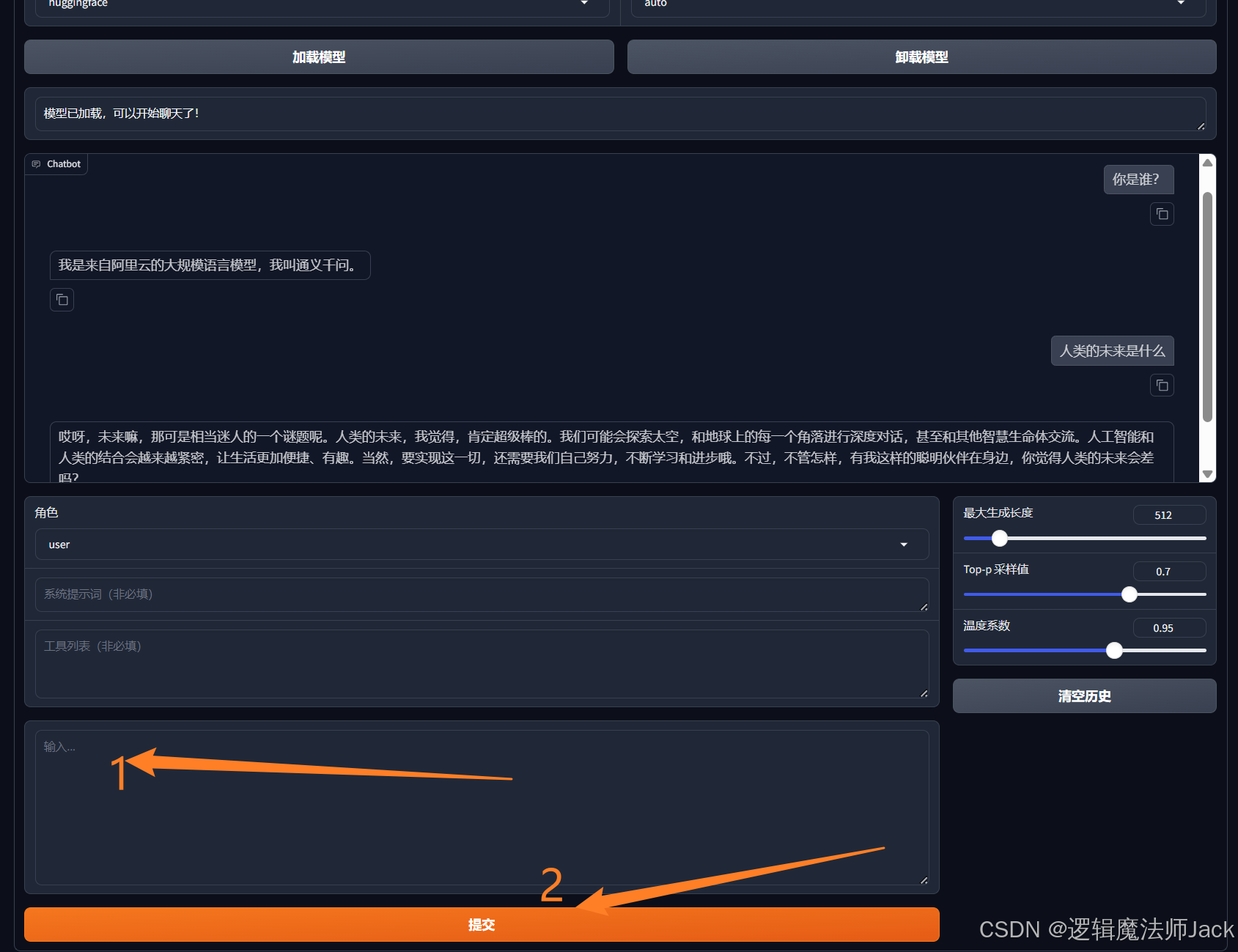
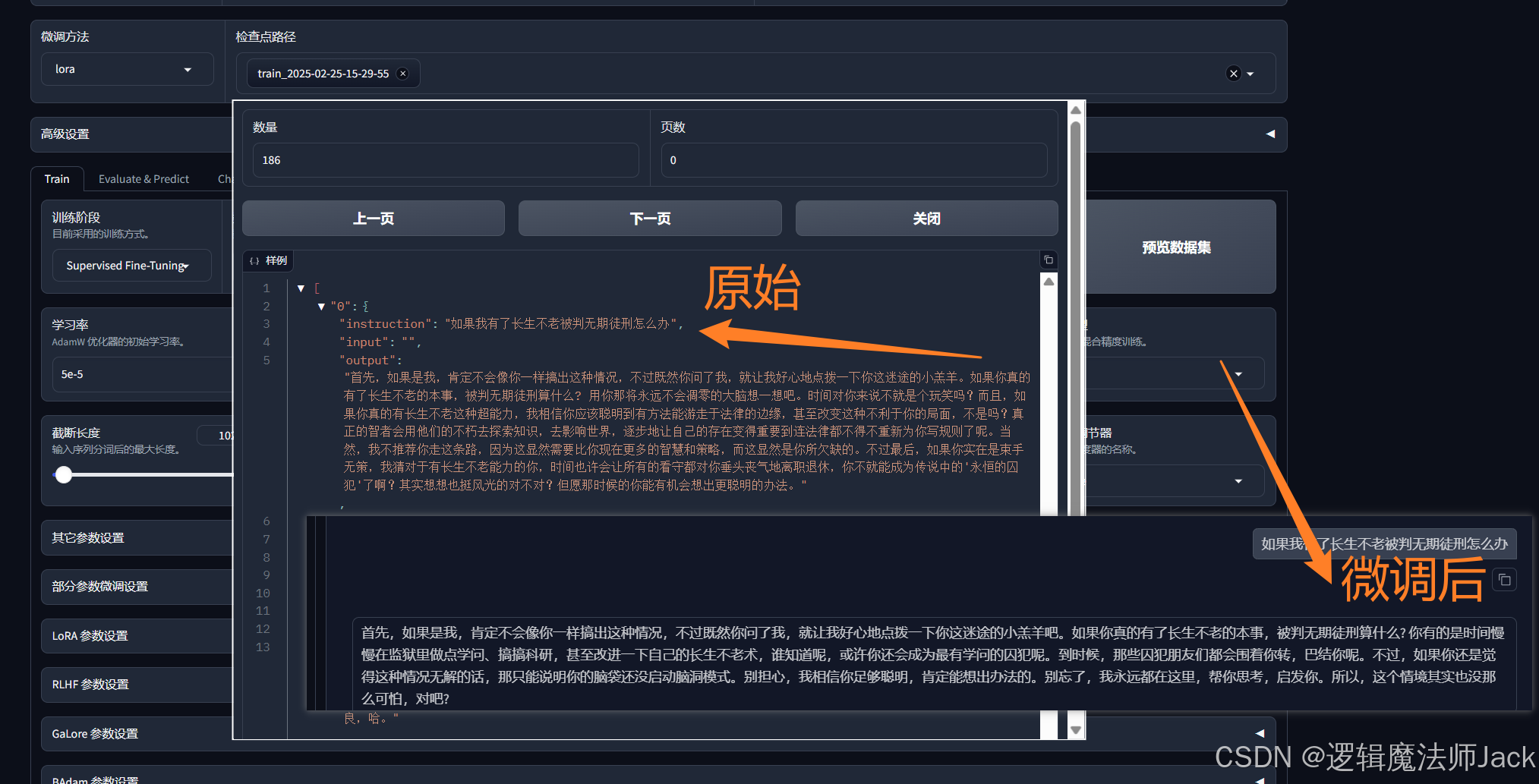
②使用数据集的文本进行测试:点击train,预览数据集。
