(三十四)Flask之SQLAlchemy_sqlalchemy metadata 使用
目录:
- 每篇前言:
- SQLAlchemy
-
- 1. 安装:
-
- (1)执行原生SQL:
- (2)建表:
-
- 第一种:使用metadata创建表:
- 第二种:使用类的方式创建表:
- (3)增删改查:
-
- 增:
- 删:
- 改:
- 查:
- (4)拓展几个常用操作:
- (5)外键关联相关:
- (6)一对多场景:
- (7)多对多场景:
-
- 1. 表结构创建:
- 2. 插入数据:
- 4. 查询:
- 4. 删除:
- 2. 使用:
-
- (1)建表:
- (2) 拓展的基本增删改查:
- (3)常用查询:
- 3. 补充——神奇的子查询写法:
-
-
- 普通的子查询:
- 神奇的子查询:
-
- 4. 两种创建session的方式:
-
- (1)多线程操作时,为每个线程都创建一个session:
- (2)使用scoped_session创建session【推荐】:
- 拓展——flask-sqlalchemy中`SQLAlchemy().session`默认也是使用的上述第二种方式(scoped_session)
每篇前言:
🏆🏆作者介绍:【孤寒者】—CSDN全栈领域优质创作者、HDZ核心组成员、华为云享专家Python全栈领域博主、CSDN原力计划作者
- 🔥🔥本文已收录于Flask框架从入门到实战专栏:《Flask框架从入门到实战》
- 🔥🔥热门专栏推荐:《Python全栈系列教程》 | 《爬虫从入门到精通系列教程》 | 《爬虫进阶+实战系列教程》 | 《Scrapy框架从入门到实战》 | 《Flask框架从入门到实战》 | 《Django框架从入门到实战》 | 《Tornado框架从入门到实战》 | 《爬虫必备前端技术栈》
- 🎉🎉订阅专栏后可私聊进一千多人Python全栈交流群(手把手教学,问题解答);进群可领取Python全栈教程视频 + 多得数不过来的计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我【博主V信:GuHanZheCoder】一起学习进步,一个人可以走的很快,一群人才能走的更远!
👇 👉 🚔文末扫码关注本人公众号~🚔 👈 ☝️
SQLAlchemy
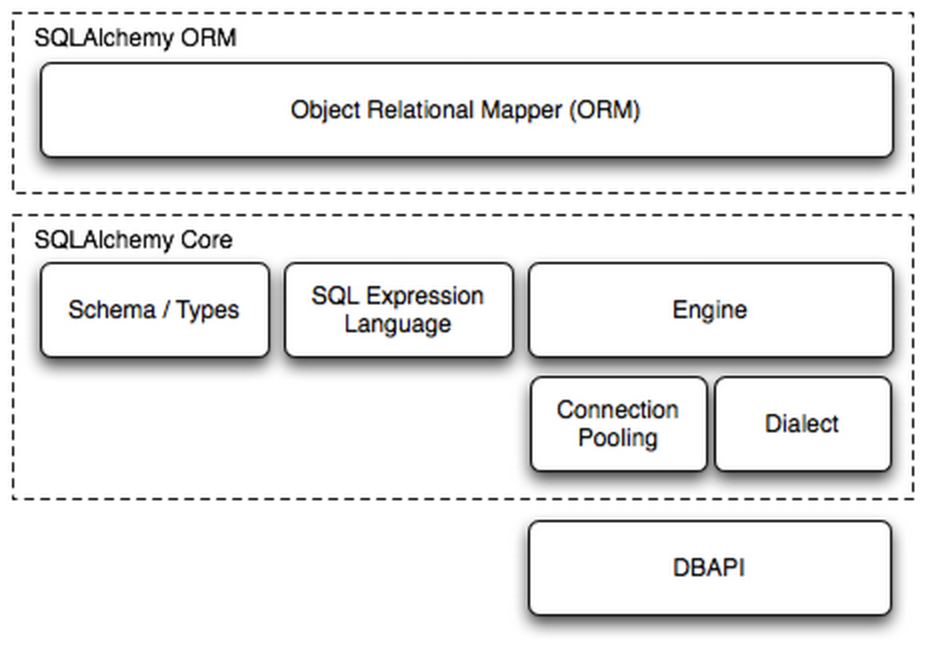
SQLAlchemy是一个Python编程语言下的SQL工具和对象关系映射(ORM)库。它提供了一种以更Pythonic的方式与数据库进行交互的方式。通过SQLAlchemy,我们可以使用Python类和对象来表示数据库表和查询,而不是直接使用SQL语句。该框架建立在数据库API之上,使用对象关系映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。如下第一张图:
该库的主要组件包括:
-
Core部分: 提供SQL表达式语言,允许你以Python代码的方式构建和执行SQL语句。
-
ORM部分: 允许你定义数据库模型,将数据库表映射到Python类,并通过这些类来进行数据库操作,而无需直接编写SQL语句。
SQLAlchemy的优势包括灵活性、可移植性和强大的查询功能。它支持多种数据库后端,如SQLite、MySQL、PostgreSQL等。通过使用ORM,可以更轻松地进行数据库操作,而无需深入了解底层的SQL语法。
知识点补给站:
第一个——什么是ORM:
ORM(对象关系映射)是一种编程技术,它将数据库中的数据映射到编程语言中的对象,使得通过对象来操作数据库变得更加直观和方便。ORM框架负责处理数据库操作,开发者可以使用面向对象的方式进行数据库交互,而不必直接编写SQL语句。这提供了一种抽象层,简化了数据库操作的复杂性。
对象关系映射:
- 类 ——> 表
- 对象 ——> 记录(一行数据)
############################################################################################
第二个——ORM和原生SQL哪个好?
