Linux《基础IO》
在之前的篇章的当中我们已经学习了进基础的概念以及进程控制相关的概念,那么接下来在本篇当中就可以开始了解LInux当中的基础IO。在此先会通过复习之前C语言当中的文件IO来引入文件系统的相关调用接口,了解了这些接口之后就能理解之前学习的语言当中文件相关本质是如何执行;接下来将了解到文件描述符这一新概念,理解重定向的本质;再对我们之前实现的自主命令行解释器新增重定向的功能,并且还要理解为什么说Linux下一切皆文件,再理解内核缓冲区和文件缓冲区的区别,最后简单设计libc库。一起加油吧!!!

目录
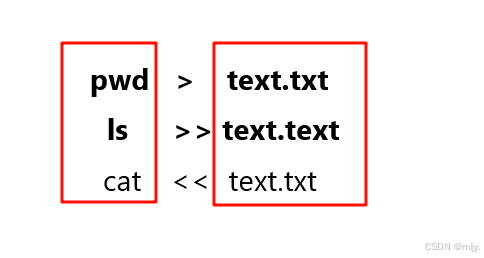
1.理解文件
2.接口回顾
3. 引入I/O系统调用
4. 文件描述符
5. 重定向
6. 给myShell添加重定向功能
完整代码
7. 理解“一切皆为文件”
8. 缓冲区
9. 简单设计libc库
1.理解文件
通过之前的学习知道文件=文件内容+文件属性。当文件内的内容为空时文件也是要占据相应的内存空间,但是文件原本是存储在磁盘当中的,当用户进行相应的文件操作实际上的流程是怎么样的呢?
我们知道在冯诺依曼体系当中CPU是只和内存打交道的,那么原本存储在磁盘当中的文件要进行对应的操作就需要先从磁盘加载到内存上;在该过程当中实现是由操作系统创建对应的进程之后由进程来实现以上的操作,这些进程本质上就是相应的系统调用,而在语言的层面上是通过封装相应恶的系统调用来实现出函数提供给用户使用;例如在C当中的fopen、fwrite、fclose等文件相关大的操作。
但用户可能会同时打开多个文件,那么这就使得需要对打开的文件进行管理,这其实是由操作系统来实现的。在本篇当中本质上了解的是“内存”级的文件,而要了解文件是如何在磁盘当中进行读取的需要等到之后的文件系统篇章中。
2.接口回顾
通过之前的学习我们已经了解了C当中提供的文件相关的操作函数,那么接下来就先复习这些函数的使用,之后再通过这些函数来引入Linux当中文件相关的系统调用。
当以下使用fopen打开一个在当前的路径下不存在的文件,我们知道当使用r方式是会出现报错的,这时需要使用w方式这时就会在当前的路径创建对应文件名的文件
#includeint main(){ FILE* fp=fopen(\"text.txt\",\"w\"); if(fp==NULL) { perror(\"fopen error!\"); } if(fp!=NULL)printf(\"open success!n\\n\"); fclose(fp); return 0;}以上的代码编译为可执行程序之后执行的结果如下:
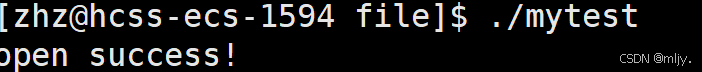
并且在当前的路径下创建出了名为text.text的文件
![]()
在此接下来就可以使用fwrite和fread来对以上创建的text.text文件进行读写的操作,例如以下的代码
#include#includeint main(){ FILE* fp=fopen(\"text.txt\",\"w\"); if(fp==NULL) { perror(\"fopen error!\"); } const char *str1 =\"hello world!\\n\"; int cnt=5; while(cnt--) { fwrite(str1,strlen(str1),1,fp); } fclose(fp); return 0;}以上代码就是使用fwrite来将str1字符串写入到text.txt文件当中,在此写入5次,运行以上代码编译生成的可执行程序之后再查看text.txt就会发现内容确实被写入了
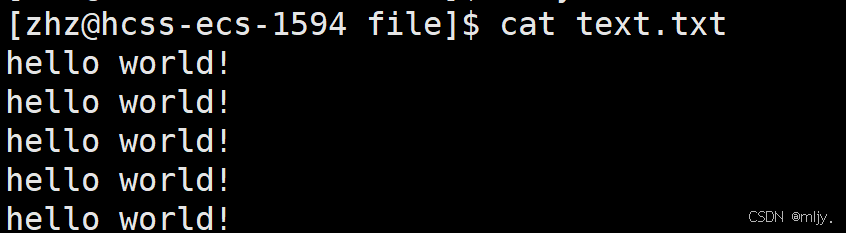
以上向text.tet当中输入了对应的字符串,那么接下来试着使用fread来读取text.tet当中的内存,例如以下的代码:
#include #include int main() { FILE* fp=fopen(\"text.txt\",\"r\"); if(fp==NULL) { perror(\"fopen error!\"); } const char *str1 =\"hello world!\\n\"; char ch[1024]; while(1) { size_t s=fread(ch,1,strlen(str1),fp); if(s>0) { ch[s]=0; printf(\"%s\",ch); } //当读取到文件的末尾时退出 if(feof(fp)) { break; } } fclose(fp); return 0;}以上的代码当中就创建了一个临时的数组来存放从文件当中读取的数据,之后每次使用fread从text.txt当中读取str1长度的字符,fread函数的返回值就是读取到的字符的个数。
以上代码编译为可执行程序之后输出的结果如下所示:
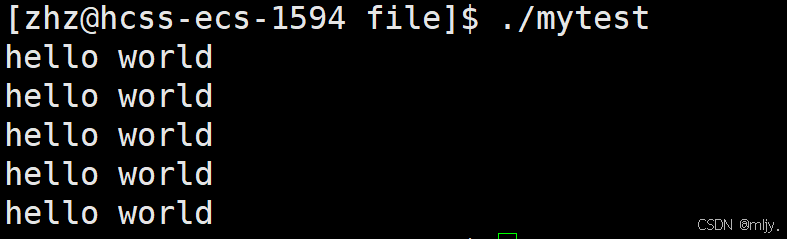
通过以上简单的代码就复习了C当中提供将进行文件操作的函数,我们知道在使用fopen打开文件的时候返回值时是对应的文件流指针。而当未进行任何的文件操作时,系统当中默认就打开了以下的三个标准输入输出流。
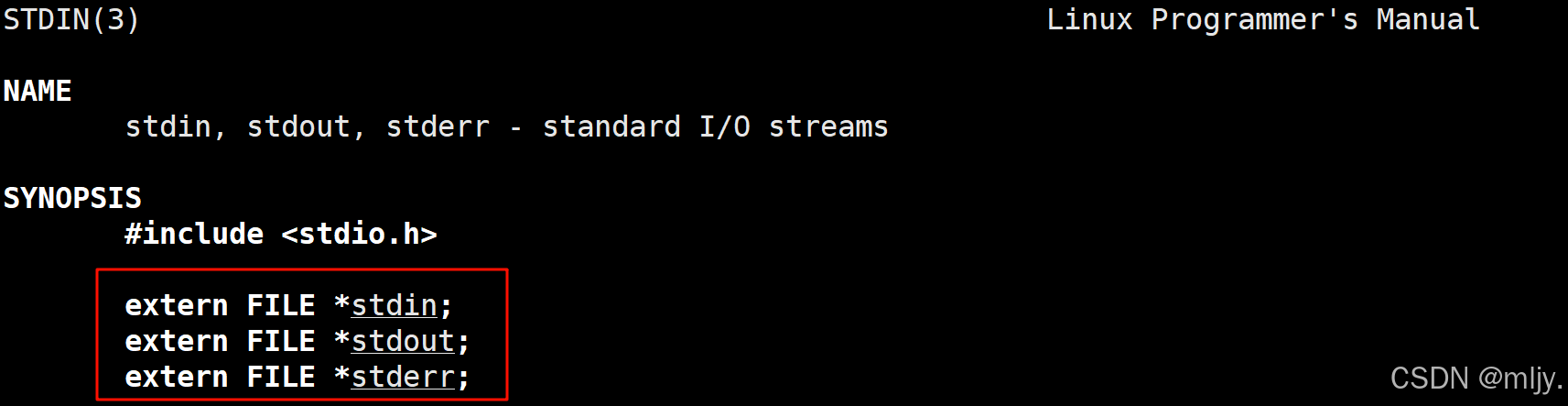
以上得到三个指针分别表示标准输入、标准输出、标准错误。
此时就要思考为什么默认就要把以上的三个文件流指针打开呢?
我们知道程序是用来做数据处理的,那么数据默认的获得和输出途径就应该是键盘和显示器,Linux下一切皆文件,此时将这两个设备对应的文件流指针打开就是便于用户操作的。
3. 引入I/O系统调用
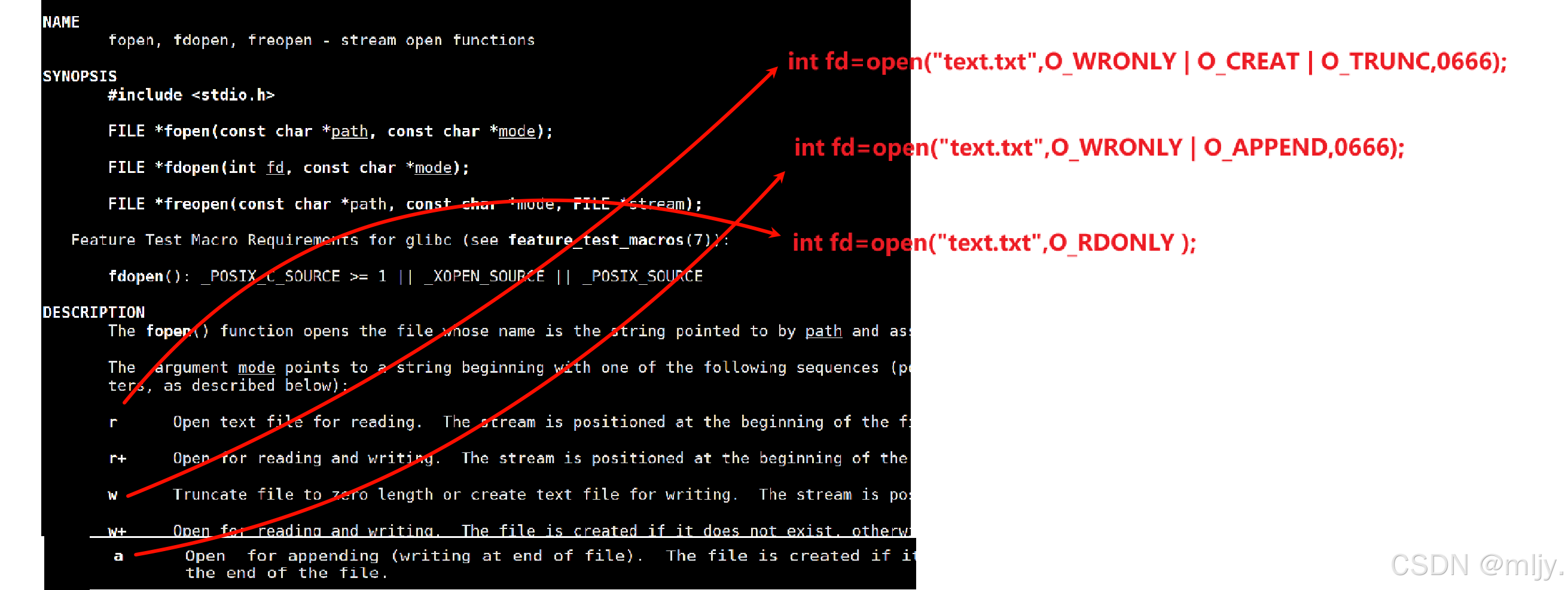
以上提到的fopen函数在打开对应的文件时打开文件的时所带的选项决定了打开文件大的方式,在之前C语言当中的学习知道有以下的打开方式
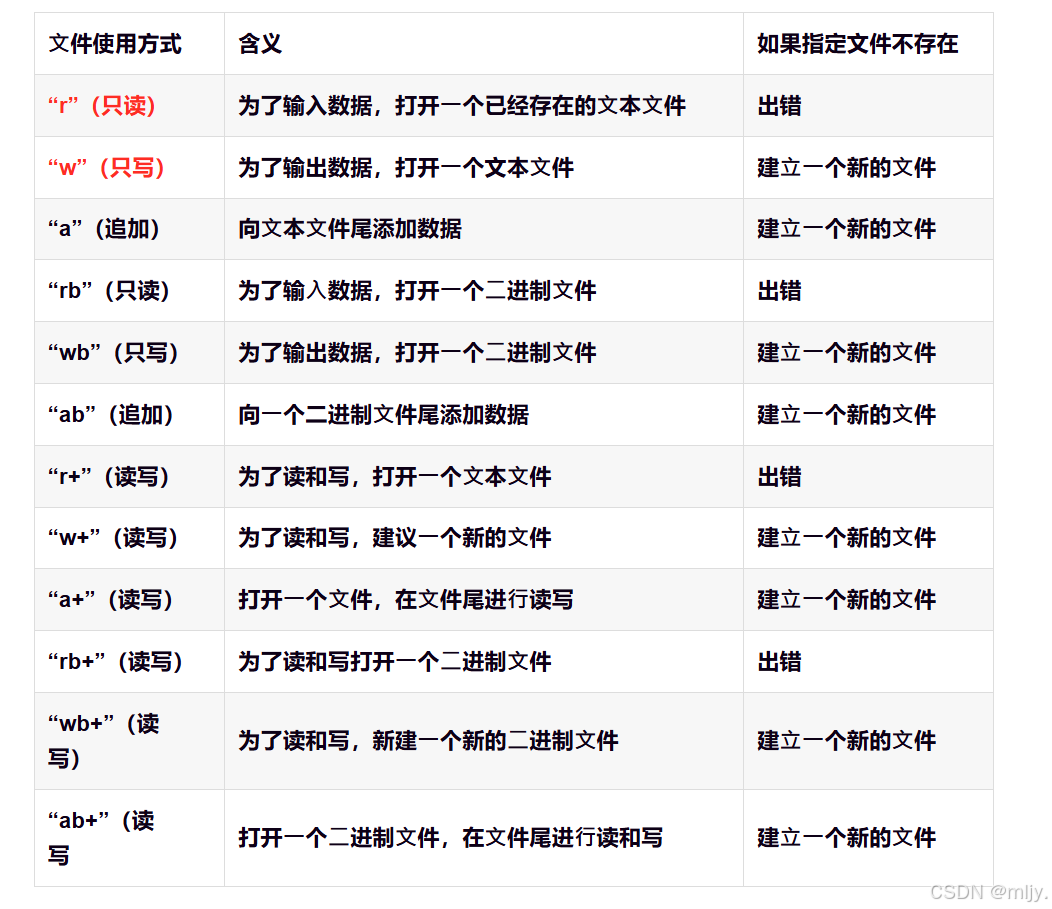
在此我们最常见大的就是使用读、写以及追加的方式进行打开。那么fopen函数内部究竟是如何实现不同的打开方式的呢?