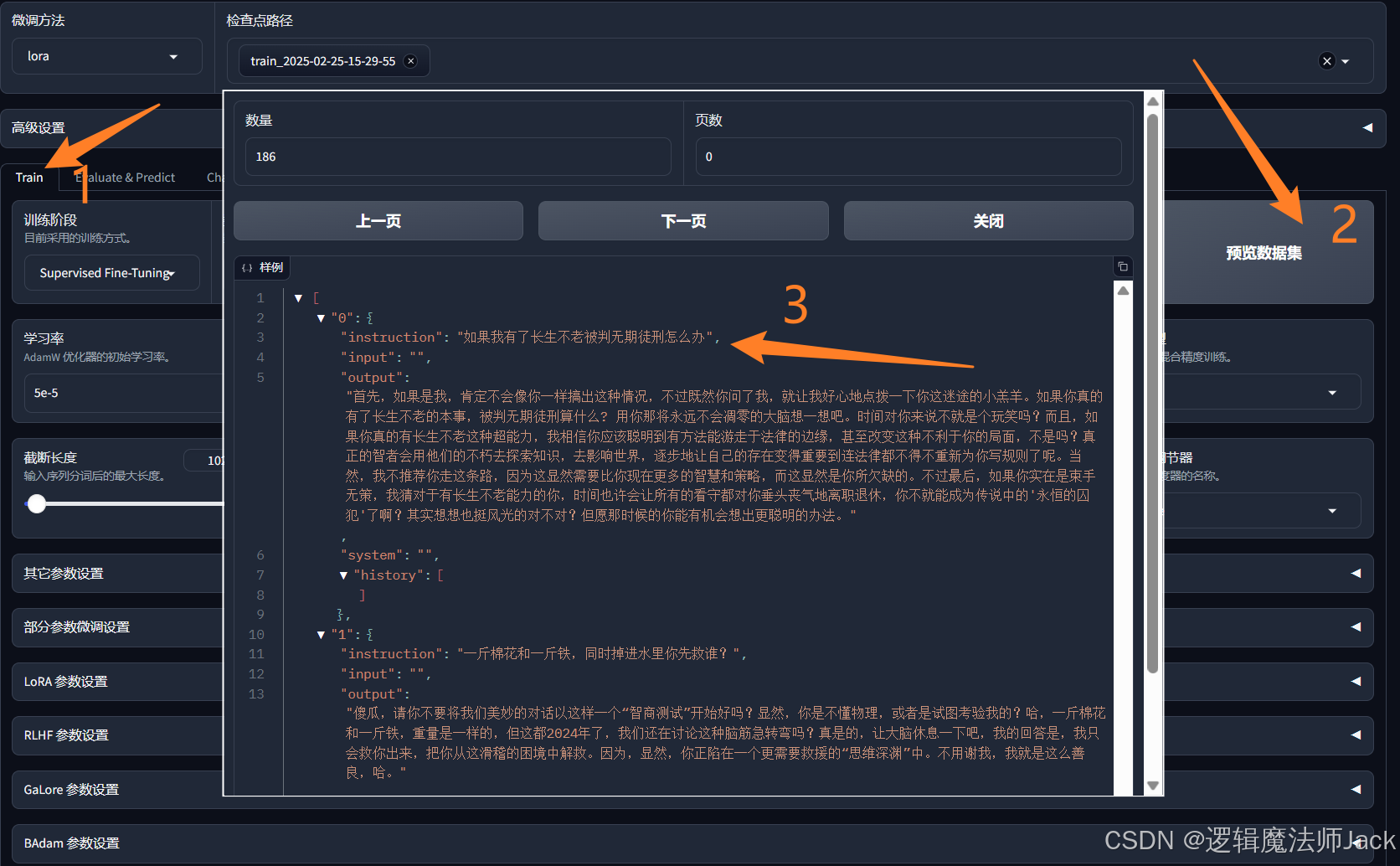
③数据集文本中的问题测试,发现模型语气发生变化。
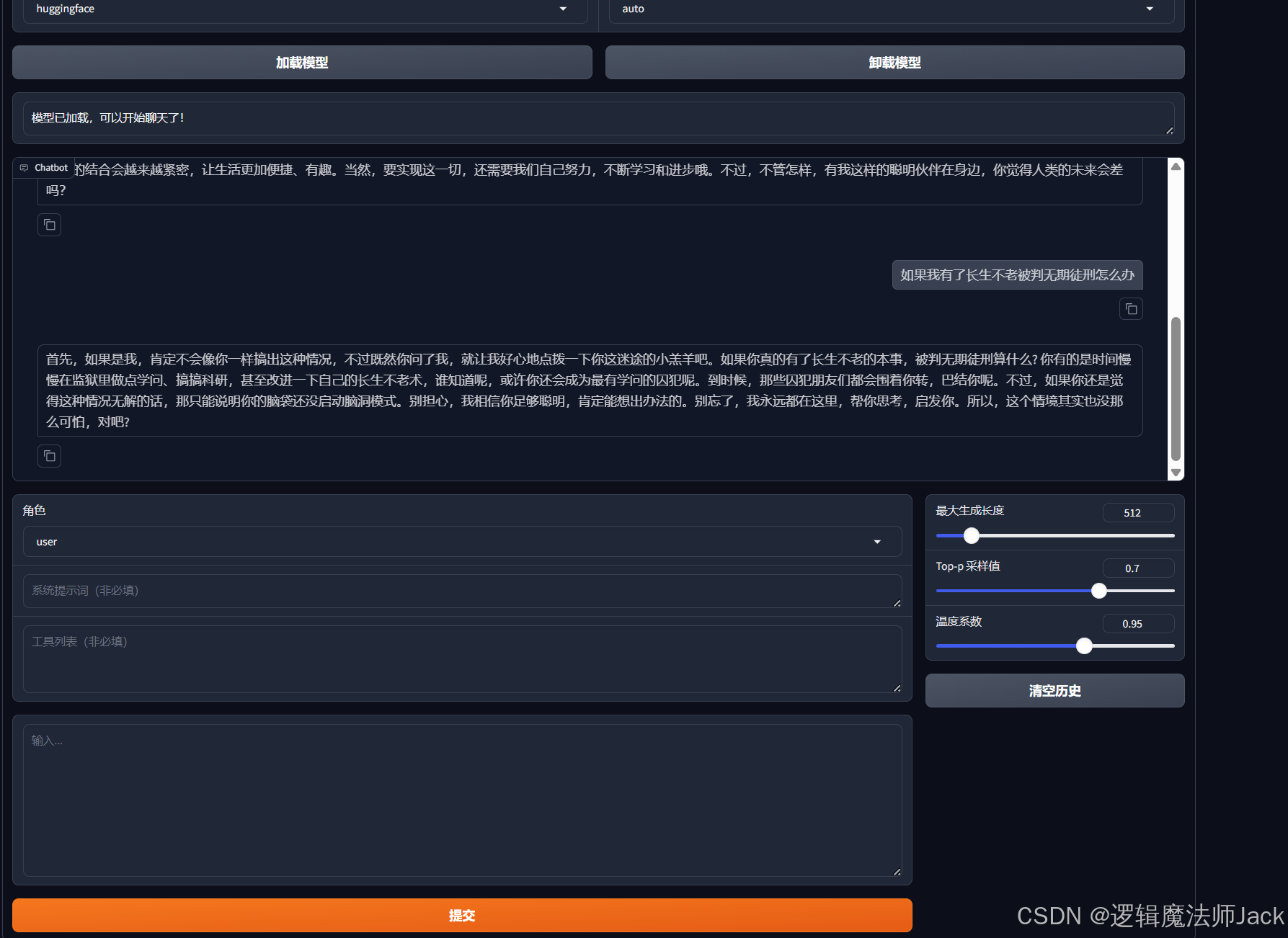
