深度学习之----Bert模型
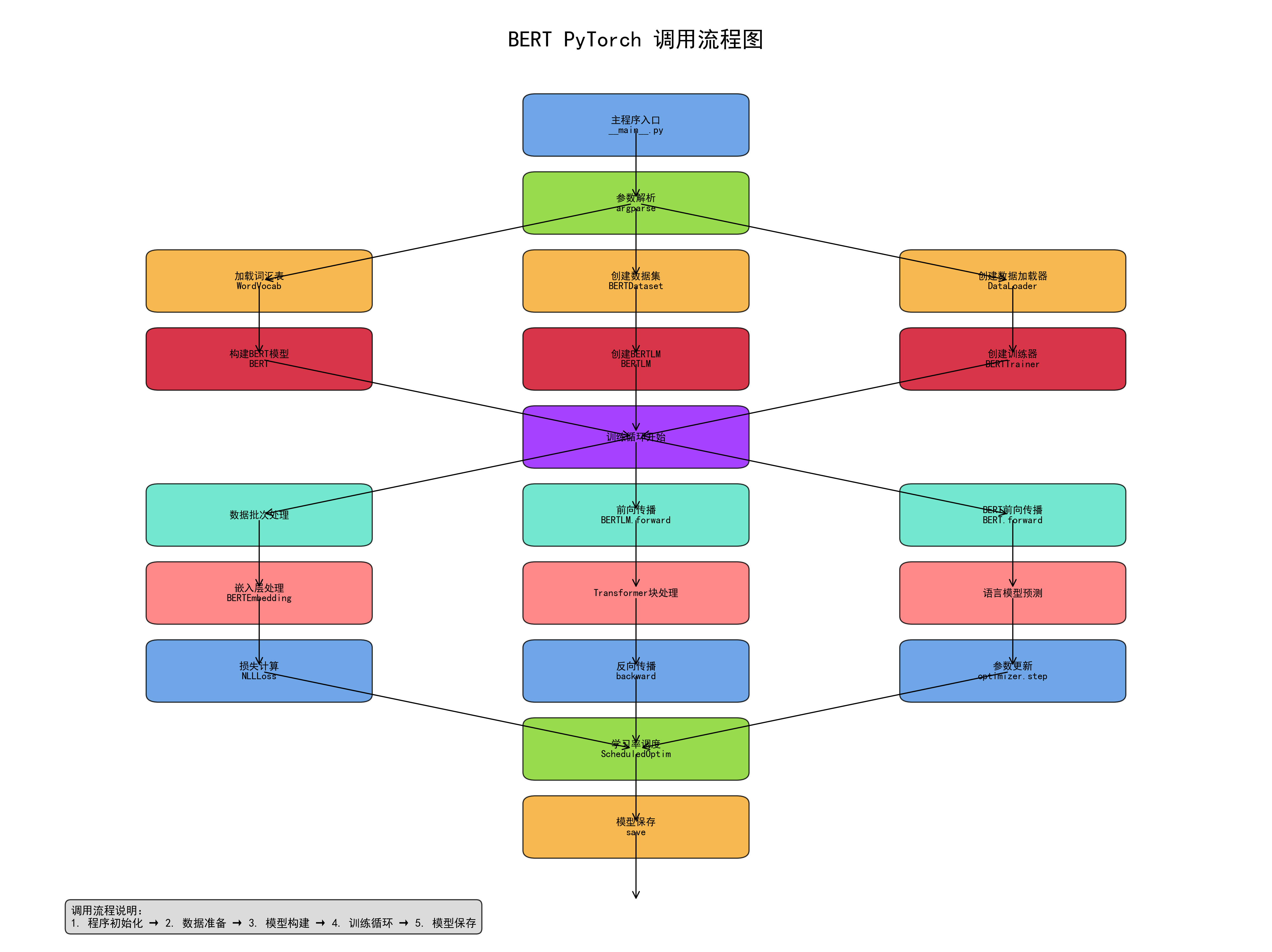
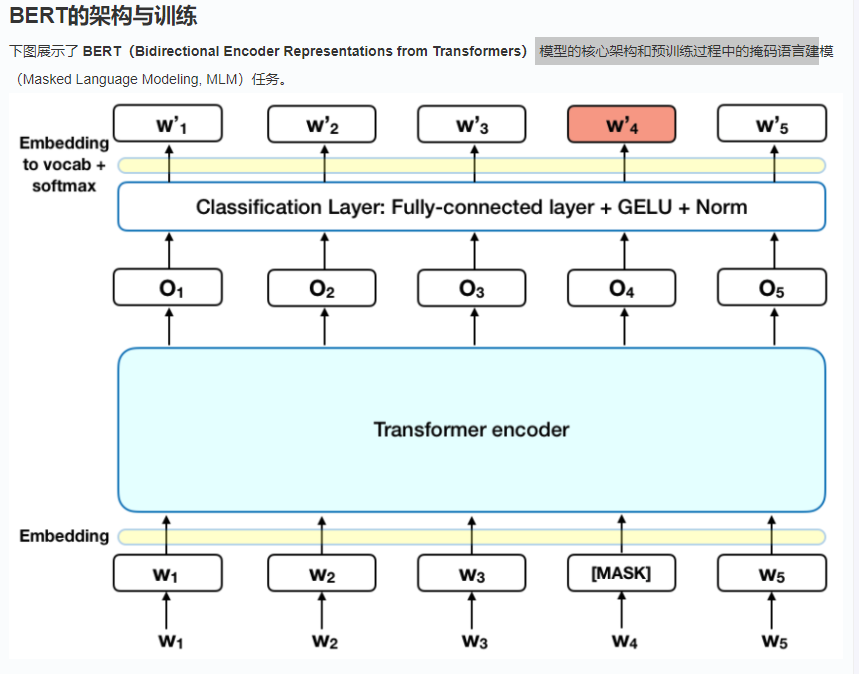
Bert的原理解析如下:
一、 BERT 的核心原理
-
核心思想:深度双向上下文理解
-
突破单向限制: 传统语言模型(如 ELMo、GPT-1)要么是单向(从左到右),要么是浅层拼接的双向。BERT 的核心创新在于它在预训练阶段就使用了真正的双向 Transformer 编码器。
-
Transformer 编码器: BERT 完全基于 Transformer 模型中的编码器部分。Transformer 利用自注意力机制,允许模型在处理一个词时,同时关注输入序列中所有其他词的上下文信息,从而建立词与词之间的依赖关系模型。
-
\"深度双向\"的含义: 模型在预训练目标(MLM)的设计上,强制要求模型利用某个词左右两侧的所有上下文信息来预测该词本身。这与从左到右生成文本的语言模型(如 GPT)或仅用左侧信息的模型有本质区别。
-
-
预训练任务:让模型学习通用语言知识
BERT 通过两个巧妙设计的自监督任务在大规模无标注文本(如 Wikipedia, BookCorpus)上进行预训练:-
任务 1:Masked Language Model
-
操作: 随机遮盖输入句子中约 15% 的 token(词或子词)。
-
目标: 模型需要预测这些被遮盖的 token 原本是什么。
-
关键点:
-
遮盖允许模型利用双向上下文进行预测(被遮盖词左右两边的词都对预测有帮助)。
-
被遮盖的 token 有 80% 的概率被替换为
[MASK],10% 替换为随机 token,10% 保持原词不变。这增加了模型的鲁棒性,防止模型过度依赖[MASK]这个特殊标记,并让模型知道有些词没有被修改。
-
-
-
任务 2:Next Sentence Prediction
-
操作: 给模型输入两个句子 A 和 B,其中 50% 的情况下 B 是 A 的真实下一句,50% 的情况下 B 是从语料库中随机抽取的句子。
-
目标: 模型需要判断句子 B 是否是句子 A 的下一句。
-