要解答以上的问题就需要了解open系统调用
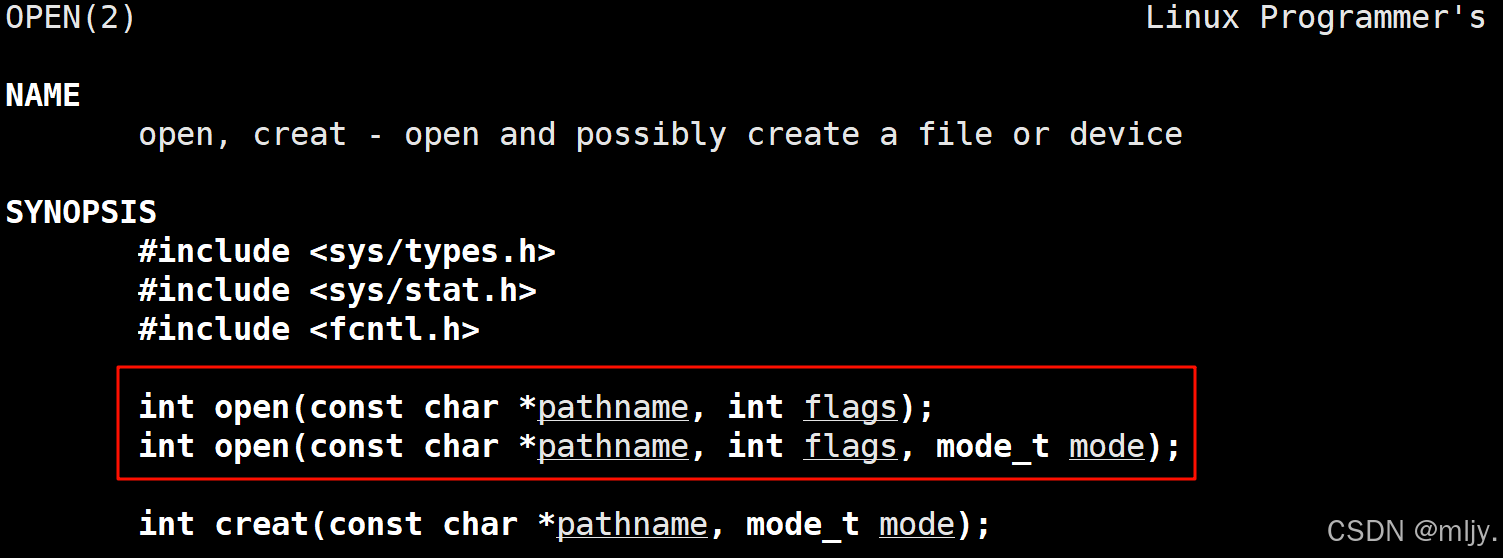
以上通过man手册可以看出open系统调用是有两个的,一个是带mode参数另一个则没有。在此就存在问题了,那就是在C语言当中我们知道是不支持函数重载的,那么以上为了能同时存在两个函数名一样的函数呢?其实在这两个函数本质上是一个函数,这个函数是一个可变参数函数。
那么open系统调用要如何使用呢,其实使用的方式和C语言当中的fopen是非常的类似的,第一个参数都是要打开文件的文件名,之后的第二个参数是要打开文件的标志位,最后一个参数mode是当打开的文件不存在时创建对应文件的权限。
通过man手册就可以看到标志位的传输依靠的是6个宏的,
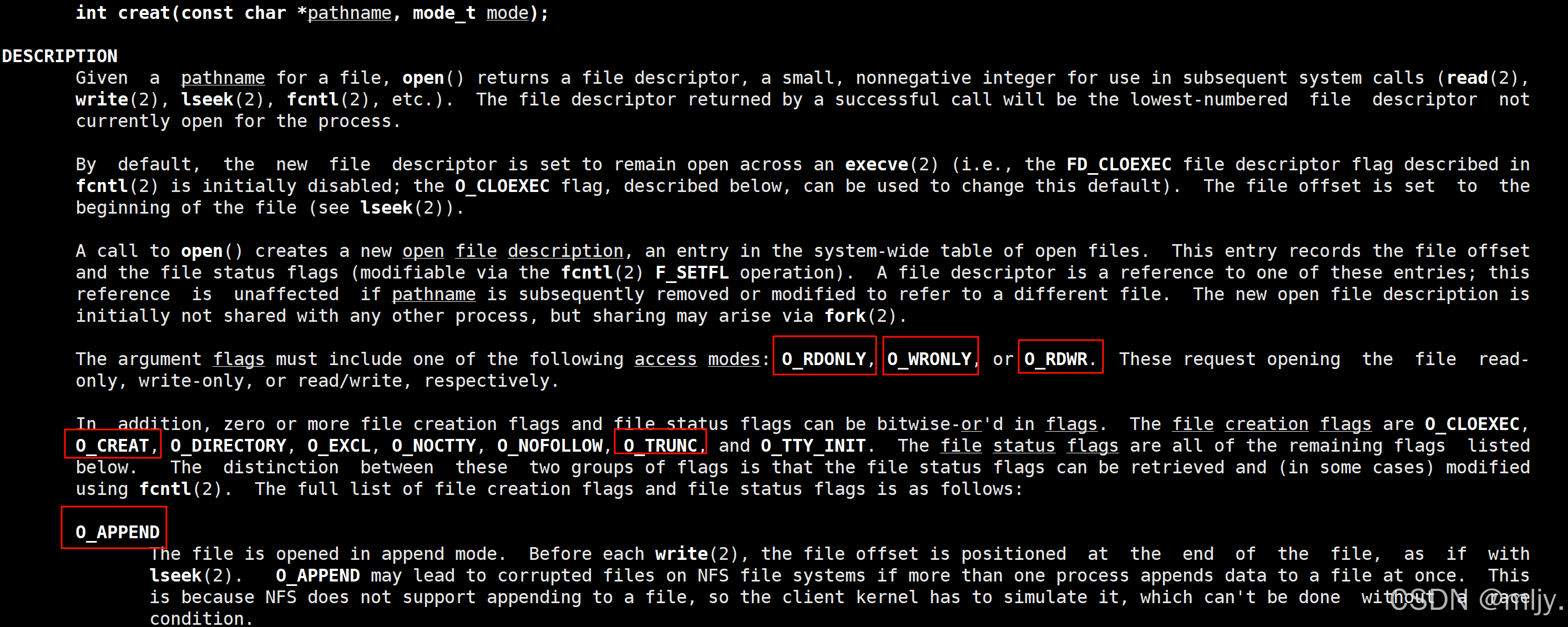
O_RDONLY: 只读打开 O_WRONLY: 只写打开 O_RDWR : 读,写打开 //这三个常量,必须指定⼀个且只能指定⼀个O_CREAT : 若⽂件不存在,则创建它。需要使⽤O_APPEND: 追加写成功:新打开的⽂件描述O_TRUNC:创建文件时将原本文件内的内容覆盖
本质上标志位就是使用了位图的思想,以上的6个宏就可以进行按位或的方式将标记位进行传递,这样就避免了需要使用过多的参数才能实现的问题。
为了更好的理解open系统调用当中的标志位参数是如何传递的,接下来来看以下的实例:
#include#define ONE (1)#define TWO (1<<1)#define THREE (1<<2)#define FOUR (1<<3)void flags(int flag){ if(flag& ONE)printf(\"flag have 1\\n\"); if(flag& TWO)printf(\"flag have 2\\n\"); if(flag& THREE)printf(\"flag have 3\\n\"); if(flag& FOUR)printf(\"flag have 4\\n\"); printf(\"-------------------------------\\n\");}int main(){ flags(ONE); flags(TWO); flags(THREE); flags(FOUR); flags(ONE | TWO); flags(ONE | TWO | THREE); flags(ONE | TWO |THREE |FOUR); return 0;}以上的代码当中创建了4个宏,接下来使用不同的宏进行给flags函数,该函数内就可以得到函数实参当中传递过来的宏包括哪些。
以上代码编译为可执行程序之后输出如下所示:
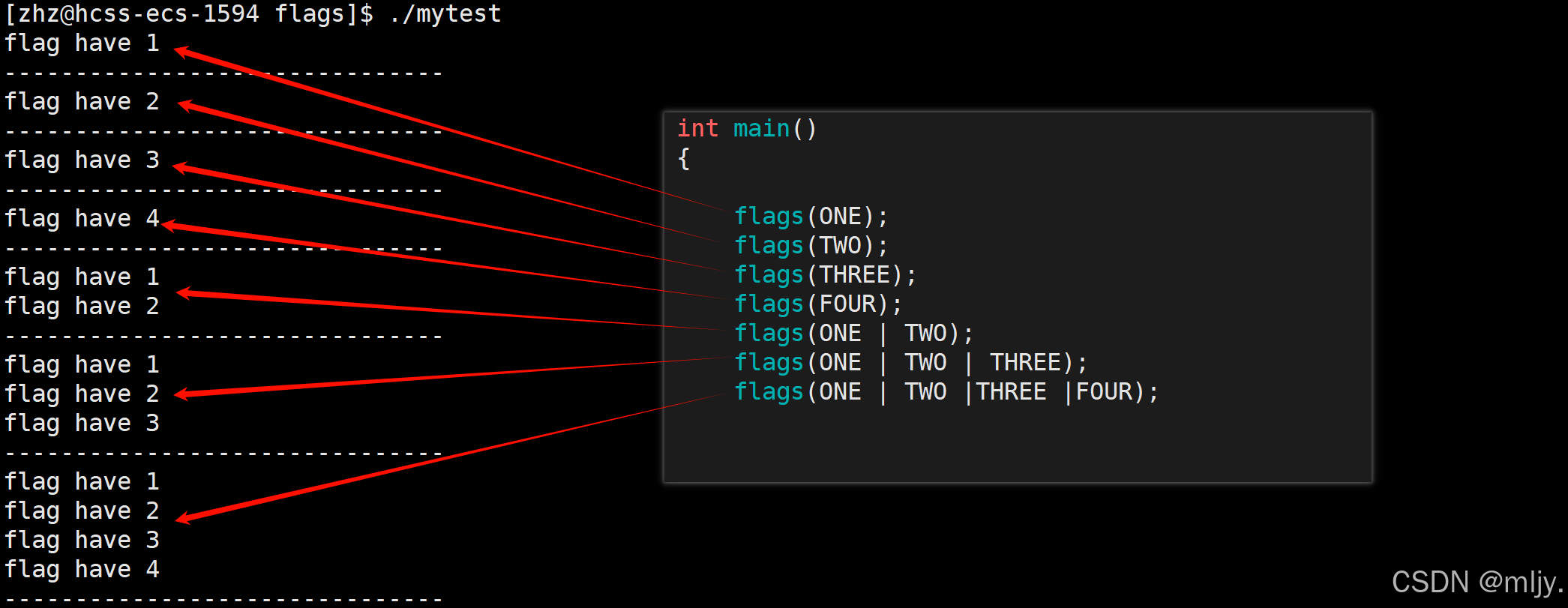
open内标志位实现其实就和以上代码实现的方式类似。
接下来就来使用open系统调用
例如以下的代码:
#include #include #include #include #include #include int main() { int fd=open(\"text.txt\",O_WRONLY | O_CREAT | O_TRUNC); if(fd<0) { perror(\"fopen error!\"); } close(fd); return 0; } 以上代码实现的就是将text.txt文件在当前路径下以写的方式打开,并且创建text.txt文件清空创建。
那么在执行以上的程序时先将原来创建的text.txt删除,之后再执行以上程序看看有什么效果。
注:以上使用到了close关闭文件的系统调用,使用该系统调用的使用需要引用头文件#include
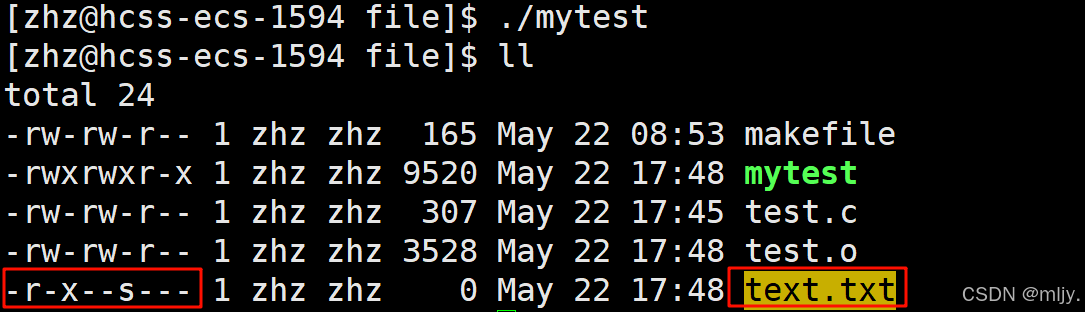
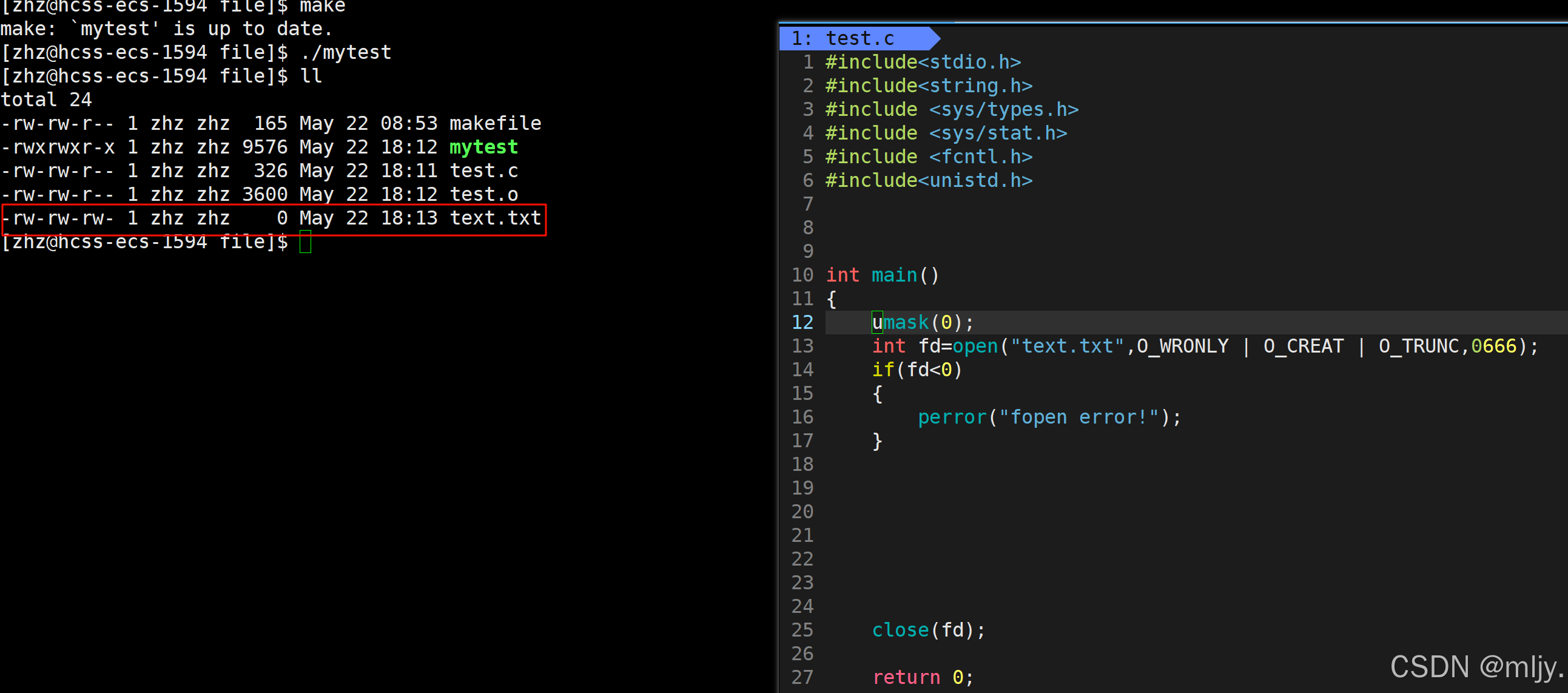
通过使用ll指令就可以看出此时创建的text.txt文件的权限是有问题的,其实这时因为在使用open的时候没有传对应的权限的参数。
将以上的代码修改之后:
#include #include #include #include #include #include int main() { int fd=open(\"text.txt\",O_WRONLY | O_CREAT | O_TRUNC,0666); if(fd<0) { perror(\"fopen error!\"); } close(fd); return 0; } 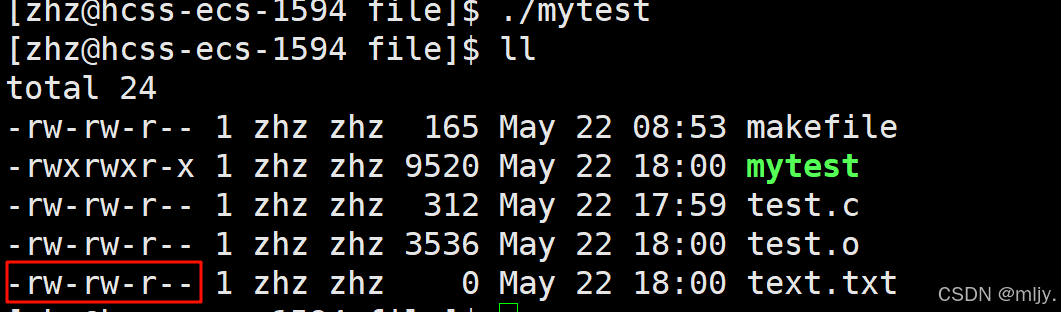
进行以上的修改之后创建出来的text.txt文件的权限就正常了,但是这时还有一个问题就是为什么我们使用open系统调用的时候穿的是权限是666,最终生成出来的文件的权限却是664呢?
其实该问题在之前学习权限相关的知识的时候就已经讲解过了,我们传的权限其实并不是最终生成的文件权限,最终文件的权限=~umask& 起始权限,在此起始权限就是我们传的权限,而umask就是权限掩码。在Linux当中默认的权限掩码是2。
那么如果我们就想在创建对应的text.txt文件的时候umask的值为0,但是又想在其他的进程当中umask的值还是保持为2,那么这时要如何操作呢?
在此就可以使用umask系统调用
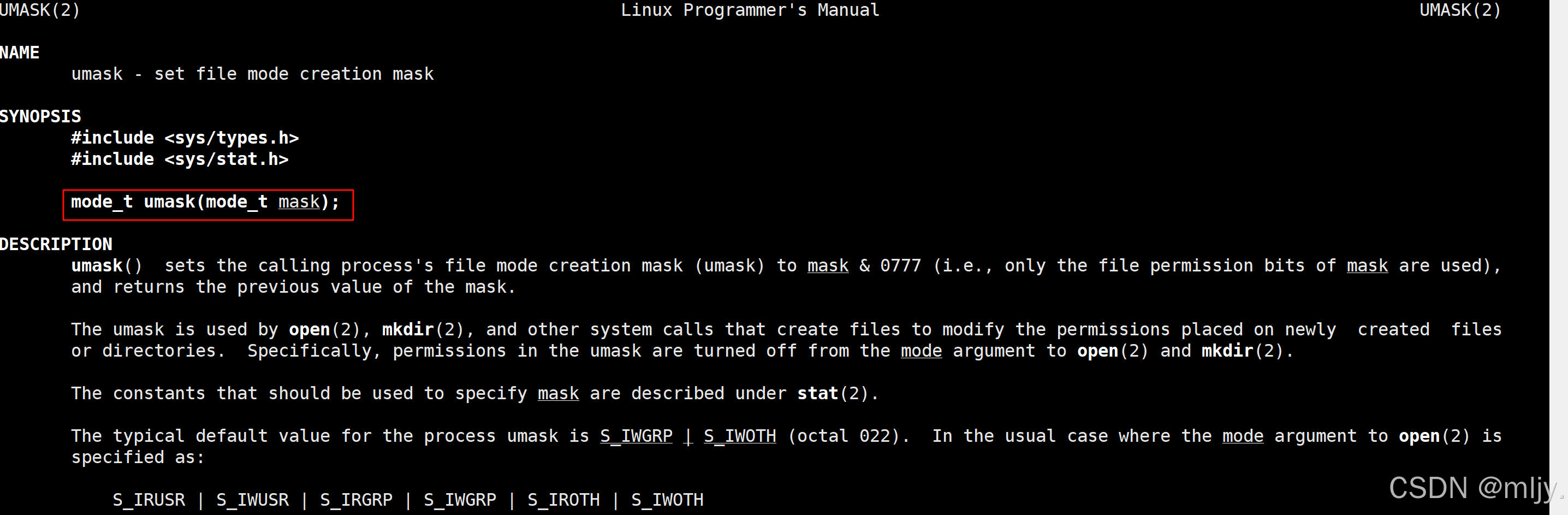
以上使用open系统调用能实现打开对应大的文件,那么如果要对文件进行写入就需要使用到write系统调用。
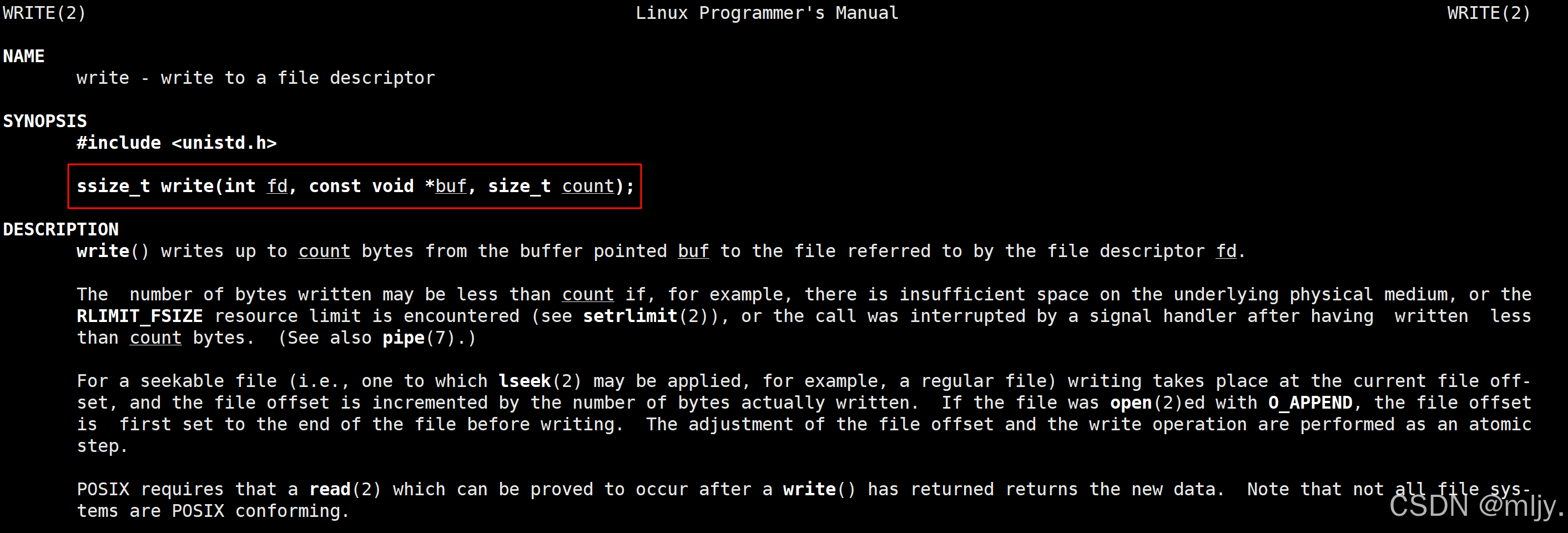
通过以上man手册当中的说明就可以看出write的第一个参数是对应的要进行写入操作的文件调用open的返回值,第二个参数是要进行写入内容的指针,最后一个参数是要进行写入内容的字节数。
以下就是将text.txt文件使用open打开之后在使用write来进行文件的写入
#include #include #include #include #include #include int main() { int fd=open(\"text.txt\",O_WRONLY | O_CREAT | O_TRUNC,0666); if(fd<0) { perror(\"fopen error!\"); } const char* msg=\"hello world\\n\"; int len=strlen(msg); int cnt=5; while(cnt--) { write(fd,msg,len); } close(fd); return 0;}以上就是使用open结合write系统调用来实现打开text.txt文件再向该文件当中写入对应的内容。以上的代码编译为对应的可执行程序之后执行之后text.txt文件当中就可以看到以下的内容

以上代码当中调用open的打开时候方式的标志位是只读、 覆盖式的创建,那么如果要实现打开文件之后追加方式写入,那么这时就需要将标志位修改为 O_WRONLY | O_APPEND
以上的代码修改为向text.txt文件当中实现追加代码如下所示:
#include #include #include #include #include #include int main() { int fd=open(\"text.txt\",O_WRONLY | O_APPEND,0666); if(fd<0) { perror(\"fopen error!\"); } const char* msg=\"hello world\\n\"; int len=strlen(msg); int cnt=5; while(cnt--) { write(fd,msg,len); } close(fd); return 0;}运行以上的代码查看text.txt文件内的内容就会发现进行了追加操作
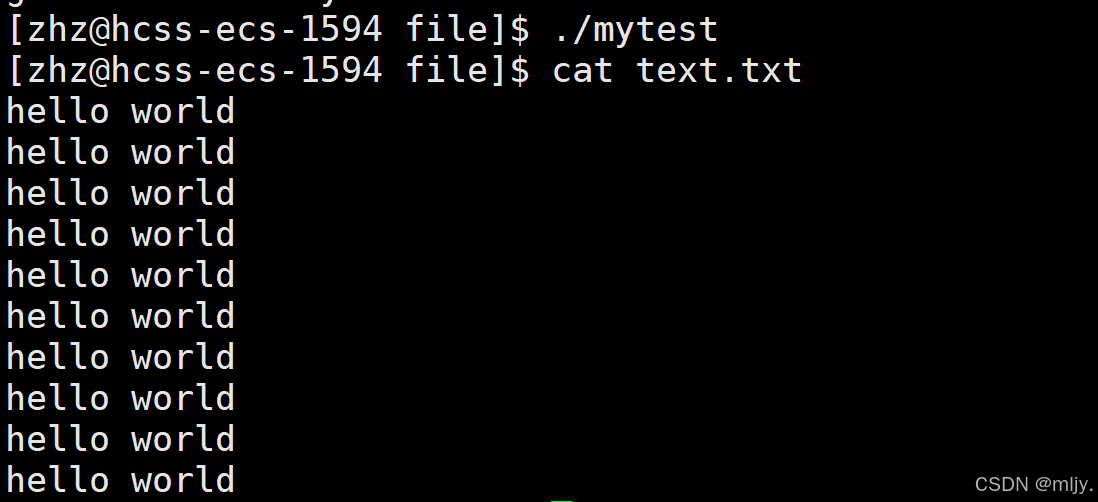
以上是向文件当中写入数据,那么如果要在指定的文本当中读取数据又要使用什么样的系统调用呢?