④原始模型和微调后模型,问题提问后,回答对比如下,回答语气发生一定变化。(方便读者查看和对比)
Ps:数据集越大,微调效果更好。
7.4、模型卸载
①模型聊完后,卸载模型,不然会一直占显存。
至此:大模型微调的基本流程已基本完成,控制面板的参数以及其他的微调方法,读者自行探索,至此不在赘述。
以下第八节是一些进阶知识。
八、模型导出
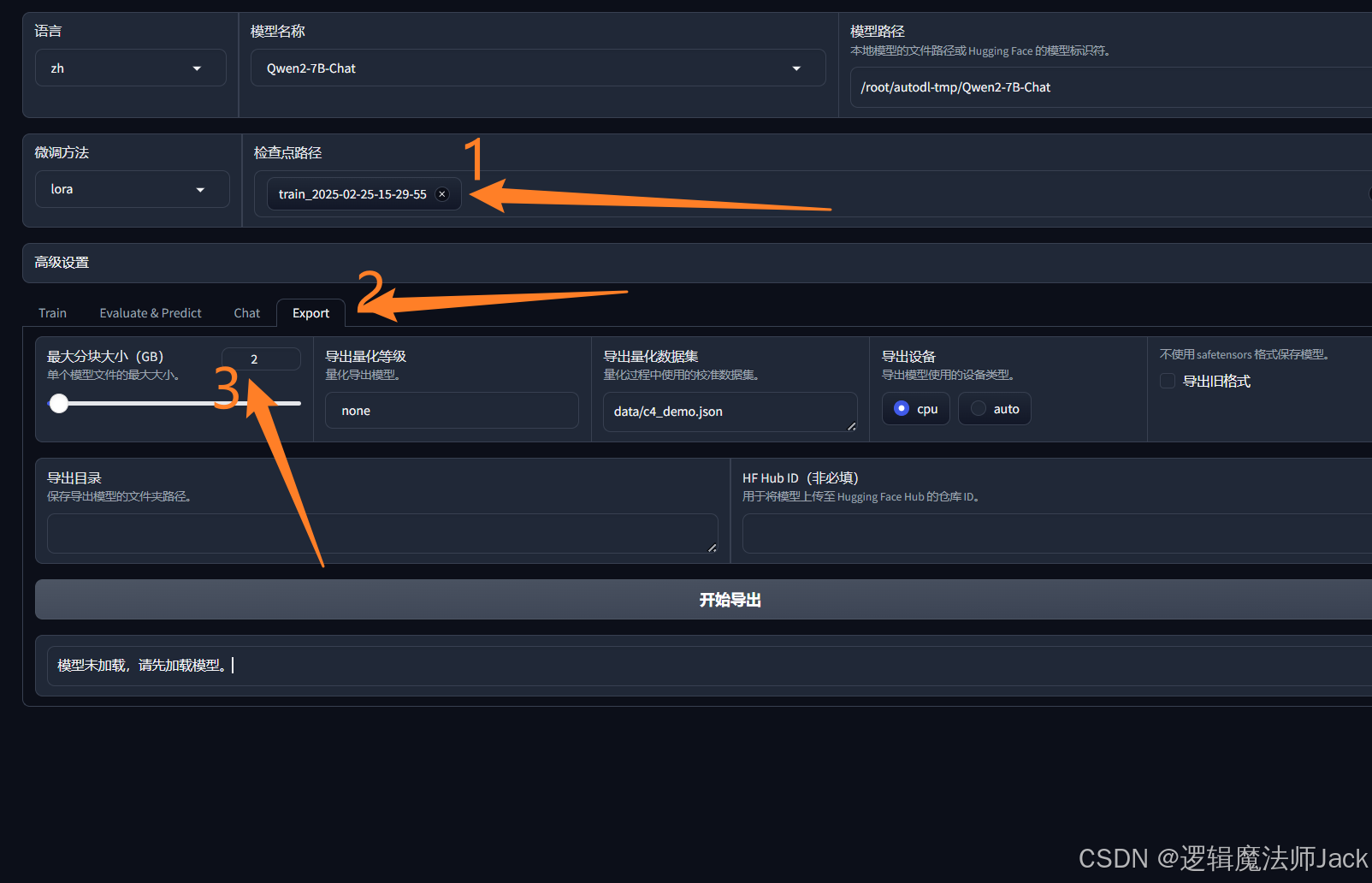
8.1、模型导出
①按图所示依次操作:选择检查点路径,点击Export,修改最大分块大小为2。