关键点: 使模型学习句子间的逻辑和连贯关系,这对问答、自然语言推理等需要理解句子间关系的任务至关重要。
-
输入表示: 在输入序列的开头添加
[CLS]token,在句子 A 和 B 之间添加[SEP]token。
-
-
-
模型架构:Transformer Encoder 堆叠
-
由 L 层(例如 12 层
bert-base, 24 层bert-large)相同的 Transformer Encoder 层堆叠而成。 -
每层 Transformer Encoder 包含:
-
多头自注意力机制: 计算序列中每个 token 与其他所有 token 的关联程度(注意力权重),整合上下文信息。
-
前馈神经网络: 对每个位置的表示进行非线性变换。
-
残差连接和层归一化: 用于稳定训练和加速收敛。
-
-
输入表示: 每个输入 token 的最终表示由三部分 Embedding 相加构成:
-
Token Embeddings: 词或子词本身的嵌入向量。
-
Segment Embeddings: 标记 token 属于句子 A 还是句子 B。
-
Position Embeddings: 表示 token 在序列中的位置信息。
-
-
特殊标记:
-
[CLS]:序列开头,其最终层的输出常被用作整个序列的聚合表示,用于分类任务。 -
[SEP]:分隔句子。 -
[MASK]:用于 MLM 任务。 -
[UNK]:未知词。 -
[PAD]:填充。
-
-
-
输出表示:上下文相关的词向量
-
经过多层 Transformer Encoder 处理后,模型输出一个与输入序列等长的向量序列。
-
序列中每个位置的输出向量都融合了整个输入序列的上下文信息。这意味着同一个词在不同句子中或同一句子不同位置,其输出向量是不同的(动态词向量)。这是 BERT 强大的关键。
-
-
二、 BERT 的调用机制(微调)
预训练好的 BERT 模型是一个强大的通用语言表示生成器。要用于具体的下游任务(如文本分类、问答、命名实体识别),需要进行微调。
-
核心过程:
-
加载预训练模型: 获取在大型语料库上预训练好的 BERT 模型及其权重(如
bert-base-uncased,bert-large-cased)。 -