两个都好,选择ORM或原生SQL通常取决于项目需求和个人偏好。
ORM的优点:
抽象化: ORM提供了面向对象的抽象,使得数据库操作更接近编程语言的习惯,减少了直接编写SQL的需要。
可维护性: ORM使代码更清晰、易读,减少了手动管理数据库连接和结果集的繁琐细节,提高了代码的可维护性。
跨数据库平台: ORM通常支持多种数据库平台,因此可以轻松切换数据库引擎而无需更改大量代码。
生产力: ORM减少了手动编写SQL语句的时间,提高了开发速度,尤其是在简单到中等复杂度的项目中。
原生SQL的优点:
灵活性: 直接使用原生SQL语句能够更灵活地执行复杂查询、优化和调整数据库操作,适用于一些高度优化的场景。
性能: 对于一些复杂的查询或涉及大量数据的操作,原生SQL通常能够更好地优化执行计划,提高性能。
数据库专业性: 对于有丰富数据库经验的开发者,直接使用原生SQL可能更符合其专业知识,更容易理解和调优。
综合考虑:
在简单项目和迅速开发的场景下,ORM可能更具优势,可以提高开发效率。而在对性能要求极高、需要进行复杂查询和数据库优化的情况下,原生SQL可能更为合适。在实际应用中,也可以根据项目的具体情况,将ORM和原生SQL结合使用,发挥各自的优势。
############################################################################################
第三个——DB First 和 Code First:
DB First(数据库优先):
DB First 是一种开发方法,其中开发人员首先定义数据库结构,然后从数据库中生成相应的类或实体。通常,这涉及使用工具或ORM(对象关系映射)框架,能够自动生成与数据库表相对应的类。
- 步骤:
- 定义数据库表结构,包括表、列、关系等。
- 使用工具或ORM框架,通过数据库连接获取表的元数据。
- 自动生成相应的类或实体,这些类的属性通常映射到数据库表的字段。
- 优点:
- 快速创建实体类,省去手动编写类的步骤。
- 可以确保数据库结构与代码实体的一致性。
- 缺点:
- 不够灵活,对于数据库结构的更改可能需要重新生成类。
- 自动生成的代码可能不符合特定编码风格要求。
Code First(代码优先):
Code First 则是相反的方法,开发人员首先定义应用程序中的类或实体,然后根据这些类创建数据库表。ORM框架负责将类与数据库表进行映射。
- 步骤:
- 定义应用程序中的类,这些类通常表示数据库表。
- 使用工具或ORM框架,根据类的定义生成数据库表。
- 优点:
- 更灵活,可以通过代码轻松调整数据库结构。
- 可以使用面向对象的思维方式设计应用程序。
- 缺点:
- 初始开发可能相对慢,需要手动创建类。
- 需要注意数据库和类的一致性,特别是在复杂的关系映射中。
选择:
选择DB First还是Code First通常取决于项目需求和开发人员的偏好。DB First适用于已有数据库结构的项目,而Code First适用于从零开始创建应用程序的情况。在一些项目中,也可以采用混合的方式,结合两者的优势。
###########################################################################################
第四个——ORM的实现原理(Unit of Work 设计模式):
ORM的实现原理:
ORM(对象关系映射)通过将对象模型和关系数据库之间建立映射,实现了对象与数据库表之间的转换。以下是ORM的主要实现原理:
映射: ORM通过映射将对象的属性映射到数据库表的字段,建立对象与数据库之间的关系。这包括对象的属性类型、关系映射(如一对多、多对多关系)等。
查询语言: ORM提供了一种查询语言,允许开发人员使用面向对象的方式进行数据库查询,而无需直接编写SQL语句。这种查询语言被翻译成对应的SQL查询。
数据操作: ORM负责将对象的状态与数据库同步,包括插入、更新、删除等操作。它提供了一组API,开发人员通过这些API对对象进行CRUD操作,ORM则负责将这些操作映射为对应的SQL语句。
事务管理: ORM通常支持事务管理,确保对数据库的操作是原子的、一致的、隔离的、持久的(ACID特性)。
DDD中的Unit of Work(工作单元):
在领域驱动设计(DDD)中,Unit of Work是一种设计模式,用于管理对象的生命周期和数据的事务性。在ORM中,Unit of Work负责跟踪对象的变化并协调这些变化的持久化。
对象追踪: Unit of Work负责追踪被加载到内存中的对象的状态变化,包括新增、修改、删除等。
事务控制: Unit of Work在一次业务操作中负责管理事务的开始和结束,以确保一系列的操作要么全部成功,要么全部失败,从而维护数据的一致性。
协调持久化: Unit of Work协调将变化同步到数据库,确保对象的状态与数据库的一致性。
在ORM中,Unit of Work与数据映射器(Mapper)协同工作,确保对象与数据库之间的交互是有效且一致的。
1. 安装:
pip install sqlalchemy注1:SQLAlchemy无法修改表结构,如果需要可以使用开源软件Alembic来完成。
注2:SQLAlchemy本身无法操作数据库,其内部使用pymysql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作。
(1)执行原生SQL:
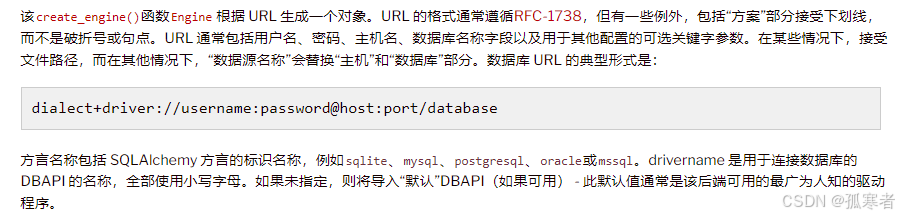
from sqlalchemy import create_engine, textengine = create_engine(\"mysql+pymysql://root:123456@127.0.0.1:3306/gset\", max_overflow=5)connection = engine.connect()result = connection.execute(text(\'select * from translate_log\'))print(result.fetchall())拓展1:可指定操作各类数据库,create_engine里的数据库链接URL详见官网:https://docs.sqlalchemy.org/en/20/core/engines.html#sqlalchemy.create_engine
URL的典型形式如下图:
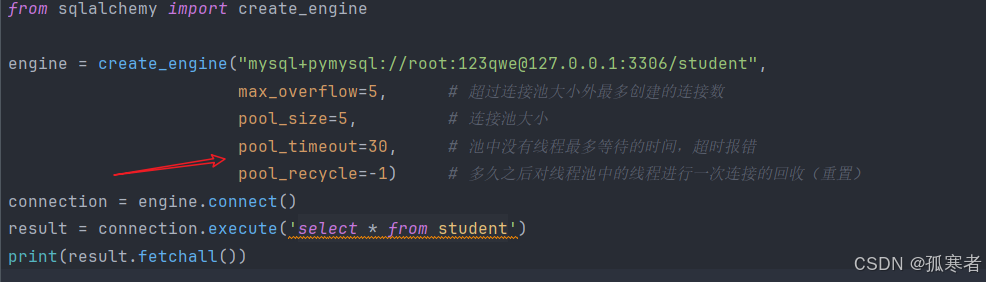
拓展2:SQLAlchemy自带线程池:
(2)建表:
SQLAlchemy内部组件调用顺序为:使用 Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 进行数据库操作。Engine使用Schema Type创建一个特定的结构对象,之后通过SQL Expression Language将该对象转换成SQL语句,然后通过 ConnectionPooling 连接数据库,再然后通过 Dialect 执行SQL,并获取结果。
TIPS:有两种建表的方式可选——使用类的方式和使用metadata方式创建表。二者区别在于metadata可以不指定主键,而是用class方式必须要求有主键。
第一种:使用metadata创建表:
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaDataengine = create_engine(\"mysql+pymysql://root:123456@127.0.0.1:3306/gset\", echo=True, # echo=True打印输出信息和执行的sql语句 默认Flase max_overflow=5 )meta = MetaData() # 生成源类# 定义表结构user = Table(\'user\', meta, Column(\'id\', Integer, nullable=Table, autoincrement=True, primary_key=True), Column(\'name\', String(20), nullable=True), Column(\'age\', Integer, nullable=True) )host = Table(\'host\', meta, Column(\'ip\', String(20), nullable=True), Column(\'hostname\', String(20), nullable=True), )meta.create_all(engine) # 创建表,如果存在则忽视第二种:使用类的方式创建表:
from sqlalchemy import create_engine, Column, Integer, String, Datefrom sqlalchemy.ext.declarative import declarative_baseengine = create_engine(\"mysql+pymysql://root:123456@127.0.0.1:3306/gset\", echo=True, max_overflow=5 )base = declarative_base()# 定义表结构class User(base): __tablename__ = \'book\' id = Column(Integer, primary_key=True) name = Column(String(32)) date = Column(Date)base.metadata.create_all(engine) # 创建表,如果存在则忽视# Base.metadata.drop_all(engine) 删除表(3)增删改查:
增:
from sqlalchemy import create_engine, Column, Integer, Stringfrom sqlalchemy.orm import sessionmaker, declarative_baseengine = create_engine(\"mysql+pymysql://root:123456@127.0.0.1:3306/gset\", max_overflow=5, echo=True)base = declarative_base() # 生成orm基类class User(base): __tablename__ = \'user\' id = Column(Integer, autoincrement=True, primary_key=True) name = Column(String(20)) age = Column(Integer)sessoion_class = sessionmaker(bind=engine) # 创建与数据库的会话类Session = sessoion_class() # 生成会话实例user1 = User(name=\'wd\', age=22) # 生成user对象Session.add(user1) # 添加user1,可以使用add_all,参数为列表或者tupleSession.commit() # 提交# Session.rollback() # 回滚Session.close() # 关闭会话删:
data = Session.query(User).filter(User.age == 22).delete() # 会删所有Session.commit()Session.close()改:
# data=Session.query(User).filter(User.age > 20).update({\"name\": \'jarry\'}) # update语法data = Session.query(User).filter(User.age == 22).first()data.name = \'GuHanZheCoder\'Session.commit()Session.close()查:
from sqlalchemy import create_engine, Column, Integer, Stringfrom sqlalchemy.orm import sessionmaker, declarative_baseengine = create_engine(\"mysql+pymysql://root:123456@127.0.0.1:3306/gset\", max_overflow=5, # echo=True )base = declarative_base()class User(base): __tablename__ = \'user\' id = Column(Integer, autoincrement=True, primary_key=True) name = Column(String(20)) age = Column(Integer) def __repr__(self): # 定义 return \"(%s, %s, %s)\" % (self.id, self.name, self.age)sessoion_class = sessionmaker(bind=engine)Session = sessoion_class()# get语法获取primrykey中的关键字,在这里主键为id,获取id为3的数据data = Session.get(User, 3)print(data)data = Session.query(User).filter(User.age > 22, User.name == \'wd\').first()print(data)# filter语法(传的是表达式)两个等于号,filter_by语法(传的是参数)一个等于号,可以有多个filter,如果多个数据返回列表,first代表获取第一个,为all()获取所有data = Session.query(User).filter(User.age == 20, User.name.in_([\'GuHanZheCoder\', \'wd\'])).all() # in语法print(data)data = Session.query(User).filter_by(name=\'wd\').first()print(data)Session.commit()Session.close()(4)拓展几个常用操作:
# 获取所有数据data = Session.query(User).all() # 获取user表所有数据for i in data: print(i)# 统计# count = Session.query(User).count() # 获取总条数count = Session.query(User).filter(User.name.like(\"w%\")).count() # 获取过滤后总条数print(count)# 分组from sqlalchemy import func # 需要导入func函数res = Session.query(func.count(User.name), User.name).group_by(User.name).all()print(res)(5)外键关联相关:
from sqlalchemy import create_engine, Column, Integer, String, ForeignKeyfrom sqlalchemy.orm import relationship, declarative_basefrom sqlalchemy.orm import sessionmakerengine = create_engine(\"mysql+pymysql://root:123456@127.0.0.1:3306/gset?charset=gbk\", # ?charset是连接数据库的字符集编码(和数据库的编码一样) encoding=\"utf-8\", echo=True, max_overflow=5 )Base = declarative_base()class User(Base): __tablename__ = \'user\' id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(20)) age = Column(Integer) def __repr__(self): return \"\" % (self.id, self.name, self.age)class Host(Base): __tablename__ = \'host\' user_id = Column(Integer, ForeignKey(\'user.id\')) # user_id关联user表中的id hostname = Column(String(20)) ip = Column(String(20), primary_key=True) # 通过host_user查询host表中关联的user信息,通过user_host,在user表查询关联的host,与生成的表结构无关,只是为了方便查询 host_user = relationship(\'user\', backref=\'user_host\') def __repr__(self): return \"\" % (self.user_id, self.hostname, self.ip)Base.metadata.create_all(engine)Session_class = sessionmaker(bind=engine)Session = Session_class()host1 = Session.query(Host).first()print(host1.host_user)print(host1)user1 = Session.query(User).first()print(user1.user_host)# 骚操作:# 如果想在增加一条host表数据的同时添加一条user表数据,因为relationship的使用,可以一行代码实现:Session.add(Host(hostname=\"百度\", host_user=User(name=\"xiaowang\", age=18)))(6)一对多场景:
应用场景:
-
当我们购物的时候,有一个收发票地址,和一个收货地址。
关系如下:默认情况下,收发票地址和收获地址是一致的,但是也有可能我想买东西送给别人,而发票要自己留着,那收货的地址和收发票的地址可以不同。
即:一个顾客可以有多个地址,而每个地址只属于一个顾客。
这就需要
Customer和Address类之间建立一对多的关系~