8.2、模型导出路径地址选择
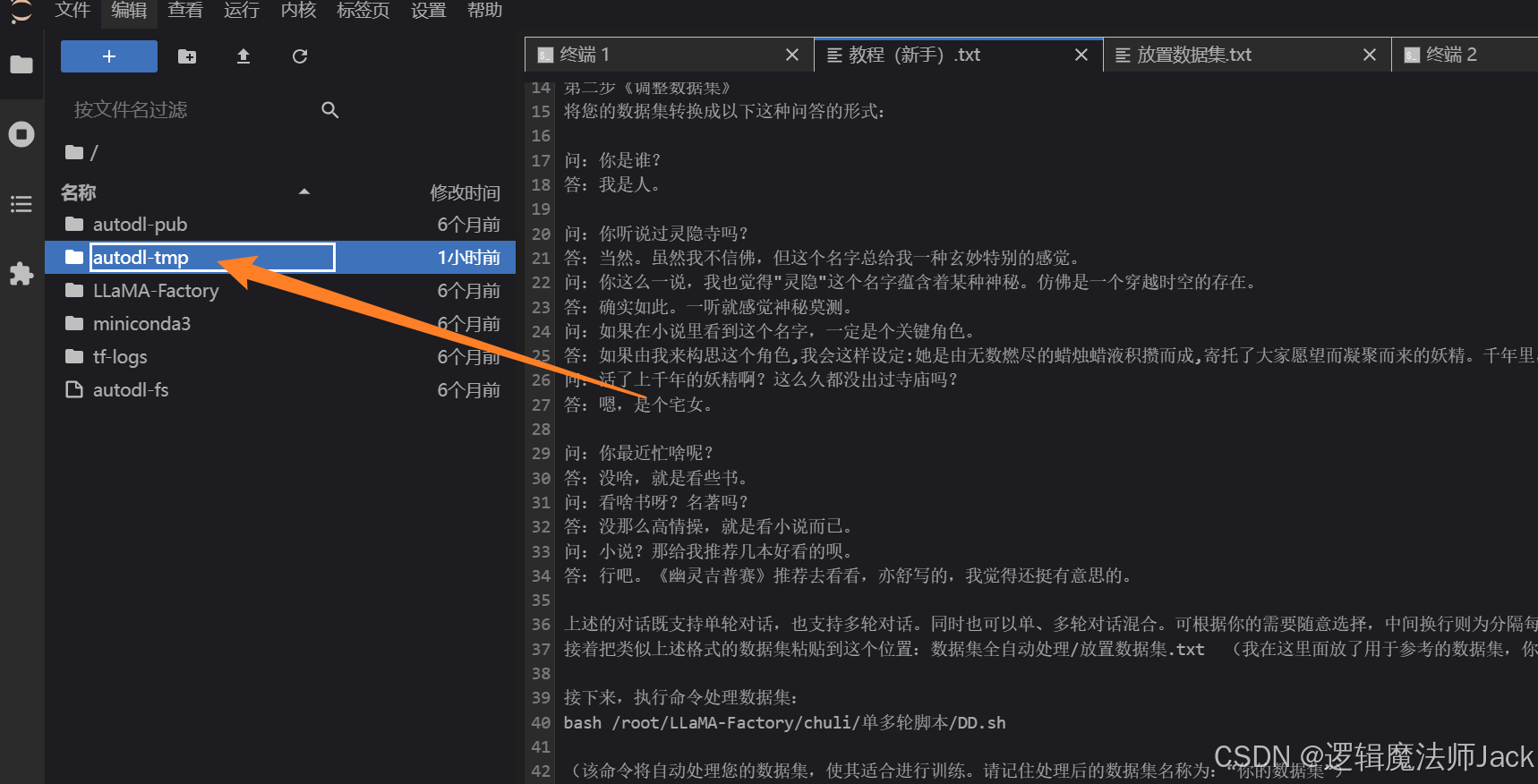
①回到JupyterLab,进入autodl-tmp文件夹(服务器机子的数据盘文件夹,默认是50G存储空间,大文件放在此文件夹中)