在此操作系统当中提供了read的系统调用来实现。
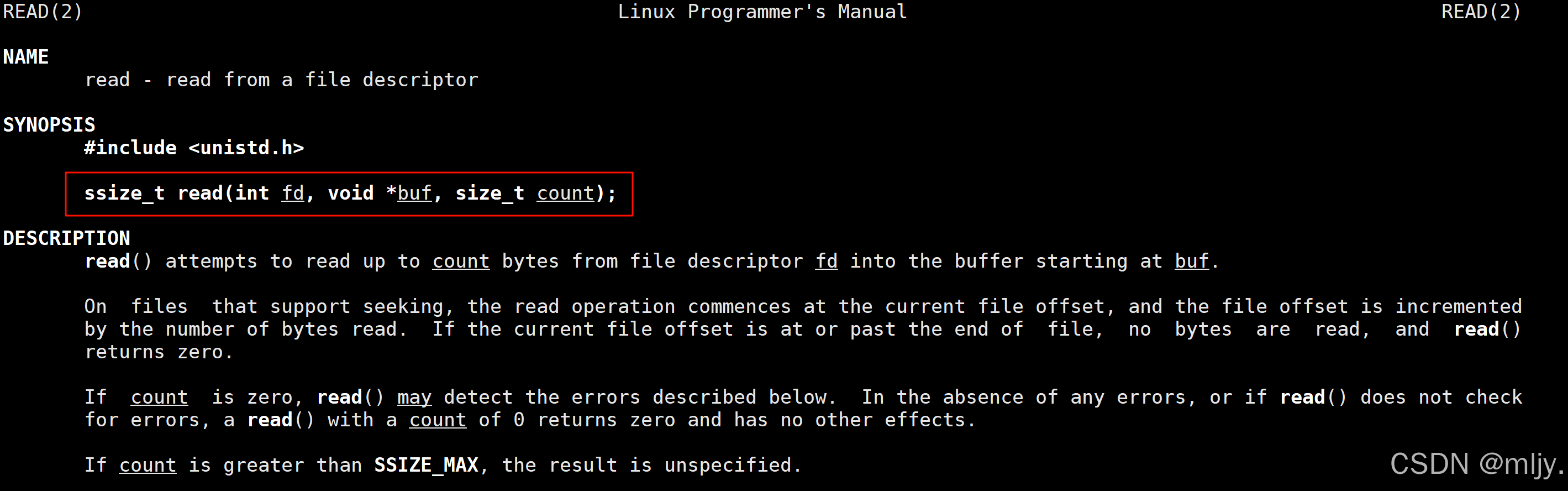
read函数的第一个参数是打开文件返回的值,第二个参数是要从文件当中读取数据存放的临时内存的指针,最后一个参数是读取的数据的字节数。
该系统调用的返回值为读取文件得到的字节数,当读取失败的时候返回值为-1

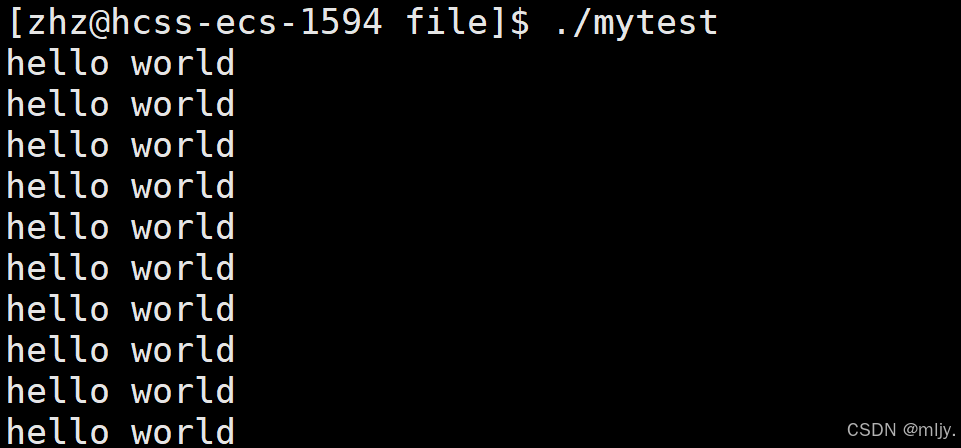
以上示例当中对之前我们创建的text.txt函数来实现读取 :
#include #include #include #include #include #include int main() { int fd=open(\"text.txt\",O_RDONLY ); if(fd0)printf(\"%s\",buffer); else break; } close(fd); return 0;}以上代码编译为可执行程序之后输出结果如下:
以上我们就了解了Linux当中进行文件操作的系统调用,那么了解了这些系统调用之后就可以理解C当中给我们实现的关于文件的操作是如何实现的,其实本质上C当中使用的文件相关的函数就是封装了操作系统当中提供的系统调用。
例如fopen就是封装了open系统调用,而fope能实现不同的方式打开文件其实是不同打开方式的fopen函数的封装的open的flags参数不同,在fopen当中当用户传入的打开方式参数是w时封装的open当中flags参数实参就为O_WRONLY | O_CREAT | O_TRUNC,当用户是以a方式打开的时候,open当中flags参数实参就为O_WRONLY | O_APPEND,当用户以r方式打开的时候open当中实参就为O_RDONLY。
除了fopen之外,fclose就是封装为了open实现的,而在C语言当中在对文件进行写入或者是读取的时候是有很多的方式的,有按照文本方式写入的,还有按照二进制进行写入的;其实这些函数本质上但是调用了write该系统调用,write都是按照二进制的方式进行写入的,而那些不同的写入方式是语言层上提供的。
其实C/C++等的语言在不同的操作系统当中其库函数封装底层的系统调用都是不一样的,但是表层提供给用户的函数接口都是一样的,这些语言这样做的原因是为了提高其在不同平台的兼容性;这样就可以使得同一份的代码在不同的平台下都能可以正常的运行,这样可以使得用户群体更加的多样。语言通过封装系统调用来实现各种功能这就是运用了面向对象的三大特点其中的封装。
4. 文件描述符
以上我们使用到open系统调用的时候返回值fd是什么呢?要解答该问题就需要了解文件描述符的概念
我们知道操作系统当中是默认打开三个标准输入输出流的,而通过之前的学习知道使用fopen的时候其返回值本质上是结构体指针。在该结构体当中存在一个名为fileno的变量其实该变量就是文件描述符。
接下来来看以下的代码:
#include #include #include #include #include int main() { printf(\"stdin->%d\\n\",stdin->_fileno); printf(\"stdout->%d\\n\",stdout->_fileno); printf(\"stderr->%d\\n\",stderr->_fileno); return 0;} 以上就通过访问三个标准输入、输出流当中的fileno变量,看看有什么特点

通过输出就可以看出标准输入对应的文件描述符是0,标准输出默认的文件描述符是1,标准错误默认的文件描述符是2。
那么是不是就是说明操作系统当中文件描述符是从0开始的呢?
确实是这样的,有了这么长时间的编程经历看到以0为开始的结构我们马上就能想到数组,其实以上提到的文件描述符本质上就是数组的下标。
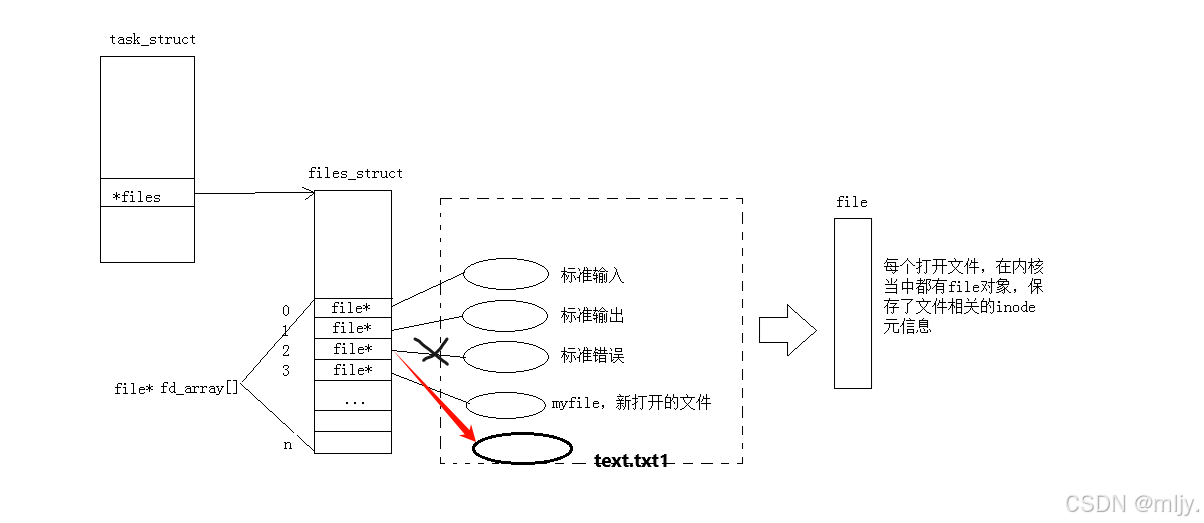
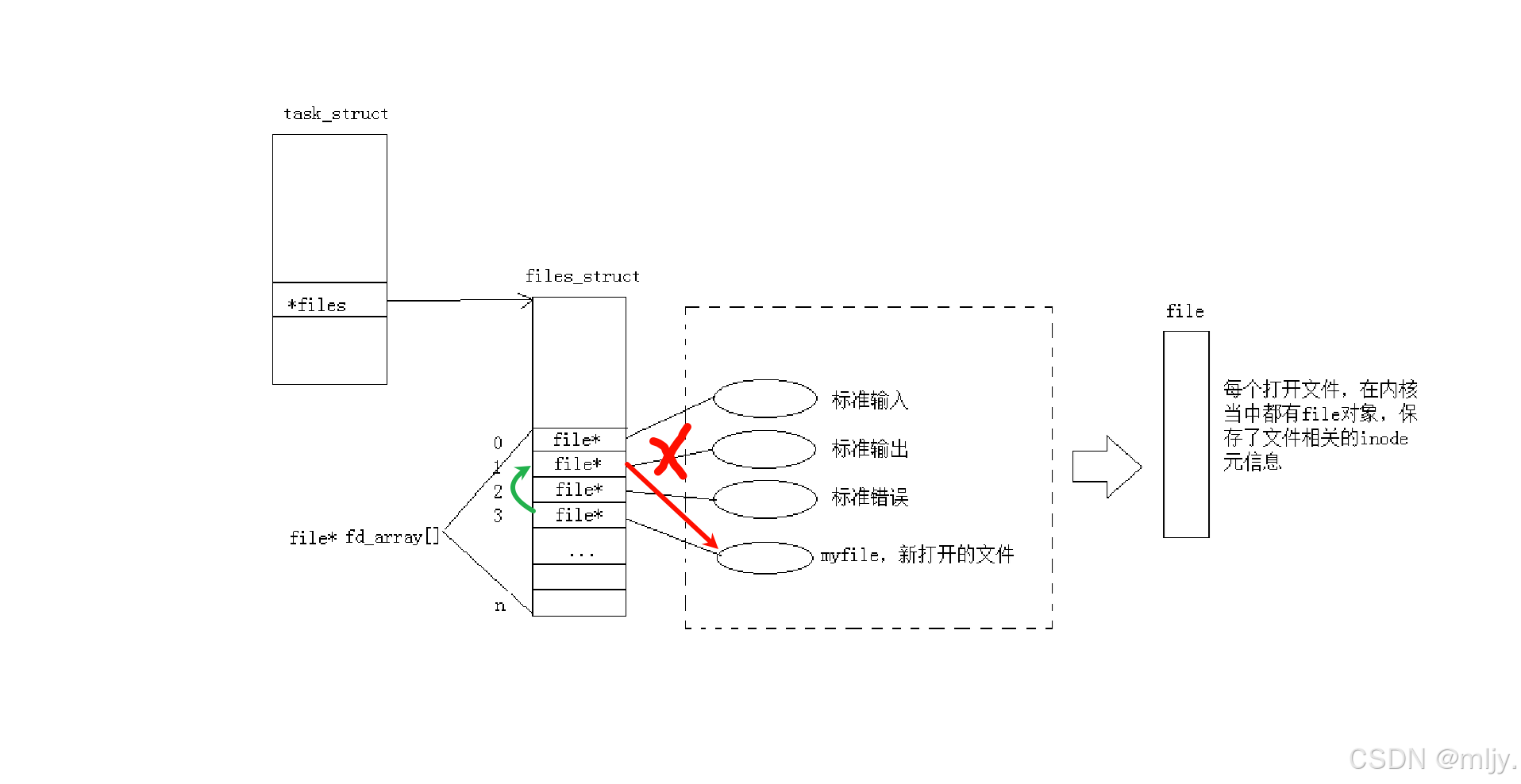
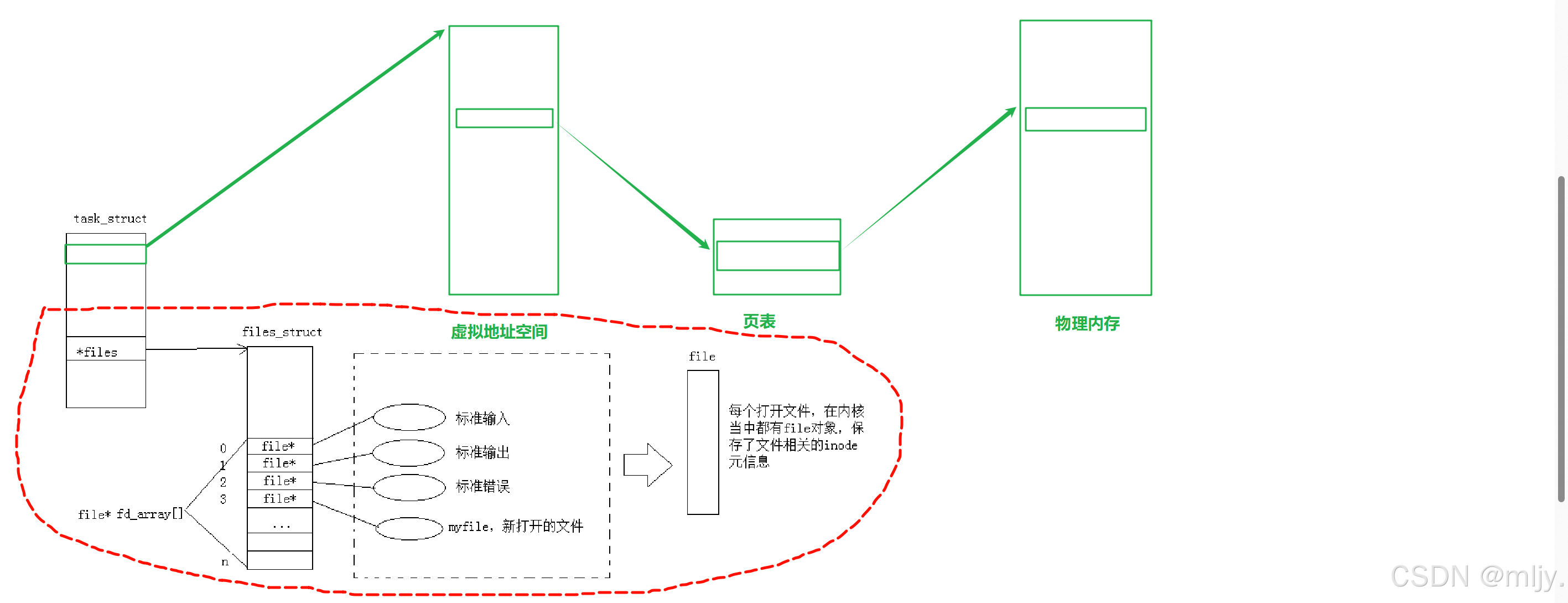
其实当对应的进程打开文件之后在操作系统内存当中就会为每个文件产生相应的文件file对象,该结构体内存储了文件的相关内容以及属性。和之前我们学习进程的管理类似操作系统对文件的管理也是先描述再组织,那么创建file结构体的对象就是进行先描述,那么之后再进行再组织这些结构体对象其实是通过数组来实现的;在操作系统当中对于每个进程都会有一个文件描述符表,其本质就是一个指针数组, 每个数组的元素就是一个指向file的指针。
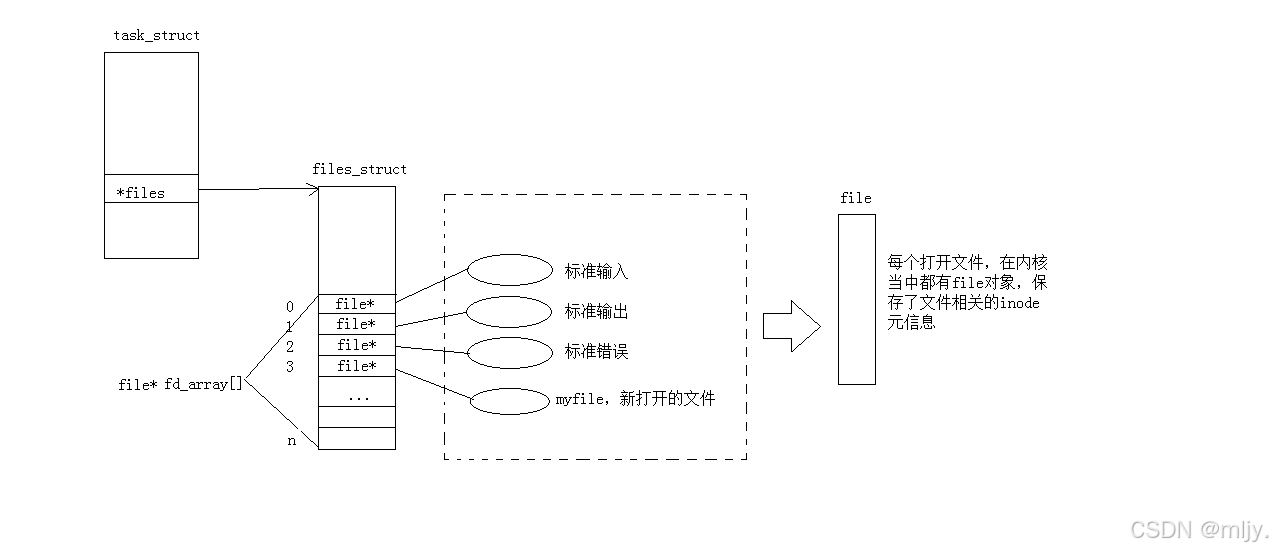
以上提到的文件描述符表的指针存储对应进程的task_struct当中。当在进程当中打开其他的文件时会从下标3开始将对应的文件的指针填充在数组上,这样就可以将新打开的文件也进行先描述再组织。
5. 重定向
接下来来看以下的代码:
先在当前路径下创建text.txt1、text.txt2、text.txt3文件
#include #include #include #include #include #include int main() { printf(\"stdin->%d\\n\",stdin->_fileno); printf(\"stdout->%d\\n\",stdout->_fileno); printf(\"stderr->%d\\n\",stderr->_fileno); int fd1=open(\"text.txt1\",O_RDONLY ); int fd2=open(\"text.txt2\", O_RDONLY); int fd3=open(\"text.txt3\",O_RDONLY ); printf(\"fd1->%d\\n\",fd1); printf(\"fd2->%d\\n\",fd2); printf(\"fd3->%d\\n\",fd3); printf(\"fd1->%d\",fd1); printf(\"fd2->%d\",fd2); printf(\"fd3->%d\",fd3); close(fd1); close(fd2); close(fd3); return 0;}以上代码输出的结果如下所示:
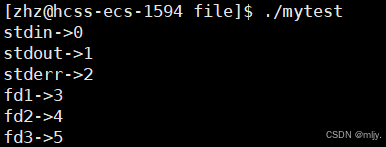
以上我们依次打开text.txt1,text.txt2,text.txt3那么就会依次将这几个文件的file对象指针填到文件描述表当中。
那么这是就有一个点值得思考了,那就是如果在以上的代码当中分别将标准输入输入、标准输出和标准错误关闭会行打开的文件的文件描述符又会有什么特点呢?