from sqlalchemy import Integer, ForeignKey, String, Columnfrom sqlalchemy.orm import relationship, declarative_baseBase = declarative_base()class Customer(Base): __tablename__ = \'customer\' id = Column(Integer, primary_key=True) name = Column(String) billing_address_id = Column(Integer, ForeignKey(\"address.id\")) shipping_address_id = Column(Integer, ForeignKey(\"address.id\")) billing_address = relationship(\"Address\", foreign_keys=[billing_address_id]) shipping_address = relationship(\"Address\", foreign_keys=[shipping_address_id]) # 同时关联同一个表的一个字段,使用relationship需要指定foreign_keys来说明关联时使用的外键,为了让sqlalchemy清楚表与表之间的关系class Address(Base): __tablename__ = \'address\' id = Column(Integer, primary_key=True) street = Column(String) city = Column(String) state = Column(String)(7)多对多场景:
很多时候,我们会使用多对多外键关联,例如:书和作者,学生和课程,即:书可以有多个作者,而每个作者可以写多本书,orm提供了更简单方式操作多对多关系,在进行删除操作的时候,orm会自动删除相关联的数据。
1. 表结构创建:
from sqlalchemy import Column, Table, String, Integer, ForeignKeyfrom sqlalchemy import create_enginefrom sqlalchemy.orm import relationship, declarative_baseengine = create_engine(\"mysql+pymysql://root:123456@127.0.0.1:3306/gset?charset=gbk\", echo=True, max_overflow=5 )Base = declarative_base()stu_cour = Table(\'stu_cour\', Base.metadata, Column(\'stu_id\', Integer, ForeignKey(\'student.id\')), Column(\'cour_id\', Integer, ForeignKey(\'course.id\')) )class student(Base): __tablename__ = \'student\' id = Column(Integer, autoincrement=True, primary_key=True) stu_name = Column(String(32)) stu_age = Column(String(32)) # course是关联的表,secondary是中间表,当然,也可以在第三张关联表中使用两个relationship关联student表和course表 courses = relationship(\'course\', secondary=stu_cour, backref=\'students\') def __repr__(self): return \'\' % self.stu_nameclass course(Base): __tablename__ = \'course\' id = Column(Integer, autoincrement=True, primary_key=True) cour_name = Column(String(32)) def __repr__(self): return \'\' % self.cour_nameBase.metadata.create_all(engine)2. 插入数据:
from sqlalchemy import Column, Table, String, Integer, ForeignKeyfrom sqlalchemy import create_enginefrom sqlalchemy.orm import relationshipfrom sqlalchemy.orm import sessionmaker, declarative_baseengine = create_engine(\"mysql+pymysql://root:123456@127.0.0.1:3306/gset?charset=gbk\", echo=True, max_overflow=5 )Base = declarative_base()stu_cour = Table(\'stu_cour\', Base.metadata, Column(\'stu_id\', Integer, ForeignKey(\'student.id\')), Column(\'cour_id\', Integer, ForeignKey(\'course.id\')) )class student(Base): __tablename__ = \'student\' id = Column(Integer, autoincrement=True, primary_key=True) stu_name = Column(String(32)) stu_age = Column(String(32)) # course是关联的表,secondary是中间表,当然,也可以在第三张关联表中使用两个relationship关联student表和course表 courses = relationship(\'course\', secondary=stu_cour, backref=\'students\') def __repr__(self): return \'\' % self.stu_nameclass course(Base): __tablename__ = \'course\' id = Column(Integer, autoincrement=True, primary_key=True) cour_name = Column(String(32)) def __repr__(self): return \'\' % self.cour_namesession_class = sessionmaker(bind=engine)session = session_class()stu1 = student(stu_name=\'wd\', stu_age=\'22\')stu2 = student(stu_name=\'jack\', stu_age=33)stu3 = student(stu_name=\'rose\', stu_age=18)c1 = course(cour_name=\'linux\')c2 = course(cour_name=\'python\')c3 = course(cour_name=\'go\')stu1.courses = [c1, c2] # 添加学生课程关联stu2.courses = [c1]stu3.courses = [c1, c2, c3]session.add_all([stu1, stu2, stu3, c1, c2, c3])session.commit()拓展:
- 因为使用了relationship,还可以像下面这样添加数据!
# 正向操作:obj = student(stu_name=\"xiaowang\", stu_age=18)obj.courses = [course(cour_name=\"物理\"), course(cour_name=\"化学\")]session.add(obj)session.commit()# 反向操作:obj = course(cour_name=\"英语\")obj.students = [sutdent(stu_name=\"xiaoming\", stu_age=11), student(stu_name=\"xiaozhang\", stu_age=16)]session.add(obj)session.commit()4. 查询:
session_class = sessionmaker(bind=engine)session = session_class()stu_obj = session.query(student).filter(student.stu_name == \'wd\').first()print(stu_obj.courses) # 查询wd学生所报名的课程cour_obj = session.query(course).filter(course.cour_name == \'python\').first()print(cour_obj.students) # 查询报名python课程所对应的学生session.commit()4. 删除:
session_class = sessionmaker(bind=engine)session = session_class()cour_obj = session.query(course).filter(course.cour_name == \'python\').first()session.delete(cour_obj) # 删除python课程session.commit()2. 使用:
【单表+一对多+多对多】
(1)建表:
from sqlalchemy.orm import declarative_basefrom sqlalchemy import Column, Integer, String, UniqueConstraint, Index, DateTime, ForeignKeyfrom sqlalchemy import create_engineimport datetimeengine = create_engine(\"mysql+pymysql://root:123456@127.0.0.1:3306/gset?charset=gbk\", echo=True, max_overflow=5 )Base = declarative_base()class Classes(Base): __tablename__ = \'classes\' id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32), nullable=False, unique=True)class Student(Base): __tablename__ = \'student\' id = Column(Integer, primary_key=True, autoincrement=True) username = Column(String(32), nullable=False, unique=True) password = Column(String(64), nullable=False) ctime = Column(DateTime, default=datetime.datetime.now) class_id = Column(Integer, ForeignKey(\"classes.id\"))class Hobby(Base): __tablename__ = \'hobby\' id = Column(Integer, primary_key=True) caption = Column(String(50), default=\'王者荣耀\')# 多对多的第三张表需要手动写class Student2Hobby(Base): __tablename__ = \'student2hobby\' id = Column(Integer, primary_key=True, autoincrement=True) student_id = Column(Integer, ForeignKey(\'student.id\')) hobby_id = Column(Integer, ForeignKey(\'hobby.id\')) __table_args__ = (\"\"\"唯一索引(UniqueConstraint):在表格的定义中添加一个唯一索引,该索引由 \'student_id\' 和 \'hobby_id\' 两个字段组成,并使用名称 \'uix_student_id_hobby_id\' 标识。唯一索引的目的是确保表格中的每一行都具有唯一的 (\'student_id\', \'hobby_id\') 组合。\"\"\" UniqueConstraint(\'student_id\', \'hobby_id\', name=\'uix_student_id_hobby_id\'), \"\"\"索引(Index):添加一个名为 \'ix_sutdent_id_hobby_id\'的索引,包含两个字段 \'student_id\' 和 \'hobby_id\'。\"\"\" # Index(\'ix_sutdent_id_hobby_id\', \'student_id\', \'hobby_id\') )Base.metadata.create_all(engine)知识点补给站:
-
唯一索引(UniqueConstraint)的作用:
- 确保唯一性: 确保在表格中没有两行记录具有相同的 (‘student_id’, ‘hobby_id’) 组合。如果试图插入或更新记录,导致违反这一唯一性规则,将会引发唯一性冲突的异常。
- 优化查询: 数据库可以使用索引来更有效地执行与这两个字段有关的查询,提高查询性能。
总体而言,通过设置唯一索引,可以在数据库层面强制确保某些字段或字段组合的唯一性。
-
索引(Index)的作用:
- 提高查询性能: 数据库可以使用这个索引更快地执行基于 ‘student_id’ 和 ‘hobby_id’ 的查询,减少查询的时间复杂度。
- 降低插入、更新、删除性能: 索引的存在可能使插入、更新、删除等写操作的性能略有降低,因为除了对表格的修改外,还需要维护索引的结构。
(2) 拓展的基本增删改查:
增:
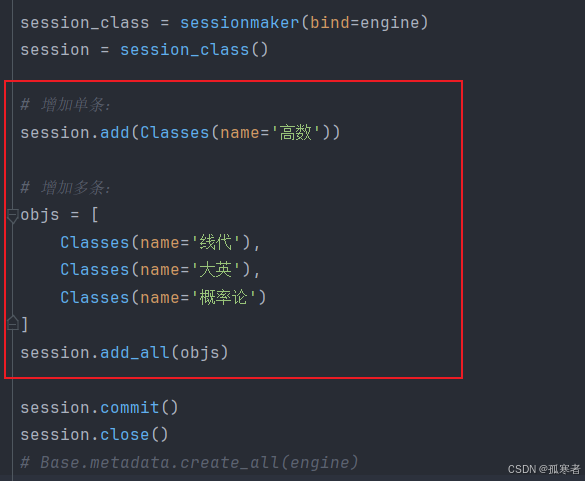
改:
(将classes表中id大于0的所有数据的name字段加上后缀111)
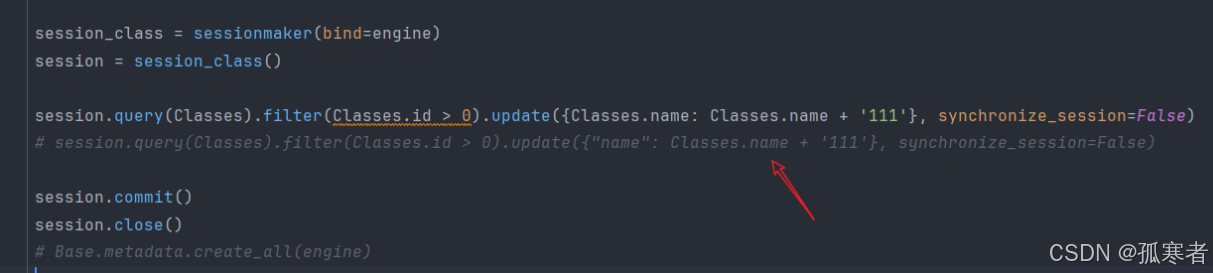
注意:
上述是字符串,所以synchronize_session值为False;
如果是数值的话,synchronize_session值需要改为evaluate。
查:
(1)label —— 给字段取别名:
# select id, name from classesresult = session.query(Classes.id, Classes.name).all()for item in result: # print(item[0], item[1]) print(item.id, item.name)# select id, name as xx from classesresult_2 = session.query(Classes.id, Classes.name.label(\'xx\')).all()for item in result_2: print(item.id, item.xx)(2)text + params —— 构造复杂查询:
res = session.query(Student).filter(text(\"id<:value and name=:name\")).params(value=22, name=\'xiaoming\').order_by(Student.id).all()(3)from_statement —— 构造SQL语句:
res = session.query(Student).from_statement(text(\"SELECT * FROM student where name=:name\")).params(name=\'xiaowang\').all()# SELECT * FROM student where name=\"xiaowang\"(4)查询打印所有学生信息(包含对应的班级名称):
# 方法一:# isouter=True 代表左查询objs = session.query(Student.id, Student.name, Classes.name).join(Classes, isouter=True).all()print(objs)# 方法二:objs = session.query(Student).all()for item in objs: print(item.id, item.username, item.class_id, item.cls.name)方法二需要在Student类中加下述代码:
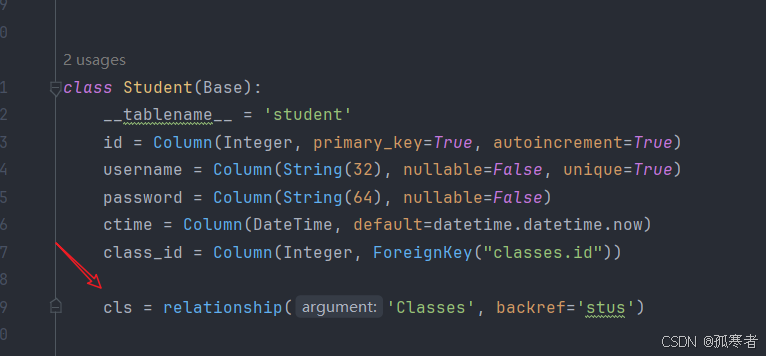
因为加了上述代码,所以现在Classes类中也多了一个字段stus。
查询课程名为:大学体育的所有学生的信息。
obj = session.query(Classes).filter(Classes.name == \'大学体育\').first()student_list = obj.stusfor item in student_list: print(item.id, item.username)(3)常用查询:
常用的【条件】查询:
res = session.query(Classes).filter(Classes.id.between(1, 3), Classes.name == \'大英\').all()res = session.query(Classes).filter(Classes.id.in_([1, 2, 3])).all()res = session.query(Classes).filter(~Classes.id.in_([1, 2, 3])).all()res = session.query(Classes).filter(Classes.id.in_(session.query(Classes.id).filter_by(name=\'大英\'))).all()from sqlalchemy import and_, or_res = session.query(Classes).filter(and_(Classes.id > 3, Classes.name == \'大英\')).all()res = session.query(Classes).filter(or_(Classes.id < 2, Classes.name == \'物理\')).all()res = session.query(Classes).filter( or_( Classes.id < 2, and_(Classes.name == \'化学\', Classes.id > 3), Classes.name != \"\" )).all()通配符:
res = session.query(Classes).filter(Classes.name.like(\"大%\")).all()res = session.query(Classes).filter(~Classes.name.like(\"大%\")).all()限制:
res = session.query(Classes)[1: 2]排序:
res = session.query(Classes).order_by(Classes.name.desc()).all()res = session.query(Classes).order_by(Classes.name.desc(), Classes.id.asc()).all() # 写多个的话,优先按最左边的排序,相同的话按第二个排序,以次类推分组:
from sqlalchemy.sql import funcres = session.query(Student).group_by(Student.class_id).all()res = session.query( func.max(Student.id), func.sum(Student.id), func.min(Student.id)).group_by(Student.name).all()res = session.query( func.max(Student.id), func.sum(Student.id), func.min(Student.id)).group_by(Student.name).having(func.min(Student.id) > 2).all()连表:
res = session.query(Student, Hobby).filter(Student.id == Hobby.id).all()res = session.query(Student).join(Hobby).all() # inner join res = session.query(Student).join(Hobby, isouter=True).all() # left join组合:
# objs = session.query(A).join(B, and_(A.xid == B.id, A.id > 2), isouter=True).all()# select * from a left join b on a.xid = b.id and id > 2q1 = session.query(Student.name).filter(Student.id > 2)q2 = session.query(Hobby.caption).filter(Hobby.id < 2)res = q1.union(q2).all() # 有重复只留一个q1 = session.query(Student.name).filter(Student.id > 2)q2 = session.query(Hobby.caption).filter(Hobby.id < 2)res = q1.union_all(q2).all() # 都留3. 补充——神奇的子查询写法:
普通的子查询:
select * from A where id in (select a_id from B)select * from A where id in [1, 2, 3]神奇的子查询:
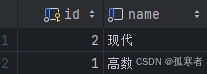
名为classes的表:
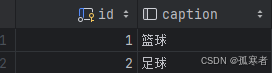
名为hobby的表:
select id, name from classes;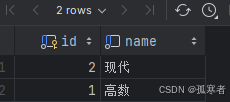
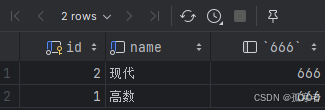
select id, name, 666 from classes;(这样会给查询结果新增一列,值都为666)
# 神奇的子查询:select id, name, 666, (select id from hobby where hobby.id = classes.id) as bfrom classes;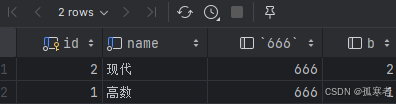
SQLAlchemy也支持上述“神奇的子查询”:
sub_query = session.query(func.count(Server.id).label(\"sid\")).filter(Server.id == Group.id).correlate(Group).as_scalar()result = session.query(Group.name, sub_query)\"\"\"SELECT group.name AS group_name, (SELECT count(server.id) AS sid FROM server WHERE server.id = group.id) AS anon_1 FROM group\"\"\"简单讲一下:
目的是检索每个Group的name列以及与每个Group相关的Server表的id列的数量。
-
func.count(Server.id).label(\"sid\"): 这一部分是一个聚合函数,计算Server表中id列的数量,并使用label方法给这个计数起了一个别名sid。 -
filter(Server.id == Group.id): 这是一个过滤条件,指定了在Server表和Group表之间使用id列进行匹配。 -
correlate(Group): 这将子查询与外部查询关联起来,确保子查询中的Server.id和外部查询中的Group.id是相关的。correlate(Group): 在SQLAlchemy中,correlate方法用于将子查询与外部查询关联起来,以确保子查询中的条件引用了外部查询的表。在这个例子中,correlate(Group)确保子查询中的Server.id引用的是外部查询的Group.id,这样就建立了关联。这是因为Server.id == Group.id条件需要在子查询中引用外部查询中的Group表,而不是创建一个独立的没有关联的子查询。 -
as_scalar(): 这将子查询转化为标量值,以便在主查询中使用。as_scalar(): 在SQLAlchemy中,as_scalar()方法用于将子查询转化为标量值,使其可以在主查询中作为一个单一的值使用。标量值意味着子查询返回的结果是一个单一的数值,而不是一个结果集。在这个例子中,通过调用as_scalar(),子查询func.count(Server.id).label(\"sid\")被转换为一个标量值,因此可以在主查询中像普通的列一样使用。 -
sub_query = ...: 这一行创建了一个子查询,其中计算了与每个Group相关的Server表中id列的数量,并将其命名为sid。 -
result = ...: 这一行使用主查询,选择了Group表中的name列和上述子查询sub_query。
最终,通过这个查询,将获得一个结果集,其中包含每个Group的name列和与每个Group相关的Server表的id列的数量。
4. 两种创建session的方式:
(1)多线程操作时,为每个线程都创建一个session:
import modelsfrom sqlalchemy.orm import sessionmakerfrom sqlalchemy import create_enginefrom threading import Threadengine = create_engine(\"mysql+pymysql://root:123456@127.0.0.1:3306/gset?charset=gbk\", # echo=True, pool_size=2, max_overflow=0 )XXXX = sessionmaker(bind=engine)def task(): session = XXXX() data = session.query(models.Classes).all() print(data) session.close()for i in range(10): t = Thread(target=task) t.start()这种方法需要注意的是:一旦开线程操作的话,一定要保证在线程里面创建session,如上。
如果在线程外面创建session就会报错!
(2)使用scoped_session创建session【推荐】:
可以猜到——这玩意底层是使用的threading.local()对象来实现的为每个线程创建及关闭session~
import modelsfrom sqlalchemy.orm import sessionmaker, scoped_sessionfrom sqlalchemy import create_enginefrom threading import Threadengine = create_engine(\"mysql+pymysql://root:123456@127.0.0.1:3306/gset?charset=gbk\", # echo=True, pool_size=2, max_overflow=5 )XXXX = sessionmaker(bind=engine)session = scoped_session(XXXX)def task(): # session = XXXX() data = session.query(models.Classes).all() print(data) session.remove() # scoped_session创建的session要用remove关闭for i in range(10): t = Thread(target=task) t.start()简单扣一波源码:
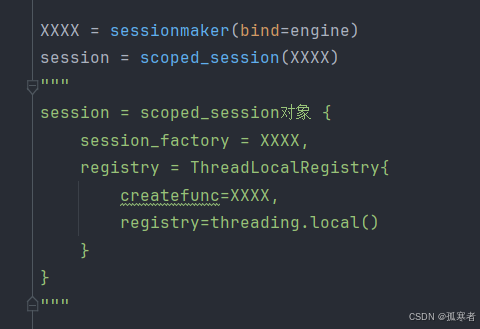
先看session = scoped_session(XXXX)做了什么?