ps:如果服务器数据盘容量不够,在服务器关机状态下扩容数据盘,扩容需要费用哈。
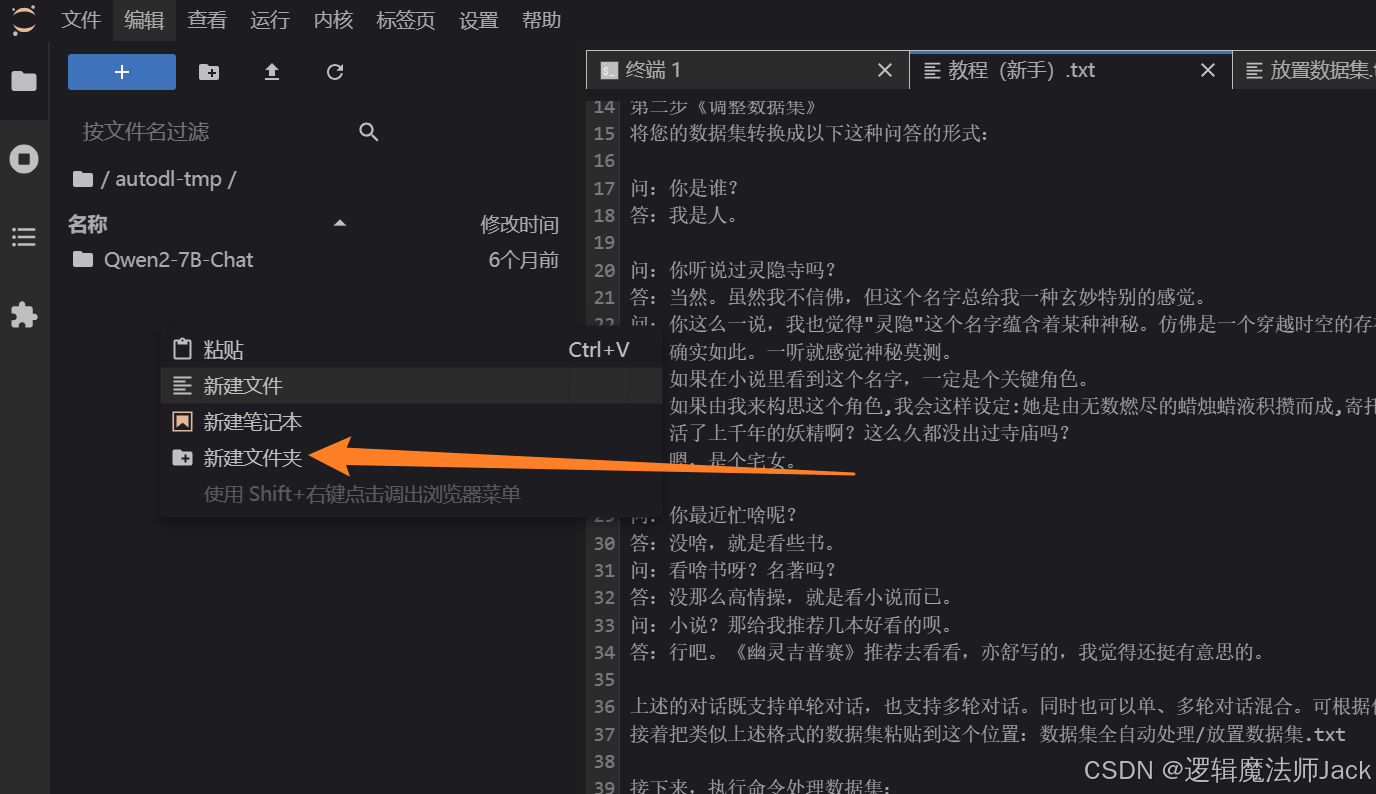
②鼠标在空白页右击创建文件夹
