基于WAN 2.1高性能的文本转视频模型速览:Wan14BT2VFusioniX
Wan2.1_14B_FusionX
一、模型概述
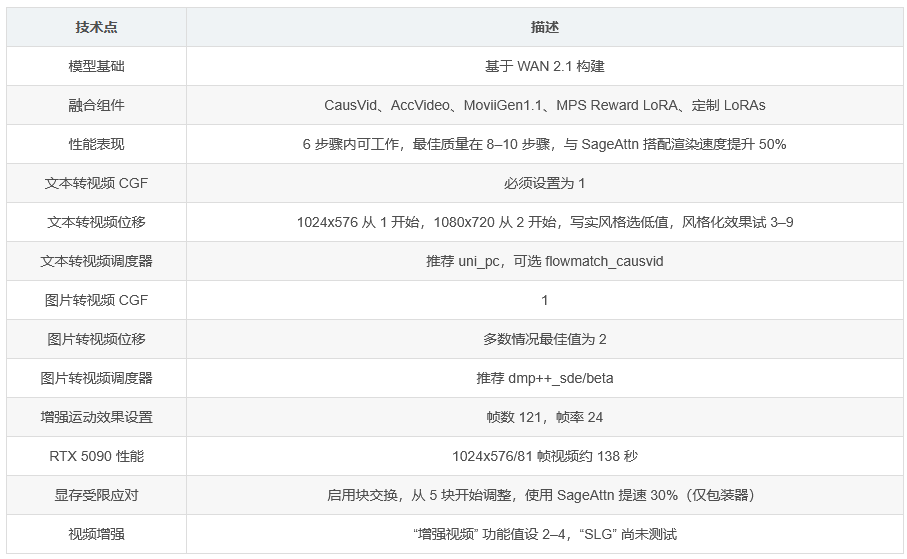
Wan2.1_14B_FusionX 是一种高性能的文本转视频模型,建立在 WAN 2.1 的基础上,并与多个研究级组件融合,以提升视频生成的运动质量、场景一致性和视觉细节。该模型专为 ComfyUI 工作流程优化,能够在 6 步骤内完成快速迭代,即使在仅 8 步骤时也能提供出色的性能表现。
二、技术细节
-
模型融合 :该模型整合了 CausVid(用于因果运动建模,提升流动性和动态效果)、AccVideo(改善时间对齐和加速)、MoviiGen1.1(提供电影般的平滑度和照明效果)、MPS Reward LoRA(针对运动和细节进行调整)以及定制的 LoRAs(增强纹理、清晰度和细节)等多个组件,所有合并模型均采用宽松的开源许可(Apache 2.0/MIT)。
-
性能表现 :在 6 步骤内即可工作,最佳质量出现在 8–10 步骤,可作为 Wan2.1-T2V-14B 的即插即用替代品,与 SageAttn 搭配使用时渲染速度可提升高达 50%,并且支持原生 WAN 工作流程(速度略慢)。
三、使用细节
-
文本转视频 :CGF 必须设置为 1;位移方面,1024x576 分辨率从 1 开始,1080x720 分辨率从 2 开始,追求写实风格时选择较低值,追求风格化效果时可尝试 3–9;推荐使用 uni_pc 调度器,也可选择 flowmatch_causvid(在某些细节上表现更优)。
-
图片转视频 :CGF 为 1,位移在大多数情况下以 2 为最佳,推荐使用 dmp++_sde/beta 调度器,若想增强运动效果并减少慢动作,可将帧数设为 121,帧率设为 24。
四、性能技巧
在 RTX 5090 上,以 1024x576 分辨率和 81 帧生成视频大约需要 138 秒。如果显存有限,可以启用块交换,从 5 个块开始并根据需要调整,使用 SageAttn(仅限包装器)可提速约 30%,但不要使用 teacache。如果要增强视频效果,可尝试 “增强视频” 功能,设置值为 2–4,而 “SLG” 尚未经过测试,可以自行探索。
五、提示词辅助
为了获得更优质的电影效果,可以使用 WAN 电影视频提示词生成器 GPT,它能增加视觉丰富度,对提升质量大有帮助。