1.将标准输入关闭
#include #include #include #include #include #include int main() { close(0); printf(\"stdin->%d\\n\",stdin->_fileno); printf(\"stdout->%d\\n\",stdout->_fileno); printf(\"stderr->%d\\n\",stderr->_fileno); int fd1=open(\"text.txt1\",O_RDONLY ); int fd2=open(\"text.txt2\", O_RDONLY); int fd3=open(\"text.txt3\",O_RDONLY ); printf(\"fd1->%d\\n\",fd1); printf(\"fd2->%d\\n\",fd2); printf(\"fd3->%d\\n\",fd3); printf(\"fd1->%d\",fd1); printf(\"fd2->%d\",fd2); printf(\"fd3->%d\",fd3); close(fd1); close(fd2); close(fd3); return 0;}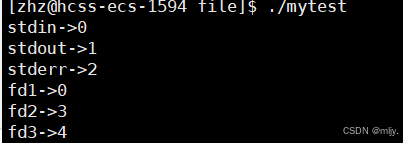
2.将标准输出关闭
#include #include #include #include #include #include int main() { close(1); printf(\"stdin->%d\\n\",stdin->_fileno); printf(\"stdout->%d\\n\",stdout->_fileno); printf(\"stderr->%d\\n\",stderr->_fileno); int fd1=open(\"text.txt1\",O_WRONLY ); int fd2=open(\"text.txt2\", O_RDONLY); int fd3=open(\"text.txt3\",O_RDONLY ); printf(\"fd1->%d\\n\",fd1); printf(\"fd2->%d\\n\",fd2); printf(\"fd3->%d\\n\",fd3); return 0;}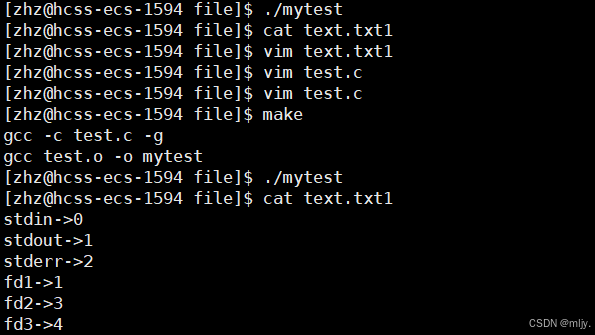
3.将标准错误关闭
#include #include #include #include #include #include int main() { close(2); printf(\"stdin->%d\\n\",stdin->_fileno); printf(\"stdout->%d\\n\",stdout->_fileno); printf(\"stderr->%d\\n\",stderr->_fileno); int fd1=open(\"text.txt1\",O_WRONLY ); int fd2=open(\"text.txt2\", O_RDONLY); int fd3=open(\"text.txt3\",O_RDONLY ); printf(\"fd1->%d\\n\",fd1); printf(\"fd2->%d\\n\",fd2); printf(\"fd3->%d\\n\",fd3); return 0;}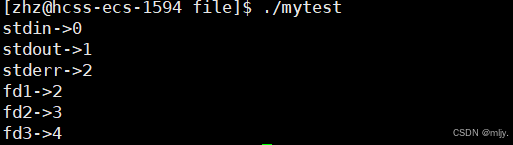
注:以上在打开文件的之后未将文件使用close关闭是因为关闭文件之后出现的现象就需要使用到缓冲区的概念来解释,但是当前缓冲区的概念我们还未了解,依因此在此就不使用close。
通过以上的三段代码就可以看出当出现小位置的文件描述符未被使用的时候,新打开的文件分配的文件描述符就会从小的开始分配。因此打开新的文件时分配的文件描述符的原则是:分配未被使用的且是最小的。
了解了以上的概念之后,在此就可以引入重定向的原理了,其实重定向就是改变原本进程当中的文件描述符表内数组下标对应的元素。
以上的代码1当中就是将原本文件描述符表当中的0下标内的指针修改为text.txt1文件file指针。
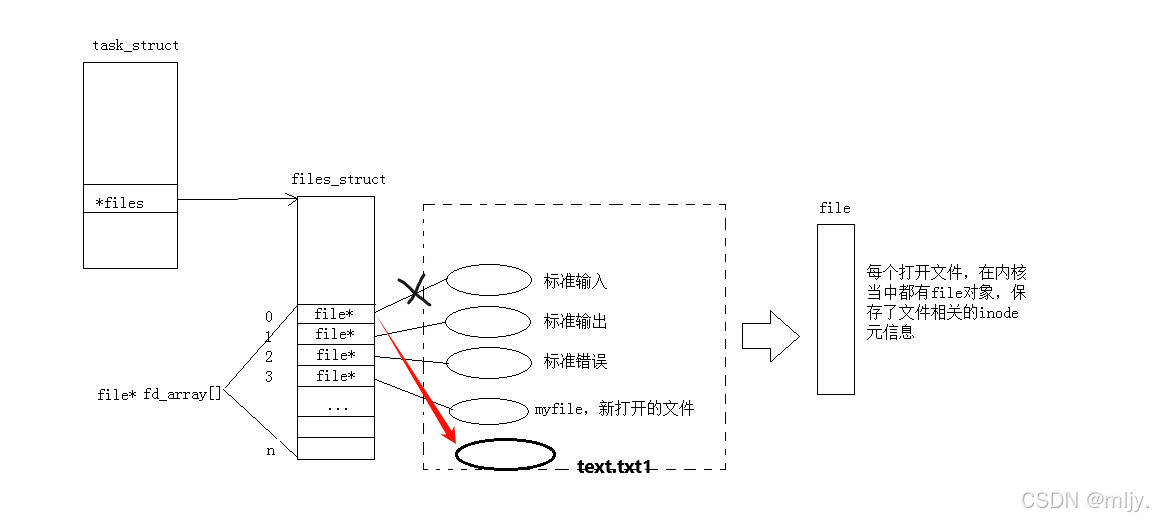
以上的代码1当中就是将原本文件描述符表当中的1下标内的指针修改为text.txt1文件file指针。
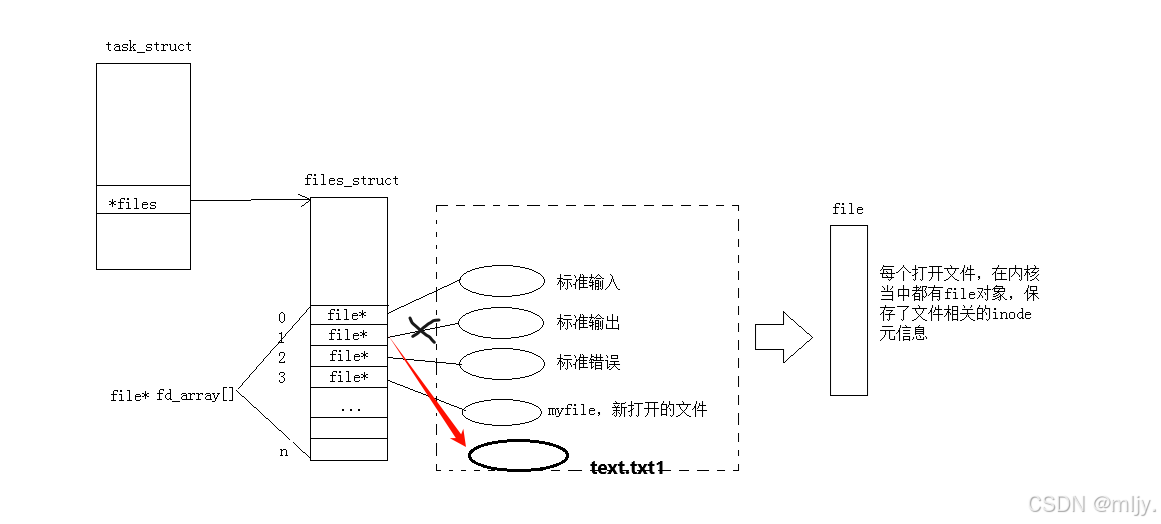
以上的代码1当中就是将原本文件描述符表当中的2下标内的指针修改为text.txt1文件file指针。
以上我们通过先关闭对应文件的方式确实是能实现重定向的,但是其实一般是不会使用这种方式的,而是使用系统调用dup2
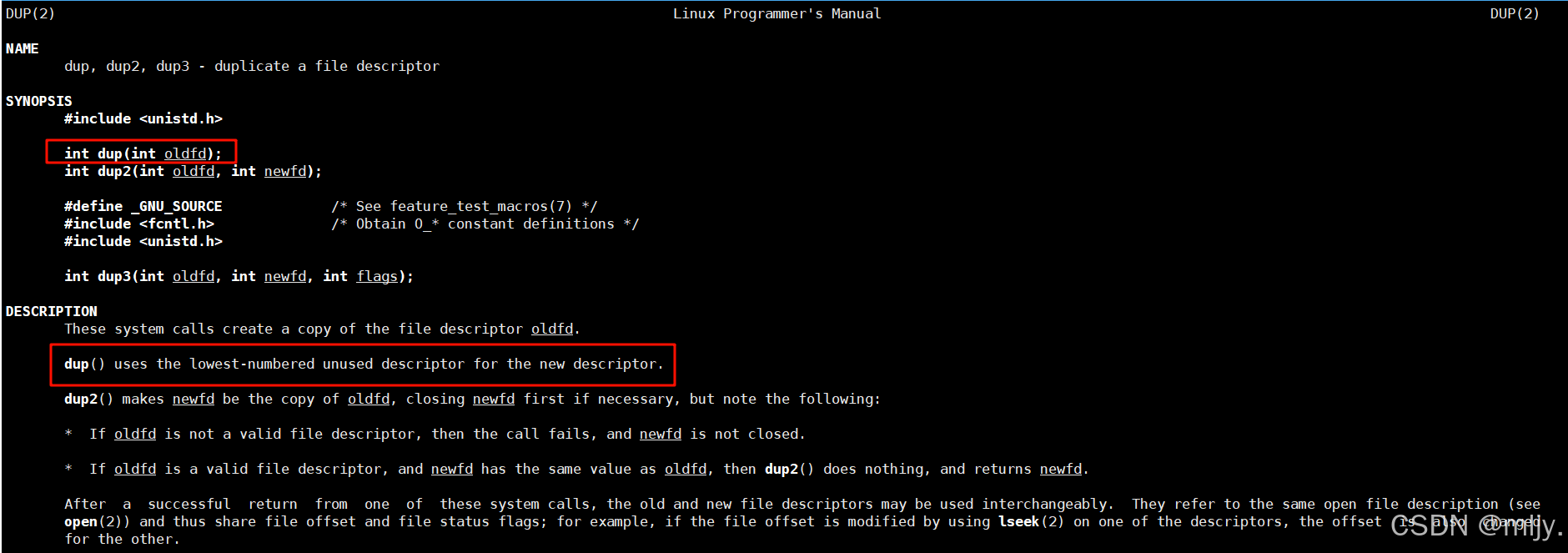
通过man手册当中就可以看到,dup系统调用实现的是将文件描述符表当中oldfd下标的内的指针拷贝到newfd下标当中。
例如以下示例:
#include #include #include #include #include #include int main() { int fd1=open(\"text.txt1\",O_WRONLY ); int fd2=open(\"text.txt2\", O_RDONLY); int fd3=open(\"text.txt3\",O_RDONLY ); dup2(fd1,1); printf(\"fd1->%d\\n\",fd1); printf(\"fd2->%d\\n\",fd2); printf(\"fd3->%d\\n\",fd3); return 0;} 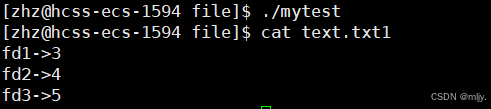
以上的代码就先打开三个文件之后再将文件描述符为1的数组下标内的指针修改为text.txt1文件的file对象指针,此时程序原本要输出到显示器上的内容就会输出到text.txt1文件当中。
那么有了dup2系统调用,就可以使用dup2要将标准输出对应的文件描述符的下标内容替换指定的file指针
例如以下的代码:
#include #include #include #include #include #include int main() { int fd1=open(\"text.txt1\",O_WRONLY ); dup2(fd1,1); printf(\"fd1->%d\\n\",fd1); return 0;}以上的代码当中就将新打开大的text.txt1对应的文件file指针将文件描述符表当中1下标的内容覆盖。
在之前的学习当中我们已经了解过了输出重定向,输入重定向和追加重定向是如何使用的,那么结合本篇当中以上的学习就有一个疑惑了,那就是默认的标准输出和标准错误都是向显示器当中输出,那么这时为什么还要有标准错误呢?不是直接使用一个标准输出就可以实现了吗?