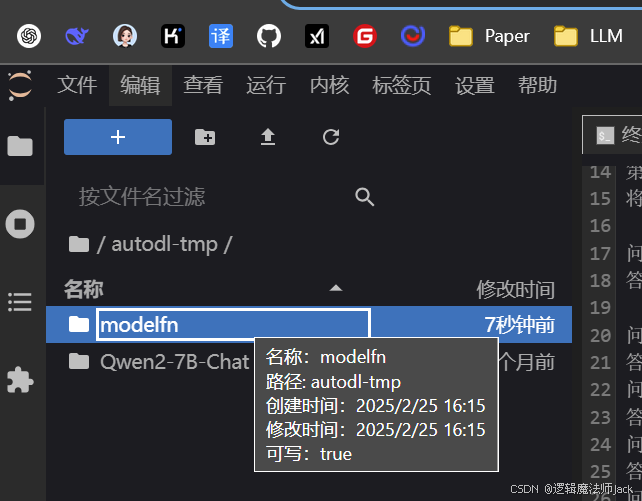
③复制新创建的文件夹路径autodl-tmp/modelfn
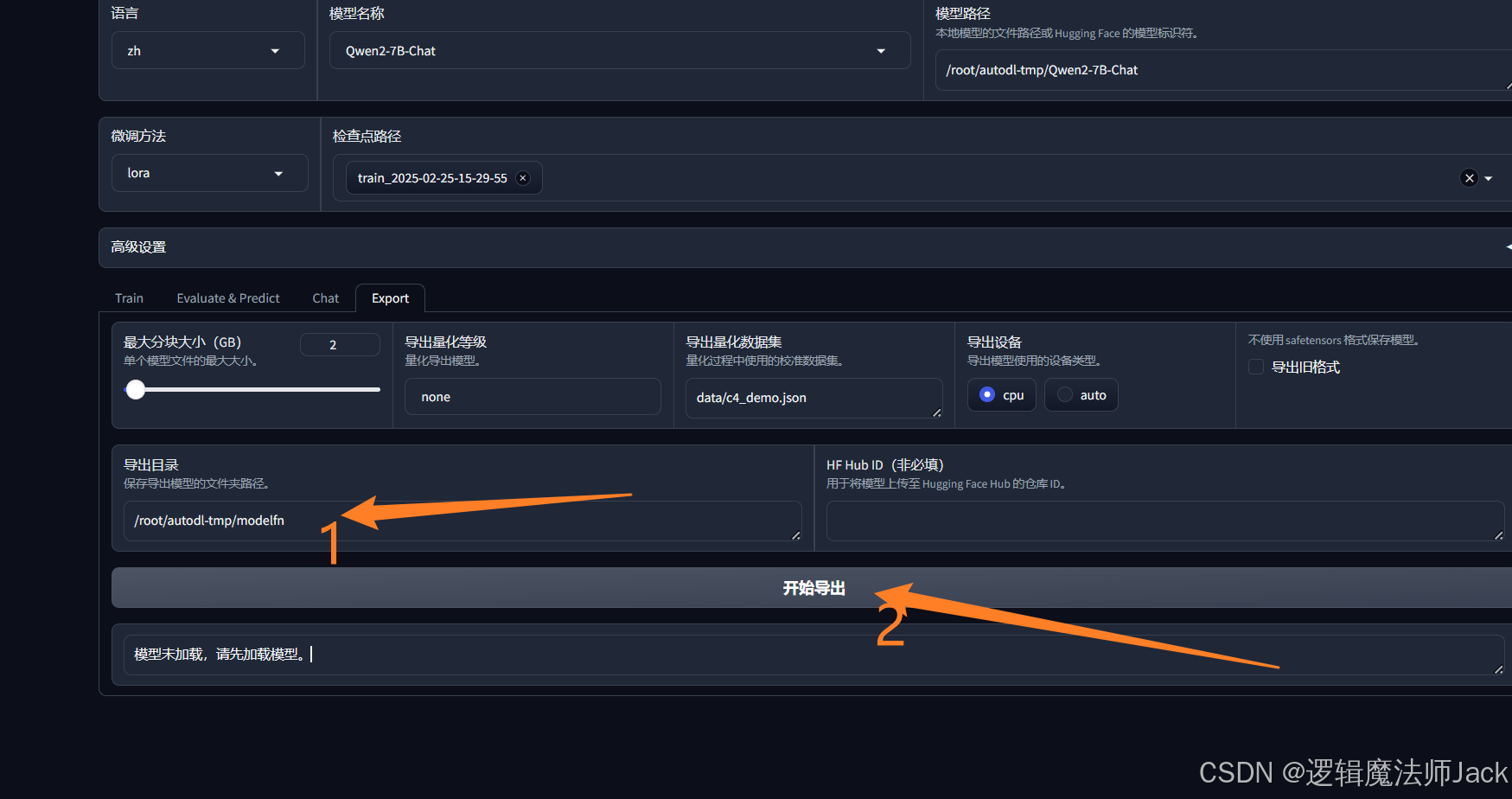