添加任务特定层: 在预训练好的 BERT 模型之上,添加一个简单的、与任务相关的输出层(通常很轻量)。
-
例如文本分类: 在
[CLS]token 的输出向量上添加一个全连接层 + softmax。 -
例如问答: 添加两个全连接层,分别预测答案在原文中的开始位置和结束位置。
-
例如命名实体识别: 在每个 token 的输出向量上添加一个分类层(如 CRF 或 softmax)。
-
-
微调训练: 在特定任务的标注数据集上,同时训练添加的任务层和预训练 BERT 模型的参数(或只训练顶层,但通常微调所有层效果更好)。使用较小的学习率,因为预训练权重已经很好。
-
-
输入处理:
-
Tokenization: 使用 BERT 专用的
WordPiece分词器将输入文本分解成子词 token。 -
构建输入序列:
-
对于单句任务:
[CLS] + tokens + [SEP] -
对于句子对任务:
[CLS] + tokens_sentence_A + [SEP] + tokens_sentence_B + [SEP]
-
-
Padding & Truncation: 将序列填充(pad)或截断(truncate)到模型要求的固定最大长度(如 512)。
-
生成 Input IDs, Attention Mask, Token Type IDs:
-
input_ids: Token 在词汇表中的索引序列。 -
attention_mask: 标记哪些位置是实际 token (1),哪些是 padding (0),让模型忽略 padding。 -
token_type_ids/segment_ids: 标记每个 token 属于句子 A (0) 还是句子 B (1)。对于单句任务,通常全为0。
-
-
-
输出利用:
-
模型输出一个包含每个输入 token 的上下文表示的序列 (
last_hidden_state)。 -
根据任务类型,利用不同部分的输出:
-
[CLS]输出: 用于分类任务(情感分析、自然语言推理等)。 -
所有 token 输出: 用于序列标注任务(命名实体识别、词性标注)、问答(预测答案跨度)。
-
特定 token 输出: 有时用于特定任务。
-
-