其实在一般的情况下标准输出和标准错误输出的都是显示器文件,但是可以使用重定向来将常规的输出消息和错误的消息进行分离,就例如计算机或者是服务器当中错误都是写入到日志当中的,其实现的原理就是将原本要输出到显示器上儿童通过重定向来输出到指定的文件当中。
例如以下的代码:
#include #include int main() { std::cout<<\"hello cout\"<<std::endl; printf(\"hello printf\\n\"); std::cerr<<\"hello cerr\"<<std::endl; fprintf(stderr,\"hello stderr\\n\"); return 0; } 以上的代码当中就分别使用C和C++当中的方法向标准输出和标准错误当中输出了数据,将以上代码编译为可执行程序之后输出的内容如下所示:
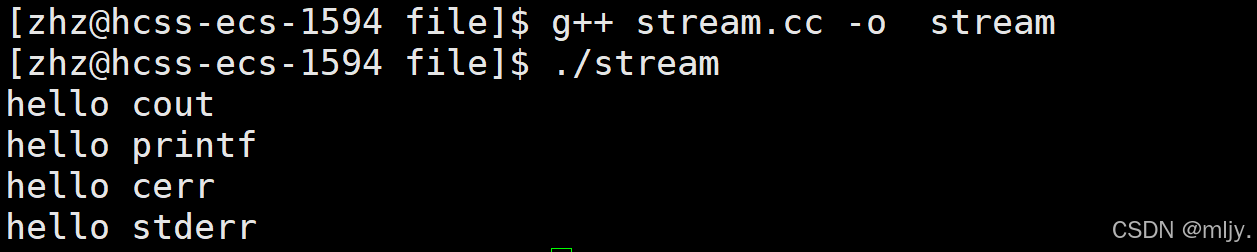
如果要将以下程序输出的结果输入到指定的文件当中我们知道可以使用到>来实现
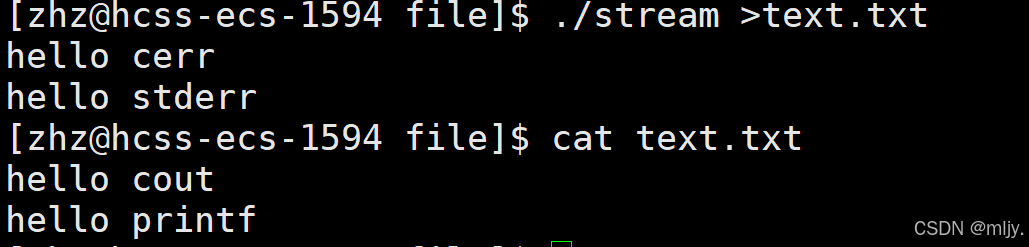
以上我们将stream执行的内容输出到了text.txt文件当中,但是为什么以上还是会在显示器当中就输出到标准错误当中的内容显示到显示器当中呢?
要解答以上的问题就需要了解输出重定向的本质,实际上在使用 > 输出重定向时,其实本质上执行的是 可执行程序 1 > 指定的文件。以上的命令本质上执行的是 ./stream 1 > text.txt 也就是将原本要要输出到标准输出文件当中的内容输出到指定的文件当中,但是这时原来我们的代码当中还有两句代码是要输出到标准错误当中的,标准错误对应的文件描述符是2;因此执行以上的指令还是会将标准错误的内容输出到显示器上。
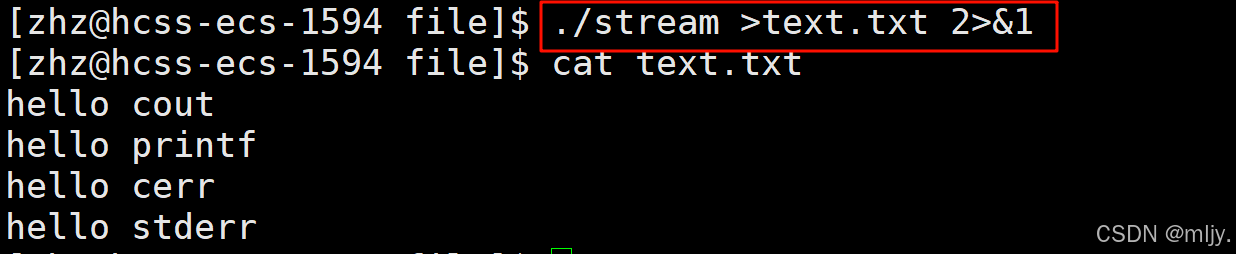
那么如果要将标准错误的内容也输出到text.txt当中,那么这时要怎么操作呢?
在此有两种方式可以解决;第一种是使用追加重定向的方式就标准错误的内容追加到文件当中

第二种是直接将文件描述符表当中1下标当中的内容覆盖到下标为2当中
6. 给myShell添加重定向功能
通过以上的学习我们已经了解了重定向实现的原来,那么接下来就试着来给之前实现的myshell添加上重定向的功能,让用户可以在命令行当中将程序执行的结果输出到指向的文件当中。
要给给myshell当中添加重定向的功能,那么就需要在获取到用户输入的内容之后再进行是否要进行重定向的分析,以下就再RedirCheck函数当中使用对应的功能。
当用户再命令行当中输入重定向的指令之后其实是可以将用户的指令分为以下的两个部分的
分别是重定向符之前的内容以及重定向符之后的内容,那么此时就需要创建一个字符串来存储指令后半部分的内容。
那么如何让原本输出到标准输入或者从标准输入当中读取替换为使用重定向符之后的文件当中进行读取或者输出呢?
要实现以上的功能就需要在原本执行程序的函数当中在使用fork创建子进之前打开对应的文件之后再使用dup2来实现重定向。
因此先在原本的代码当中添加以下的代码
//创建表示不同重定向的宏 //无需重定向 #define NONE_ENDIR 0 //输入重定向 #define INPUT_REDIR 1 //输出重定向 #define OUTPUT_DEDIR 2 //追加重定向 #define APPEND_REDIR 3 //存储用户输入的重定向的类型 int redir=NONE_ENDIR;//存储要进程重定向的文件std::string filename; 接下来就可以试着来对用户读取的指令当中判断是否要进行重定向的操作
//清空重定向符之后的空格void TrimSpace(char* cmd,int &end){ while(isspace(cmd[end])) { end++; }}//重定向分析void RedirCheck(char* cmd){ //将上一次获取重定向的数据清除 redir=NONE_ENDIR; filename.clear(); //遍历用户输入的字符串,判断对应的重定向类型 int start=0; int end=strlen(cmd)-1; while(start<end) { //输入重定向 if(cmd[end]==\'\') { //输出重定向 if(cmd[end-1]==\'>\') { cmd[end-1]=0; redir=APPEND_REDIR; } //追加重定向 else{ redir=OUTPUT_DEDIR; } cmd[end++]=0; //清空重定向符之后的空格 TrimSpace(cmd,end); filename=cmd+end; } else{ end--; } }}注:以上使用到open就需要在代码当中添加上头文件 和
以上在实现了重定向的分析之后接下来就需要在执行原来的命令当中在子子进程当中实现重定向的功能。
//创建子进程执行命令int Execute(){ //创建子进程 pid_t pid=fork(); if(pid==0) { int fd=-1; //判断用户执行的重定向类型 if(redir==INPUT_REDIR) { //输入重定向以读的方式打开filename文件 fd=open(filename.c_str(),O_RDONLY); if(fd<0)exit(1); dup2(fd,0); close(fd); } else if(redir==OUTPUT_DEDIR) { //输出重定向以写的方式打开文件 fd=open(filename.c_str(),O_CREAT | O_WRONLY |O_TRUNC,0666); if(fd<0)exit(1); dup2(fd,1); close(fd); } else if(redir==APPEND_REDIR) { //追加重定向以写并且追加的方式打开文件 fd=open(filename.c_str(),O_CREAT | O_WRONLY | O_APPEND,0666); if(fd0) { //设置进程退出码lastcode值 lastcode=WEXITSTATUS(status); } return 0;}在实现了以上的代码之后就有一个问题需要思考了,那就是在进行进程替换之前进行的重定向会不会因为进程替换的而影响呢?
答案是不会的,通过之前的学习我们知道进程替换的本质实际上是没有创建新的进程而是在物理内存当中将原来进程的代码和数据替换为指定进程的代码和数据。
实现以上函数之后接下来在main函数中调用
在main函数当中可以在调用完RedirCheck函数之后将redir和filename的值打印出来看看是否符合要求。
int main(){ //从父进程当中获取环境变量表 InitEnv(); while(true) { //1.输出命令行提示符 PrintCommandPrompt(); //2.获取用户输入的命令 //创建数组存储用户输出的数据 char commandline[COMMAND_SIZE]; if(!GetCommandLine(commandline,sizeof(commandline))) continue; //3.重定向分析 RedirCheck(commandline); printf(\"redir:%d,filename:%s\\n\",redir,filename.c_str()); //4.命令行分析 if(!CommandParse(commandline)) continue; // Print(); //5.检测并处理内建命令 if(CheckAndExecBuiltin()) continue; //6.执行命令 Execute(); } return 0;}将myshell.cc重新编译之后生成myshell,之后执行myshell看看是否能实现重定向的功能
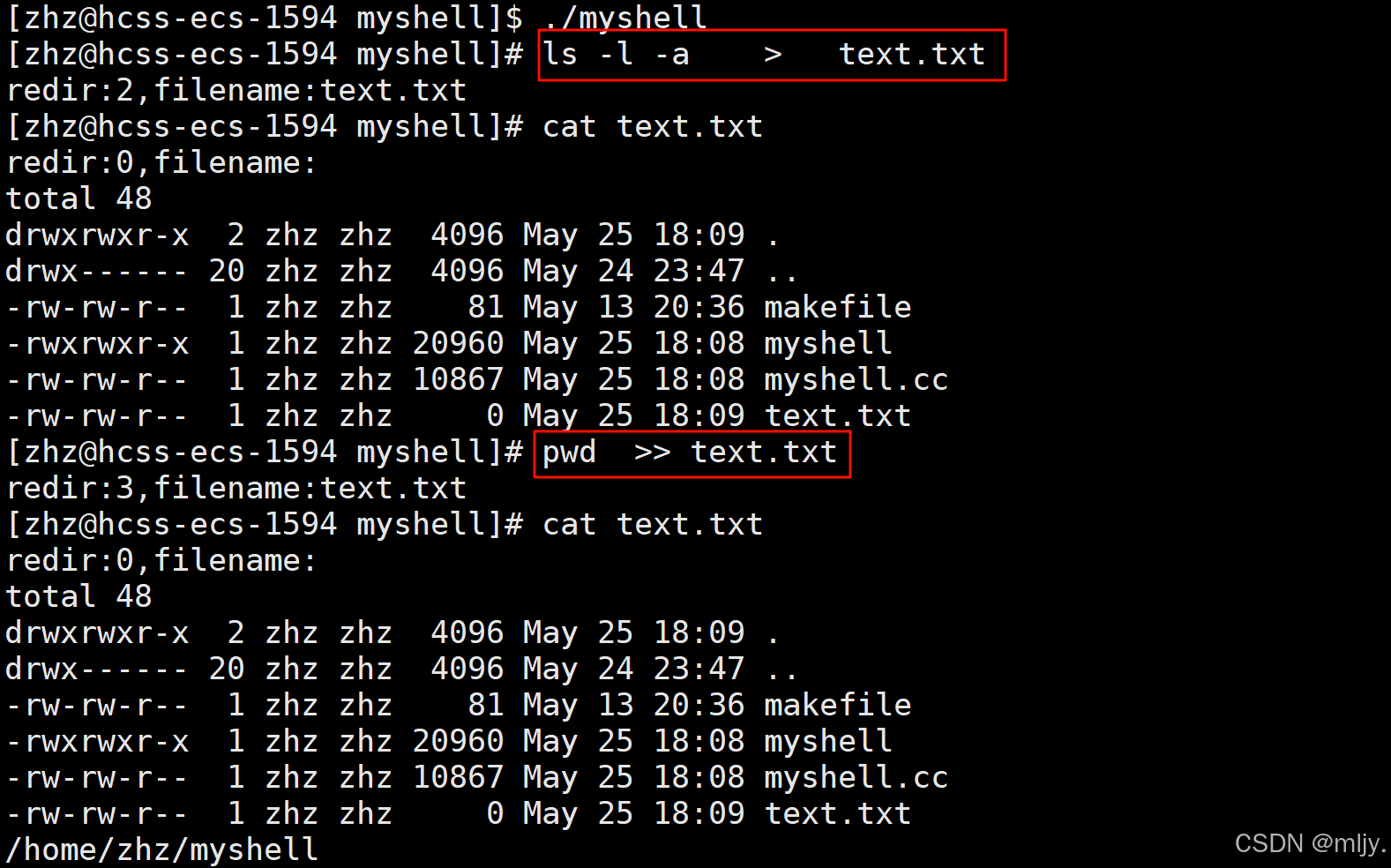
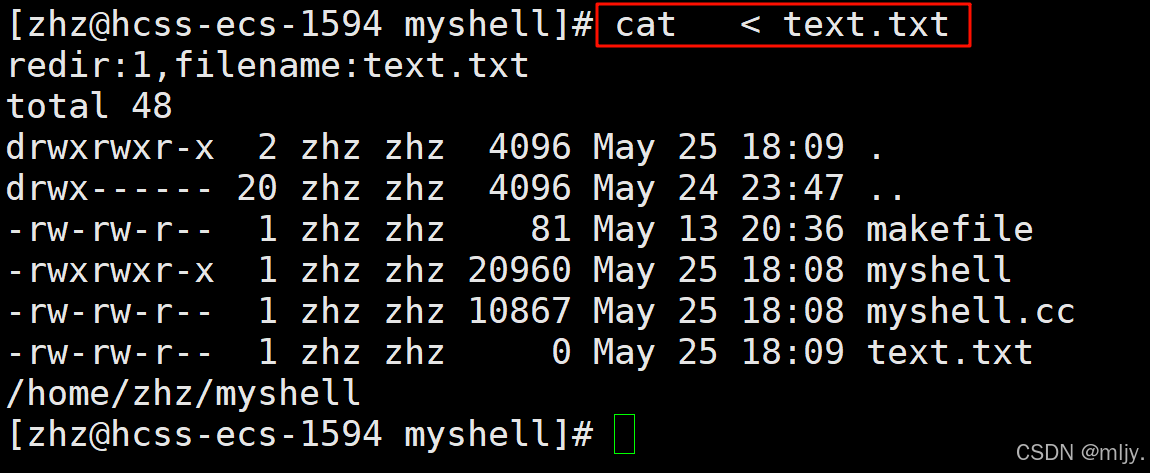
通过以上的输出结果就能说明实现的重定向功能是符合要求的
完整代码
#include#include#include#include#include#include#include#include #include //上一次执行的程序的退出码int lastcode=0;#define COMMAND_SIZE 1024#define FORMAT \"[%s@%s %s]# \" //1.命令行参数表#define MAXARGC 128char* g_argv[MAXARGC];int g_argc=0;//2.环境变量表#define MAX_ENVS 200char* g_env[MAX_ENVS];int g_envs=0;//使用prev_pwd存储最近一次的路径std::string prev_pwd;//创建表示不同重定向的宏//无需重定向#define NONE_ENDIR 0//输入重定向#define INPUT_REDIR 1//输出重定向#define OUTPUT_DEDIR 2//追加重定向#define APPEND_REDIR 3//存储用户输入的重定向的类型int redir=NONE_ENDIR;//存储要进程重定向的文件std::string filename;//获取当前登录的用户名const char* GetUserName(){ const char* name=getenv(\"USER\"); return name==NULL?\"None\":name;}//获取当前主机名const char* GetHostName(){ const char* hostname=getenv(\"HOSTNAME\"); return hostname==NULL?\"None\":hostname;}//获取当前路径const char* GetPwd(){ static char* cur_pwd=nullptr; if(cur_pwd!=NULL) { free(cur_pwd); } cur_pwd=getcwd(NULL,0); return cur_pwd==NULL? \"None\":cur_pwd;}//得到当前用户的家目录const char* GetHome(){ const char* home=getenv(\"HOME\"); return home==NULL?\"\":home;}//导入父进程的环境变量表至当前进程当中void InitEnv(){ extern char** environ; memset(g_env,0,sizeof(g_env)); g_envs=0; //获取环境变量 for(int i=0;environ[i];i++) { g_env[i]=(char*)malloc(strlen(environ[i])+1); strcpy(g_env[i],environ[i]); g_envs++; } g_env[g_envs]=NULL; //导入环境变量 for(int i=0;g_env[i];i++) { putenv(g_env[i]); } environ=g_env; }//执行cd指令bool cd(){ //判断执行的是否是cd -,是的话就获取当前的当前的路径 if(!