进scoped_session():
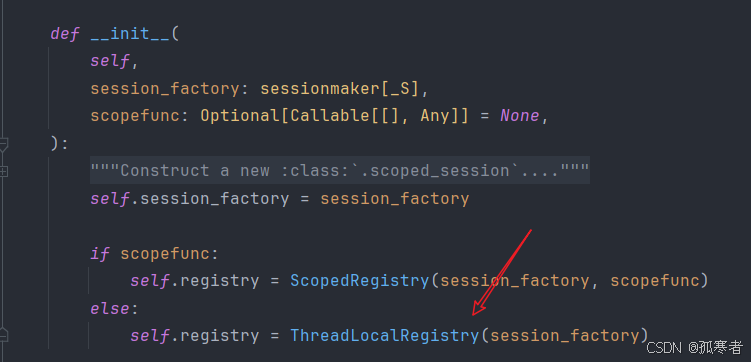
进ThreadLocalRegistry():

回一层:
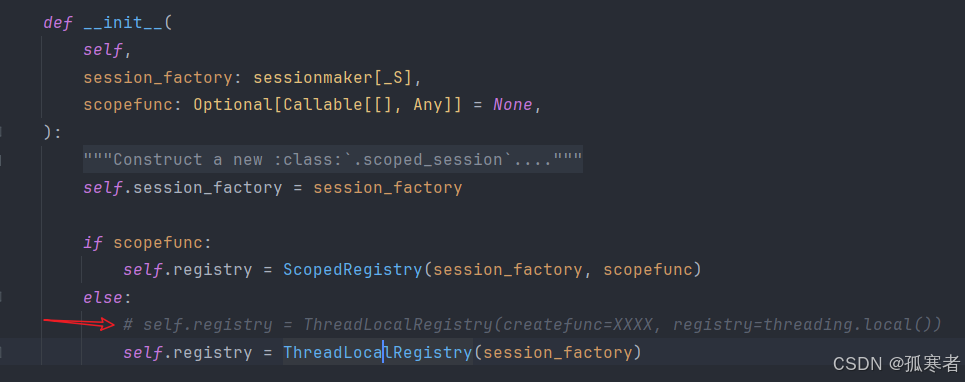
再会回一层::
继续看执行data = session.query(models.Classes).all()做了什么?
首先要找到query()方法在哪?
但是scoped_session类里面没有!而且这个类没有父类!
那么这个方法在哪呢????
-
切记:类的方法还可以通过反射
setattr来动态设置!!!class Demo(object): passfor i in [\'k1\', \'k2\']: setattr(Demo, i, lambda self: 1)obj = Demo()v = obj.k1()print(v) # 输出:1
所以继续看scoped_session类这个文件的下面:
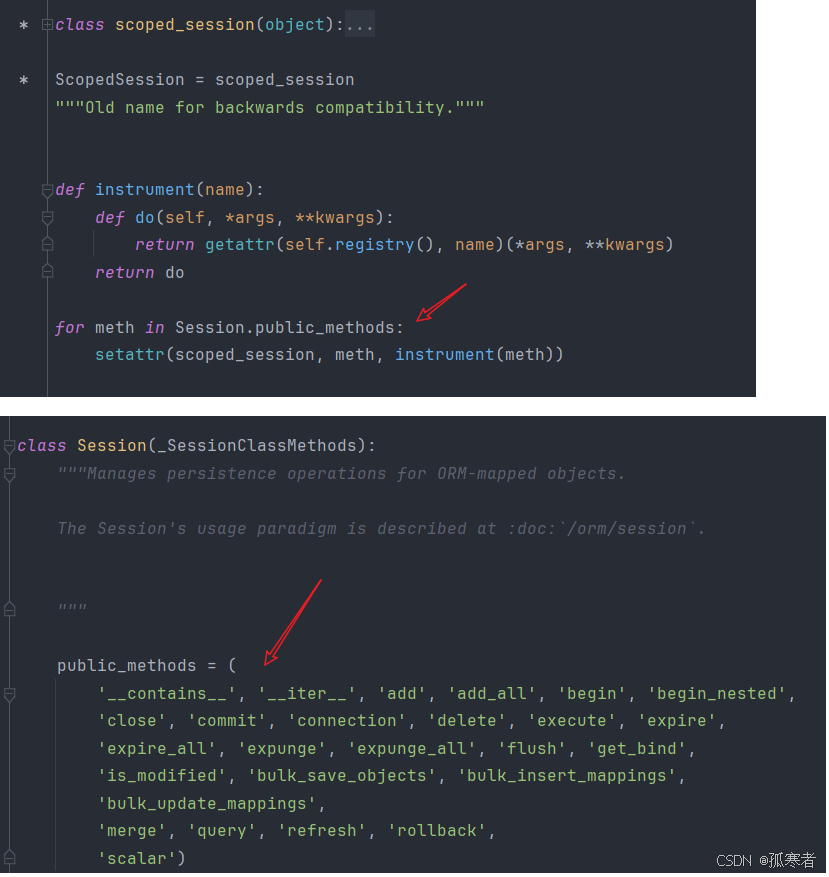
需要注意的是:上图中Session类就是第一种方法里创建的session对象所用的类,可以通过打印type证实!
所以上图就是将原本Session里的public_methods里的所有方法加到scoped_session类上!
