鸿蒙APP开发-语音识别_鸿蒙开发语音识别
鸿蒙提供了语音识别服务可以将音频信息转换为文本,基于此能力我们可以实现语音转文字、语音输入等功能。(目前仅支持中文离线模式)
若要实现语音识别功能,首先我们需要实现录音功能(注意开启麦克风权限),可参考文章鸿蒙APP开发-录制音频。只不过录制的音频不再写入文件,而是写入语音识别引擎。
创建语音识别引擎
若要实现语音识别,我们需要通过speechRecognizer模块的createEngine创建语音识别引擎,创建时传入引擎配置参数,创建后还要设置事件回调,用于自定义事件触发时的执行逻辑,这里我们重点关注onResult即可。
/** *创建引擎 */async createEngine() { let engine = await speechRecognizer.createEngine({ language: \'zh-CN\', //语种,当前仅支持“zh-CN”中文。 online: 1 //1为离线,当前仅支持离线模式 }) //设置事件回调,用于处理识别过程中各种事件发生时的处理逻辑 engine.setListener({ // 开始识别成功回调 onStart(sessionId: string, eventMessage: string) { console.info(`onStart, sessionId: ${sessionId} eventMessage: ${eventMessage}`); }, // 事件回调 onEvent(sessionId: string, eventCode: number, eventMessage: string) { console.info(`onEvent, sessionId: ${sessionId} eventCode: ${eventCode} eventMessage: ${eventMessage}`); }, // 识别结果回调,包括中间结果和最终结果 onResult: (sessionId: string, result: speechRecognizer.SpeechRecognitionResult) => { console.info(`onResult, sessionId: ${sessionId} sessionId: ${JSON.stringify(result)}`); //此处可获取识别结果,但注意要将结果赋值给状态变量需要用到this,则需要将此函数改为箭头函数 this.result = result.result }, // 识别完成回调 onComplete(sessionId: string, eventMessage: string) { console.info(`onComplete, sessionId: ${sessionId} eventMessage: ${eventMessage}`); }, // 错误回调,错误码通过本方法返回 // 返回错误码1002200002,开始识别失败,重复启动startListening方法时触发 onError(sessionId: string, errorCode: number, errorMessage: string) { console.error(`onError, sessionId: ${sessionId} errorCode: ${errorCode} errorMessage: ${errorMessage}`); }, }) return engine}这里有一个注意点就是箭头函数的问题,若直接在页面中使用,将结果赋值给状态变量,则将普通函数改为箭头函数。
创建采集器
这里的创建可以直接使用参考文章鸿蒙APP开发-录制音频中的部分内容。
根据官方文档要求的语音配置:
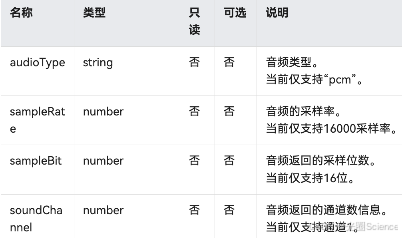
/** * 创建采集器 */async createCapturer() { const streamInfo: audio.AudioStreamInfo = { samplingRate: audio.AudioSamplingRate.SAMPLE_RATE_16000, sampleFormat: audio.AudioSampleFormat.SAMPLE_FORMAT_S16LE, channels: audio.AudioChannel.CHANNEL_1, encodingType: audio.AudioEncodingType.ENCODING_TYPE_RAW } const capturerInfo: audio.AudioCapturerInfo = { source: audio.SourceType.SOURCE_TYPE_VOICE_COMMUNICATION, capturerFlags: 1 } return await audio.createAudioCapturer({ streamInfo, capturerInfo })}初始化
在页面加载时,我们调用以上内容实现创建采集器和语音识别引擎。这里我们需要创建对应全局变量使得采集器和引擎可以全局调用。
补充:sessionId为识别会话,可以使用自动生成的uuid;写入到引擎的数据需要时Uint8Array类型,这里直接通过new实现转化。
this.createCapturer().then(capturer => { this.capturer = capturer this.capturer?.on(\'readData\', buffer => { this.engine?.writeAudio(this.sessionId, new Uint8Array(buffer)) })})this.createEngine().then(engine => { this.engine = engine //创建引擎绑定到状态变量})开始识别
创建函数编辑开始录音的逻辑,这里我们需要开启语音识别,开启录音监听。
这里用到的sessionId需要做到统一,audioInfo的配置与上述录音配置一致即可。
/** * 开始录音 */start() { //开启语音识别 this.engine?.startListening({ sessionId: this.sessionId, audioInfo: { //与录制的音频配置对应 audioType: \'pcm\', sampleRate: 16000, sampleBit: 16, soundChannel: 1 } }) //开启录音 this.capturer?.start()}结束识别
这里我们需要关闭录音,关闭引擎的识别状态。
/** * 结束录音 */async stop() { //结束录音 await this.capturer?.stop() //结束语音识别 this.engine?.finish(this.sessionId)}完整代码