(g_argc==2 && (strcmp(g_argv[1],\"-\")==0))) { //获取当前路径 prev_pwd=GetPwd(); } //判断命令行参数的个数 if(g_argc==1) { //命令行参数的个数为1就说明用户输出的命令是cd,此时就直接返回当前用户的家目录即可 std::string home=GetHome(); if(home.empty())return true; chdir(home.c_str()); } else { //使用变量where得到第二个参数 std::string where=g_argv[1]; //当第二个参数为-时执行的命令是返回最近一次的路径 if(where==\"-\") { std::string tmp=GetPwd(); std::cout<<prev_pwd<<std::endl; chdir(prev_pwd.c_str()); prev_pwd=tmp; } //当第二个参数是~时执行的命令是返回当前用户的家目录 else if(where==\"~\") { std::string home=GetHome(); //std::string homestr=home.substr(0); // std::cout<<home<<std::endl; chdir(home.c_str()); } //不是以上的情况就将路径切换为用户指定的路径 else{ chdir(where.c_str()); } }//更新环境变量表 int pwd_idx = -1; for(int i = 0; g_env[i] != NULL; i++) { if (strncmp(g_env[i], \"PWD=\", 4) == 0) { pwd_idx = i; break; } } // 获取当前工作目录 char* cwd = getcwd(NULL, 0); if (cwd == NULL) { return \"None\"; // 错误处理 } // 构建新的 PWD 环境变量字符串 size_t len = strlen(cwd) + 5; // \"PWD=\" + 字符串长度 + 1 char* pwd_str =(char*) malloc(len); if (pwd_str == NULL) { free(cwd); return \"None\"; // 内存分配失败 } snprintf(pwd_str, len, \"PWD=%s\", cwd); free(cwd); // 更新环境变量表 if (pwd_idx != -1) { free(g_env[pwd_idx]); // 释放旧的 PWD 条目 //printf(\"%s\\n\",prev_pwd); g_env[pwd_idx] = pwd_str; // 设置新的 PWD 条目 } else { // 确保有空间添加新环境变量 if (g_envs < MAX_ENVS - 1) { g_env[g_envs++] = pwd_str; g_env[g_envs] = NULL; // 确保列表以 NULL 结尾 } } return true;}//执行echo指令void Echo(){ //判断用户输入的参数个数是否为2 if(g_argc==2) { //将用户输入的第二个参数存储到opt当中 std::string opt=g_argv[1]; if(opt==\"$?\") { //输出错误码lastcode的值 std::cout<<lastcode<<std::endl; lastcode=0; } else if(opt[0]==\'$\') { //输出对应环境变量的数据 std::string env_name=opt.substr(1); const char*env_vlue=getenv(env_name.c_str()); if(env_vlue) std::cout<<env_vlue<<std::endl; } else{ //不为以上的情况就直接将用户输入的第二个参数输出 std::cout<<opt<<std::endl; } }}//执行export指令bool Export(){ char* newenv =(char*)malloc(strlen(g_argv[1])+1); strcpy(newenv,g_argv[1]); //std:: cout<<g_argv[1]<<std::endl; // std:: cout<<newenv<0? true:false;}void Print(){ for(int i=0;g_argv[i];i++) { printf(\"argv[%d]->%s\\n\",i,g_argv[i]); } printf(\"argv:%d\\n\",g_argc); for(int i=0;g_env[i];i++) { printf(\"argv[%d]->%s\\n\",i,g_env[i]); }}//检查用户输入的指令是否为内建命令 bool CheckAndExecBuiltin(){ std::string cmd=g_argv[0]; if(cmd==\"cd\") { cd(); return true; } else if(cmd==\"echo\") { Echo(); return true; } else if(cmd==\"export\") { Export(); return true; } else{ //…… }return false;}//清空重定向符之后的空格void TrimSpace(char* cmd,int &end){ while(isspace(cmd[end])) { end++; }}//重定向分析void RedirCheck(char* cmd){ //将上一次获取重定向的数据清除 redir=NONE_ENDIR; filename.clear(); //遍历用户输入的字符串,判断对应的重定向类型 int start=0; int end=strlen(cmd)-1; while(start<end) { //输入重定向 if(cmd[end]==\'\') { //输出重定向 if(cmd[end-1]==\'>\') { cmd[end-1]=0; redir=APPEND_REDIR; } //追加重定向 else{ redir=OUTPUT_DEDIR; } cmd[end++]=0; //清空重定向符之后的空格 TrimSpace(cmd,end); filename=cmd+end; } else{ end--; } }}//创建子进程执行命令int Execute(){ //创建子进程 pid_t pid=fork(); if(pid==0) { int fd=-1; //判断用户执行的重定向类型 if(redir==INPUT_REDIR) { //输入重定向以读的方式打开filename文件 fd=open(filename.c_str(),O_RDONLY); if(fd<0)exit(1); dup2(fd,0); close(fd); } else if(redir==OUTPUT_DEDIR) { //输出重定向以写的方式打开文件 fd=open(filename.c_str(),O_CREAT | O_WRONLY |O_TRUNC,0666); if(fd<0)exit(1); dup2(fd,1); close(fd); } else if(redir==APPEND_REDIR) { //追加重定向以写并且追加的方式打开文件 fd=open(filename.c_str(),O_CREAT | O_WRONLY | O_APPEND,0666); if(fd0) { //设置进程退出码lastcode值 lastcode=WEXITSTATUS(status); } return 0;}int main(){ //从父进程当中获取环境变量表 InitEnv(); while(true) { //1.输出命令行提示符 PrintCommandPrompt(); //2.获取用户输入的命令 //创建数组存储用户输出的数据 char commandline[COMMAND_SIZE]; if(!GetCommandLine(commandline,sizeof(commandline))) continue; //3.重定向分析 RedirCheck(commandline); // printf(\"redir:%d,filename:%s\\n\",redir,filename.c_str()); //4.命令行分析 if(!CommandParse(commandline)) continue; // Print(); //5.检测并处理内建命令 if(CheckAndExecBuiltin()) continue; //6.执行命令 Execute(); // Print(); //char arr[1024]; //scanf(\"%s\",arr); } return 0;}7. 理解“一切皆为文件”
在之前Linux的学习当中我们就一直听到一句话就是Liinux下一切皆文件,但是之前只是知道了这就话;而没有真正的理解这就话的原理,那么接下来就从本质上理解什么是一切皆文件
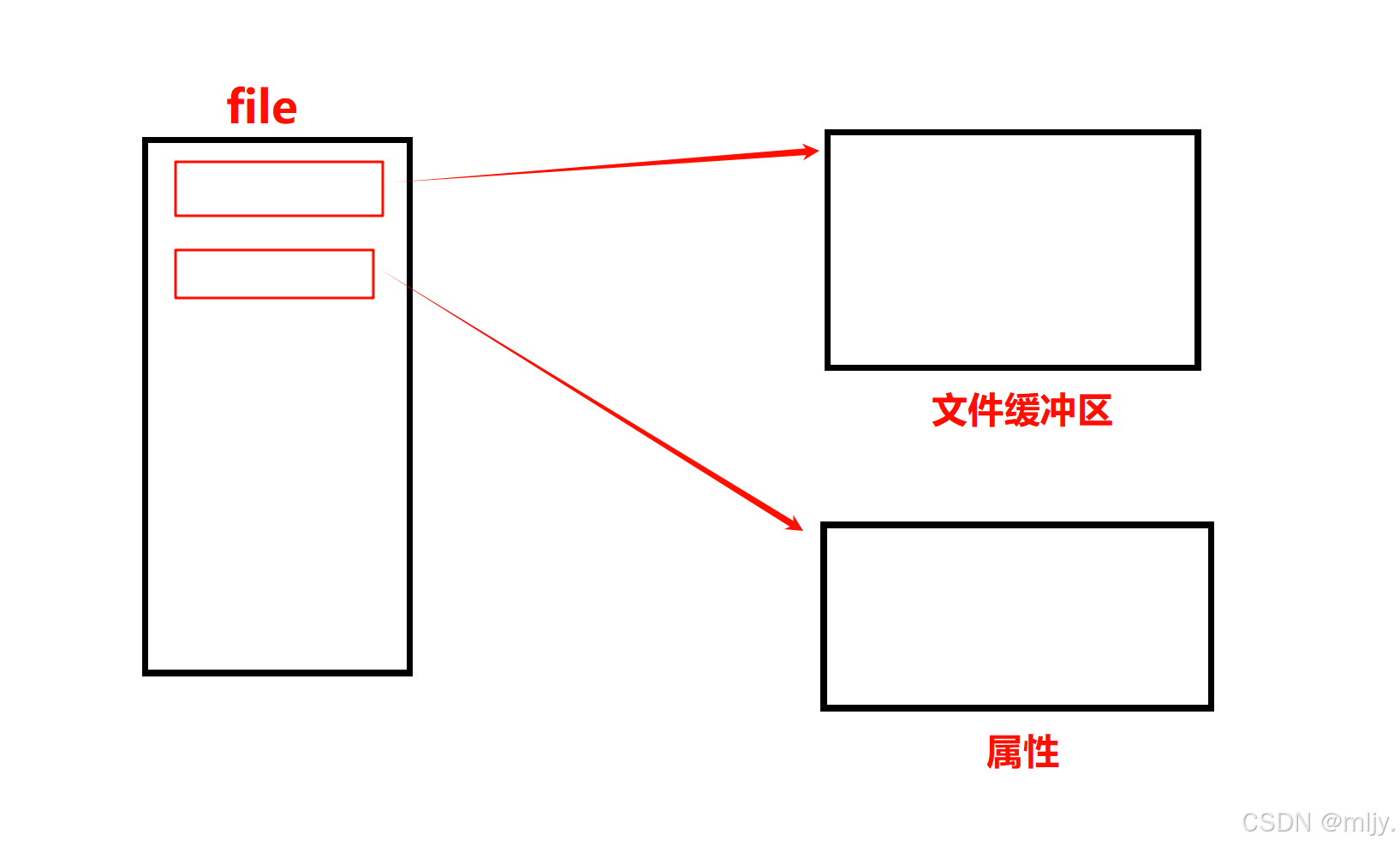
在解释以上的问题之前先来了解文件的缓冲区是在什么位置的,其实在文件的file结构体当中存在一个指向一块内存的指针,该指针指向的就是文件的缓冲区,除此之外还会有一个指向另外一个结构体的指针,该结构体内存储着文件的属性。
其实在计算机的硬件当中不同的硬件进行读写的操作方式都是不同的,但是不同的硬件都是需要有读写的能力的,那么在操作系统当中就在文件的file结构体当中添加了一个硬件读写的函数指针,这样就就可以使得访问设备都是通过函数指针来访问之后,该函数的类型和参数都是相同的。
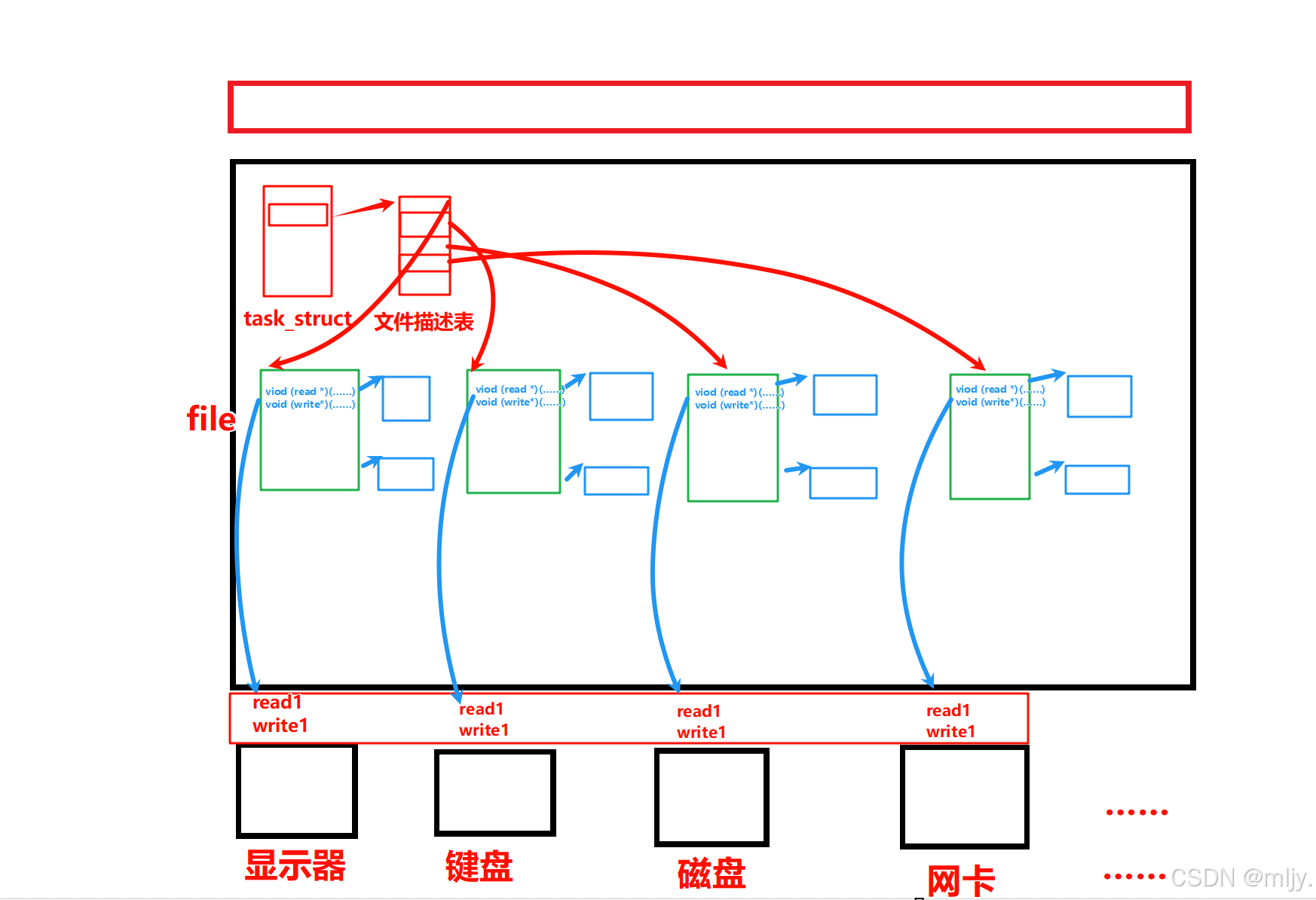
在以上当中其实将各个文件的file连接在一起整个结构被称为VFS(虚拟文件系统) ,这时就可以将该结构视为基类,而以下的各个硬件就视为派生类,整个结构就实现出了C语言版的多态
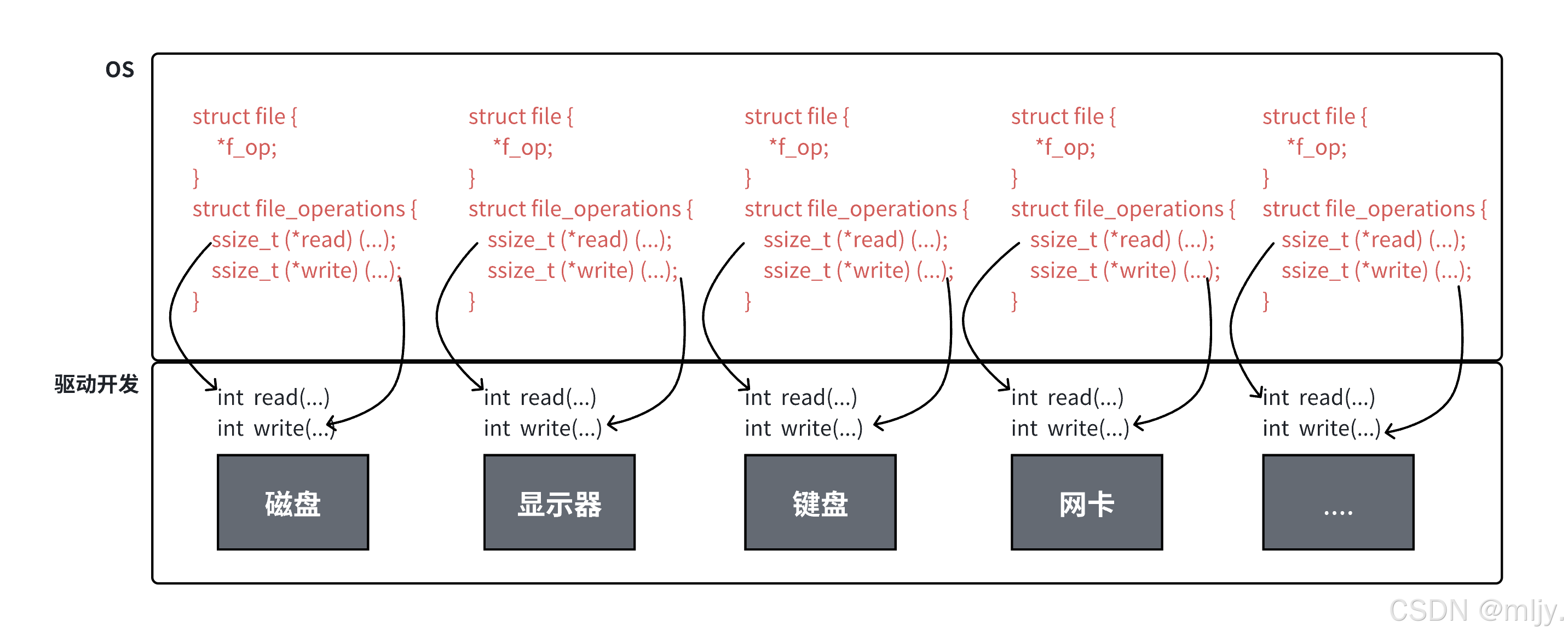 上图中的外设,每个设备都可以有自己的read、write,但⼀定是对应着不同的操作方法!!但通过struct file 下 file_operation 中的各种函数回调,让我们开发者只⽤file便可调取 Linux 系统中绝⼤部分的资源!!这便是“linux下⼀切皆⽂件”的核心理解。
上图中的外设,每个设备都可以有自己的read、write,但⼀定是对应着不同的操作方法!!但通过struct file 下 file_operation 中的各种函数回调,让我们开发者只⽤file便可调取 Linux 系统中绝⼤部分的资源!!这便是“linux下⼀切皆⽂件”的核心理解。
在Linux当中使用以上的结构设计的这样做最明显的好处是,开发者仅需要使用⼀套 API 和开发工具,即可调取 Linux 系统中绝大部分的资源。
8. 缓冲区
其实在之前的学习当中我们就已经在许多的地方涉及到了缓冲区,例如在f了解flush、了解exit和_exit的区别的时候,但是在之前我们只是知道有缓冲区这一概念而不知道缓冲区具体是在那里。接下来来就来详细的了解缓冲区的概念。
其实在操作系统当中是存在两个不同的缓冲区的,分别是文件内核缓冲区和语言层缓冲区。
我们知道当使用fopen打开一个文件的时候返回值是一个FILE类型的指针,那么这时在操作系统当中就会创建出一个FILE的结构体对象,在该结构体当中存储在文件描述符等的数据,还会有一个指向缓冲区的指针。
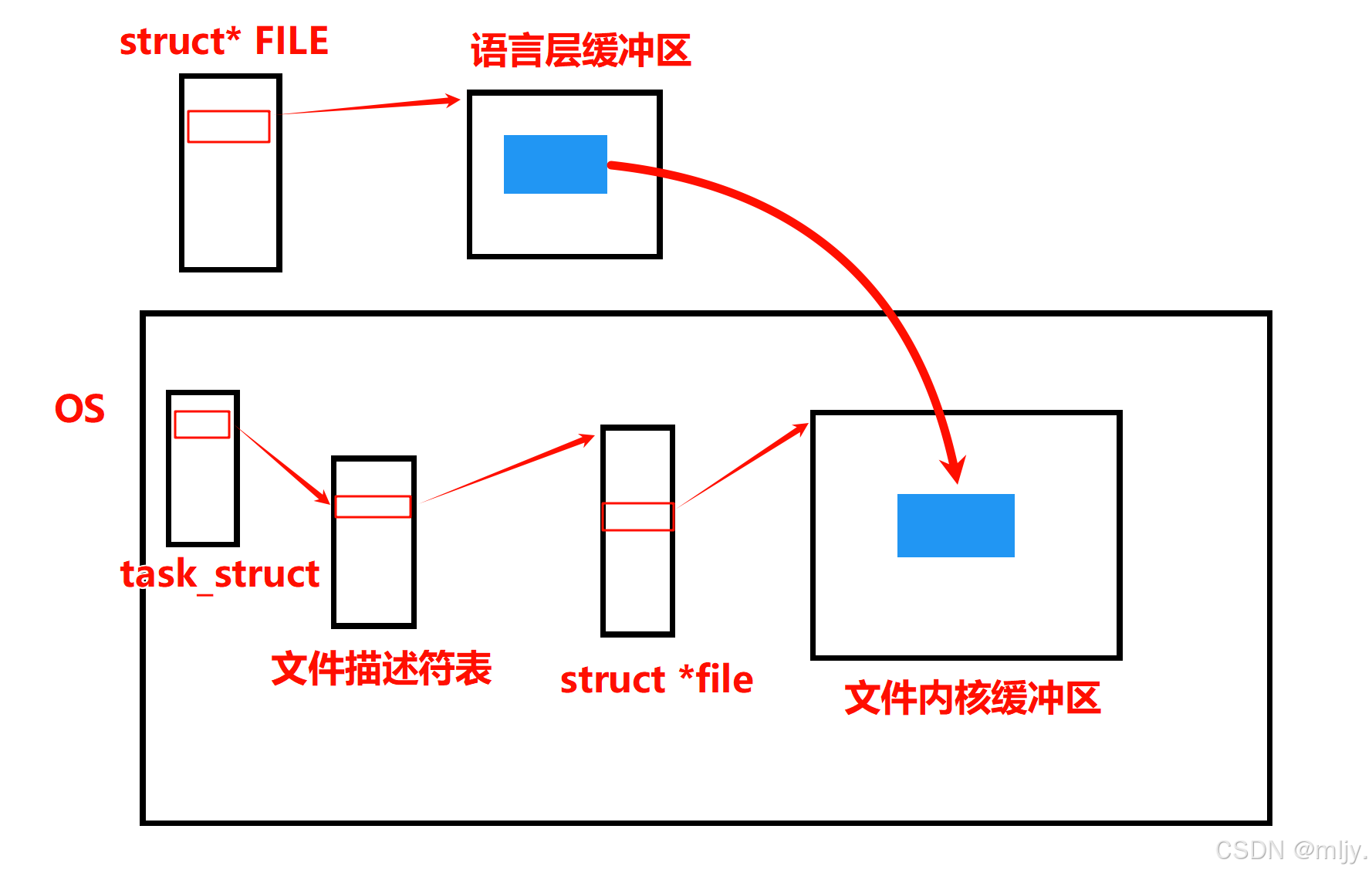
实际上在语言层面要对文件进行写入操作的时候是会将数据先存储在语言的缓存区上,之后当满足要求之后再将缓冲区内的数据拷贝到文件内核大的缓冲区当中。
那么问题就来了,若要将语言层缓冲区的数据刷新到文件内核的缓冲区当中需要满足什么条件呢?