比如add,add_all,query方法,加完之后就是这个样子:
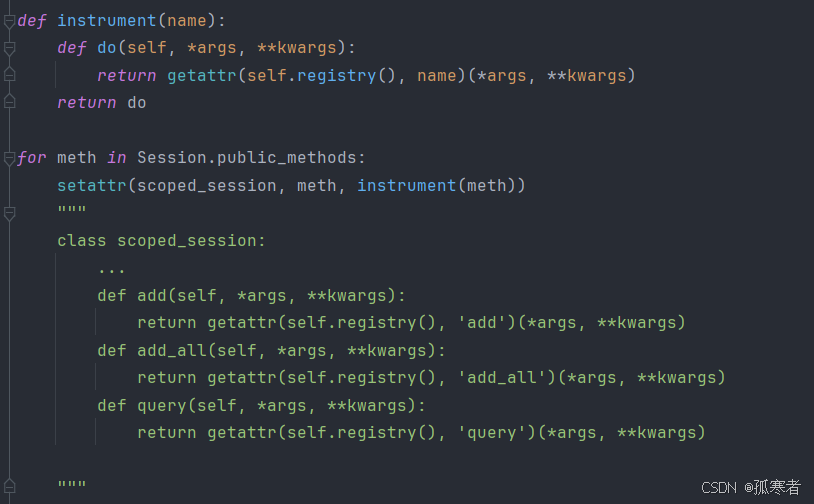
所以当执行data = session.query(models.Classes).all()的时候就会触发ThreadLocalRegistry对象的call方法:
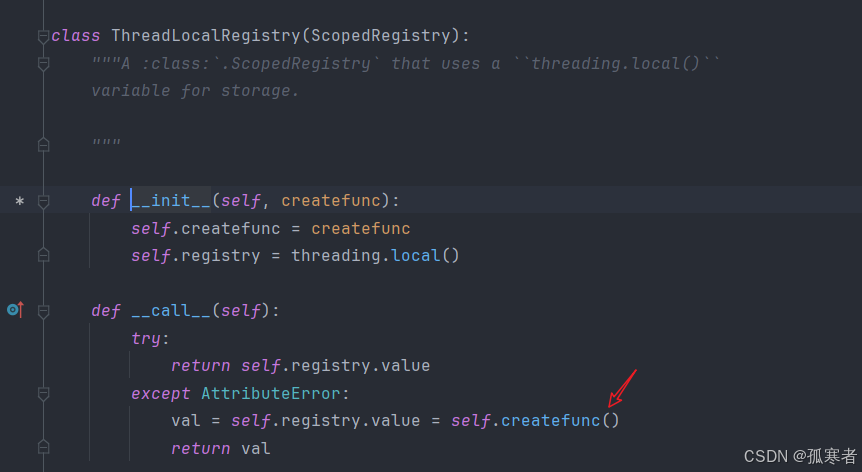
最开始self.registry里还没有值,所以会执行self.createfunc(),就是执行XXX()【第一种方法里的那个sessioin】并放到threading.local()里,这样就为对应线程创建了session!
然后就会触发getattr调用原来session对象的query方法~
继续看session.remove():
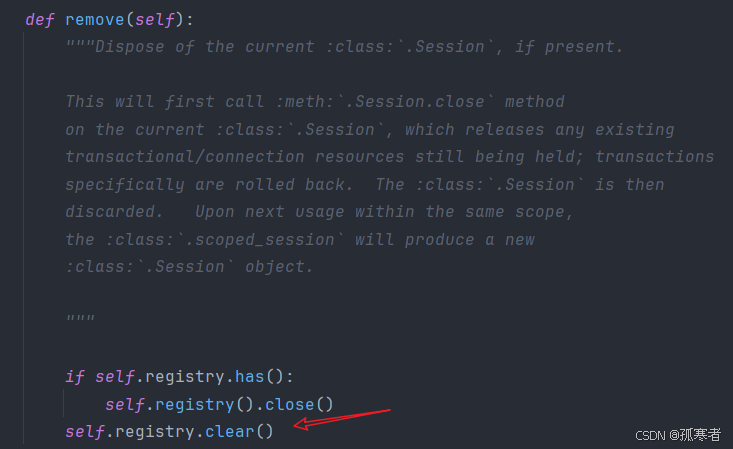
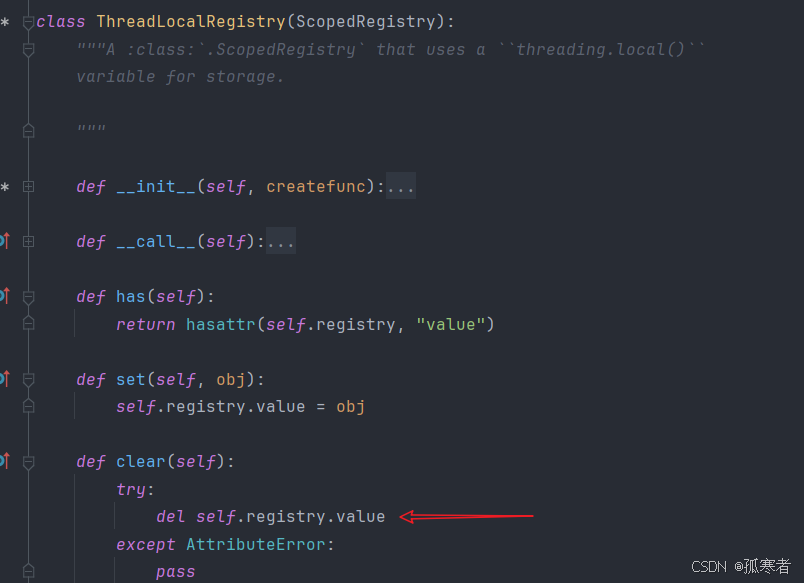
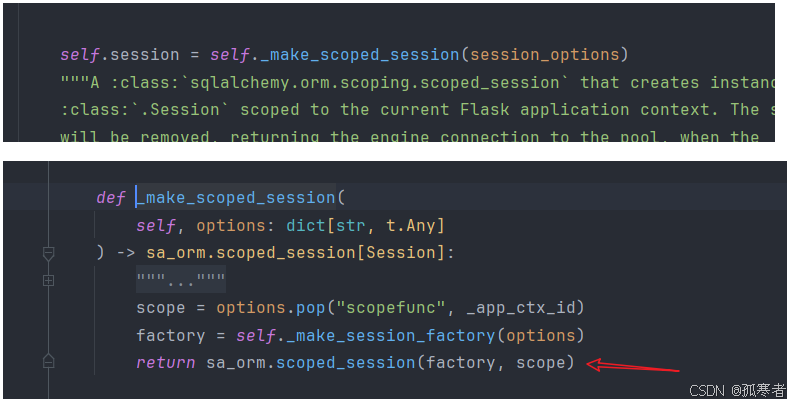
拓展——flask-sqlalchemy中SQLAlchemy().session默认也是使用的上述第二种方式(scoped_session)
👇🏻可通过点击下面——>关注本人运营 公众号👇🏻 🎯 深度交流 | 📌 标注“来自 CSDN”
🌟 解决问题,拓展人脉,共同成长!(非诚勿扰) 🚀 不止是交流,更是你的技术加速器!