import { speechRecognizer } from \'@kit.CoreSpeechKit\';import { audio } from \'@kit.AudioKit\';import { util } from \'@kit.ArkTS\';@Entry@Componentstruct SpeechRecognizer { @State result: string = \'\'; engine: speechRecognizer.SpeechRecognitionEngine | undefined capturer: audio.AudioCapturer | undefined sessionId: string = util.generateRandomUUID() /** * 创建引擎 */ async createEngine() { let engine = await speechRecognizer.createEngine({ language: \'zh-CN\', //语种,当前仅支持“zh-CN”中文。 online: 1 //1为离线,当前仅支持离线模式 }) //设置事件回调,用于处理识别过程中各种事件发生时的处理逻辑 engine.setListener({ // 开始识别成功回调 onStart(sessionId: string, eventMessage: string) { console.info(`onStart, sessionId: ${sessionId} eventMessage: ${eventMessage}`); }, // 事件回调 onEvent(sessionId: string, eventCode: number, eventMessage: string) { console.info(`onEvent, sessionId: ${sessionId} eventCode: ${eventCode} eventMessage: ${eventMessage}`); }, // 识别结果回调,包括中间结果和最终结果 onResult: (sessionId: string, result: speechRecognizer.SpeechRecognitionResult) => { console.info(`onResult, sessionId: ${sessionId} sessionId: ${JSON.stringify(result)}`); //此处可获取识别结果,但注意要将结果赋值给状态变量需要用到this,则需要将此函数改为箭头函数 this.result = result.result }, // 识别完成回调 onComplete(sessionId: string, eventMessage: string) { console.info(`onComplete, sessionId: ${sessionId} eventMessage: ${eventMessage}`); }, // 错误回调,错误码通过本方法返回 // 返回错误码1002200002,开始识别失败,重复启动startListening方法时触发 onError(sessionId: string, errorCode: number, errorMessage: string) { console.error(`onError, sessionId: ${sessionId} errorCode: ${errorCode} errorMessage: ${errorMessage}`); }, }) return engine } /** * 创建采集器 */ async createCapturer() { const streamInfo: audio.AudioStreamInfo = { samplingRate: audio.AudioSamplingRate.SAMPLE_RATE_16000, sampleFormat: audio.AudioSampleFormat.SAMPLE_FORMAT_S16LE, channels: audio.AudioChannel.CHANNEL_1, encodingType: audio.AudioEncodingType.ENCODING_TYPE_RAW } const capturerInfo: audio.AudioCapturerInfo = { source: audio.SourceType.SOURCE_TYPE_VOICE_COMMUNICATION, capturerFlags: 1 } return await audio.createAudioCapturer({ streamInfo, capturerInfo }) } aboutToAppear(): void { this.createCapturer().then(capturer => { this.capturer = capturer this.capturer?.on(\'readData\', buffer => { this.engine?.writeAudio(this.sessionId, new Uint8Array(buffer)) }) }) this.createEngine().then(engine => { this.engine = engine //创建引擎绑定到状态变量 }) } /** * 开始录音 */ start() { //开启语音识别 this.engine?.startListening({ sessionId: this.sessionId, audioInfo: { //与录制的音频配置对应 audioType: \'pcm\', sampleRate: 16000, sampleBit: 16, soundChannel: 1 } }) //开启录音 this.capturer?.start() } /** * 结束录音 */ async stop() { //结束录音 await this.capturer?.stop() //结束语音识别 this.engine?.finish(this.sessionId) } build() { Column() { Text(\'识别结果\' + this.result) Button(\'点击开始录音\') .onClick(() => { this.start() }) Button(\'结束录音\') .onClick(() => { this.stop() }) } .height(\'100%\') .width(\'100%\') }}