以上满足以下三个条件其中之一即可实现刷新
1.用户执行强制刷新
2.刷新条件满足
3.程序退出之前
以上的强制刷新和程序退出之前刷新比较容易理解,但是这个刷新条件满足又是什么呢?
其实在语言的层面对应不同的硬件实现了不同的刷新策略,一般来说会有三种的刷新策略,分别是立即刷新、全刷新、按照行刷新。立即刷新一般是用于无缓冲区的情况,全刷新则是当缓冲区满了再刷新这种刷新的效率是最高的,行刷新则一般是用在显示器当中。
以上就了解了缓冲区的基本概念,那么接下来就要思考缓冲区存在的意义是什么呢?并且为什么要有这么多的刷新策略呢?为什么不能当语言层的缓冲区当中一有数据就直接刷新呢?
其实缓冲区实现出来的最终目的是为了提高使用者的效率,在将语言层缓冲区内的数据刷新到文件内核缓冲区当中实际上是通过调用系统调用来实现的,我们知道调用任何的系统调用都是要消耗系统系统的资源的,那么如果无论什么都使用立即刷新的方式就会使得效率受到影响,因此对于不同的文件类型需要有不同的刷新策略。
当将语言层当中的数据刷新到文件内核缓冲区时,就将数据交给了OS,那么这时就可以认为将数据传给了硬件。
接下来就通过两段代码来进一步的理解缓冲区是如何在实际当中运作的
代码1:
#include#include#include #include #include #includeint main(){ close(1); int fd1=open(\"text.txt1\",O_CREAT | O_WRONLY | O_APPEND,0666 ); printf(\"fd1->%d\\n\",fd1); printf(\"hello world\\n\"); printf(\"hello world\\n\"); printf(\"hello world\\n\"); const char* msg=\"hello\\n\"; write(fd1,msg,strlen(msg)); return 0;}以上的代码当中先将标准输出关闭,之后以追加的方式打开文件text.txt1,那么这时该文件文件描述符就为1,之后代码当中原本要写入到显示器当中的数据都会输出到该文件当中。之后使用printf和write进行输出,那么这时我们就可以预测到该代码执行之后会将以上输出语句内数据都写入到text.txt1文件当中。
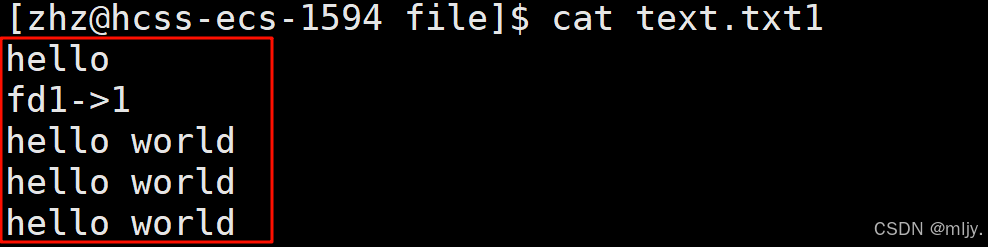
最终的结构也确实如我们预想的一样
那么如果这时在以上的代码最后使用close将该文件关闭,执行的结果还会和原来一样吗?
#include#include#include #include #include #includeint main(){ close(1); int fd1=open(\"text.txt1\",O_CREAT | O_WRONLY | O_APPEND,0666 ); printf(\"fd1->%d\\n\",fd1); printf(\"hello world\\n\"); printf(\"hello world\\n\"); printf(\"hello world\\n\"); const char* msg=\"hello\\n\"; write(fd1,msg,strlen(msg)); close(fd1); return 0;}执行之后会发现文件当中只有hello这一条一句被写入了,这是为什么呢?

在了解了缓冲区的知识之后以上的问题就很容易解答了,当在关闭文件之前使用printf写入的数据还是存储在语言层的缓冲区当中的,这时将文件关闭之后是不满足三个刷新条件其中之一的,那么这时就只会将使用write系统调用写入到文件内核缓冲区当中数据存储到文件当中。
代码2
#include#include#include #include #include #include int main() { close(1); int fd1=open(\"text.txt1\",O_CREAT | O_WRONLY | O_APPEND,0666 ); printf(\"hello printf\\n\"); fprintf(stdout,\"hello fprintf\\n\"); const char* msg=\"hello write\\n\"; write(fd1,msg,strlen(msg)); //添不添加输出的结果有什么区别呢? fork(); return 0;}以上的代码当中当不添加fork的时候很好理解就是向对应的文件当中输出三条语句

当时当添加上fork之后竟然会先text.txt1当中输出以下的内容
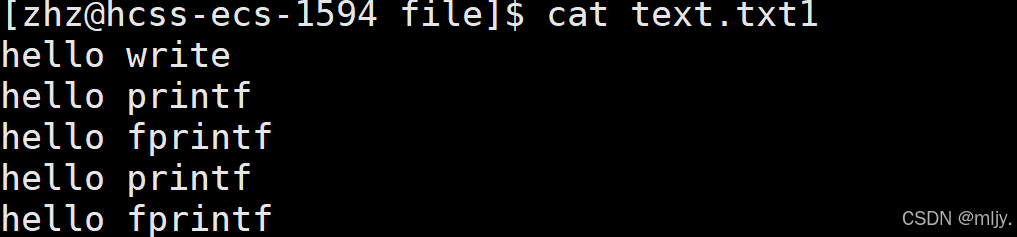
要解答以上的问题还是需要结合缓冲区的知识,以上在fork创建子进程之前使用C语言函数输出的两条语句其实还是在语言层的缓冲区当中,因为子进程在创建的时候会将父进程的代码和数据全部拷贝,这就会使得在子进程语言层缓冲区也会有这两条语句。而使用write系统调用的十直接写入到文件内核缓冲区当中,该操作是在fork之前的子进程就不会进行这一操作。因此最终就会向text.txt1当中写入两次hello printf和hello sprintf
当你能完全理解以上两段代码的原理就说明你已经理解缓冲区的原理了
9. 简单设计libc库
以上在了解了缓冲区的相关概念之后就可以试着来实现自己的libc库,最终实现之后在程序当中能通过调用库中的函数实现文件的读写等操作,类似C当中提供的fopen、fwrite、fclose。
首先创建一个全新的目录,在该目录下创建三个文件分别为mystdio.h、mystdio.c、user.c,再创建对应的makefile文件,makefile要实现的是将mystdio.c和user.c编译生成可执行程序mystdio
makefile:
mystdio:mystdio.c user.c g++ -o $@ $^ -std=c++11 .PHONY:clean clean: rm -f mystdio 接下来在mysydio.h内实现各个函数的定义
mystdio.h:
#pragma once #include //缓冲区的最大值 #define MAX 1024 //刷新策略 #define NONE_FLUSH (1<<0) #define LINE_FLUSH (1<<1) #define PULL_FLUSH (1<<2) //存储文件信息的结构体 typedef struct IO_FILE { //文件描述符 int fileno; //打开文件方式标志位 int flag; //缓冲区 char outbuffer[MAX]; //缓冲区长度 int bufferlen; //刷新策略 int flush_method; }Myfile; //打开文件 Myfile* MyFopen(const char* path,const char* mode); //关闭文件 void MyFclose(Myfile* ); //对文件进行写入 size_t MyFwrite(Myfile*,void *str,int len); //将语言缓冲区当中的数据刷新 void MyFFlush(Myfile*); 以上实现了函数的声明之后就可以在mystdio.c内实现函数的定义
mystdio.c:
#include\"mystdio.h\"#include #include #include #include#include#include//创建对应文件的Myfile结构体对象static Myfile* BuyMyfile(int flag,int fd){ Myfile* f=(Myfile*)malloc(sizeof(Myfile)); if(f==NULL)return NULL; f->fileno=fd; f->flag=flag; f->bufferlen=0; f->flush_method=LINE_FLUSH; memset(f->outbuffer,0,sizeof(f->outbuffer)); return f;}//打开文件Myfile* MyFopen(const char* path,const char* mode){ int fd=-1; int flag=0; //写方式 if(strcmp(mode,\"w\")==0) { flag=O_WRONLY |O_CREAT |O_TRUNC; fd=open(path,flag,0666); } //读方式 else if(strcmp(mode,\"r\")==0) { flag=O_RDONLY; fd=open(path,flag); } //追加方式 else if(strcmp(mode,\"a\")==0) { flag=O_WRONLY | O_CREAT | O_APPEND; fd=open(path,flag,0666); } else{ //.... }return BuyMyfile(flag,fd);}//关闭文件void MyFclose(Myfile* file){ if(file->filenofileno); //释放Myfile结构体对象内存 free(file);}//向文件内写入size_t MyFwrite(Myfile* file,void *str,int len){ //将str数据拷贝到缓冲区当中 memcpy(file->outbuffer+file->bufferlen,str,len); file->bufferlen+=len; //判断是否满足刷新的条件:刷新条件为行刷新且当前缓冲区当中内容以\\n结尾 if((file->flush_method & LINE_FLUSH) && file->outbuffer[(file->bufferlen)-1]==\'\\n\' ){ MyFFlush(file); } return len;}//刷新缓冲区void MyFFlush(Myfile* file){ if(file->bufferlenfileno,file->outbuffer,file->bufferlen); (void)n; //将文件缓冲区当中的数据强制同步到文件当中 fsync(file->fileno); file->bufferlen=0;}以上就实现了mystdio.c内的各个函数,以上在MyFFlush当中使用到了fsync系统调用,该系统调用的作用是将文件在内存中的修改强制同步到磁盘,这样就可以实现每次在将缓冲区的数据刷新的时候能同步到对应的文件当中。
接下来在user.c当中添加stdio.h的头文件之后就可以调用我们实现的函数来实现文件的操作
user.c
#include\"mystdio.h\" #include #include #includeint main() { Myfile* f=MyFopen(\"./text.txt\",\"a\"); if(f==NULL) { exit(1); } int cnt=5; char* str=(char*)\"hello world\\n\"; while(cnt--) { MyFwrite(f,str,strlen(str)); printf(\"buffer:%s\\n\",f->outbuffer); sleep(1); } MyFclose(f); return 0; } 以上代码当中在打开text.txt文件之后向文件当中写入,在写入过程当中每秒观察一次缓冲区的情况
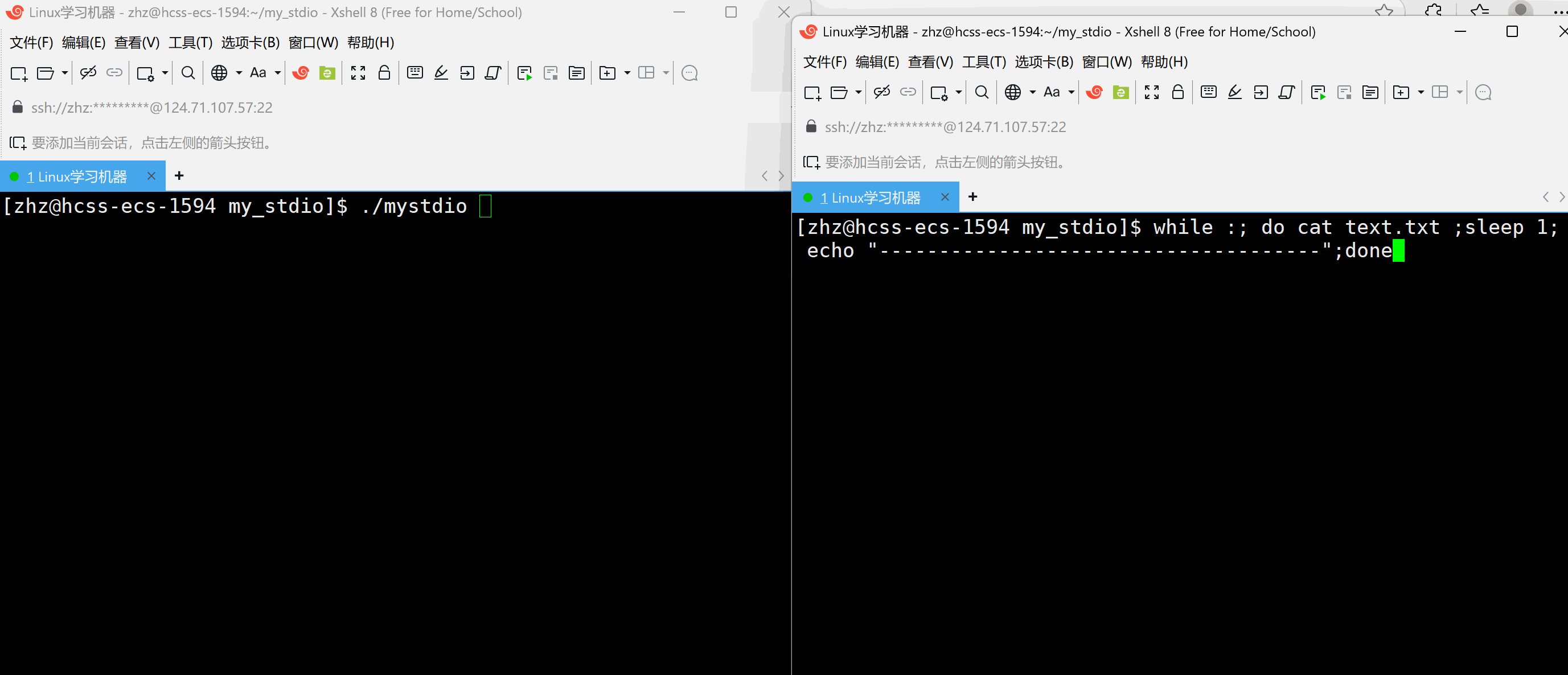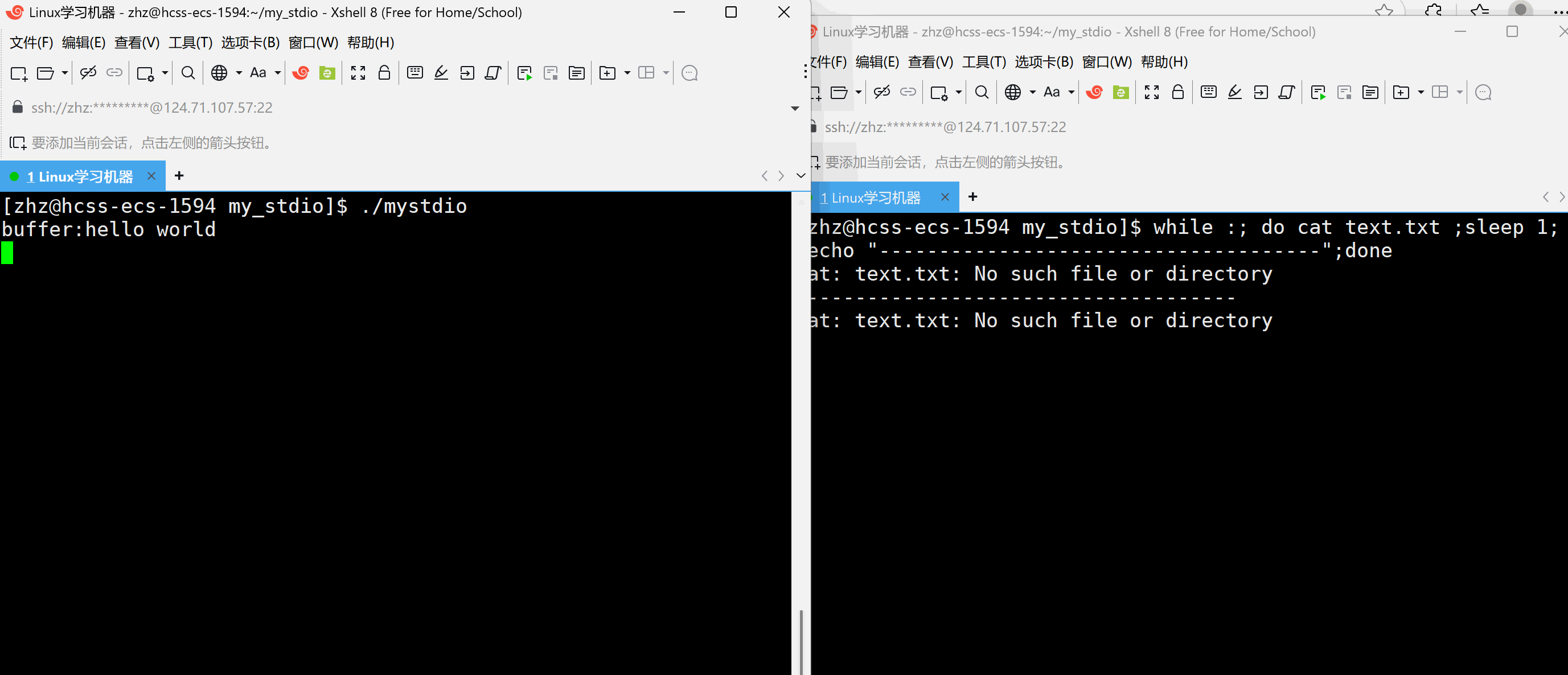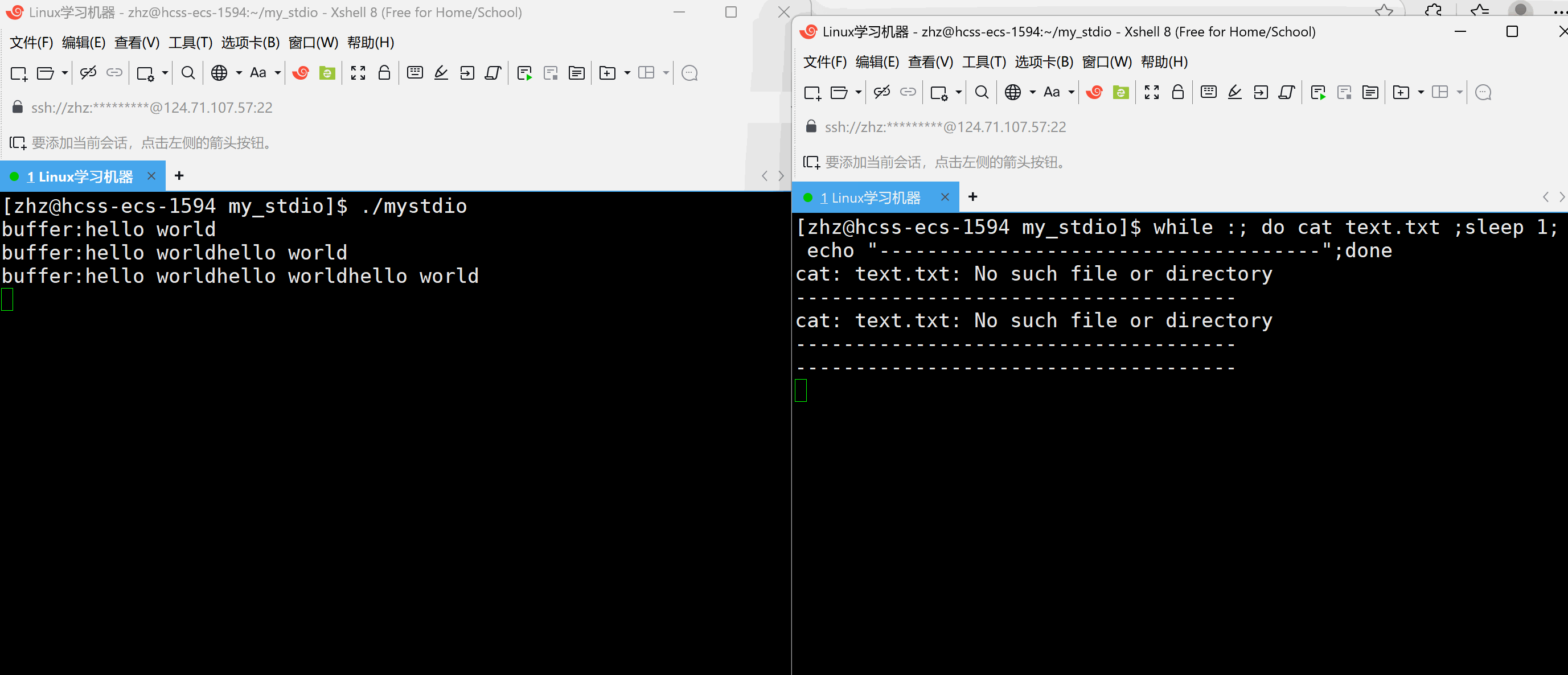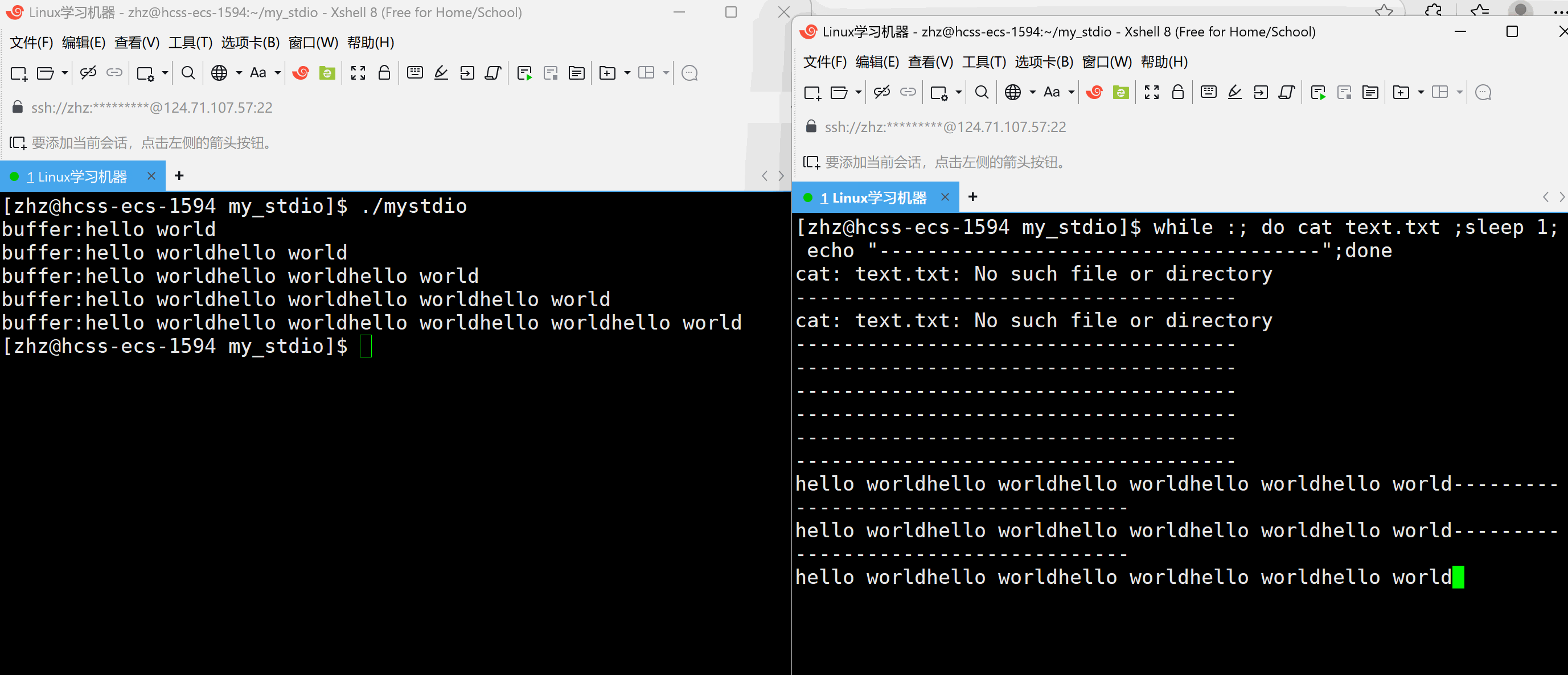
以上就会发现当以上代码是在程序结束的时候一次性的刷新。那么如果要写入一次就刷新一次就需要在写入之后进行刷新
#include\"mystdio.h\" #include #include #includeint main() { Myfile* f=MyFopen(\"./text.txt\",\"a\"); if(f==NULL) { exit(1); } int cnt=5; char* str=(char*)\"hello world\\n\"; while(cnt--) { MyFwrite(f,str,strlen(str)); MyFFlush(f); printf(\"buffer:%s\\n\",f->outbuffer); sleep(1); } MyFclose(f); return 0; } 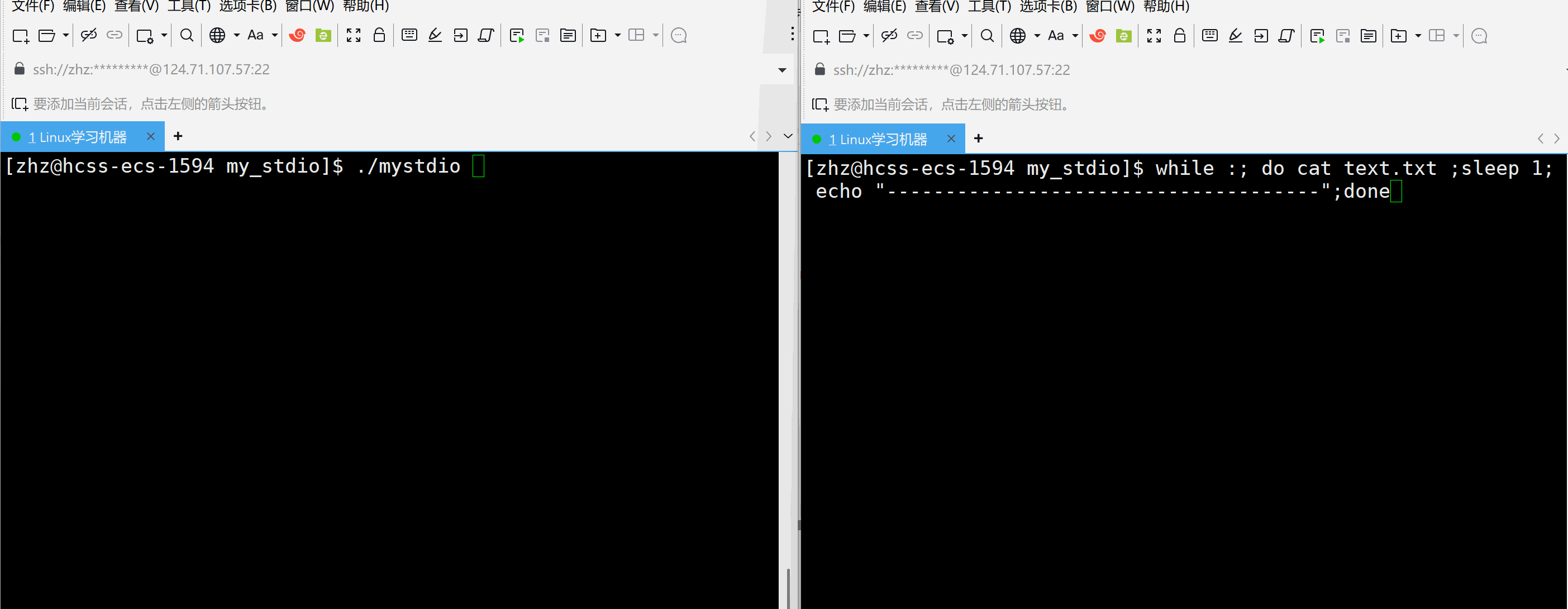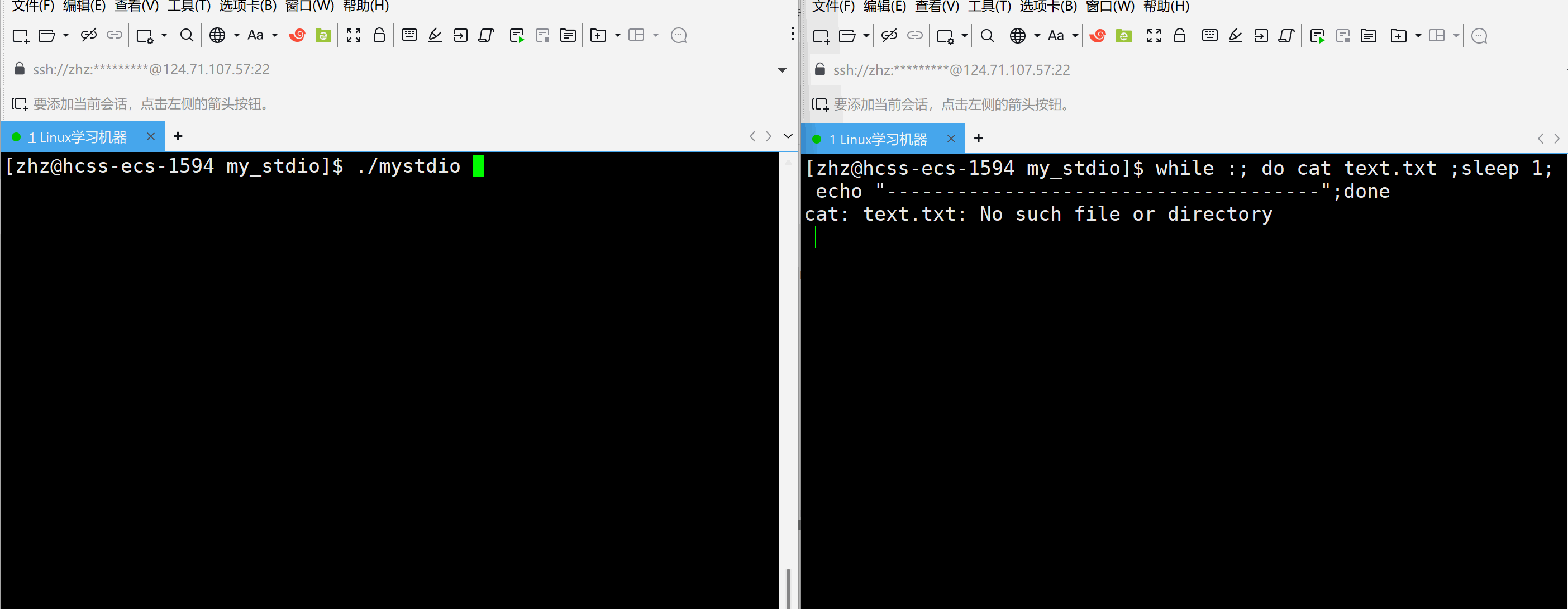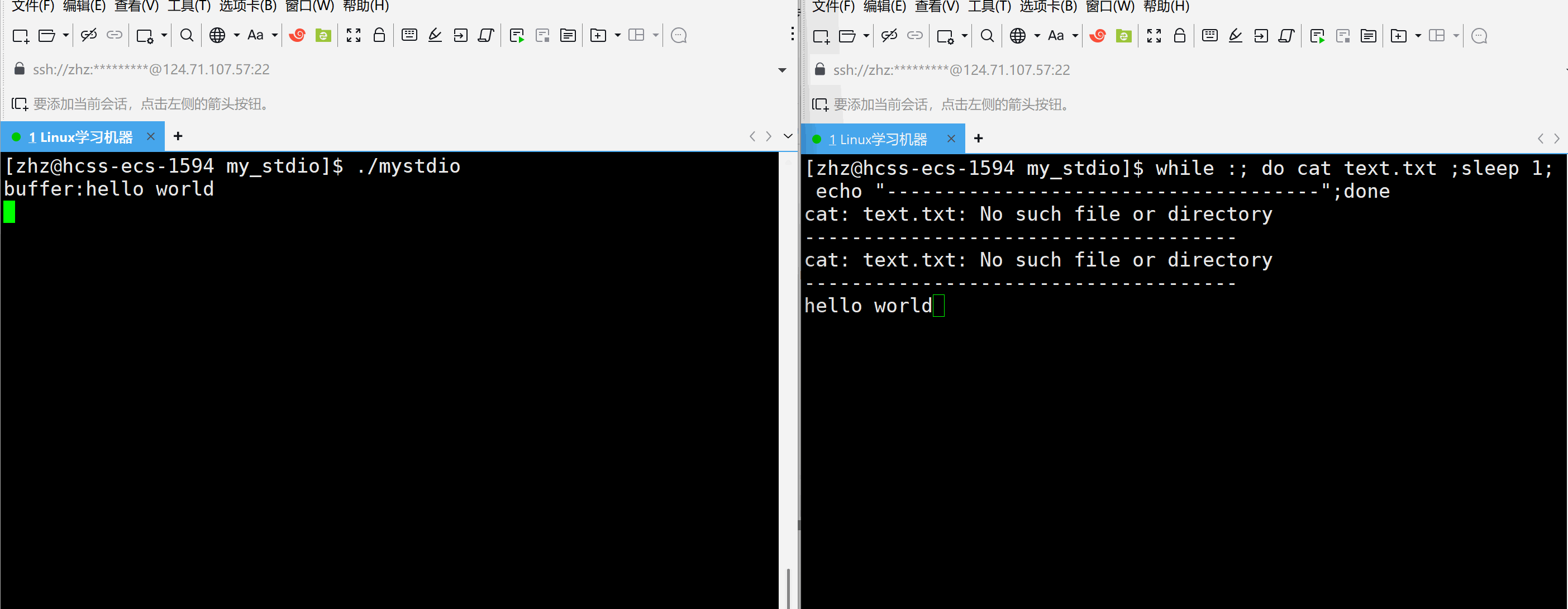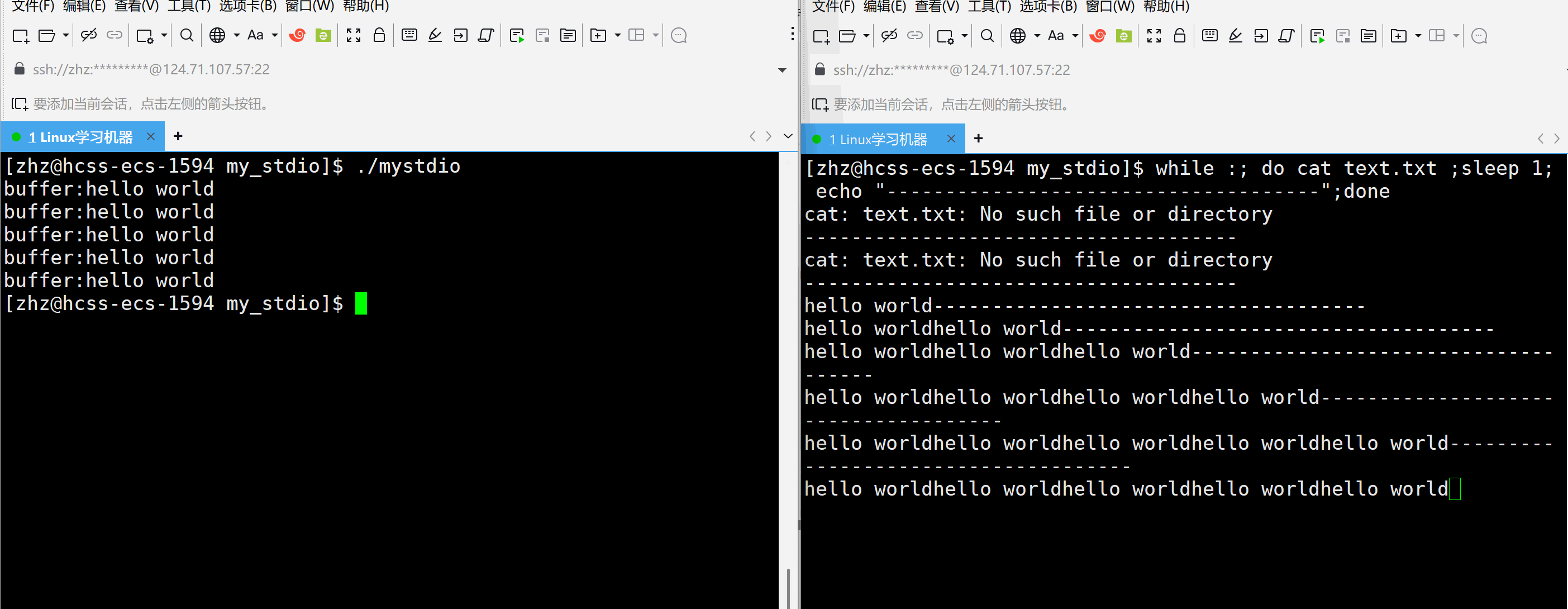
以上就是本篇的全部内容了,接下来将开始文件系统的学习,未完待续……