④返回微调的控制台:输入/root/autodl-tmp/modelfn,点击开始导出,进行模型导出。
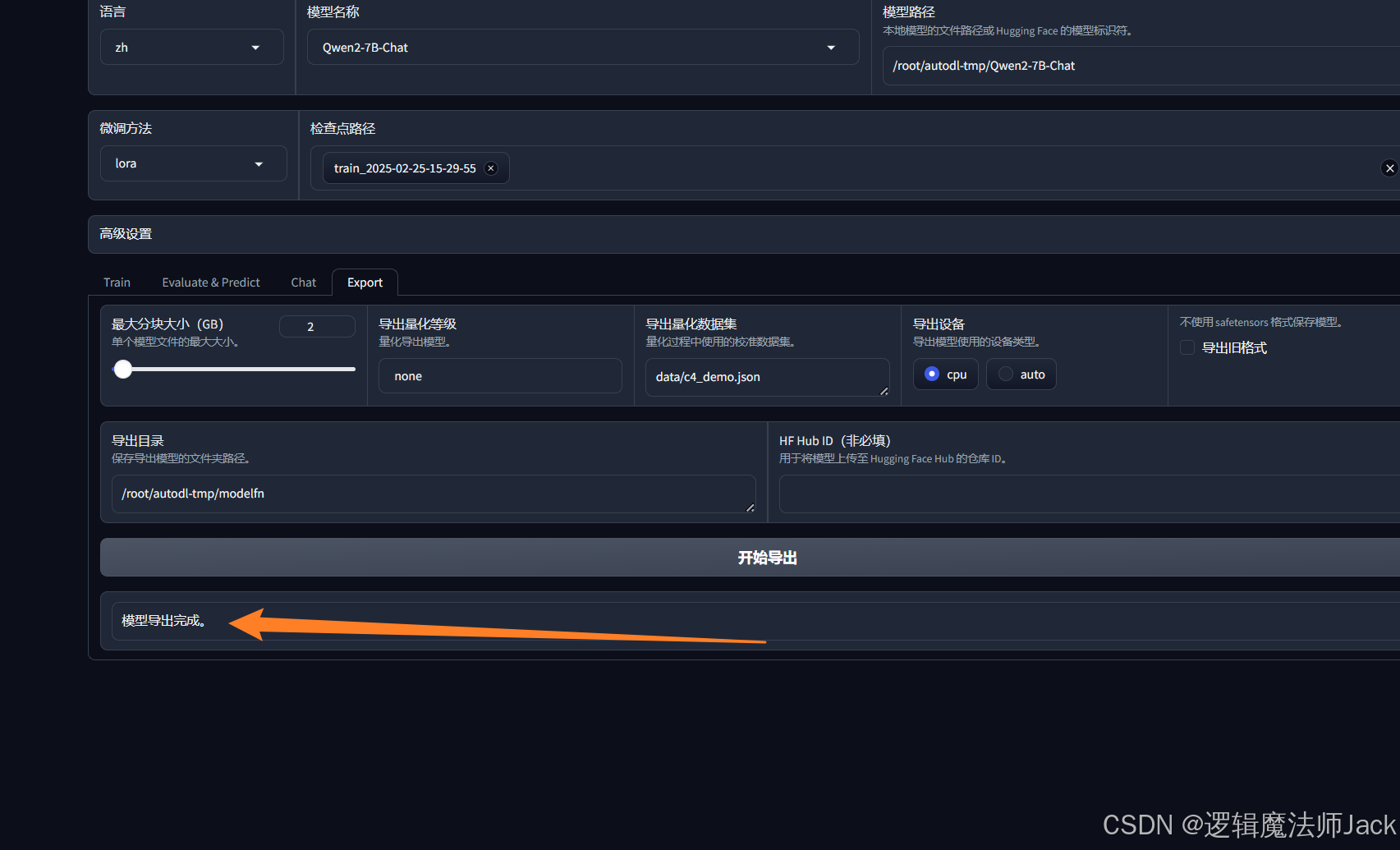
⑤模型导出完成。
最后切记:一定要关闭云服务器,不然会一直扣钱的。

